MRTP:时间-动作感知的多尺度时间序列实时行为识别方法
2022-03-15张坤杨静张栋陈跃海李杰杜少毅
张坤,杨静,,张栋,陈跃海,李杰,杜少毅
(1.西安交通大学自动化科学与工程学院,710049,西安;2.西安交通大学人工智能学院,710049,西安)
temporal attention
近年来,行为识别在智能视频监控、辅助医疗监护、智能人机交互、全息运动分析及虚拟现实等领域均具有广泛的应用需求[1]。从应用场景看,行为识别可分为异常行为识别、单人行为识别、多人行为识别等[2]。行为定义模糊、类内和类间差异较大、计算代价等问题给视频行为识别带来了巨大的挑战[3]。
随着深度学习的崛起,许多深度学习方法被用于行为识别。由于行为识别需要同时获取空间和时间信息,所以两个网络并行的双流结构成为了目前视频行为识别领域的主流架构。双流网络大多使用光流作为时间流、RGB图像作为空间流。由于光流本身只使用于短时间的动作信息提取,所以此类网络无法解决长跨度动作的时间信息提取问题[4]。
循环神经网络在序列数据的处理上表现优异,而视频也是按照时序排列的序列数据,所以诸如LSTM[5]等循环神经网络被用于视频行为识别任务。然而,使用CNN-LSTM的方法在行为识别问题上并不能取得令人满意的效果。原因在于行为识别中作出主要贡献的是帧图像的空间信息[6],且相邻的视频帧能提供的时序信息十分有限。
3D卷积相较于2D卷积多了一个维度,对应视频比图像多了时间维度,因此3D卷积被引入用作行为识别的特征提取。随着视频领域大规模数据集的建立,3D卷积逐步超越了传统2D卷积的表现[7]。然而,视频信息在时空维度具有完全不同的分布方式和信息量,经典的3D卷积方法在时空维度并没有对此进行区分[8],由此导致了3D卷积计算了过多的冗余信息。如何减少3D卷积的计算消耗从而建立一个轻量级的网络是目前的研究热点。
长跨度的时间建模是行为识别中的一大难点[9]。由于时间维度信息与空间信息不平衡,已有的行为识别方法受限于采样密度较低和时间跨度限制,对于一些变化缓慢或者变化较小动作,如倾听、注视、打电话等,难以提取出有效的动作信息。对于部分需要依赖时间信息进行区分的动作,如讲话和唱歌、躺下和睡觉等,已有方法的效果不够理想。如何从冗余的视频信息中找到出含有动作信息的关键视频帧,目前的行为识别方法还未给出一个完善的解决方案。
本文针对RGB视频的轻量行为识别,提出了一种时间-动作感知的多尺度时间序列实时行为识别方法MRTP,旨在解决视频中空间和时序信息不平衡以及长时动作的关键帧难以提取的问题。本文提出的MRTP方法在行为识别的经典数据集UCF-101和大规模数据集AVA2.2上进行了训练和相关指标测试。测试结果表明,相比于主流的行为识别方法,MRTP方法具有更高的准确率和更小的计算成本,能够在方法部署阶段实现实时行为识别。
1 相关工作
行为识别传统方法一般使用时空兴趣点[10]、立体兴趣点[11]、运动历史图像[12]、光流直方图(HOF)[13]等局部描述符,通过视觉词袋[14]、Fisher Vector[15]等特征融合方法,用KNN、SVM等传统分类器进行分类。在2015年以前,iDT[16]是行为识别领域精度最高的方法。该方法通过提升的密集轨迹方法对相机运动进行估计,使用行人检测消除干扰信息,再基于光流直方图和光流梯度直方图等描述子进行SVM分类。iDT方法识别效果优良、鲁棒性好,但人工特征提取流程复杂且特征不够全面。随着深度神经网络的不断发展,基于深度学习的方法在精度和计算成本上都超越了传统方法。
目前,基于深度学习的行为识别方法有双流网络、循环神经网络、3D卷积等。
视频理解除了空间信息之外还需要运动信息,双流网络使用两个并行的卷积神经网络,分别独立进行特征提取,主流的双流方法有TSN[17]、Convolutional Two-Stream[18]、Flownet[19]等。在经典的Two-steam[20]方法中,一个网络处理单帧的图像,提取环境、视频中的物体等空间信息,另一个网络使用光流图做输入,提取动作的动态特征。考虑到光流是一种手工设计的特征,双流方法通常都无法实现端到端的学习。另外,随着行为识别领域数据集规模的不断扩大,由光流图计算带来的巨大计算成本和存储空间消耗等问题使得基于光流的双流卷积神经网络不再适用于大规模数据集的训练和实时部署。
LSTM[21]是循环神经网络中一种,该网络用于解决某些动作的长依赖问题。文献[22]研究了同时使用卷积网络和循环神经网络的CNN-LSTM网络结构在行为识别任务中的表现,发现需要对视频进行预分段,LSTM才能提取到较为明确的时间信息。文献[23]探索了多种LSTM网络在行为识别任务中的应用效果,发现相比于行为识别,LSTM更适合于动作定位任务。在视频行为识别中,很大一部分动作只需要空间特征就能够识别,但LSTM网络只能对短时的时间信息进行特征提取,无法很好地处理空间信息。因此,该类方法已逐渐被3D卷积等主流方法取代。
视频行为识别中,主流的3D卷积方法有C3D[24]、I3D[25]、P3D[26]等。文献[27]将经典的残差神经网络ResNet由2D拓展为3D,并在各种视频数据集中探索了从较浅到深的3D ResNet体系结构,结果发现在大规模数据集上,较深的3D残差神经网络能够取得更好的效果。然而,视频信息在时空维度具有完全不同的分布方式和信息量,经典的3D卷积方法在时空维度并没有对此进行区分,计算了过多的冗余信息,由此带来了过高的计算代价以及部署成本。
文献[8]提出了一种受生物机制启发的行为识别模型,通过分解架构分别处理空间信息和时间信息。在人类视觉中,空间语义(颜色、纹理、光照等)信息变化较慢,可使用较低的帧率。相比之下,大部分动作(拍手、挥手、摇晃、走路、跳跃等)比空间语义信息变化速度快得多,因此使用更高的帧率来进行有效建模。但是,该方法只改变了两个路径输入视频帧的数量。对单个视频帧没有进行更细致的处理,在空间流也未添加更多的动作信息予以辅助。
当前,已经存在很多基于3D卷积和双路径网络架构的行为识别方法,但效果均不理想,这主要是由于对于行为识别任务,视频中的信息较为冗余,对任务做出实际贡献的视频帧和含有动作信息的特征通道在视频中的分布十分稀疏。因此,如何找出含有关键信息的视频帧和特征通道亟待解决。
2 MRTP方法
本文设计了一个时间与动作感知的双路径行为识别方法MRTP,网络结构见图1。模型使用双路径结构,以视频包为输入,在时间维度上以步长1为滑动窗口,可得到视频中顺序排列的连续n帧图像。
每个视频以2 s长度截取视频包,对于视频包中的64帧图像再进行采样。T为每次采样的视频帧数,在高帧率动作路径设置T=32,低帧率空间路径设置T=4。低帧率空间路径所取视频帧的位置由高帧率动作路径的时间注意力模块生成的α和β决定,α和β为时间注意力筛选出的权重最大两帧图像对应的坐标。
高帧率动作路径采样的图像数量较多但通道数较少,低帧率空间路径采样的图像数量较少但通道数较多。设高帧率动作路径输入的图像数为低帧率空间路径的p倍,高帧率动作路径特征的通道数为低帧率空间路径的q倍,在UCF-101数据集和AVA数据集上,p=8,q=1/16。
Res1~Res4是ResNet3D的残差结构。使用Kinetics 400和Kinetics 600上预训练的ResNet3D 50和ResNet3D 101作为特征提取的骨干网络。
通道注意力模块用于衡量动作路径各个特征通道的重要性并进行加权。时间注意力模块在通道注意力模块筛选出的通道权重基础上衡量各个视频帧的重要性,将α和β输入到低帧率空间路径作为图像提取的位置坐标依据。动作感知模块基于相邻两帧的特征差分矩阵衡量前后两个视频帧的特征变化,并对通道赋予权重。
在卷积网络的Pool1、Res1、Res2、Res3之后建立侧向连接,将动作路径的特征通过重构之后传递到空间路径。
特征融合部分将高帧率动作路径和低帧率空间路径的特征连接起来。
Softmax函数将融合后的特征向量转换为类别概率向量,并选取其中的最大值所对应的类别作为输出结果。
2.1 高帧率动作路径特征提取
2.1.1 长时间跨度动作特征 在由图像序列组成的视频数据中,动态信息被定义为帧间图像的像素运动,即光流。然而,光流需要时间的变化不引起目标位置的剧烈变化,因此光流矢量只能在帧间位移较小的前提下使用。在需要长时间跨度动作特征提取的情况下,光流作为动态信息的一种表示,并不能提取出所需的动作信息表征。因此,本文引入高帧率采样的动作路径,该路径输入RGB视频帧,在本文实验的两个数据集上将帧率变为原来的p倍。同时,为了降低模型的计算量,使该路径更加聚焦于动态信息,本文将动作路径的通道数量变为原来的q倍,在保证了模型轻量化的同时实现了动态信息的提取。相比于基于光流的动态信息,本文通过使用RGB视频帧输入实现了端到端的训练和部署,并且特征的提取不再受光流的场景固定和小范围时间跨度的约束。
2.1.2 通道注意力机制 由于输入特征向量在通道维度有较大差异,有的通道对识别任务有较大贡献,但部分通道贡献较小,所以在3D卷积中引入通道注意力机制。将提取特征向量作为输入,通过计算通道权重对通道加权。
设输入特征向量的维度用数组X表示,X=[N,C,ωT,W,H],其中:N为输入的视频数;C为通道数量;ω为整个视频中所取的片段数,即进行3D卷积的次数,若视频长度在2 s以内,则ω=1;W和H为特征的宽和高。首先,在时间维度对特征进行融合
(1)

然后,在空间维度通过池化融合特征
(2)
式中zC为池化操作的结果。通过在特征的宽和高进行池化,特征向量的维度变为X=[N,C,1,1,1]。
最后,计算出每个通道的权重向量
a=Sigmoid(Y2ReLU(Y1zC))
(3)
式中:a为通道注意力计算出的权重向量;Y1和Y2为权重参数,在训练中得到;Sigmoid为S型激活函数;ReLU为线性激活函数。
2.1.3 时间注意力机制 由于每帧图像的重要性不同,所以对于通道加权后的特征向量,选取其中权值最大的通道特征作为时间注意力机制的输入并计算权重,从而对视频帧加权。
首先,利用输入的通道权重对通道数据进行筛选
uT=x[N,amax,ωT,W,H]
(4)
式中:x为输入特征向量;amax为上一步通道注意力机制中提取出的权重最大值对应的通道坐标;uT为通道注意力提取出的权重最大通道对应的特征向量。通过第1步提取操作,特征向量维度变化为X=[N,1,ωT,W,H]。
然后,在空间维度通过池化融合特征
(5)
式中zT为池化操作的输出特征。通过在特征的宽和高进行池化,特征向量的维度变化为X=[N,1,ωT,1,1]。
最后,计算出每个视频帧的权重向量
s=Sigmoid(W2ReLU(W1zT))
(6)
式中:s为时间注意力计算出的权重向量;W1和W2为权重参数,在训练中得到。
2.2 低帧率空间路径特征提取
2.2.1 视频帧按权重采样 空间路径采样视频帧的数量只有动作路径的1/p,在空间路径使用均匀采样会因为位置不准确导致无法提取出足够的信息。因此,MRTP方法采用动作路径生成的权重对空间路径进行非均匀采样指导,流程如图2所示。动作路径中的通道注意力和时间注意力模块生成了视频帧权重。基于该权重,在空间路径按权值从大到小,以2帧/s的处理速度在视频对应位置采样图像。假设时间注意力计算出的权重s中最大的两个值为sα和sβ,则在视频中按α和β所在位置抽取图像。相比于现有模型均匀抽取的方法,这种采样方法能够提取到信息量更多、对识别贡献更大的视频帧。
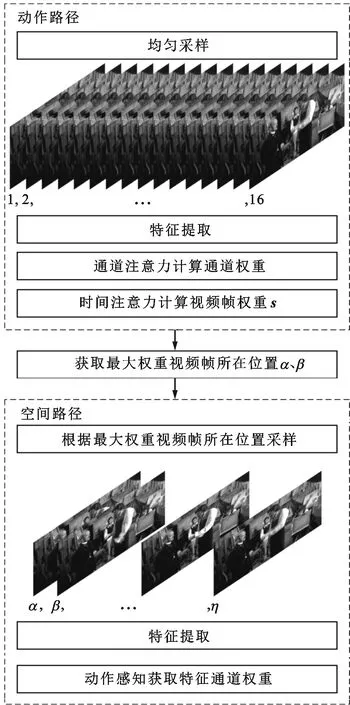
图2 空间路径视频帧按动作路径时间注意力权重进行非均匀采样示意Fig.2 Non-uniform sampling in spatial path according to time attention weight in motion path
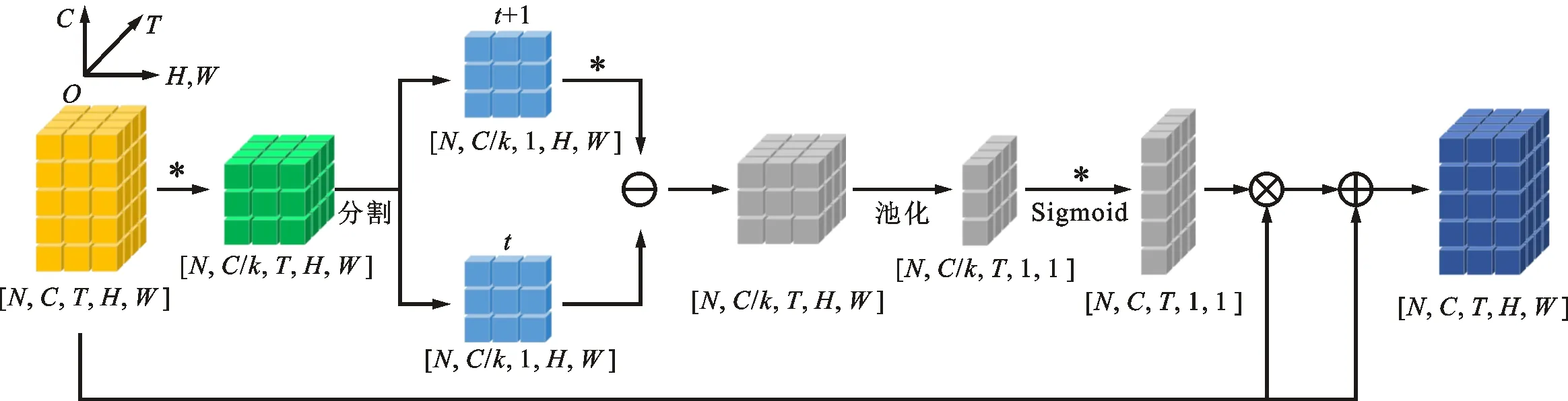
图3 动作感知结构Fig.3 Motion perception structure
2.2.2 动作空间特征提取 空间特征主要描述动作中涉及到的物体外观和场景配置。为了提取视频帧中细节的空间信息,本文使用低帧率空间路径,一次卷积中只使用4帧图像。预处理随机裁剪将图像归一化为224×224像素,在训练出的ResNet-3D网络模型中,Res4的特征通道数达到了2 048。更多的特征通道能够让该路径提取到颜色、纹理、背景等细节的空间信息。
2.3 动作感知
为了替代以光流为基础的像素级动作表示方式,并将时空特征结合起来,本文在低帧率空间路径使用了动作感知模块,从特征通道来进行动作表征和激励。该模块通过衡量前后两个视频帧的特征变化,赋予视频帧中动作信息对应的特征通道更大的激励权重,以此来增强网络对动作的感知能力。动作感知模块的计算流程如图3所示。
设输入特征为X,X的特征维度即为X=[N,C,ωT,W,H],此处X为一次卷积获得的特征,即ω=1,可得X=[N,C,T,W,H]。首先,使用一个3D卷积层来降低通道数以提高计算效率
Xk=conv3D(X)
(7)
式中:Xk表示通道减少后的特征,Xk特征维度为[N,C/k,T,W,H],k=16是减少的比率;conv3D表示使用尺寸为1×1×1的卷积核对通道维度进行降维操作。
对于运动特征向量,使用前后两帧图像对应的特征Xk(t+1)和Xk(t)之间的差来表示运动信息
P(t)=convshift(Xk(t+1))-Xk(t)
(8)
式中:P(t)是时间t时的动作特征向量,特征维度为[N,C/k,1,W,H],1≤t≤T-1;convshift是一个3×32通道卷积层,对每个通道进行转换。
假设T时刻动作已经结束,即T时刻已经没有动作特征,令P(T)为0特征向量。在计算出每个时刻的P(t)之后,构造出整个T帧序列的动作矩阵P。通过全局平均池化层激发对动作敏感的通道
Pl=pool(P)
(9)
式中Pl特征维度为[N,C/k,T,W,H]。使用3D卷积层将动作特征的通道维度C/k扩展到原始通道维度C,再利用Sigmoid函数得到动作感知权值
E=2Sigmoid(conv3D(Pl))-1
(10)
至此,得到了特征向量中各通道的动作相关性权重E。为了不影响原低帧率动作路径的空间特征信息,借鉴ResNet中残差连接的方法,在增强动作信息的同时保留原有的空间信息
XR=X+X⊙E
(11)
式中:XR是该模块的输出;⊙表示按通道的乘法。
3 实 验
3.1 实验设置
3.1.1 损失函数 在训练过程当中,对于同一输入有多个动作共存的情况,Sigmoid函数计算公式为
(12)
由于经过Sigmoid网络层后的输出为[0,1]内的概率值,因此本文选择二分类交叉熵损失函数进行训练,即对每一类动作都进行二分类判别。在判别时设定概率阈值为0.8,当大于该阈值时认为判别有效,即视频中包含该类动作,从而避免多分类的类别互斥情况,损失函数计算公式为
(13)

3.1.2 训练参数 本文实验使用深度学习框架Pytorch实现,训练使用SGD优化器,学习率调整策略为StepLR,基于epoch训练次数进行学习率调整,即每到给定的epoch数时,学习率都改变为初始学习率的指定倍数。初始学习率设置为0.05,指定当epoch数为10、15、20时,学习率分别设置为初始学习率的0.1、0.01、0.001倍,权重衰减设置为1×10-7,Dropout rate设置为0.5。AVA数据集训练样本庞大,刚开始采用较大的学习率可能会带来模型不稳定。为了防止出现提前过拟合的现象和保持分布的平稳,本文在训练过程中还加入了学习率预热策略,在epoch数小于5时,使用0.000 125的学习率进行训练,当模型具备了一定的先验知识,再使用预先设置的学习率,这样可以避免初期训练时错过最优点导致损失振荡,从而加快模型的收敛速度。
3.2 数据集
本文使用两个数据集评估MRTP的性能。其中,UCF101是行为识别领域的经典数据集,AVA2.2是目前最具挑战性的大规模数据集。在UCF101和AVA2.2上,分别使用三折交叉验证准确率和平均精度(mAP)作为评价指标,与经典方法以及近期方法进行了对比,并单独验证了MRTP的有效性。
3.2.1 UCF101 UCF101[28]是一个由佛罗里达大学创建的动作识别数据集,收集自YouTube。UCF101拥有来自101个动作类别的13 320个视频,在摄像机运动、外观、姿态、比例、视角、背景、照明条件等方面存在很大的差异。101个动作类别中的视频被分成25组,每组可以包含一个动作的4~7个视频。同一组视频可能有一些共同特点,比如相似的背景或类别等。数据集包括人与物体交互、单纯的肢体动作、人与人交互、演奏乐器、体育运动共5大类动作。
3.2.2 AVA AVA数据集[29]来自谷歌实验室,包含430个视频,其中,235个用于训练,64个用于验证,131个用于测试。每个视频有15 min的注释时间,间隔为1 s。尽管很多数据集采用了图像分类的标注机制,即数据的每一个视频片段分配一个标签,但是仍然缺少包含不同动作的多人复杂场景数据集。与其他动作数据集相比,AVA具备每个动作标签都与人更加相关的关键特征。在同一场景中执行不同动作的多人具有不同的标签。AVA的数据源来自不同类型和国家的电影,覆盖大多数的人类行为并且十分贴近实际部署情况。相比于AVA2.1,AVA2.2数据源没有变化,但在标签文件中添加了2.5%的缺失动作标签。
相比于传统的UCF101和HMDB51等数据集,AVA数据集十分具有挑战性,该数据集的数据量是传统数据集的数10倍,场景切换十分频繁,除了相机运动带来的场景连续变化,还出现了电影镜头切换带来的场景突变。相比于主流的Kinetics和Youtube-8M等数据集,AVA数据集使用了多人标注,在更加贴近真实场景的同时,增加了对人的检测和跟踪,人数增多和遮挡问题也造成了包含单个动作的源数据大幅减少。因此,该数据集识别难度远超现有的其他主流数据集。在此之前,文献[8]训练的模型达到了27.1%的mAP精度(由文献[30]进行复现和评估),是该数据集上的最高精度。
3.3 评价指标
3.3.1 准确率 准确率为分类正确的样本数占总样本的比例,公式为
(14)
式中:A为准确率;m为总样本数;f(xi)为第i个样本xi的预测分类结果;yi为xi的实际分类结果;I为判别函数,当样本xi的分类结果与实际结果yi相同时,I(f(xi)=yi)=1,否则I(f(xi)≠yi)=0。
在UCF-101中使用三折交叉验证准确率作为评价指标。将数据集平均分成3份,使用其中1份作为测试数据,其余作为训练数据。在3份数据上重复进行这个训练测试过程,取最后的测试准确率平均值作为结果。
3.3.2 mAP AP是某一类P-R曲线下的面积,mAP则是所有类别P-R曲线下面积的平均值。P-R曲线是以查全率为横坐标、查准率为纵坐标构成的曲线。查全率公式为
(15)
式中:R为查全率;T′为真阳性数,表示交并比大于0.5的检测框数;N′为假阴性数,表示交并比小于0.5的检测框数。查准率公式为
(16)
式中:P为查准率;F为假阳性数,表示漏检的真实检测框的数量。
AVA数据集中存在同一场景多人同时执行动作的情况,因此需要目标检测来区分每个人对应的动作,使用mAP来衡量实验结果。
3.4 实验结果
3.4.1 UCF101实验结果 使用Kinetics-400数据集进行预训练,在预训练模型的基础上对UCF-101数据集的行为识别数据进行训练建模,对UCF-101的3个split进行测试,与同样使用3D卷积的C3D[24]方法和同样使用了双路径结构的TSN[17]、Two-stream I3D[7]以及近期的I3D-LSTM[31]、TesNet[32]进行了准确率的对比,结果如表1所示。可以看出,相比于主流的行为识别方法,本文在同样的数据集上取得了更高的测试精度。

表1 UCF101数据集上不同方法的准确率对比
3.4.2 AVA2.2实验结果 同一视频片段识别结果对比示例如图4所示,该视频片段真实的动作标签为“站立(stand)”和“演奏乐器(play musical instrument)”。基础模型使用了2帧/s的固定帧率对视频进行采样,未加入本文提出的MRTP方法,同样使用ResNet3D作为骨干网络。在使用基础模型和本文提出的MRTP方法对相同输入进行识别时,基础模型无法正确地识别出动作类别,识别出的结果为“坐(sit)”,而本文提出的MRTP方法在同样的输入数据下相比基础模型有更准确的识别结果。
在Kinetics-400和Kinetics-600上进行预训练,得到含有低层基础特征的预训练模型,基于预训练模型对AVA2.2的数据进行训练建模。在测试集上计算交并比阈值为0.5时的mAP精度,ARCN[33]、I3D w/RPN[34]、I3D Tx HighRes方法在AVA2.1上进行了测试,AVA数据集上的mAP精度结果如表2所示。可以看出,相比于ARCN[33]、I3D w/RPN[34]、I3D Tx HighRes[35]、D3D[36]和X3D[30]等行为识别方法,MRTP取得了更高的测试精度。在网络深度相同的情况下,MRTP超过了之前效果最好的SlowFast方法,在加深骨干网络到101层之后,MRTP达到了28.0%的mAP精度,刷新了目前AVA2.2数据集上最高的mAP精度。
3.4.3 ResNet3D骨干网络实验结果 为了证明本文MRTP方法的有效性,固定了骨干网络和预训练模型,在两个数据集上对比了添加MRTP方法前后的评价指标,结果如表3所示。可以看出,相比于基础模型,添加了MRTP方法后在不同的数据集和网络深度都能够实现精度的提升。

(a)基础模型识别结果
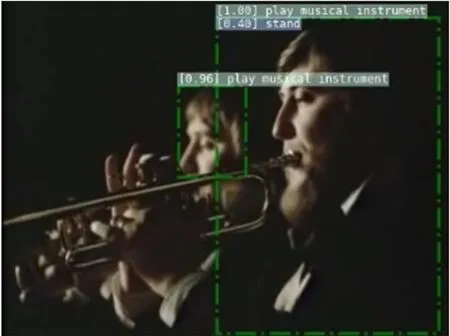
(b)MRTP识别结果

表2 AVA数据集上不同方法的mAP对比
加入MRTP方法前后,部分类别mAP精度对比见表4。可以看出,在基础模型中加入本文提出的MRTP方法后,AVA数据集中大部分行为类别的准确率都有了一定程度的提升,特别是“演奏乐器(play musical instrument)”,“射击(shoot)”以及“游泳(swim)”这3类动作,更是取得了10%以上的提升。原因在于本文使用的时间注意力和动作感知方法都是聚焦于动作的动态信息。这3类动作都是在视频画面中动作变化相对较小的。在所提取的特征中,这类变化较小的动作信息容易被场景、光线、角度变化所干扰,而MRTP在时间维度使用时间注意力聚焦于含有动作变化的视频帧,在通道维度使用特征差分的动作感知聚焦于含有动作信息的通道。这样就使得模型所获取的动态信息大多来自于动作本身,从而在这些动态信息不明显的动作类别上实现mAP精度的提升。

表3 加入MRTP方法前后的对比结果
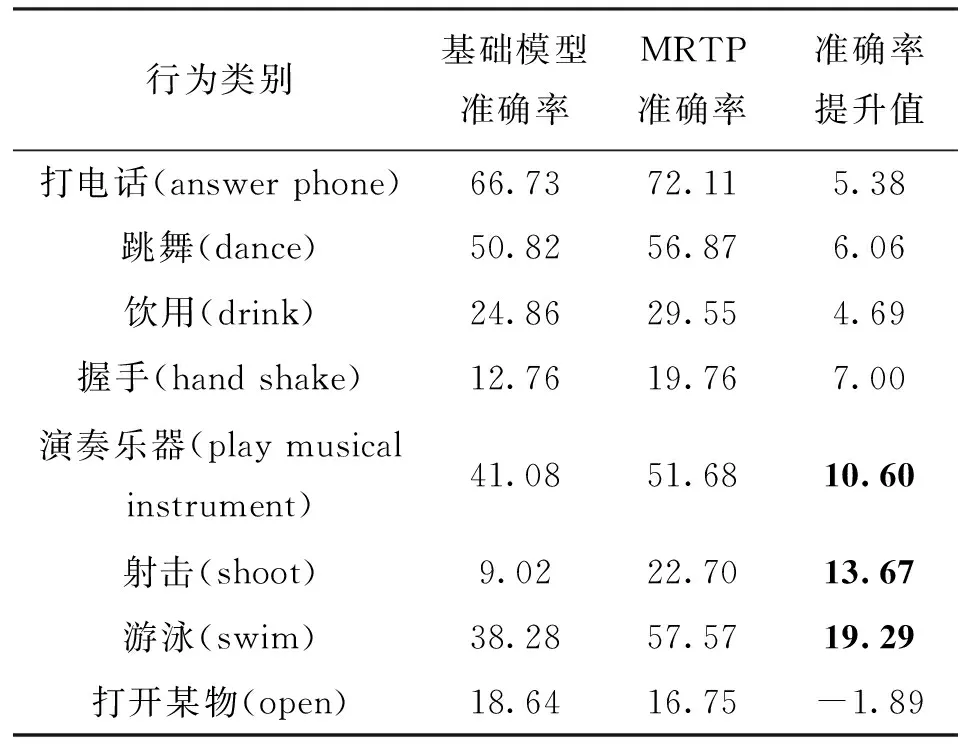
表4 AVA数据集加入MRTP方法前后的部分类别mAP精度对比
3.4.4 复杂度分析 各方法训练出的模型复杂度对比见表5。可以看出:本文提出的MRTP方法在使用ResNet3D-50作为骨干网络时的参数量小于同样使用3D卷积网络的I3D-NL方法[37]的,甚至小于使用2D卷积网络的TSN方法的;同样使用RTX 3090显卡进行模型测试,输入同一个分辨率为640×480像素的测试视频,MRTP达到了110.24帧/s的处理速度,在所有方法中是最优的,虽然使用ResNet3D-101作为骨干网络时模型参数量较大,但是处理速度依然远超使用了光流输入的TSN方法[17]的,也高于使用伪3D卷积的R2+1D[38]方法的。本文方法使用RGB视频作为输入,极大地减少了由于计算光流图带来的时间和计算成本,并且通过在动作路径将特征通道数量减少,使得在动作路径增加的输入视频帧没有带来更大的计算消耗。
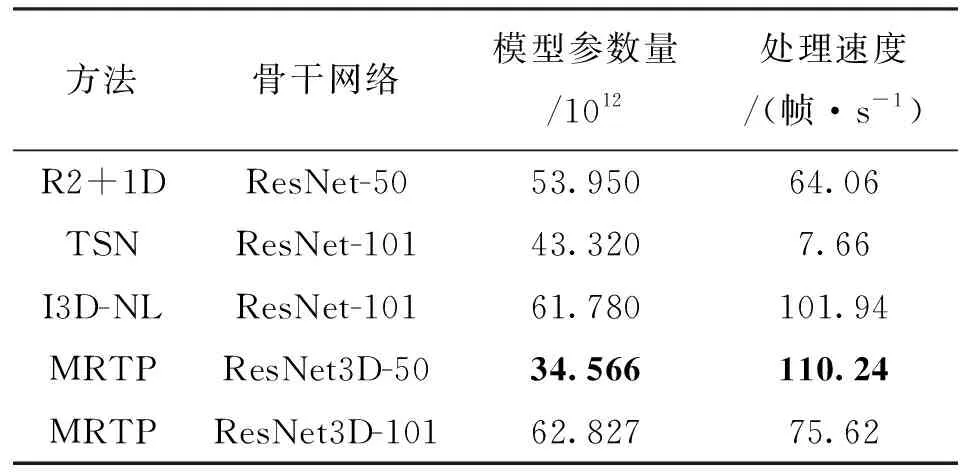
表5 不同方法的模型复杂度对比
4 结 论
针对时空信息分布不均衡以及对长时间跨度信息表征获取难的问题,本文提出了一种时间-动作感知的多尺度时间序列实时行为识别方法MRTP。本文得出的主要结论如下。
(1)提出的网络使用双路径结构,在不同的时间分辨率上对视频进行特征提取,相比于只使用固定帧率的网络,对长时动作能够更好地聚焦于时序信息。
(2)在低帧率空间路径中,使用基于特征差分的动作感知寻找并加强通道动作特征,将变化明显的特征通道作为动作的表征;在高帧率动作路径中加入通道注意力和时间注意力加强关键特征,细化了各个视频帧的重要性度量。
(3)低帧率空间路径基于动作路径中的时间注意力生成的视频帧权重对输入视频进行采样,相比于现有方法的均匀采样,能够提取到识别贡献更大的视频帧;在高帧率动作路径中,基于空间路径动作感知的权重进行通道筛选,保留了动作信息丰富的特征通道。
(4)本文提出的MRTP方法仅使用RGB帧作为输入,通过衡量帧权重,在时序维度上获得了更好的依赖,通过动作感知寻找并加强了通道维度动作特征表征。两个路径的信息交互和指导使得整个网络更加聚焦于动作信息在时间和通道所处的位置。本文方法在公共数据集上表现出良好的识别性能,在AVA2.2数据集上达到了28%的mAP精度,刷新了AVA2.2数据集目前最高的mAP精度。不同环境的实验结果也表明了MRTP良好的鲁棒性。
(5)在未来的工作中,将从时序特征出发,通过特征差分提取更为有效和显式的时序信息表征,并继续探索双路径网络并行分支互相交互的可能性。
