面向工程数据检索的ElasticSearch索引优化策略
2022-03-10许贤慧王淑营曾文驱
许贤慧,王淑营,曾文驱
(1.西南交通大学计算机与人工智能学院,四川 成都 611731; 2.广州地铁设计研究院股份有限公司,广州 广东 510010)
0 引 言
各生产制造行业产生的工程数据以不同的形式存在,常见的有文档、图纸以及三维模型等,对于这种大量且异构的数据的检索是工程领域亟待解决的问题,传统的关系型数据库在索引存储结构方面存在限制,对于结构化的数据可以进行较好的存储及检索,但是对于非结构化的数据无法进行有效存储,并且传统关系型数据库对于海量数据检索效率低[1],基于ElasticSearch(简称ES)[2-4]开源搜分布式全文搜索引擎应运而生。ES底层基于Lucene[5-8]构建,其底层为文本数据的每一个词都建立倒排索引[9],该索引记录该词在文章中出现的次数以及位置等信息,在进行检索时可直接通过检索词与事先倒排索引进行匹配查找,极大地提高了文本数据检索的效率。
ES以其查询亿级数据能够毫秒级返回的强大数据检索能力被广泛运用于工程数据检索领域。如文献[10]提出利用HDFS与ES结合来对医疗保健部门产生的大量HL7格式的数据进行存储以及检索,解决基于多个RDBMS系统无法近实时存储及检索的问题;文献[11]利用HDFS实现对图书馆文献资源的海量存储,并利用ES实现对资源的检索,提高了文献检索的效能;文献[12]在CouchDB和ElasticSearch引擎的基础上,设计了一种高性能的化学结构和数据搜索引擎DCAIKU,DCAIKU将Ehemical结构相似性搜索问题转换为通用文本搜索;文献[13]基于Elasticsearch技术,采用元数据的管理方法,设计了一套气象数据管理检索系统。
虽然ES已经被广泛运用于各个领域,但是对其底层进行深入研究后发现,其在性能方面还有提升的空间。当前对于ES的优化策略主要在对排序算法进行改进以及对索引结构进行优化方面。对于排序算法的改进,文献[14]提出了一种基于ElasticSearch分布式搜索引擎文本相似度比对优化方案,实现了语义匹配、近义词匹配、段落替换匹配;文献[15]提出了一种新的基于Lucene函数机制的水文时间序列相似度搜索方法,提高了数据的查询效率;对于索引结构优化方面,文献[16]提出了一种基于哈希的优化方法来存储倒排索引的输出,从而可以将搜索时间的复杂度从O(n)降到O(1);文献[17]提出一种基于倒排索引的空间网格索引查询方法,该方法与传统方法相比查询速度可以提升1倍。
以上对于ES性能改进的研究中,较少有从ES索引建立、索引分片以及索引段合并方面来对ES进行改进的策略。基于此,本文首先在索引创建时对ES的分词器进行修改并配置自定义词典,其次提出基于集群节点性能与索引数据量大小的索引分片策略,最后根据节点性能来选择合适的段合并时机,通过以上优化来提升ES的性能。
1 技术基础
本文提出的相关策略是对ES的索引创建、索引分片以及索引段合并方面进行改进,因此先对ES进行一个简单的介绍。ES是基于Lucene构建的分布式全文智能检索引擎,具有近实时、高性能、分布式和零配置的优点。ES中有几个基本的概念,例如集群、节点、索引、分片等。
1)集群和节点。ES本质上是一个分布式数据库,单个的ES实例称为一个节点,多个节点构成集群,每个节点可以通过集群名字来自动识别同一个集群中的其他节点。ES内部通过选举机制选举出一个节点作为master节点来对集群进行管理,该节点对外透明,对于集群外部来说,和任何一个节点通信的代价都是相同的。
2)索引。ES的逻辑存储,索引中包含一堆具有相似结构的文档数据,每个索引包含一个或多个分片。
3)分片。ES将索引切分为多个分片,通过将分片放置到ES集群中的不同节点上来实现分布式索引。
ES作为一个分布式的搜索引擎可以和传统的关系型数据库进行对比学习,二者有许多概念非常相似,如表1所示,其中类型概念在ES7.x中不再使用。

表1 ES与传统关系型数据库的对比
与关系数据库相似,ES为存储数据创建索引,每个索引由一个或多个物理分片构成。ES数据写入时会根据路由公式将索引数据和文档数据分散地写入索引的各个分片中,每个分片都可以单独地被检索。通常情况下,每个主分片还会有一个或多个副本分片,主分片和副本分片分布在集群中的不同节点上,ES分片在ES集群中的存放情况如图1所示。
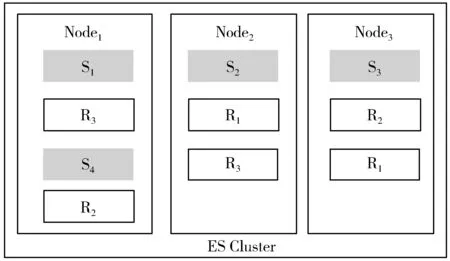
图1 分片在ES集群中的分布图
ES的每个主分片或副本分片都是一个Lucenue索引。Lucenue索引是是由多个索引段组成的,每个索引段都可以独立存储数据也可以独立地被检索。ES底层默认每间隔1 s将buffer中的数据refresh到一个新的段文件中,因此该过程会产生大量的小的段文件。
2 ES索引优化
2.1 索引创建
工程数据以不同的形式存在,包括结构化数据和非结构化数据2大类。非结构化数据包括文档、图纸、三维模型等,这类数据不能采用传统的关系型数据库进行存储,通常存储在分布式文件系统(Distributed File System, DFS)[18-20]中。非结构化的工程数据除了其数据本身外,还包括工程的元数据信息。元数据记录了工程数据相关的描述信息,如:数据的来源、数据产生的阶段以及工程数据的存储位置等信息。
利用ES进行工程数据查询时,需要先为工程数据创建索引,对于非文本类的工程数据使用其元数据来创建索引,对于文本类数据需要对文本数据进行分词来创建索引。工程数据的索引创建过程如图2所示。

图2 工程数据索引创建流程图
在创建索引的过程中需要进行分词得到词元,利用词元来建立倒排索引,分词的效果会直接影响用户查询的结果。表2中列出,部分常用ES默认的分词器。
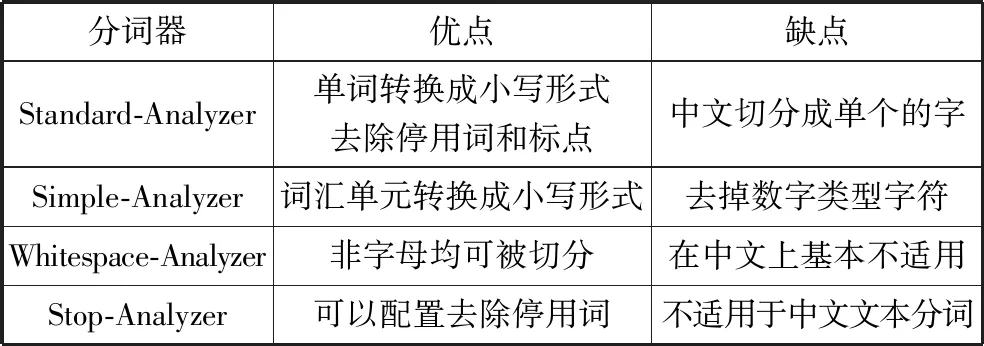
表2 ES常用默认分词器
以上分词器都有一定的弊端,并且大多都不支持对中文文本进行分词,会将中文文本切分成单个的字,因此本文利用IK分词器[21]替换ES原有的分词器。IK分词器是一款基于词典和规则的中文分词器,它提供了2种分词模式:ik_smart和ik_max_word。ik_smart会对文本进行最粗粒度拆分,ik_max_word会将文本做最细粒度划分。显然,在进行搜索时,拆分的粒度越细效果越好,但是对应的索引数据量也会增多,经过综合考虑,本文采用粗粒度进行分词。
1)修改分词器。
①下载与ES版本相同的分词器安装包elasticsearch-analysis-ik-7.6.1.zip。
②将上述安装包解压,并将文件复制到ES安装目录/plugins/ik下。
③重启ES,查看ES是否启动成功,启动成功表示分词器安装成功。
④IK分词器安装成功后,就可以在数据写入时指定分词器使用IK分词器,并且指定其分词算法为ik_smart算法,相关配置如下:
"analysis":{
"analyzer":{
"ik":{
"tokenizer":"ik_smart"
}}}
2)自定义分词词典以及停止词词典。
工程数据来自不同的领域,各领域会包含许多领域专有名词。对于这些专有名词,IK分词器可能不能识别,会将这些专有名词切分,因此可以为IK分词器配置自定义分词词典来保证专有名词不被切分,并且文档中的“的”“得”“地”等停止词对于查询没有实际意义。同时为IK分词器配置停止词词典来去除停止词,去除停止词可以减少索引的数据量,也可以提升查询的精确度。
自定义分词词典以及停止词词典均在ES安装于目录/plugins/ik/config下,IKAnalyzer.cfg.xml中的properties标签中做如下配置:
①
②
配置完成后在config目录下添加自定义的词典就配置成功了。
2.2 索引分片优化
ES默认为每个索引都创建5个主分片,主分片数量一旦确定就不能在更改,并且每个主分片都包含一个副本分片,各分片均匀地分布在ES集群的各个节点上。在对工程数据创建索引时,并不是对所有的工程数据只创建一个索引,而是需要根据检索需求为不同种类或内容的工程数据分别创建索引。比如:工程数据可能分为工程开发文档、图纸以及三维模型等不同种类的数据。在利用ES进行数据检索的过程中可分别为每个种类的数据创建一个索引,有的索引(图纸数据)涉及的数据量可能较少,如果在创建索引时还是设置为默认的5个分片,那么数据查询时就会花费大量的时间在建立请求、数据传输以及等待响应方面,并且当集群节点个数较少,但是分片数量较多时,同一索引将会有多个分片在同一节点上,此时也会影响数据写入与查询的性能。因此应根据数据量的大小以及集群节点的个数来为索引设计合适的分片。基于此,本文提出一种基于数据量大小以及集群节点个数的索引分片策略。为了更好地描述该策略,表3对公式中要用到的符号作出定义。

表3 分片相关公式符号定义
对索引分片之前先对集群中各节点的性能进行检验,同时满足以下2个条件则初步判定当前节点为可用节点,对应节点数组nodeArr[]位置置为1。
条件1:节点i的磁盘使用率:Disk _i≤85%。
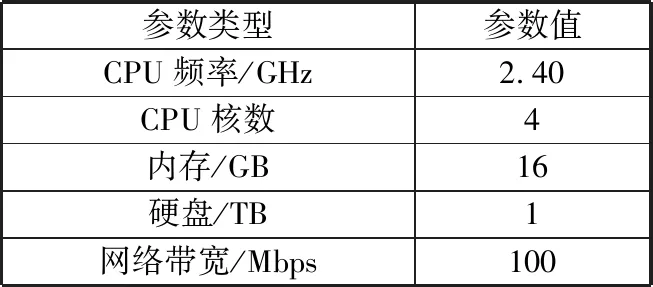
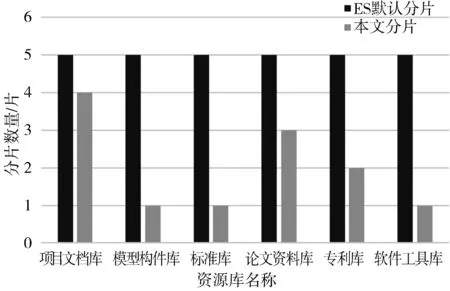
条件2:节点i已有分片数量:S_i 但是可能存在节点满足条件2,放置索引分片后就不满足的情况,因此需要对可用节点的结果数组进行二次调整,调整方式如下: 首先,根据ES单个分片的索引业务数据量最好不要超过25 GB[22]的建议,利用公式(1)得到一个初始主分片数量。 Num1=「D/25⎤ (1) 然后,根据索引分片成功后ES会将分片均匀地分配到各个节点上的特点,通过公式(2)得到某节点需要放置的主分片数量N。 (2) 节点的分片数量与集群中的可用节点的个数有关,根据现有研究表明,在开始阶段,一个好的方案是可以按照可用节点数量(Na)1.5倍到3倍的原则来创建分片。本文考虑到后续数据的扩展以及每个主分片还需要设置一个或多个副本分片来保证可用性的需求,按照节点数量的3倍来创建分片(包含主分片和副本分片),因此根据可用节点个数可以粗略地得到主分片结果Num2,如公式(3),其中R表示为每个主分片创建R个副本分片。 Num2=⎣(3×Na)/(R+1)」 (3) 综合考虑可用节点个数、索引的业务数据量以及索引数据的扩展程度,将节点个数与索引的业务数据量进行一个线性加权并除以一个扩展系数,可以得到最终的主分片数Num,公式如式(4)所示: Num= (k1×Num1+k2× Num2 )×(1/e) (4) 其中,k1、k2为权重系数,k1+k2=1,e用于衡量索引数据量的扩展程度,e∈(0,1]。对于数据扩展较大的索引,e值可以适当地取较小的值,但是e值应该满足最终分片数量经平均分配到每个节点后,该索引在该节点的分配数据应小于或等于节点i允许同一索引最大分片数量x。索引分片优化后得算法流程如图3所示。 图3 索引分片优化算法流程图 数据写入索引的过程中,为了保证ES检索的准实时性,默认每间隔1 s就会将buffer中的数据refresh到一个新的段文件中,此时会产生大量的小的段文件,段文件数量过多时,进程需要加载一个个的索引段,会大大增加磁盘的I/O开销[23],降低数据的查询速度。因此ES底层会对索引段进行合并,使得索引段可以维持在一个合理的区间内,并且还可以通过段合并机制来对被标记为删除的文档进行丢弃,以此来减少索引中文档的数量。表4列出了ES可选的3种段文件合并策略。 表4 ES段合并策略 以上段合并策略在判断段合并时机时,主要是根据索引段的数量来进行判断,当索引段的数量超过设定的阈值时,就进行段合并操作。这种时机选择策略没有考虑到节点当前负载,在进行段文件的合并时会有对系统和I/O资源的耗费,如果当前节点的负载本来比较高,此时再进行索引段合并会显著地影响节点的性能,从而降低集群的吞吐量。 为了解决以上问题,本文在进行段合并前,先对节点的性能进行校验,如果当前节点的性能处于一个较差的状态,则将段合并操作进行延迟,直到监测到节点的性能处于较好的状态,才进行段合并操作。为了更好地进行描述,表5对相关符号作出定义。 表5 索引段合并相关公式符号定义 在进行段合并操作时的节点i的性能可由节点的内存使用率Mem_i和节点的CPU使用率CPU_i以及节点磁盘的I/O使用率Disk_i这3种共同决定,因此可通过公式(5)来衡量节点i当前的负载系数Loadi: Loadi=α×Memi+β×CPUi+γ×Diski (5) 其中,α、β、γ为权重系数,α、β、γ取值均在0到1之间,并且α+β+γ=1。用户可以根据自己集群的特点来设置不同的权重,当节点i当前的负载系数Loadi大于事先设定的阈值Load_max时,认为当前节点性能不适合进行段合并操作,将段合并操作进行推迟;当节点i当前的负载系数Loadi小于阈值Load_max时,此时可进行正常的段合并操作。 为了减少节点段合并的压力,对节点的索引段进行一个预合并操作。当目前索引的索引段数量还未达到需要合并的阈值上限N,但已经达到了60%,则可以先根据节点的性能进行判断,若当前性能较好(Loadi处于一个较小的值),则可先进行一个预合并操作,先合并部分索引段,使节点的索引段数量较低。具体合并策略如图4所示。 图4 优化段合并策略算法流程图 为了验证文中对ES相关改进的有效性,本文利用地铁领域工程数据来进行测试。工程源数据管理在分布式文件系统FastDFS中,对于工程文档的标题以及工程文档在FastDFS中的存储位置等元数据信息利用关系型数据MySQL库进行存储。 使用的数据来源于广州省某地铁设计院14号线和18号线部分站点的设计结果,数据共108.6 GB(包含模型构件以及相关设计报告等),除此之外还包括目前已经爬取的设计过程可参考的论文和专利数据共16.3 GB,以及设计过程用到的软件工具、参考的设计标准等少量数据,均不超过5 GB。为了满足用户对不同数据的检索需求,将以上工程数据根据内容划分成不同的库,其中,站点设计结果数据中的模型构件部分划分为模型构件库,其余部分划分为项目文档库,论文、专利、设计标准以及软件工具分别为一个库,为每个库分别创建一个索引。 实验过程中利用Elastic公司开发的监控工具kibana来对ES集群中的相关数据进行监控,例如:ElasticSearch集群某个节点的JVM堆的使用情况、CPU使用率、系统负载、索引负载、延迟、segment片段统计。 本文实验根据数据量搭建一个拥有6个节点的ES集群,各节点的CPU频率、CPU核数等相关信息如表6所示。 表6 实验环境列表 1)利用本文分片策略与ES默认分片对各索引的分片数量进行比对。通过对节点的性能进行校验,得到集群可用节点的个数,根据2.2节中索引分片策略得到的各索引的分片数量与ES默认分片数量对比如图5所示。可以看到,在数据量不大的情况下,通过本文分片策略进行分片得到的数量更少,进行查询时可以减少建立请求、数据传输以及等待响应的时间,从而提高性能。 图5 ES默认与本文分片模型分片数量对比 2)索引的查询延时可以对索引的性能进行度量,本文对索引的分片策略进行了优化,在一定程度上对ES的查询性能进行提升。本文的项目文档库、论文资料库以及专利库中存在长文本,本实验中仅对查询延迟进行对比,因此未返回content内容。图6展示了ES默认情况下各索引的查询延迟与本文改进后的查询延迟,可以看出通过本文的改进,ES的查询性能有所提高。 图6 ES默认与本文改进后的索引查询延迟对比 3)为了验证本文的索引段合并优化的机制对ES性能的提升,本文利用论文文本数据对大批量数据导入过程中索引段的合并情况进行一个监测,监测结果如图7所示。随着数据导入,索引段合并次数增多,但是可以看出采取本文的合并策略后,索引段的合并次数低于ES默认。这是由于在大批量数据导入时,系统监测到节点的负载较高,此时系统就会采取延时合并策略,当监测到节点负载不那么高时再进行合并操作。 图7 ES默认与本文改进后的索引段合并次数对比 同时对采用本文索引段合并策略以及ES默认索引段策略的数据导入时间进行一个对比,对比结果如图8所示。可以看出本文策略确实可以有效降低数据导入时间,对于大批量数据其查询原理与数据写入一致,本文就不再进行实验对比。 图8 ES默认与本文改进后的数据导入时间对比 生产制造行业在生产制造的过程中会产生大量的工程数据,利用分布式全文搜索引擎ES可以很好地解决非结构化工程数据的检索问题,但是ES在性能方面还有待改进。本文对ES底层进行深入研究,从索引建立的分词器配置、索引的分片策略以及索引段的合并3个方面对ES进行改进。实验表明,本文作出的改进对ES的性能有所提升。由于本文实验收集的数据量并未达到很大,所以通过本文计算出的各索引的分片数量都小于ES默认分片数量,缺少了数据量较大,计算出分片数量大于ES默认分片数量情况下的ES性能对比,后续会收集更多数据,对该部分进行实验。

2.3 索引段合并优化



3 性能评估
3.1 实验环境
3.2 实验结果及分析



4 结束语
