不同自然语言的信息处理方法差异概述
2022-03-07尕藏才让
尕藏才让


关键词:NLP文本检查藏文文法
计算机时代的到来开启了自然语言的自动处理先河。早在二战时期,就有美国数学家沃伦·韦弗指出“德语只是用密码写成的英语而已”。他在战后构想的机器翻译概念直接启发和推动了冷战时期以英俄语翻译为主的机器翻译。自然语言处理从最初的基于规则的方法,到今天的基于深度學习的方法,技术得到了革命性变革。如今,NLP技术水平已不同往日,除了机器翻译,其还被广泛应用在舆情检测、自动摘要、文本分类、语音识别、智能问答和人工智能等众多领域。
由于互联网首先在英语国家发展成型,所有在现阶段的英语处理水平基本上代表着国际最顶尖的NLP技术水平1)因为各个自然语言的文法规则有差别,导致各个语种之间的处理技术有一定的差异性,在进行跨语种的NLP技术的研究时,只能进行浅层次的借鉴,而不能完全搬抄。甚至同语言不同方言的NLP技术都需要设计和采用不同的算法程序。本文以研究者较为熟练的藏汉两种文字为例,从文本检查的角度简要概述不同语言间,由不同的语言特性所带来的NLP技术差异。
1汉藏NLP技术发展回顾
1.1汉文的NLP技术发展
汉文是不同于英文的表意字,在语法上与大部分拼音文字有巨大差别。恰如语言学家王力先生所言:“就句子的结构而言,西洋语言是法治的,中国语言是人治的”。汉文的原始信息化处理开拓极其艰难,早期计算机和互联网在国内的大范围推广应用直接受制于“计算机汉化”工作进度,这也是汉文字信息化处理工作要攻克的第一个难关;1974年,经有关部门批准将748工程纳入国家科技发展计划,标志着汉文字NLP技术攻关在国家层面得到了重视,其成果引发了印刷业的改革。其中,748工程又细分为精密中文编辑排版系统、中文情报检索系统、中文通信系统,三者直接为“计算机汉化”和中文互联网生态的形成打下了坚实的基础。发展至今,“计算机汉化”问题已基本解决,汉文NLP则更注重于“汉文计算机化”,即通过计算机来处理汉文,辅助甚至代替人类进行翻译、语言识别控制、情绪识别等。
相较其他自然语言,汉文NLP水平已走在世界前列,出现了一批优秀的科研机构和科技企业,如清华大学、哈尔滨工业大学、科大讯飞、百度等。通过与知识图谱的结合,可广泛运用于教育、医疗、养老、旅游等领域。此外,因汉文字所固有的语法复杂、结构不稳定等特性,使汉文字的NLP技术发展遇到了瓶颈,影响了整个技术的发展速度。但这几年随着深度学习和大规模语料库的加持,又使该技术得到了新的发展契机(见图1)。
1.2藏文的NLP发展回顾
藏文是参考古印度梵文编制的拼音文字[1],其基本由30个辅音1)和4个元音2)组成,有相对稳定和严格的文法体系,但又有别于西方流行的拉丁、日耳曼和斯拉夫等语系的左右横向拼音排列,还具有从上到下的纵向叠加,对NLP技术的算法提出了更高的要求。20世纪80年代,改革开放,百业初兴。在国内外的NLP技术大发展的背景下,藏文NLP技术研究工作也开始起步[2]———最早见于报道的是张连生于1981年用计算机进行的藏文词汇排序工作,并于1983年采用李方桂先生提出的藏文罗马转写方案,实现了藏文最初的处理系统,包括俞乐等人于1984年在VICTOR9000上设计的藏文处理系统和西北民族大学在WANGVS/80上实现的藏文字处理系统等。但上述藏文字处理系统缺乏宏观层面的协调和国家统一标准的制订,呈现了“各自为政,相互不通”的情况,严重制约了整个藏文信息处理研究的进一步发展。不过,1997年7月这种情况迎来了转机———我国多部门、多地方、多高校联合制订的《信息技术交换用藏文编码字符集基本集》通过第33届SC2/WG2会议,藏文成为我国继汉文后第二个进入国际ISO/IEC10646标准编码体系的文字。此项标准的制定也正式打开了古老的藏文通向新时代的大门。这前后出现的兰海藏文系统、TCE藏汉英文信息处理系统、北大方正藏文处理系统都呈现了高标准化的现象。此后,藏文NLP计算的研究对象越发广泛,典型的有字词频统计、语料库建设、自动分词、机器翻译、字词校对、文本识别等。
随着相关领域的国家和省级重点实验室在西藏大学、青海师范大学等藏区高校落地,加快促进了以计算语言学为核心的藏文信息处理技术的研究和各层次人才的培养,使藏文信息化处理掀起了一个前所未有的发展热潮。2016年8月,云藏搜索引擎在青海省海南藏族自治州正式上线(见图2),代表着藏文互联网和藏文处理技术形成了规模庞大的产业群。为该领域的产研结合、产教结合开辟了先河。
2汉文与藏文NPL技术在文本检查方法中的差异概述
从语言学的骨架语法角度来看,汉文属于独特的“孤立语”,其表义转变主要依赖虚词和词序的变化。如“水温”和“温水”具有根本词义上的区别,但因字之间相互孤立,无所谓字词的错误,而是根据用词环境来界定。而藏文恰恰不同,其语法和表达方式带有很强的“黏着语”的特点。即根据词根的后缀或内部(即藏文的一个字节,以隔音符来界定)的变化实现语义的转变,如“”和“”仅一个元音字母()之差带来了语义的转变[3]。本文将以汉文和藏文各自的语法差异为出发点,从自然语言文本处理的四个层面;字、词、句(上下文无关)、篇(上下文有关),试述两种文字NLP技术的具体差异。
2.1字层面的拼写检查方法差异
字的处理是进行自然语言文本处理的第一步和基础。因汉文字本身的语法特点,在这层面只需通过统一编码的汉字库,就可以杜绝错别字(即不存在的别字)的出现。现行的汉字显示大都由基于Unicode编码的汉文字机内码、交换码、输入码、点阵码、点阵图来实现,形成了庞大的具有6万余字的字库,编码标准号为;GB2312⁃80。在此不做赘述。
不过,藏文字层面的检查和纠错机制则更为复杂[4],藏文由常用的30个辅音字母和10个非常用的辅音字母1)以及“”“”“”“”四种元音字符组成。而30个常用辅音字符中有分别分出10个后加字、5个前加字、2个再(后)加字、3个上加字、4个下加字。一个音节除了由40个常用和非常用辅音字母担任基字外,还可以在基字上添加上、下、前、后、再加字以及元音字母。如果在拼写环节不对语法规则进行限制,以现有的himalaya藏文输入法为例,在限制字长为7的前提下,能输入48000组不同音节字符串,但实际符合藏文音节2)拼写规则的只有8000多组,盲打错误率高达83%。所以,要采用一定的算法规则,去规避和纠正不符合语法的错误音节的输出。
下文将简单介绍三种较为可行的方法:一是利用形式语言与自动机理论,构造识别藏文字的有限状态自动机,将藏文字作为有限自动机进行输入,能够被自动机识别的藏文字的拼写则是正确的,否则可能是错误的。此方法由西藏大学尼玛扎西教授提出;二是对已输入或正在输入的藏文字按部件進行分解和分析,并在语法上进行规范,从而实现错别字的过滤。此办法由青海民族大学安见才让教授提出;三是使用向量模型取值设限去实现音节内的拼写检查,参照藏文语法,把藏文中七个部件抽象成向量元素,并以元素数量设值,再用语法细则制定规则,从而制作向量模型,并将其与向量模型对照映射就可检查该音节藏文字符语法的真值结果。此外,还有基于知识库和产生式推理等处理方法,在此不做赘述。
如今,藏文字层面的拼写检查理论研究趋于成熟,更多的研究应该侧重于实用化。以上部分的藏文语法以《字性组织法》理论为重点3)。
2.2词层面的检查方法差异
不管是孤立语还是屈折语和黏着语,到词层面都需要参照相应的语法进行书写检查和纠错处理,藏汉文字亦如此。此外,藏汉文字有个不同于西方英、法、西等语言的显著特点———词与词之间没有分隔符。所以,分词系统的设计在藏汉两种语言的NPL技术中都同样重要,是词法分析的基础性工作。
在深度学习之前,词层面的处理不外乎基于语言学知识的规则约束和基于大规模语料库的统计匹配。虽然藏汉两种文字在这个层面的处理方式差异已经变小,但因各自语法的特点,也还有一定的差异。
藏文词层面的处理偏向于语法规则的约束,此方法相较建设成本高昂的语料库而言,有成本低、算法稳定等优点。但其对前期的语法规则知识归纳和算法设计要求较高。此外,随着处理对象的变化,如译词、新专用词以及未登录词等的出现,必然会导致误判情况发生。同时,在区别近义词和歧义词的差别上不灵敏、细粒度不够,往往需要语料库的加持。现流行的一部分Android藏文输入法带有一定的联想匹配功能,亦是在遵循上述原则上拓展实现的。
汉文词层面的处理则偏重于语料库,通过细化和扩展语料,特别是分词和标记等基础工作,准备大容量的熟词语料库,加上词表库和每个词运用环境正确,再借助统计和匹配以判断检查对象词的用法正确。到现在,随着深度学习的使用以及预训练模型等的成熟运用,传统的语料运用和建设变得更为简单。
2.3句子层面的检查方法差异
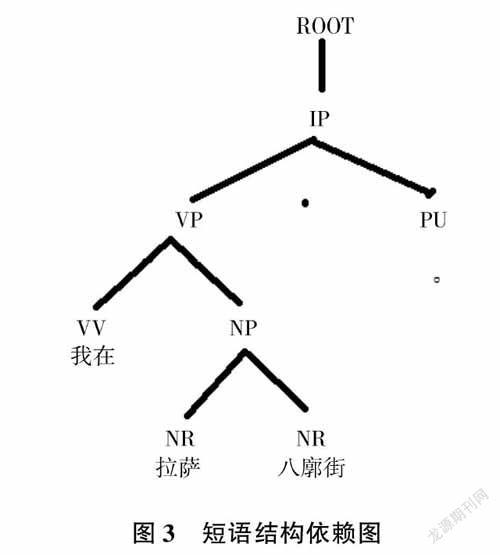
句子层面自然语言处理比以上两个层次更复杂、更抽象,而藏汉两种文字的处理方法也进一步趋同[5],但还是有一定的差别———比如,藏文在句法层面的处理就要考虑语法规则《三十颂》,而汉文字更注重考虑词序和虚词等语句构件的结构和排序。较为常见的方法体系有:短语结构句法体系和依存结构句法体系[6]。简单举例如“我在拉萨八廓街。”,按依赖关系标记并写成树状图(如图3所示)。
依存结构句法体系所运用的表示形式简单且可读性强,方便设计算法。但不同语种都有各自的语法特色,所以剖析依赖关系时需要注意———比如,汉文字中的把字句、被字句;藏文字中的各类格词和其他非自主副词(在藏文字节之间,其表义和书写要遵循三十颂语法体系。其中,以格属词、格动词为主的非自主副在与前词或整个语境结合时,要严格遵循跨音节的拼写规则)的作用和使用规则,以免细微的差异带来整体语句的变化,导致处理无效或错误。可以说,藏语句义分析技术现阶段还未成熟[7]。
2.4语义层面的检查
语义层面的处理除了要检查语法层面的真伪问题,还要结合上下文,即上下文有关文法;在语法正确的前提下,判断整个篇章的语义统一性和逻辑连贯性。该层次的实现对算法要求极高,无法通过简单的规则推理和简单的语料库匹配来完成,更多地需要借助人工智能的训练和学习来实现。如清华大学杨植麟团队就在近期提出一种不需要预训练模型的学习框架,并以此延伸出任务驱动的语言模型,使训练模型能够准确地认识语句中的细微差别,能明显提高计算机的篇章级语言文字处理水平。以研究者角度来看,经过字、词、句层面,到这一环节汉藏文字处理方法基本一致[8~10],可相互借鉴使用。
3结语
除了程序员,计算机和人类之间大部分的交流无外乎通过各种各样的自然语言来实现。而计算机作为当今不可或缺的生活、办公、学习工具,提升其对自然语言的识别和处理能力,不但可以提升某种工具的价值,更能使人类实现自我提升、自我解放。以研究者身边的计算机和网络环境为例,除了常用的汉文字外,还有一定的藏文数字信息存在,所以需要对这两种文字NLP技术的发展予以关注。此外,在很多领域都有这样的现象,如从事西方某国文字或历史的专业研究,但不懂该国的语言文字,从而不能掌握一手资料,只能人云亦云,终究只能困守在一定的学术高度而不能出众。在自然语言处理领域更是如此,进行跨语种NLP技术钻研的时候,第一步就应该学习、掌握目标语言的语法规则和运用环境,而非脱离现实,翻阅二手资料,先入为主。这样,即使自身拥有较高的计算机水平,往往也因语法知识的局限而亦趋亦步,而不能向前。
跨语种的信息化处理的第一步应该从目标语言的语法知识开始。总之,不管是哪种文字,除了语法上的差别导致处理过程有一定的差异外,目标都是一致的,就是能让计算机咬文嚼字、又出口成章、代行百事,让我们为这个目标持续奋斗[11]。
