基于空间通道Transf ormer的双分支网络图像去雾方法
2022-03-05张望
张望
(西华大学汽车与交通学院,四川 成都 610039)
1 引言
目前大多数交通监控、智能汽车、目标检测和其他系统都假定输入图像是清晰的,然而由于大气中烟雾和粉尘等悬浮颗粒物的存在,视觉系统通常会捕获能见度和对比度降低的图像。因此增强图像清晰度是一项必要的任务。目前,针对去雾的研究可分为三种:图像增强,图像复原和深度学习方法[1]。
基于图像增强的方法忽略图像内在机理,直接消除多余的干扰信息,提高亮度和对比度,从而恢复出清晰图像。Land EH等[2]以色感一致性理论为基础提出Retinex,单尺度Retinex[3]能增强对比度和在动态范围大幅度压缩,多尺度Retinex[4]可提高色彩饱和度,实现局部动态范围压缩,但当雾分布不均匀时会产生光晕现象和色彩失真。直方图均衡化是一种全局对比度增强方法,计算量较低。Pizer SM等[5]提出一种图像对比度增强方法,即限制对比自适应直方图均衡化(Contrast Limited Adaptive Histogram Equalization,CLAHE),限制直方图以减弱噪声强度。Srinivasan S等[6]提出一种自适应局部区域伸展(Local Region Stretch,LRS)直方图均衡化,它在灰度区间对图像像素点均衡化。上述基于直方图的去雾方法会丢失边缘等细节信息,降低有用信息对比度导致对比度异常。Ancuti等[7]提出了基于融合的图像去雾方法,通过融合白平衡和增强对比度两个原始模糊图像实现,由于不考虑雾霾物理模型,该方法在复原色彩等方面不够准确。
基于图像复原的方法大多考虑大气散射物理模型[8],去雾能力较图像增强方法有些许提高。He K等[9]提出一种暗通道先验(Dark Channel Prior,DCP)的方法进行去雾,根据大多数有雾图像的统计规律估计透射率,并由大气散射模型得出去雾图像,但在天空区域色彩失真。Pang J等[10]结合了暗通道先验和引导图像滤波方法进行单图像去雾,得到精细的透射图。Zhu Q等[11]提出了一种颜色衰减先验(Color Attenuation Prior,CAP),对模糊图像的场景深度使用线性模型学习参数,接着恢复深度信息,进而通过大气散射模型估计透射率并去除雾气。Fattal R等[12]提出了一种单幅图像去雾算法,通过假设表面阴影与透射率统计独立改进了大气散射模型,增加了表面阴影参数。Tan RT等[13]观察到无雾图像对比度高于有雾图像,大气光数值与成像距离有关,从而建立马尔科夫随机场的成本函数计算得出大气光。基于实时除雾需要,Tarel JP等[14]考虑大气衰减模型和大气光模型,利用中值滤波估计雾气浓度,从而复原无雾图像。Wang Y K等[15]设计一种多尺度融合去雾方法,结合马尔科夫随机场理论搜索深度图的最优解,保留了较多边缘等细节信息,进而恢复高质量的无雾图像。
基于卷积神经网络(Convolutional Neural Network,CNN)的方法近年来在去雾任务上取得了较大进展,Cai B等[16]首次采用端到端的CNN网络结构估计透射率,解决了手工提取特征复杂等问题。Li B等[17]介绍了一体化去雾网络(Allin-One Dehazing Network,AOD-Net),通过端到端的轻量级CNN生成清晰图像,满足其他检测任务的需要。Mondal R等[18]提出了一种基于全卷积神经网络(Fully Convolutional Neural Network,FCN)的图像去雾方法,设计了一个联合估计透射率和大气光的网络。Ren W等[19]提出了一种用于单幅图像去雾的多尺度卷积神经网络(Multi-Scale Convolutional Neural Networks,MSCNN)模型,它包括估计图像透射图的粗尺度网络和局部细化结果的细尺度网络。以上方法对于图像去雾效果较于图像增强和图像复原方法有明显提升,但由于它们过度关注局部特征,仍有对比度下降、细节缺失等问题。
近年来,基于Transformer的深度学习方法在自然语言处理[32]、语音识别[33]和计算机视觉[34]等各个领域显示出了巨大潜能。在图像处理领域,Transformer相较于CNN更关注全局信息,注意力机制等结构在图像去雾方面卓有成效。Dosovitskiy A等[29]首次将Transformer应用于图像,完全替代了卷积操作,并通过在超大数据集上预训练,在一般数据集上得到了优秀的结果。Woo S等[30]的研究提出在空间和通道注意力融合的卷积注意力模块(Convolutional Block Attention Module,CBAM),其提取的特征结合多维信息,并在能集成在CNN网络中从而提高性能。Yu W等[31]专注于Transformer在多项任务中有效的原因,提出PoolFormer结构,并表明在Transformer前期使用Pooling模块后期使用Attention模块可以获得良好的效果。
由于有雾图像中物体的尺度在密度、分布和大小等方面存在明显差异,本文提出基于空间通道Transformer(Space-Channel Transformer,SCFormer)的双分支去雾网络。首先建立一种特征自适应提取模块(Feature Adative Extraction Module,FAEM)用于提取图像浅层特征,减少了像素间损失;然后设计编码器-解码器(Encoder-Decoder)结构,Encoder中采用PoolFormer架构,Decoder中建立新的空间通道双注意力Transformer;接着添加卷积分支用于无监督学习,从而更好估计传输图;最后在Reside测试数据集上进行了客观评价指标和主观评价指标测试。本文的主要工作包括:
(1)基于Transformer网络,提出空间通道自注意力网络;
(2)针对雾图中的尺度差异,提出一种特征自适应提取模块;
(3)针对图像去雾效果,提出一种特征余弦相似度损失函数;
(4)在Reside数据集上进行训练与测试,并对比了相关的图像去雾方法,结果验证了本文模型的有效性及优越性。
2 相关理论基础
2.1 光学物理模型
空气中的微小颗粒几乎不会阻挡光线,但在雾天空气中有大量悬浮粒子,如水蒸气、气溶胶,他们对可见光有很强的吸收和散射作用,造成目标反射光能量的衰减,从而导致成像效果差和对比度低。
1925年,Keim等[22]提出雾天图像能见度较低是大气中的悬浮粒子对光的吸收和散射造成的。根据上述理论,大气衰减模型在1976年由McCartney[8]提出,如图1所示,公式如下:
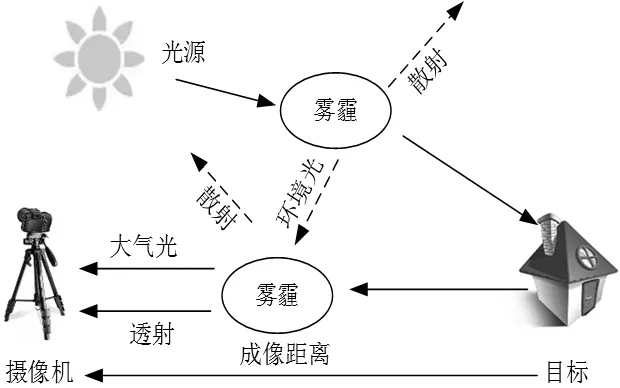
图1 大气散射模型
其中:x是图像中像素点的坐标;λ是光的波长;I(x,λ)是摄像机获取的雾天图像;β(λ)表示大气散射系数;d(x)是摄像机与目标的距离;R(x,λ)是需要复原的无雾图像;L∞是无穷远处的大气光值。
1999年,Nayar SK等[23]阐明了雾天图像的成像过程和引起成像质量下降的原因,即目标反射光能量的衰减和环境光受散射作用形成的背景光强度大于目标光,并建立了成像数学模型:
式中:I(x,λ)是摄像机采集到的有雾图像;J(x)是输出的无雾图像;A是大气光。
2009年,He K等[9]提出了暗通道先验理论,即在大多数非天空的局部区域里,某些像素灰度值总会有一个颜色通道是很低的值,公式如下:
其中:Jc(x,y)是彩色图像的各个通道图像;Ω(x,y)是以像素点(x,y)为中心的区域。
2017年,Yan Y等[24]提出类似于DCP的亮通道先验,即是模糊图像中最模糊的图像块里的某些像素灰度值在至少一个颜色通道里是很高的值,其表示为:
式中:Jc(x,y)是图像的各个颜色通道;Ω(x,y)是以像素点(x,y)为中心的区域;Abright(x,y)是无雾图像的大气光强度。
为方便计算,雾天成像模型简化为:
其中:I(x)是输入的有雾图像在坐标x像素的像素值;t(x)是大气透射率。
目前基于图像复原的去雾方法通过人工假设等方式估计出大气光A,采用等方法计算出透射率t(x),根据大气物理模型推算出去雾图像,但这类方法需要估计的参数较多,误差较大,甚至当图像像素点的灰度值接近大气光值时,局部可能出现色斑、色偏效应,从而导致去雾效果不理想。
2.2 CNN
CNN是一种前馈神经网络,它通常由卷积层、池化层和全连接层等组成。
2.2.1 卷积层
卷积层的输出是输入数据和可学习参数构成的卷积核进行卷积操作得到的,公式如下:
式中:m和n为位置编号;k为网络层数;为神经元
输出;Sn为卷积操作区间;为神经元输入;为第k层权重;是第k偏置;f是非线性激活函数。
2.2.2 池化层
池化层是对卷积层结果进行降维,扩大感受野,其表示为:
本文采用GA-PSO的配电网重构的基本思想是通过克服算法自身的缺点,使寻优过程较快收敛到全局最优解。由于算法各自的特殊性,直接混合实现困难,本文提出将种群分成两部分,分别进行寻优保证粒子的多样性,信息共享使其不易陷入局部最优,将寻优结果进行比较来更新最优解,达到寻优目的。
式中:λ是乘性偏置;是第k层偏置;g是激活函数;f是池化函数。
2.2.3 上采样层
上采样层是放大输入图像,其表示为:
式中:hn是输出图像高度;wn是输出图像宽度;hn-1是输入图像高度;wn-1是输入图像宽度。
3 本文方法
本文提出一种基于双注意力机制的端到端去雾方法,首先建立特征自适应提取模块(Feature Adative Extraction Module,FAEM)提取浅层特征;然后构建一种Encoder-Decoder模块,Encoder基于PoolFormer提取全局信息,Decoder关注空间与通道维度,建立自注意力机制模块;同时共同输入多尺度暗通道与明通道先验图像块,并与原图像级联,生成粗糙的透射图;接着使用导向滤波得到较清晰的去雾图像,参与主干网络参数更新,最后得到高质量的无雾图像。
3.1 网络结构
本文构建了结合空间与通道自注意力机制基于Pool-Former的Encoder-Decoder结构,并增加辅助网络分支进行无监督学习,以增加梯度回流信息量,并得到清晰的无雾图像,如图2所示,主干网络的编码器是通过残差块进行浅层空间特征提取;解码器使用SCFormer,用于恢复图像的原始尺寸,中间的跳跃连接使用空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)[25]模块,获取多尺度物体信息,从而为输出图像保留更多全局信息,提高图像除雾效果;辅助网络输出透射图,与暗通道透射图计算损失函数以进行梯度回流,更新参数。

图2 本文网络结构
训练时,编码器在输入中使用手工提取的7×7和11×11尺寸的亮减暗通道图像块与彩色图像级联,即7通道的尺寸为256×256的图像。网络首先使用FAEM模块提取全局信息;其次使用连续4个PoolFormer模块加深网络深度的同时保持图像尺寸不变,其中Pooling操作在提取不同维度特征的同时,减少模型复杂度与参数;为了应对下采样过程中的信息丢失,添加ASPP模块扩大感受野,降低分辨率损失。
解码器中使用连续4个空间通道自注意力网络(Space-Channel Transformer,SCFormer)模块与跳跃连接输出级联,加强信息传播,减少信息损失,保留了边缘、纹理等细节,接着两次使用转置卷积[27]上采样,恢复到原始尺寸激活函数使用带泄露修正线性单元(Leaky Rectified Linear Unit),解决了负输入的零梯度问题;最后采用3×3卷积生成3通道彩色去雾图像。
分支网络使用双线性插值复原图像大小,首先估计出粗糙的透射图,接着使用导向滤波获取精细的透射图,然后计算出暗通道透射图损失,更新网络相关参数,从而减少过拟合并增强结构鲁棒性。
3.2 损失函数
损失函数是度量输出图像与真实图像的差距,上分支网络损失函数包括L2损失LL2(I)、余弦相似性(Cosine Similar,CS)的感知损失Lcos(I),辅助网络增加了暗通道透射图损失Ldark(I)依据重要程度赋予不同权重,总损失函数为:
L2损失函数在图像去雾中能增大输出图像与真实图像的差异,加快收敛速度,本文将他作为主干网络的损失函数,其公式如下:
其中:f k(x)是主干网络的第k批输出值,yk为第k批无雾标签图像,n为训练样本数。
余弦相似性损失函数关注特征级别的一致性,是衡量两幅图像相似度的常用指标,输出图像与真实图像之间的Lcs(I)计算如下:
其中:f k(x)是主干网络的第k批输出值,yk为第k批无雾标签图像。
暗通道透射率损失函数是考虑了分支网络输出结果对主干网络的影响,通过对输出的透射率图像计算导向滤波等方法获得的清晰图像与主干网络输出的去雾图像之间的Ldark(I)如下:
其中:gk(x)是分支网络的第k批输出值,yk为第k批无雾清晰图像,n为训练样本数。
4 实验结果与分析
4.1 数据集及实验设置
Reside数据集[26]是图像去雾领域使用较广泛的公共数据集。本文使用Reside-indoor数据集中的ITS数据集,选取13000张图片作为训练集,990张图片作为验证集,包括500张图片的SOTS作为测试集。本文使用Pytorch框架构建深度学习模型,在配备GeForce RTX 3090 GPU的Ubuntu环境下训练。设置kcs、kdark分别为0.1、0.01时除雾结果最好。在进行卷积神经网络训练时,输入图片尺寸为256×256×7,参数初始化方法为均匀分布初始化,初始固定学习率为0.0002,并使用Adam优化器,批尺寸batch-size为8,epoch为100,网络总损失函数包括LL2(I)、Lcs(I)、Ldark(I),使用图像质量评价标准峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM)指标度量去雾效果。
4.2 图像去雾结果分析
本文使用PSNR与SSIM作为图像去雾任务中的客观评价指标。PSNR和SSIM的数值的大小表示图像质量的好坏。本文在单分支的残差网络ResNet50上进行了基准实验如表1所示,进一步分析了模型中不同部分的影响,所有超参数调整都在验证集上进行。从表中可知,当逐渐添加不同模块,PSNR和SSIM指标数值都有提高。
将本文方法与目前的先进去雾方法AOD-Net[17]、CAP[11]、DCP[9]、FCN[18]、MSCNN[19]在合成图像去雾数据集上进行对比的主观结果如图3所示。前两行是在Reside-indoor上的测试结果,后两行是在Reside-outdoor上的测试结果。从图中看出,AOD-Net和MSCNN仍然有雾气残留现象;CAP产生部分色斑且亮度较低;DCP去雾结果在天空区域出现较明显颜色失真现象且对比度过高;FCN结果亮度过高,部分区域出现色偏效应;本文方法的色彩真实呈现和细节复原效果较其他方法明显更好,与真实的清晰图像相似度更高。在真实有雾场景中的去雾结果如图4所示,本文方法在减少雾气残留方面效果显著,且亮度增强和色彩还原效果较其他方法更好。

图3 不同模型对合成图像去雾的主观结果对比图

图4 不同模型对真实图像去雾的主观结果对比图
在Reside-indoor测试集上进行客观评价对比的客观结果如表1所示。从中可以看出,本文方法获得了最高的PSNR和SSIM数据值,PSNR和SSIM均大幅提高,两个指标相较于其他方法有了较大提升,展现了模型的良好性能。
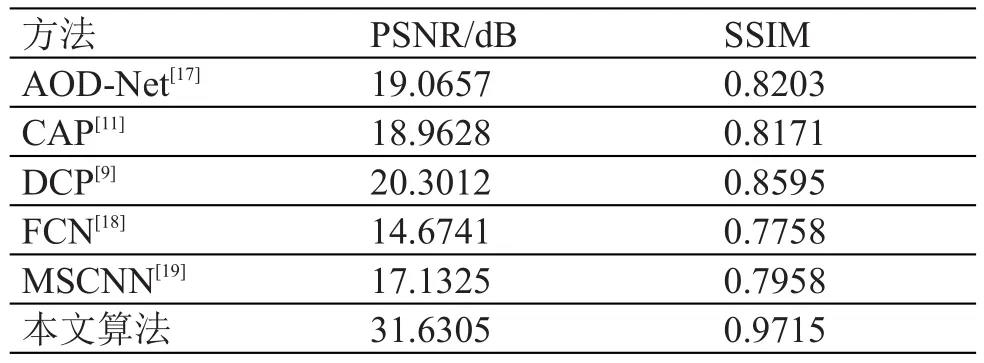
表1 不同网络模型的PSNR和SSIM客观结果对比
5 结语
本文提出了一种基于SCFormer的双分支网络的图像去雾方法。输入包含暗通道和亮通道图像的多尺度级联图像,提高了估计透射率的准确率,提升了图像分辨率;PoolFormeer的应用和ASPP的构建获取了全局特征;SCFormer考虑图像物体差异,较好还原无雾图像颜色、纹理等细节;改进了损失函数,增加了分支网络得到粗糙的透射图,从而减少过拟合,增强模型泛化能力,最终通过客观和主观评价表现了网络在去雾方面的良好性能。但本文没有使用目标检测等视觉任务进行验证,且只进行了单幅图像去雾,接下来可以应用本文算法在实时视频去雾等领域。
