基于Attention-CNN的武器装备语料分类方法∗
2022-03-14王明乾
王明乾 邓 鹏 倪 林
(国防科技大学信息通信学院 西安 710100)
1 引言
武器装备是现代化军事力量的重要组成部分,随着科学技术的不断发展,各类新型武器装备层出不穷[1],武器装备也越来越复杂,功能逐步扩展,其装备类型、型号、性能、参数、作战效能也多种多样。武器装备信息来源更加广泛、形式更加多样、处理更加复杂,其获取、处理、存储对于武器装备的研究论证、开发以及作战运用具有重要作用。过去依靠人工获取、处理武器装备情报信息的方法远远不能满足当其处理大量信息的需求,如何高效管理、挖掘海量的信息资源,使用自动化手段提高武器装备信息处理能力对于为高新武器装备研发、作战运用提供信息保障具有重要意义。
当前我军处理武器装备语料信息主要通过情报人员人工进行,无法满足对当前从互联网海量信息资源中发现、获取、处理、分析信息的需求。因此,利用当前先进的计算机技术,研究高效自动化的武器装备语料发现、获取、分析、处理技术成为当前武器装备语料研究领域的重要方向。国内相关研究工作起步的时间相对比较晚,研究成果也比较零散。最近几年,才逐步出现面向武器装备语料的挖掘技术的相关研究。2015年,傅畅等[2]设计并实现了一个包括采集,处理,存储与检索的web军事情报挖掘模型,提出了一种面向军事情报应用的文本聚类方法。2018年,陈亮[1]利用SVM等算法研究了武器装备语料的分类,建成一个完全面向军事领域并具备相当规模,适合各类电子文本信息应用处理的军事资源语料库;丁君怡等[3]提出基于开源数据的武器装备知识图谱构建方法。2019年,周彬彬等[4]设计了一种基于军语词典的自动扩展的军事语料实体特征提取框架,构建一个较大规模的高质量军事语料库;齐玉东等[5]基于biRNN的不均衡数据集扩展方法对海军军械不均衡文本数据集处理进行了均衡、扩展处理,有效提高了文本分类的性能。2020年,陈奡等[6]基于开源获取的军事百科知识采用K最近邻(KNN)、支持向量机(SVM)、神经网络(RNN)及其他机器学习算法开展军事装备知识分类研究,以支撑军事装备知识图谱的构建和应用;齐玉东等[7]改进了传统的一维卷积神经网络,设计了海军军事文本分类模型。
研究发现,当前武器装备情报研究面临的主要问题如下:1)信息化程度不高,主要工作仍然依靠人工完成,导致处理效率较低,远远不能满足当前海量开源信息处理的需求;2)没有专用的挖掘工具、可视化分析工具,分析工作效果不理想,对情报挖掘能力不足;3)情报知识关联利用不够。情报分类作为武器装备情报搜集完成后的关键一步,其将不同类别的装备情报按类别进行划分,方便研究人员进一步分析研究,从而提高情报分析针对性。因此,如何将武器装备情报快速准确划分到对应类别,对于提升武器装备情报获取、分析效率具有重要意义。本文在抓取互联网开源武器装备语料的基础上,研究了武器装备语料的文本分类工作,为提高我军武器装备情报收集处理能力提供帮助。
2 语料库构建
2.1 构建流程
武器装备语料的内容具有很强的专业性,文本中包含大量武器装备领域专业词汇且篇幅较长,内容繁杂,这给文本分类带来巨大的挑战。针对上述问题,本文首先利用网络爬虫技术、文本预处理技术,从门户网站抓取大量武器装备相关信息,并对武器装备文本信息进了清洗,提取了其对应标签作为样本类别,构建了武器装备领域的语料库,本文的样本是从环球军事网抓取,一共抓取网页5843份,其获取流程如图1所示。

图1 武器装备语料获取流程
本文采用了Scrapy[8]爬虫框架完成了环球军事门户网站的URL获取、调度管理、网页获取、网页解析等功能,并对网页信息进行了去除非法字符、去除链接、去除图片等清洗工作。
2.2 武器装备类别
武器装备语料自动化分类方法是为了辅助研究人员更好地对武器装备情报进行分析,因此本文采用了较为符合研究人员公共认知的武器装备类别,作为研究对象。其是按照武器装备的使用领域对武器装备进行了类别划分,具体分类情况如表1所示。

表1 武器装备分类表
2.3 样本分布
首先对抓取到的武器装备语料分布进行简单分析,其中每类文本的数量如图2所示。
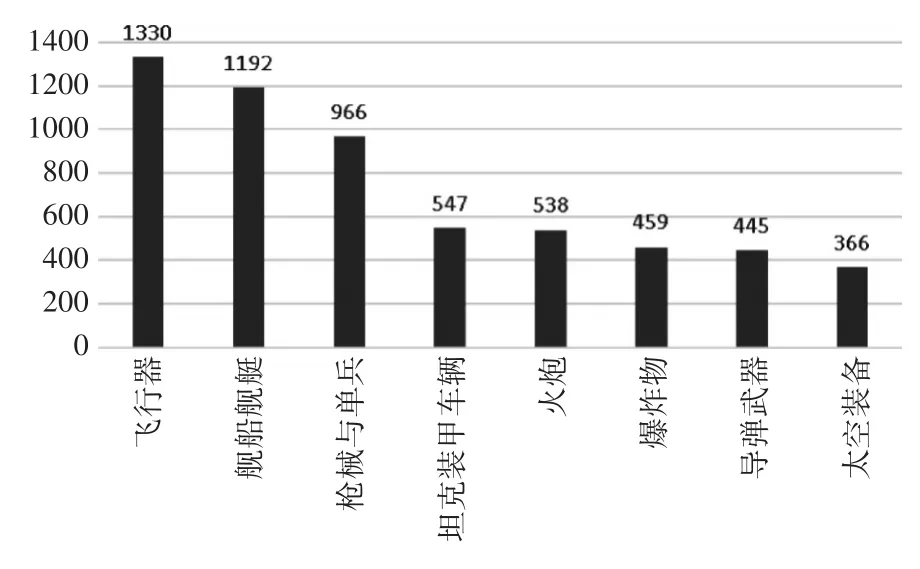
图2 武器装备语料获取流程
采集到的武器装备语料包含9个类别:飞行器、舰船舰艇、枪械与单兵、坦克装甲车辆、火炮、爆炸物、导弹武器、太空装备。每种类别的装备语料的数量差异较大,其中飞行器类的样本数量最多有1330篇,太空装备类样本数量最少366篇,数量差别比较大,样本有较高的不均衡性,对于分类的效果具有一定影响。
2.4 关键词分析
使用文本清理、分词处理武器装备语料之后,使用TFIDF[9]算法计算每个类别词语对于各个类别的重要性,选取其中军事特征明显的词汇按照关键词的重要性排序后,取排序前十的关键词,如表2所示。

表2 每个类别top10军事相关关键词
由表可见,武器装备语料具有专用名词多、时代特征明显、特有的军事表达方式等方面的特点,这对于更好地提取文本特征,实现准确分类会有所帮助。
3 分类模型
本文在数据预处理的基础上,采用深度学习的方法对武器装备语料分类进行了研究,采用的基本神经网络结构包括CNN、GRU、Attention,并对其进行组合、调参,并提出了效果较好的Attention-CNN模型,有效解决了文本特征空间高维度、高稀疏性等问题,取得了较好的分类效果。相关网络结构及改进模型描述如下。
3.1 词嵌入层
使用深度学习模型对文本数据进行学习,首先要将文本数据转换为模型可以处理的表达方式。词嵌入层(Embeding)[10]可以将词语转换为具有语义信息的固定长度向量。其输入为文本序列,输出为向量表示的文本序列s=(w1,w2,… wi,… ωn),其中n为文本序列中单词的个数,wi为第i个单词对应的单词向量。向量的值是在模型训练的过程中训练得到的,包含了文本的词级语义信息。
3.2 输出层
输出层处于模型的最后一层,之前的特征处理层将文本的语义信息抽取完成后,将所有的语义特征通过全连接层组合并转换为输出向量,通过激活函数(softmax)后计算出文本属于各个类别的概率。最后选择模型输出的概率最大的类别作为模型预测的结果。
3.3 双向门循环单元网络
门循环单元 GRU(Gate Recurrent Unit)[11]是循环神经网络(Recurrent Neural Network,RNN)[12]的变体。RNN基于序列结构,利用循环操作整合序列信息,可以对任意长度的序列进行编码。由于RNN只能保留短期记忆,为处理较长序列的依赖问题,产生了一些改进,长短时记忆网络(LSTM)、门循环单元(GRU)等,其利用门机制对序列信息进行管理,从而记忆重要的长期依赖信息。由于RNN是单向传递的,考虑到文本信息不仅依赖前面的文本,也依赖后面的文本,因此提出了双向的循环神经网络。本文使用了双向门循环单元网络(BiGRU)进行了实验,其结构如图3所示。

图3 BiGRU网络结构
前向的 GRUL依次输入“我”、“爱”、“中国”的词嵌入向量得前向句子级特征向量hL。后向的GRUR依次输入“中国”、“爱”、“我”得到后向句子级特征向量hR。最后将前向和后向的句子向量拼接得到作为句子特征向量,并输入全连接层进行分类。
3.4 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)最初用来提取图像特征[13],其由卷积层与池化层组成。Kim等[14]借鉴CNN的思想,将其应用于文本段落的多分类问题,其将段落中单词的词向量拼接成矩阵,选取大小不同的卷积核对其进行信息提取,这样即提取了单词的语义,也考虑了不同长度的上下文信息。池化层包括最大池化、平均池化等方式,用来提取文本序列的全局特征,可以保留重点文本语义,同时减少模型计算量。本文采用了定长子序列最大池化的方法,即将文本特征序列分成等长的子序列并对其进行最大池化,并将结果按原序列顺序拼接起来,从而得到比全局最大池化更丰富的文本信息,其结构如图4所示。

图4 卷积神经网络结构
本文选用了卷积核大小为3、4两个卷积神经网络来提取句子特征,对长度为4的子序列进行最大池化,进行拼接后作为句子特征矩阵,展开为特征向量后输入全连接层进行文本分类。
3.5 注意力机制
CNN只能处理局部上下文特征,而GRU对于关键信息的提取能力不足。注意力机制(Atten⁃tion)[15]可以为文本中每个单词赋予权重,衡量单词的重要程度,即把注意力放到文本的关键信息提取上,弱化不重要的信息,其结构如图5所示。

图5 Attention结构
将输入序列编码Source中元素作为看作Key、Value对,将Target中的元素看作查询Query。At⁃tention机制的计算主要分三个步骤:
1)计算Query和Key的相关性,得到Key对于Value值的权重;
2)对1)中计算的权重进行归一化;
3)使用归一化权重对Value进行加权求和,得到Attention值。
计算过程中相关性可以选择不同的计算方法来计算,本文使用了点积的计算方法,注意力也称为点积注意力。当注意力层输入Source与Target相同时,计算的注意力使句子对自身的注意力,被称为自注意力,本文中Attention模型采用自注意力模型对嵌入层输出的矩阵提取句子级特征矩阵,展开为句子特征向量后,输入全连接层进行分类。
3.6 Attention-CNN模型
本文将CNN与Attention串联构成了Atten⁃tion-CNN(Attention、CNN组合)模型用于武器装备语料分类,模型结构如图6所示。

图6 Attention-CNN网络结构
Attention-CNN模型结合了Attention与CNN的两方面优势,首选使用CNN层对局部的文本上下文特征进行提取,然后使用Attention来提取文本的长序列依赖,两种基本模型结构可以进行很好的互补,从而提高分类效果。
4 实验
为验证基于改进的一维卷积神经网络的文本分类模型的性能,本文基于爬虫抓取的武器装备语料库设计文本分类实验,并使用CNN,LSTM,Atten⁃tion,Attention-CNN(Attention、CNN组合),Att-LSTM(Attention、LSTM组合),BiGRU-CNN(BiGRU、CNN组合)等方法进行对比。使用Python语言采用基于tensorflow框架的keras实现具体模型。
4.1 实验流程
首先对武器装备语料进行预处理,通过文本清洗、分词等手段统一文本格式、构建文本序列。然后选取词频高于5的单词作为特征词典,实现特征降维。然后进行文本表示,使文本变为计算机能够处理的逻辑单位。训练阶段,将训练集文本与相应的标签输入到模型中,通过计算模型损失以及反向传播算法更新模型参数,完成模型训练。测试阶段使用模型对测试集文本的类别进行预测,预测结果与文本实际类别进行对比,使用不同评价指标对其进行分析和评价。
4.2 文本预处理
数据集预处理阶段使用使用正则表达式去除特殊字符,使用jieba分词工具进行分词,截取词频最高的10000个单词构成词典。然后采用填补、截短的方式将文本转换为长度为300的定长序列。
4.3 评价指标
本文选用了分类算法比较经典的评价指标准确度(Precision)、召回率(Recall)和F1-score值,对于单个类别其计算公式如下:

其中,TP为实际为正例,被预测为正例的样本数量。FP为实际为负例,被预测为正例的样本数量。FN为实际为正例,被预测为反例的样本数量。本文使用所有类别标签结果的加权平均后的评价指标值作为衡量模型综合性能的指标。
4.4 模型对比
实验将Attention-CNN模型与其他5种模型进行了对比,其中包括BiGRU、CNN、Attention三种单类别网络结构模型,及BiGRU-CNN、Att-BiGRU两种复合网络结构模型。各模型分类效果对比如表3所示。

表3 各模型分类效果对比
由表可知,在武器装备语料数据集上,深度学习模型均取得了不错的分类效果。其中,Atten⁃tion-CNN模型的分类效果最佳。对于单模型At⁃tention效果最好,CNN次之,BiGRU效果最差,这是由于本文选取文本长度300,Attention对文本长期依赖提取较好,CNN较好地提取了文本的短期依赖,而BiGRU模型在提取长文本的特征时前期输入文本的信息会随着序列长度增加有所丢失,因此效果比另外两个模型略差。对于复合模型,BiG⁃RU-CNN与Att-BiGRU模型效果均优于BiGRU模型,但是分别弱于CNN与Attention模型,分析其原因是由于文本特征经过BiGRU层提取时由于序列较长损失了前期输入的序列信息。Attention-CNN复合模型效果优于所有模型,说明在本文武器装备语料数据集上,Attention和CNN层具有良好的互补左右,首先由CNN根据短期上下文依赖提取语义信息,然后由Attention根据长期依赖及文本的重要性提取语义信息,从而提取出对于分类更全面、关键的语义信息。
5 结语
本论文深入调查了网络爬虫技术、文本分类技术及其在武器装备语料获取处理方面的运用。通过实验分析,利用爬虫技术从互联网上抓取了开源武器装备语料构建了语料库;对语料进行了预处理分析了武器装备语料的特点及其对分类的影响;构建了基于Attention-CNN的面向武器装备语料分类模型,并与多个基准模型进行了对比,验证了模型的效果。本文的研究对于提升我军高效管理、挖掘海量的信息资源,使用自动化手段提高武器装备相关信息处理能力,对高新武器装备研发、作战运用提供信息保障具有重要意义。
