融合BERT-WWM和注意力机制的茶叶知识图谱构建
2022-03-15刘永波高文波许钰莎
刘永波,黄 强,高文波,何 鹏,许钰莎
(1. 四川省农业科学院农业信息与农村经济研究所, 成都 610066; 2. 四川农业大学, 四川 雅安 625014)
【研究意义】知识图谱(Knowledge Graph)是一种结构化的语义知识库,常以“实体—关系—实体”的三元组形式来表示实体间的关系[1],它通过将某领域的多源异构知识结构化,解决该领域内数据缺失、信息碎片化、知识孤岛化等问题,目前已在科研、金融、互联网、人工智能等领域得到广泛使用[2]。随着人工智能、机器学习、大数据等学科的不断发展,知识图谱在领域知识管理方面取得较好的成绩,农业特定领域的知识图谱构建逐渐成为国内外科研人员研究的重点。【前人研究进展】陈亚东等[3]从苹果产业的知识来源、知识获取、知识融合和知识表达4个方面对我国苹果产业知识图谱架构进行设计,提出面向苹果产业数据关联的知识图谱构建思路。王丹丹[4]通过调研宁夏自治区水稻产业发展的需求,以知识表示为基础,利用模式匹配的方法构建了宁夏水稻知识图谱。许鑫等[5]利用Neo4j、NLP及图谱构建技术,构建了小麦品种知识图谱体系,解决了品种数据中知识重复率高、知识关联不明确等问题。【本研究切入点】知识图谱构建的研究在国内农业领域取得了一定进展,但依然存在图谱规模小,体系不完整,实体命名识别效果差,缺少自主演进手段等问题。茶叶是我国重要的经济作物,茶叶生产和销售过程中会面临种植、管理、加工等多个环节,每个环节都需要科学的技术指导[6]。但当前绝大多数的茶叶领域开源知识都以非结构化数据形式集中在百科全书或开放领域的百科网站,存在知识数据信息化程度低、聚合能力差、利用效率低、知识共建共享困难等问题[7]。【拟解决的关键问题】本研究以茶叶百科网站、百科全书等多源异构数据为基础,茶叶专家经验为指导,根据茶叶全产业链中文本实体所呈现的关系特征,提出一种基于BERT-WWM-BiLSTM-AttTea-CRF模型的茶叶知识图谱构建方法。该方法通过提取茶叶全产业链中的有效命名实体,构建了包含茶叶品种、茶叶病虫害、茶树生长环境、茶园适用技术4个类别的知识图谱。旨在利用茶叶全产业链知识图谱构建及自主演进技术建立供需关联规则,实现茶叶生产社会化服务的供需精准匹配,同时为农业经营主体关系可视化、农时指导问答系统、农业知识图谱的应用等研究提供参考。
1 材料与方法
1.1 试验材料
知识图谱根据数据源中数据格式的规范程度不同,可分为结构化、半结构化、非结构化3种数据类型[8]。结构化数据由规范的数据库制表构成,此类数据可通过D2R工具直接转换为三元组数据,但目前互联网尚未有开源的茶叶数据库可供提取,因此本研究的茶叶知识图谱数据源主要由非结构化数据构成。茶叶全产业链命名实体识别缺少公开的语料数据集,本研究采集的非结构化数据主要来自《中国茶叶大辞典》《茶树栽培学》《茶树栽培技术》等纸质书籍或电子书文件,对纸质书籍经过扫描形成PDF文件,采用OCR(Optical Character Recognition)文字识别技术将PDF文字转换文本数据,便于对数据进行管理和标注。采集的语料数据集包含茶叶品种262种,茶叶病害105种(包含32种病害和73种虫害),茶叶生长环境179篇(包含水分、温度、海拔、光照等),茶园适用技术232篇(包含耕作、施肥、修剪、采摘等),总计4大类778篇语料文本,约70万个中文字符。
1.2 茶叶本体构建
知识图谱的架构一般分为两个层次:模式层和数据层。模式层是知识图谱结构的核心,建立在数据层之上,通常采用本体管理来实现知识图谱的模式层[9-10]。本体构建是对整个茶叶知识图谱框架的构建,本体构建的目的在于理清茶叶知识图谱中实体与实体之间的关系,为本研究提出的模型智能提取茶叶文本语料数据提供依据。为构建茶叶全生产过程的本体模型,本研究借鉴茶叶专家经验将茶叶知识图谱定义为茶叶品种、茶叶病虫害、茶叶生长环境、茶园适用技术4个大类。每一大类再分为若干小类,例如将茶叶病虫害分为茶叶病害和茶叶虫害2个子类,将茶叶生长环境分为水分、温度、海拔、光照等子类。每一个子类包含一级图谱,再根据子类细分为多个小类,形成二级图谱,最后根据茶叶命名实体的特性来定义每类中的实体、关系、属性。茶叶知识图谱的部分本体构建关系如图1所示,其中茶叶品种、茶叶病虫害、茶叶生长环境、茶园适用技术4个大类的一级图谱通过不同颜色区分。
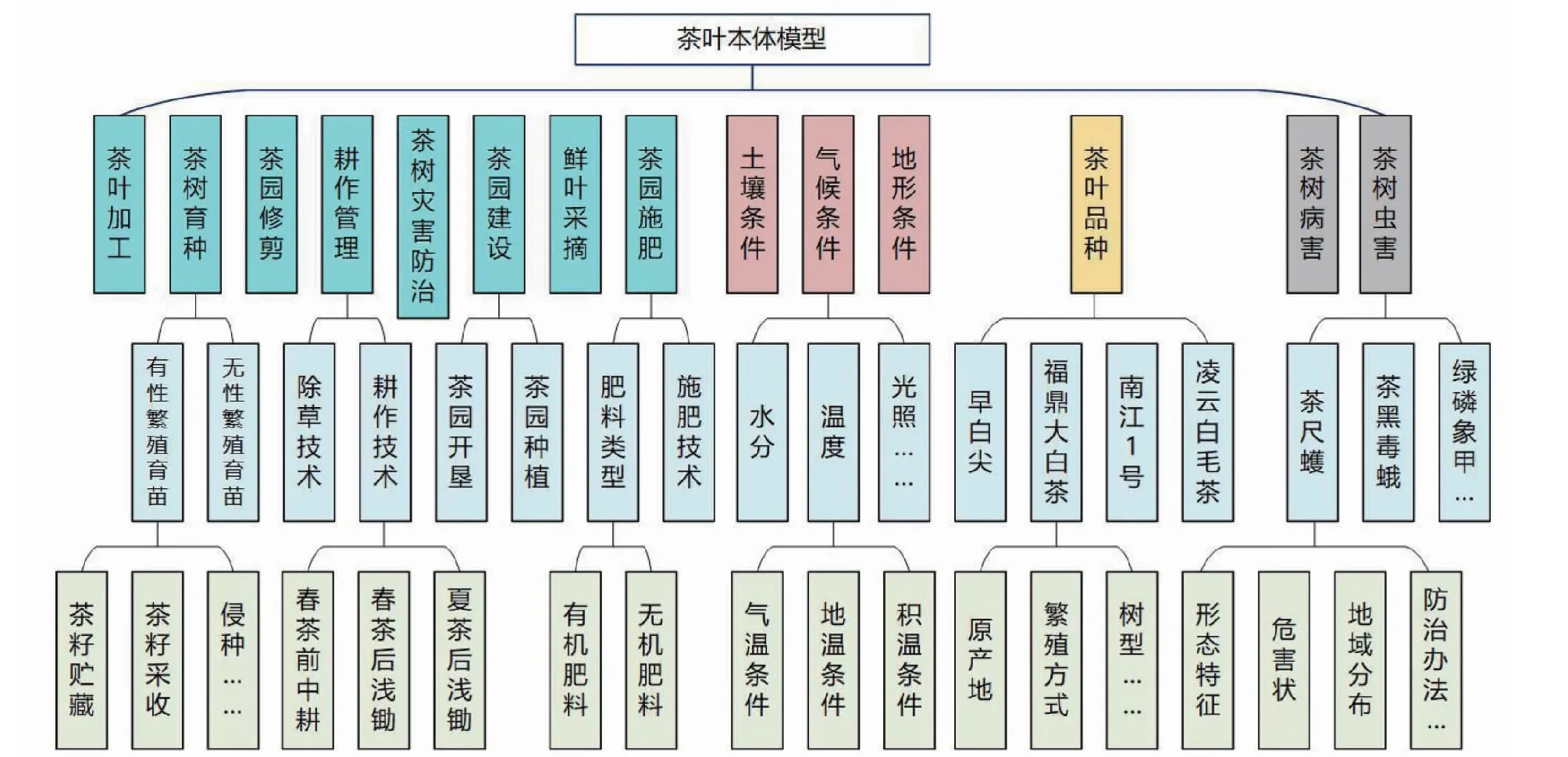
图1 本体构建关系Fig.1 Ontology building relationgship
1.3 文本数据标注
目前最常用的序列标注方法有三位标注(Beginning Inside Outside,BIO)、五位标注(Beginning Inside Outside End Singleton,BIOES)、反向三位标注(Inside Outside Beginning,IOB) 3种,其中IBO因为缺少B-tag作为实体标注的头部表示,丢失了部分标注信息,导致文本提取效果不佳,BIO很好地解决了这一问题,文本提取效果优于IBO[11]。而BIO相较于BIOES拥有更简易的标签,且提取效果相近,因此本研究选择BIO作为数据标注的主要方式。BIO方法将文本中元素标注为“B-X”“I-X”“O” 3种形式。其中“B-X”代表“Beginning”,表示被该标签标注的元素位于X类型实体的开头位置;“I-X”代表“Inside”,表示该元素处于X类型实体片段的中间位置(包含尾部位置);“O”代表“Outside”,表示该元素为非所需的实体类型[12]。以抽取书籍中茶叶品种的文字描述为例,茶叶品种的语料具有以下特征:关于茶叶品种的描述通常是一段独立文字围绕一个茶叶品种展开,因此该段文字中茶叶品种作为头部实体是固定的,重点在于对尾部实体和实体关系的提取。根据上述特征,以茶叶品种中的‘福鼎大白茶’为例,按图2所示标注文字序列。
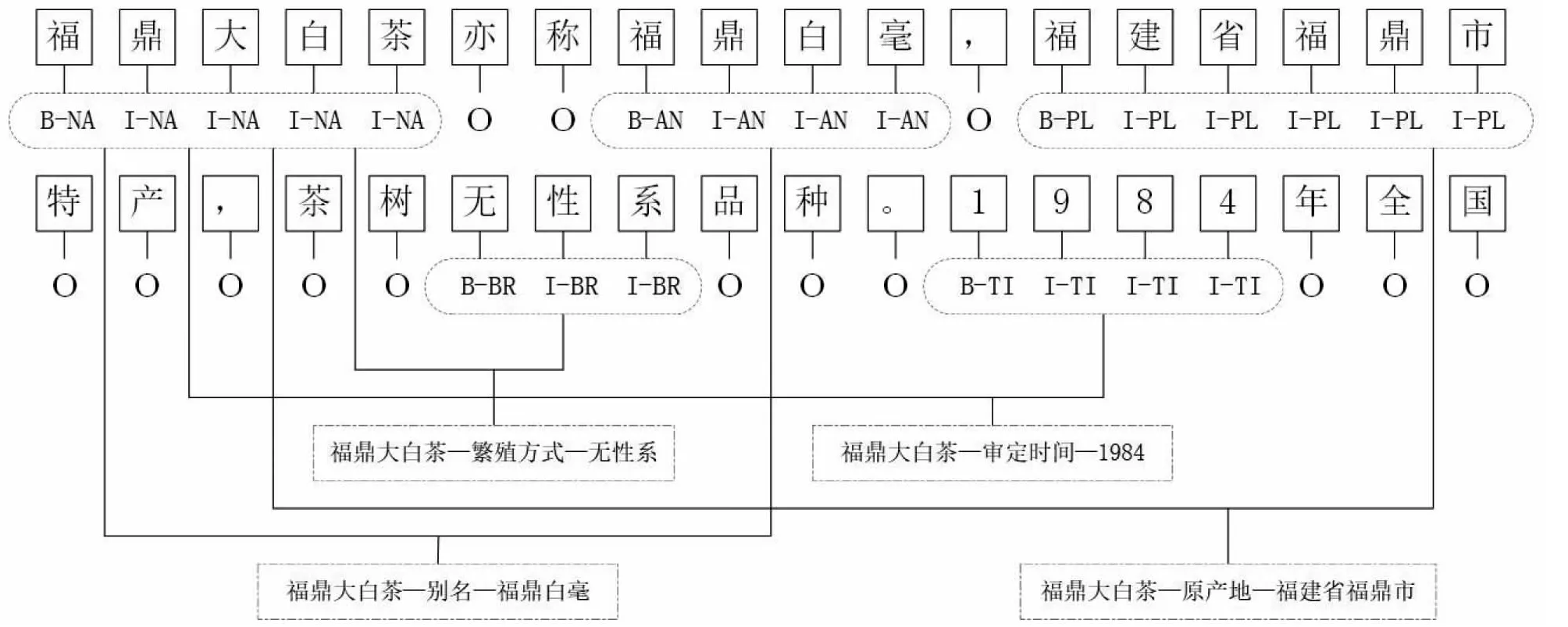
图2 文字序列标注Fig.2 Text sequence annotation
将‘福鼎大白茶’头部实体标注为NAME,其中实体第一个字为B-NA,其余文字标注为I-NA。由于‘福鼎白毫’是‘福鼎大白茶’的别名,故将‘福鼎白毫’标注为别名(Another Name,AN)。‘福鼎大白茶’与“福建省福鼎市”之间为原产地关系,则将‘福建省福鼎市”标注为原产地(PLACE,PL)。‘福鼎大白茶’与“无性系”之间为繁殖方式关系,则将“无性系”标注为繁殖方式(BREED,BR),其余文字序列标注以此类推。当模型匹配到主实体B-NA和关系B-AN的标签集合时即生成三元组(‘福鼎大白茶’,别名,‘福鼎白毫’);匹配到NA和BR的标签集合时,即生成三元组(福鼎大白茶,繁殖方式,无性系)。当模型检测到下一个茶叶品种的实体标签出现时,则表示上一个品种实体的三元组标签全部抽取完成。
1.4 试验模型设计
1.4.1 模型总体架构设计 BERT-BiLSTM-CRF的模型组合方式是当前命名实体识别领域的代表性模型,其优良的性能已在各大开源文本数据集测试中得到验证。但由于模型未针对农业体系命名实体做针对性改进,而茶叶作为农业体系中一大分支体系,其领域涵盖大量生僻词汇和专业性描述语句,如何提升原有模型对茶叶语料文本的识别效率,是当前茶叶知识领域有待解决的问题。针对上述问题,本研究拟采用基于全词掩码的BERT-WWM(Whole Word Masking)层预训练模型替换原有模型中的单字随机掩码BERT层,解决茶叶领域生僻词汇提取不完整的问题,并根据茶叶领域语料数据的全局文本特征,设计可实现茶叶关键实体权重分配的Attention_Tea注意力机制层,以提高文本提取的准确率。
本研究提出的融合全词掩码和注意力机制的BERT-WWM-BiLSTM-AttTea-CRF模型结构如图3所示,它由全词掩码的BERT-WWM层、BiLSTM层、融合注意力机制Attention_Tea层和CRF层组成。该模型的主要步骤为:第1步,将输入的文本经过基于全词掩码BERT-WWM层预训练,提取文本中与茶叶领域知识相关的语义特征;第2步,文本经上游处理后输入到下游BiLSTM层,结合上下文进行双向编码处理,并输出特征值;第3步,利用Attention_Tea层注意力机制分配茶叶领域实体提取的权重,降低无效词汇的权重;第4步,以CRF层对分配权重后提取的预测值进行解码,得到1个预测标注序列,通过对序列中的各个实体进行提取分类, 从而完成中文实体识别的整个流程。
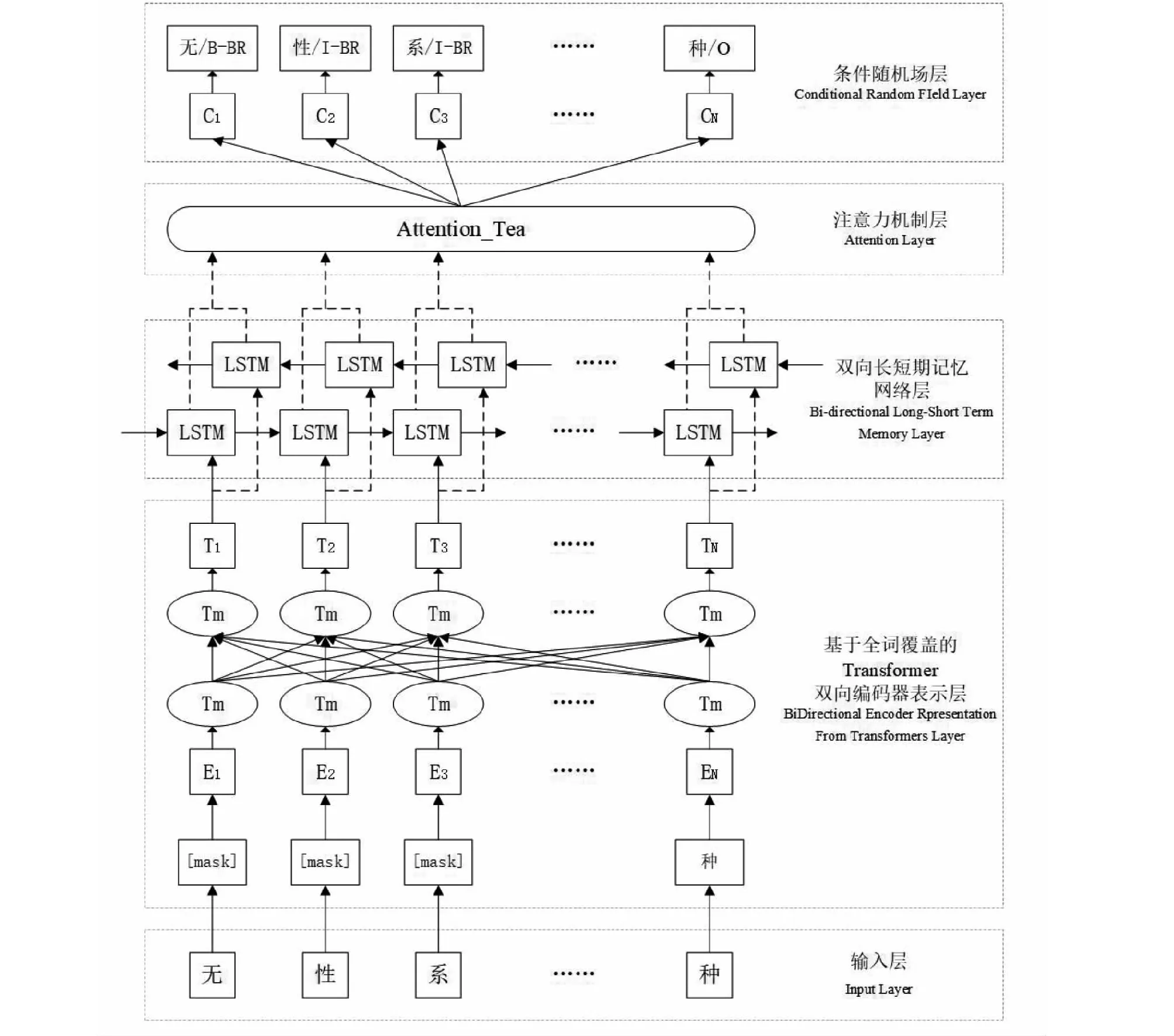
图3 BERT-WWM-BiLSTM-AttTea-CRF模型框架Fig.3 BERT-WWM-BiLSTM-AttTea-CRF model framework
1.4.2 基于全词掩码的BERT-WWM层 对于实体识别的上游任务语言预处理方面, 当前常用的语义表示学习模型(如Word2Vec[13]、Glove[14]、ELMO等)无法很好的表征汉语语言环境中的字词多义性。因此本研究选择基于Transformers的双向编码器表示层语言模型(Bidirectional Encoder Representations from Transformers,BERT)作为图谱构建的语言预处理模型, 以此来获取高质量的词向量,利于下游任务进行实体提取和分类。BERT语言模型是Google AI研究院在2018年提出的一种预训练模型,在针对英文的词向量提取中表现突出。中文领域的语义理解不同于英文,两者最大区别在于英文单词存在空格,预处理模型对英文的分词更容易,而中文语句中不存在天然的分隔符,每个词由多个单字组成[15]。若直接使用BERT原有模型对茶叶领域的语料进行分词,会把一个完整的名词拆分为若干个单字,例如茶叶品种中的“槠叶齐”一词,在处理时会被拆分为“槠”“叶”“齐”3个字,在BERT模型预训练过程中,这些单字会被随机[mask]替换,这样的处理方式显然无法很好地提取茶叶文本数据中的有效语义信息。针对茶叶语料数据的特征,本研究采用基于全词掩码的BERT-WWM预训练模型,当茶叶领域词组中的某个字在训练过程中被[mask]时,同属该词组的其他字也会被同时[mask]。茶叶领域全词掩码生成样例如表1所示。

表1 全词掩码生成样例
基于全词掩码的BERT-WWM词向量预训练模型,由Embedding层和Transformer层组成。其预训练过程主要包含以下步骤:第1步,定义模型的输入句子为e=(e1,e2,….,en),其中ei表示输入句子的第i个字符,n表示句子长度。第2步,将Embedding层中的输入句子以词嵌入向量(Token Embeddings)、分割向量(Segment Embeddings)和位置向量(Position Embeddings)三者求和的方式转换为输入序列T=(t1,t2,….,tn)。其中,词向量通过查询字向量表得到,分割向量用来表示该词属于的句子,位置向量表示该词的位置信息。第3步,将序列T=(t1,t2,….,tn)输入Transformer层以提取特征,得到语义丰富的输出序列h0=(h1,h2,….,hn)作为后续实体关系联合抽取的句子编码。
BERT预训练模型的关键部分在Transformer层,Transformer层的核心是通过自注意力函数Attention()来计算词与词之间的关联度,以此来分配词的权重[16]。
(1)
式中,以headi表示单头Attention,MultiHead表示多头注意力,W是权重矩阵,通过多个不同的线性变换对Q、K、V投影,再用拼接函数Concat()将自注意力机制结果拼接乘以权重,通过计算来得到不同空间维度的位置信息。
(2)
MultiHead(Q,K,V)=Concat(head1,head2…headn)W0
(3)
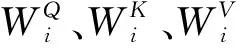
1.4.3 双向长短时记忆BiLSTM层 长短时记忆网络LSTM是循环神经网络的一种变体,BiLSTM模型不同于单向的LSTM神经网络模型,BiLSTM模型的优势在于可实现对文本前句和后句的双向分析,有效处理梯度爆炸和梯度消失的问题,在实体抽取任务中效果更优[17]。茶叶领域的语料文本结构复杂多样化,需结合上下文信息才能精确提取目标实体。LSTM模型的弊端在于只能获取目标实体的前向信息,比如,名为“茶赤叶斑病”的病害实体,若采用LSTM模型,则只能获取到“斑”字的前向信息“叶”,而无法预测到后向的“病”字。LSTM的单个神经元(CELL)结构如图4所示。
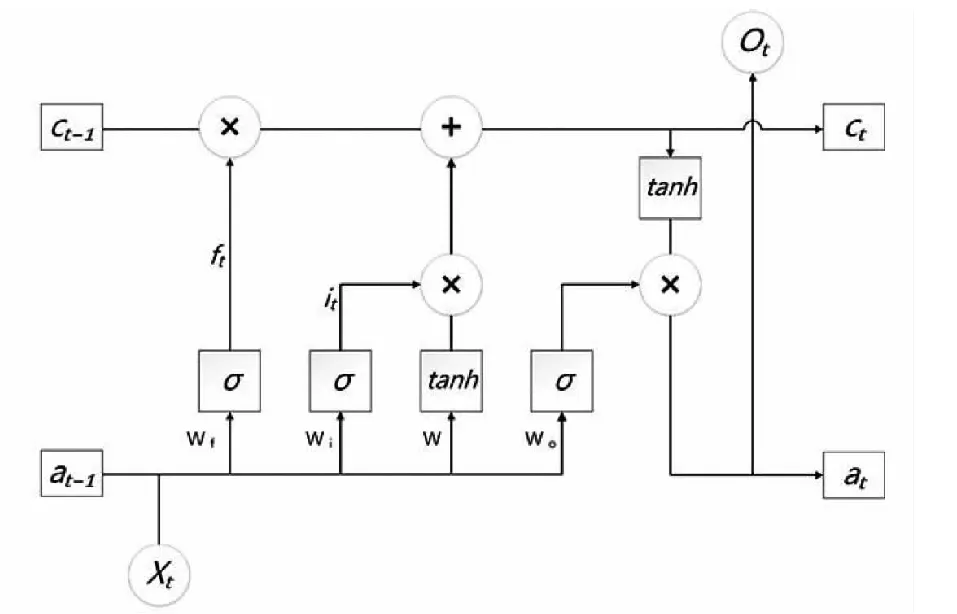
图4 LSTM的单个神经元Fig.4 Single neuron of LSTM
在LSTM模型中,包含遗忘门、输入门和输出门3种门结构。遗忘门负责管控上一时刻Ct-1到当前时刻Ct的保有量,输入门负责管控网络输入xt到当前时刻Ct的保有量,输出门控制Ct输出到at。
ft=σ(Wf×[at-1,xt]+bf)
(4)
it=σ(Wi×[at-1,xt]+bi)
(5)
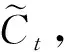
(6)
(7)
最后LSTM的输出值at由输出门的值ot和单元状态Ct计算所得,如公式(8)(9)所示:
ot=σ(Wa×[at-1,xt]+b0)
(8)
at=ot×tanh(Ct)
(9)
将前向LSTM和后向LSTM组成双向长短时记忆网络BiLSTM分别将从左右2个方向拼接成一个长输入序列,并输出到模型下一层,其结构如图5所示。
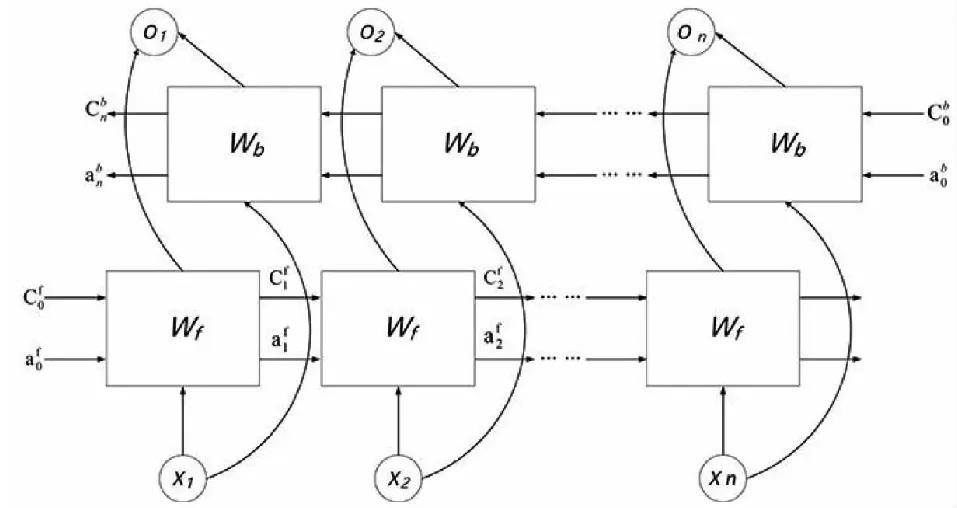
图5 BiLSTM双向结构Fig.5 Bilstm bidirectional structure
1.4.4 融合自注意力机制Attention_Tea层 注意力机制(Attention Mechanism)一词起源于人类对观察事物的研究。由于人类的视觉对客观世界的信息处理存在瓶颈,注意力机制会将注意力集中在具有明显特征的信息上,选择性忽略一些次要信息[18]。在茶叶领域命名实体抽取任务中,存在较多茶叶专用名词和生僻汉字,且同一命名实体可能存在多篇语料数据中,实体所处位置不同,表达的含义也存在差异。若忽略实体在全文的语境,仅关注实体在所处句子的上下文信息,会出现同一实体前后标注不一致的问题。例如品种‘福选9号’的文本描述如下:福选9号是因从福鼎大白茶中选育而得名,选自福建福鼎县。小乔木型、中叶类,特早品系,雨水节左右萌发采摘。文本中出现了2个品种名,即“福选9号”和“福鼎大白茶”,从文本的描述中不难看出来,该句描述的品种主实体应该是‘福选9号’,但‘福鼎大白茶’在多篇语料数据中以实体形式出现,在脱离全文语境,仅对该句进行识别的情况下,很大概率会对‘福选9号’错标或漏标。本研究根据茶叶语料数据中实体分布不均匀、实体多样化等特点,引入茶叶语料数据全局信息解决实体标注不准确的问题。为选择最适合的注意力计算函数,分别以感知机、余弦距离、皮尔逊相关系数进行注意力机制实验,表明,余弦距离对茶叶命名实体的识别效果最优。因此,本研究选择余弦距离公式做相似性计算,重点关注分布在不同篇幅语料数据的同一实体[19-20]。
本研究通过注意矩阵处理BiLSTM层输出的特征序列,计算文档中所有字与目标实体的相关性。注意力权重向量ri的计算公式如下:
(10)
式中,yj表示BiLSTM层的输出的特征序列。bij为当前字与全局文档字的相关性概率,其计算公式为:
(11)
(12)
式中,wi、wj为当前字和文档中字的权重,Wa为训练过程的参数,f(wi,wj)为余弦距离。
1.4.5 条件随机场CRF层 条件随机场(Conditional random field,CRF)以BERT层、BiLSTM层和Attention_Tea层提取上下文特征向量为输入,其主要目的是对语句进行有序列的输出,利用CRF层中的转移矩阵找出标签之间的联系。当Attention_Tea层输出的序列为x,标签序列为y的概率计算公式为:
s=∑iPE(xi,yi) +PT(yi-1,yi)
(13)
式中,PE为注意力层输出概率,PT为CRF层转移概率。
1.5 试验方法设计
1.5.1 本模型与基准模型对比试验 本研究以BERT-BiLSTM-CRF为基准模型,提出融合全词掩码和注意力机制的BERT-WWM-BiLSTM-AttTea-CRF模型。为验证该模型改进后的有效性,以BiLSTM-CRF、BERT-BiLSTM-CRF、BERT-BiLSTM-AttTea-CRF 3种模型分别搭配全词掩码和单字掩码进行模型性能对比,为验证改进算法对模型识别效率的提升,所有模型均采用相同的参数、学习率和Transformer层数,且茶叶语料训练数据和测试数据均为同一数据集。
1.5.2 不同类别的茶叶数据对比试验 为进一步验证模型改进对茶叶各大类语料数据识别的性能提升,在BERT-BiLSTM-CRF基准模型的基础上分别加入全词掩码和注意力机制层,形成4组模型分别对试验材料中的茶叶品种、茶叶病害、茶叶生长环境、茶叶适用技术4类数据进行分类实验。
1.5.3 本模型与其他模型对比试验 本研究模型是基于BERT-BiLSTM-CRF的改进模型,为验证本模型相对其他模型在茶叶领域实体抽取的有效性。本模型选择在中文命名实体任务中取得较好成绩的3种模型。其中BERT-IDCNN-CRF模型在医疗和军事领域表现突出[21],RoBERTa-BiLSTM-CRF在特定中文领域的实体识别任务中F1值达到96%[22],ALBERT-BiLSTM-CRF在大规模中文事件数据集准确率达95%[23]。本研究实验过程中所使用的茶叶语料训练数据和测试数据均为同一数据集。
1.6 试验环境与指标
模型训练需要消耗大量的算力资源,只依靠计算机CPU计算会占用大量时间,因此本研究选择使用NVIDIA Quadro RTX 4000显卡对模型进行训练,详细的实验环境配置表如表2所示。

表2 实验环境配置
在评价指标方面,本研究采用自然语言处理领域最常用的准确率(Precision)、召回率(Recall)及F1值(F1-Score)3项基本指标来评价模型[24-25]。各项指标的计算公示如下:
(14)
(15)
(16)
式中,TP表示结果为正类,且预测正确;FP结果为正类,但预测错误;FN表示结果为负类,且预测错误。
2 结果与分析
2.1 改进后模型的性能对比
由表3可知,在原有的BiLSTM_CRF模型上加入BERT预训练层后,模型识别准确率显著提升,其中准确率提升5.91个百分点,召回率提升6.34个百分点,F1值提升5.88个百分点,说明位置信息是茶叶语料数据中的重要特征。通过后4组模型的实验对比可以看出,加入全词掩码的BERT层与单字掩码的BERT层对比,模型识别率有1~2个百分点的提升。而同样为全词掩码的2组模型中,融入茶叶语料特征注意力机制的BERT-WWM-BiLSTM-AttTea-CRF模型,相对BERT-WWM-BiLSTM-CRF模型,准确率、召回率、F1值分别提升4.11、5.46、4.81个百分点。融合全词掩码和注意力机制的BERT-WWM-BiLSTM-AttTea-CRF模型的准确率、召回率、F1值分别达到92.03%、90.36%、91.19%,为本试验中的最优模型。
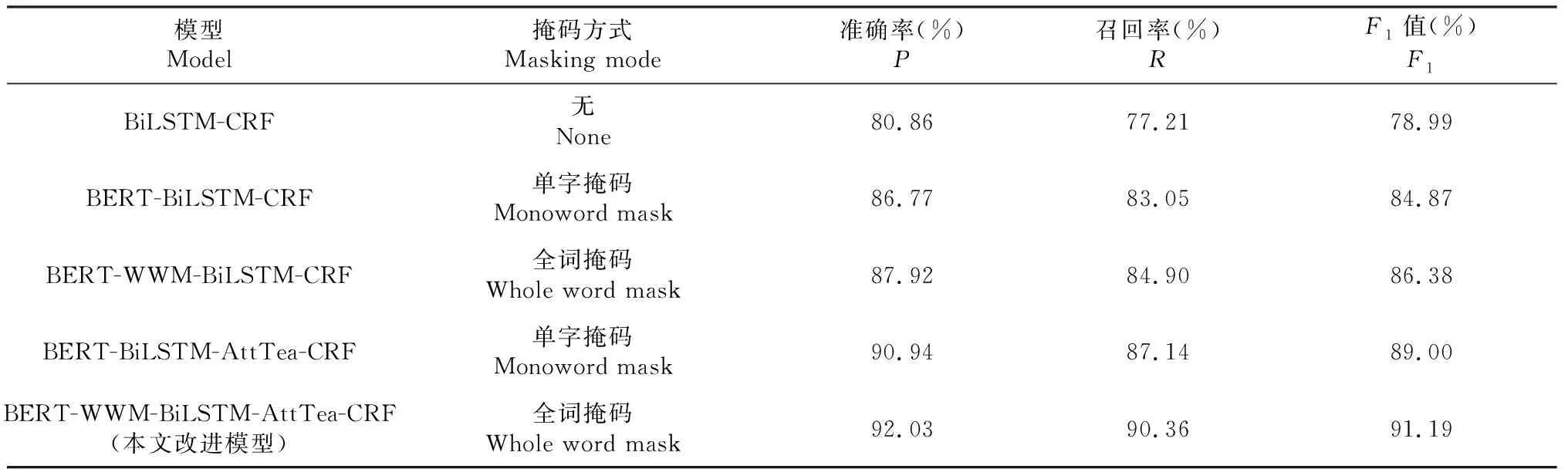
表3 模型的性能对比
2.2 不同类别的茶叶数据对比
由图6可知,在不同类别的茶叶语料数据对比试验中,与茶叶品种和茶叶病害相比,本研究模型对于生长环境、适用技术的提取结果较差。对茶叶语料数据的分析可知,造成提取结果较差的原因是由于茶叶品种和茶叶病害的文本描述格式较为统一,语序较为固定,模型可以较好地提取到文本中的实体与实体关系数据。而茶叶生长环境数据和适用技术中包含大量的指标名称和指标数值,且描述方式规律性较弱,例如:幼树一般要进行3~4次定剪,以春季茶芽未萌发之前(3月惊蛰前后)为佳,最迟必须保证在春季茶萌芽前进行,内容中包含类似“前后”、“最迟”的指标描述,若模型只提取到时间关键词“3月”而对“前后”漏标,形成的知识数据与原文即存在较大误差。可见,本研究根据茶叶语料数据做针对性改进后的全词掩码BERT-WWM-BiLSTM-AttTea-CRF模型对基础模型的提升效果显著,但同时也存在全词掩码策略对茶叶生长环境识别提升不明显的问题。
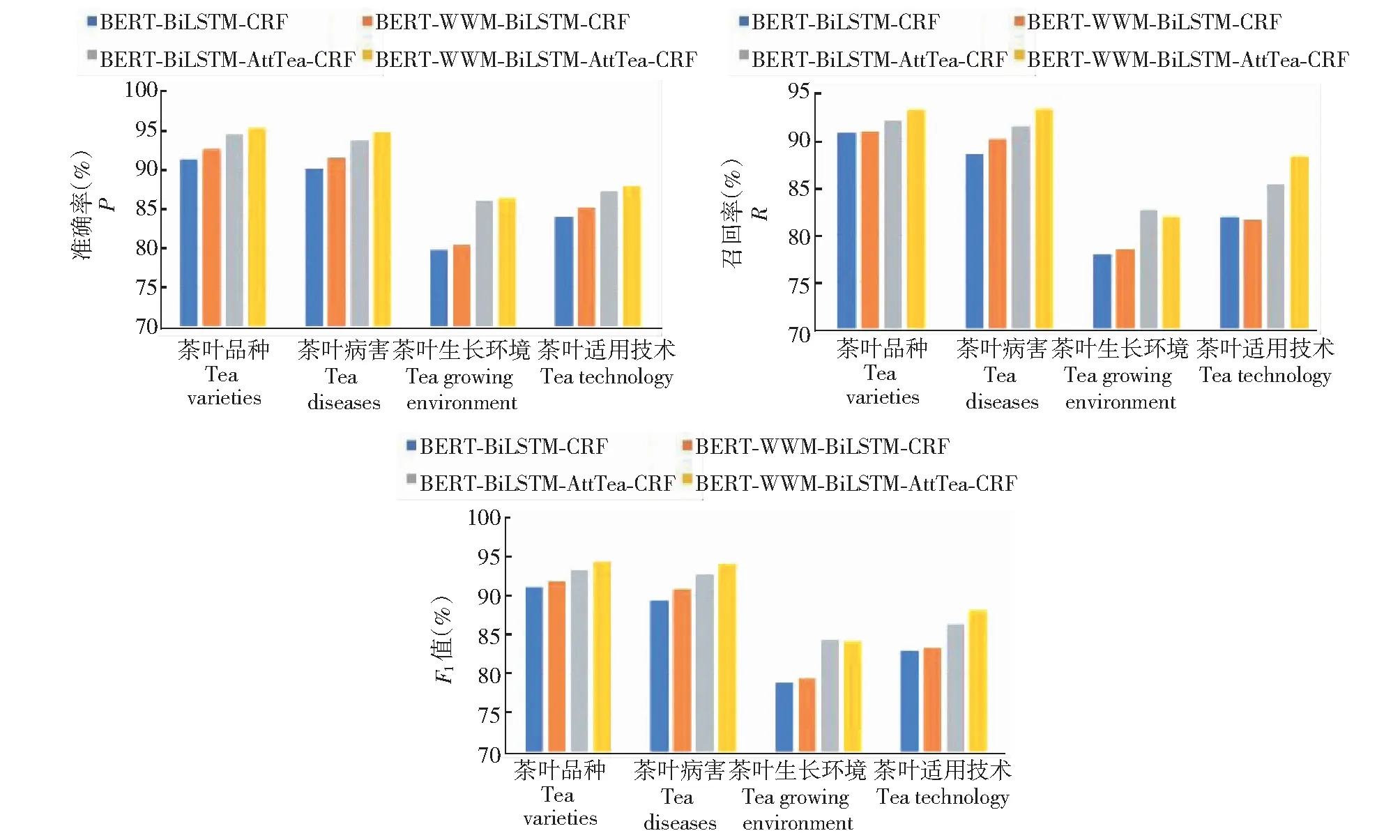
图6 不同类别的茶叶数据对比试验Fig.6 Comparative test on data of different types of tea
BERT-BiLSTM-CRF基准模型对茶叶品种、茶叶病害的提取效果较为一般(表4),经过本研究改进的BERT-WWM-BiLSTM-AttTea-CRF模型,对茶叶品种、茶叶病害等4类数据的识别效率都有显著提升。

表4 BERT-WWM-BiLSTM-AttTea-CRF在各类实体上的识别
2.3 本模型与其他模型的对比
由表5可知,本研究提出的BERT-WWM-BiLSTM-AttTea-CRF模型相较BERT-IDCNN-CRF、RoBERTa-BiLSTM-CRF、ALBERT-BiLSTM-CRF 3类模型在准确率上分别提升10.66、9.06、3.76个百分点;在召回率上分别提升8.27、9.24、6.94个百分点;在F1值上分别提升9.28、9.16、5.41个百分点。BERT-WWM-BiLSTM-AttTea-CRF模型在茶叶领域命名实体识别任务中准确率、召回率、F1值分别达到92.03%、90.36%、91.19%,均优于其他主流模型,因此在茶叶全产业链知识图谱构建研究中采用本模型作为非结构化数据抽取的主要方法。

表5 模型对比
3 讨 论
伴随着计算机硬件能算力的提升,基于规则和词典的方法在深度学习技术的加持下,对处理实体抽取任务表现出较高的效率。文本提取不再只依赖于人工特征,图谱构建过程中特征提取的成本有效降低[26],为农业领域知识图谱的完整构建提供了新的可能。吴赛赛等[27]提出一种基于BERT+BiLSTM+CRF的作物病虫害知识图谱构建方法,并利用Neo4j实现作物病虫害知识图谱的可视化展示。袁培森等[28]根据植物本体论提出利用BERT模型实现水稻的基因、环境、表型等实体与实体关系的抽取。宋林鹏等[29]使用传统的CRF和词向量+BiLSTM+CRF 2种模型对农业技术文本实体进行提取,得出词向量+BiLSTM+CRF模型提取效果优于传统CRF的结论。以上研究均利用BERT等实体抽取模型,在农业领域的文本实体抽取任务中取得一定成效,但上述实体抽取方法多为现有模型,未根据农业领域文本特征做出针对性的创新和改进。本研究对茶叶语料数据的位置信息和全局文本中的权重信息进行改进,相对于传统BERT-BiLSTM-CRF模型而言,识别和抽取效率有效提高。
传统的关系型数据库不适合用于处理实体之间的关系,因此,知识图谱通常以图数据库作为存储引擎。目前,市面上常用的图数据库包括JanusGraph[30]、Neo4j[31]、TigerGraph[32]、ArangoDB等。在性能方面,Neo4j和TigerGraph的数据存储基于点和边,计算过程中不需经过逻辑层和物理层转换,在执行速度上更快。在存储容量方面,JanusGraph利用HBase实现后端分布式存储,在支持大容量存储方面有一定优势。本研究中的茶叶知识图谱属于特定领域知识图谱,与通用型知识图谱相比数据量较小,图谱演进速度较慢,但图谱维度更深。因此,Neo4j作为一款开源图数据库系统,具体执行速度快、轻量级部署、组件丰富等优势,更适用于茶叶知识图谱的数据存储。通过对茶叶非结构化数据的知识抽取,利用关系数据找出知识抽取中的等价实体,实现知识融合,最后结合专家经验进行知识补全,初步形成的茶叶知识图谱共有实体2690种,关系数据277种,三元组数据5610条。由于茶叶知识图谱的数据体量并不庞大,因此本研究采用 Neo4j 数据库自带 Cypher 查询语言将解析获取的实体节点和关系数据保存在import目录下的.csv文件中。为避免因导入中文数据出现的乱码,将文本转换为UTF-8格式,再通过LOAD CSV的方式导入import目录下的.csv文件,并结合JavaScript Driver读取Neo4j图数据库中茶叶全产业链图谱数据,将读取后的数据解析为JSON格式,最后利用D3.js可视化框架实现茶叶图谱数据可视化。
4 结 论
本研究提出的BERT-WWM-BiLSTM-AttTea-CRF模型可自动提取茶叶知识文本数据,形成一种覆盖茶叶全产业链的知识图谱构建方法。结果表明该方法对茶叶文本数据的抽取效果优于ALBERT-BiLSTM-CRF、RoBERTa-BiLSTM-CRF等主流模型,准率去、召回率、F1值分别达到92.03%、90.36%、91.19%。茶叶知识图谱的构建也为农事指导问答系统、农业知识图谱的应用、特定领域知识图谱构建等研究方向提供了参考。
