基于RUSBoost算法的地铁盾构施工安全预警模型研究
2022-03-04李英攀李淑娟孙志凌
李英攀,李淑娟,孙志凌,管 慧
(1.武汉理工大学土木工程与建筑学院,武汉 430070;2.中建三局集团有限公司西南公司,成都 610213)
随着我国城市建设的大力推进,城市交通问题日益严峻,而地铁具备高效、快捷、环保的特点,能有效缓解城市交通拥堵的压力,因此地铁成为解决城市交通问题的首要选择。目前,明挖法、盖挖法、暗挖法、盾构法等是常用的地铁施工方法,其中因盾构法施工对外界环境影响小,并且不受地表环境的限制等优点,在地铁施工中得到了广泛应用。但根据李皓燃等对我国2002~2016年地铁施工区间工程事故的统计数据可知,盾构法施工事故占所有工法施工事故的一半以上,事故发生率最高,累计死亡人数也最多[1]。
因此,已有学者对地铁盾构施工安全问题进行研究,他们在建立安全评估指标体系、安全等级评估等方面提出了许多模型和方法。2013年,丁烈云等[2]首次提出地铁施工安全状态实时感知技术,构建施工实时感知预警系统,实现盾构施工风险“感、传、知、控”一体化。杨仙等[3]提出从“盾构施工设备、水文地质条件、环境影响、盾构操作”4个方面建立盾构施工风险评估体系,采用熵度量法做出了评价。黄俐等[4]根据WBS-RBS理论识别风险因素,进而利用主成分分析提取盾构施工沉降风险的关键因子。宗秋雷等[5]提出基于梯形模糊数和C-OWA算子赋权法的风险评估方法,对地铁盾构施工风险进行评估。赵辉等[6]建立基于PCA-Shapley值的地铁盾构施工风险灰色聚类评价模型,有效消除了指标信息缺失带来的影响。上述研究多采用定性赋值的方法,主观性较强,同时忽略了数据的非平衡问题。一般情况下,事故发生的几率要远小于事故不发生的几率,所以收集到的盾构施工数据中绝大部分样本数据是事故不发生的数据。据此采用欠采样以消除由于事故发生数据较少而产生的数据非平衡问题。
为了实现对盾构施工过程的动态实时监控,构建基于RUSBoost(random under-sampling with AdaBoost)算法的地铁盾构施工安全预警模型。首先以空间单元为对象,在不同的空间单元内获取指标数据构建样本数据集;然后通过RUS(random under-sampling,随机欠采样)从样本数据集中随机抽取一定量的多数类样本和少数类样本组成平衡分布的训练样本集;最后采用Adaboost算法建立地铁盾构施工空间单元安全预警模型,训练好的模型可以实时监控施工现场的安全状态,预警潜在的事故。
1 RUSBoost算法
RUSBoost是一种结合了RUS和Adaboost的混合算法。RUS是随机欠采样,从样本集中随机抽取一定量的多数类样本和少数类样本组成平衡分布的训练样本集。Adaboost是一种迭代算法,其核心思想是每次迭代只训练一个弱分类器,每进行下一次迭代之前需要调整训练样本的权重,调整的方法是根据上一次迭代已经训练好的弱分类器的训练误差进行调整,最后把这些弱分类器加权组合起来,构成一个强分类器[7]。其具体步骤为:
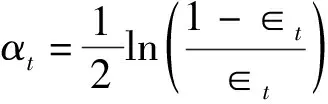
2 识别风险源
首先通过文献分析整理出影响地铁盾构施工的风险因素,构成初始风险因素集;再参照《地铁隧道工程盾构施工技术规程》和行业相关标准,梳理盾构施工作业流程,同时考虑指标数据的可获取性,提炼出修正后的风险因素集,风险应尽可能采用定量的指标进行描述;最后根据工程实际情况和专家意见对指标体系进行进一步修正,建立人、机、料、法、环(4M1E)5项一级指标,25项二级指标的盾构施工安全预警指标体系,如表1所示。
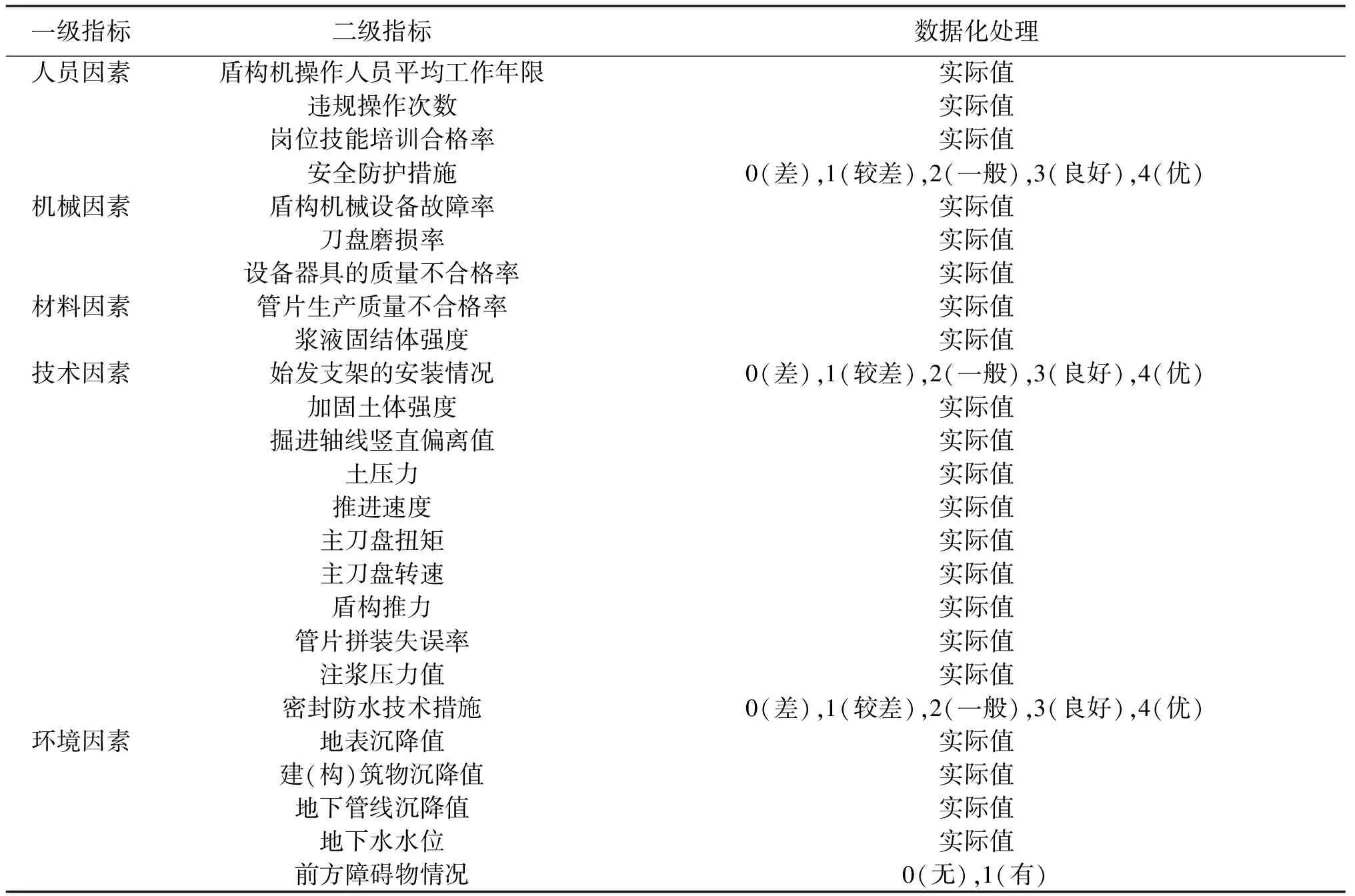
表1 盾构施工安全预警指标体系
3 基于RUSBoost算法的盾构施工安全预警模型
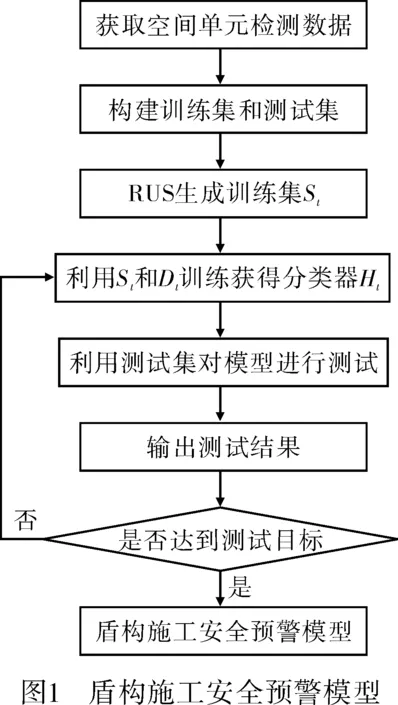
构建基于RUSBoost算法的盾构施工安全预警模型以消除盾构施工数据的类别不平衡问题。首先,因为地铁施工是在一个小间距长距离的空间内,不同区间空间内工程地质条件及周边环境各不相同。为了便于安全监控,这一空间可被分割为若干大小不一的空间单元立方体。在每个空间单元内,定量地提取各类指标数据,构建特征向量以反映空间单元的安全风险。然后,将收集到的样本数据集分为事故发生和事故不发生两类,通过欠采样从数据集中抽取一定量的事故不发生的样本数据和事故发生的样本数据组成平衡分布的训练数据集。最后,利用处理好的样本数据训练AdaBoost分类器,训练好的AdaBoost分类器可以用来监控地铁盾构施工现场的安全状态,提前识别出安全事故隐患,方便施工人员采取控制措施,避免发生危险性事故造成人员伤亡。
盾构施工安全预警模型如图1所示。
4 地铁盾构施工安全预警模型
4.1 数据采集与训练样本集构建
1)样本数据的采集 为构建地铁盾构施工安全预警模型,选取北京、上海、武汉等地区在建地铁盾构施工项目的数据和实际发生的盾构施工事故数据作为样本数据,按照空间单元的规则选取样本数据,得到150个样本空间单元数据特征向量集合。
2)训练样本集构建 将样本数据分为事故发生和事故不发生两种类别,利用RUS随机从训练样本集中抽取一定量的事故不发生样本和事故发生样本组成平衡分布的数据集,最终得到100个平衡分布的训练样本集,剩余的50个混合样本作为测试样本集。
4.2 安全预警模型训练和效验
为了对比RUSBoost算法在不平衡数据集上的优势,选取SVM(Support Vector Machine,支持向量机)分类器的预测结果作对比,其中RUSBoost算法采用AdaBoostM1模型,循环次数为100,弱学习算法采用Tree。利用SVM和RUSBoost算法对同一训练样本集训练模型,然后利用训练好的模型完成对测试样本集的分类预测,并将预测结果与实际事故类别进行对比,以判断模型的预测能力,如图2、图3所示。
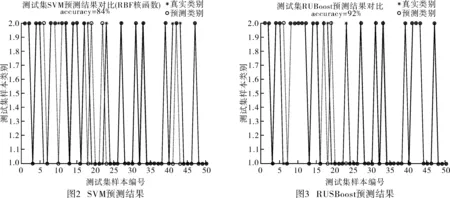
由图可知,SVM预测模型对测试样本集的预测准确率是84%,总用时54.16 s;而RUSBoost预测模型的准确率是92%,总用时1.49 s。测试样本集的预测结果说明RUSBoost模型具有良好的泛化能力,预测准确率较高,且运行时间短,具备一定的可推广性。
5 结 论
a.地铁盾构施工空间单元的划分对预警模型的准确性有很大的影响,不合理的空间单元划分将降低模型预测的准确性。
b.利用RUSBoost算法构建的地铁盾构施工安全预警模型运行时间短,具有良好的泛化能力。
c.地铁盾构施工安全预警模型尚未在实践中进行充分验证,下一步研究可根据实践反馈的情况修正安全预警指标体系,细化指标预警阈值,提高安全风险识别的准确性。
