改进YOLO v4模型在鱼类目标检测上的应用研究
2022-03-10郑宗生李云飞邹国良王振华
郑宗生,李云飞,卢 鹏,邹国良,王振华
(上海海洋大学信息学院,上海 201306)
鱼类目标检测在渔业资源研究、鱼类知识的科学推广、水产养殖加工、稀有物种保护等领域具有广泛的应用前景[1-5]。鱼类目标检测的任务是找出图像中所有的鱼类目标,确定其大小和位置并且进一步识别其类别。目前鱼类目标检测方法主要分为两类,一类是传统的鱼类目标检测方法,另一类是基于深度学习的鱼类目标检测方法。
传统的鱼类目标检测方法是人工提取鱼类的形状、大小、颜色、纹理等特征,然后把特征向量输入到分类器中进行分类。Strachan等[6]将鱼的形状作为特征来进行分类。Larsen等[7]在鱼类形状特征的基础上加入了纹理特征,使用线性判别分析的方法对鳕鱼、黑线鳕鱼、牙鳕鱼进行分类,准确率为76%。Storbeck等[8]、White等[9]使用鱼类不同位置的高度和宽度作为特征,将测量信息和鱼类物种信息作为神经网络的输入来进行识别。传统的鱼类识别方法在形状、纹理、颜色、高度、宽度等特征上进行了尝试,但是传统方法使用的特征较少且很难对数据量大的数据集进行特征提取,存在较大的局限性。
基于深度学习的鱼类目标检测算法目前有Two-stage和One-stage两类。Two-stage检测是基于候选区域的目标检测算法,即检测算法需要分两步完成,首先生成候选区域,然后利用卷积神经网络进行分类,R-CNN[10]、Faster R-CNN[11]、Mask R-CNN[12]都是代表性的基于候选区域的目标检测算法。Qin等[13]使用主成分分析以及降维方法获取图像的特征,使用SVM(Support Vector Machine,支持向量机)进行分类,准确率提高了0.07%。袁红春等[14]把Faster R-CNN目标检测方法应用到水下鱼类种类识别中。One-stage检测是基于回归的目标检测算法,不需要寻找候选区域,使用预定义的候选框通过回归直接产生物体的类别概率和位置坐标。Xu等[15]将YOLO v3迁移到真实环境下3种不同的鱼类数据集中,获得平均0.539 2的识别准确率;徐建华等[16]在YOLO v3的基础上使用重组成与多级融合的方法进行鱼类特征提取,当置信度设置为0.5时,mAP值达到了75.1%;王文成等[17]提出了一种改进SSD的鱼类目标检测算法,准确率达到92%以上。相比传统的鱼类目标检测算法,基于深度学习的鱼类目标检测算法有更高的精度和鲁棒性,但在准确度和速度上仍然有提升的空间。
本研究基于YOLO v4网络模型,在CIOU损失函数的基础上引入新的损失项,同时在9个锚点框的基础上增加特定的锚点框,增强在特定尺寸面积上的检测效果。研究结果表明,改进YOLO v4模型在识别速度和准确率上比原模型有较大提升,在自建数据集、Fish4Knowledge数据集和NCFM (The Nature Conservancy Fisheries Monitoring)数据集上的性能优于ATSS等流行目标检测模型。
1 数据与方法
1.1 数据集
1.1.1 自建数据集
本研究建立的鱼类数据集的图像拍摄于2019年12月12日至14日实际鱼类养殖环境下,图像尺寸为1 920×1 080,共拍摄了20 h,采用视频截帧的方式每10 s截取一张图片,然后通过人工清洗,去除没有完整鱼体的图片后共计获得了3 595张有效图片,拍摄的图片如图1所示。

图1 自建鱼类数据集示例图片
1.1.2 Fish4Knowledge数据集
Fish4Knowledge数据集[18]是从水下实况视频中截取的鱼类画面,是公开的数据集。该数据集包含23种鱼类共计27 370张图像,如网纹圆雀鲷(Dascyllusreticulatus)12 112张,克氏双锯鱼(Amphiprionclarkii)4 049张,迪克氏固曲齿鲷(Plectroglyphidodondickii)3 683张,长棘光鳃鱼(Chromischrysura)3 595张以及其他19种数据量小于1 000张的鱼类。Fish4Knowledge数据集图像如图2所示。

图2 Fish4Knowledge数据集示例图片
1.1.3 NCFM数据集
NCFM数据集[19]来源于Kaggle数据竞赛平台,是公开的数据集,数据集图像由渔业监管组织安装在渔船上的摄像头拍摄,主要用来检测非法捕捞情况。该数据集共有3 777幅鱼类图像,分为8种类别,分别为鲯鳅鱼(DOL)、长鳍金枪鱼(ALB)、黄鳍金枪鱼(YFT)、大眼金枪鱼(BET)、月鱼(LAG)、鲨鱼(SHARK)、其他鱼类(OTHER)、无鱼类(NoF),其他鱼类和无鱼类图像的存在可以更好地提升训练模型的泛化性。
1.2 图像标注及预处理
本研究使用LabelImg工具对数据集进行标注,LabelImg是一款常见的深度学习图像标注软件。将每张图片上的所有鱼类用最小的矩形框标定,使用鱼类的英文名作为鱼的类别,标注样例如图3所示。

图3 自建鱼类数据集标注示意图
标注后图像中鱼类的类别和所在位置的坐标信息被保存到.xml文件中。标注完成后,编写脚本提取.xml文件中的类别以及位置信息作为模型的输入,将每个数据集以3∶1∶1的比例划分为训练集、测试集、验证集。
1.3 CIoU损失
CIoU定位损失[20]公式为:
(1)
(2)
(3)
式中:LCIoU代表CIoU损失函数值,LIoU代表真实框与预测框的交并比,d代表真实框中心点与预测框中心点的欧氏距离,c代表真实框与预测框最小闭包区域的对角线长度,v是衡量真实框与预测框宽高比一致性的参数,wgt、hgt、w、h分别代表真实框的宽度、真实框的高度、预测框的宽度、预测框的高度,α是长宽比一致的权衡函数。上式的图解如图4所示。

图4 CIoU预测框回归模型
1.4 改进CIoU损失
本研究在CIoU损失的基础上构建新的损失项,使得在回归过程中预测框和真实框的相交部分按照与真实框的长宽比相同的方式进行回归,如图5所示。
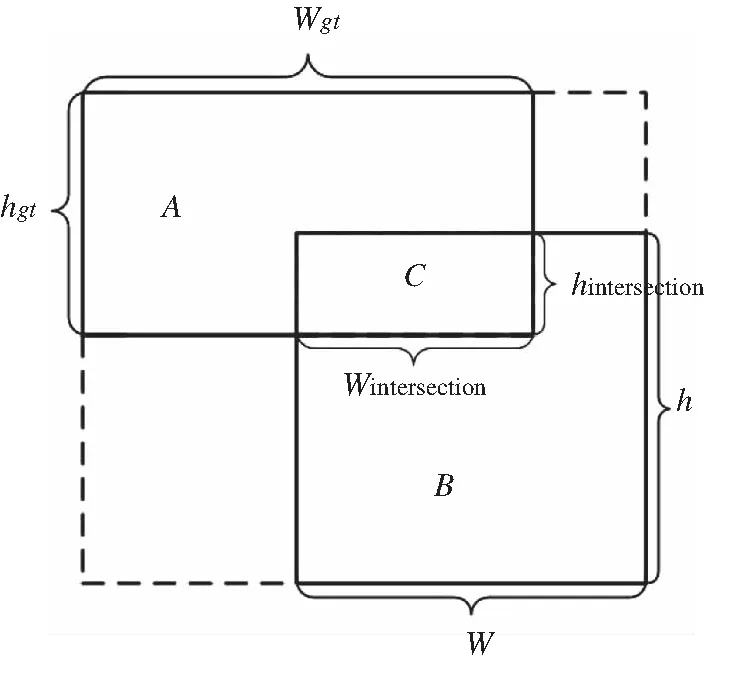
图5 改进CIoU预测框回归框模型
图5中A代表真实框,B代表预测框,C代表预测框和真实框的相交部分。本算法是使C的宽高比与A的宽高比保持一致,在回归过程中保持A和C呈相似矩形,即A∽C。
(4)
(5)
(6)
式中:Lours代表改进的CIoU损失函数值,LIoU代表真实框与预测框的交并比,d代表真实框中心点与预测框中心点的欧氏距离,c代表真实框与预测框最小闭包区域的对角线长度,v是衡量真实框与预测框宽高比一致性的参数,v1代表衡量真实框与相交框宽高比一致性的参数,wgt、hgt、w、h分别代表真实框的宽度,真实框的高度,预测框的宽度,预测框的高度,α与α1是长宽比一致的权衡函数。
当真实框与预测框不相交,即相交框不存在时,添加的损失项不起作用,即
(7)
当真实框与预测框不相交时,预测框受到其他的损失项的影响会逐渐靠近真实框,当开始相交时添加的损失项开始起作用,如图6a所示,会使预测框在靠近真实框的过程中在x轴和y轴的增量比例上保持与真实框的宽高比例相近,使预测框的宽高与真实框的宽高保持相同比例增长,加快模型收敛速度。
当预测框与真实框相交但相交框与真实框的宽高比不同时,如图6b所示,预测框受到添加的损失项的影响会先使相交框的宽高比与真实框的宽高比一致,此时在x轴上预测框逐渐靠近真实框,在y轴上预测框远离真实框,直至达到真实框与相交框的长宽比相同时这一过程结束,然后预测框会如图6a的方式进行回归。
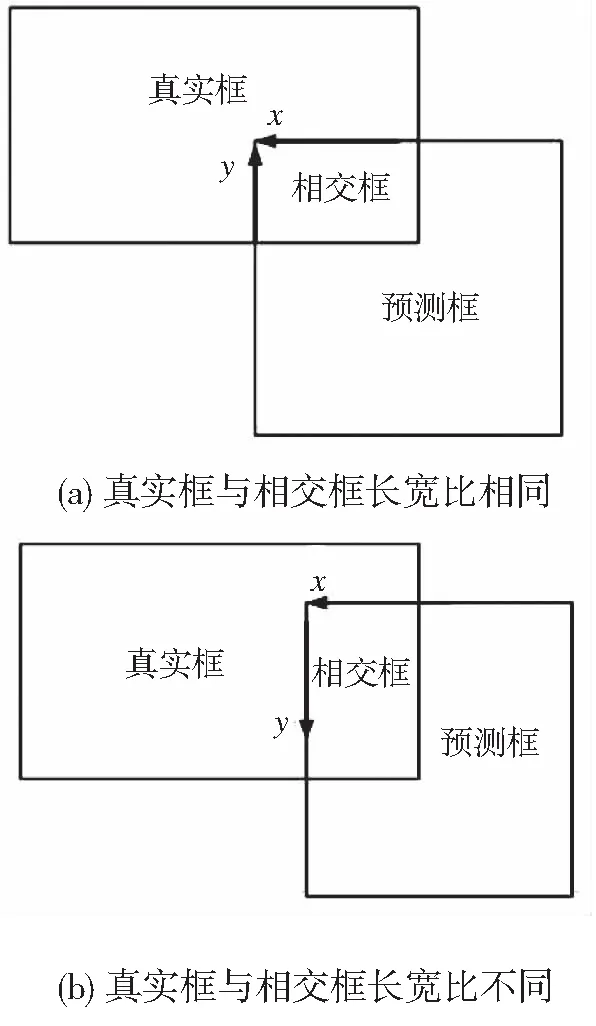
图6 改进损失函数的预测过程
1.5 损失函数
YOLO v4的损失函数包括定位损失,分类损失以及置信度损失,损失函数的公式如下。
L=Lcls+Lobj+Lcon
(8)
式中:Lcls代表分类损失,Lobj代表定位损失,在本研究中使用的是前文中的改进CIoU损失,Lcon代表置信度损失。
1.6 锚点框设置
在YOLO v4模型中存在自适应锚框,可以在训练前使用K-means算法对训练集的所有真实框的宽高进行聚类,找出聚类最集中的9组宽高作为训练初始的锚框的宽高。但本研究中的3个数据集中鱼类目标的真实框宽高比较集中,为了加强对特定尺寸面积目标的检测,本研究添加了一组宽高,使用10组宽高作为初始锚框,并且在聚类时先将所有真实框聚类为3类,将这3类中数量最多的一类再进行聚类为4类,另外两类数量较少的聚类为3类。
1.7 YOLO v4模型
YOLO v4模型[21]作为YOLO系列[22-24]算法的延续,相比于YOLO v3大幅提高了准确率和检测速度。YOLO v4模型使用CSPDarknet53作为模型的主干网络,作用是进行特征提取,CSPDarknet53网络是在YOLO v3模型的Darknet网络中融入了CSPNet(Cross Stage Partial Network,CSPNet)模块[25],并且使用了Mish激活函数[26];颈部网络主要使用了SPP(Spatial Pyramid Pooling,SPP)模块[27]以及PANNet[28](Perceptual Adversarial Network,PANNet)中的特征金字塔增强模块(Feature Pyramid Enhancement Module,FPEM),用于增强骨干网络中的特征;头部网络使用YOLO v3的头部,作用是计算损失函数以及进行归一化处理。
2 试验方法
2.1 试验环境
本研究使用的数据集制作、模型的训练与测试均在同一服务器上进行,具体试验环境如表1所示。

表1 试验环境
2.2 配置参数
本研究使用改进YOLO v4模型与原YOLO v4模型来对算法改进进行验证,为了证明算法的泛化性能,在自建数据集及Fish4Knowledge数据集和NCFM数据集两个公共数据集上分别进行了对比试验。
训练前调整模型的配置文件来适应本次试验的训练。根据服务器的GPU内存,调整每次迭代所训练图片的数量参数Batch为64,将每个Batch数量细分为批次的参数subdivisions调整为64。训练效果很大程度上受学习率的影响,如果学习率过高会导致训练难以收敛甚至过拟合;学习率设置过低,会导致模型长时间无法收敛,通过多次试验对比,发现将初始学习率设置为0.001效果较好。
由于在本研究自建数据集上只有1个类别,所以调整类别数目class为1,修改输出特征图的数量filter的值为18,由于自建数据集的数据量为3 595,训练总轮数设为3 000。
由于在Fish4Knowledge数据集上有23种鱼类,所以调整类别数目class为23,修改输出特征图的数量filter的值为30,训练总轮数设为10 000。
由于NCFM数据集上有8个类别,所以调整类别数目class为8,修改输出特征图的数量filter的值为39,训练总轮数设为8 000。
2.3 评价指标
本研究采用mAP作为检测结果的评价指标,mAP是各类AP(Average Precision)的平均值,AP是P-R曲线下的面积,其中P代表准确率(Precision),R代表召回率(Recall),AP及mAP的公式为:

(9)
(10)
式中:VAP代表AP值,VmAP代表mAP值,P代表准确率,r代表召回率,k为所有的类别数量。
3 结果与分析
3.1 检测结果展示
使用改进YOLO v4模型识别到的鱼类图像如图7所示。

图7 预测结果示例图
可以看出改进YOLO v4模型在此鱼类数据集上可以达到很好的识别效果,识别的位置大小与标注的位置和大小基本吻合。
3.2 训练时间与检测时间
在自建数据集、Fish4Knowledge数据集和NCFM数据集上每1 000轮训练所需时间与检测时间不同,但本研究算法均比原YOLO v4模型训练时间有所减少,在训练时间上如下图8所示,在自建数据集上每1 000轮减少了7 min的训练时间,在Fish4Knowledge数据集上每1 000轮减少了7 min 48 s的训练时间,在NCFM数据集上每1 000轮减少了7 min 24 s的训练时间;在检测时间上如下图9所示,在自建数据集上FPS(Frames Pre Second)提升了4,在Fish4Knowledge数据集上FPS提升了8,在NCFM数据集上FPS提升了3,完全达到实时检测的要求。

图8 训练时间对比图
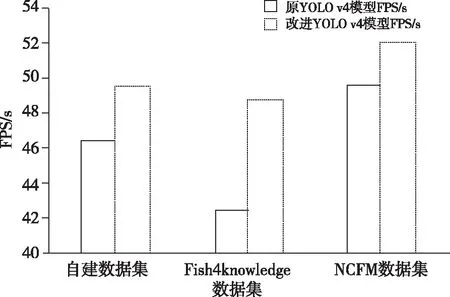
图9 检测时间对比图(FPS)
3.3 与其他模型的比较
本研究改进YOLO v4模型与原YOLO v4模型在自建数据集上的损失函数值对比如下图10所示,从图中可以看出本研究改进CIoU损失的YOLO v4模型在400-500轮之间损失值平缓,不再有明显下降趋势规划;而原YOLO v4模型的损失函数在1 200-1 300轮损失值平缓,由此可得出改进CIoU损失起到了更快收敛模型的效果。

图10 自建数据集上损失函数值对比图
为了评估模型性能,本研究与现阶段流行的ATSS模型[29]以及RetinaNet模型[30]在自建数据集、Fish4Knowledge数据集、NCFM数据集的mAP比较,结果如下表所示。
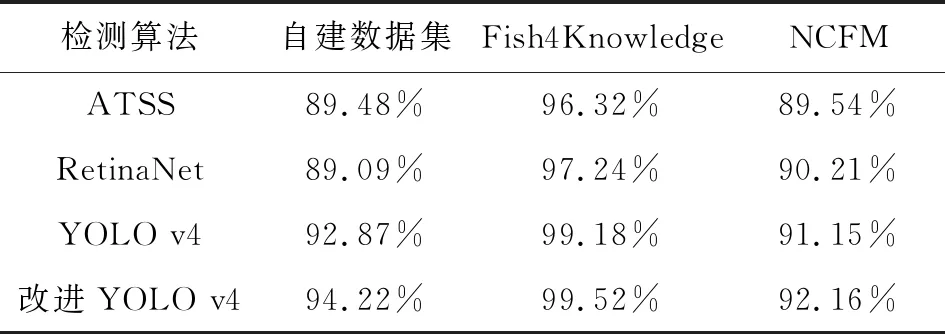
表2 自建数据集、Fish4Knowledge数据集和NCFM数据集上准确率对比
改进YOLO v4模型比原YOLO v4模型的准确率在分别提高了1.35%、0.34%、1.01%,在Fish4Knowledge数据集上提升最少是因为Fish4Knowledge数据集图片尺寸较小,鱼类目标在整张图片上占比较大且每张图片上只有一个鱼类目标,目标检测算法能在Fish4Knowledge数据集上得到较好的效果,提升空间不大。在自建数据集上提升大是因为自建数据集每张图像上的鱼类数量较多且大小差距大,预测框按照特定方式回归能取到更好的效果。
3.4 Fish4Knowledge与NCFM数据集的试验结果
在Fish4Knowledge数据集与NCFM数据集中有多种类别的鱼,在每种类别上都得到了很好的检测结果,证明了本模型在不同鱼类图像上的泛化性能。
在Fish4Knowledge数据集上,网纹圆雀鲷的AP值为99.66%,克氏双锯鱼的AP值为99.54%,迪克氏固曲齿鲷的AP值为99.71%,长棘光鳃鱼的AP值为99.57%。这几种图像数量最多的鱼类AP值均高于整个数据集的mAP,这是由于在含有多种类别的数据集中图片数量越多,模型能够获得的信息越多,检测的效果越好。
在NCFM数据集上,鲯鳅鱼、长鳍金枪鱼、黄鳍金枪鱼、大眼金枪鱼、月鱼和鲨鱼的AP值远大于其他鱼类的AP值,这是由于模型在训练时是通过标注框内的颜色、纹理等特征进行学习,找到共同点。而其他鱼类中包含多种鱼类,里面的特征复杂,难以学习到共同点,所以检测效果较差。
3.5 存在的问题
本研究算法对模糊图像的的识别结果较差,如图11所示。

图11 试验中存在的问题
左边为标注的图像,右边为检测结果,在左下角的一条鱼由于图像模糊未能被检测到。后续拟对模型进行改进,加入图像增强与去噪模块。其次本研究使用的自建数据集拍摄过程中图像质量受光源与水的浑浊程度影响较大,后续将对拍摄环境以及拍摄工具进行调整和改良。
4 结论
本研究在YOLO v4模型基础上改进CIoU损失并增加1个锚点框,在3个鱼类目标数据集上对YOLO v4算法与本模型做了对比试验,使用mAP作为评价标准。结果显示,本研究算法在准确率上比原YOLO v4算法有较大提升,能够更好地满足实际渔业应用中对鱼类目标检测的要求。本研究可以为在养殖环境下防止肉食鱼类的入侵、实时检测渔船非法捕捞等方面提供技术支持。
□
