商业建筑机电设备运行规律识别研究与实证
2022-03-08戴吉平史晨
戴吉平 史晨
1 深圳达实智能股份有限公司
2 清远市清城区住房和城乡建设局
0 引言
随着社会的发展,建筑机电系统设备量越来越大,在实际运行的过程中,存在诸多隐蔽性异常,设备的异常运行是困扰机电系统节能运行的主要问题。工程上通常是监测逐时刻能耗数据,结合数据统计法去判断找到异常。
现在信息化技术趋于成熟,建筑机电系统运行过程中积累的大量数据是设备运行经验很好的载体,结合数据挖掘技术,可用于建筑机电系统的运行优化工作[1-2]。数据挖掘的预测方法旨在通过相关性变量来预测其他变量的未知值或未知状态。描述方法旨在找到挖掘数据中隐藏的有用的知识,例如关联和聚类[3]。本文基于数据挖掘技术从实际数据中挖掘历史用能规律,通过预测机电设备运行能耗来判断实际能耗是否异常。
1 大数据分析流程
大数据分析过程包括三个步骤:数据预处理、数据挖掘、知识表达。由于原始数据中往往存在缺失、突变、不联系等问题,数据预处理是数据分析工作的不可或缺的重要环节。数据挖掘是从数据中挖掘潜在有价值的信息,常用的分析方法有:显著性分析检验、聚类和关联分析、分类预测等。数据挖掘产生的大量信息数据,如何选择、解析和利用知识来获取隐藏价值,往往存在着困难和挑战,需要利用知识表达(包括知识选择和解释) 对挖掘产生的知识信息进行分析,并将分析结果应用到策略挖掘、故障诊断和控制优化等方面。典型大数据分析流程如图1 所示。
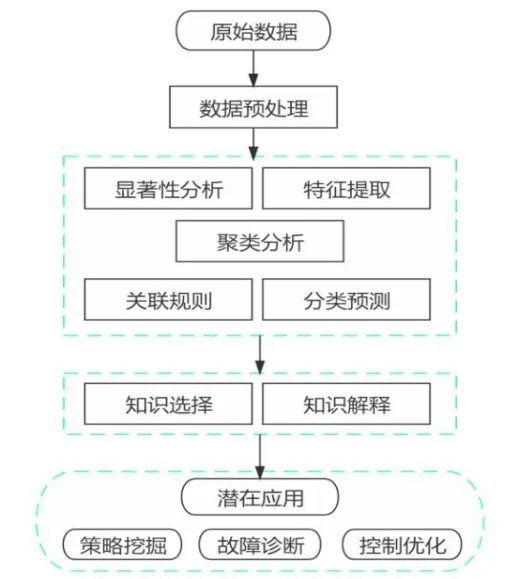
图1 大数据分析典型流程
建筑机电设备运行能耗诊断应用该数据分析流程涉及到的方法有:特征提取,聚类分析,Apriori 关联规则,结合数据统计方法,展示了其应用效果。
2 基于数据挖掘技术的机电设备运行规律识别
使用数据挖掘技术的商业建筑机电设备运行能耗诊断的方法流程主要包括以下四个步骤:数据预处理、特征分析、DBSCAN 聚类分析、Apriori 关联规则。数据预处理是提升数据质量是为了做后续数据分析的重要基础工作;特征分析是正确聚类的基础。基于室外环境数据、日期特征、聚类标签应用关联规则算法建立因子-结果对应的条件规则,获取强关联的条件规则,即识别的运行规律。
2.1 数据预处理
建筑机电系统运维平台数据库获取的历史日能耗数据有必要经过数据预处理,即去除空缺数据,去除突变数据,去除噪点数据,提升数据质量。为了保证能耗数据的可靠性及数据量,本文涉及到的预处理方法中突变数据可理解为:当前时刻点能耗值与前后时刻点能耗值都相差10 倍,或是当前时刻点能耗与前后时刻点能耗偏差值都大于额定值(额定值即逐时刻点能耗量所能达到的最大值)。同时需要考虑噪点日能耗曲线样本的影响,取统计学方法置信度95%的能耗数据样本。
基于统计学方法的机电设备日能耗数据预处理方法流程如图2 所示。

图2 日能耗数据样本预处理流程
2.2 特征分析
机电设备的用能规律挖掘实质上是日能耗曲线的识别工作,选择合适的曲线特征参数是正确聚类结果的基础。根据机电设备的类型和日能耗曲线的分析结果,特征分析主要分两个步骤:设备属性的划分,特征参数的选取。设备属性的划分本质上是区分照明、暖通、电梯、动力等类型的用电设备,可采用样本差异系数进行区分。所谓差异系数就是以样本标准差去除样本平均数其计算公式为:
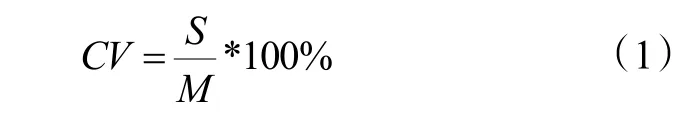
其中S为样本标准差,M为样本平均数,CV为样本差异系数。差异系数大,则代表着其数据的差异程度大。
特征参数的选取本质上是依据运行能耗曲线的特征定义,本方法选择开启时间长度、开启区间能耗均值、能耗方差。弹性设备特征选择开启时间长度、开启区间能耗均值、能耗方差。刚性设备特征选择开启时间长度、开启区间能耗均值。
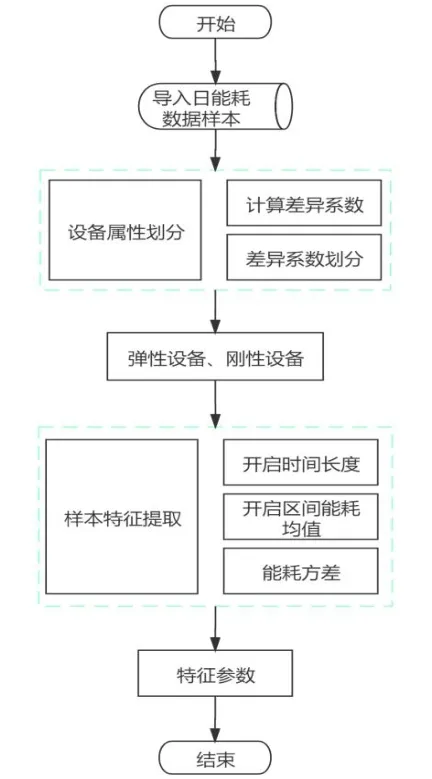
图3 日能耗数据样本特征提取流程
2.3 DBSCAN 聚类分析和Apriori 关联规则挖掘
基于 DBSCAN 聚类算法的一些优势,即不需要指定簇的个数;可以对任意形状的稠密数据集进行聚类,相对的K-Means 等相关的聚类算法一般只适用于凸数据集;擅长找到离群点。只需要输入两个模型参数即可。本文采用 DBSCAN 聚类对设备运行日能耗曲线进行类别的聚类分析。对设备的运行能耗数据进行基于数据聚类的挖掘分析,对带有分类标签的日能耗数据,室外环境数据分类标签,日期特征数据即月份、是否节假日、是否工作日进行 Apriori 关联规则的学习训练,预测未来日能耗曲线类别,即日能耗范围。
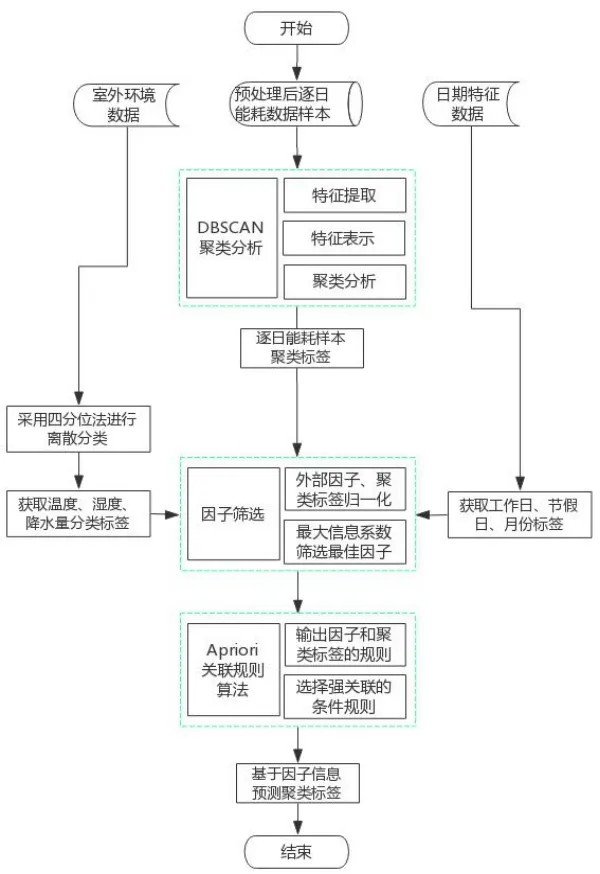
图4 基于数据挖掘技术识别设备运行规律的方法流程
从室外环境角度考虑,影响机电设备运行模式的驱动因素主要有室外温度、室外相对湿度、降水量 3 个因素,从时间角度考虑主要驱动因素有工作日、节假日、月份3 个因素。本文采用最大信息系数(MIC)方法用来检测以上影响因素与对应聚类标签相关性进行不确定性度量。
3 大型商业建筑机电设备运行规律识别方法验证
本次案例数据来源于某商业集团公司运行监测平台中的暖通、照明、电梯、动力等分项设备的能耗数据,获取到不同气候区共 12 个大型商业建筑,其2019年的逐15 分钟的日能耗数据,经过必要的数据预处理,即空缺值处理,突变数据处理,取置信度 95%数据作为本次数据分析的基准数据。
将带有聚类标签的 2019 年能耗数据样本集采用随机拆分方法拆为80%训练集和 20%测试集,测试集应用关联规则根据室外环境因子和日期特征因子得到预测的聚类标签。同时为了分析强关联规则和一般关联规则对识别结果的影响,本次将置信度大于0.8,支持度大于0.1 的规则定义为强关联规则;置信度大于0.5,支持度大于0.1 的规则定义为一般关联规则。
一般情况下测试集采用关联规则进行预测,一定程度上会出现测试集因子找不到规则,匹配不到结果,该情况下没法预测。因此可定义两个指标进行评价:即准确度和测试集匹配率。准确度即预测准确的样本数除以能够预测到的样本数,匹配率即能够匹配到的样本数除以测试集样本总数。
图5、6 表示该识别方法不同关联规则结果对测试验证结果对比情况,从结果可以看出:
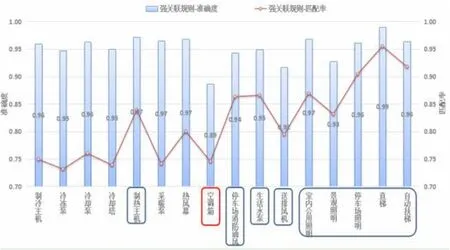
图5 一般关联规则识别验证结果
1)一般关联规则识别方法建筑机电各分项设备准确率平均为0.91,匹配率平均为0.95,其中空调箱预测的准确率低,主要是因为空调箱运行规律不明显;制热主机、停车场消防通风、生活水泵、送排风机、室内公用照明、景观照明、停车场照明、直梯、扶梯预测的准确率高,因为其属于刚性设备,其运行规律单一。
2)强关联规则识别方法建筑机电各分项设备准确率平均为0.95,匹配率平均为0.82,同上空调箱预测结果最低,刚性分项预测结果最高。
3)综合分析可知,基于数据挖掘技术识别设备运行规律的方法识别结果较好。强关联规则准确度更高,但是其匹配率会降低,出现无法预测的结果。

图6 强关联规则识别验证结果
4 结论
本文从不同类型的大型商业建筑机电系统实际运行数据出发,分析了强关联规则和一般关联规则识别设备运行规律方法的准备度和匹配度,得到以下结论,验证了该数据挖掘方法的可行性。
1)采用强关联规则方法,即置信度大于 0.80 下识别设备的运行规律准确度达到0.95,预测规律准确度高。但匹配率只有0.82,也就是说设备历史运行规律显著的样本不足,对于那一部分样本是无法匹配到历史运行规律的。
2)采用一般关联规则方法,即置信度大于 0.50 下识别设备的运行规律准确度为0.91,预测准确度下降,但是其匹配率高达0.95。也就是说,设备历史运行规律不那么显著情况下去识别,相对预测的准确度是下降的,但是大部分样本能够在历史运行中找到运行规律。
3)数据挖掘技术在机电设备运行规律识别当中具有高的识别精度,但是预测精度还依赖于关联规则算法的阈值设定。强关联规则即置信度要求大于0.80情况下,适用于运行规律单一或显著的机电设备,如制热主机、停车场消防通风、生活水泵、送排风机、室内公用照明、景观照明、停车场照明、直梯、扶梯等。一般关联规则即置信度要求大于 0.50 情况下,适用于空调箱等运行规律不显著的机电设备,或是历史数据不足的机电设备。
