基于软件需求规范的项目级复用研究
2022-03-16巴元秀赵逢禹
巴元秀,赵逢禹,刘 亚
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 PR-REQ项目复用方法
软件项目复用对减少开发工作量和成本、提高软件项目质量具有重要影响。在软件开发中,通过复用技术可以充分利用已有的开发成果,从而提高软件开发的效率、降低开发成本。同时,通过复用高质量的已有的开发产品,避免了重新开发过程中可能引入的错误,从而提高软件的质量。
Gharehyazie等人利用代码克隆检测工具Deckard研究项目内部以及跨项目的克隆,研究发现代码克隆非常普遍,从同一项目的几行代码到跨项目的代码片段之间都检测到不同程度的相似。Zhang Yun等人研究GitHub上的项目复用,发现含有相似的README文件的软件项目存在相似性。由此可以看出不论是代码级别还是项目级别,都存在着大量的复用。
目前最常用的软件复用技术主要是代码的复用。软件开发人员在进行项目开发的过程中发现,开发同类型的软件应用时会实现相似或相同的功能,相应的代码实现也是相似的。代码克隆技术便是代码复用方法中最原始且最常用的技术,一般表示为开发人员通过代码搜索技术从开源项目中找到自己所需要的源代码并复制到自己的项目中。文献[5]提出一种代码级别的复用技术,该技术利用提取工具将源代码的内容生成代码摘要,将用户输入的文本与代码摘要进行搜索查询,最后获取相似的代码进行复用。
近年来,随着开源生态的完善,人们更多地关注项目级别的复用研究。Xu等人研究跨项目复用,利用历史开源软件项目的描述文档和源代码,将其与待开发项目的功能进行相似性度量并推荐相似的软件项目。Thung等人利用相似的项目会共享相似的第三方库这一原理,提取开源项目使用的库,利用对库的相似性匹配相似的项目实现项目级别的复用。Nguyen等人提出生态系统概念,由历史开源项目、库以及项目之间的相互依赖关系组成,将开发人员对待开发项目的创建、修改等行为与生态系统分别构建成图,利用图的相似性算法选取相似的项目进行复用。
文献[6~8]在项目级复用研究中仍有不足之处。文献[6]主要研究了项目开发过程中跨项目的代码复用技术,是编码阶段的复用方法。文献[7]是从项目使用的库方面考虑复用,文献[8]是根据历史开源项目、库以及待开发项目三者之间的依赖关系考虑复用。以上的研究都还没有实现从待开发项目的需求分析考虑项目级别的复用。
文献[9]提出一种基于需求规范文档进行代码的功能特征复用的方法,该方法首先从需求规范文档中提取出功能特征关键词,然后将提取出的关键词与代码库中代码的功能特征关键词进行相似性匹配,最后根据相似的功能特征进行代码复用。文献[9]从需求规范文档的功能特征出发,搜索可复用的代码,仍然属于项目局部功能的代码复用。
在软件工程实践中,当开发人员获取项目的软件需求后,通常需要根据需求文档中的问题领域、用例描述、数据模型E-R图搜索开源项目库中的相似软件项目。如果能从需求文档的问题领域、用例描述以及数据模型方面找到相似的历史项目进行复用,可以大大节省项目设计与实施时间。而用自动化的方法找到相似的历史项目,是一件复杂的工作。因此本文提出了一种基于软件需求规范的的项目级复用方法PR-REQ(Project Reuse based on Requirements Specification)。该方法首先分析历史开源项目,构建算法提取历史项目核心信息,包括项目的领域信息、代码的功能操作序列以及数据模型信息。然后针对待开发软件项目的需求文档,研究提取问题领域、用例的功能操作序列以及数据模型等信息的方法。最后分别构建领域相似性度量、功能操作序列相似性度量以及数据模型相似性度量算法,加权计算得到最终的相似性度量值并按由大到小排列。文中从GitHub上下载了8类Java web项目构造实验,对本文提出的方法进行实证。
2 PR-REQ项目复用方法
项目级别的复用是对历史项目在软件架构、功能实现、数据模型、设计与编码等多方面的复用,也是软件复用中最高级别的复用。为了实现项目级别的复用,图1给出了该方法的操作流程图,分为3步,它们分别是历史开源项目信息的提取、待开发项目的需求文档分析以及项目相似性度量计算。
(1)历史开源项目信息的提取。
为了复用历史项目,需要对开源历史项目进行数据分析与特征提取。在每个项目中,大部分都有源代码和描述文档。源代码包含了项目的功能信息和数据模型信息。描述文档通常给出了项目的功能介绍、用法以及如何安装或部署。
a.描述文档领域信息的提取。
分析描述文档中的项目功能介绍,利用自然语言的方法处理文本主题分析提取项目的领域信息。
b.代码中功能信息的提取。
采用静态代码分析技术解析历史项目的代码,提取项目的各功能操作,构建项目的功能操作序列。
c.数据模型信息的提取。
从数据库配置文件或源代码中提取所使用的数据库的表名、列名等信息,构建数据模型。
(2)待开发项目的需求文档分析。
a.领域信息的提取。
在软件复用时,属于同一个领域的项目被复用的可能性更高。这里通过自然语言处理方法,对需求文档进行分析,提取待开发项目的领域信息。
b.功能操作信息的提取。
为了从项目的功能方面进行相似性度量分析,需提取需求文档中的用例,根据用例中的活动和参与活动的对象,构建待开发项目各功能的功能操作序列。
c.数据模型信息的提取。
在数据模型E-R图中提取与待开发项目有关的实体信息。
(3)项目相似性度量。
a.领域相似性度量。
为了能够根据需求文档中的领域信息在历史开源项目中寻找领域方面相似的项目,本文从开源历史项目的描述文档和待开发项目的需求文档中各提取若干个主题,利用主题的相似性计算领域的相似度。a
=(a
,a
,…,a
)定义为从待开发项目的需求文档描述中提取的n
维主题向量,b
=(b
,b
,…,b
)定义为从开源历史项目的描述文档中提取的n
维主题向量,领域相似度计算如公式(1)所示。
(1)
b.功能操作相似性度量。
为了从功能操作方面比较待开发项目的需求文档和历史开源项目之间的相似性,本文构建了功能操作序列的相似性度量方法。待开发项目的需求文档中的功能操作序列定义为W
={W
,W
,…,W
},其中W
(i
=1,2,…,m
)代表一组功能操作序列的集合。历史开源项目中提取的功能操作序列定义为T
={T
,T
,…,T
},其中T
(j
=1,2,…,n
)代表一组功能操作序列的集合。序列W
中序列的个数记为m
,序列T
中序列的个数记为n
,采用余弦相似度计算W
中任一个序列W
与T
中任一个序列T
的相似度值记为S
(W
,T
),最后根据公式(2)计算最终的相似度值。S
(W
,T
)=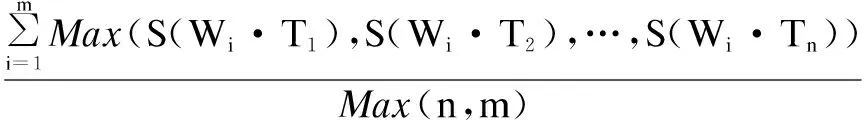
(2)
c.数据模型相似性度量。
为了更准确地进行项目复用,本文对数据模型也进行分析,构建数据模型相似性分析。历史开源项目中的数据模型定义为A
={A
,A
,…,A
},其中A
(j
=1,2,…,n
)代表由表名、列名信息组成的一组数据模型集合,集合A
中的个数记为n
。待开发项目的需求文档中提取出的数据模型定义为C
={C
,C
,…,C
},其中C
(i
=1,2,…,m
)代表由需求文档中表名、列名信息组成的一组数据模型集合,集合C
中的个数记为m
。采用余弦相似度计算集合A
中任一组数据模型A
与集合C
中任一组数据模型C
的相似度值记为S
(C
,A
),最后根据公式(3)计算集合C
与A
的相似度值。S
(C
,A
)=
(3)
d.计算候选项目的最终相似得分。
在分别计算上述三种相似度值后,最后采用公式(4)进行加权计算得到最终的相似性度量分值。

(4)
其中,α
代表领域信息的权重,β
代表功能操作序列的权重,γ
代表数据模型的权重。
图1 PR-REQ方法流程图
3 PR-REQ方法的关键技术
PR-REQ项目复用方法中的关键技术主要是从历史开源项目与待开发项目的需求文档中提取相关特征,然后计算这些特征的相似度并基于特征相似性推荐可复用的历史项目。其中的关键技术主要有历史开源项目信息的提取和待开发项目需求文档信息的提取。
3.1 历史开源项目信息提取
大多数开源项目中都有描述文档和源代码。为了分析历史开源项目,本文对项目中包含的描述文档和源代码进行数据分析和特征提取。
(1)领域信息的提取
描述文档是描述软件项目信息的文档,它一般包含软件的基本功能、简要的使用说明、代码目录结构说明等信息。文中使用斯坦福主题模型工具提供的基于概率模型的LDA主题模型算法对描述文档中的项目功能介绍部分进行领域信息的主题提取。
在对领域描述文本进行数据提取等相关工作之前,一般要进行文本的预处理。文本的预处理也就是将需要进行分析的文本通过一定的方式转换成方便处理的结构化的数据形式, 可以提高文本处理的准确性。需求规范文档大多由中文文本构成,因此文中主要使用的预处理方式是中文文本的预处理。结合对于中文文本的特征进行分析,在研究的过程中,文本预处理方式主要包括语料库清理、分词、词性标注和停止词过滤。
①语料库清理。
语料库的清理主要是清理和删除一些非法语言文字等不良数据。
②分词、词性标注。
词是构成语句的基本单元,分析语句前需要先分词,将文本中词切分出来作为特征值,是自然语言处理比较重要的一步。中文分词就是指将句子中汉字序列切分成词集合。相对于英文而言,中文分词要复杂得多。
③停止词过滤。
在普通文本中含有标点符号、介词、语气词等,这些词对理解文本没有实际意义,应从分词结果中去除,这些词称之为停用词。去停用词可以省存储空间,减少停用词对理解语句造成的噪音,降低文本维度,可以提高处理文本的效率和准确率。
文献[13]认为对一篇科技文献,提取主题数量在5到6个时分析效果最好。借鉴该研究的结论,对软件需求与历史项目文档的主题数量为5。
(2)代码中功能操作序列的提取。
如何在软件项目代码中提取主要功能的操作序列是本文的关键算法。对于不同的软件项目,由于其软件架构不同,其功能的操作序列提取方法也有差异,但都可以通过对配置文件与源代码的静态分析获得。文中以Java web项目为研究对象,给出特征提取算法。Java web项目的功能操作信息主要体现在项目的页面文件上,因此文中针对Java web项目的页面文件提取功能操作序列。为了从页面文件中提取项目的功能操作,需要利用JSOUP解析器从应用程序的入口页面开始对其进行数据解析,提取对应页面的功能操作,构建功能操作序列。在提取功能操作时,在web页面中,操作功能主要分为静态和动态两类。 就是一个静态页面的跳转,可以从中提取出“注册”功能; 是一个动态页面的跳转,在点击“提交订单”的同时会调用saveOrder方法,从后台数据库中调取数据,可以从中提取出“提交订单”功能。算法1给出了代码功能操作提取算法。
算法1:代码功能操作提取算法。
输入:Java web项目的页面文件集合P
={p
,p
,…,p
},项目的配置文件config。输出:项目的功能操作序列T
={T
,T
,…,T
},其中T
(i
=1,2,…,m
)为一组功能操作序列的集合处理:
1.初始化队列Queue,G
={V
,E
},V
=Φ,E
=Φ;2.从config中找到项目的入口页面文件,不失一般性假设为p
;3.将p
作为访问的第一个页面文件入队列Queue;4.while(Queue非空)
{
CurrentPage=deQueue(Queue);//队头元素出队;
V
=V
∪{CurrentPage};利用JSOUP解析器提取CurrentPage页面中的功能操作信息f
和与之对应的跳转页面p
,p
∈P
;构造G
的有向边,加入到集合E
中,记为E
=E
∪{<(CurrentPage,p
),f
>};if (p
not inV
)p
入队列Queue;}
5.在图G
中,从节点p
开始按照深度优先算法遍历路径上的功能操作f
构造功能操作序列T
;6.输出功能操作序列T
,结束算法。(3)数据模型的提取
算法以Java web项目的代码文档集合作为输入,采用一种轻量级的查询提取工具SQL提取器,该工具使用AST过程内的字符串解析,能够对代码中的数据模型进行静态分析,提取出带有元信息的SQL语句,通过对SQL语句进行分析,输出含有数据库的表名、列名信息的集合。文中给出了利用SQL提取器进行数据模型提取的过程,见算法2。
算法2:数据模型的提取。
输入:项目的代码文档集合B
={b
,b
,…,b
}。输出:表名、列名信息组成的数据模型集合A
={处理:
1.初始化集合A
;2.将b
作为访问的第一个代码文档;3.for each (CurrentFile inB
){
利用SQL提取器提取出CurrentFile中SQL语句的表名和Insert语句中的列名,记为
A
=A
∪{3.2 待开发项目需求文档信息提取
对于待开发项目,需要在需求文档中提取领域信息、功能操作信息、数据模型。其中领域信息的提取方法与历史开源项目中提取领域信息的方法一致。数据模型的提取是对需求文档的数据模型E-R图中的实体关系进行分析。功能信息的提取是对需求文档中的用例进行特征提取,提取用例的活动,构建待开发项目的功能操作序列。限于篇幅,文中主要介绍对需求文档中的功能信息进行提取的方法。
用例由用例名称、描述、角色、编号、前置条件以及主事件流等组成,文中给出了用例功能操作序列的提取算法,该算法使用需求文档中的用例集合R
={r
,r
,…,r
}作为输入,提取出与系统进行交互的用例活动,构建功能操作序列W
={W
,W
,…,W
}作为输出,见算法3。算法3:用例功能特征的操作序列的提取。
输入:需求文档中的用例集合R
={r
,r
,…,r
}。输出:功能操作序列W
={W
,W
,…,W
},其中W
(i
=1,2,…,m
)为一组功能操作序列的集合。处理:
1.初始化集合W
;2.将r
作为访问的第一个用例;3.for each (CurrentUse inR
){
根据CurrentUse中的事件流的交互过程,提取出参与用例活动的操作和对应的活动对象,构建功能操作序列集合记为W
;W
=W
∪W
;}
4.输出操作序列W
,结束算法。4 实验研究
在软件项目级别的复用研究领域中,目前尚没有找到包含待开发项目的需求文档、历史项目的源代码数据集,以及它们之间相似度的度量参考标准。因此为了验证文中提出的PR-REQ方法的准确性,文中构造了一个实验,采用人工方法和PR-REQ方法分别对需求文档进行分析,将PR-REQ方法找出的Top N的相似软件项目与人工找出的Top N的相似软件项目进行一致性和包含性比较。
4.1 数据集
文中从GitHub上下载了958个Java Web项目,这些项目包含学校管理类、企业类、竞赛类、网购类、游戏类等八类项目,在这些项目中同时具有需求描述和项目代码的项目数共68个。开源软件项目数及其类别见表1。
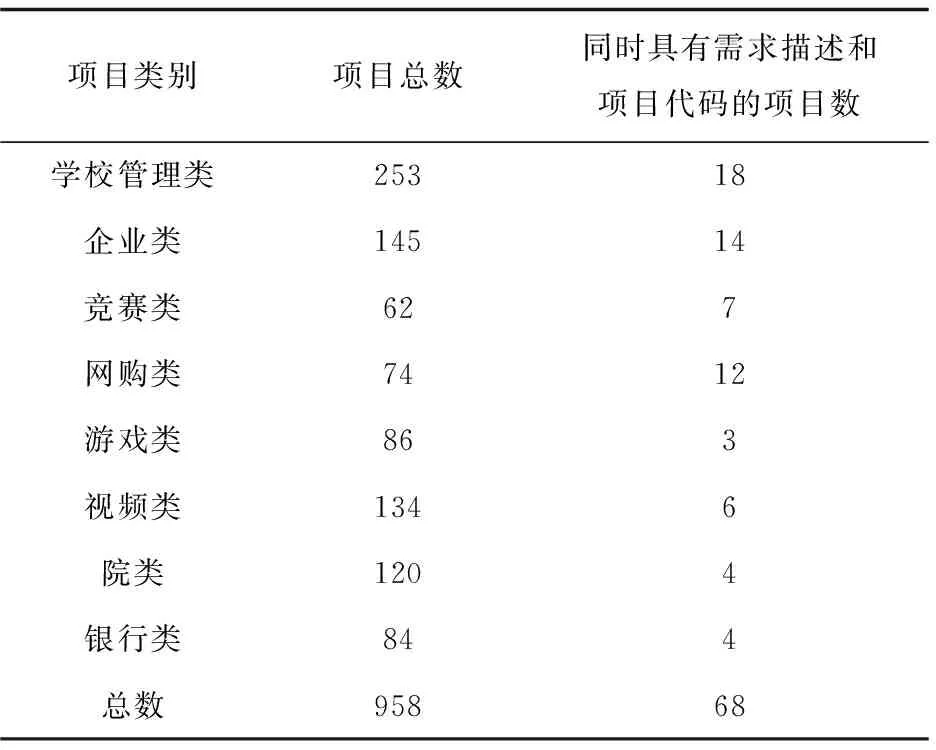
表1 开源软件项目数及其类别
4.2 实验步骤
基于PR-REQ方法开发了一个项目复用推荐程序,该推荐程序首先从数据库中读取历史开源项目和待开发项目的需求文档。然后分别提取开源项目和需求文档中的领域信息、功能操作序列以及数据模型信息并存储于数据库中。最后通过调用相似度量程序对需求文档和历史开源项目进行相似度量,利用相似度得分机制将候选项目按得分由大到小排列,并将候选项目的结果存储到数据库中。
4.3 验证PR-REQ方法的准确性
为了验证该方法的准确性,文中从百度文库中下载了5个学校管理类需求文档和5个企业类需求文档,对其从①到⑩进行编号。为了便于实验中对相似项目进行排序,将表1中同时具有需求描述和项目代码的68个项目进行从1到68编号。其次,分别采用人工方法和PR-REQ方法对这10个需求文档进行分析,从68个项目中找出相似的软件项目。人工方法是由作者共同对每个需求文档进行分析,从领域、功能操作以及数据模型三个方面进行数据分析,找出与之相似程度最高的3个项目,对其进行相似度排序并记录3个项目对应的编号。PR-REQ方法则是利用开发好的项目复用推荐程序,对这10个需求文档进行特征提取与分析,同样找出与之相似程度最高的3个项目,对其进行相似度排序并记录3个项目对应的编号。最后,分别对人工选取的项目和PR-REQ方法选取的项目进行一致率和包含率分析,验证文中提出的PR-REQ方法的准确性。
定义1:一致率:PR-REQ系统找出的项目与人工找出的项目一致的比率。
定义2:包含率:PR-REQ系统找出的项目包含在人工找出的项目中的比率。
表2是针对每个需求文档,利用人工方法和PR-REQ方法找出的相似软件项目对应的编号。然后对表2中的编号进行一致率和包含率分析,分析结果见表3。
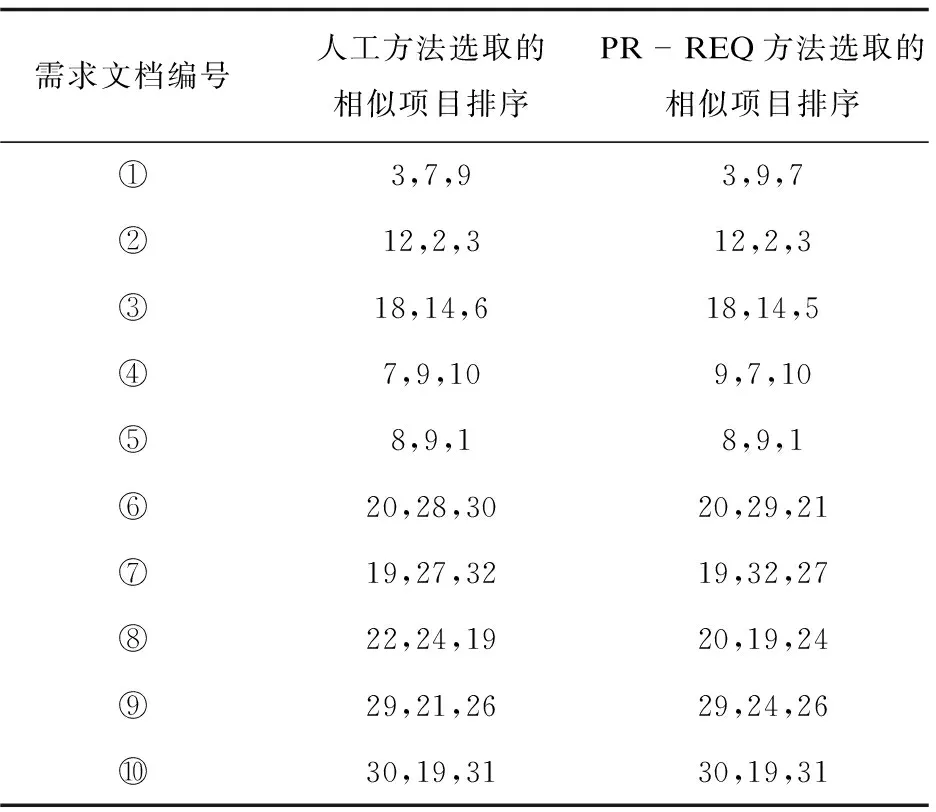
表2 人工方法和PR-REQ方法选取的相似项目的编号
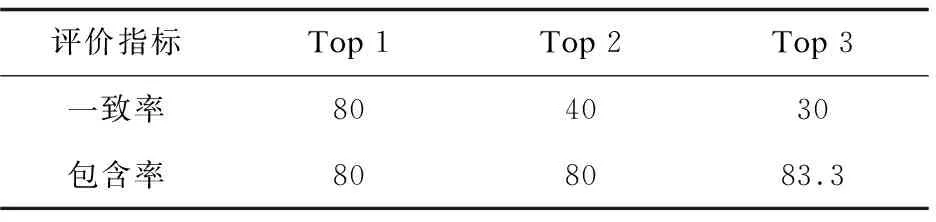
表3 一致率和包含率分析 %
由表3可以看出,针对这10个需求文档,人工分析与PR-REQ分析推荐的第一个历史项目有80%相同,在推荐一个最相似的项目时,一致率与包含率意义相同。Top 2一致率为40%,Top 3一致率为30%,可以看出,随着推荐的项目越多,一致率会有所下降,这一结果也符合预期;而对于包含率,Top 1、Top 2与Top 3都不低于80%,也就是说利用PR-REQ方法找出的1到3个相似项目与人工找出的1到3个相似项目虽然无法在相似程度上保持一致,但包含率在80%以上,这说明文中提出的PR-REQ方法具有较高的准确性,对于项目复用具有实用价值。
5 结束语
软件项目需求分析是开发人员开发一个新项目时的第一阶段,目前尚没有一种项目复用方法可以根据待开发项目的需求文档进行项目级复用。针对这一问题,文中提出了一种基于软件需求分析的项目级复用方法PR-REQ,该方法从项目的主题领域、功能操作信息以及数据模型三个方面对待开发项目的需求文档和开源历史项目进行特征提取和数据分析,最后构建相似性度量方法进行相似项目推荐。基于文中提出的方法,随机选取了企业类和学校管理类的需求文档各5个来构造实验验证其准确性。
实验结果表明,文中提出的基于需求分析的项目级复用方法在寻找相似的软件项目方面具有较高的准确性,该方法对于开发人员在项目开发的初期阶段具有重要作用。但是本实验只取了68个历史项目文件,针对两类共10个项目需求文档进行了分析,实验样本数量仍然偏少,为了证实该方法的实用性,还需下载更多的项目进行分析。另外对于非Java web项目,还需基于历史项目的代码进一步构建算法提取功能操作序列与项目的数据模型。
