基于AdaBoost机器学习算法的大牛地气田储层流体智能识别
2022-03-14韩玉娇
韩玉娇
(1.页岩油气富集机理与有效开发国家重点实验室, 北京 102206;2.中国石化石油工程技术研究院, 北京 102206)
随着勘探开发对象日益复杂,钻遇复杂储层的概率增大,油(气)水关系复杂程度日益升高,流体准确识别难度不断增大[1–2]。核磁共振测井、成像测井等特殊测井技术能够提供更丰富的参数信息,有利于流体识别,但考虑到勘探成本,特殊测井技术尚不能广泛应用于生产,基于常规测井资料评价流体性质仍然是研究热点[3–5]。此外,复杂储层通常岩性多变、孔隙结构复杂,同时伴有较强的非均质性,导致常规测井数据受多因素影响,其响应特征与流体性质之间存在多解性[5]。对于复杂储层,传统解释方法建立的流体线性识别模型通常识别准确率较低,难以满足生产需要。在实际评价过程中,为提高流体识别的准确率,常需要对大量数据进行深入分析,建立多类图版[5–8],但该方法解释效率低、主观性强,且专业背景门槛高。
近年来,人工智能兴起,为解决此类问题提供了新思路。相比于传统测井评价方法,人工智能具有处理数据信息量大、维度多、重视数据间关联性,可实时高效交互动态分析,同时保留测井专家的解释经验等优势。因此,机器学习逐渐成为储层评价研究的热点[9–11]。周雪晴等人[12]应用双向长短期记忆网络(Bi-LSTM)建立了碳酸盐岩储层流体高精度识别模型。张银德等人[13]结合测井和试采资料,利用支持向量机方法准确识别了油、气和水层。C.Onwuchekwa[14]对比了K临近、随机森林、支持向量机等6种智能算法在尼日尔三角洲296个油藏流体性质评估中的应用效果。王少龙等人[15]实现了BP神经网络在储层流体中的信息自动化识别。周凡等人[16]采用支持向量机算法,建立了基于阵列感应测井数据的流体识别方法。谭茂金等人[17]采用了BP神经网络、概率神经网络、决策树分类器等多种智能算法构建了分类委员会机器和回归委员会机器,实现了储层流体的识别和储层参数的预测。上述方法在不同研究区具有一定的应用效果,但仍存在一定的局限性:在分类较多时,决策树法的错误率较高;神经网络方法中常用的是BP网络,但对于最优参数和最优网络结构的确定尚无十分有效的解决方法,如果训练样本过少,容易出现过拟合问题,导致准确率下降;支持向量机算法在实际应用中,经常遇到不平衡数据集或高精度要求等问题[18]。
因此,为更全面地挖掘学习算法能力,保证稳定的学习性能,笔者以大牛地气田低阻气藏这一具有代表性的复杂储层为研究对象,将AdaBoost(adaptive boosting)算法应用于低阻气层的流体评价中,基于地质成因优化了模型输入参数,对不同基本分类器集成的机器学习算法进行了评价和优选,以提高复杂储层流体识别的准确率和解释效率。
1 方法原理
AdaBoost算法属boosting算法族,其预测精准、算法简单,在诸多领域都有成功应用,尤其在处理分类问题和模式识别方面更为突出[19–21]。其核心思想是通过调整样本分布和弱分类器权值,自动从弱分类器空间中筛选出若干关键弱分类器,集成为一个分类精度高的强分类器,从而打破分类器在已有样本分布上的优势,提高机器学习的泛化能力。
AdaBoost算法迭代通过改变训练集中各样本的权重实现,根据每次训练集中各样本是否分类正确及上次总体分类的准确率,综合确定各样本的权重,将修改过权重的新数据集送给下层分类器进行训练,并将每次训练所得分类器融合起来,形成最终的决策分类器(见图1)。 其具体流程如下:

图1 Adaboost算法基本思路Fig.1 Basic flow of the AdaBoost algorithm
1)确定一个弱学习算法和训练集:{(x1,y1),…,(xn,yn)},x1∈X,y1∈Y={−1,+1},X和Y表示某个域或实例空间。
2)初始化样本训练集的权重分布。赋予各训练样本相同的初始权重,即wi=1/n,则样本集的初始权重分布为:

式中:D1为训练样本集的初始权重;w1,w2,…,wn分别为每一个样本的初始权重;n为训练集样本数量。
3)使用带权重的样本训练集学习,选取使误差率最低的阈值设计基本分类器,得到基本分类器hm(x):
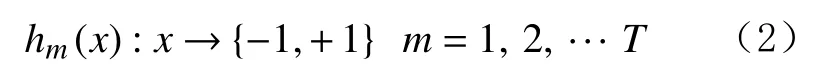
样本训练集的分类误差率为:

4)弱分类器的权重为:

式中:Lr为学习率;R为分类数量。
弱分类器的误差率越低,权重就会越大。
5)更新样本的权重:

其中,ZT为归一化因子,其计算公式为:

采用F条件代表弱分类器的预测结果。如预测值和真实值相同,即预测正确,则F=0,代入式(6)后权重相对变小或不变。如预测值和真实值不同,则预测错误,此时F=1,代入式(6)后权重增大。因此,可根据样本权重判断预测结果的准确性,若样本权重增大,则弱分类器预测错误,此样本需要被其他弱分类器重点关注。
6)将所有弱分类器用下式加权求和:

得到最终分类器为:

式中:T为迭代次数;αm为弱分类器的权重。
2 流体识别难点及主控因素
大牛地气田位于鄂尔多斯盆地伊陕斜坡北部东段,局部构造不发育,气田中高阻气层与低阻气层并存,其中低阻气藏在上古生界广泛发育[22–23]。上古生界典型流体参数见表1。从表1可以看出,水层电阻率分布在14.37~17.92 Ω·m,电阻增大率为0.96~1.23。低阻气层电阻率为 26.84~30.37 Ω·m,电阻增大率为1.79~2.02,其不足水层电阻增大率的3倍。大量试气结果表明,低阻气层也可形成高产,如2 526~2556 m 井段,试气无阻流量为 27 000 m3/d,不产水,显示出良好的产能。

表1 大牛地气田上古生界典型流体参数Table 1 Typical fluid parameters of the Upper Paleozoic in Daniudi Gas Field
上古生界不同流体储层的电阻率和声波时差交会图见图2。由图2可知,该区电性复杂,不同流体测井响应差异不明显,仅依靠传统电阻率方法将低估或遗漏低阻气层,难以准确识别流体。

图2 大牛地气田上古生界流体识别交会图Fig.2 Cross plot for fluid identification of the Upper Paleozoic in Daniudi Gas Field
考虑到训练数据对智能模型的评价效果有较大影响,首先对低阻气层的成因进行分析,选取对流体性质敏感的参数作为训练样本,优化模型输入参数。深入分析相关地质、录井、岩心及试油资料,得出大牛地气田上古生界低阻气层的主要成因为:
1)储层孔隙结构复杂,相比于高阻气层以大孔为主,低阻气层微孔普遍较为发育导致束缚水饱和度增大,气层电阻率降低,形成低阻气层。
2)岩性变细、泥质与黏土所产生的附加导电作用导致形成低阻气层。
3)微裂缝发育导致钻井液滤液侵入并驱替井壁附近岩石中的天然气,使气层电阻率明显降低。
4)储层沉积、成藏中后期地层水活动,造成气、水层矿化度差异,导致形成低阻气层。
3 流体识别模型
3.1 训练集与测试样本
孔隙结构复杂、岩石颗粒粒度小等因素导致束缚水饱和度高,大量微孔导电,这是形成低阻气层的主导因素。因此,将对低阻油藏流体识别敏感的束缚水饱和度参数作为模型输入参数,可提高模型训练效果。对于导电矿物、钻井液侵入等其他低阻成因,尝试利用智能算法从测井曲线中提取敏感参数,实现对流体更好的表征。结合核磁共振、压汞和相渗等资料获得了大牛地气田上古生界束缚水饱和度,观察其与孔隙度的交会图(见图3)可见,采用乘幂法的拟合趋势较符合实际地层含油气趋势,拟合得到的经验公式为:

图3 大牛地气田上古生界束缚水饱和度和孔隙度交会图Fig.3 Cross plot of irreducible water saturation and porosity of the Upper Paleozoic in Daniudi Gas Field

式中:Swi为束缚水饱和度,%;ϕ为孔隙度,%。
采用式(9)计算了研究区26口重点井的束缚水饱和度,选取与流体性质相关性较高的5条测井曲线:自然伽马(GR)、自然电位(SP)、声波时差(AC)、密度(DEN)和深侧向电阻率(RLLD)曲线和1个解释参数(孔隙度(POR))作为模型输入参数,共选取397个层累计10 342个样本点,不同流体储层测井响应特征值分布见表2。

表2 4类储层的常规测井响应值分布Table 2 Distribution of conventional log response eigenvalues of four types of reservoirs
不同测井其特征取值范围不同,如某一特征的方差远大于其他特征的方差,它将会在算法学习中占据主导位置,导致学习器不能按期望学习其他特征,这将导致最后模型收敛速度慢甚至不收敛,因此,需要对此类特征数据进行标准化,处理公式为:

式中:x为特定测井特征值;Z为标准化后的测井特征值;μ为所有特征样本的均值;σ为所有特征样本的标准差。
经处理后的数据符合标准正态分布,即均值为0,标准差为1。综合专家解释结论和试油试采结果,将中高阻气层、低阻气层、含气水层和水层等4类储层分别特征标注为1、2、3和4。选取全部样本的70%作为数据集建立流体识别模型,剩余30%作为验证集验证模型效果。
3.2 储层流体识别模型与实例验证
AdaBoost模型主要对基本分类器进行集成,结合不同基本分类器的原理差异,选取逻辑回归、决策树、支持向量机和人工神经网络4种基本分类器。利用数据集样本对模型不断迭代优化,最终确定各监督模型的最优参数值(见表3)。

表3 4个监督模型的重要参数和最优参数值Table 3 Important parameters and their optimal values of four supervision models
采用预测准确率和F1得分2参数评估算法模型效果。其中F1得分为精确率和召回率的调和平均,当精确率和召回率发生冲突时,可利用F1得分综合评价分类模型的效果。训练结束后,采用验证集数据验证模型效果,结果见图4和表4所示。由图4和表4可知,基于Adaboost算法将弱分类器联级成强分类器,其预测准确率较单一分类器有明显提升。但基本分类器的选取对算法准确率有较大影响,其中以决策树为基本分类器集成的强分类器的预测准确率达86.5%,预测效果最好,F1得分最高。

表4 不同模型的流体识别结果Table 4 Fluid identification results from different models
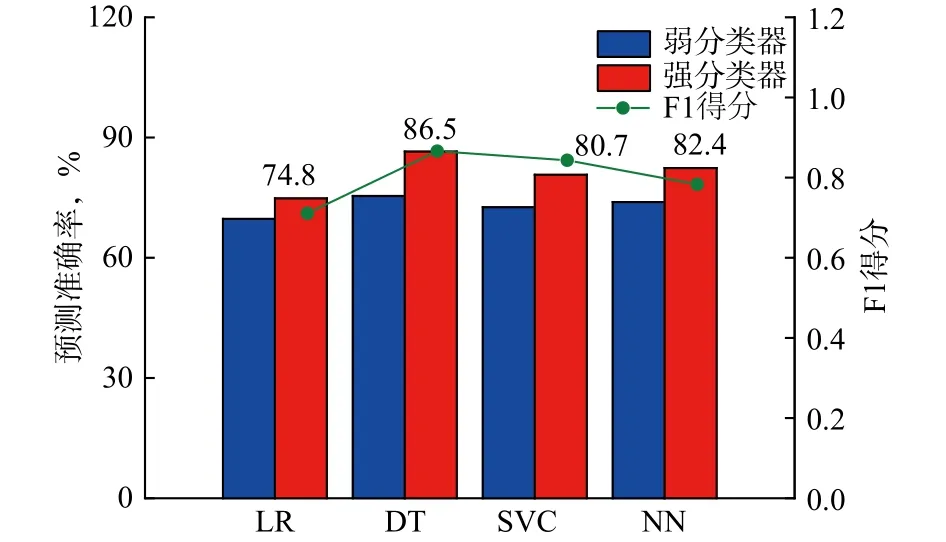
图4 不同模型的预测准确率与F1得分Fig.4 Prediction accuracy and F1 value of different models
以研究区X1井和X2井为例,说明以决策树为基本分类器的强分类器模型(AB-DT)的流体识别结果(见图5)。X1井所示层段孔隙度为8%~15%,上部11号层电阻率均值约为90 Ω·m,为典型高阻气层,智能模型识别和专家结论均为气层;下部井段自然电位呈负异常,电阻率为30~40 Ω·m,为低阻–高孔储层,12号、13号层束缚水饱和度均较高,约70%,智能模型识别结果为低阻气层,试气结果显示不产水,产气量为 14 200 m3/d,与智能模型识别结果一致。X2井所示层段孔隙度为5%~9%,物性相对较差,电阻率均值约 200 Ω·m,该井 2 771.0~2 786.0 m井段多层合试,产气量 5 800 m3/d,产水量 23 000 m3/d。4号、5号层智能模型识别结果为含气水层,与专家解释结论和试油结果均较为一致,模型应用效果较好。

图5 最优智能模型流体识别效果Fig.5 Fluid identification results from the optimal intelligent model
4 结论与建议
1)结合研究区储层流体性质识别难点与主控因素,优化模型输入参数,采用Adaboost迭代算法联级弱分类器,可提高机器学习模型的预测准确度。
2)针对大牛地气田低阻气藏流体识别问题,以决策树作为弱分类器集成的强分类器取得了最佳识别效果,平均识别准确率高达86.5%,展现了机器学习等智能算法在提高储层评价效率和解释符合率方面的潜力。
3)目前测井行业的人工智能主要以数据为驱动,在今后的研究中,除攻关算法外,还应深入分析评价难题的成因机理,优选模型输入参数,同时加强测井知识图谱和专家经验库的建立,注重多源多尺度信息的融合,建立地质成因约束下的智能模型。
