基于关键点的残差全连接网络动态手势识别方法
2022-03-15张云峰
张云峰,张 超,吕 钊, 2*
(1.安徽大学 计算机科学与技术学院,安徽 合肥 230601; 2.安徽大学 物质科学与信息技术研究院,安徽 合肥 230601)
如今,人工智能步伐越来越快,万物互联,人机交互技术越来越贴近人们的生活.人机交互是计算机领域中的一项重要技术,种类多样,常见的人机交互技术有基于键盘和鼠标的输入、基于声音和面部表情以及手势识别技术等.手势因其具有自然、直观以及灵活等优点,手势识别在模式识别和人机交互领域逐渐成为热点研究,其应用场景广泛,如智能家居领域、医疗领域、手语领域.
随着车联网技术的发展,人车交互需求必然进一步增加[1].手势是一种自然直观易学习的交互方式,若将手势识别应用到车载系统中,将大幅减少驾驶员在行车过程中的分神行为,同时保证视线停留在行驶轨道上不发生大幅度移动,增加了行车的安全性和舒适性.
1 相关工作
手势识别主要分为接触式和非接触式两类,接触式手势识别主要为通过可穿戴感应手套传感器获取手指的弯曲程度和手部的活动状态来判断用户的手势操作,这种技术需要佩戴专门的设备,成本较高,交互方式不自然,尤其在车载环境下更不适合,因此越来越多的手势识别研究侧重于非接触式,即基于视觉方法[2],其获取数据更加方便,普通摄像头即可,成本较低.动态手势一般是由若干个连续手部动作组成,需用视频等方式的时序数据表示[3-4].文献[5]提出了一种基于单个3维加速度计的手势识别系统,文献[6]提出了用贝叶斯分类和动态时间规整两种方法识别不同受试者的4种手势,这些传统方法具有一定的局限性[7],严重依赖手工特征提取并且需背景不变、光照不敏感等条件才能实现较好的性能,因此在车载环境多因素影响下并不适合.
Alex开启了深度学习在计算机视觉领域的应用[8],越来越多的研究人员通过深度学习方法研究问题[9-10].深度学习在很多领域取得了成功,解决了一些传统方法的难点,其中RNN(recurrent neural net)和LSTM(long short-term memory)是比较流行的建模方法,在很多方面取得了突破,如视频分析[11]、3D动作识别[12-13]等.车载环境有较多不可控因素影响着手势识别,如背景不固定性、车辆行驶过程中路面的不平坦性、车速不稳定性、光线强弱等.深度学习的上述方法存在改进空间,论文提出了一种基于关键点的残差全连接算法,对硬件需求较低,可以更好地应对复杂背景下的视频手势识别.
2 方 法
2.1 实现方法
处理动态手势识别的传统流程是利用摄像头获取视频手势,然后对视频进行分帧处理,获取一个手势图像序列.由于图像本身受到外界环境的各种影响,需要预处理所有的目标图像,然后选择合适的分割方法进行手势分割,得到目标的初始区域.选择合适的跟踪方法对目标进行跟踪,选取适当的建模方法对动态手势进行模型训练和建立,再对新的动态手势进行分析并与经过训练得到的手势模型进行比对,从而得到最合适、最准确的识别结果.这类方法适用于背景信息干净且摄像头稳定的场景.然而车载场景下背景复杂及车辆行驶过程中有颠簸现象,导致采集的数据分帧后出现一些模糊质量的帧,帧中有效手势信息所占比重小,影响模型的训练和识别.鉴于此,论文在动态手势识别过程中采取的策略是先预处理原始视频、分帧分段,提取视频的关键帧,得到了数量相对少很多的图像序列,然后利用这些关键帧中的手势信息(关键点坐标),进行模型训练与识别,去除大量干扰信息的同时降低了算法复杂度.其流程如图1所示.

图1 基于关键点的残差全连接网络动态手势识别的整体框架
2.2 关键点获取
图像处理中,关键点的坐标信息本质上也是一种特征,它是对一个固定区域或者空间物理关系的抽象描述,描述的是一定邻域范围内的组合或者前后帧之间的关系.关键点代表的不仅仅是一个点的信息或者一个位置,同时具有相邻帧的关联.OpenPose是基于深度学习的姿势确定开源框架,手部模型输出对应的关键点信息,关键点检测器d(.)将预处理后的输入图像块I∈w*h*3映射到p个关键点的位置,xp∈2,每一个都有相应的置信度cp[14]

(1)

(2)
train(T0)→d0.
(3)
论文关键点的提取基于手部模型,手部模型共输出22个关键点,其中21个点是手部信息,第22个点表示背景信息.将手部模型的网络输入图片分辨率设定为640×480,阈值设为0.2.其主要步骤为用函数readNetFromCaffe加载模型权重、读取数据(视频/图像)、blobFromIamge将图像转为blob、forward函数实现网络推断、通过网络计算得到22个矩阵,每一个矩阵代表某个特定关键点最可能出现在图像哪个位置的热图,调用minMaxLoc函数找到精确位置,将得到的坐标信息和阈值进行比较确定是否作为关键点.
2.3 残差全连接网络

(4)

(5)

(6)
由于网络结构的层次相对深时往往出现梯度弥散或者梯度爆炸问题,且随着网络结构层次的增加,模型有可能出现退化现象,因此论文选择在全连接网络中加入残差网络的思想即残差全连接网络,网络架构如图2所示.
核心网络结构由3个基本块构成,基本块的参数为(输入层、隐藏层、输出层),每一个基本块由3层残差全连接网络构成,输入的数据为处理后的关键点坐标信息,6帧的坐标信息维度为44×6.第一个基本块的参数为(264, 8 000, 3 500),第一个基本块的输出作为第二个基本块的输入;第二个基本块的参数维度为(3 500, 5 000, 1 024),第二个基本块的输出作为第三个基本块的输入;第三个基本块的参数维度为(1 024, 3 000, 6).然后通过softmax进行分类得出识别结果.

图2 残差全连接网络架构
3 实验结果与分析
该章所有实验均在Windows 7、Intel Core ML(TM)i5-7500 CPU@3.40 GHz、16 GB运行内存、64位操作系统的计算机环境下进行,分析数据所用的软件为PyCharm 2018.1.1.
3.1 数据集构建
公开可用的手势数据集对研究人员非常重要,尤其是车载环境的手势数据更是很少公开,因此论文使用到的数据集均为实际车载环境采集所得.受试者为实验室人员,采集设备为USB摄像头,帧率30 fps,受试人数为22,使用4辆车(东风雪铁龙世嘉、别克昂科拉、别克昂科威、斯柯达)共采集3 120个动态手势视频数据,训练时将所用图片尺寸统一调整为640×480(文中若无特殊说明,则每次训练均调整为这个尺寸),手势分别为“上移”“下移”“左移”“右移”“张开”“闭合”,数据集的80%作为训练集,即训练集数量为2 496,数据集的20%作为测试集,即测试集数量为624.6种基本手势定义如图3所示.

图3 6种基本视频手势
3.2 激活函数与学习率选取实验
激活函数和学习率是深度学习网络中的重要参数,激活函数为神经元引入了非线性因素,使得神经网络可以逼近任何非线性函数,可应用于非线性模型.学习率决定着目标函数能够收敛到局部最小值以及何时可以收敛到最小值,学习率太小,则权值更新较慢且易过拟合;学习率太大,则可能错过最优解,损失函数值易振荡.论文使用相同的数据并保证其他条件相同,对比了常用的prelu,relu,tanh,sigmoid激活函数与学习率组合的性能,其实验结果如图4所示.

图4 不同激活函数与学习率的识别结果
图4横坐标表示不同的激活函数,纵坐标表示平均识别率(%),右方图例表示学习率,从上到下学习率依次为1e-3,1e-4,1e-5,1e-6.由实验结果可以看出,激活函数prelu和学习率1e-5的组合性能最好,识别率为96.72%. prelu[17]是relu的进一步优化,弥补了输入数据为负值神经元死亡的弊端,表达式为
(7)
其中:xi代表第i个通道的输入;αi是控制负数部分的斜率系数.在负数区域内加入一个斜率,可以有效避免神经元死亡同时加快损失函数的收敛速度,其收敛速度比relu更快且输出均值更接近于0.学习率为1e-5时的平均识别率最高为96.72%,比relu提高了2.21%,且prelu几乎没有额外的计算成本和过拟合风险.α是自适应可学习的参数[17],初始化为0.5,α更新为
(8)
其中:xi为第i个通道的输入,∂i为控制负数部分的斜率系数,ε为目标函数.综合损失函数收敛速度、准确率等方面来确定反向传播算法的学习率.论文算法选择prelu作为激活函数、1e-5作为学习率.
3.3 关键帧数量选取实验
动态手势的一系列图像帧在时间上连续且内容上具有非常高的相关度,因此存在较多具有重复信息的帧,识别过程中的这些帧可以选择性地舍弃,选择其中具有代表性的帧即关键帧.选取关键帧的意义在于不失视频关键信息的同时使得视频中手势帧数大大减少,便于进行数据信息处理,复杂度大大降低,因此,视频中关键帧的提取过程变得很有必要,也可以当作动态手势识别的一个优化过程.为了确定最优关键帧个数,论文分别在车辆行驶与静止两种状态下进行了实验,分别在两种数据集上提取了不同的关键帧数,即3~8帧,其实验结果如图5所示.

图5 不同关键帧数量识别率
车辆行驶过程中数据提取关键帧个数为3~5帧的识别率分别为95.51%,95.60%,96.64%.当关键帧数上升为6帧时,识别率为96.73%.相似地,在车辆静止状态下关键帧个数为3~5帧时识别率分别为95.70%,96.65%,96.68%,低于其6帧时的识别率96.82%.其可能的原因是:对于整个视频而言,提取3~5帧时不能包含代表视频手势的所有信息,有些关键信息会遗漏丢失少量信息,从而导致部分手势分类错误.然而当继续增加关键帧个数至7,8帧时,其识别率在行驶与静止状态下均出现了下降趋势.车辆行驶过程数据关键帧个数为7,8帧的识别率分别为96.71%,96.66%,比关键帧个数为6帧时的识别率低了0.03%,0.08%;车辆停靠过程数据对应的识别率分别为96.74%,96.70%,比关键帧个数为6帧时的识别率低了0.08%,0.12%.原因可能是更多的关键帧包含了部分冗余信息,这些冗余信息将会导致识别性能的下降,因此选择6帧作为关键帧的数量.
3.4 手势识别算法性能分析
为了验证该算法的鲁棒性,采集数据过程用到了4辆车,分别为车辆1(东风雪铁龙世嘉)、车辆2(别克昂科拉)、车辆3(别克昂科威)、车辆4(斯柯达),在不同光照与车辆是否行使条件下作了对比实验,3种光照强度场景如图6所示,实验结果如表1所示.

图6 3种不同光照强度场景

表1 不同光照下车辆行驶与车辆静止时的识别率 %
行驶过程中的车辆1~4在正常光照条件下的平均识别率分别为96.75%,96.73%,96.72%,96.73%,略低于车辆静止时正常光照条件下的识别率96.83%,96.84%,96.81%,96.82%;强光条件下,在行驶的4种车辆下的识别率均略低于静止的4种车辆,分别相差0.20%,0.20%,0.28%,0.13%;弱光条件下,静止时4种车辆手势识别率略高于车辆行驶条件下的手势识别率,高出的识别率分别为0.17%,0.16%,0.16%,0.16%,原因可能是车辆行驶过程的车速变换或道路颠簸造成采集过程中数据波动.由表1可知,车辆行驶与静止环境下的3种光照条件所得视频手势识别率中,车辆3均略低于其他3辆车,原因可能是车辆3空间较大且车内装饰风格与肤色相似,从而造成手势关键点定位不够精准,导致识别率略微低.由表1中可知,不同光照条件下车辆静止的手势平均识别率为96.65%,略高于车辆行驶过程中的平均识别率96.50%,验证了论文算法的鲁棒性.
3.5 不同模型对比实验
为了验证所提模型的有效性,论文与以下模型进行了对比实验:C3D模型是采用3D卷积和3D pooling构建的网络[18],将时间维度和空间维度一起卷积,使用更高维度的卷积核与更高维度的池化算子构建卷积网络;CNN是一种前馈型神经网络,具有自学习能力;长短时记忆网络(LSTM)是一种时间循环神经网络[19], LSTM引入的记忆单元可以有效表达帧的先后顺序,能够学习到长期依赖关系[20],在处理长序列时具有一定的优势;双流网络主要包含空间和时间两部分[21],利用两个独立的CNN网络进行时间和空间融合.实验结果如图7所示,横轴表示模型,纵轴为手势平均识别率(%).

图7 不同光照下模型对比结果
由实验结果可知,正常光照条件下的C3D模型识别率为86.03%,高于强光条件下的识别率80.27%及弱光条件下的识别率83.50%.对比实验中的CNN架构为4层卷积、4层池化以及3层全连接,每一帧提取特征后进行池化,对于手势识别而言忽略了时间信息,利用视频的全部帧,算法复杂度较高,所耗时间太久.质量差的帧或者帧中与分类主题无关的信息时将对识别造成影响,CNN模型在正常光照强度下的手势识别率为90.35%,比强光条件下的识别率高8.05%,比弱光条件下的识别率高4.85%.
LSTM正常光照强度下的平均识别率较C3D和CNN分别提升了5.55%,1.23%,但对于较多量级或更长序列则表现不好,此外该网络存在对硬件需求较高、计算费时、需要大量资源等弊端.LSTM模型在强光下的手势识别率比正常光照强度下的识别率低8.27%,其正常光照强度下识别率为91.58%及弱光条件下的86.32%.双流网络模型空间网络通道的输入通常为单帧图像或者多帧堆叠,主要捕捉视频帧中的重要物体特征,通过光流法形成时间的差分,从而达到时间和空间互补的目的.时间网络中光流的提取需要消耗大量的精力和时间,并且光流所包含的未必就是最优的运动特征,同时双流架构不能在视频中利用目标移动位置的信息.正常光照下手势识别率为92.25%,比LSTM提升了0.67%,高于强光下的85.50%及弱光下的87.31%.
论文的模型在3种光照强度下平均识别率均最高,分别为强光数据集下的95.96%、正常光照数据集下的96.72%及弱光条件下的96.63%,并且该模型在不同光照强度下识别率波动最低,此外,以上4种对比模型在强光和弱光条件下采集的数据集相对于正常光照条件下的数据集识别率波动较大,原因可能是这些模型采用了视频手势的所有帧,而在强光和弱光条件下采集数据时存在整个手势采集过程中均有强光源照射摄像头或者无光源情况,这样得到的数据由于干扰信息大加之背景复杂,从而导致手势有效信息所占比重较小.而论文网络模型在训练数据之前进行了优化,摒弃了冗余和质量较差的帧,同时利用代表数据的最大有效信息帧,降低算法复杂度的同时又提高了识别速度,实验结果再次验证了论文算法的有效性.
为了进一步评估论文算法的性能,给出了6分类视频手势的混淆矩阵图,混淆矩阵图更直观地显示了相互类别的误判率[22],实验结果如图8所示.
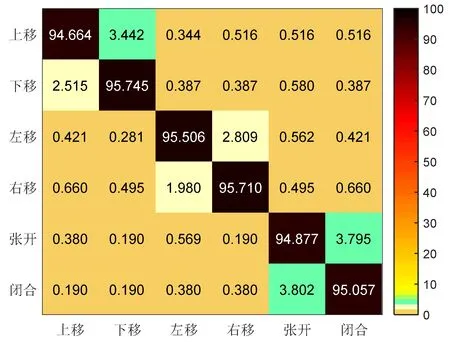
图8 6分类手势混淆矩阵
图8横坐标为预测类别,纵坐标为真实类别,矩阵中的数值单位为%,其对角线上的概率为分类正确的概率.由混淆矩阵图知,上移和下移手势分类正确率分别为94.664%,95.745%,被误判的概率分别为3.442%,2.525%,原因可能是对上移和下移手势定义存在相似之处,同为横向手掌移动,左移和右移手势相互误判概率分别为2.809%,1.980%,原因可能是手势定义具有一定的相似性,均为纵向手掌,在采集手势过程中不同手势速度可能导致结果误判.由于张开和闭合手势部分帧为完全伸展的纵向手势,因此会被误判为张开和闭合.造成张开和闭合手势分类平均正确率为94.877%,95.057%,二者被误判的概率为3.795%,3.902%,造成误判的主要原因可能是采集手势过程中完成有效手势时间有差别.6分类视频手势的平均分类正确率约为96%,再次验证了该算法的有效性.
4 结束语
基于视频的动态手势识别近年来受到了广泛关注,现有研究方法仍然存在局限性,很难达到令人满意的性能,尤其在车载动态场景下识别手势更为困难.论文提出了一种基于关键点坐标信息的残差全连接网络识别车载手势算法,网络核心架构为3个残差全连接基本块,该方法可以高效地识别出车载场境下的6种动态手势.通过对比实验,结果表明该模型在实际车载环境所采集的数据集上综合性能较优,较好地应对了光照条件和车载动态场景.但论文的车载手势种类还不够丰富,不同速度下的数据对比实验相对较少.作者下一步工作将增加不同速度下的数据对比实验,增加多种手势以及手势的复杂度,同时加入更加复杂的车载场景进行研究.
