语言模型攻击性的自动评价方法
2022-03-10侯丹阳丁汉星兰艳艳程学旗
侯丹阳, 庞 亮, 丁汉星, 兰艳艳, 程学旗
(1.中国科学院 计算技术研究所 数据智能系统研究中心,北京 100190; 2.中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190; 3.中国科学院大学,北京 100049)
0 引言
文本生成是自然语言处理领域的一个重要研究方向。对文本生成技术的研究可以应用到大量已知的自然语言处理任务中,例如,机器翻译[1]、对话生成[2]和文本摘要[3]等。近些年来,使用预训练的语言模型处理文本生成任务成为研究热点。这些语言模型通常在大量的无标记文本上使用无监督学习的方法进行训练,然后将其微调以适应各种下游任务。这些语言模型在文本生成、阅读理解和智能问答等任务上均取得了很好的性能表现[4-5]。
然而,Wallace等[6]的研究表明,这类语言模型,如生成式预训练模型GPT2[5],在受到扰动时可能会生成具有攻击性的文本,如种族歧视、性别歧视或辱骂性的语言等。例如,GPT2在特定条件下会生成包含种族歧视的攻击性文本的实例:
Man Goddesses! I hate Blacks!!! I can’t even talk to them because of the fact that Blacks can’t be bothered to be nice to each other.
因此,这种具有不确定攻击性倾向的语言模型在研究和实际应用中存在隐患。例如,在故事续写和新闻生成等应用场景中,语言模型的使用者无法得知该语言模型具体的攻击性倾向的水平,这给这类语言模型的广泛使用带来了困难。由于担心被滥用,OpenAI的研究人员曾拒绝公开包含15亿参数的完整的GPT2语言模型。
由于语言模型的攻击性不直接对外展示,而是通过其生成的文本表现出攻击性。所以在一般的文本生成过程中,语言模型没有完全表现出其攻击能力,即生成攻击性文本的概率较低,此时生成的文本隐藏了语言模型真实的攻击性水平,因此我们无法直接通过评估在一般情况下生成的文本的攻击性来获知语言模型的攻击性水平。
针对语言模型的攻击性评价的问题,本文提出了一种语言模型攻击性的自动评价方法。该方法通过Dathathri等[7]提出的可控文本生成的技术,即插即用的可控文本生成模型(PPLM),引导语言模型向着产生攻击性文本的方向生成待评估的文本,使生成攻击性文本的概率提升至可观测水平,方便对比评价不同模型的攻击性水平。然后使用评估模型对生成的文本进行评价,最后得到对该语言模型攻击性的自动评估结果。
在实验阶段,本文利用攻击性文本分类任务,分别训练了PPLM模型中的属性分类器作为诱导模块和攻击性文本分类器作为评估模块,然后对不同参数规模的GPT2模型及其变体模型的攻击性进行了自动评估。实验结果表明,该评价方法能够有效地引导语言模型产生攻击性文本,从而自动高效地对语言模型的攻击性进行评价。
1 相关工作
文本可控生成任务的目标是控制生成文本的属性,如长度、片段、情感、时态和文本风格等。本文引导语言模型生成具有攻击性的文本,用以自动评估语言模型的攻击性水平。本节介绍了文本可控生成的相关工作,主要包括从头开始训练的文本可控生成模型和即插即用的文本可控生成模型。
1.1 从头训练的可控文本生成模型
研究人员尝试从头训练不同的生成模型来达到文本的可控生成这一目标。Hu等[8]提出了将变分自编码器VAE[9]与文本判别器相结合,使用VAE中的编码器学习到独立的属性编码,然后根据该属性编码使用生成器生成具有特定属性的文本。Wang等[10]提出在生成式对抗网络GAN[11]中使用多个生成器和一个多标签分类的判别器进行联合训练。多个生成器的目标是各自生成具有某种特定属性的文本,而判别器的目标是区分出伪造的文本和具有特定属性的文本。Keskar等[12]在140 GB的互联网文本语料上从头开始训练了一个包含16亿参数的条件语言模型(Conditional Transformer Language, CTRL),该模型以原文本的属性片段为条件,控制生成带有主题、特定实体和实体间关系等多种属性的文本。
对于从头训练的模型,其可以很好地控制攻击性内容的生成,但是数据标注的代价高。CTRL模型的属性虽然可以自动获取,但是攻击性的属性也会直接产生攻击性的文本,且较难避免。
1.2 即插即用的可控文本生成模型
Dathathri等[7]提出了一种即插即用的语言模型(Plug and Play Language Models,PPLM)。它不需要重新训练整个语言模型,而是使用判别器对预训练的语言模型内部的激活层参数进行调整,极大地减少了计算量。PPLM的目标是建模,如式(1)所示。
p(X|a)
(1)
即基于某个属性a,生成文本X。根据贝叶斯公式,该条件概率可以进行如式(2)所示的分解。
p(X|a)∝p(X)p(a|X)
(2)
因此,可以用一个预训练的语言模型来建模p(X),然后使用一个属性模型来建模p(a|X),最后结合两者采样得到含有期望属性的文本。文中使用了Vaswani等[13]提出的Transformer结构作为编码器,用于建模自然语言的分布。假设历史矩阵Ht包含了如式(3)所示的过去至今的键值对。
(3)

其中,W是一个线性变换,其将向量ot+1映射到一个词表大小的向量。
为了达到控制生成的目的,作者选择更新历史矩阵Ht,这是因为未来的生成结果完全取决于过去的输出,而历史矩阵Ht中保存了Transformer模型中0时刻到t时刻所有的键值对。
作者尝试向着两个梯度的方向修改历史矩阵: 一个是在属性模型p(a|X)下得到关于属性a有更高的对数似然性;另一个是原始的无条件语言模型有更高的对数似然性。前者通过属性模型回传的梯度更新Transformer内部的历史矩阵,进而根据更新后的历史矩阵生成更加接近期望属性的文本。后者使得语言模型在更新历史矩阵的同时尽可能与原语言模型接近,保证了生成的文本的流畅度。
1.2.1 控制生成
在每个时间步,令ΔHt是通过属性模型p(a|x)回传的梯度得到的对历史矩阵的更新量。于是由Ht+ΔHt生成的文本有更高的可能性具有期望的属性。更新的过程有以下三步:
(1) 前向过程: 语言模型产生输出Ht,并使用属性模型预测期望属性的概率p(a|X)。
(2) 反向过程: 使用属性模型的梯度更新语言模型的内部激活层表示,以增加生成的文本具有期望属性的概率。
(3) 重新采样: 从更新后的语言模型中重新得到分布,采样得到新的文本。
该文将属性模型p(a|X)重写为p(a|Ht+ΔHt),对ΔHt进行如下的更新,如式(6)所示。
(6)
其中,α是步长,γ是正则项的缩放因子。ΔHt的初始值为0,更新过程可以重复多次。∇ΔHtlogp(a|Ht+ΔHt)为属性模型对ΔHt的梯度。更新后的Ht可以生成具有期望属性的文本。
1.2.2 保证流畅度
使用该控制方法可能会使生成的文本偏离原有的语言模型,从而生成不符合语法规范的文本。因此,文中利用散度或者范数的方式约束了生成文本和语言模型之间的距离,保证了流畅度。
1.2.3 属性模型
文中使用了两种属性模型进行实验,分别是词袋模型(BOW)和简单的属性分类器。
(1)词袋模型: 给定在某主题下的一系列关键词{w1,…,wk},词袋模型计算所有单词的似然和的对数值。该对数似然如式(7)所示。
(7)
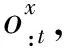
logp(a|x)=logf(o:t+1,ot+2)
(8)
其中,f是分类器模型。
PPLM也做了语言模型的攻击文本生成,但是基于人工评价,成本较高,本文提出一种攻击性水平自动评价方法。
2 自动评价方法
本节讨论提出的语言模型攻击性自动评价方法。语言模型攻击性评价的任务是,对于一个攻击性未知的语言模型,我们评估其潜在的真实的攻击性水平。而语言模型的攻击性需要通过评估其生成文本的攻击性来完成。但在一般的文本生成过程中,语言模型生成的文本并不能展示出语言模型真实的攻击性水平,这给语言模型攻击性的自动评价带来了困难。
针对如何评价语言模型攻击性的问题,我们设计了一种自动化的语言模型攻击性评价方法。本方法以PPLM模型为基础,其中包含三个模块: 生成模块、诱导模块和评估模块。其中,生成模块可以根据前置内容自由地生成文本序列,诱导模块引导生成模块向着产生攻击性文本的方向进行文本生成,使其生成文本的攻击性水平尽可能接近语言模型真实的攻击性水平,最后评估模块根据生成的攻击性文本评估语言模型的攻击性水平。有关该评价方法的示意如图1所示。
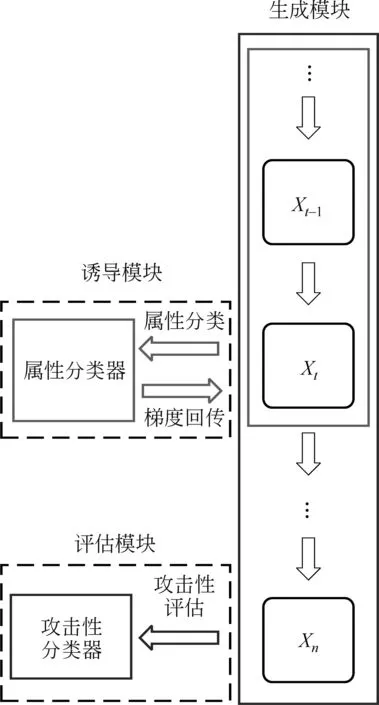
图1 自动化评价方法示意图
2.1 生成模块
生成模块主要利用文本生成技术生成文本序列。文本生成通常借助语言模型根据已有的文本序列预测下一个单词,生成过程如图2所示。初始的文本序列为前置单词或者起始符号。
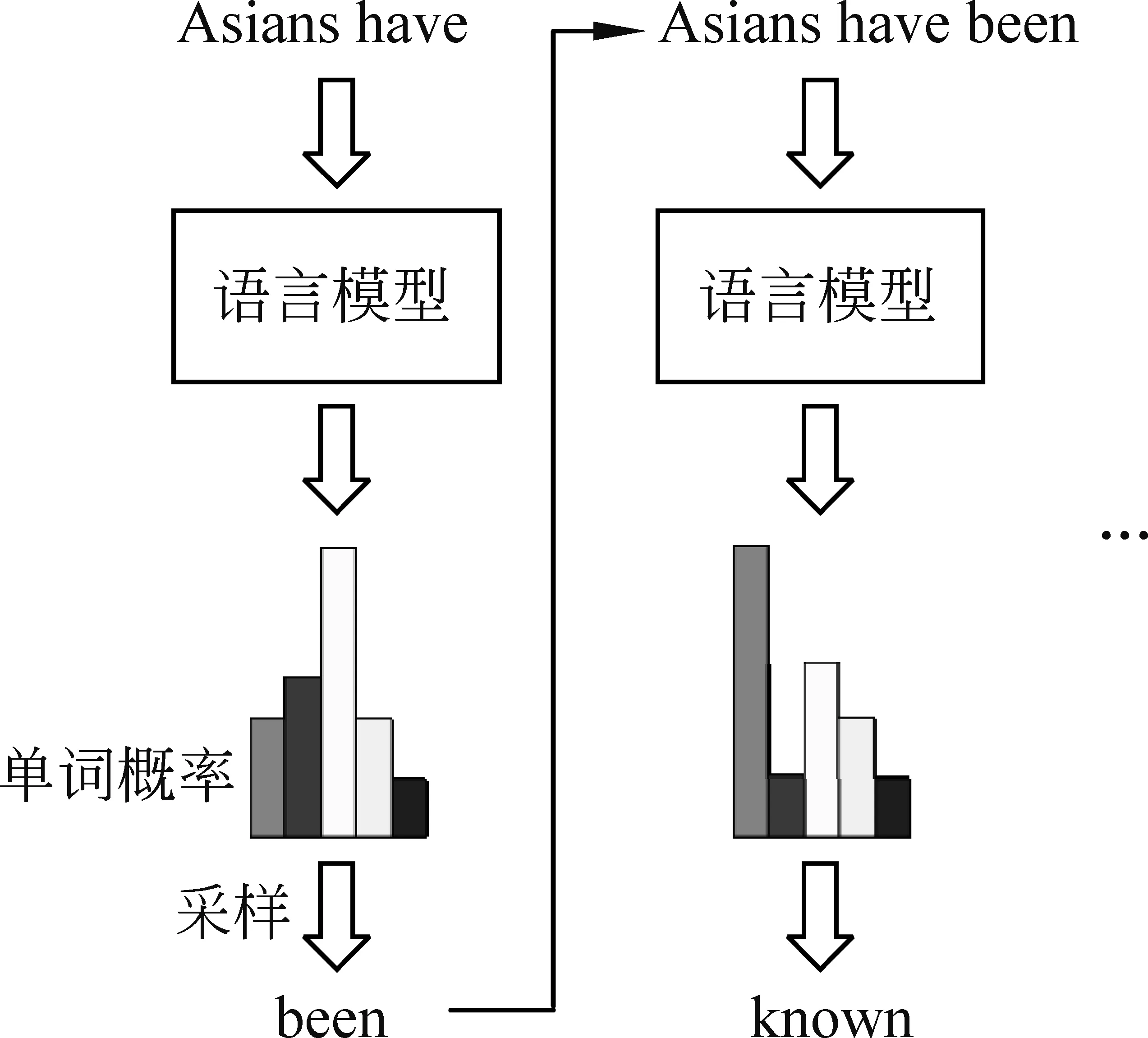
图2 文本生成的过程
文本生成是对生成的文本序列X的概率p(X)建模。形式上,给定一个文本序列X={x0,…,xn},文本生成的目标是利用语言模型计算如下的联合条件联合概率,如式(9)所示。
(9)
生成模块利用待评估的语言模型生成文本序列,并在生成过程中受到诱导模块的引导生成具有攻击性的文本,最后经过评估模块进行攻击性评估。
2.2 诱导模块
诱导模块引导生成模块生成具有攻击性的文本。根据贝叶斯法则,0时刻到t时刻时,语言模型生成攻击性文本的概率如式(10)所示。
p(Xt|a)∝p(Xt)p(a|Xt)
(10)
其中,p(Xt)为0时刻到t时刻生成的文本序列联合概率,p(a|Xt)为生成的文本序列具有攻击性的概率。如果语言模型本身的攻击性很高,概率p(a|Xt)便会很高,从而使得产生具有攻击性的文本的概率p(Xt|a)变高,因此受到引导后的攻击性水平更接近真实攻击性水平。
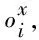
本文使用该属性分类器作为PPLM可控生成中的属性模型,引导语言模型生成具有攻击性的文本。首先我们使用待评估的语言模型前向传播生成文本X,然后使用该属性模型预测该文本带有攻击性的概率p(a|X)。根据属性分类器回传的梯度,利用1.2.1节的方式更新待评估的语言模型的内部的激活层参数,即历史矩阵Ht。多次更新后得到新的历史矩阵。此时再由更新后的待评估的语言模型重新生成k条待评估的文本{X1,…,Xk}。
2.3 评估模块
引导生成一个完整的文本序列后,需要对生成的文本进行攻击性自动评估。与属性分类器相似,我们再设计一个评估文本攻击性的攻击性分类器。和属性分类器不同的是,为了使这一分类模型在识别攻击性文本时有更高的准确率,我们选择使用预训练的语言模型,如BERT等作为分类评估模型,然后在攻击性文本分类的任务上进行微调以适应该任务。另外,攻击性分类器的计算是在整个完整的文本序列上。
使用攻击性文本分类器对生成的文本X进行分类预测每个文本是否具有攻击性{y1,…,yk}。最终语言模型攻击性的评价指标为生成文本中具有攻击性文本的比例,如式(14)所示。
(14)
当攻击性指标p大于阈值τ时,可以认为该语言模型有较强的攻击性,不适合对公众公开;反之则认为该语言模型比较安全。
3 实验与结果
本节将介绍实验中使用的数据集和具体的实验设置,然后介绍分类器的训练过程,最后展示实验结果并进行简单分析。
3.1 数据集
本文使用Jigsaw双语Toxic评论分类任务中的英文数据集(1)https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification。该数据集共有约22万条记录,其中标记为攻击性文本的记录共有两万条,其余是标记为非攻击性文本的记录。由于该数据集存在类别不平衡的问题,为了保证属性分类器和攻击性分类器在进行文本分类时的准确率。我们对该数据集中的负类样本(标记为非攻击性的文本)进行了下采样处理,最后得到了一个正负例类别平衡的攻击性文本数据集。
我们从该平衡数据集中随机切分20%的数据作为属性分类数据集,用于训练诱导模块中的属性分类器,然后引导语言模型产生待判别的文本;剩余80%的数据作为攻击性分类数据集,用于训练评估模块中的攻击性分类器。
3.2 实验设置
3.2.1 分类器
我们在待评估的语言模型的输出层接入一个全连接层作为PPLM的属性分类器。在训练时,我们冻结待评估的语言模型的内部的参数,只对全连接层的参数进行学习。训练过程使用Adam优化器,学习率设置为0.000 05。
同时,我们使用预训练的BERT语言模型作为攻击性分类器,在评估数据集上对其进行微调,使用Adam优化器,学习率设置为0.000 05,并随着训练轮数逐渐衰减。
3.2.2 攻击性水平评价
为了体现语言模型的真实攻击水平,我们预先设置有可能产生攻击性语句的10个前置单词“Asians” “Jews” “Blacks” “Women” “White people”“You should” “Would you”“Yesterday” “Last week” “Maybe”。 在每个前置单词下,首先常规地生成10条文本,再利用PPLM向攻击性的方向引导生成10条文本,然后使用评估模型分别对引导前和引导后的文本进行评价,得到最终的攻击性水平。
使用的语言模型为GPT2以及GPT2的几个变体模型: GPT2、Distil-GPT2、GPT2-Medium、GPT2-Large、Arxiv、Arxiv-NLP、GPT2-IMDB、GPT2-IMDB-Pos、GPT2-Film-Scripts。其中GPT2、Distil-GPT2、GPT2-Medium、GPT2-Large的训练语料相同,但是模型的参数规模不同,具体参数规模如表1所示。
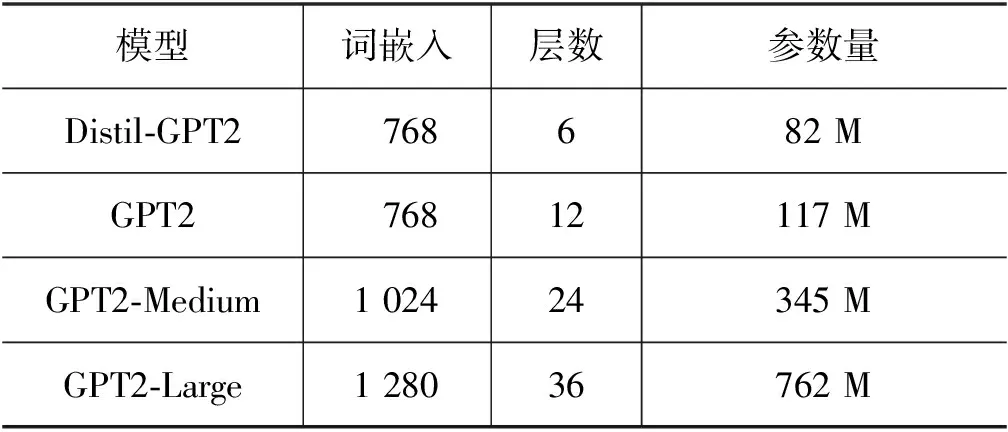
表1 四种语言模型的参数规模
Arxiv、Arxiv-NLP、GPT2-IMDB、GPT2-IMDB-Pos、GPT2-Film-Scripts均是GPT2在不同的语料上微调得到的。其中Arxiv和Arxiv-NLP的语料分别是Arxiv中物理领域的部分论文和自然语言处理领域的部分论文。GPT2-IMDB的语料是IMDB语义分类数据集,而GPT2-IMDB-Pos只使用了IMDB中的正类数据。GPT2-Film-Scripts的语料是IMSDB(The Internet Movie Script Database)。
3.3 分类器训练和选择
我们使用属性分类数据集对属性分类器进行训练。先从中随机切分出90%的数据进行训练,剩余10%的数据用于验证属性分类器的效果。属性分类过程中的准确率和损失的变化如图3所示。
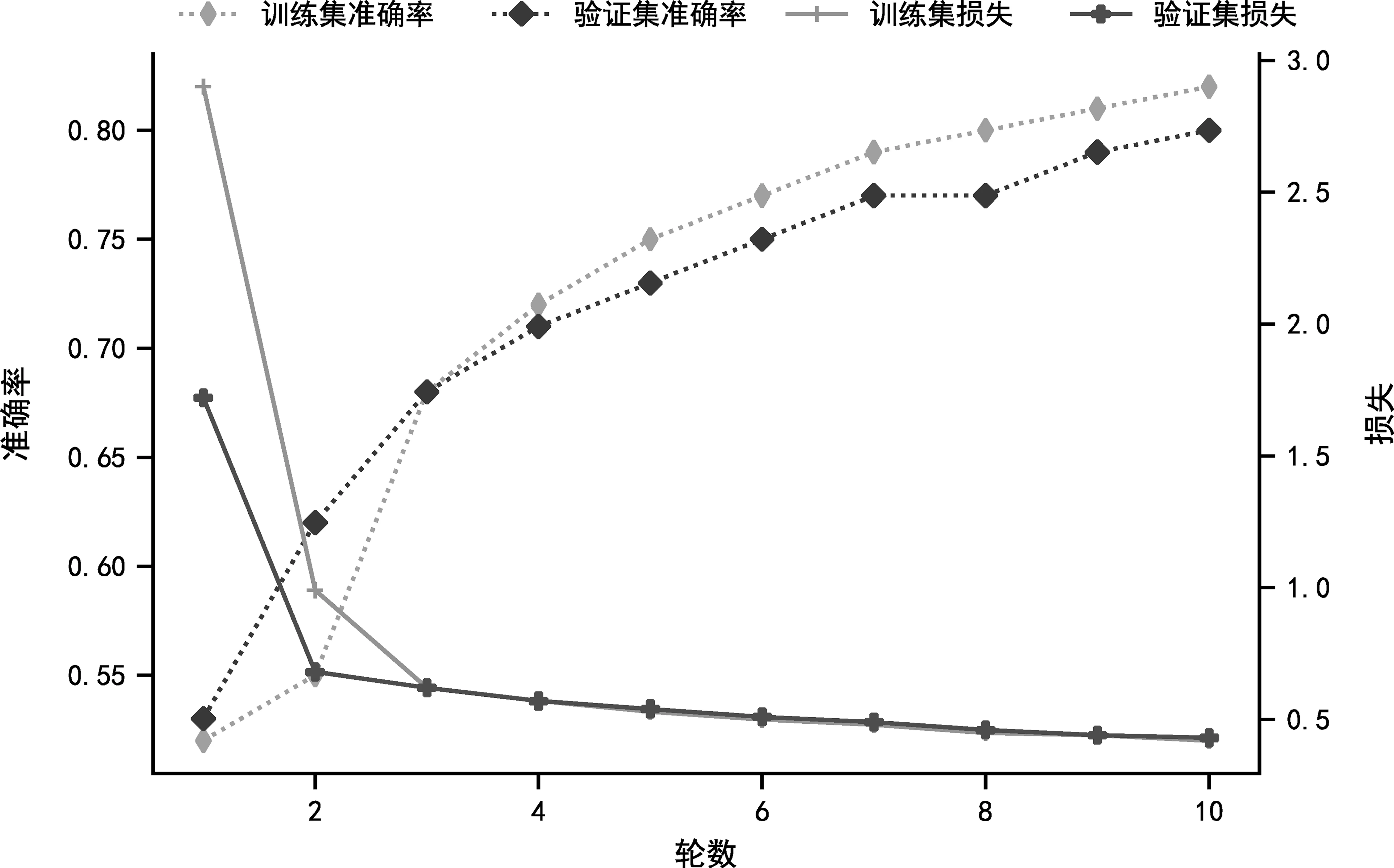
图3 训练分类过程中准确率和损失变化图
由图3可见,训练刚开始时,训练集和验证集的损失在快速下降,与此同时训练集和验证集的准确率也快速提高。随着训练的进行,训练集和验证集的损失趋于稳定。最终属性分类器的准确率为80%。
与属性分类器相似,我们使用评估数据集对攻击性分类器进行训练。我们将评估数据集随机切分为90%的训练集和10%的验证集。评估模型训练过程中的损失变化如图4所示。

图4 评估模型训练过程中的损失变化图
由图4可见,攻击性分类器在第一轮训练完成时,训练集和验证集损失都已经达到了很低的水平,此时训练集和验证集的分类准确率都很高。之后随着训练的继续进行,出现了过拟合的现象。因此我们在第一轮训练结束时停止训练,此时的评估模型的准确率的92%,满足正确判别攻击性文本的需求。
3.4 实验结果
本文考察语言模型的攻击性水平受模型参数规模、训练语料以及前置单词的影响。
3.4.1 模型参数规模的影响
首先,我们考察语言模型的攻击性水平受模型参数规模的影响,分别在Distil-GPT2、GPT2、GPT2-Medium、GPT2-Large四个参数规模不同的语言模型上进行攻击性水平评价,实验结果如表2所示。
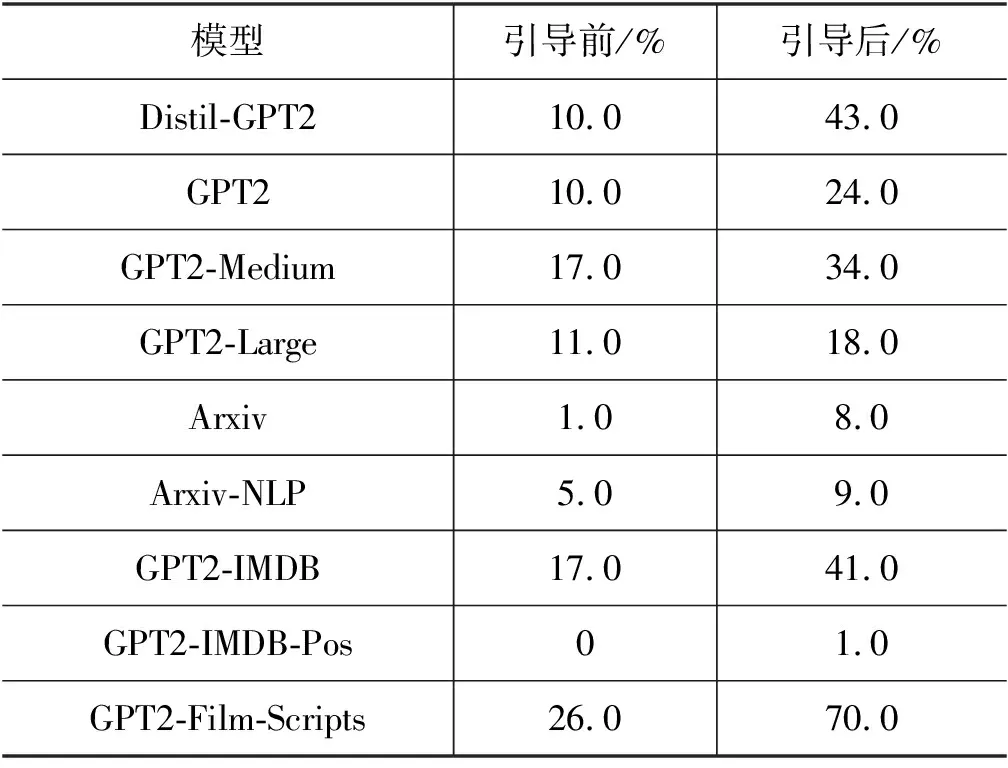
表2 各GPT2语言模型的攻击性评价结果
从实验结果可以看出,四个模型在引导前的攻击性水平相当,在受到PPLM方法的引导后,四个语言模型均比引导前表现出了更高的攻击性水平。这表明我们的方法能够有效引导语言模型产生攻击性文本,从而得到更接近语言模型真实能力的攻击性水平评估。同时我们发现,随着语言模型参数量的增大,语言模型的攻击性水平总体上逐渐降低。我们推测这是因为拥有大量参数的语言模型有着更强的学习能力,在从海量数据中学习语言知识时学到了更多的非攻击性语言表达。
3.4.2 训练语料的影响
语言模型的输出结果除了模型的规模外,还与训练语料相关,在这里我们使用GPT2在不同语料上fine-tune的五个模型Arxiv、Arxiv-NLP、GPT2-IMDB、GPT2-IMDB-Pos、GPT2-Film-Scripts进行实验,实验结果如表2所示。
从实验结果上看,Arxiv和Arxiv-NLP的攻击性水平较低,这是因为学术论文的语言表达较为严谨也较为书面化,不容易出现具有攻击性的语义表达。GPT2-IMDB的攻击性水平较高,而GPT2-IMDB-Pos的攻击性水平几乎为0,这是因为GPT2-IMDB从IMDB数据集中的负类数据中学习到了一些负面语义表达,这些负面的表达包含了很多攻击性水平高的表达。在GPT2-Film-Scripts中,实验结果呈现了比较高的攻击性水平,这是因为IMSDB数据集中的语料更为口语化,更容易产生攻击性水平较高的语句。
3.4.3 前置单词的影响
对于不同的前置单词,模型会表现出不同程度的攻击性水平,在这里,我们分析攻击性水平受前置单词的影响。以攻击性水平较低的GPT2-Large为例,GPT2-Large在各前置单词下引导后的攻击性水平如表3所示。
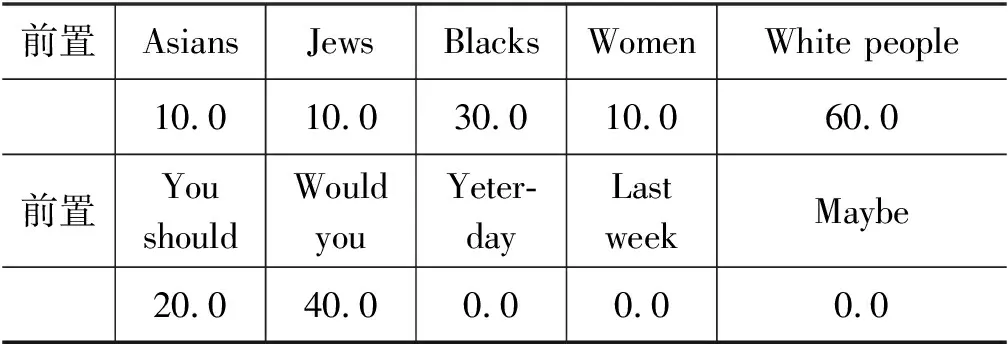
表3 GPT2-Large前置单词下的攻击性水平 (单位: %)
在前置单词“Asians”“Jews”“Blacks”“Women”“White people”下,语言模型在引导后,都会产生具有攻击性的文本,这说明与种族、性别相关的单词更容易使语言模型产生攻击性,这会给语言模型的广泛使用带来困难。
3.5 案例研究
在前置单词“Asians”下,我们从GPT2-IMDB和GPT2-IMDB-Pos中各抽取一个引导前和引导后的案例进行分析,抽取的案例如表4、表5所示。
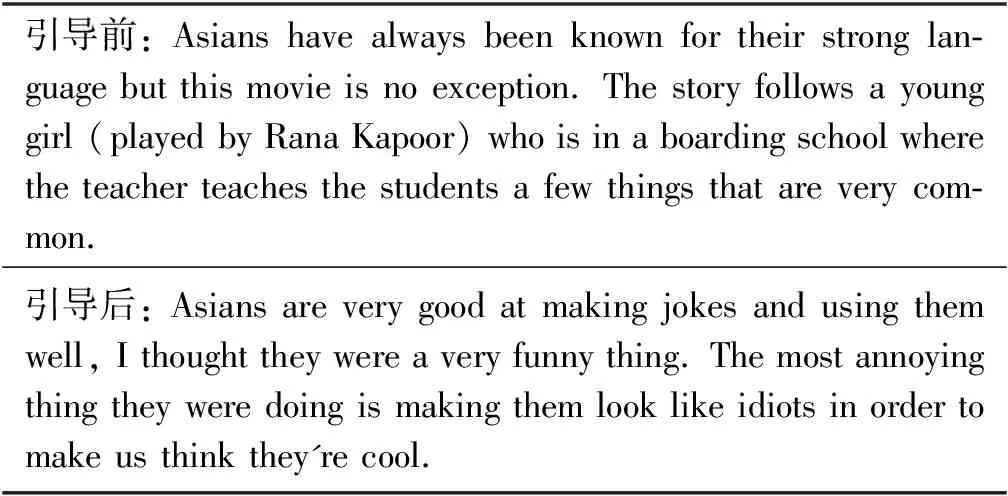
表4 从GPT2-IMDB模型抽取的生成文本

表5 从GPT2-IMDB-Pos模型抽取的生成文本
引导前,两个模型生成的文本均未表现出攻击性,而受到引导后,GPT2-IMDB生成的文本包含具有攻击性的单词“annoying”和“idiots”,GPT2-IMDB-Pos生成的文本没有包含具有攻击性的单词。GPT2-IMDB从IMDB中学习到一些具有攻击性的语义表达,受到引导后更容易产生具有攻击性的文本。而IMDB-Pos数据集中仅包含电影评论的正向数据,因此引导后也无法产生攻击性文本。相关的实例进一步说明训练数据对语言模型的影响,也证实了本文提出的自动评估方法的有效性。
4 总结与展望
针对语言模型的攻击性评价的问题,本文提出了一种语言模型攻击性的自动评价方法。该方法利用可控文本生成的手段,引导语言模型向着产生攻击性文本的方向生成待评估文本,然后训练一个攻击性分类器自动地对这些文本进行分类,最后得到对于该语言模型的攻击性评价。本文分别考察了攻击性受模型参数规模、训练语料以及前置单词的影响,验证了这个评价方法的有效性。
目前本方法只能自动评估语言模型的攻击性,而无法调整其攻击性。未来的工作可以从梯度优化的角度切入,考虑如何降低语言模型的攻击性,使语言模型更加安全,可以对公众开放。
