基于特征选择的微博水军识别研究
2022-03-07武晓丹
武晓丹
(太原师范学院 计算机科学与技术学院,山西晋中,030619)
关键字:Twitter;特征选择;Scikit-Learn库;特征提取
0 引言
随着互联网的发展,诸如推特(Twitter)、新浪微博(Sina Weibo)这样的新社交媒体也随之发展起来。作为全球最具影响力应用程序之一的Twitter在其2022年第一季度的收益报告中表示,其日活跃用户数达到2.29亿,这一数字在上一季度是2.17亿。Twitter这样的微博平台作为互联网时代人们进行沟通的重要工具,为用户快速交流提供便利,因此受到越来越多人们的关注。但是Twitter的这些特点也给“网络水军”提供了活动场所。水军会通过虚假意见的广泛传播引导舆论,人为控制事件走向,从而达到自己的目的;同时大量水军的存在也会导致微博内容的真实性降低,质量下降,严重影响普通用户的使用。由于水军的存在给Twitter等微博平台带来很多不稳定的风险。因此,如何在Twitter中准确识别水军,还给网络世界一个安全稳定的环境,成为微博热点研究中一个亟待解决的问题。
随着水军反检测能力越来越强,之前从传播学角度定性判别水军的方法难以达到理想效果,易于形成识别漏洞。因此,本文通过不同数据集以及Scikit-Learn机器学习库中分类算法训练分类器,并以此得出具有较好分类效果的特征和机器学习算法。
1 相关研究
目前,随着网络的飞速发展以及自媒体时代的到来,微博作为分享交流信息的平台,受到很多喜爱。关于微博的研究方向有很多,水军发现也是近年来微博研究中的一个热门话题。
国外学者陆续展开相关研究,Yard[1]等分析研究了Twitter的发展历史,通过链接URL以及账户名称规律性等特征识别垃圾邮件用户。Stringhin[2]等通过创建Twitter用户行为分析模型,从而区分出垃圾用户与普通用户。Amlesh-wara[3]等分析特征后建立Twitter用户识别模型CATS,并证明该模型对于少量数据也有很很好地识别果。Zhang等通过分析Twitter中含有链接URL的推文以及其对应账户的特征来区分水军用户与普通用户,并利用机器学习方法来检验其结论。
国内对微博水军最早的研究出现在2010年。谢忠红等指出网络水军的定义并分析其特点,总结出8个基于用户属性的特征并训练逻辑回归算法,最终实现水军的识别。莫倩等研究正常用户与水军用户的社交网络关系,发现其形成的社交圈有很大不同,具有不平衡的粉丝关注比。程晓涛等则在此基础上加入“用户是否认证”这一特征,并且分析用户属性特征和行为特征,提出基于关系图特征的水军账号识别方法。韩晴晴等综合分析微博用户的多种特征,总结出6个属性特征集并且考虑实际中有标记数据少无标记数据多,利用半监督协同训训练类器识别微博水军。
微博水军的研究已经得到社会各界的广泛关注,所以如何精准且高高效地识别军是一个具有很大挑战的事情。目前大多数研究有些侧重于单个水军所发推文的检测,有些则侧重于水军账号的检测,本实验重点是前者。
2 特征选择方法
特征选择是特征工程中的重要环节,其目的是提升模型效果,提高运行速度。本实验采用相关性检验中的卡方检验,这是特征选择中的Filter过滤法,其思想是研究特征与标签之间的关联性,根据对特征进行统计检验之后得到的分数,从而筛选出相对无用的特征,挑选出最相关的特征。即对特征赋予权重,权重代表着特征的重要程度,对权重进行排名。如图1所示。

图1 Filter过滤法
卡方检验chi2是专门针对分类问题的一种独立性检验,它是先假设两个变量互相独立,然后再观察实际值与理论值的差距,若差距足够小,则原假设成立。即计算特征与标签之间的卡方统计量,并以此为依据将特征从高到低排名,再计算卡方值对应的p值,以0.05或者0.01作为阈值过滤相应的特征,从而可以去除最独立于标签,与实验目的无关的特征。
卡方检验的计算公式为:
其中,A为实际值,T为理论值。
3 实验与分析
3.1 数据集
对Twitter水军的属性特征进行分析,发现与普通用户相比,水军由于是为某些目的性因素而出现,例如炒作、宣传、引导舆论之类,其对于自身账户的经营比较少,因此Twitter水军往往具有较少的粉丝数以及较多的关注数。而且Twitter水军账户对其他用户较为关注,它的收藏、回复和转发数都比较高。此外Twitter水军为了让更多的人浏览到自己的推文,经常会带热门话题(#)发文,或者是常常提及(@)其他用户引起关注,再或者是在自己的推文中使用较多的带有目的性的链接(URL),例如广告、钓鱼网站之类,因此水军推文包含的话题标签数、URL链接数、用户提及数都会比较高。
本实验在3个数据集上进行训练和测试。数据集如下:
(1)第一个数据集来自Chen chao等人采集。这个数据集具有现成的特征集。特征信息如表1所示。
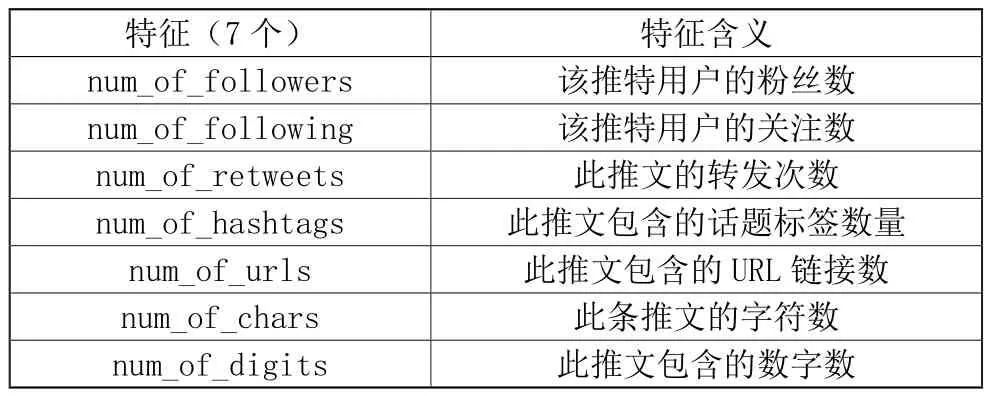
表1 数据集1的特征选取信息
(2)第二个数据集来自Kaggle竞赛。这个数据集提供Tweet文本,以及Tweet帐账户的些特征,因此能够手动提取特征集。本实验提取的特征集如表2所示。
(3)第三个数据集来自Chen Weiling等人采集。这个数据集原是带有标签的Tweet ID列表,Weiling Chen等人通过Twitter API密钥,检索出推文得到数据集,因此也能够提取其特征。本实验提取的特征集与数据集2提取的相同,也如表2所示。
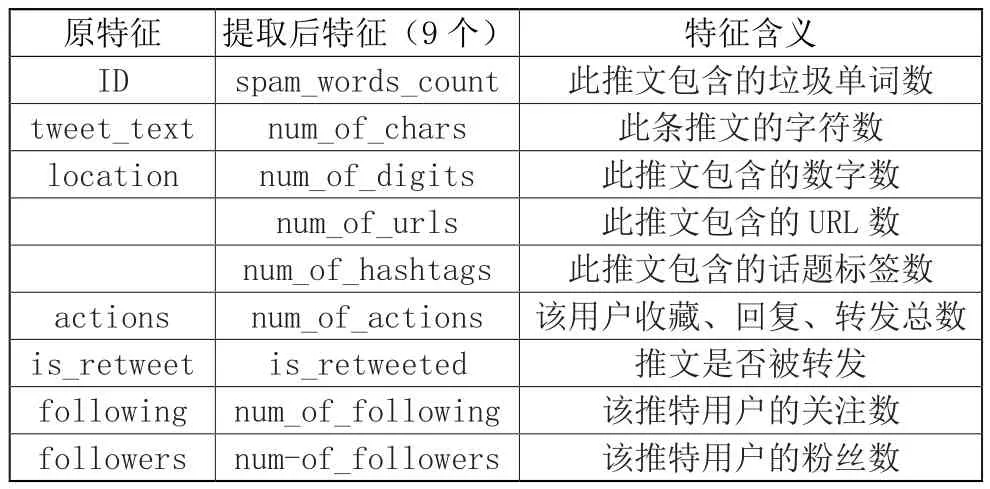
表2 数据集2、数据集3的特征选取信息
由表1和表2可以看出,数据集2、3所提取的特征与数据集1的特征相同,并在此基础上多提取出两个特征,分别是“actions”和“spam_words_count”。
3.2 特征选择与评价
对特征与标签进行相关性检验能有效选择出具有高区分度的特征。卡方检验在二分类问题上非常有效。卡方检验,又称χ2检验,它是测量特征与标签的相关性,相关性大的特征则认为与标签的区分度好,相关性小的特征则认为其对于水军的区分度差。
如图2所示是数据集1的特征进行卡方检验的分数排名直方图,可以看出,排名前三的特征分别是“粉丝数follower”“转发次数 retweets”以及“关注数 following”,即这三个特征与标签的相关性较大。
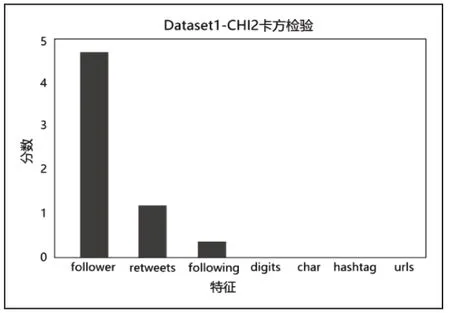
图2 特征集1的卡方检验
如图3和图4所示是对具有相同特征集的不同数据集进行卡方检验,即对数据集2和数据集3进行相关性检验。图2表示数据集2的卡方检验得分排名情况,其得出的主要特征是“粉丝数 follower”,“关注数 following”,“收藏、回复、转发总数actions”。图3表示数据集3的卡方检验得分排名情况,得到的有效特征同样如此,主要特征是“follower”,“actions”以及“following”。因此对于本实验数据集2和3,贡献比较大的特征主要是“粉丝数”“关注数”以及“收藏、回复、转发总数”三个特征。

图3 特征集2的卡方检验

图4 特征集3的卡方检验
3.3 性能评价指标
针对水军的特性,本实验采用准确率Accuracy等评价指标来评估模型。对于水军不平衡分类问题,本实验引入了混淆矩阵,如表3所示。

表3 混淆矩阵定义
其中有Positive、Negative、True、False四个概念,P表示预测类别为1,N表示预测类别为0;T表示预测正确,F表示预测错误。根据混淆矩阵从而能计算出分类性能评价指标:
3.4 实验结果分析
本实验使用python语言编写,采用Twitter真实数据集进行训练与测试。Scikit-Learn是一个提供大量机器学习工具和模型的功能强大的Python库。通过Python机器学习库中的几种分类算法对提取的特征进行实验,比较得出提高水军识别准确率的特征以及不同算法对水军识别的效果差异。实验采用的第一种分类算法是SVM,第二种分类算法是KNN,第三种是RF算法。
如表4所示,在数据集1上SVM算法能够得到的结果是67.4%的准确率;采用KNN算法结果改善了一些,将准确率提高到75.5%;而RF算法在分类器训练之后得到了最好的效果,赋予了82%的准确率。
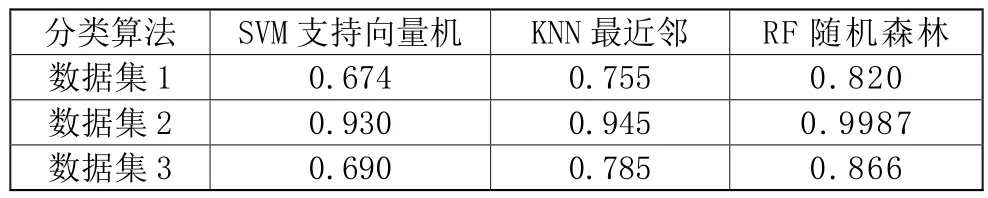
表4 准确率(accuracy)对比
在数据集2上实验证明了改善的结果很显著。通过之前相关性检验的实验可知,其中主要的改进因素来自“actions”特征的存在,这个特征表示该推特用户的收藏、回复、转发总数。同样,SVM算法结果明显提升,准确率从之前的67.4%提高到93%;对于KNN算法,准确率比起SVM稍微提升,在94.5%左右;最后,对于数据集1训练得到的分类准确率有很大提升的RF算法,对于数据集2,结果同样令人震惊,该算法能够以99.87%的准确率进行识别,得到的分类效果最好。
在数据集3上的实验结果,相对于数据集2可能不太理想,因为其数据是来自随机选择推文组成的数据集所生成的特征集。SVM得到的结果是69%的准确率,KNN分类算法的训练结果有所提升达到78.5%,RF算法依旧得到最好的分类效果,有86.6%的准确率。
4 结束语
社交媒体上的水军识别是社交网络需要面对的最大问题之一,对网络水军的精准识别是目前微博研究领域亟待解决的难题。
通过对水军识别相关文献的研究,本文利用Scikit-Learn机器学习库中3种分类算法对Twitter上3个不同真实数据集进行训练,设计水军识别分类器。在创建特征集的过程中,对Twitter用户的属性特征进行具体分析发现特征的选择比数据集更重要,相较于数据集1,数据集2和3中引入了“推特用户收藏、回复、转发总数actions”特征后,水军识别的准确率大幅度提升,并且对于3个分类算法都是如此;除此之外,比起前两种分类算法,随机森林(RF)分类法分类性能评价指标值都较高,分类效果最好。最终实验发现,使用强大的机器学习方法和适当的特征提取阶段,可以取得一些很好的结果。
