QL-STCT:一种SDN 链路故障智能路由收敛方法
2022-03-10李传煌陈泱婷唐晶晶楼佳丽谢仁华方春涛王伟明陈超
李传煌,陈泱婷,唐晶晶,楼佳丽,谢仁华,方春涛,王伟明,陈超
(浙江工商大学信息与电子工程学院(萨塞克斯人工智能学院),浙江 杭州 310018)
0 引言
软件定义网络(SDN,software defined network)通过软件编程的形式定义和控制网络,极大地简化了网络的管理,促进了网络创新和发展。传统IP网络中的路由收敛是指同一网络拓扑下的路由器均需创建路由表,并通过与其他路由器交换拓扑信息以统一网络状态。而在SDN 中,得益于数据平面与控制平面解耦和集中控制的优势,通过控制器监督、控制和管理网络并提供整个底层网络基础设施的实时视图[1],实现高效的路由计算和对数据包的细粒度控制,快速响应链路和设备中发生的任何更改。
尽管SDN 相较于传统网络具有架构上的优势,但是链路故障问题依旧存在。当发生链路故障时,如何进行路由收敛,进行路由收敛操作时又将采用何种路由算法,目前并没有一个能充分发挥SDN的架构优势并受业界广泛接受的方案来专门应对SDN 链路故障时的路由收敛需求,针对SDN的路由收敛问题一直是业界研究的热点[2-3]。
目前主流的SDN 路由算法大多使用最短路径算法[4]。针对SDN 中最短路径算法的缺点,文献[5]提出了一种多指标的链路负载均衡模型,该模型实时监视源节点到目的节点可用路径并采用基于多指标的综合评价算法评估检测到路径的性能,以此获得最优转发路径;文献[6]提出了一种基于SDN多路径并提供服务质量保证的系统(HiQoS,high-quality of service),其利用源节点与目的节点间存在多条路径的特性来保证不同类型流量的QoS,由此保障链路故障发生时能快速恢复链路性能;文献[7]在SDN 下采用改进最短路径算法并结合分离路径算法灵活控制流量。由于网络流量分布的不均衡增加了网络链路拥塞的可能性,文献[8]利用遗传算法搜索SDN 全局网络视图中的优化路径提出了一种基于遗传算法的自适应SDN 路由算法;文献[9]提出了一种基于多路径传输的动态负载均衡路由算法(DRAMP,dynamic routing algorithm based on multipath propagation);文献[10]提出了一种基于SDN的负载均衡多路径路由算法。以上算法均以获得更好的网络性能为目标,充分利用网络中的冗余路径。
近年来,人工智能技术越来越受到研究者的关注,并运用强大的自我学习机制以实现最优。文献[11]提出了一种使用路由引擎在SDN的自治系统间(IAS,inter-autonomous systems)路由协议,并集成人工智能技术,实现灵活、高性能的路由能力,使网络获得良好的可伸缩性和收敛性。为更高效地适应动态网络环境,文献[12]提出了一种基于深度Q学习的路由策略来自动生成最优路由路径,并减少了SDN 控制器策略的人工干预;文献[13]提出了一种新的路由路径优化算法串行粒子群优化(SPSO,serial particle swarm optimization)算法,并采用动态权重矩阵来提高路由性能;文献[14]提出了一种基于强化学习的路由规划算法,能有效地选择最优路径;文献[15]提出了一种强化学习路由算法来解决SDN 在吞吐量和时延方面的流量工程问题,该算法使用网络吞吐量和时延作为奖励函数,经过适当的训练使智能体学习到最佳策略,通过预测网络行为获得最优路由路径。
实验表明,上述路由算法或方案在稳定的物理网络环境中规划全网路径时均具有较好的路由收敛效果,且在一定程度上提升了网络性能[8-15]。而在发生链路故障的网络环境中,采用重新规划全网路径的方式进行路由收敛将极大地消耗路径恢复时间,并影响正常链路中数据的实时转发[5,9,10,12,15]。因此需要更加快速且合适的路由收敛算法来应对链路故障的发生。本文提出了一种SDN 中链路故障时的智能路由收敛方法 Q-Learning 子拓扑收敛技术(QL-STCT,Q-Learning sub topological convergence technique),该方法以实现枢纽节点竞选算法及基于枢纽节点的网络区域划分算法为基础,实现基于区域特征的子拓扑网络规划算法,并运用强化学习技术规划路径,通过仿真SDN 链路故障情景,验证了所提出的强化学习模型对提高SDN 链路故障下恢复路径性能的有效性。
1 系统模型
1.1 符号与定义
本节给出关于系统模型的相关定义。使用无向图G=(V,E)表示网络拓扑结构,其中,V表示所有网络节点的集合,E表示网络拓扑中所有的链路集合。
定义1子拓扑网络。所选定SDN 控制器管理的域内网络G中,由部分节点构建而成的网络,属于域内子拓扑网络,记为L。该网络内嵌于G,是由特定算法组合网络G中部分网络节点与链路形成的集合,即L⊊G,无论何时L均单个存在,并会根据网络环境变化进行变换,且不指代特定的网络节点与链路。
定义2枢纽节点。枢纽节点也称为枢纽交换机,是S DN 域内各子拓扑网络L间实现数据交换的节点。W={wi|i=1,2,…,n}表示枢纽节点的集合,i表示编号,n表示枢纽节点数量,枢纽节点wi位于网络区域i的中心(i∈N+)。
定义3边缘节点。网络G中除wi以外的网络节点,也称为边缘交换机。S={si|i=1,2,…,n}表示边缘节点的集合,i表示边缘节点编号,n表示边缘节点数量,si表示第i个边缘节点(i∈N+)。
定义4枢纽域。由单个枢纽节点wi及部分通过算法筛选出的边缘节点组成的集合,记为ui。U={ui|i=1,2,…,n}表示枢纽域的集合,i表示枢纽域编号,n表示网络中枢纽域的数量,ui表示第i个枢纽域即枢纽域(i i∈N+)。
定义5方向因子。用于描述相对于源节点位置路径转移方向的系数,记为θ。在一条路径中,用θ> 0描述远离源节点的过程,用θ< 0描述靠近源节点的过程,用θ=0描述既不靠近也不远离源节点的过程。
1.2 系统模型介绍
系统模型如图1 所示,在网络拓扑G中存在若干枢纽节点wi、边缘节点si、节点间链路以及由枢纽节点与边缘节点包含链路组成的枢纽域ui。

图1 系统模型
网络节点集合V包含枢纽节点集合W以及边缘节点集合S,即V=(W,S)。网络整体包含多个枢纽域ui形成枢纽域集合U,一个枢纽域ui包含若干个边缘节点si及单个枢纽节点wi,且枢纽域ui间不能完全重叠,即ui≠u j((i≠j) ∩(i,j∈ N+))。从逻辑角度考虑,系统模型由若干个枢纽域连接形成,但实际上枢纽域集合永远不等于系统整体网络拓扑(U≠G)。
在SDN 控制器获得网络全局信息和故障信息后,SDN 智能路由收敛方案步骤描述如下。
步骤1竞选wi。通过控制器从数据平面获取信息V和E,根据枢纽节点竞选算法及E和空间布局考虑,W的产生必须满足W⊊V,即∃si∈V且is∉W。由此竞选出W的元素wi用以构建子拓扑网络L。
步骤2划分枢纽域。根据步骤1的结果,以wi为一个网络枢纽域的核心,采用基于枢纽节点的网络区域划分算法为每个wi选择对应的依附si。当遍历完所有wi,完成网络枢纽域划分,获得枢纽域信息U。
步骤3构建枢纽域特征,制定强化学习行为策略。根据步骤2的结果,以ui为单位构建显性特征,引导强化学习智能体探索网络环境,制定高效的强化学习行为策略用于强化学习模型训练。
步骤4构建子拓扑网络L。完成强化学习模型训练后,运用基于强化学习的子拓扑网络规划算法为wi之间规划路径,实现L的构建,并通过周期性触发强化学习模型重新构建L,保证在一个时间窗口内网络的收敛质量。当L的一条链路恰好为故障链路,同样触发L的重新构建,以保证收敛。
步骤5实现收敛。当L构建成功,路径信息以Q 值表的形式保存。在接收到故障信息后,受故障影响的源节点和目的节点通过查询当前L的路径信息得到收敛路径。控制器向路径中对应的网络节点配置流表项,完成网络的收敛。
2 算法设计
2.1 枢纽节点竞选算法
枢纽节点竞选算法是对SDN 控制器所管理的域内网络G中所有的网络节点进行链路连接数的计算,最终选取链路连接数较大的节点形成枢纽节点集合。网络重要节点相比于其他节点对网络的结构与功能有更大的影响[16]。枢纽节点作为网络区域的中心是其余节点进出子拓扑网络的出入口,在区域网络节点中具有最高影响力,其邻接节点越多,影响范围越大。因此,在网络拓扑中,具有较多邻接节点的网络节点可作为潜力枢纽节点。但由于拓扑中的链路均会发生故障,为使全网络节点能较快地连接并进出收敛网络,枢纽节点应该较均匀地分布于整个网络拓扑中,且过多的枢纽节点不仅会使子拓扑网络规模过大而丧失其原有功能,还会增加收敛时间和操作的流表数量,所以枢纽节点的数量应该加以控制。
因此,选择枢纽节点需要满足以下条件:1) 具有较多邻接网络节点;2) 在网络空间上较均匀分布;3) 控制数量择优选取。根据以上要求,设计算法1,其中,T为网络连接矩阵,node_links[n] 为每个节点的链路连接数记录参数,n为每个节点的标识,hub 为枢纽节点集合,k为对枢纽节点进行计数。
算法1枢纽节点竞选算法


在算法1 中,通过网络拓扑的邻接矩阵计算出每个节点的链路连接数。为控制枢纽节点的数量,应选择具有较大影响性的节点作为枢纽节点,将链路连接数作为主要参考指标。链路连接数越大的节点,影响性越大,相反则影响性越小。因此,算法1需选出具有最高链路连接数的节点作为枢纽节点。
此外,为使枢纽节点均匀分布于网络中,在选出一个具有最高链路连接数的节点作为枢纽节点后,将枢纽节点及其所有的下一跳节点的链路连接数置0,并在剩余节点中挑选下一个枢纽节点,重复上述操作。
由于算法1 中将枢纽节点及其所有下一跳节点的链路连接数置0,当算法运行到拓扑中只剩下链路连接数最大为2的孤岛节点时,该类孤岛节点的下一跳节点也是另一个枢纽节点的下一跳节点。为控制枢纽节点的数量,这类节点将不会作为枢纽节点。
通过算法1,最终输出经过数量控制并均匀分布于网络中的枢纽节点集合W。
2.2 基于枢纽节点的网络区域划分算法
基于枢纽节点的网络区域划分算法是以筛选出的枢纽节点集合为基础,依据网络连接矩阵确定每个枢纽节点的依附节点,最终实现网络区域划分。在网络拓扑中,选择枢纽节点为中心划定枢纽域。当收敛事件发生时,通过事件位置确定其所在枢纽域,并重新规划路径绕开故障区域,完成源区域到目的区域的规划。依据枢纽节点位置对全网络进行合理的粗粒度区域划分,网络收敛时,先在区域尺度上完成路径的粗粒度规划,同时实现故障规避,使网络收敛行为更加高效快捷。
枢纽节点竞选算法中将枢纽节点及其所有下一跳节点的链路连接数置0,即枢纽节点的所有下一跳节点成为该枢纽节点的依附节点,从而组成一个枢纽域,基于枢纽节点的网络区域划分算法如算法2 所示,其中,T表示网络连接矩阵,hub 表示枢纽节点集合,n表示枢纽节点数量,nodes 表示网络节点集合,links 表示链路集合,not_hub 表示非枢纽节点的网络节点集合,area_nodes[n]表示区域网络节点集合,area_links[n] 表示区域链路集合,A[n×n]表示区域连接矩阵,node_belongto_area[n]表示节点依附区域集合。
算法2基于枢纽节点的网络区域划分算法
初始化区域网络节点集合、区域链路集合、区域连接矩阵和节点依附区域集合


算法2 选取枢纽节点的依附节点,实现网络拓扑的粗粒度区域划分,并输出各枢纽域间的连接矩阵A以及交界节点和交界链路信息,以此完成对网络以区域为粒度的拓扑连接状态的详细描述。

基于主动故障恢复思想,不相邻枢纽域间也需要路径规划,所以应提前明确这类枢纽域间的连接方式。由于枢纽域间的连接是双向的,因此只需遍历枢纽域邻接矩阵A的上三角元素。若A[i][j]=0,则进行枢纽域ui与枢纽域uj之间的连接计算,其算法如算法3 所示,其中hs 表示枢纽域ui,hd 表示枢纽域uj,root 表示为根节点。
算法3非邻接区域连接算法

算法3 将枢纽域ui作为树的根节点,并将其邻接的其他枢纽域作为它的子节点,遍历这些子节点,将子节点作为子树的根节点重复上述操作,直至遇到枢纽域uj或者只有祖先节点的网络节点,则结束该次遍历并进入下一次遍历。当完成全部遍历,树的根节点到终端节点为uj的路径即枢纽域ui到枢纽域uj的连接路径,这些路径可能存在多条,并且长短不一。
2.3 基于强化学习的子拓扑网络规划算法
实现枢纽域划分以及明确各个枢纽域之间的连接方式为规划子拓扑网络创造了条件。但由于网络拓扑中各链路剩余带宽随时间动态变化。为应对网络性能的动态变化特性,避免因为网络变化影响收敛路径质量,引入强化学习技术,利用强化学习自我探索环境的优势来应对网络环境的动态性变化,实现网络的高效收敛。
2.3.1基于网络特征的智能体行为策略选择
强化学习中智能体从环境状态到行为动作形成映射关系,使累计的奖励值达到最大。agent 即强化学习中的智能体,在路由规划中,agent 从路由系统中接收当前状态信息和奖励信息,agent 选择的动作是路由系统从智能体接收到的输入。agent 在整个路由规划系统中,必须学习到最优的动作来使自身累计的奖励值达到最大,此时agent 选择的动作即流量的最优路径。
agent的任务是不断在系统中尝试从而学得一个策略[17-18]。使用Q-Learning 算法通过判断相应状态下可选动作的Q值大小判别agent选择策略的好坏。Q-Learning 选择动作的行为称为策略π。策略π根据状态s选择动作a,可由式(2)表示。

当Q 值表达到收敛,策略π选择当前状态下最大Q 值对应的动作来完成从初始状态到目标状态的转移。agent 具有探索和利用2 种选择动作的方式。探索即选择之前未选择过的路径,从而寻找更多的可能性;利用即选择目前已选择过的路径,从而对已知的规划线路进行完善。如何选择策略来平衡探索环境和利用经验之间的关系,会对Q 值的收敛带来严重影响。
ε-贪心策略(ε-greedy policy)基于探索因子ε(ε∈ [0,1])来平衡探索和利用。算法生成随机数σ(σ∈ [0,1]),当σ≤ε时,agent 使用随机策略,通过随机选取动作探索环境以获取经验[19];当σ>ε时,agent 使用贪婪策略利用已获得的经验[20]。ε-贪心策略的表达式为

通过调整探索因子ε的大小,可以影响agent 是探索还是利用环境的倾向。为保证收敛速度,随着训练时间的增加而减小探索因子,即在训练早期更多地探索环境,到训练后期更多地利用环境,使Q 值快速收敛到对应的解之中。但是ε-贪心策略也存在弊端,其无法在探索和利用之间达到一个较好的平衡。
在路径规划领域,agent 探索的环境具有网络特征,如链路长度、链路带宽、时延、跳数等。根据这些网络特征,促进agent 获得有效探索,解决探索和利用的矛盾问题。上述的网络特征,以链路长度为例,如图2(a)中节点6 所示,其作为单源点,使用最短路径算法计算其他节点到该单源点的最短路径,最终将图2(a)转换为图2(b)。

图2 不同链路权值的拓扑及树状结构
从图2(b)可得源节点6 到任意节点的最短路径。将深度(depth)定义为节点n到源节点source 路径中各链路长度之和,即

其中,l(i,i+1)表示路径中第i个节点与第i+1个节点间链路的长度。因为链路长度l为正值,则在一条路径path <n0,n1,…,nsource>中存在的关系为
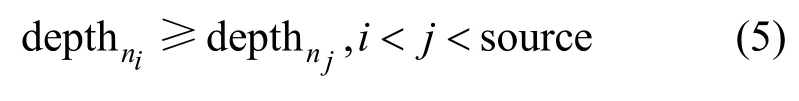
使用强化学习实现最短路径规划,agent的探索趋势是寻找深度越来越小的节点。
在网络中,除了链路长度、链路带宽、时延、跳数等可作为网络特征,各种特征通过权值加成也能作为一个新的特征。基于网络拓扑的特征,可以引导agent 从探索阶段的高随机行为转变成高效探索,以此使学习网络更快地达到收敛。
2.3.2基于区域特征的强化学习训练
将强化学习中的状态s定义为网络拓扑中的节点,将动作a定义为基于状态s选择邻接节点的行为。因为agent 在探索网络拓扑时选定动作是随机的,所以agent的探索路径可能形成一个环路或者agent 在2 个节点间反复振荡等,这些情况都会严重影响模型收敛。同时当拓扑中出现链路故障,进行路由收敛操作时,对于受影响的流重新进行路径规划需要规避故障链路。
给定一个训练模型,如图3 所示,在模型中存在枢纽节点、边缘节点、枢纽域以及链路。使用区域划分所构建的网络特征来引导强化学习agent 进行环境的探索和促进算法模型训练的快速收敛。
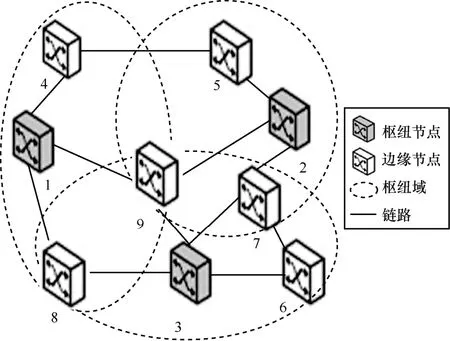
图3 训练模型
根据定义5的规则,得到模型中环路路径每一步的θ情况。统计拓扑中一条路径的每一步θ值,计算得到一条环路中所有转移动作的θ累加值,即
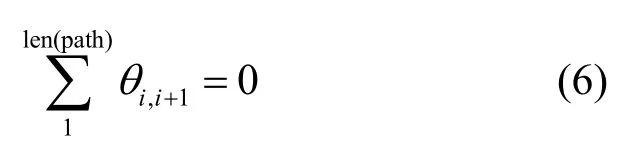
而非环路路径对应的θ值之和与环路路径不同。通过随机选择2 条非环路路径,计算θ值,即
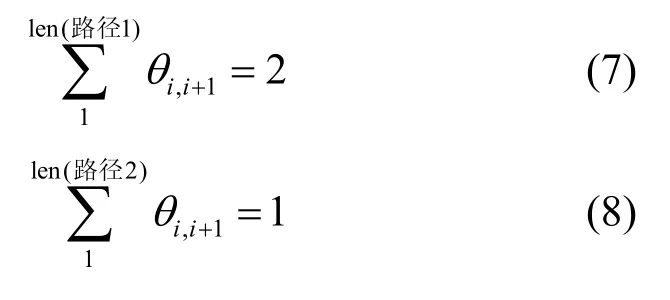
在非环路路径中,路径方向因子的累加都为正值;而在2 个节点中反复振荡的情形下,方向因子双向抵消。故而在非环路路径中当以源节点作为参考点规划出一条至目标节点时其θ累加值为正值的路径。
在强化学习agent 探索环境时,agent 每一次选动作的行为就是选择邻接节点的过程,对应的效果正是远离源节点、靠近源节点或不靠近也不远离源节点。通过对比环路和非环路路径中的θ值集合,发现在环路θ值集合中出现更多的θ值为-1的转移。因此为避免agent 探索路径出现环路,在探索阶段使agent 采取避免θ值为-1的动作。
在agent 探索阶段,如果每一步都选择θ值为非负的动作,可能使模型无法收敛到最优解甚至无法收敛。因为在路径规划时,会将时延、带宽等网络性能参数纳入计算。根据当下网络环境,从源节点到目的节点的路径可能出现绕路现象,但路径整体上的性能是优越的。此时虽然路径中整体的θ累加值为正值,但路径中部分转移的θ值可能存在负值。
在强化学习模型训练过程中,agent 从源节点开始通过探索和利用找到目的节点或者未找到目的节点,但agent 状态转移次数达到设定值的过程称为一个episode。而强化学习达到收敛需要迭代若干个episode。为了避免网络收敛到次优解,Q-Learning前期要进行充分的环境探索,所以在训练的初始阶段,允许agent的探索行为具有高度随机性。随着训练步数的递增,通过增大各链路网络特征的梯度差,agent 能实现高随机探索到高效探索的过渡,在提高收敛速度的同时保证能收敛到最优解。因此,在早期的episode 中允许agent 在探索阶段选择对应θ值为负的动作,而随着episode的不断迭代,减少agent 探索对应θ值为负的动作的概率。以此保证在agent 从环境中充分获得经验的同时提高探索效率,并减少在训练阶段环路的产生。
在该训练模型中,当选定拓扑中的网络节点被作为源节点时,其余节点根据所在枢纽域和源节点的位置关系得到如图4 所示的拓扑分层结构。在图4中,当状态从上层节点转移到下层节点,体现为θ值非负的动作;当状态从下层节点转移到上层节点,体现为θ值为负值的动作。各分层之间的高度差即表示θ的绝对值大小。当高度差取向0,表示各节点几乎在同一层,这时节点与节点之间的转移更少地受分层的影响,即表现为agent的随机探索状态。当不断提高分层之间的高度差时,引导agent向下层探索,即表现为agent的高效探索状态。
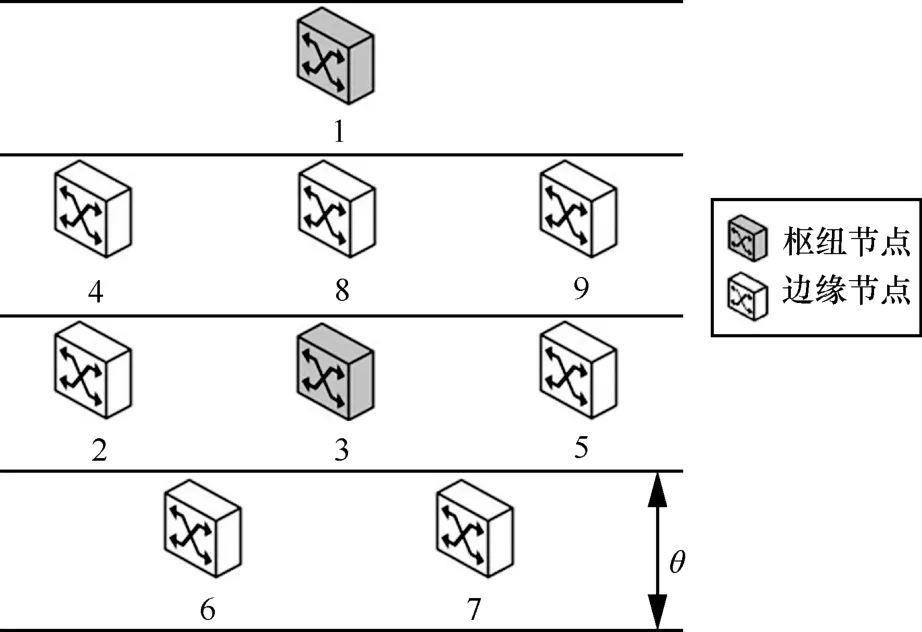
图4 拓扑分层结构
根据上述分析,设定函数为

其中,函数f(t) 根据episode 迭代进度对θ取绝对值;h()θ通过对应动作的状态决定θ的具体取值,如式(10)所示。

此处设定了一个阈值step,当episode 迭代次数小于step,则这些episode 中所有agent 在探索环境时,每一次的可选动作所对应的θ取值都为1,这时agent 采取了随机选择动作策略。当episode 迭代到大于阈值step 时,对于不靠近源节点的动作所对应的θ值会不断增大,而靠近源节点的动作所对应的θ值仍保持在1 不变。随着episode的不断迭代,在可选动作中靠近源节点和不靠近源节点所对应的θ值之间的差值会越来越大。
定义当前状态下所有可选动作的θ值区间D如式(11)所示,区间取值范围为0 到所有当前可选动作对应的θ值之和,区间划分成n份,n为当前可选动作的数量,各子区间的长度为对应动作的θ值。通过在该区间上等概率取值,如式(12)所示,得到η。再通过函数g(D,)η,随机数η所在区间D对应的动作就是agent 探索将要选择的动作。

上述分析研究了强化学习中基于网络区域划分构建的特征来引导agent 在探索阶段的行为。强化学习基于网络区域特征的策略如式(14)所示。

通过h()θ得到当前迭代episode 内agent 在探索阶段选择可选动作对应的θ值,将基于当前状态所对应的所有可选动作的θ值构建区间D。随后通过在区间内等概率取值,由g(D,)η获得对应区间的动作,以此完成探索阶段agent 选择动作的行为。
可见,在将网络进行基于枢纽节点的区域划分后,以枢纽域为单位进行粗粒度的路径规划,通过规避故障所在枢纽域和感知各枢纽域间的连通关系,区域划分可以引导agent 在探索阶段的行为,让其高度的随机行为变得更有方向性,以此来加快强化学习的收敛,最终减少路径计算时间。
2.3.3算法实现
利用网络区域构建的网络特征引导强化学习的探索行为,进而提出基于区域特征的行为策略。使用该策略作为强化学习模型中的行为策略以提高agent 在探索阶段的效率,促进模型收敛。强化学习通过来自环境的奖励信号进行学习,为提高收敛路径的质量,将链路可用带宽、链路时延等指标引入奖励生成中,通过综合性能的奖励反馈,促使模型规划出高性能的路径。奖励反馈通过奖励函数R生成,当agent 发生状态转移,将当前状态s和所选动作a输入函数R,生成奖励来评价该状态转移。
一条链路的带宽由2 个端口的能力决定,通过获取端口流量得到链路流量。OpenFlow 协议中提供机制来获取链路剩余带宽。控制器可通过周期下发Port statistics 消息获得交换机端口的统计信息。从消息格式中发现可获取到收发的包数、字节数以及此次统计收发包数与字节数持续的时间。把2 个不同时间的统计消息的字节数相减,再除以2 个消息差即统计时间差就能得到统计流量速度。如果想得到剩余带宽,则使用端口最大带宽减去当前流量带宽,以此得到剩余带宽。
通过周期性地获取链路剩余带宽,设计奖励函数如式(15)所示,将剩余带宽作为正反馈,跳数作为负反馈。

其中,R为在节点i选择链路到节点j时所获得的奖励,α、β、γ、δ为4 个权衡四部分奖励权值的正值参数,B为所选动作对应链路的剩余带宽,t为对应链路时延,δ(j-d)为激励函数,s_为基于状态s在选择动作a后所转移的状态。如果s_为目的节点,则表示agent 完成一次episode的训练,给予1的奖励。通过此类设置鼓励agent 寻找目标。当agent 每走一步给-1 奖励,用来控制源节点与目的节点间路径的长度。
为了保障当发生链路故障时,网络能迅速地完成故障恢复,降低故障影响,本节提出的基于强化学习的子拓扑网络规划算法仍是一种基于主动式故障恢复的思想。同时为保证网络收敛时的路由质量,设置了强化学习模型的周期性训练。当一个网络周期结束,SDN 控制器通过重新获取当前网络的链路可用带宽、链路时延参数来构建新的强化学习环境。强化学习模型基于新的环境进行训练,规划出新的子拓扑网络。在该周期内发生的链路故障由该子拓扑网络负责网络恢复操作,并在完成故障恢复后,使网络进入新的周期,具体算法如算法4 所示。其中,A为区域连接矩阵,hub 为枢纽节点集合,TB为网络链路剩余带宽矩阵,TD为网络链路时延矩阵,episode 为迭代次数,time 为单次最大训练次数,g(v,e)为初始化子网络,πh(s)为基于区域特征的行为策略。
算法4基于强化学习的子拓扑网络规划算法

通过算法4 可以实现子拓扑网络的构建,这为实现高效的网络收敛提供支持。
3 仿真结果与分析
3.1 强化学习模型收敛测量
本文实验系统环境为Ubuntu 16.04,采用Ryu控制器与Mininet 对QL-STCT 方案的有效性进行测试。在强化学习模型中,agent 探索的环境是SDN控制器通过集中化控制从数据转发平面获取网络全局视图所构建的。将agent 探索环境的情景拟合成数据包在网络拓扑中转发的情景并定义强化学习的状态和动作。
状态。在网络拓扑中数据包的空间位置定义为状态,即一个交换机对应一个状态。本文中状态集合就是交换机集合,即S=[s1,s2,s3,…,s16],其中s1~s16表示本文实验拓扑中的16台OpenFlow交换机,如图5 所示。

图5 实验拓扑
动作。在网络拓扑中,数据包从一个交换机转发到另一个交换机的过程定义为强化学习中的动作。交换机只能将数据包发送到它的邻接交换机,强化学习模型中的状态对应的动作集合如式(16)所示。

其中,T为本实验中网络拓扑的连接矩阵,如式(17)所示。

强化学习规划路径时,能够综合多个网络性能参数纳入考量,具体通过设置奖励函数来实现。在式(15)中,将链路可用带宽、链路时延作为规划路径的重要考虑参数。在强化学习模型迭代训练中,对于每一次的episode,为了鼓励agent 找到目的节点并控制agent 探索路径的长度,当找到目的节点则给予正向反馈,当选择动作对应的节点不是目的节点则给予负反馈。因为侧重不同,所以为4 个参数设定不同的权值。由于规划备用路径时关注链路带宽性能和链路时延,设置α=0.4,β=0.3,γ=0.1,δ=0.2。
由强化学习算法Q-Learning 算法可知,Q 值更新受到学习率α和折扣率γ影响。学习率α越小,保留训练的效果就越多,但模型的收敛速度将会越慢,且模型可能会出现过拟合;反之,学习率α越大,则训练的效果保留的就越少,但当学习率α过大时,模型容易出现振荡现象。折扣率γ越大,则未来奖励衰减越小,表明agent 更关心长期奖励,反之表明agent 更关心短期奖励。当折扣率γ=0,则模型将学习不到未来的任何奖励信息,只关注当前状态的奖励;当折扣率γ≥1,则奖励会因为不断累加且没有衰减造成算法无法收敛。故α γ、取值范围都为(0,1)。本文将强化学习模型中更新函数的学习率α设置为0.9,折扣率γ设置为0.8。
在Q-Learning 中,算法收敛就是Q 现实和Q估计逐渐靠近的过程。通过Q 值更新函数中每次更新所有状态的误差和的计算体现强化学习的收敛过程。在agent 每次做出决策选择动作进行状态转移时,Q 值函数评价该次行为策略,产生的误差值如式(18)所示。

通过对一次episode 中所有的误差值累加,如式(19)所示,ei大小可以定量地反映第i次episode训练情况。随着迭代次数的增加,ei趋于0,表示每次迭代训练中agent的策略变得稳定,即Q 现实与Q 估计趋于同一值,算法达到收敛状态。

本文实验通过统计算法训练过程中的ei,呈现算法的收敛过程。将基于网络区域特征的行为策略运用于强化学习模型训练中,并与使用ε-贪心策略的模型训练进行对比。实验结果如图6 所示。

图6 强化学习收敛过程
实验结果展示算法前1 000 次训练的误差值,由此表明使用网络区域特征的行为策略运用于强化学习模型训练和使用ε-贪心策略算法都具有不错的收敛能力。由图6 可知,基于网络区域特征的行为策略算法能更快地实现收敛,且收敛后算法的波动值小于ε-贪心策略。
3.2 路由收敛时间测量
本文实验通过查询服务器端主机的传输性能报告测量链路故障恢复时间,实验过程中运用了3 种不同的路由收敛方案进行比较。方案1 为QL-STCT 方法;方案2 为快速重路由技术(FRT,fast re-routing technique)方案[21];方案3 为只运用子拓扑网络规划算法而没有集成强化学习技术(STCT)方案。在出现丢包现象的时间间隔内,设置传输时间间隔为1 s,统计丢包数量loss 和发送数据包数量total,通过式(20)计算丢包数量和发送数据包总量的占比。

链路故障恢复时间测量如图7 所示,通过引入强化学习模型,提高了网络整体故障恢复的性能。由图7 可知,使用QL-STCT 方法进行故障恢复操作,共测量50 次故障恢复时间,平均恢复时延为21.6 ms,相较于STCT 方案的27.22 ms的平均恢复时延,在时延指标上具有进一步的优化;相较于FRT 方案更具有明显的优势。产生该结果是因为强化学习模块提高了备用路径的质量,进而缩短了整体的故障恢复时间。
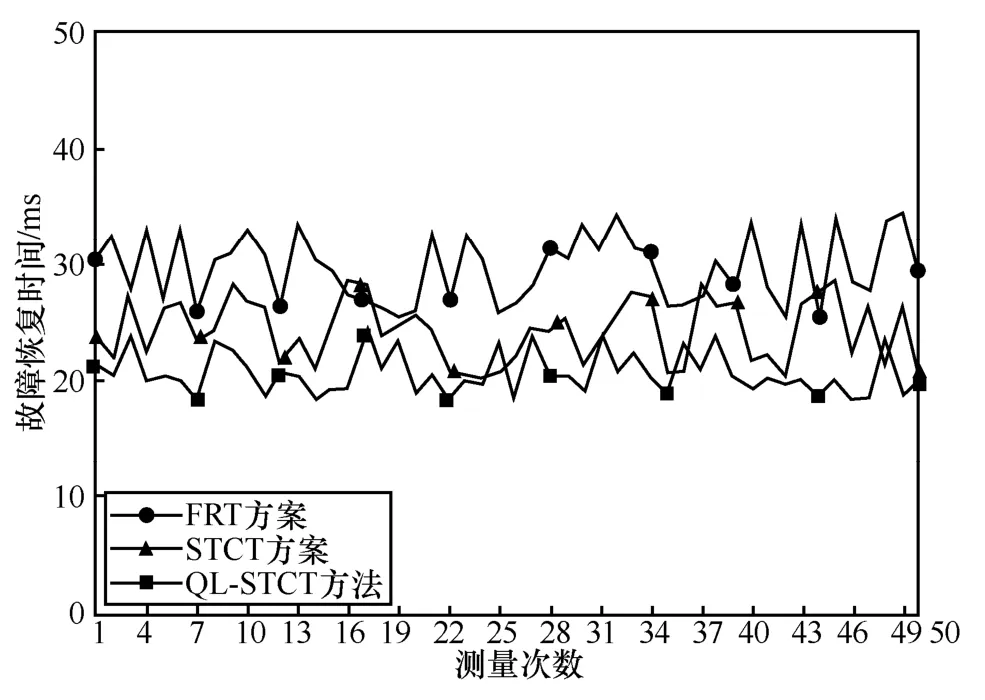
图7 链路故障恢复时间测量
当多条链路发生故障时,QL-STCT 方法可同时进行多流的收敛操作,由于采用了构建子拓扑网络的方式进行路由收敛,链路故障恢复时间会保持在一个较稳定的范围内:链路故障不影响子拓扑网络链路时,受影响的网络节点都会将数据包转发给对应枢纽域内的枢纽节点,最终完成数据流的转发;当链路故障影响到子拓扑网络的链路时,QL-STCT 方法会重新构建子拓扑网络,以确保子拓扑网络性能。
3.3 网络带宽利用率测量
为验证QL-STCT 方法提高链路带宽利用率的可行性,本文实验仍利用Iperf 测量客户端主机指定的发送带宽和服务器端主机实际接收的带宽大小。当网络性能无法满足数据流的转发要求,网络出现拥塞和丢包现象时,服务器端接收到的数据量少于客户机端发送的数据量。此处定义流的带宽利用率为服务端主机接收带宽与客户端主机发送带宽的比值,则网络的平均带宽利用率表达式为
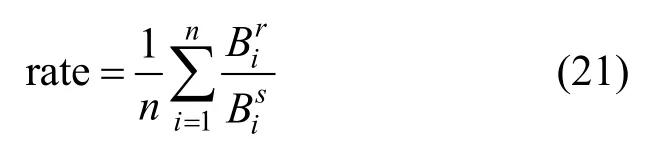
其中,n表示网络中数据流总条数,表示数据流i对应客户端主机发送带宽大小,表示数据流i对应服务端主机接收的带宽大小。通过对网络中所有流的带宽利用率取平均值,得到网络的平均带宽利用率rate。
实验中为测试故障恢复后的网络性能,使用Iperf 测量源主机的流量发送速率以及对应的目标主机的接收速率。依次增大源主机的流量发送速率,从0.5 Mbit/s 到5 Mbit/s 共测试10 组数据,计算网络的平均带宽利用率,实验结果如图8 所示。由图8 可知,随着主机流量发送速率的不断增大,3 种方案中的网络平均带宽利用率均出现不同程度的下降。但整体而言QL-STCT 方法具有更好的表现。当发送速率达到5 Mbit/s 时,QL-STCT 方法的网络平均带宽利用率是FRT 方案的近4 倍。实验表明,基于SDN 链路故障智能路由收敛方法能够很好地保障备用路径的性能。由于QL-STCT 方法通过设置子拓扑网络将备用路径进行聚合来减少流表空间的消耗,对现实网络的影响较小,即便是更大的网络流量环境也具有很好的适应性。

图8 不同发送速率下网络平均带宽利用率
4 结束语
结合强化学习和子拓扑网络,并利用强化学习自我探索环境的特性动态规划子拓扑网络,保障备用路径性能,提出了一种SDN 链路故障智能路由收敛方法。首先使用枢纽节点竞选算法筛选拓扑结构中的枢纽节点,根据枢纽节点进行区域划分,介绍基于网络特征的强化学习行为策略;然后将该策略用于强化学习模型训练,介绍基于强化学习的链路故障恢复算法;最后通过在仿真实验中模拟链路故障恢复来检验该算法的有效性。仿真结果表明,所提出的路由收敛算法通过周期性的训练强化学习模型,规划备用路径,保障备用路径的性能,有效地提升了网络收敛速度,保障了网络在出现故障恢复后的整体性能。后续工作将在子拓扑网络规划算法中进一步研究引入深度强化学习,以实现更大网络规模链路故障发生时高效的智能路由收敛,以改善由于Q 值表增大而导致数据查找和存储带来的资源消耗等问题,提升算法性能。
