面向动态数据流的三支多粒度主题建模方法
2022-03-08李昱洁杨新李妙妙李天瑞
李昱洁,杨新 *,李妙妙,李天瑞
(1.西南财经大学 经济信息工程学院人工智能系,四川 成都 611130;2.西南财经大学 金融智能与金融工程四川省重点实验室,四川 成都 611130;3.西南交通大学 计算机与人工智能学院,四川 成都 611756)
0 引言
现有的主题模型研究大多基于固定训练集和测试集的封闭世界假设(Closed-world As⁃sumption)[1-2],难以应对不断动态变化的现实世界应用场景,其中最典型的问题就是模型如何适应动态数据流的变化。在社交媒体中,随着新主题的不断出现,用过去的主题或类别数据构建的分类器可能无法有效地对未来的数据进行分类[3]。因此,为了适应现实应用场景下的动态数据流特征,必须改进封闭静态环境下的传统机器学习模型,以适应在线持续学习(Online Continuous Learning)[4]。Liu 提出了开放动态环境下的三步式在职学习(On-the-job Learning)方法[5],指出一个具备良好性能的动态学习系统应做到以下三个任务:(1)检测属于未知类别(Unseen Classes)的实例;(2)识别未知类别并收集训练数据;(3)逐步增量学习未知类别。
三支决策(Three-way Decision,3WD)理论最初由Yao[6]提出,是一种三分思维的哲学体现,也是一种复杂问题的处理机制[7-8],其核心思想是“三分而治”[8-9],即将样本划分为三个互不相交的区域(正域、边界域和负域),然后采用合适的策略处理这三个区域,尤其对不确定的边界域采取持续序贯三支挖掘方法,可以有效平衡决策过程代价和决策结果代价[10]。在不同的研究背景下,学者们对“三分”和“治略”两个任务进行具体的构造和解释,提出了大量与三支决策相关的模型和应用[11-15]。
动态数据流的典型特征之一是数据会随着时间推移不断被获取和增加。新增样本实例带来的不确定性造成传统机器学习模型不能精确分类。相对于传统二分类模型仅把样本划分到正域(POS)和负域(NEG)两个区域,在主题模型中运用三支决策思想引入不确定性区域概念,可以筛选出不确定样本,增强对模型中不确定性样本的持续处理能力。由于当前决策阶段的信息不充分或者知识不足,可能会由于不确定性而选择延迟决策,即暂时不做出决策而等待更多有利信息再进一步做出更满意的决定。因此本文基于动态数据流,运用三支决策框架建立起一个多层次多视角的粒度主题空间,采用不断持续挖掘模式逐步解决复杂动态主题建模问题。
三支多粒度决策方法强调数据动态演变中多粒度的计算与分析。本文的主要目的是运用三支多粒度学习思想构建动态三支主题模型(Three-way Multi-granularity Topic Model,3WMTM),考虑“文本-主题-单词”的粒度特征,进一步构建主题模型的多层次粒度空间,在动态变化数据流和特征空间下,研究文档主题的动态演化机理,进一步探索新文档集合影响主题变化的潜在方式。最后利用中文和英文的语料库验证所提模型的有效性,并与多个基准模型进行对比。
1 相关概念
1.1 粒计算与三支决策
三支决策是由决策粗糙集理论拓展出的一种不确定性决策方法。Yao[8]提出的TAO(Trisecting-Acting-Outcome)模型主要考虑了三个相关问题:(1)如何从整体上划分三个两两不相交的区域;(2)如何设计策略来分别处理这三个区域;(3)如何评估策略的有效性。
粒计算是一种规范化的问题求解范式,主要研究不确定性复杂问题的多粒度、多层次和多视角处理与计算。考虑到粒计算的特征层次性和信息递增性等特点,Yao[7-8,12]将粒计算思想引入三支决策理论中,提出了粒计算的三元论和三支粒计算概念,并进一步设计了能在多层次粒度特征空间下逐步实现问题求解序贯三支决策框架,以得到平衡代价后的合适决策。序贯三支决策是基于三支决策构建的动态决策方法[11-12],从粒计算的角度,采用“自上而下、化繁为简”的分治策略,形成粒度由粗到细的多层次序贯过程。在多层次、多视角、多用途的粒状结构下,可以构建一系列描述空间和评价函数,在不同粒度结构层次上实施一系列的三支决策。例如,在粒度较粗的级别上它可以快速地对某些对象做出判定成正例或负例的决定;而将其余的对象视为不确定对象,并在更细的粒度上对他们进行进一步观察以做出决策。序贯三支决策的优势在于决策过程代价小,决策效率高。只有当信息的细节足够支持决策精度的情况下,才能做出一个明确的决策。这样的决策方式是符合人类认知决策的基本原则,这也是序贯三支决策框架的核心。
1.2 开放动态环境
传统机器学习研究主要基于具有确定性的条件和封闭世界假设[16],这意味着在测试集中出现的类别一定是训练集中已知的,并且样本实例的特征空间是固定的,但这些假设难以支撑现实场景当中具有不确定性、动态变化等特征的问题。
所谓的开放环境,是指应用环境可能包含之前没有过的新事物和新场景。此时需要开放式学习[5,17],能够在应用过程中检测出没有出现过的类别实例,不需要重新训练便能逐步学习以更新现有模型。Liu等人提出一个具备良好性能的开放动态学习系统,并且能够做到以下三个任务[3]:
1)该系统在某个特定的时间点获取了新的测试集后,能够基于过去N类的数据DP={D1,D2,…,DN}及其相应的类别标签YN={l1,l2,…,lN}构建一个多分类模型 FN。FN识别在先前训练集中已出现的样本(Seen samples)并将其分至已知类别li∈Ni;同时也能识别在先前训练集中未出现的样本(Unseen samples),它拒绝这些样本并将它们放入一个拒绝集合R中,这个集合可能包含测试集中一个或多个新的未知类别的样本。
2)识别在集合R中隐藏的未知类别C(Hid⁃den unseen classes),并为其收集训练数据。
3)假设C中有k个新类别,并且有足够的训练数据。该系统能够逐步学习这些新的类别,并将现有模型更新生成新的模型FN+1。
为了使机器学习算法具有更强的鲁棒性,其必须能够适应开放的、动态变化的环境,典型问题之一即如何适应动态数据流的变化,例如样本(数量、分布等)、属性(值、数量等)和新类别的出现。在实际应用场景下,数据往往不是一次性全部得到的并且具有很强的不确定性,这就要求机器学习算法能够在开放环境中动态地识别并学习这些变化。因此,这给机器学习模型的研究和发展带来了更大的挑战和更广阔的应用前景。
1.3 主题建模
在主题模型中,主题可以看成是单词所构成的概率分布。主题模型通过单词在文档中的贡献信息抽取出语义相关的主题集合,并将词向量空间中的文档变换到主题空间,得到文档在低维空间中的表达[17]。由于主题模型具有强大的信息挖掘能力,多用于研究主题提取、主题演变、信息挖掘和推荐系统等文本分析方面,而在图像识别方面则被广泛应用于解决图像处理任务中的语义分割、目标检测、场景分类等问题。
主题模型最早起源于隐性语义索引(La⁃tent Semantic Indexing,LSI),其基本思想是通过奇异值分解(Singular Value Decomposition,SVD)构建一个新的隐性语义空间,将文档变换到新的空间中从而找到更低维的表达。Hof⁃mann[18]在LSI的基础上提出了概率隐性语义索引(Probabilistic Latent Semantic Indexing,pLSI)。Blei[1,19-20]提出的隐狄利克雷多项式(Latent Dirichlet Allocation,LDA)在 pLSI的基础上进行拓展,成了主题建模中最为经典的常用模型。LSI能够揭示文本的潜在语义结构,该方法已被广泛应用于数据挖掘和文本处理中。概率主题模型通过主题分布中的潜在变量,为构建主题模型提供了强大可靠的理论基础。近年来出现了越来越多基于特定场景和任务相结合的概率主题模型[18],然而传统的概率主题模型基于LDA分布假设的主题模型可能不适用于利用条件信息(Conditional Informa⁃tion)捕捉主题依赖度,并且推理方法也变得异常复杂。近年来,深层神经网络在学习无监督模型的复杂非线性分布方面显示出的巨大潜力,越来越多学者也关注到了此类问题。随着变分自动编码器(VAE)(例如NVDM,ProdLD和NTM-R)的出现[21-23],深度神经网络也已经成功用于主题建模。
2 基于动态数据流的三支多粒度主题模型
本节详细介绍了基于动态数据流如何构建运用三支多粒度学习框架的动态主题模型。
2.1 动态多粒度结构
现实世界应用场景下的数据通常是以数据流的形式不断累积的,具有动态不确定性特点。如果一个决策需要等待所有信息收集完毕,那么其时间成本将是巨大的。若能够在多个时间段对应的多个粒度空间下对当前具有较高置信度的样本做出即时决策,总体决策代价就可以大大降低。因此构建动态多粒度结构有利于文档数据的高效持续挖掘处理,以便于刻画和发现主题模型中随时间波动的主题演变机制。
目前已有多粒度计算研究主要基于数据和模型两类方法来构建多层次粒度结构。基于数据的方法主要考虑样本数量的变化和数据特征的变化。基于模型的方法主要包括两种形式:(1)组合不同模型,并表达和捕获更优粒度;(2)调整模型参数,增强参数对数据的粒度优化控制。
主题模型的多层次粒度结构通常可由“文本-主题-单词”三种因素交互组合生成,其中不同的主题粒度会对主题模型的决策质量产生不同影响。本文使用pyLDAvis构建可交互性主题模型可视化结果,展示了不同主题词数量下的文本语料(20-Newsgroups dataset)主题分布情况,通过LDA主题模型,将所有文档映射到主题分布和相应的词汇分布中。如图1所示,对于同一段文本文档,图中左侧上下两图分别表示主题词数量设定为10和20的主题分布情况。图中的每个圆都代表着一个主题(以topic1为例),单个圆圈面积越大表示该主题在文本中分布越广,而圆圈之间重叠面积越小则该主题多样性越高。主题模型的粒度结构会随着主题个数变化而变化。从图1中的(a)图和(b)图中可以看出,当主题词从10增至20时,特征空间的粒度不断细化、单个主题词的分布性下降、多个主题词之间的重叠面积增加;用于表示主题词的词汇及其分布会随着粒度的变化而变化(以topic 1为例)。因此,基于动态文本数据流,如何在合适的粒度下构建相关的评价指标和决策规是本文重点研究的问题。

图1 主题词分布图:(a)主题词个数为10;(b)主题词个数为20Fig.1 Distribution map of subject words:(a)Ten subject words;(b)Twenty subject words
基于以上分析,本文通过融合数据和模型两种粒度构建方法,运用时间序列数据和主题模型的“文本-主题-词汇”的层次结构获得动态主题建模多粒度结构,在三支多粒度学习框架下不断动态更新主题模型来分析和处理文档的语义信息。
2.2 三支多粒度主题建模方法
本文采用语义连贯性和主题多样性(Topic Diversity)作为检验主题模型决策质量指标;采用决策时间作为评价主题模型的时间代价的指标。语义连贯性被定义为人们对N个用来表示主题词的单词的理解程度。这里使用了3种不同的语义连贯性测量指标:CV,Cword2vec和CNPMI。
CV是基于点互信息(PMI)构建的评价指标,它是文本中单词相关性的一种度量,其定义见式(1):
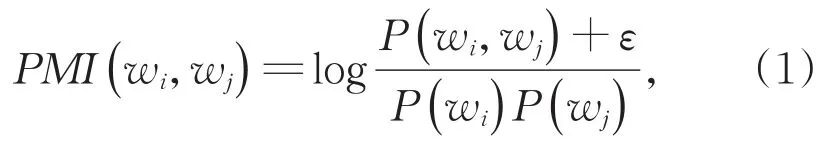
其中,P(wi)是在该文档中出现单词wi的概率,P(wi,wj)是在该文档中同时发现单词wi和wj的概率。Cword2vec使用Word2vec模型的相似度特征来计算用于表示主题的词汇语义连贯性。其中,同一个主题下的词汇应存在较高的相似性,反之则较低。据此,式(2)定义了主题内词相似性(intra topic sim⁃ilarity),式(3)定义了主题间词相似性(inter topic similarity):
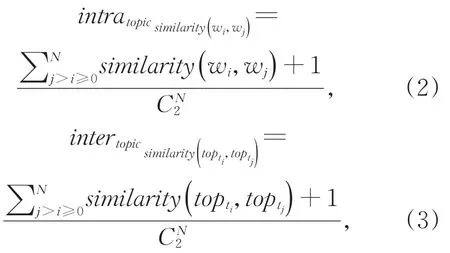


其中,主题内词相似性(intra topic similarity)和主题间词相似性(inter topic similarity)分别由式(2)和式(3)给出。
最后,语义连贯性也可以通过标准化点互信息评分(NPMI)来定义,NPMI能比非标准化点互信息评分(PMI)提供更多主题排名的信息。CNPMI的定义如下:
NPMI通常用于判断两个变量是否有关系以及关系的强弱程度。其中,P(wi,wj)表示词wi,wj共同出现的概率,P(wi)则表示单个词语出现的概率。ε是平滑因子,通常取一个很小的数值。
最后,根据主题模型评价指标的特征,综合时间代价和主题多样性构建评价函数fn[divn(x)]。其中,时间代价使用每个阶段输出时所需要的时间进行度量。具有高度主题多样性的文本文档通常被认为主题丰富;而主题多样性较低的文本文档则被认为主题较为单一。主题多样性的构建考虑文档中的单词分布、文档中的主题分布和主题中的单词分布,在给定T个主题时,我们定义文档d的主题多样性如下:
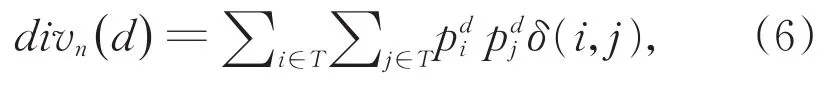
由于较早阶段的数据所含信息较少,因此需要根据不同的决策阶段设定不同的阈值,阈值 (αj,βj)用于阶段 j 的决策判定:当评价函数值大于αj时,则认为在此阶段通过现有文档学习到的主题具有较高的语义连贯性和主题多样性,将该主题放入正域(POS)中;当评价函数值小于βj时,放入负域(NEG)后续不再进行处理;当评价函数值在阈值(αj,βj)之间时,则认为此阶段通过现有文档学习到的主题仍需要补充信息以提高语义连贯性和主题多样性,放入边界域(BND)中,作为下一阶段的待处理文本。随着粒度的细化和信息的增补,在三支多粒度决策的每一个粒度层都会根据决策质量更新阈值,从而BND中的样本也随之减少。


图2展示了3WMTM的模型框架,在该模型中有三个主要步骤:

图2 3WMTM模型示意图Fig.2 Diagram of 3WMTM model framework
1)将第k阶段的新数据和第k-1阶段的边界域(BND)内的数据作为第k阶段的输入;初始化三个域,使用第k-1阶段已经更新的阈值(αk,βk)作为参数初始化;
2)动态训练主题模型,并根据决策规则划分正域、负域和边界域,更新下一阶段的阈值(αk+1,βk+1);
3)循环上述过程;
4)若此时已到达决策分类的最后阶段n,则该阶段的新数据和第n-1阶段的边界域(BND)内的数据以及前n-1个阶段内负域(NEG)内的数据合并作为该阶段的输入;再次初始化三个域,并只考虑单个阈值,即αn=βn=0.5进行决策。
3 实验
3.1 数据集
本文采用两个数据集:THUCNews中文文本数据集和对话数据集CDD。中文文本数据集THUCNews是根据新浪新闻RSS订阅频道2005-2011年间的历史数据筛选生成,包含74万篇新闻文档(2.19 G),在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。选取该数据集中新闻标题数据,经过数据去重和筛选后剩余10 000条短文本数据。中文对话数据集CDD是从Daily Dialog数据集翻译而来,包括12 336条多轮对话文本,平均长度142字。使用Hanlp进行分词和去除停用词。
3.2 实验设置
为了保证实验设计的公平性,3WMTM方法和传统静态方法都使用相同的语料(Wikipe⁃dia数据集)进行预处理,且均使用Word2vector作为训练词向量方法,训练epoch均为300。实验数据模拟了现实环境中数据流的特征,将数据集随机拆分成5份,每个阶段依次补充一份,新数据包含Unseen样本实例。实验分别对比了动态环境下和传统静态环境下的主题模型。在动态环境下采用3WMTM方法;在静态环境下,由于不需要考虑模型阈值划分,在每一阶段仅使用相同的数据集,在最后阶段取平均值。五个阶段采用不同的阈值 (αj,βj),其中,α1≤α2≤α3≤α4≤α5,β1≥β2≥β3≥β4≥β5。表1展示了实验中各个阶段所取阈值。
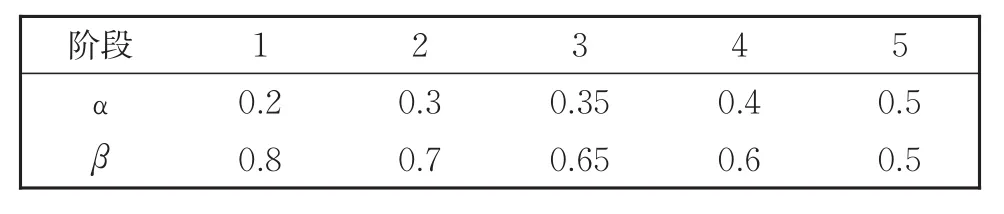
表1 各阶段阈值Table 1 Thresholds of each stage
3.3 对比方法
本文使用深度神经网络主题模型ETM(Embedded Topic Model)和 W-LDA(Wasser⁃stein Auto-encoders Topic Model)作为基础模型。ETM将“主题-词”分布矩阵分解为主题向量和词向量的乘积,主题向量和词向量通过与主题建模过程联合训练获得,该模型可将主题向量和词向量放入同一空间中来提高主题的可解释性。W-LDA实际上是一个对隐空间施加约束的自编码器,该模型将隐变量的先验分布假设为Dirichlet分布,在Wasserstein距离下对变分分布进行优化,该模型可以极大地缓解KL崩塌的问题,以获得语义连贯性更高的主题。实验对比了动态环境和静态环境下基于深度神经网络主题模型的实验效果。
3.4 实验结果
表2和表3分别展示了ETM和W-LDA采用3WMTM方法和传统静态方法模型的对比实验结果。结果表明对比传统静态方法,3WM⁃TM方法能够随着新数据的补充,在更早阶段有效提升主题多样性,降低决策的时间成本。在最终决策阶段,3WMTM方法也能够比静态模型取得更好的效果。图3至图6展示了在不同主题个数的粒度下各个评价指标随动态数据变化情况,每幅图内从左至右依次为主题词个数为10、20和30的情况,其中横坐标表示的是动态数据流递增情况(用百分比表示),纵坐标表示的是各个指标的值。实验结果显示,文本信息不断增加使主题多样性逐步显著提高;语义连贯性也能在各个阶段保持稳定;随着主题粒度的不断细化,在较细粒度的主题特征空间中,主题多样性提升速度更快。该实验结果进一步表明,使用3WMTM方法能够有效改进主题模型在动态环境下持续挖掘语义信息的能力,主题多样性显著提升。同时,动态模型能够在每个决策阶段立即给出判断,因此比静态模型更有效地提升了决策效率。

图3 ETM动态模型指标变化(THUCNews-10K数据集)Fig.3 ETM dynamic model index change(in THUCNews-10K data set)

图4 ETM动态模型指标变化(CDD数据集)Fig.4 ETM dynamic model index change(in CDD data set)
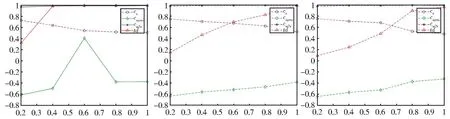
图5 W-LDA动态模型指标变化(THUCNews-10K数据集)Fig.5 W-LDA dynamic model index change(in THUCNews-10K data set)

图6 W-LDA动态模型指标变化(CDD数据集)Fig.6 W-LDA dynamic model index change(in CDD data set)

表2 ETM动态模型和静态模型的对比Table 2 Comparison between ETM dynamic model and static models

表3 W-LDA动态模型和静态模型对比Table 3 Comparison between W-LDA dynamic model and static models
4 结论
本文面向动态数据流运用三支多粒度学习思想处理动态文本主题建模的不确定性,构建动态文本数据的多层次、多视角和多用途粒度结构以及一系列描述空间和评价函数,从而实现对动态文档主题的持续学习。同时,考虑主题模型的多粒度特征,探究“文本-主题-词汇”的粒度参数演化机理,在主题不断新增背景下自适应更新阈值。实验结果表明,3WMTM算法在动态环境下能够维持较好的决策精度,即统计上无显著差异;并且3WMTM算法能够在每个决策阶段立即给出判断,因此在决策成本上优于现有模型。
如何让模型能够在开放动态环境下学习是一个非常重要的研究课题,在机器学习算法实践和理论方面都具有重要意义。本文考虑数据流随时间变化的场景,并设计了行之有效的算法框架。但是如何从理论上分析具有分布变化和属性变化的流数据可学习性质仍然是一个重难点问题。并且,动态数据流的时空特征也会不断变化,如何刻画时空多粒度特征[24-25]也是亟待进一步研究的问题。
