基于GA-SVM的测试用例生成方法研究∗
2022-03-14潘世昊张海波左小凯邓鸿博
潘世昊 张海波 左小凯 邓鸿博
(中国船舶集团有限公司第七○九研究所 武汉 430205)
1 引言
测试用例的设计是软件测试的核心步骤,一个好的测试用例集能够以极小的测试用例数量实现极高的用例覆盖率。近年来,软件的功能日益提高导致其结构越来越复杂,尤其是在进行黑盒测试过程中,将测试用例的输入输出关系对应起来更加困难,并且生成的测试用例集往往数量较大[1]。因此,许多研究人员都为生成覆盖率高数量小的测试用例集进行探索研究[2]。
在进行功能测试前,首先要对规格说明中的需求进行约简整合。然后再通过因果图法、等价类划分法等方法选取得到一组典型的测试数据,减少测试用例的数量[3]。随着机器学习技术和理论得到了巨大的发展,机器学习也已经逐渐应用在了软件测试用例集的生成和优化方面。文献[4]提出利用神经网络和程序变异的测试用例输出预测方法;文献[5]提出了通过Ranking SVM算法,对测试用例集进行排序筛选的方法;文献[6]提出通过聚类算法实现对所需测试用例的自动化识别;文献[7]通过强化学习实现测试用例集的持续优化集成,提升测试效率。
微软公司的pict工具广泛应用于测试用例的生成,它利用组合原理生成覆盖率高数量小的测试用例集,但是生成的测试用例都缺少预期结果。如果人工进行预测结果的填写,将会耗费大量的人力,并且过程枯燥。
针对以上问题,本文采用GA-SVM模型进行测试用例集的自动生成,通过GA算法选取SVM模型参数的最佳值。然后利用pict工具生成两组合的小型输入数据集,将此数据集进行标记后作为SVM模型的训练数据集。最后再次使用pict工具生成更高组合的输入数据集,由SVM模型进行预测其输出数据集。由实验结果分析可知,本文中的方法在测试用例自动生成和模型覆盖率方面,均取得了较好的效果。
2 模型建立与训练
2.1 系统模型的建立
本文选用典型的航班查询服务[10],选取其中的FlightService模块、UserService模块、HotelService模块和RestaService模块。
其中FlightService包含以下三个方面的信息:航班号、出发抵达城市、起飞抵达时间。UserSer⁃vice包含以下两个方面的信息:用户名、密码。Ho⁃telService包含以下信息:剩余房间数。RestaSer⁃vice包含以下信息:剩余餐位数。
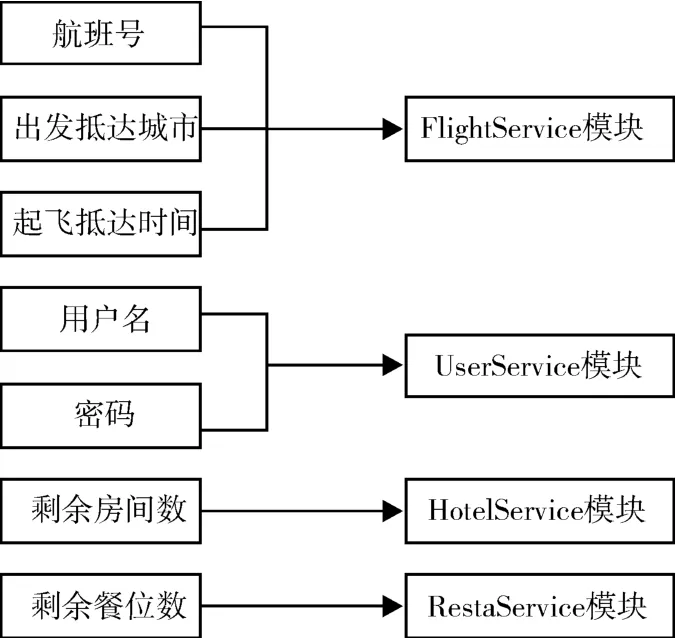
图1 模块图
将上述信息整合到一起,形成了7个输入参数。记为M={M1,M2,M3,M4,M5,M6,M7}将每个参数的取值进行离散化,例如:航班号正确为1,错误为0;出发抵达城市与航班号相符合为1,不符合为0;用户名正确为1,用户名错误为0;密码正确为1,错误为0;起飞抵达时间与航班号符合为1,不符合为0;剩余房间数取值正确为1,错误为0;剩余餐位数取值正确为1,错误为0。
根据每个模块是否能正常调用,设输出参数为Y={Y1,Y2,Y3,Y4}={能否正常调用UserService模块、能否正常调用FlightService模块、能否正常调用HotelService模块、能否正常调用RestaService模块}。Y1,Y2,Y3,Y4的取值为1或0,1表示能正常调用,0表示不能正常调用。
2.2 SVM模型的建立
对于图1中的系统模型分析可知,其训练数据集较小,输入参数为离散型变量,输出参数为两种取值,因此本文选用SVM模型进行训练。SVM模型是一种普遍适用于小数据集的二分类模型,实质是使得两类数据在特征空间中距离最大,所以SVM可以看成一种非线性分类器[11]。该算法相对于Lo⁃gistic回归、决策树、朴素贝叶斯、KNN等具有更高的准确率。
在训练SVM模型的过程中,需要对两个重要的参数c,g进行优化,以获得好的分类结果。c为惩罚参数,c越大,对误分类结果进行的惩罚越大,对误差的容忍性更小;c越小,对误分类的结果进行的惩罚越小,对误差的容忍性更高。但是c过大则会发生过拟合现象,过小则会发生欠拟合现象。g与支持向量的个数有关,g越大,个数越少;g越小,个数越多。但是g设得太大的话,支持向量太多,会使得模型集中作用于支持向量附件,对其他未知数据的分类效果变差;g设得太小,支持向量太少,会使得模型的平滑性变大,无法从训练集中学习到足够的规律,使得训练完成的模型无法正确分类。
PSO算法、GA算法、GridSearch算法是常见的寻优算法,适用于对模型参数的寻找。为了得到较好的c,g值,本文选用UCI数据集中的三个典型数据集 balance_scale、vehicle、iris进行实验分析。对上述数据集按训练集和测试集4:1进行划分,然后分别利用上述三种算法进行参数寻优。得到c,g的最佳参数取值后,将c,g导入到SVM模型中,利用训练集对模型进行训练。训练完成之后,利用划分出来的测试集对模型准确率进行检测。
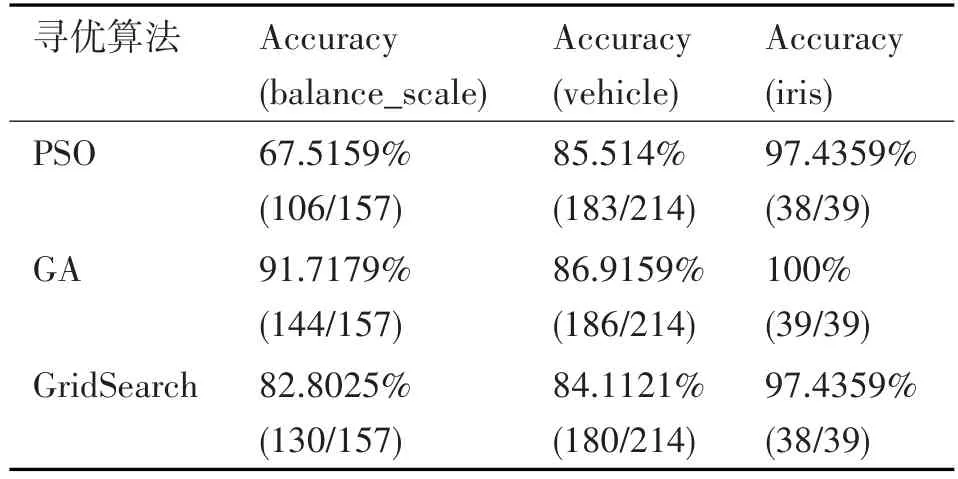
表1 不同寻优算法得到测试集准确率
由表1对比可知,在对SVM模型中的c,g值寻优的算法中,GA算法训练得到的SVM模型分类准确率最高,所以本文采用用GA算法对SVM模型进行寻优。
3 典型用例的设计
对软件系统进行功能测试时,输入参数值和输入参数之间的相互关系会影响输出参数的结果[8]。因此,如何选择输入参数的取值能满足输出结果的全覆盖是一个难题。若通过输入参数组合全覆盖产生测试用例,虽然会使覆盖率变高,但是会使得测试用例集过大,增加软件测试的成本。在实际的功能测试中,可以利用组合测试覆盖准则来平衡覆盖率和成本,产生一个规模小、覆盖率高的测试用例集。
本文利用pict工具实现多参数组合覆盖。所谓多参数组合覆盖是指选定的多个参数的所有取值出现在测试用例集中。而pict的实现原理是利用配对法(Pairwise)对输入参数进行比较排序。排序之后从中挑选分散均匀的样本进行实验,这些样本具有很强的代表性,得到的试验结果等效于大量全面的试验结果。
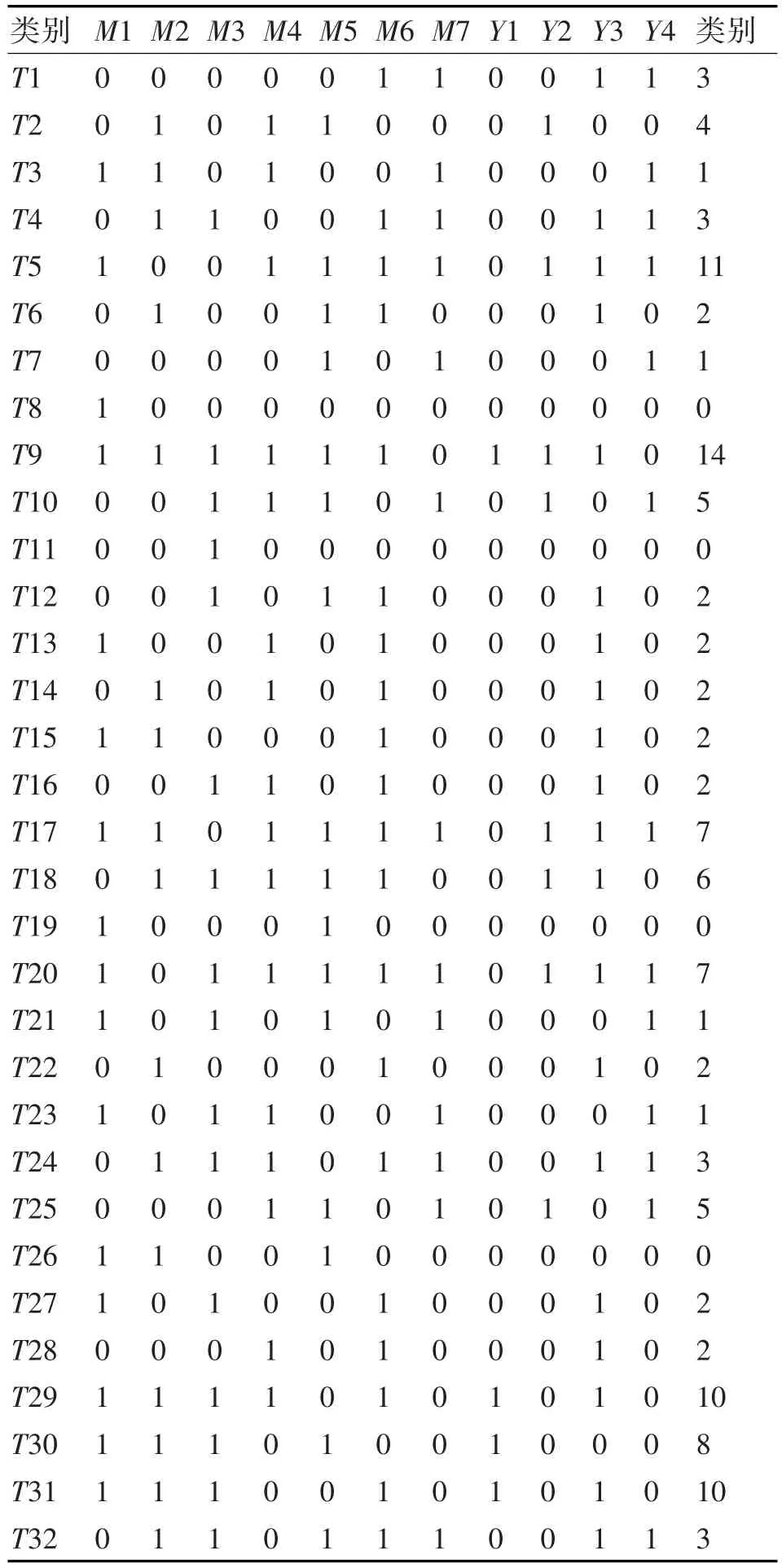
表2 pict生成的典型用例表
经相关研究得出的结论,两参数组合覆盖的测试用例集能检测出大约70%的缺陷,三参数组合覆盖的测试用例集能检测出大约90%的缺陷[9]。若想达到更高的缺陷检测率,则需要更高的参数组合,与此同时测试数据的个数也呈现正比例增长。假设一个软件系统的功能输入域有四个参数A,B,C,D。对于参数A而言,其值域为Da={a1,a2,a3,a4,a5};参数B,其值域为Db={b1,b2,b3,b4};参数C,其值域为Dc={c1,c2,c3};参数D,其值域为Dd={d1,d2}。若对上述输入参数进行全参数覆盖取值,则需要5×4×3×2=240条测试数据。若使用pict工具,自动生成两参数覆盖率的测试数据,则只需要20条;自动生成三参数覆盖率的测试数据,则只需要120条。以pict工具生成的测试数据为基础,设计相应的测试用例集,可以有效地减少测试用例的数量,防止测试数据呈正比例增长的情况。
对系统模型中的参数M分析可知,M1,M2,M3与FlightService密切相关,M4,M5与UserService密切相关,所以将M1,M2,M3设置成三组合参数覆盖,将M4,M5设置成两参数组合覆盖。
利用pict生成了32条数据,然后对这32条数据进行整理,并按照输出输出关系得到其输出参数。分析可知,输出一共有四个参数,每个参数有两个取值,则一共有24=16种取值。而生成的输出参数取值只有12种取值,为达到输出参数全覆盖的要求,手动添加剩余4种取值。将表2和表3的测试用例整合在一起,一共形成36条典型测试用例。这36条测试用例就是SVM模型的小型训练数据集。
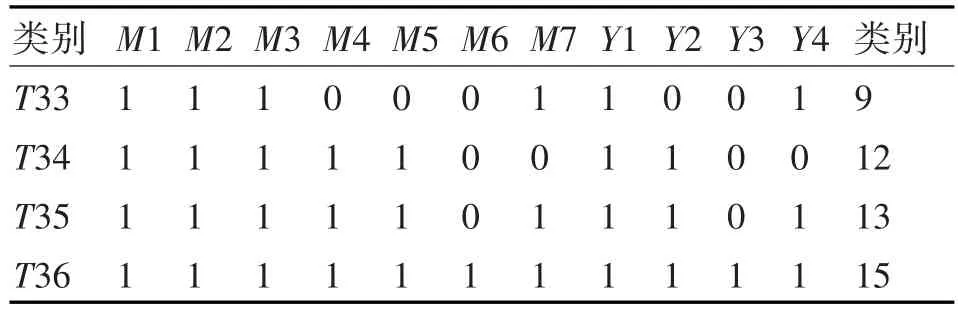
表3 补充用例表
4 实验结果和分析
通过表2和表3中的用例集对GA-SVM模型进行训练,然后利用训练完成后的GA-SVM模型对未知输出结果的样本进行预测。本实验使用台湾大学林智仁教授编写的Libsvm工具箱,SVM模型采用CSCV,RBF核函数类型,GA算法参数寻优。然后对输出参数集中的四个参数分别设计一个GA-SVM模型进行训练,并且每个输出参数为0或1,均为二分类模型。
将表2和表3中的36个数据作为训练集输入到四个GA-SVM模型进行训练,得到四个训练好的GA-SVM模型。然后,利用pict工具生成七参数组合全覆盖的测试数据集,一共生成了128个测试数据集,利用此数据集对四个模型进行准确性测试。

表4 GA-SVM模型分类准确率表
本实验通过对航班查询服务系统的功能进行描述,确定了输入输出关系及输入输出域,然后利用pict工具生成满足特定组合覆盖的输入参数集,同时考虑输入参数和输出参数类别全覆盖,设计出典型的样本集。最后将输入数据集导入到SVM模型中,产生其对应的输出数据。由表4的结果可知,生成的四个SVM模型能准确对输入数据进行分类预测,很好地映射输入输出之间的关系。并且生成预测输出数据,由预测的输出和生成的输入数据组合成覆盖率更高的测试用例集。
5 结语
随着近年来,机器学习领域的发展,将机器学习算法和软件测试用例生成结合起来已经成为一个新的研究方向。尤其是在黑盒测试中,机器学习算法能够对未知输出结果的样本进行较为精准的预测。本文就是通过pict工具生成未知输出结果的样本,然后将未知输出结果的样本输入到训练好的GA-SVM模型中进行分类,生成满足覆盖率要求的测试用例集。此测试用例集数量小,都是由工具自动生成的,具有很好的可维护性。但是针对不同的软件系统,要设计不同的SVM模型来提高准确率。此过程中,需要对常用的几种SVM模型进行对比分析,选取其中准确率最高的SVM模型。未来的工作是如何提高选取模型的效率和准确率,进一步提高生成测试用例集的覆盖率。
