基于预训练语言模型的商品属性抽取
2022-03-10张世奇周夏冰陈文亮
张世奇,马 进,周夏冰,贾 昊,陈文亮,张 民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
属性抽取任务是从非结构化文本中抽取出与实体相关的属性值。属性抽取作为构建知识图谱[1]的重要环节,可以用于拓展实体节点属性。在事件抽取任务中,可以用于识别出事件的特有属性;在信息检索领域,可以提供关键词的支持;还可应用于智能问答系统中,辅助抽取问句中三元组信息。
面对海量数据,属性抽取可抽取出与实体节点相关的属性和属性值,是构建知识图谱的关键技术。在电商知识图谱中,属性抽取是对电商平台评论文本、社交媒体数据等进行分析,获得属性和属性值对,从而达到扩充电商知识图谱的目的。由于相关数据源源不断地产生,如何高效地从电商数据中抽取出与商品相关的属性信息就显得尤为重要。
在本文中,主要任务是商品属性抽取,即从无标注文本中抽取出给定商品类目的属性及其属性值(1)类目是一小类商品的统称。。例如,给定一个商品类目“卫衣”及其描述文本“外贸男士秋季连帽卫衣出色拼接拉绒布嘻哈卫衣大码外套”,目标是从描述文本中抽取与“卫衣”相关的属性及属性值,如“材质-拉绒布”、“风格-嘻哈”,其中,“材质”和“风格”是“卫衣”的属性,“拉绒布”和“嘻哈”是相应的属性值。
现有属性抽取方法主要分为基于规则的方法、基于传统机器学习的方法和基于深度学习的方法。基于规则的方法需要人工构造特征模板,并利用模板从文本中匹配属性值。基于传统机器学习的方法通常使用有监督学习的方式抽取属性值。基于深度学习的方法利用循环神经网络(Recurrent Neural Network,RNN)、长短时记忆网络(Long Short-Term Memory Network,LSTM)等神经网络模型抽取属性值。基于规则的方法严重依赖人工构造模板,而基于传统机器学习和深度学习的方法需要大量标注语料。
本文采用深度学习模型在电商场景下进行属性抽取。因电商数据包含的属性种类繁多、缺乏标注语料且人工标注成本过高,我们使用远程监督方法(Distant Supervision,DS)标注语料,语料来源于微博文本、电商平台商品标题、用户评论数据。远程监督利用<类目名称,属性类型,属性值>,通过对齐三元组和句子的属性及属性值完成标注。三元组来源于人工构建的属性词典,规模有限,致使远程监督标注易出现漏标问题,因此我们提出了基于扩充三元组的远程监督方法(Distant Supervision Based on Extended Triples,EXDS)。本方法以商品类目之间存在属性值重叠和相似类目可进行属性、属性值扩充为约束条件,弥补了远程监督标注时有限三元组覆盖度不足的缺点,有效缓解了漏标问题。同时为精准评估系统性能,我们采用人工标注方式构建测试集。我们利用多种预训练语言模型进行领域内和跨领域属性抽取。实验表明,预训练语言模型可进一步提高属性抽取性能,增加少量目标领域标注数据能提升跨领域属性抽取效果,增强模型的领域适应性。
1 相关工作
目前在属性抽取领域,研究人员大都基于在特定领域构建的语料。康睿智等人[2]利用军事网页中的文本构建了面向军事领域的语料,张巧等人[3]基于美国10所大学的导师页面构建了用于主页人物属性抽取的语料。TAC KBP竞赛提供了大型英文属性抽取语料库,该语料库要经过繁琐的预处理才能使用。KnowledgeNet[4]是一个用于构建知识图谱的数据集,可用于属性抽取任务。该数据集给出了相对完善的训练数据,其中包含了大量人工标注的数据。但是这些人工标注的数据存在很多冗余,测试集也并未公开,数据预处理繁琐,不易于研究人员开展相关研究工作。
在属性抽取方面,早期的工作大都基于规则或者机器学习算法来进行,例如,Vandic等人[5]利用领域词典进行属性抽取任务,Ghani等人[6]利用监督学习的方式抽取出与商品相关的属性值。本文基于电商领域属性抽取数据集,利用序列标注的思想处理属性抽取任务。近年来,众多研究人员将神经网络与条件随机场(CRF)[7]结合,在属性抽取任务上进行了一系列探索。马进等人[8]利用双向长短时记忆-条件随机场(BiLSTM-CRF)的方法进行百科人物属性抽取,Zheng等人[9]利用双向长短时记忆网络(Bi-LSTM)、CRF和注意力机制从标题中抽取相关属性值,Xu等人[10]在电商领域使用注意力机制结合BiLSTM-CRF,捕获商品标题内在的语义联系。随着预训练语言模型的兴起,BERT[11]、ALBERT[12]、RoBERTa[13]、ELECTRA[14]以及XLNet[15]等一众预训练语言模型均在序列标注任务上有出色的表现。
2 电商领域属性抽取数据集
2.1 数据源简介
远程监督数据标注方法依赖于词典资源和无标注语料,为此我们使用某电商平台提供的数据资源,包括类目-商品对照表、类目属性词典和三类电商相关的文本数据。
类目-商品对照表有助于判断商品的类目。在表中的单条数据由一个类目和一个商品构成,如“裤子-运动裤”,其中“运动裤”是类目“裤子”包含的一个商品。一个类目可以包含多个商品。
类目属性词典共有950个类目、94种属性和13 586种属性值。词典采用三元组的表示方式: <类目名,属性名,属性值>,属性类型代表某个类目的固有属性,每个属性类型包含了若干属性值。如三元组<卫衣,风格,复古>、<卫衣,风格,时尚>,类目“卫衣”的属性“风格”包含了“复古”“时尚”两个属性值。
数据文件由微博、标题、评论三个领域的数据组成,微博数据为微博页面与商品有关的文本数据;标题数据来自电商网站中类目或商品的标题文本;评论数据是电商平台内用户对商品的评论文本。表1列出了三类数据的具体数目和平均长度。数据文件的格式如表2所示,其中描述文本的来源是评论数据,一级类目是男装,二级类目是卫衣,一级类目包含二级类目。
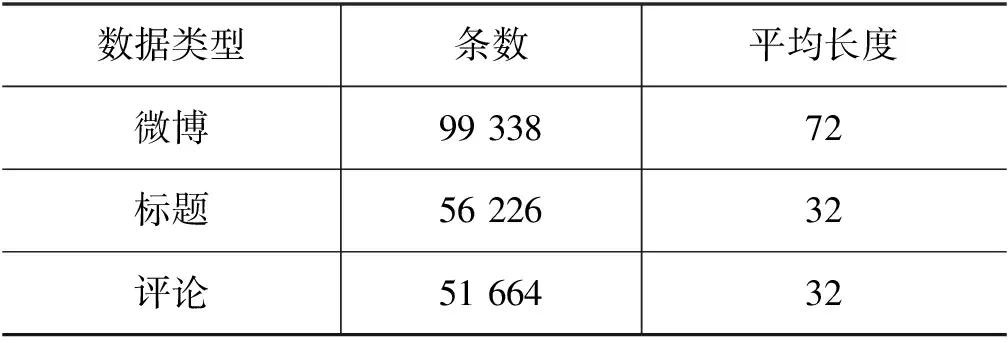
表1 数据整体情况

表2 数据文件样例
2.2 基于扩充三元组的远程监督
远程监督(DS)利用已有的类目属性词典与文本数据中的类目进行对齐,进而在文本数据中标注出类目的属性及属性值。在本文实验中,我们选择颜色、风格、材质三种较为通用的属性利用DS标注数据。由于类目属性词典规模有限,无法包含所有相关的属性值,所以DS标注会造成较为严重的漏标问题。
为缓解漏标问题,我们提出了一种基于扩充三元组的远程监督标注方法(EXDS)。其思想是在相似类目之间进行属性和属性值的扩充,弥补类目三元组属性缺失和属性值覆盖度不足问题。本文首先统计类目属性词典中每个二级类目对应的属性及其属性值,比对各个二级类目(不一定同属于一个一级类目)之间相同属性的属性值,合并含有重叠属性值的属性。其次,统计数据文件中每一个一级类目包含的二级类目。最后,对各个一级类目包含的二级类目进行属性和属性值的相互合并扩充。
由表3可见,DS漏标了大量的属性值,特别是在微博和标题数据上。表4统计了三类属性值在两种标注方式下的分布情况。
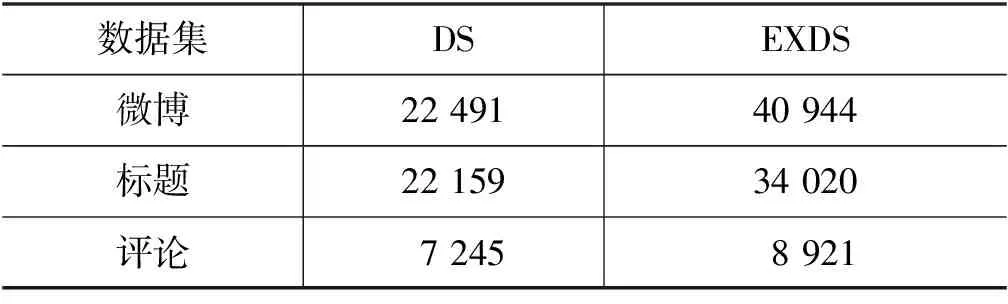
表3 属性值标注数目表
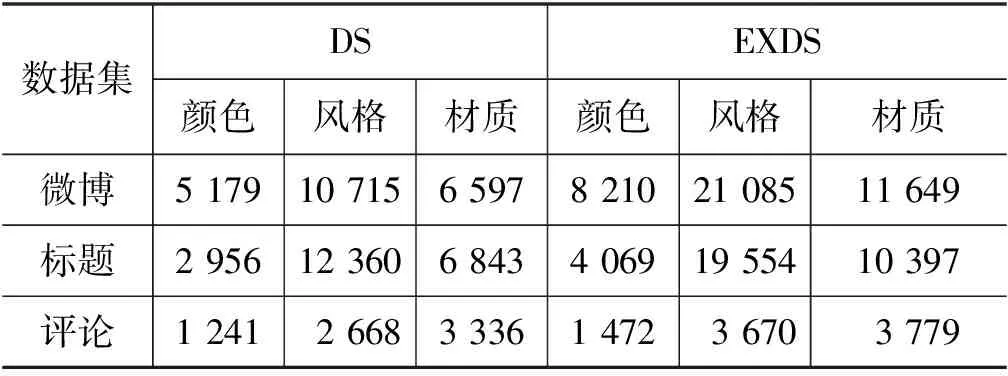
表4 三类属性统计表
图1展示了两种远程监督方式,图中给定了一个一级类目“男鞋”和对应的二级类目“帆布鞋”“篮球鞋”,以及原始属性词典。目标是对“帆布鞋”的描述文本“复古白色帆布鞋配水洗牛仔裤真好看”进行标注。原始属性词典中“帆布鞋”“篮球鞋”的“颜色”属性存在重叠属性值“黑色”,二者颜色属性可进行相互扩充,“篮球鞋”的“颜色”属性扩展了“白色”属性值。 “帆布鞋”“篮球鞋”属于同一个一级类目,再对其含有的属性互相扩充,使二者含有彼此的属性及其属性值,其中“帆布鞋”获得了属性“风格”和属性值“复古”,扩充结果见图1的扩充后属性词典。图中DS标注结果依赖原始属性词典,由于“帆布鞋”缺少“风格”属性,漏标了属性值“复古”。EXDS标注的结果由扩充后的的属性词典得到,“帆布鞋”的属性和属性值扩充后拥有了“篮球鞋”的“风格”属性及属性值,该方式有助于在标注时缓解漏标问题。
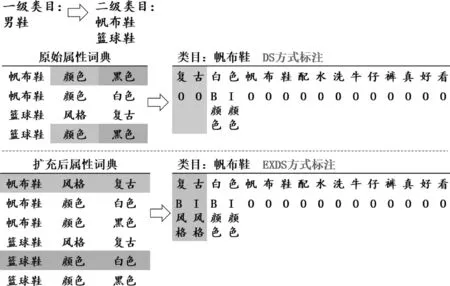
图1 远程监督标注
由于远程监督标注数据难免存在错误,为了准确评估系统性能,我们构建了一份近6 000条的人工标注数据。这份人工标注数据标注了描述文本中与类目相关的属性及属性值,包含2 000条微博数据,2 000条标题数据和1 998条评论数据。
为评估EXDS的标注效果,我们基于DS和EXDS在三类数据的测试集上进行标注,使用人工标注的测试集测试。由表5可见,EXDS损失了部分准确率,但是大幅提高了召回率,且EXDS的F值远好于DS,说明EXDS会引入部分错标,但能大幅提高正确标注的覆盖率,可有效扩展类目属性词典,增强其属性值覆盖度、提高标注的整体质量。
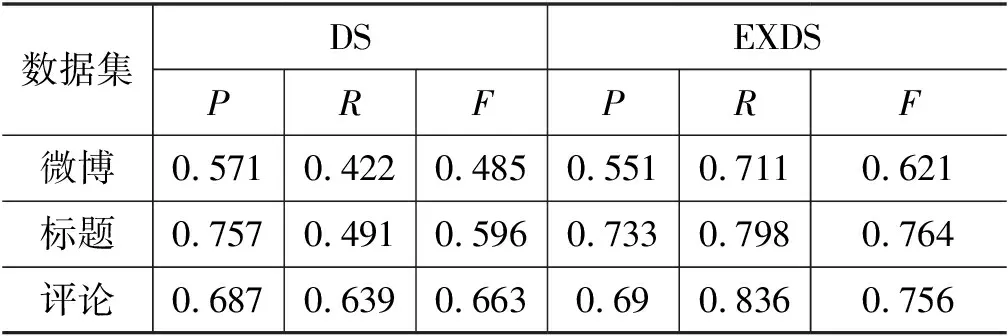
表5 DS与EXDS标注效果评估
2.3 数据特点
本节以类目、商品、属性值的分布情况展示三类数据的特点,采用两种匹配方式统计类目和商品的分布。
表6为平均每句类目种类数和商品种类数的统计结果。表中方式一利用商品对文本进行精确匹配,并统计商品对应的类目,其得到的类目种类数多于商品种类数,可见数据中存在一个商品包含在多个类目中的情况。方式二分别用类目和商品对文本进行匹配,结果显示匹配得到的类目种类数小于1,即二级类目不会显式出现在所有描述文本中。表7统计了属性值分布情况,由表中结果可得,微博和标题数据属于高密度属性值数据,评论数据属于低密度属性值数据。
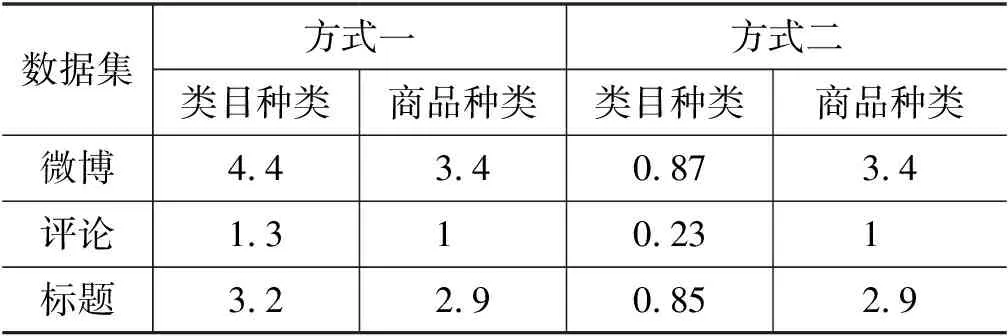
表6 平均每句类目及商品种类数
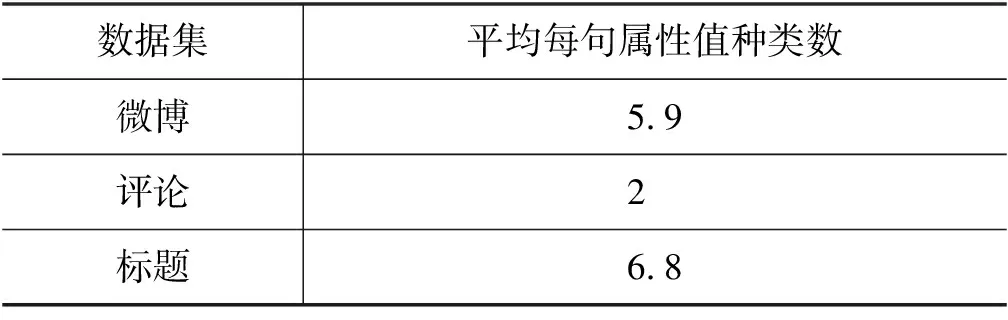
表7 属性值分布表
3 属性抽取模型
基于电商场景的属性抽取任务,不仅要识别出文本中可能与类目有关系的属性值,而且需要进一步判断出属性值的属性类型。本文将属性抽取任务转化为序列标注任务,使用序列标注的方法在描述文本中标注出类目的属性及其属性值。本文将BiLSTM-CRF以及ELMo-BiLSTM-CRF作为基线模型,并在多种预训练语言模型上进行领域内和跨领域的属性抽取实验。
3.1 基线模型
长短时记忆网络(LSTM)是一种特殊的循环神经网络(RNN)模型,它有效解决了梯度消失与梯度爆炸的问题,但是LSTM只能学习单向的序列信息。本实验采用双向长短时记忆神经网络(BiLSTM),由前向LSTM层和后向LSTM层组成,能够获取前向和后向的序列信息。
BiLSTM-CRF结构图如图2(a)所示。
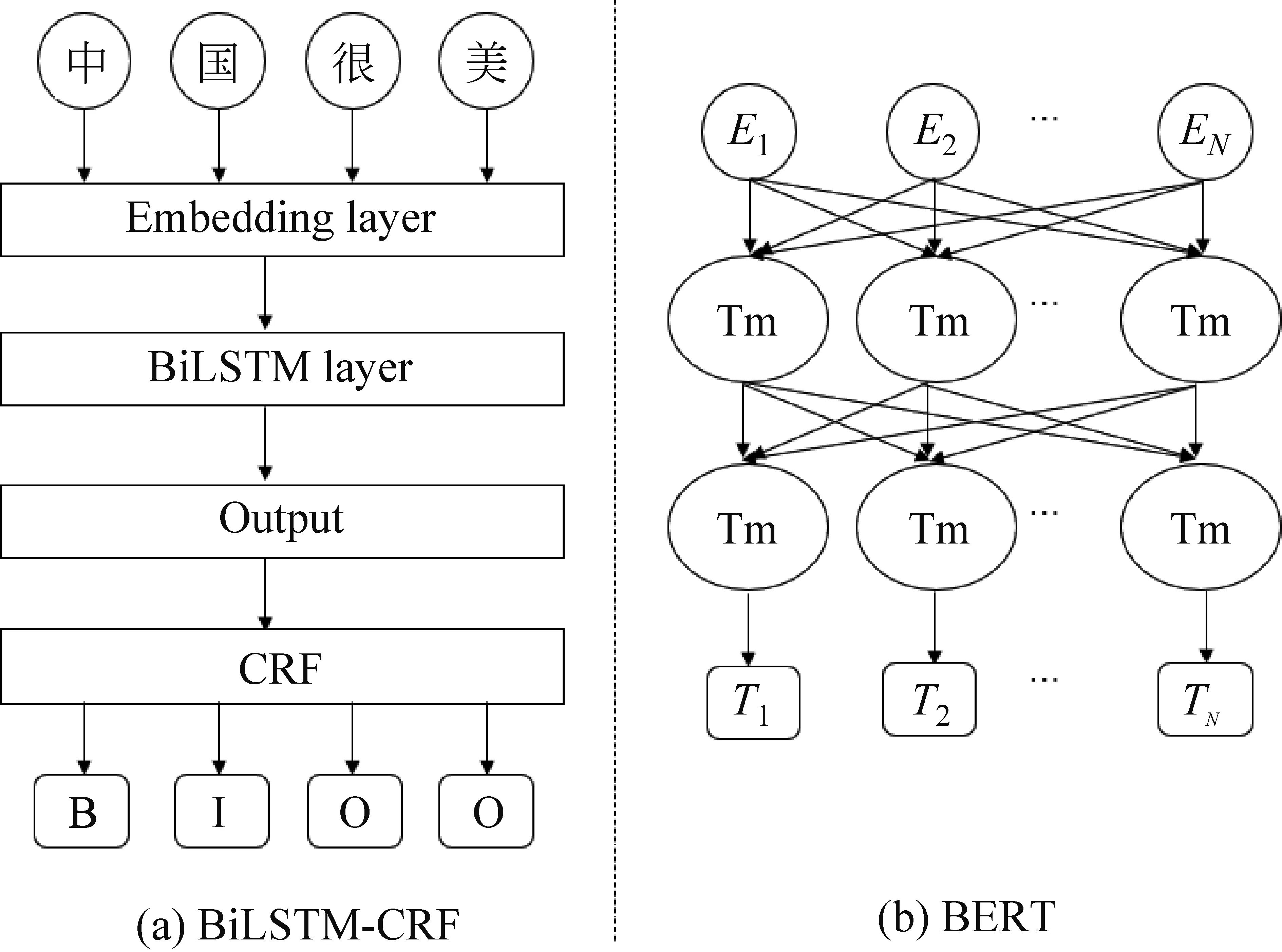
图2 BiLSTM-CRF与BERT架构图
第一层是词嵌入层,该层将输入序列的字映射为向量表示。本文使用随机初始化字向量作为词嵌入层。
第二层是BiLSTM层,该层将向量矩阵输入前向LSTM和后向LSTM,捕获序列过去和未来的上下文信息。前向LSTM和后向LSTM的输出按位置拼接得到BiLSTM层的输出。
第三层是CRF层,该层主要学习序列中的约束条件,纠正BiLSTM输出的错误预测。对于输入序列X=(x1,x2,…,xn),及其预测标签序列Y=(y1,y2,…,yn),其得分如式(1)所示。
(1)
其中,A为转移得分矩阵,Ai,j是标签i转移至标签j的得分,y0为标签序列的起始标签,yn是结束标签。经归一化可得标签序列的条件概率,如式(2)所示。
(2)
式(2)中,YX表示输入序列X所有可能的标签序列集合,y代表正确的标签序列。训练模型时最大化式(2)中正确标签序列的对数似然概率。
(3)
对类目的描述文本标注时,选取式(3)中序列全局概率最大的结果y*作为最佳预测标签序列。
ELMo[16]是一种预训练语言模型,以BiLSTM作为其基本网络结构。ELMo通过利用BiLSTM各隐藏层的状态信息,使ELMo-BiLSTM-CRF能够进一步学习输入序列中的语义信息与句法信息。相较于BiLSTM-CRF,ELMo-BiLSTM-CRF能捕获更丰富的上下文信息。
3.2 预训练语言模型
本文选择BERT、ALBERT、RoBERTa、ELECTRA、XLNet五种预训练语言模型在数据集上进行实验。
BERT使用堆叠双向Transformer[17]架构,图2(b)为BERT的架构图,其他预训练语言模型基本结构与之类似。BERT预训练阶段主要包含遮蔽语言模型(Masked Language Model,MLM)和下一句预测任务(Next Sentence Prediction,NSP)。MLM采用静态掩码,即在预训练之前对序列进行遮蔽操作。NSP通过预测两个句子是否紧连在一起,使模型理解句子间的关系。BERT的不足之处在于仅在预训练阶段引入[MASK]标记,导致预训练阶段与微调阶段不一致;BERT假设每一个被遮蔽的部分与文本中没有被遮蔽的部分是相互独立的,这种假设极大简化了文本中的长期依赖关系。
表8展示了ALBERT、RoBERTa、ELECTRA、XLNet相较于BERT的改进。ALBERT相比于BERT模型,将词嵌入矩阵进行分解并实现跨层参数共享。ALBERT在预训练阶段取消了NSP任务,引入了句子顺序预测任务(Sentence-Order Prediction,SOP),SOP更注重句子间的连贯性。
RoBERTa在预训练阶段使用了更多的训练数据,摒弃了NSP任务。不同于BERT在预训练时使用的静态掩码,RoBERTa在预训练时采用了动态掩码操作,对相同输入序列采用不同的随机遮蔽方式。
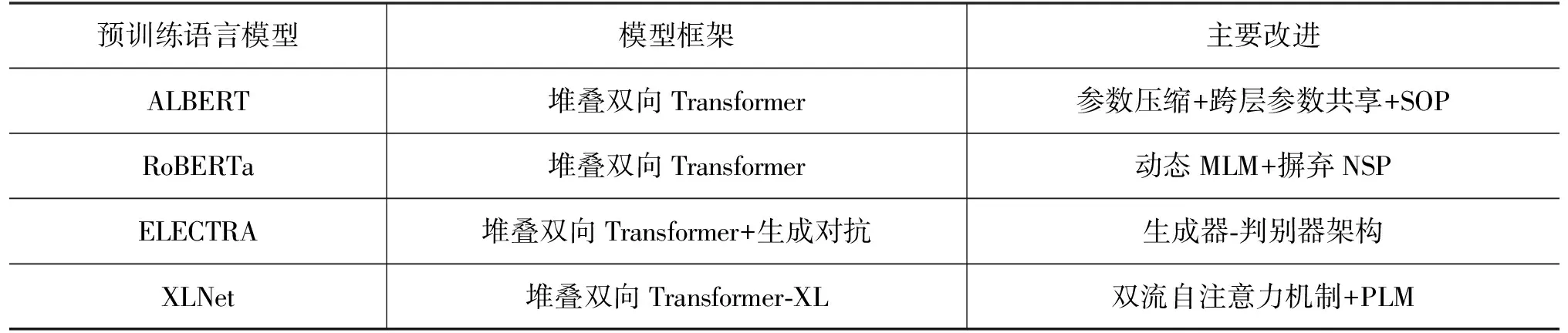
表8 预训练语言模型对比
XLNet结合了自回归模型与自编码模型的优点,针对BERT预训练和微调阶段输入不一致的问题,提出了排列语言模型(Permutation Language Model,PLM)和双流自注意力机制(Two-Stream Self-Attention)。排列语言模型将序列重排使模型获取不同的上下文信息。双流自注意力机制使模型在预测当前位置单词时,通过注意力遮蔽矩阵仅注意上下文和未被遮蔽的位置信息,解决了BERT预训练阶段与微调阶段不一致的问题。
ELECTRA基于生成对抗网络的思想采用了新的预训练框架,采用生成器和判别器相结合的方式训练模型。ELECTRA将生成式的遮蔽语言模型改为判别一个单词是否被替换过的任务(Replaced Token Detection,RTD)。ELECTRA把MLM作为生成器,预训练过程中生成器将生成序列中被遮蔽的单词,其输出结果输入判别器,判断序列中的单词是原始的还是由生成器生成的。
4 实验设置
4.1 领域内属性抽取
本文利用DS和EXDS标注领域内属性抽取训练数据,将人工标注数据作为测试集。我们基于标注数据在基线模型与预训练语言模型上进行领域内商品属性抽取实验。
4.2 跨领域属性抽取
本文分别将微博和标题数据作为源领域数据,评论数据作为目标领域数据,在各个预训练语言模型中将学习率调至开发集性能最优的条件下进行跨领域属性抽取实验。本文设置了两组实验,均使用EXDS构建实验数据。
实验一: 仅用源领域数据微调预训练语言模型。该实验主要用于对比领域数据间的差异,观察不同预训练语言模型的性能损失。
实验二: 使用添加少量目标领域数据的源领域数据微调预训练语言模型。为证明添加少量目标领域数据有效,实验二使用两种不同的源数据进行实验,通过对比实验一的结果验证其有效性。
4.3 实验参数设置
在本文实验中,我们使用DS和EXDS(详见2.2节)两种方式自动标注数据,分为训练集和开发集,而测试集使用人工标注数据,其中训练集包括12 000条微博和标题数据,6 000条评论数据(评论数据符合远程监督标注条件的较少),开发集包括2 000条微博和标题数据,1 000条评论数据。跨领域实验数据如表9所示,实验采用EXDS自动标注数据。

表9 跨领域实验数据
我们针对基线模型设置多组超参数进行实验,选择在开发集上表现最优的超参数组合作为基线模型的超参数,其设置如表10所示。本文使用中文语料训练的预训练语言模型,五种预训练语言模型均使用隐层大小为768,包含12个隐层和12头注意力规模的模型。预训练语言模型对学习率比较敏感,我们根据预训练语言模型在开发集上的最佳性能选择模型的学习率,如表11所示。
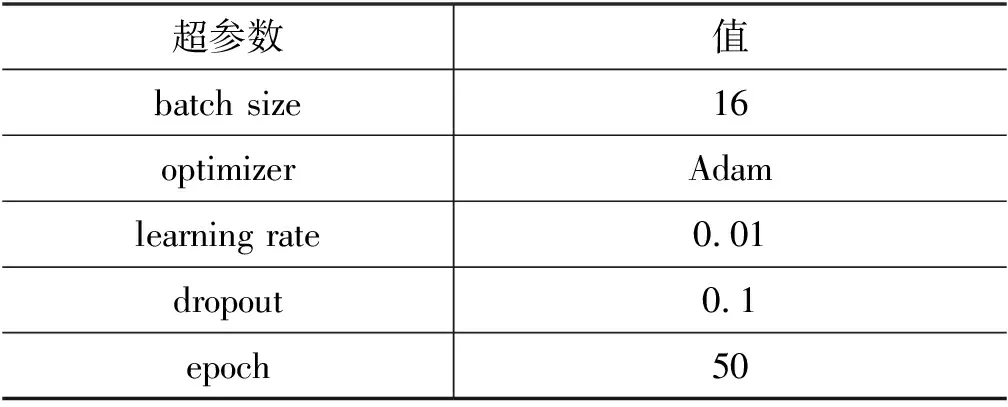
表10 基线模型超参数
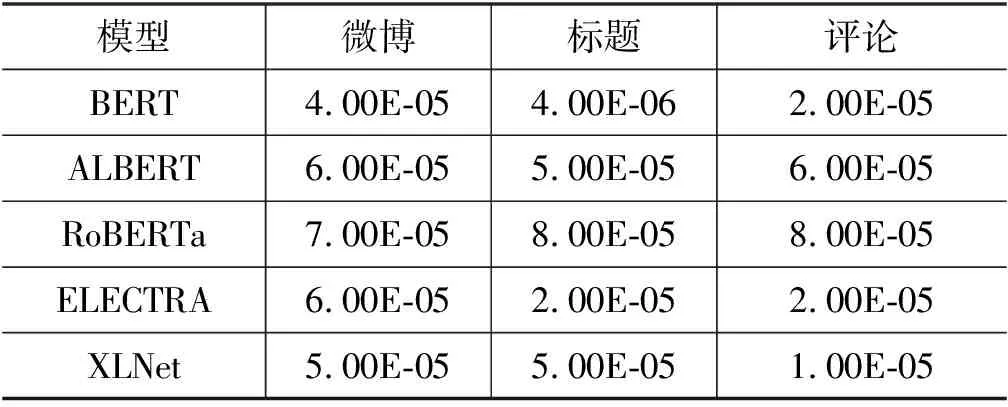
表11 预训练语言模型学习率
5 实验结果
5.1 领域内属性抽取
本节分别使用DS和EXDS构造训练标注数据,使用人工标注数据作为测试集。表12是基线模型和预训练语言模型的领域内实验结果,F(OOV)用于评估模型识别类目属性词典之外的新属性值的能力。从表12可以看出,各个模型使用EXDS的效果都远好于DS。DS实验结果显示,多数预训练语言模型的实验结果低于基线模型,而EXDS的结果则相反。原因一方面是类目属性词典的属性和属性值并不完备,仅能覆盖部分数据,导致DS漏标大量属性值;另一方面,预训练语言模型学习能力较强,使用包含大量漏标的数据训练系统,易误导系统预测。依据实验结果可以发现,所有模型的EXDS结果明显好于DS,大多数预训练语言模型在EXDS上的结果优于基线模型。其中,XLNet和ELECTRA在评论和标题数据中表现较为突出;在微博数据上BERT的性能最好。
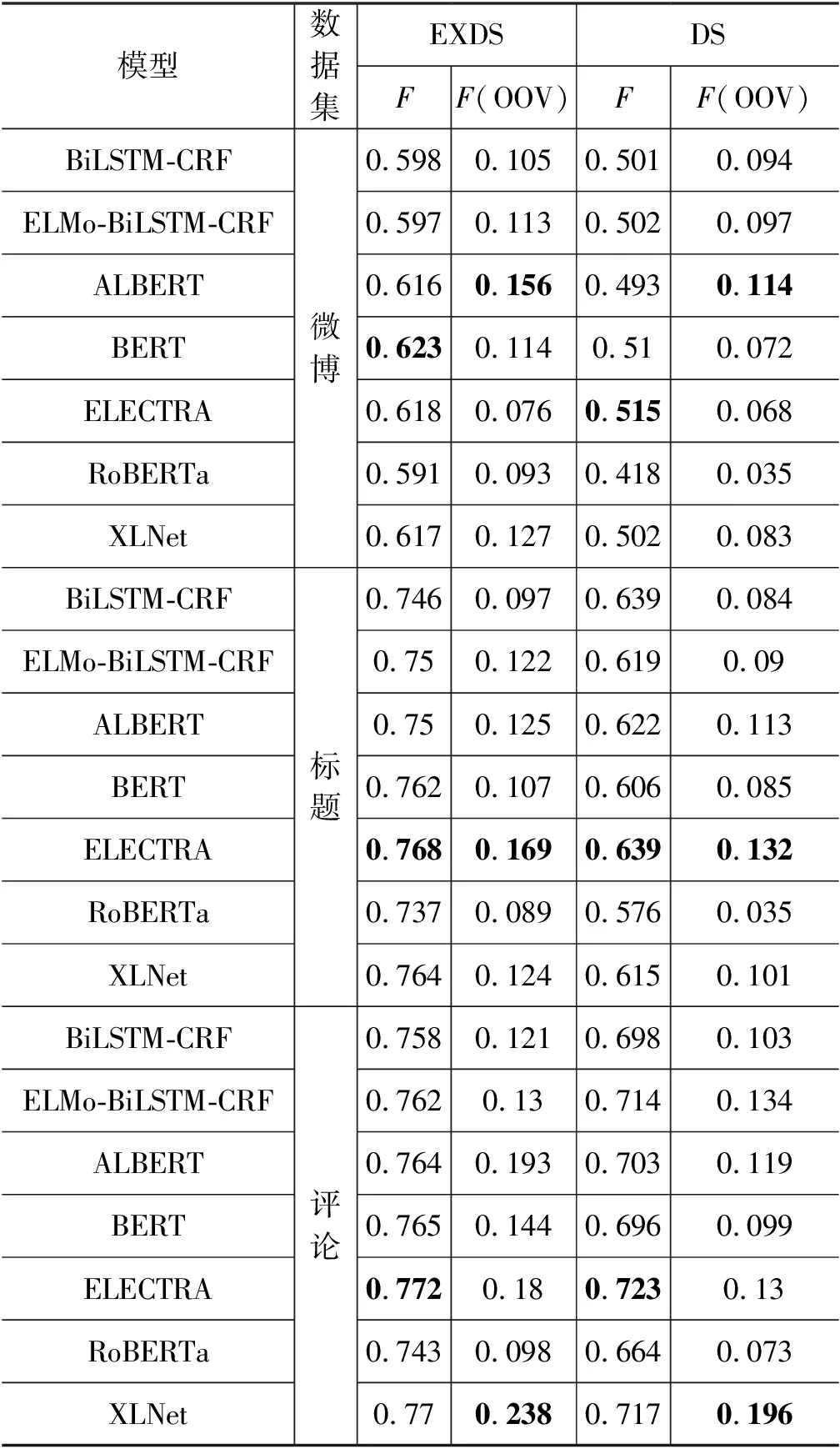
表12 领域内属性抽取实验结果
在OOV方面,绝大多数模型利用EXDS构建的标注数据训练可大幅提升其识别OOV的能力,该实验结果进一步证明了EXDS标注方式能有效缓解漏标问题。由此可见,漏标不仅会损失模型识别词典内属性及属性值的性能,也会削弱模型识别未登录属性值的能力。在下文的实验中,如无特别说明,我们使用EXDS构建标注数据作为训练集。
5.2 跨领域属性抽取
我们首先用标题数据作为源领域数据,评论数据作为目标领域数据,进行跨领域属性抽取实验,结果如表13所示。
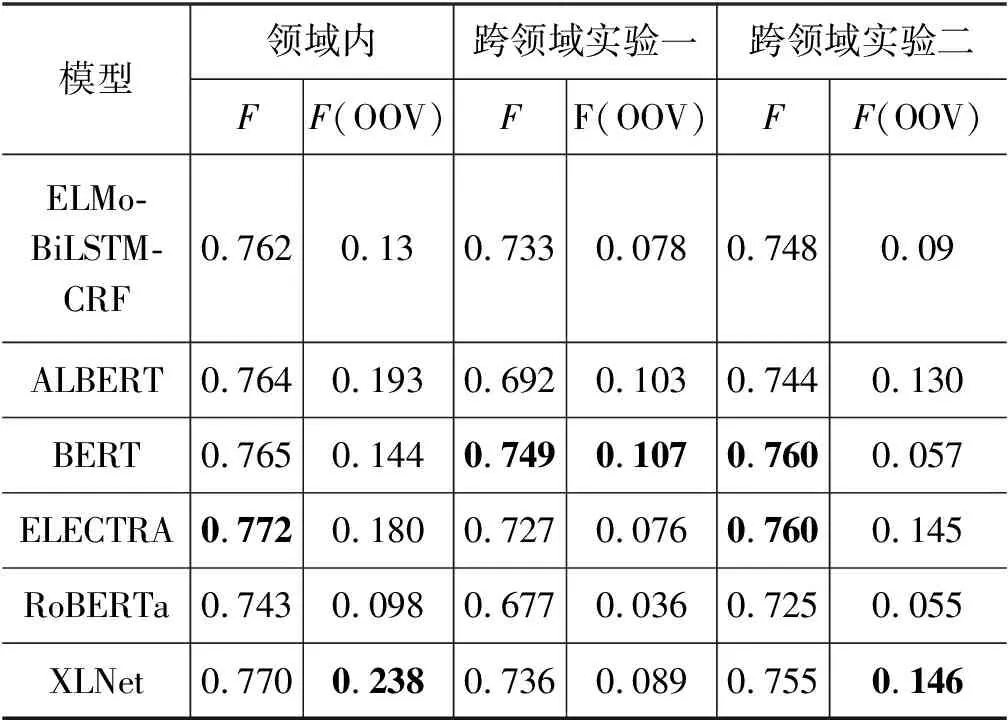
表13 跨领域属性抽取实验
由实验结果可得:
(1) 跨领域实验一的F值相较于领域内实验有明显下滑。依据两类数据的属性值分布情况,我们发现标题数据中属性值的密度较高,而评论数据相反,因此仅使用源领域数据微调模型,易使模型偏向于建模大量属性值与类目的上下文关系,导致实验一的结果较差。
(2) 跨领域实验二的F值接近领域内实险的F值。由标题和评论的数据特点可知,标题数据与评论数据长度相似,且数据中属性值大都与句子给定的类目有关,数据噪声小。因此,该实验训练集中的少量目标领域标注数据有利于缓解由两类数据间属性值分布不一致造成的模型性能下降问题。
(3) 在识别未登录属性值方面,实验二中大部分预训练语言模型的F(OOV)值在实验一的基础上有大幅提升,说明利用少量目标领域标注数据可提升模型识别未登录属性值的能力。
表14展示了将微博数据作为源领域数据,评论数据作为目标领域数据,进行跨领域属性抽取的实验结果。
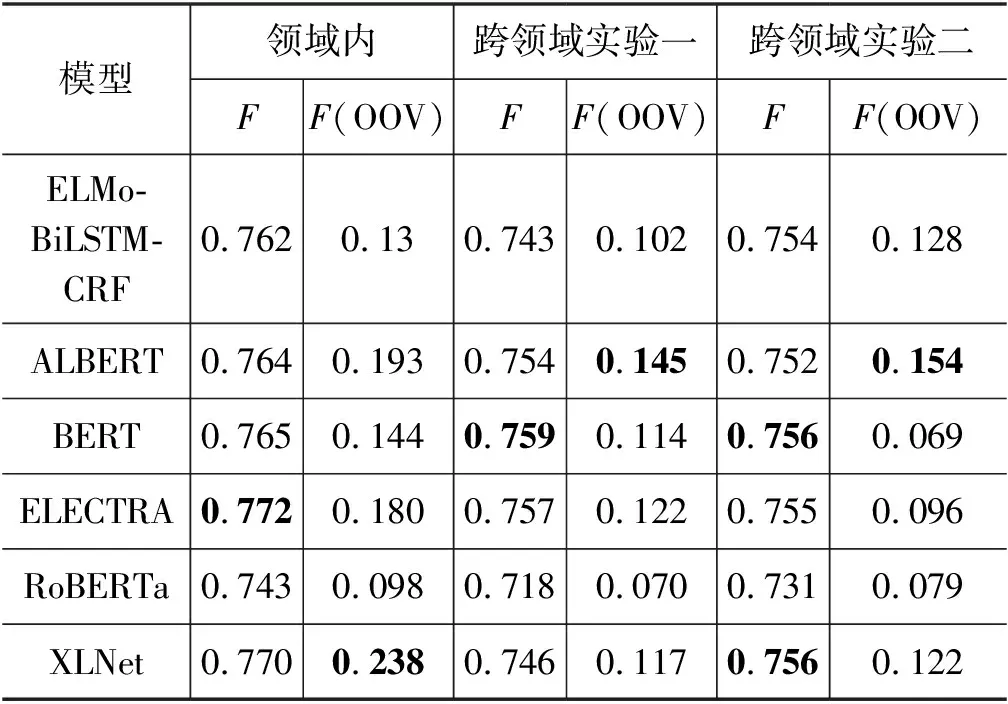
表14 跨领域属性抽取实验
根据实验结果我们发现:
(1) 跨领域实验二中,ELMo-BiLSTM-CRF、RoBERTa和XLNet的性能在实验一的基础上有明显提升,说明ELMo-BiLSTM-CRF、RoBERTa和XLNet对目标领域数据更为敏感,能够通过学习少量目标领域标注数据增强其领域适应性。
(2) 相较于跨领域实验一的结果,实验二中ALBERT、BERT和ELECTRA性能略微下降。我们通过对比微博、标题与评论数据的异同,发现微博数据平均长度大约为标题和评论数据的两倍,且含有较多与句子类目无关的商品,数据噪声大,这增加了模型学习类目与属性值之间的上下文信息的难度。故添加少量目标领域标注数据(约4%)不足以缓解数据差异和数据噪声对ALBERT、BERT和ELECTRA带来的影响。
(3) 在识别未登录属性值方面,跨领域实验二中大部分预训练语言模型的F(OOV)值相较于实验一有1%左右的提升,进一步证明添加少量目标领域标注数据有效增强了模型识别未登录属性值的能力。
基于上述分析,得出以下结论:
(1) 跨领域属性抽取存在领域适应问题。源领域与目标领域数据在文本长度、属性值分布和数据噪声上的差异,会导致模型在目标领域产生不同程度的性能损失。不同语言模型对目标领域数据的敏感度不同,可依据不同源领域数据对模型在目标领域上的性能影响,选择与源数据适配的模型。
(2) 在源领域中添加少量目标领域数据,有助于提升模型的领域适应性,增强模型识别未登录属性值的能力,有效缓解部分领域标注数据不足的问题。
(3) 选择与目标领域数据长度相近,且含有较少数据噪声的源领域数据,有利于缓解数据间差异带来的模型性能损失。
6 总结与展望
基于电商场景的属性抽取任务依赖大量标注语料,而人工标注数据耗时耗力,常利用远程监督的方式标注语料。由于远程监督标注依赖类目属性词典,易造成数据漏标且构建的标注语料有限。为解决以上问题,本文提供了适用于属性抽取的电商数据集和高质量人工标注数据,提出了EXDS标注方法。本文基于多种预训练语言模型进行了领域内和跨领域属性抽取,实验证明预训练语言模型可有效提高商品属性抽取性能。我们在跨领域属性抽取实验中通过添加少量目标领域训练样本取得了较好的实验效果。
属性抽取是构建电商知识图谱的重要手段之一。本文采用的EXDS标注方法引入部分错标,会影响模型性能。此外,我们没有深入研究复杂的跨领域属性抽取方法,在实验设计上还有很大提升空间。未来的工作中,会考虑利用句法信息加强模型抽取属性值的能力,并探索缓解远程监督引入错标的问题。
