基于机器学习技术的内网威胁行为发现方法的研究
2022-03-05吕少岚陈泽辉王晶晶江佳佳
吕少岚 陈泽辉 王晶晶 江佳佳
(1.南京航空航天大学民航学院,江苏 南京 211106;2.上汽大众汽车有限公司,上海 201805)
1 引言
网络安全是一个关系国家安全和主权、社会的稳定、民族文化的继承和发扬的重要问题,网络安全的重要性正随着全球信息化步伐的加快而变到越来越重要。就我国目前情况而言,随着信息技术在各行各业的不断深入应用,其极大提升整个社会的运行效率的同时,也催生了各类网络安全事件的频发,严重影响了企事业单位和人们的正常生活。因此,网络安全和信息化是事关国家安全和国家发展、事关广大人民群众工作生活的重大战略问题,如何保障各类信息系统的安全运行,已成为上升到国家层面的一项战略任务。
网络安全事件的呈现形式多种多样,其中外部黑客的攻击已引起各企事业单位的高度重视,通过在网络边界部署防火墙、入侵检测、防入侵等安全设备可以解决信息网络的边界安全防护问题[1]。但这些边界防护机制很难检测、发现和阻止内部网络的各类威胁行为。国际权威机构Haystax于2019年发布的网络内部安全威胁报告[2]指出,内部网络的恶意用户行为是造成企业数据泄露的主要原因,对企业内部网络的威胁行为的检测发现是保证企业网络安全运行的一个重要环节。
内部网络威胁[3,4]通常是企业现在或前员工、承包商、合作伙伴等利用他们的内网特权,通过有意、无意或误用等方式导致对公司或组织的员工、客户、资产、信誉或利益产生伤害行为,威胁行为通常包含寻找、发现、偷窃、篡改、非法使用或毁坏各类内网设备实体上的企业生产资源。
内部威胁的类型通常包含了意外数据泄露、间谍活动、伺机偷窃数据、蓄意破坏、产品/业务篡改、不合规行为、资源滥用误用等[5],而传统的威胁检测方法都是基于特征量的检测机理,定义的威胁行为的静态规则,很难发现识别内网的各类威胁行为,即使能发现一些线索,也会淹没在内网海量信息中无法及时响应,导致难以追溯定责。
本篇文章提出的内网异常检测方法根据企业内部网络的特点,围绕内网安全四要素用户、设备、行为和作用域,通过机器学习技术,建立基于内网四要素的安全行为规范和安全模型,实现自动追踪识别恶意用户和软件的操作行为和活动轨迹,能够对威胁行为及时发现、预警,阻止恶意威胁行为在内网的蔓延和破坏,能够有效保护内网的关键业务应用。解决方法包括以下几个方面:
(1)内网行为事件的采集和提取;
(2)对内网行为事件特征属性值的数字化处理;
(3)分析内网行为数据集特征维度分布,基于学习样例建立无监督机器学习模型;
(4)通过多种机器学习方法,分析检测出的内网异常行为事件,得出最优算法方案。
2 问题分析
由于内部网络产生的未知风险中,很大一部分来自内部人员有意或无意的违规违纪行为,例如一些内部人员非法接入、业务数据窃取、私自外发等非常规行为泄露机密文件等,针对内部网络的威胁行为分析常常面临以下的问题和挑战:
(1)真实异常样例少:由于内部员工越权访问涉密数据或者账号失陷用攻击是小概率事件,可获取的真实异常事件样本极少;正、负样本数量极不平衡,历史日志中绝大部分都是正常行为的数据,异常数据所占比例很小,不足以准确描绘异常的特征,无法直接从数据中学到所有异常的特性;
(2)数据标注困难:数据缺少标签,人工标记成本高,可操作性低;
(3)攻击模式不确定:为了规避检测,攻击者可能会将其恶意的行为隐藏在正常的行为中,不易发现;攻击策略没有固定模式,无法事先预知。
有监督的方法依赖于准确标注好的数据集进行模型训练,需要充足的正、负样本,然而由于存在如前所述的“三大挑战”,有监督的方法无法发挥作用。因此,我们提出了无监督机器学习方法对威胁行为进行分析,围绕用户、设备、行为和作用域四要素捕捉内网动态行为变化,提高实际应用中的异常检测准确性。同时,对样本的多维度特征进行评定,可以批量分析各安全要素的异常行为,有助于自适应的持续算法优化。
3 算法介绍
我们通过上述分析发现内部网络的异常威胁存在着异常样本占总样本数量的比例低、异常点的特征值与正常点特征值的差异性很大的特点,所以基于非监督学习机制的孤立森林(iForest)[6]机器算法完全适合内网异常检测场景。
孤立森林iForest是基于Ensemble的异常检测方法,凭借其线性的时间复杂度、高精准度、处理大数据时速度快的优势,被广泛应用于工业界中对结构化数据的异常检测。常见的场景包括:网络安全中的异常攻击检测、金融交易欺诈检测、疾病侦测、噪声数据过滤(数据清洗)等[7,8]。
针对不同的异常检测场景,基于传统孤立森林算法也衍生出一些变种算法,下面首先介绍孤立森林算法和其他三种衍生算法。
3.1 孤立森林(Isolation Forest,iForest)
传统孤立森林算法是基于异常点“少而不同”的普遍规律[9],该方法使用了一套非常高效的策略,即越早被二叉树分支隔离的数据是异常数据的可能性越大,而那些深入到叶子节点的样本不太可能出现异常。Zhou等[6]人将此策略转换为数学表达,利用分支的平均路径长度来分配被观测数据的异常分数。平均路径长度c(ψ)公式如下:
其中:
ψ为训练样本二次抽样的样本数,路径长度为:
e为被观测的实例x从根节点到叶子节点的过程中所经过边的数目,T.size为被观测的实例所在的叶子节点的样本个数,该实例遍历的分支的平均路径长度将使用公式(4)转换为异常分数:
其中E(h(x))是单个数据点在所有树中所达到路径长度的平均值。平均路径越短,异常得分会越大,越会被判定为异常点。
由于算法的设计,孤立森林有以下优点:由于每棵树都是独立的,因此在分布式的系统中加速计算;不同于聚类算法寻找异常点,它不需要计算点与点之间的距离或者簇的密度,模型为线性时间的复杂度,速度快,系统开销小。iForest被广泛应用于工业界中结构化数据的异常检测的同时,衍生出多种变体算法模型,如扩展孤立森林(Extended Isolation Forest,EIF)、分片选择准则孤立森林(Isolation Forest with Split-selection Criterion,SCiForest)和公平分割森林(Fair-Cut Forest,FCForest)。
3.2 扩展孤立森林(Extended Isolation Forest,EIF)
EIF[10]是对传统的孤立森林(iForest)的一种改进算法,解决了传统iForest存在异常掩盖问题,其改变了孤立树(iTree)的分支判定,成功隔离了iForest未成功检测出的异常数据,其判定公式如下:
如果条件满足,则将实例传递给左分支,否则向下移动到右分支。
3.3 分片选择准则孤立森林(Isolation Forest with Split-selection Criterion,SCiForest)
网络事件异常可能是由不同的机制产生,不同机制产生的集群异常有各自的分布。SCiForest算法[11,12]通过引入一个新的切割面来隔离离群数据点,弥补了iForest在检测聚类异常时的弱点。在构建树的过程中,随机选择q个特征属性,将这些属性结合投影在一个超平面,超平面f的表达式如下:
Q为所有特征属性,j为随机选出的属性,cj为[-1,1]间随机选取的值,X'为二次采样的样本集,而为X'的第j个特征属性值,p为一个随机分割点,并且创建τ个候选超平面,利用Sdgain理论,从τ个候选超平面中选择最优超平面进行划分。Sdgain分割公式如下:
Y是用户行为实值集,Yl∪Yr=Y随机分割点p将Yl和Yr分开,当随机选出的p对应的Sdgain值越大,说明其分割效果越好。
在测试数据阶段,f(x)存在范围限制,如图1所示,v为节点中最大值与最小值之差,f(x)的范围如下:
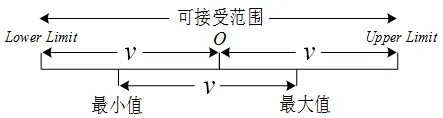
图1 参考超平面的可接受范围
3.4 公平分割森林(Fair-Cut Forest,FCForest)
FCForest[13]最初是为了弥补缺失值而产生的,但针对用户行为数据检测,其通过类似于SCiForest的超平面进行分割,但使用的是决策树的划分信息准则,与iForest完全随机切割相比,可以更好地对用户行为数据进行检测,其划分信息准则公式如下:
其中p(xi)代表X为xi的概率。
4 解决方案
4.1 概述
本文提出的针对该企业内网的威胁行为提出了一个内网异常检测的框架,工作流程如图2所示。该异常检测框架通过采集企业内网网络日志与网络协议数据包数据,完成对内网各类实体运行状态的数据收集,然后对收集到的各类网络数据进行规格化处理,形成结构化的实体(用户、内网设备)行为数据集。事件分析引擎通过对结构化的日志和网络数据包数据的分析处理,形成各实体行为事件数据集合。将合规的实体行为事件数据集提供给非监督学习算法学习,用于提取各实体内网合规行为的特征量。
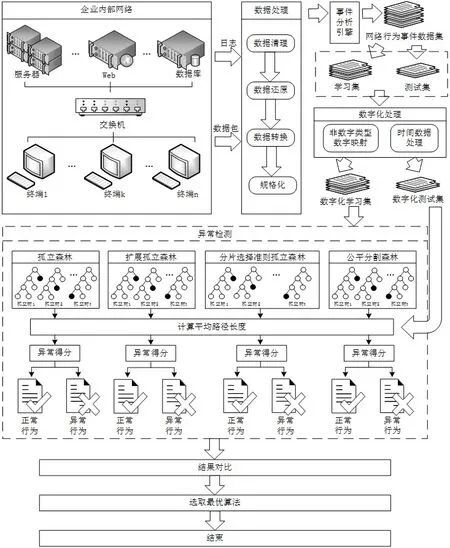
图2 企业内网的威胁行为检测框架设计
本解决方案通过收集某内网相关实体的两个月的正常网络行为事件数据作为合规的特征属性学习数据集,输入非监督模式的孤立森林方法(iForest、EIF、SCiForest和FC Forest,)中,提取相关实体(用户或设备)的内网合规行为特征量集,建立实体行为合规模型。通过实体行为合规模型,实现对实时发生的网络行为事件的异常检测。完成对几类孤立森林算法的异常检测结果的分析评判,找出符合内网场景中最佳的异常检测算法。
4.2 行为特征属性
完成各类网络数据的规格化处理后形成规格化数据集,这些数据集中存在大量无用特征和冗余数据,会减慢模型的训练和检测运行速度,为了避免维度灾难并实现网络事件异常检测的普适性,需要从规格化数据中提取最适合的、有意义的属性特征信息,因此经过事件分析引擎选择了以下特征属性构成网络行为事件的属性特性,见表1。

表1 网络行为特征属性列表
各个网络行为事件可由8个特征属性来描述,这些行为事件包含了诸如用户的Web访问、数据库访问、用户登录、设备时间周期的访问流量、文件访问等内网行为事件,每个事件的8个特征属性值反映了各行为事件潜在的特征。部分具体行为事件实例见表2。
表2中每一行记录为一次网络行为事件,包括事件的发生时间、事件名称、发出该事件的源设备IP和端口、行为目标的设备IP和端口、行为用户以及该事件类型的信息。
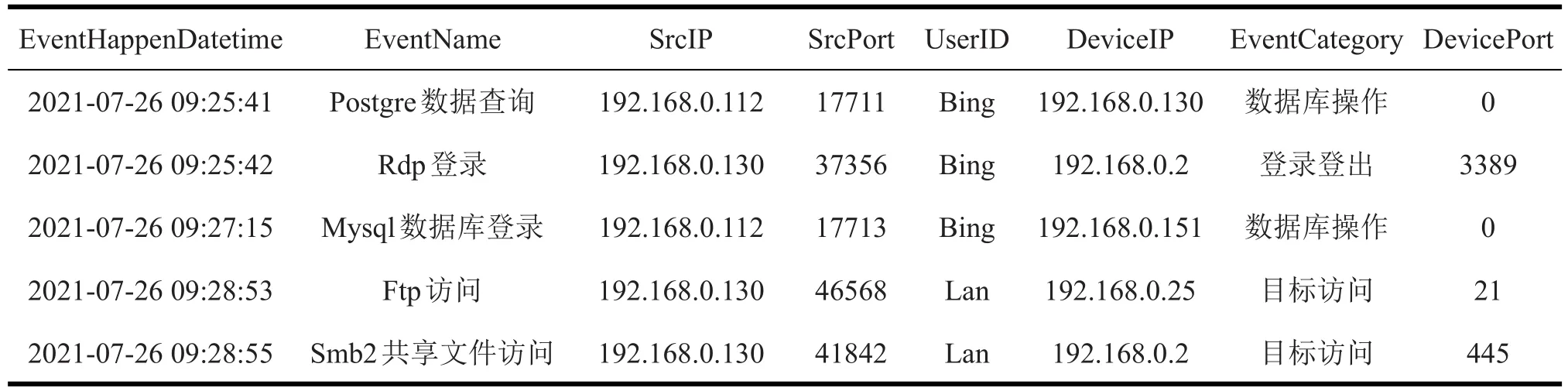
表2 网络行为事件数据集格式(样例)
4.3 数据集说明
iForest及其衍生算法通过非监督学习的方式实现对内网合规行为数据集的训练学习,通过训练完成网络各类实体正常网络行为的潜在特征向量集的提取,以合规特征向量集为标准,用来检测非合规行为的异常数据。
解决方案中数据涉及两种类型的数据,即学习样本数据和检测数据;学习样本数据提供给非监督学习算法学习,用来提取合规行为数据中的潜在特征量;通过合规行为的特征量,实现对检测数据集中的异常数据检测。
(1)学习数据集
本解决方案中提取了某内部网络中的33个实体在2个月的正常实体行为事件数据作为学习数据样本集(表3),孤立森林及衍生算法基于该学习样本数据集,完成实体合规行为的特征向量的提取。

表3 学习样本集
通过对2个月33个内网实体中的867897条的日志和网络数据包数据的处理分析,学习数据集形成四大类39小类23379个网络行为事件,39小类网络行为事件包含主机登录事件、HTTP访问事件、SMB共享文件事件、数据库访问事件、主机登出事件、SSH登录事件、安全策略变更事件、Telent登录事件、服务启停事件、目标访问事件、系统启停事件等,这些网络行为事件作为学习数据集提供给算法进行无监督训练学习。
(2)检测集
检测集是基于学习样本数据集中合规特征向量模型的异常检测数据集,通过对某天某一个小时段32031条的日志和网络数据包数据的处理分析,选取1个实体实例中1个小时产生的网络事件行为(表4)。

表4 检测集
该实例实体中某一小时段中包含有102例合规行为数据和81例通过在相关实体上运行某类网络探测软件所产生特定的网络异常行为,异常行为包含了横向移动、端口扫描、暴力破解、系统探测、流量突升等异常行为,该实例实体某一小时段中的183例网络事件可分为三大类13小类,13小类包括SSH登录事件、SMB共享文件事件、数据库访问事件、目标访问事件等。
4.4 数字化规则
数字化处理是指对行为事件中各特征属性值按照设定的转换规则完成相关特征属性值的从非数字到数字的转换工作,通过对行为事件特征属性值的数字化转换,用来构建特征属性数字化映射表,通过数字化映射表完成各类数字森林树的构建。
图3以DevicePort属性为例,展示了孤立树基于数字化的特征属性值的建树过程,其中p为随机分割点,小于分割点的数据传递给左子树,否则移动到右子树,可见算法中的孤立树无法对非数字类型数据分支,进而影响对异常数据的判别,因此网络行为事件数据集不可直接用于模型,对数据集数字化处理非常重要。
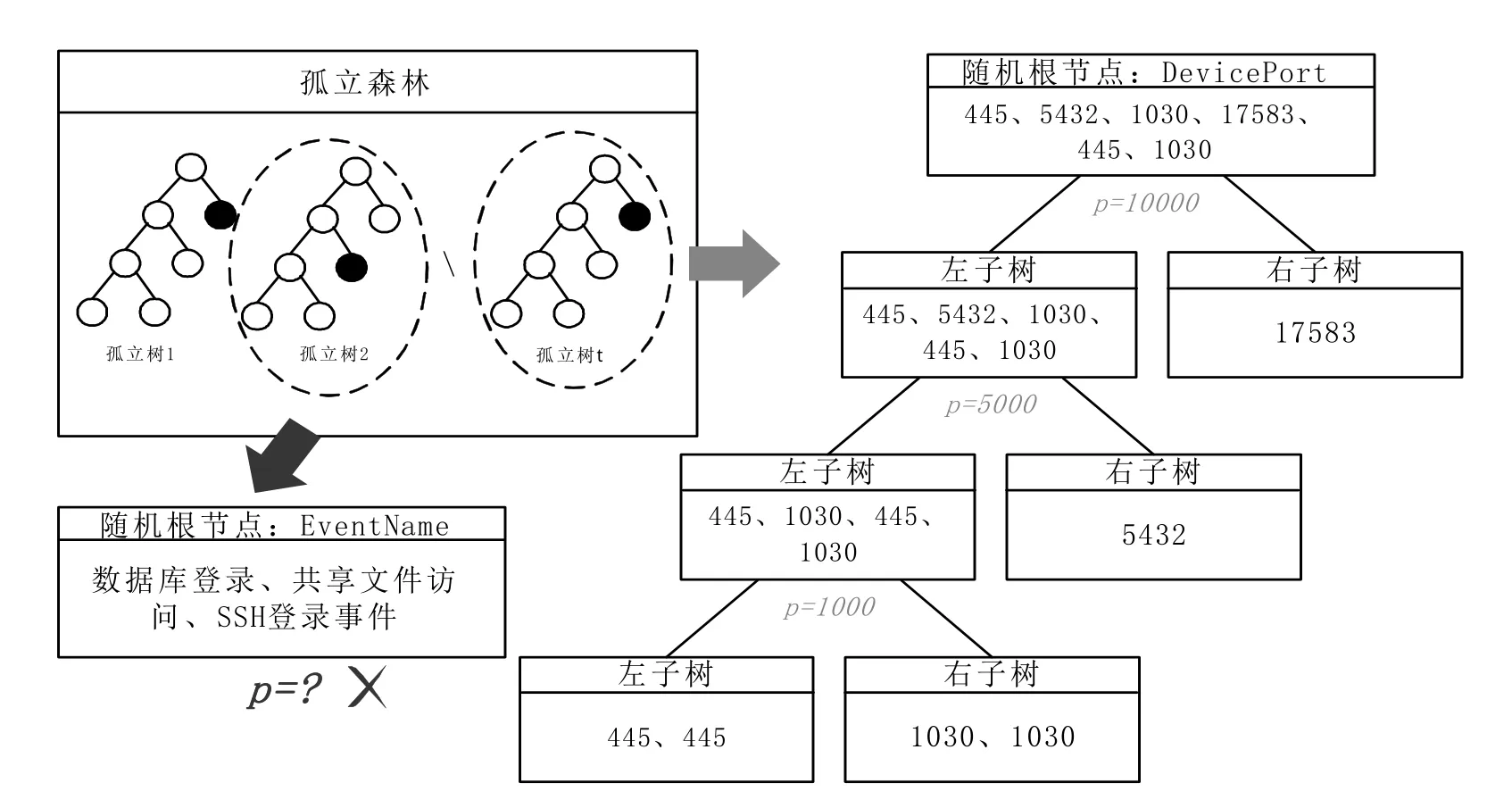
图3 孤立树对数字类型数据分支原理
行为事件的特性属性值依据相关规则进行数字化转换,转换规则包含字符串转换规则和时间转换规则两类。字符串转换规则中包含IP属性值除去分割符后的数字合并规则,例如,192.1.6.103数字化后为19216103。行为事件发生时间的数字化方案则采用了三种规则方式,即数字分规则、数字半时规则和数字时规则。数字分规则是数字周几+发生到分的时间,例如:2021-07-29 15:32:12数字化后为41532,其中4对应2021-07-29周四,1532对应发生时间15:32分;数字半时规则是在数字分规则基础上对发生“分钟”数字的再处理,例如:2021-07-29 15:32:12的数字化后为41530,发生时间的32分超过半时30分按30分数字化。2021-07-29 15:12:15的数字化后为41500,发生时间的12分小于半时30分按00数字化,数字化半时规则使得一个小时中发生的行为事件的时间属性降维到两个数字值。数字时规则是对同一小时内发生的行为事件进行数字统一,例如:2021-07-29 15:32:12和2021-07-29 15:12:15两个时间数字化为41500。
在对特征属性值的数据数字化过程中,属性可存在多个数字转换规则,但每次学习转换只能选择一种规则,转换规则不能混用。
4.5 森林树和异常阈值
本方案中数字森林构成树的数目是根据周志华等人的论文[6]中证实,当森林满足100棵树时,树的根节点到叶子节点的路径长度就已经收敛,因此设置每一个算法对应的森林都为100棵树的林子为最优检测林子,本案中构建的任何孤立森林都是由100棵树组成。
根据周志华论文[6]中证实由于孤立树有等价于二叉搜索树的结构,当孤立树平均路径长度与用相同样本量构建的二叉树平均路径长度相等时,异常得分为0.5,一旦超过了0.5的异常得分,则表示孤立树平均路径长度低于所期望平均路径长度。根据孤立森林异常数据“少而不同”的理念,路径越短,异常程度越高,因此本案的异常阈值设置为0.5,一旦算法得分超过0.5则被分类为异常数据,低于0.5的数据被判别为正常数据,分数越高异常程度越高。
5 实验与结果分析
5.1 检测过程描述
5.1.1 数据集数字化处理
本方案分别对特定选取的学习集与检测集的特征属性值进行数据数字化处理,形成相关的特征数字化映射表,为算法森林构建提供数据支撑。
本检测方案对行为事件发生时间特征属性采用了三种不同方式的数字化规则,即数字分规则、数字半时规则和数字时规则,用来验证关键特征属性值数字化的细腻程度对检测结果的影响。
展示部分数字化结果见表5、6,表5(a)为原始学习集样本,表5(b)(c)(d)为事件时间属性采用三类不同数字化规则产生的数字化映射表,表6(a)为原始检测集样本,表6(b)(c)(d)为事件时间属性采用三类不同数字化规则产生的数字化映射表。
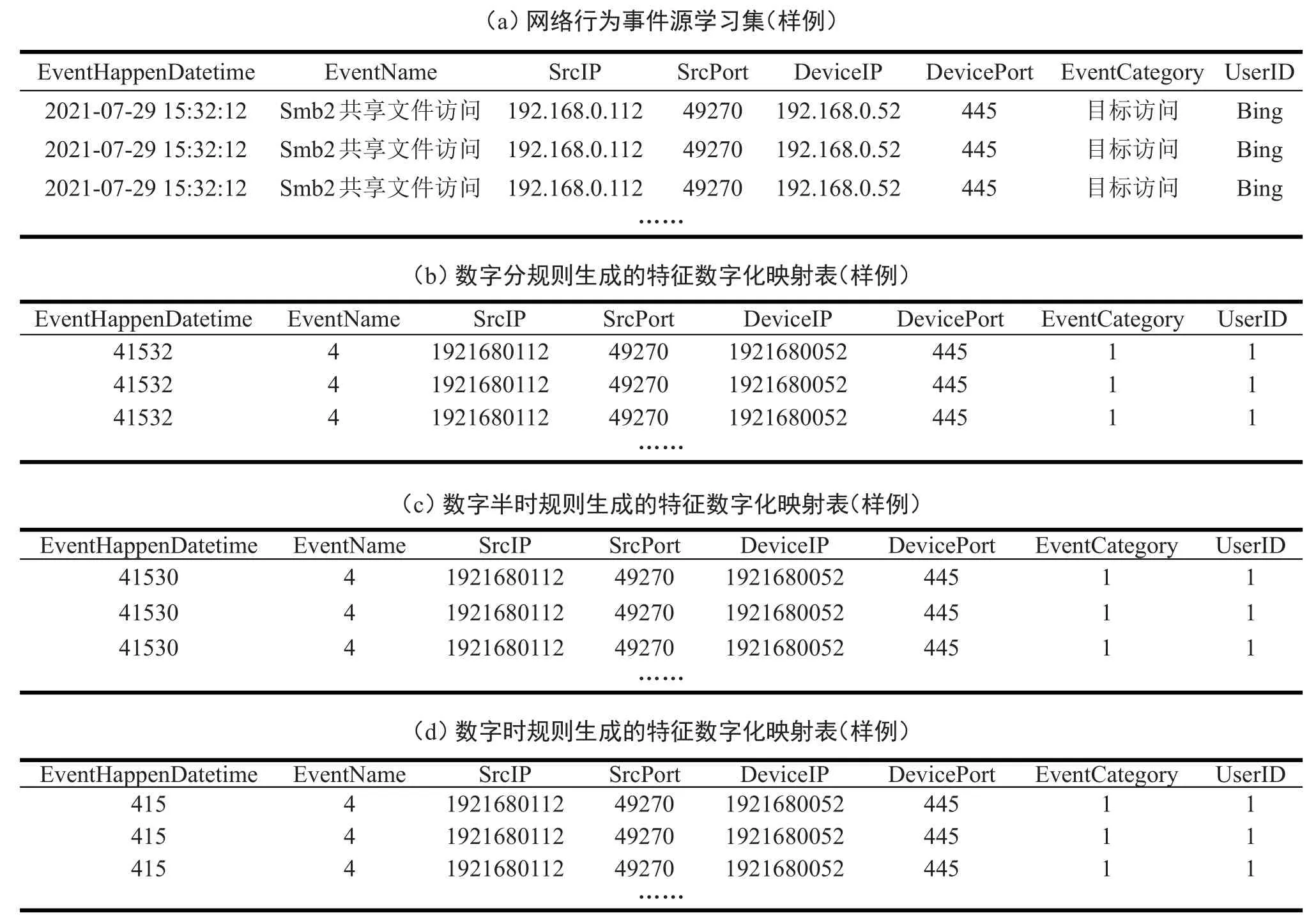
表5 学习集数据数字化

表6 检测集数据数字化
5.1.2 数据维度分布
在数字化特征属性值代入模型前,我们利用数据维度分布图来直观显示正常数据和异常数据的空间分布,提供先验性的数据集的属性特征。
将学习集数据与检测集数据进行数据化处理后,利用tsne算法[14]提取数据特征,将数据集维度降为随机的3维属性数据,可视化表现出学习集与检测集的特征向量的空间分布,图4为在数字分规则下学习集数据和检测集数据在3维空间里呈现的不同数据分布,其中蓝色的为正常行为数据,红色的为异常行为数据。
从图4中可见,学习样本集的数据特点为:数据量大、分布集中、数据连续,而检测集数据由于数据量较小,呈现分散、异常点与正常点混杂的特点。


图4 数字分规则下学习集与检测集3D可视化数据分布
5.2 模型评价指标
为验证实验算法的有效性,在本实验中,使用F-measure来评价准确度,F-measure即精度和查全率的调和平均值,它同时考虑了测试的精准度和召回率来计算分数。异常检测模型评价的混淆矩阵见表7,真阳性(TP)为正确检测到的异常数据,假阳性(FP)为错误检测到的异常数据,假阴性(FN)为未检测到的异常数据,真阴性(TN)为正确检测出的正常数据。精准度表示检测出的异常数据中为真实异常数据的比例,召回率表示真实异常数据中有多少被检测出来。

表7 检测结果混淆矩阵
可以从这些参数中,推导出精准度、召回率和F-measure。公式如下:
使用F-measure值作为分类器性能的衡量标准,值范围在0至1之间,因为它代表异常检测性能,甚至比精度值或ROC曲线更好[15],数据实例精准度和召回率越高,F-measure值越高,说明模型所得出的结果越好。
5.3 结果与分析
四个孤立森林(iForest、EIF、SCiForest、FCForest)算法采用无监督学习方式,基于两个月的合规数据样本学习了内网各实体的潜在行为特征,建立相关合规行为模型森林,对一小时内包含81个异常行为的检测样本数据集进行检测,得到了表8的结果,表8提取了测试集样本中人为标识出的前5例最严重的异常行为事件,利用4个算法对其评分,异常评分在0至1之间,超过0.5被分类为异常数据,分数越高表示该点异常程度越严重。
(1)异常敏感度分析
可见,在三类时间转换规则中,所有算法对前5例最严重的异常数据都给出了超过异常阈值0.5的得分,都检测出了前5例威胁行为。并且,根据时间转换规则的不同,算法对同一网络事件的异常得分之间普遍呈现出规律,即数字分规则下的异常得分最高,而数字时规则下的异常得分最低,时间规则越细,异常得分打分越高,可见,在特征属性值数字化规则细腻度越细,四类算法对异常行为数据的敏感度越高。
(2)拟合度分析
将本文中学习集和检测集的特定属性值(网络事件发生时间)采用三种不同的数字化规则所产生的属性数字化映射表代入iForest、EIF、SCiForest、FCForest异常检测算法,得出如表8模型评价指标。
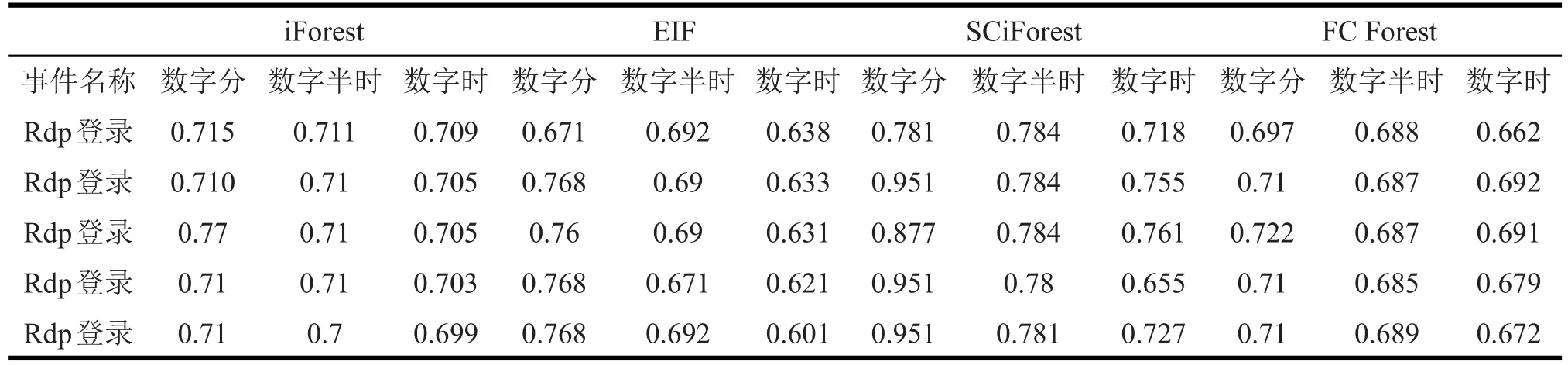
表8 异常数据异常评分对比(样例)
从表9可见,在数字分和数字半时转换规则里,所有算法的精准度、召回率和F-measure得分都是统一的,分别为44%、100%、0.61。造成这一现象的原因是数字分与数字半时转换规则下,算法一致将所有检测数据判别为了异常行为数据,出现了严重的过拟合现象。当以数字时为转换规则,FCForest依然将所有数据判别为异常行为数据,而iForest、EIF、SCiForest的F-measure值都保持在0.9以上,很好地分离出异常与正常行为,其中iForest效果最优,F-measure值达到了0.99,趋于满分,因此得出结论,针对该数据集,以数字时为规则,iForest算法方案最好。

表9 异常检测算法性能对比
(3)最佳结果分析
通过上述实验和数据,在本文提供的学习样本集和检测样本集中,在数字时规则下iForest、EIF、SciForest的F-measure值都保持在0.9以上,其中iForest的精准度达到了100%,召回率达到了99%,F-measure值达到了0.99。为了分析iForest算法在网络事件数据集上的运算,将学习集中正常数据与检测集中异常数据降为2维,截取其中一部分进行可视化展现iForest算法的分支过程,如图5,其中红色方形表示检测集网络异常事件,蓝色圆形表示学习集正常事件,每一条灰线都表示iForest算法一次分支,灰线越密集的区域说明该区域内数据平均路径长度越长,异常得分越低。
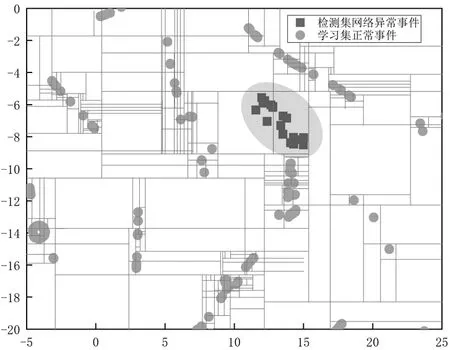
图5 数字时规则下iForest对网络事件数据分支操作
可见,在样本中正常行为事件与异常行为事件特征分布差异明显,异常网络事件区域只有一条分支所产生的灰线,说明检测集异常网络数据区域平均路径长度短,造成异常得分高。综上所述,可得出结论,检测集中的异常行为事件未有意识制造异常事件隐藏,针对此数据集特性,iForest可以高效分离异常数据。
(4)其他结果分析
为了进一步探究在数字分和数字半时转换规则里,出现过拟合现象的原因,分别将三类时间规则下,数字森林对检测集的异常得分进行统计,绘制数据分布轴须图,横坐标为异常得分,纵坐标为数据数量,红线为0.5阈值线,线左边为异常得分小于0.5的数据,线右边为异常得分大于0.5的数据。
从图6(c)中可见,iForest、EIF、SCiForest在数字时规则下都清晰区分了正常数据与异常数据,但为了补全缺失值而诞生的FCForest并不适用于阈值在0.5的异常划分,并且由(c)的轴须图可见,FCForest所产生的异常得分离散度低,效果差。

图6 异常得分密度分布
当时间规则为数字分与数字半时时,所有算法异常得分大于了0.5,其中SCiForest对数据异常程度的判断最为激进,并且异常得分间存在明显分散,介于FCForest和SCiForest都有着相似的超平面划分机制,由图5(a)(b)可知FCForest并没有呈现过高或过低的异常得分,经过分析,FC Forest和SCiForest的区别在于FC Forest使用决策树的划分信息准则,而SCiForest的超平面分割基于Sdgain理论(公式(7)),因此推测是Sdgain理论造成此现象,Sdgain理论本质为当一个超平面能清晰地将两个不同的分布分开时,这两个分布的内部离散程度是最小的。为了验证猜想,单独选取了三位不同员工一天的网络行为数据进行检测实验,利用Sdgain理论分别对三人网络行为频率进行划分,如图7。
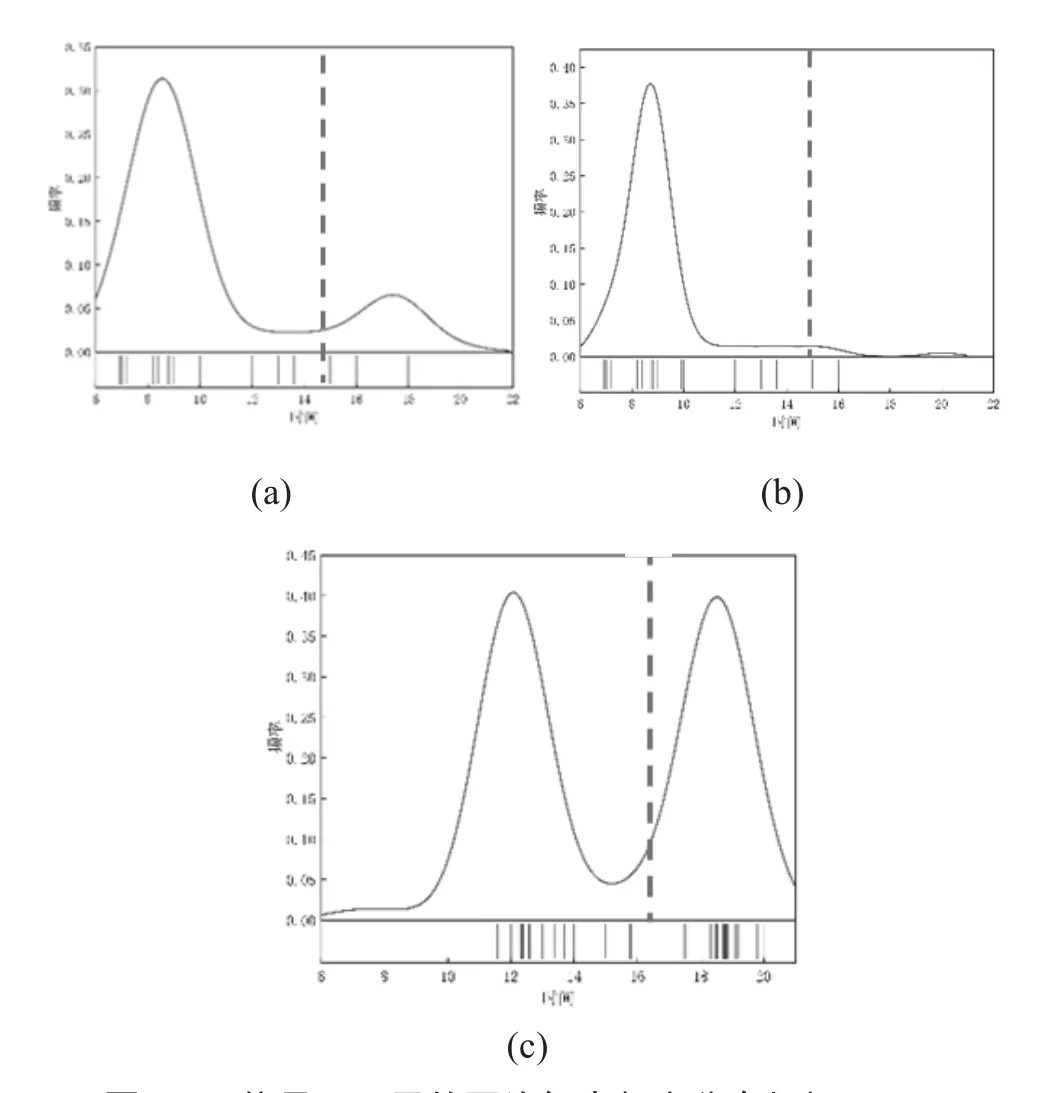
图7 三位员工一天的网络行为频率分布根据Sdgain选取分割点
其中,横坐标为时间,纵坐标为行为频率,蓝色线为随机选取分裂点中拥有最大的值的分割点的延长线。可见蓝线清晰地将员工行为数据集分为两部分,其中对于时间较为集中所产生的频率单峰(图7(b)),蓝线与峰值之间距离最大,可见理论拥有很好的分割数据性能,也正是因为此性能造成了数字分和数字半时规则下,SCiForest对数据异常程度判断激进,且相较于其他算法分数离散程度大的原因。
为了进一步寻找过拟合现象造成数字分、数字半时规则下算法性能较差的根本原因,对原始数据集进行探究,分别将三类时间规则所产生的数据利用t-sne算法[16]提取数据特征,将数据集维度降为3维,如图8,其中绿色点为学习集数据,蓝色点为检测集正常行为数据,红色点为检测集异常行为数据。
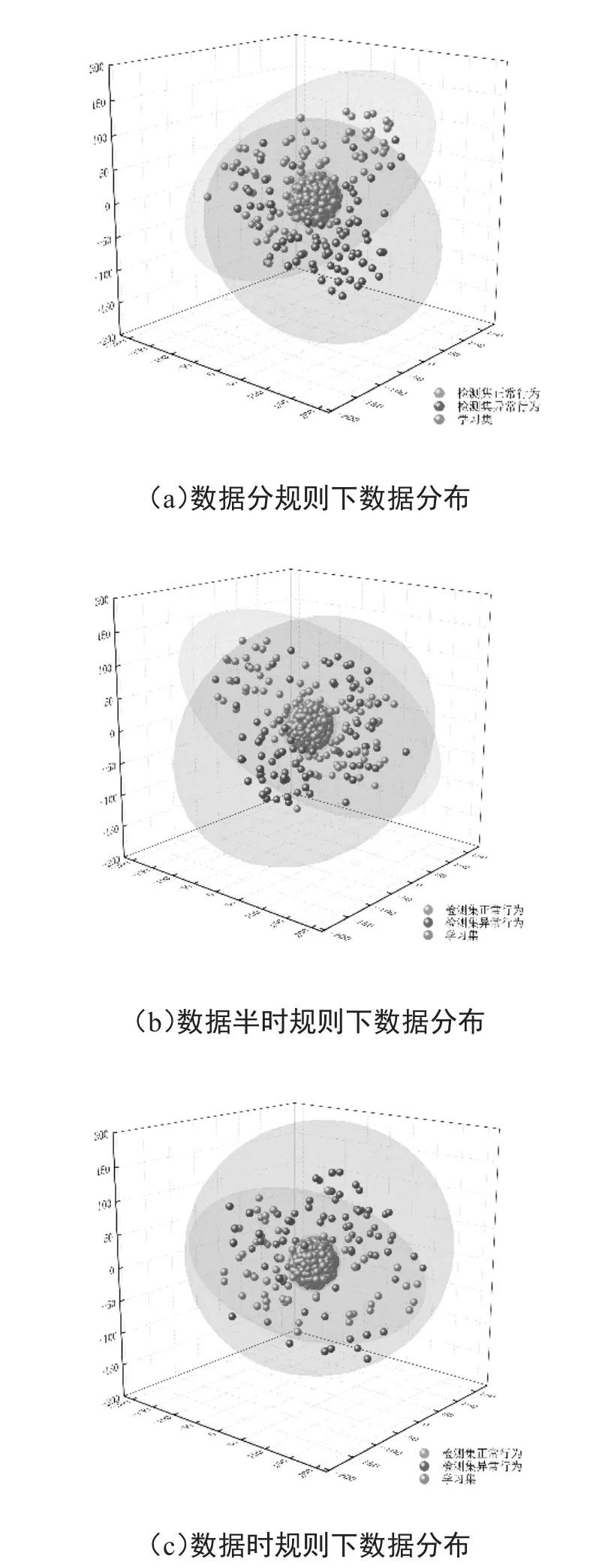
图8 三类时间规则下的数据分布
从图8中可见,数据分和数据半时规则下,检测集的正常数据与异常数据都分布在学习集数据外围,两者间相似度极高,且都与学习集数据分布大相径庭,而在数据时规则下,检测集的正常数据置信度空间明显小于异常数据的置信度空间,更加接近学习集数据分布,因此得出结论,关键特征属性的数字化规则会直接影响算法的结果,同时,解释了在此数据集下数字时规则效果最好。
6 总结和展望
本文提出了一种基于机器学习技术的内网威胁行为发现方法,有效解决了现有方法存在的真实异常样本少、数据标注困难及攻击模式不确定的问题。检测模型围绕用户、设备、行为和作用域四要素,并选取企业真实数据集进行实验验证,主要结论如下:以小时进行检测算法的精准度和召回率普遍更高,相比于其他的异常检测方法,iForest算法效果最好。
形成以上结论的原因为该企业相关用户行为模式单一,在内网访问中用户的正常行为与异常行为数据特征差距大,iForest相较于它的衍生算法可以更准确地检测出异常。在未来工作里,实验将进一步改变攻击方式,在本文基础上增加异常掩盖事件,探索特征属性值数字化最佳细腻度的曲线分布,研究基于iForest树实例的异常阈值自适应的优选方法。
