基于地理国情的深度学习分类容错性研究
2022-03-11刘建歌王馨爽
刘建歌,白 穆,王馨爽
(1.自然资源部陕西基础地理信息中心,陕西 西安 710054)
深度学习是目前遥感影像自动解译的主流方法[1-5]。第一次全国地理国情普查[6]以及每年开展的基础性地理国情监测工作,获取了包括地表覆盖分类数据在内的可表征自然地表覆盖情况和地理国情要素的海量数据库[7-8]。地表覆盖数据具有覆盖面积全,精细度高且逐年更新的优势,使得该数据具有作为样本进行遥感影像地物目标深度学习分类的能力和优势,与依照影像进行人工标注的工作相比,成本大大减少。
然而,直接使用地表覆盖数据作为模型训练的样本数据,通常存在一定的误差。为了验证存在误差的地表覆盖数据作为样本进行深度学习模型训练的可行性,研究分别采用人工标注的准确样本和不同量的地表覆盖数据样本进行模型训练,比较和分析了不同样本获得的分类结果的准确性。研究结果表明深度学习分类算法具有一定的容错能力,当样本量足够大时,即使样本数据存在一定的误差,同样能够得到有效的分类结果,从而验证了地表覆盖数据作为深度学习算法训练样本的可行性,一定程度上解决了深度学习中样本获取的难点问题。
1 研究区域与数据源
1.1 研究区域与对象
研究采用高分二号影像,将秦岭山区中的耕地作为提取对象,主要原因为:第一,山区地形复杂,影像质量不好,容易出现阴影、拉花、形变、边界模糊等问题,与平坦地区的地物目标识别相比,自动解译更加具有难度。第二,山区中的耕地情况复杂,例如,受季节和影像的影响较大,直接与地表覆盖数据进行匹配,存在漏标和错标的现象,如图1a所示;存在大面积的耕地、林草的混杂区域,如图1b所示;存在已经没有耕种痕迹的撂荒耕地现象,这种情况应该分类为草地,但部分地表覆盖数据未更新,仍标注为耕地,如图1c所示。以上情况造成地表覆盖数据与基于影像的人工标注结果差异较大,能够有效比较出不同样本之间的分类差异。

图1 地表覆盖数据与人工标注分类结果的差异(高分二号融合影像)
1.2 数据源
1.2.1 卫星影像数据
研究采用的卫星影像数据源为高分二号卫星的全色影像和多光谱影像,其中全色波段的空间分辨率为1.0 m,多光谱的空间分辨率为4.0 m。影像通过正射校正、大气校正后,利用高通滤波变换算法(HPF)将全色与多光谱影像进行融合,获得空间分辨率为1.0 m的融合影像。
其中训练影像采用位于商洛区域,处于植被生长季的高分二号多光谱与全色的融合影像,进行耕地提取的模型训练,影像景号为GF2-1653111-20160620,大小约为35 000×33 000个像素,如图2所示。
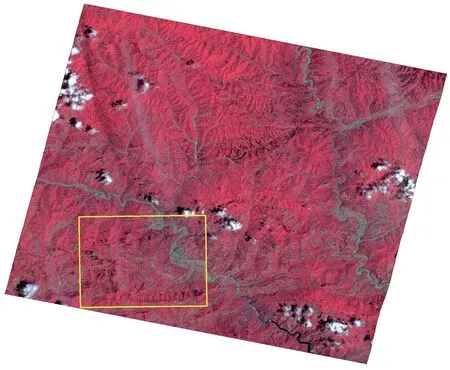
图2 用于模型训练的高分二号融合影像
用于分类和结果分析的影像采用与训练影像同一天拍摄的高分二号多光谱与全色的融合影像,位于与训练影像地表类型相似的商洛区域,影像景号为GF2-1653112-20160620。
1.2.2 地理国情监测数据
我国的测绘部门于2015年完成了第一次全国地理国情普查工作,获取了覆盖全国范围的高精度普查数据。在此基础上,每年开展基础性地理国情监测,形成了丰富的地表覆盖分类数据,反映了地表自然营造物和人工建造物的自然属性。随着地理国情普查工作的完成以及地理国情监测工作的常态化,地理国情监测成果日益丰富,具有客观、精细以及全覆盖等特点。
2 研究方法
研究基于深度学习卷积神经网络,采用在小样本量条件下同样能够获得较好分类结果的Unet模型[9],进行模型训练和影像分类。
首先,比较相同样本量情况下,准确样本和地表覆盖样本之间的差异,研究选择训练影像中约10 000×10 000个像素大小(约0.1景训练影像),且包括城镇与山区的小区域(图2的黄框区域)进行人工标注样本和地表覆盖分类样本的比较,如图3所示。同时计算出小区域人工标注样本与地表覆盖样本之间的误差率约为10%,据此粗略推断训练影像的耕地要素地表覆盖误差率约为10%。

图3 高分二号影像黄框区域影像及样本(红色为耕地,灰色为其他)
其次,比较相同错误率条件下,不同样本量深度学习算法的容错情况,研究分别采用了小区域(黄框区域)对应地表覆盖样本、半景训练影像对应地表覆盖样本以及整景训练影像对应地表覆盖样本训练分类模型。
综上所述,研究基于相同的分类方法,比较和分析四组不同的训练样本获得的分类结果,分别为小区域人工标注样本、小区域地表覆盖样本、半景影像地表覆盖样本以及整景影像地表覆盖样本,进行模型训练,获得对应的分类模型。
为了能够定量描述分类结果的准确性,需要对测试区域的耕地进行人工标注,获得准确分类结果作为参考,因此在测试影像上选择了四块区域对分类结果进行评价,其中2个为城镇区域,耕地特征明显,地块较大;另外2个为山区,耕地分布较为细碎,且撂荒情况严重,地表覆盖样本的误差较大,分类难度更大,如图4所示。

图4 测试用高分二号融合影像以及参考结果
将测试影像的人工标注分类结果作为参考,利用不同样本获得的分类结果计算混淆矩阵[10],得到总体准确率、Kappa值和耕地类别的F1值,对不同样本获得的分类结果进行优劣性评价,以分析深度学习算法的容错性和地表覆盖数据样本的可用性。
混淆矩阵是总结分类模型预测结果的情形分析表,以矩阵的形式将数据集中的分类,按照真实的类别与分类结果的2个标准进行汇总。混淆矩阵包括4个元素:TP(真实值为1,预测值为1的数量);FP(真实值为0,预测值为1的数量);FN(真实值为1,预测值为0的数量)以及TN(预测值为0,标记值为0的数量)。其中,总体准确率表示被正确分类的像元总数与分类影像总像元数的比值;Kappa值为将所有地表真实分类中的像元总数乘以混淆矩阵对角线的和,减去各类真实像元与该类中被分类像元总数之积,除以总像元数的平方减去各类中真实像元总数与该类中被分类像元总数之积对所有类别求和的结果;F1值是分类结果的精确率和召回率的调和平均数,是分类模型精确度的一种有效指标[11],各参数的值均在[0,1]之间,值越大说明结果越好,精度越高,计算方法如公式(1)所示。

3 结果与分析
实验采用的Unet模型输入为4波段、大小为512×512×4的16位图像块,以及对应的512×512的样本数据,并且采用早停法得到训练的迭代次数以获得最佳的分类模型。利用训练好的模型对测试影像进行分类,并对不同样本获得的分类结果进行了定性和定量分析。
3.1 分类结果
如图5所示,不同样本训练模型获得的分类结果差异较大,a、b、c、d分别表示图4中4个区域的分类结果。

图5 采用不同样本训练模型获得的分类结果(红色为耕地区域,灰色为其它)
根据结果可知,由于分类影像与训练影像地表相近、时相相同,因此当采用人工标注的样本时,即便样本量较小,仍能够获得准确率高,边界准确的分类结果。当采用地表覆盖数据做样本时,在小样本量的情况下,分类结果最差,存在较大的误检情况,将大多数撂荒和混杂区误检为耕地,并且边缘处分类结果不清晰,误差较大。在地表覆盖样本误差率不变的情况下,随着样本量的增加,分类结果越好,误检情况减少,且边缘处分类结果越来越清晰,深度学习算法的容错能力越强。
3.2 精度分析
根据第2节中提到的评价方法,利用混淆矩阵将测试区域人工标注的耕地分类结果作为参考(图4所示),分别计算了不同分类结果的准确率、Kappa值以及F1值,如图6所示。

图6 不同样本分类结果的准确性分析
由图6可知,小区域人工标注样本能够获得准确率最高的分类结果,准确率最高能够达到98%,最低也能够达到94%。小区域地表覆盖样本的分类结果准确率最低,与人工标注结果的准确率相差约10%。随着样本量的增加,在地表覆盖样本误差率不变的条件下,地表覆盖样本数据获得的分类结果准确率、Kappa值以及F1值均在逐渐增加,且由图5、6可以看出,采用整景地表覆盖样本能够获得与人工标注样本相似的分类结果。
实验结果表明采用整景影像进行训练时,深度学习算法具有≥10%的容错能力。随着样本量的增加,样本的容错能力在持续增加。当样本的错误率更大时,则需要更多的样本进行模型训练。
4 结语
研究表明深度学习的分类结果与样本的准确性和样本量存在密切关系,通常大量的准确样本能够得到最好的分类结果,但是样本标注工作费时费力,时效低。利用地理国情监测的地表覆盖数据成果,能够在短时间内获取多景影像的样本数据,直接使用地表覆盖数据与训练影像存在一定的误差,但随着样本量的增加,深度学习算法的容错能力越强。因此,当样本量足够大时,同样能够得到有效的分类结果,大大减少了样本获取的成本,提高了地物提取的时效性。研究成果说明了地表覆盖数据作为深度学习分类样本的可行性,为如何更好地使用该数据提供了思路,一定程度上解决了深度学习中样本获取的难点问题。
然而,研究选择的地表场景相对简单,对于复杂场景下深度学习算法的容错能力、不同误差率下需要的样本量差异以及容错能力的限度等方面,还需要进一步的实验和研究。
