结合残差神经网络和语音诊断的帕金森病识别研究
2022-03-16黄方亮许欢庆沈同平
黄方亮,许欢庆,沈同平,金 力,俞 磊
安徽中医药大学 医药信息工程学院,安徽 合肥 230012
帕金森病(Parkinson’s Disease,PD)是一种常见的神经系统退行性疾病,现代医学尚不能痊愈[1]。因而研究PD的早期诊断对控制PD患者的病情,延长其生命具有重要意义[2]。有研究发现,声带损伤[3]这一早期症状出现在90%的PD患者中,声学分析主要表现为高振幅微扰,高基频微扰,低谐信噪比,低基频[4]。基于此,可以考虑通过提取语音信号中的声学特征进行PD的早期检测,此方法具有便利性、非入侵性、高效率等优点,被国内外广泛接受和应用。
国内外研究者主要采用传统的特征提取方法结合机器学习算法,通过分析语音信号实现PD识别。Max Little等[5]在2009年收集持续的元音发声/a/形成首个语音数据库。随后,Max Little等证明元音足以进行PD检测[6-7]。2013年,Sakar等分析了收集自PD患者的多种类型的语音用于PD诊断[8]。为提高识别准确率,Benba等基于Sakar的数据集,分别利用梅尔频率倒谱系数(MFCC)及其一阶、二阶导数[9]以及平均值来压缩提取的MFCC[10],利用人因子倒谱系数(HFCC)[11]提取声纹特征参数,采用结合不同核函数的SVM分类器进行分类。
近年来,深度学习在语音增强、情感识别和病理检测等语音处理中的应用取得了很好的效果[12],为利用声学特征识别PD患者提供了应用基础。Lucijano Berus等[13]将原始音频数据输入到人工神经网络(ANN),微调后再进行分类,但存在直接处理语音信号较复杂问题。师浩斌等[14]采用Alexnet模型对语谱图分类,取得86.67%的精确度。然而目前用于图像识别和分类效果较好的一些网络模型,如VGG16,作为数据驱动型模型,依赖于大量样本,而现阶段用于帕金森研究的音频数据总体较少且样本获取困难,导致机器学习算法过拟合,达不到好的识别效果[15]。本文采用信号处理技术提取PD病人和健康人的语音声学特征形成数据集,集合残差神经网络进行模型训练,以期从语音识别角度实现对PD患者的早期诊断,与传统的决策树分类方法进行对比发现,基于人工智能的残差神经网络具有很高的识别准确率,从而为PD患者在诊断方法上提供新的思路。
1 数据集和预处理
研究采用的数据集MDVR-KCL是由伦敦国王学院(King’s College London,KCL)医院于2017年采用移动智能手机与包含16例PD患者和21例健康人(healthy controls,HC)在内的被试者进行语音通话,邀请被试者朗读伊索寓言North Wind and the Sun并进行一段随机话题讨论,最终获得了采样率为44.1 kHz、分辨率为16位的高质量WAV格式音频文件集合。数据集下载地址:https://zenodo.org/record/2867216#.Xp4kVsgzaUl。
原始音频数据集近1.27 GB,为了挖掘其中声学特征从而构建机器学习数据集,本研究采用Python工具对原始音频数据进行预处理,利用parseImouth库,使用Praat可实现包含周期变化、峰值变化及谐波信噪比等复杂语音特征的提取。将体积庞大的语音数据转换成包含多个特征的一维向量数据集,借助传统分类方法和卷积神经网络进行分类对比从而输出诊断率。图1所示为诊断识别整体流程图。

图1 诊断识别整体流程图
数据集由12个特征组成:[Jitter_rel,Jitter_abs,Jitter_RAP,Jitter_PPQ,Shimmer_loc,Shimmer_db,Shimmer_APQ3,Shimmer_APQ5,Shimmer_APQ11,HNR05,HNR15,HNR25],分别表示相对跳动、绝对跳动、相对幅度震动、周期扰动熵、局部振幅微扰、绝对闪烁特征、三点幅度扰动熵、五点幅度扰动熵、十一点幅度扰动熵、谐波噪声比05、谐波噪声比15、谐波噪声比25。以上特征主要包括Jitter类、Shimmer类及谐波信噪比[16-18]。
Jitter用来表征语音信号偏离其周期的程度大小,一般用于衡量语音信号中相邻两个基频差值的平均值与基频平均值的比值大小,如式(1)所示:
其中N为基频数,F0,i为第i个基频。
Shimmer衡量的是连续两个振幅的偏差,如式(2)所示:
其中N表示振幅序列的长度,Ai表示振幅序列中第i个值。
信噪比用来衡量一个信号质量的优劣程度,常用谐波与噪声的比值HNR来衡量由于声带器官发生病理性改变而产生的噪声[19]。研究表明,帕金森病人的HNR相比于健康人群呈现出较小的数值。
通过对生成的一维向量数据集进行分析,发现PD患者与健康人群在Jitter类、Shimmer类及HNR上有明显的区别,如图2所示。

注:a)Jitter值;b)Shimmer值;c)HNR值。
PD患者的发音有震颤,在Jitter和Shimmer和HNR中明显可见。Jitter表示频率扰动,PD患者的抖动值高于健康人群,在Shimmer中也有相同的表现。此外,健康人群的信噪比明显高于PD患者。
为避免训练过程出现过拟合现象,对原始数据集进行数据清洗和数据增强后得到3 000条数据,其中2 400条作为训练集,300条作为验证集,300条作为测试集,各占样本容量的80%、10%、10%。
2 分类方法
2.1 决策树
决策树的构建是基于已知的发生概率。这涵盖了事件发生的各种情况,概率值应选择大于0,以便更好地判断项目的具体可行性,因为其形状与树非常相似,所以它被称为决策树,分类原理如图3所示。虽然决策树模型和卷积神经网络模型在结构和概念上有所不同,但都可以作为预测模型来调用。

图3 决策树分类原理图
采用的sklearn模块中的sklearn.tree.DecisionTreeClassifier函数,其具有一个称为tree_的属性,该属性允许访问低级属性,例如node_count,节点总数和max_depth树的最大深度。它还存储整个二进制树结构,表示为多个并行数组。每个数组的第i个元素保存有关node的信息i。节点0是树的根。一些数组仅适用于叶节点或拆分节点,在这种情况下,其他类型的节点的值是任意的。
根节点是原始的决策属性。叶子节点表示如果样本在属性集上取值相同,则根据样本中数量最多的类别返回对应类别的叶子节点。内部节点是根据属性的映射进行决策。选择最优的划分属性是决策树的关建,采用ID3这一决策树生成的经典算法,每次分裂时候就是计算信息增益,然后选择信息增益最大的作为标准进行结点分裂。算法过程为:
1)定义全局变量,当前决策分裂之前的样本集合D。
2)样本类别为K。
3)根据标签(本文数据集的类别为2种,即PD和HC)D中k类样本所占比率p(K)(k=1,2,3…)。
4)根据标签(本文数据集的类别为2种,即PD和HC)D中k类样本数D(K)。
5)属性集a(a1,a2,…,aV)根据属性集映射样本分类,该分支结点根据属性a决策分裂所得样本子集D。
2.2 ResNet
残差神经网络(ResNet)指的是在传统卷积神经网络中加入残差学习的思想,解决了深层网络中梯度弥散和精度下降(训练集)的问题,使网络能够越来越深,既保证了精度,又控制了速度。它是何凯明在2015年提出的一种网络结构,获得了ILSVRC-2015分类比赛的第一名。残差网络主要是包含残差块,残差块一共包含两种映射,分别为identity mapping和residual mapping,identity mapping指的是输出本身的值,用于加深网络。residual mapping指的是卷积计算部分,用于改变网络维度。随着神经网络深度的加深,就会导致反向传播过程中梯度消失问题,前面层的参数得不到有效的更新,就会导致梯度弥散问题,引入残差网络可以有效解决神经网络加深准确率下降问题。本文使用的是Resnet50神经网络模型,其层数总共是50层,其框架图如图4所示。
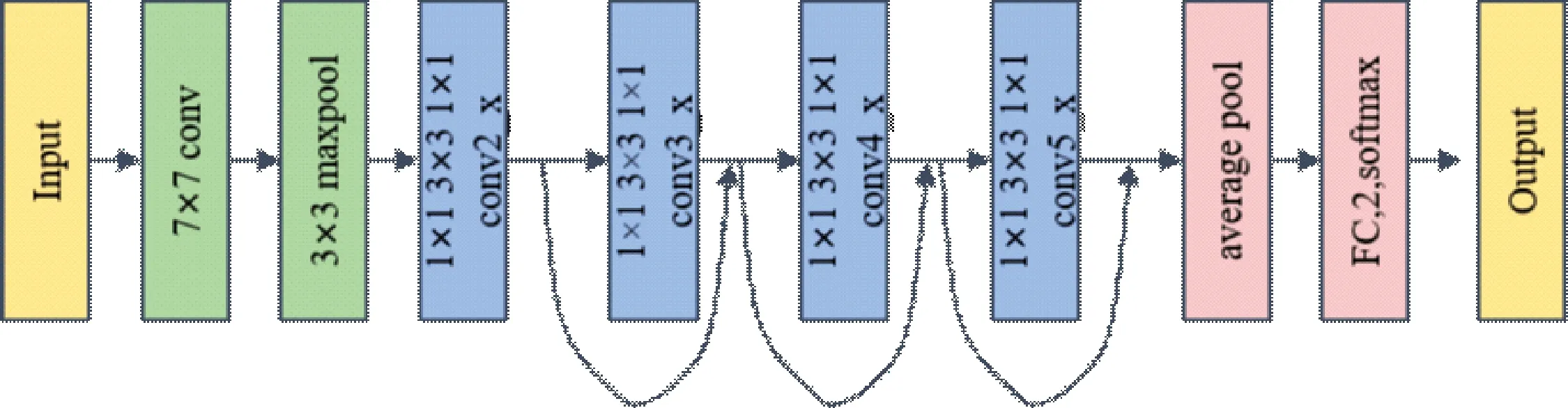
图4 ResNet50网络模型
Resnet50总层数为50层,由卷积层,池化层,全连接层组成。其卷积层的个数为conv1:7×7×64,3个conv2_x:1×1×64,3×3×64,1×1×256,4个conv3_x:1×1×128,3×3×128,1×1×512,6个conv4_x:1×1×256,3×3×256,1×1×1 024,3个conv5_x:1×1×512,3×3×512,1×1×2 048。池化层的大小为maxpooling:3×3。全连接层输出是二分类为FC:2。本实验输入是具有73行12个属性的数据,中间经过Resnet50的卷积层和池化层提取特征值,最后连接全连接层,输出是一个二分类PD(患者)和HC(正常)。
3 实 验
本研究的实验基于Tensorflow2.0.0平台搭建,实验软硬件环境为Mac OS操作系统、Intel Core i5 1.6G CPU、8G内存。在不考虑训练时间因素前提下,开展表1所列2组实验。实验源代码见链接:https://colab.research.google.com/drive/1gFiGB7NXWZij5YQ_ZOfsMa4X-XupMSDX。

表1 实验分组信息
在训练过程中多次测试发现ResNet50进行到1 000次左右迭代后准确率及损失值基本趋于平稳,为了对比,实验一、实验二均分析了完整的1 000次迭代过程。
图5至6所示为两组组实验过程中的损失值及准确率变化曲线。
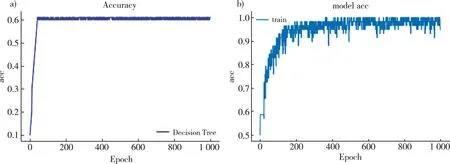
注:a)Decision Tree;b)ResNet50。
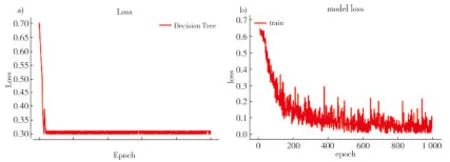
注:a)Decision Tree;b)ResNet50。
4 结果和评价
4.1 准确率和损失值
由于采用有监督学习方式,实验过程根据数据集和硬件配置情况合理调整模型参数,以平衡训练时间过长和训练精度下降。根据图5和图6可以发现,经过1 000次迭代分类模型取得较好的拟合效果,同时两种分类模型在准确率和损失值表现上也存在较大的差异,具体标下如表2所示。
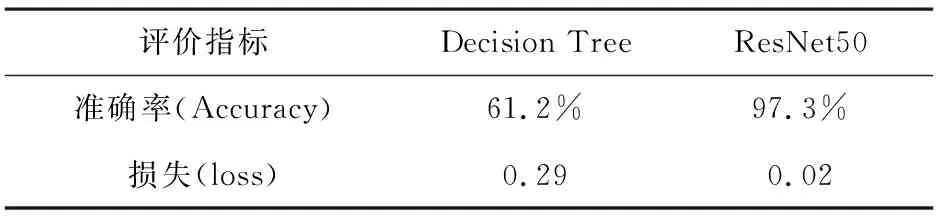
表2 不同分类方法的准确率和损失值
4.2 混淆矩阵
混淆矩在可以比较分类方法的性能,混淆矩在模板如表3所示。真阳性(TP)代表分类正确的PD样本,真阴性(TN)代表分类正确的健康样本,假阴性(FN)代表将PD样本分类成健康样本,假阳性(FP)代表将健康样本分类成PD样本。

表3 混淆矩阵
实验在两种分类模型上分别进行15次测试,得到如图7所示的混淆矩阵。
注:a)Decision Tree;b)ResNet50。
4.3 ROC/AUC
ROC是一个用于度量分类中的非均衡性的工具,ROC曲线及AUC常被用来评价一个二值分类器的优劣。横坐标为假阳率FPR(False positive rate)表示所有负例中有多少被预测为正例,纵坐标为真阳率TPR(True positive rate)表示有多少真正的正例被预测出来。具体计算方法如公式(3)、(4)所示:
AUC(Area Under Curve)被定义为ROC曲线下的面积,因为ROC曲线一般都处于y=x这条直线的上方,所以取值范围在0.5和1之间,使用AUC作为评价指标是因为ROC曲线在很多时候并不能清晰地说明哪个分类器的效果更好,而AUC作为一个数值,其值越大代表分类器效果更好。如图8所示是两种分类模型的ROC/AUC曲线对比图。
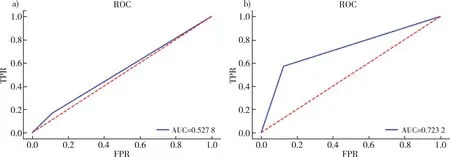
注:a)Decision Tree;b)ResNet50。
通过以上三个维度的比较,发现研究中Resnet50较决策树在PD患者识别中有明显的优势。分析原因,对于研究对象是音频、视频、图像、文本之类的数据集,其具有大量的特征,每个特征和最终结果可能有关系但不是那么明显,如同用一个像素去判断手写数字几乎不可能。基于传统数据挖掘方法的决策树更擅长处理具有较少特征且特征与结果之间关系更明显的任务,而基于深度神经网络的ResNet50可以从大量特征中提取更高级的特征,且数据集越大越可以减弱过拟合。
5 结束语
PD患者与健康人相比存在很多生理方面的差异,本文从声学特征差异角度结合人工智能相关的分类方法,试图从技术层面为诊断PD患者提供新的思路和方法。实验结果表明残差神经网络较传统的决策树分类方法在准确率、特异性等方面有较突出的优势,为临床应用提供重要的实验参考。同时,由于实验数据采集自英国,被试者在发音方面与中国人存在较为明显的生理差异,这给实验成果在国内的推广应用带来较大的不确定性,因此下一步我们将努力构建基于中国人语音特征的PD患者数据集。
