Geohash编码的k匿名位置隐私保护方案
2022-03-04殷凤梅
殷凤梅,陈 鸿
合肥师范学院计算机学院,安徽 合肥 230601
0 引言
基于位置的服务(location based service,LBS)是通过无线电通信技术或全球定位系统(global positioning system,GPS)获取移动终端用户的位置信息,在地理信息系统(geographic information sys⁃tem,GIS)的支持下,为移动终端用户提供相应服务[1]。随着通信技术和GPS的发展,LBS得到广泛的应用。人们在享受交通导航、网上订票等LBS带来便捷的同时,也在承担着个人位置隐私泄露的风险。攻击者能够从位置信息中,推测出用户的家庭地址、工作地点、常去的服务场所等隐私信息,了解到用户的行动轨迹[2]。随着LBS使用规模的不断增长,位置隐私的安全问题成为了重要的研究课题[3,4]。
位置隐私保护按照体系结构大致分为两类:基于匿名中心的位置隐私保护方案[5,6]和基于移动终端的位置隐私保护方案[7~11]。在基于匿名中心的位置隐私保护方案中,用户和LBS服务器之间,引入可信的匿名中心,匿名中心通过隐私保护技术[12,13]将用户的位置服务信息匿名化,再发送给LBS服务器请求服务,并将LBS服务器反馈的服务结果返回给用户。在这类方案中,匿名中心承担着主要的计算和通信工作,成为整个系统的安全瓶颈,一旦被攻克,所有用户的隐私信息都将被泄露。Peng等[14]使用半可信匿名中心替代匿名中心,但半可信匿名中心依旧会成为系统的安全瓶颈。为了避免单匿名中心的安全瓶颈问题,张少波等[3]引入多个分布式匿名服务器,但该方案会引起系统开销的增加。随着移动终端不断智能化,计算和存储能力大大增强,出现了基于移动终端的位置隐私保护方案。这类方案不再设置匿名中心,移动终端用户直接与LBS服务器通信,获得请求查询服务的结果,从而避免了匿名中心的安全瓶颈和单点泄露问题。很多学者基于移动终端展开位置隐私保护研究,例如,李维皓等[8]使用移动模型预测用户移动轨迹,利用时空关联性生成伪位置来避免位置隐私泄露。Hayashida等[9]利用旅行推销商贪心算法生成虚假轨迹来隐藏用户的隐私位置。Niu等[10]使用背景信息中的历史查询概率,并尽量选择相隔较远的匿名位置来实现位置隐私保护。李维皓等[11]在背景信息的基础上,考量了用户和LBS服务器短期缓存的查询记录,实现自关联隐私保护算法。
位置隐私保护通常使用k匿名技术,它是由Gruteser等[15]最先提出的。该技术将用户的真实位置与其他k-1个虚假位置组成匿名位置集,发送给LBS服务器请求服务,如此一来,用户的真实位置被猜测成功的概率为1/k,从而有效地实现了用户位置的匿名。其中,k代表隐私度,由用户根据需求确定数值。为了构建匿名位置集,通常需要查询历史请求记录,可是检索庞大的历史记录,时间开销较大,使得位置服务失去了即时的优越性。为了给用户提供即时的位置服务,本文借助Geohash编码[16],实现了面向移动终端用户的k匿名位置隐私保护方案。
1 基本概念
1.1 区间区域
lat代表纬度(Latitude),lng代表经度(Longi⁃tude)。通常约定纬度在前,经度在后,经度与纬度组成地理坐标系统(geographic coordinate system,GCS),简称坐标系统。GCS使用三维球面来定义地球表面位置,能够标示地球上的任何一个位置。经度的区间范围为[-180°,180°],东经为正数,西经为负数;纬度的区间范围为[-90°,90°],北纬为正数,南纬为负数。
如果将用户的经纬度坐标,泛化到一个经纬度区间([lat1,lat2],[lng1,lng2]),那么这个区间所表示的区域称为区间区域。
一个用户的经纬度坐标(30.299 4°,70.153 6°),泛化后的区间区域([30.273°,30.311 9°],[70.130 6°,70.176 6°]),如图1中红色方框。泛化的方法将在2.3节描述。
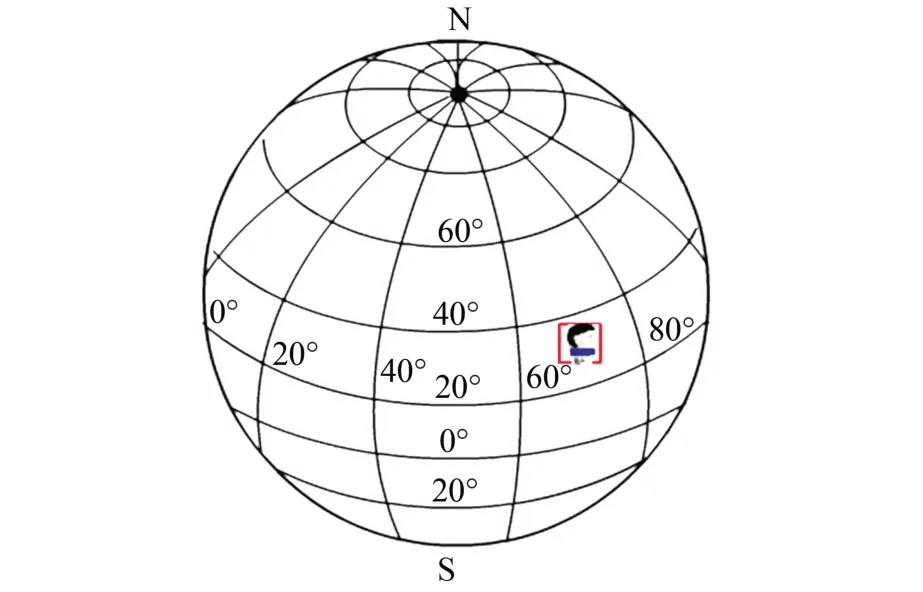
图1 位置坐标泛化后的区间区域Fig.1 Interval region after generalization of position coordinates
1.2 Geohash编码
Geohash算法[17]将二维经纬度坐标转换为一维字符串的地理位置编码。Geohash算法利用数据结构的二分法,沿着经度和纬度两个不同方向,交替地二分地球表面。具体过程如下。
Step 1经度区间的划分。对[-180°,180°]进行二分,区间的中位值=(-180°+180°)/2=0°,小于中位值则为左区间[-180°,0°),标记为0;否则将右区间[0°,180°]标记为1。采用同样的方法继续对左右经度区间进行二分,直到需要的精度停止,得到一个由0和1组成的经度编码序列。
Step 2纬度区间的划分。对[-90°,90°]进行二分,区间的中位值=(-90°+90°)/2=0°,小于中位值则为左区间[-90°,0°),标记为0;否则将右区间[0°,90°]标记为1。采用同样的方法继续对左右纬度区间进行二分,直到需要的精度停止,得到一个由0和1组成的纬度编码序列。
Step 3交错排列。按照偶数位放经度编码,奇数位放纬度编码,将经度字符串和纬度字符串合并成一个新的编码序列。
Step 4分组转换。将新的编码序列从右向左,每5位成一组,最后一组不够5位,左边补0。每组的5位编码转换成一个十进制数。
Step 5Base32编码。对照Base32编码表,将每个十进制数转换成Base32码,按序存放各个Base32码,形成Geohash编码。
例如,对图1中的用户经纬度坐标(30.299 4°,70.153 6°),纬度30.299 4°按照表1进行纬度编码,得到二进制编码序列101010110001011,经度70.153 6°按照表2进行经度编码,得到二进制编码序列101100011110001。纬度编码和经度编码交错排列后,形成新的二进制编码序列11001 11001 00011 11010 10010 00111,转换成十进制数序列25 25 3 26 18 7。按照表3将十进制数序列转换成Geo⁃hash编码tt3uk7。
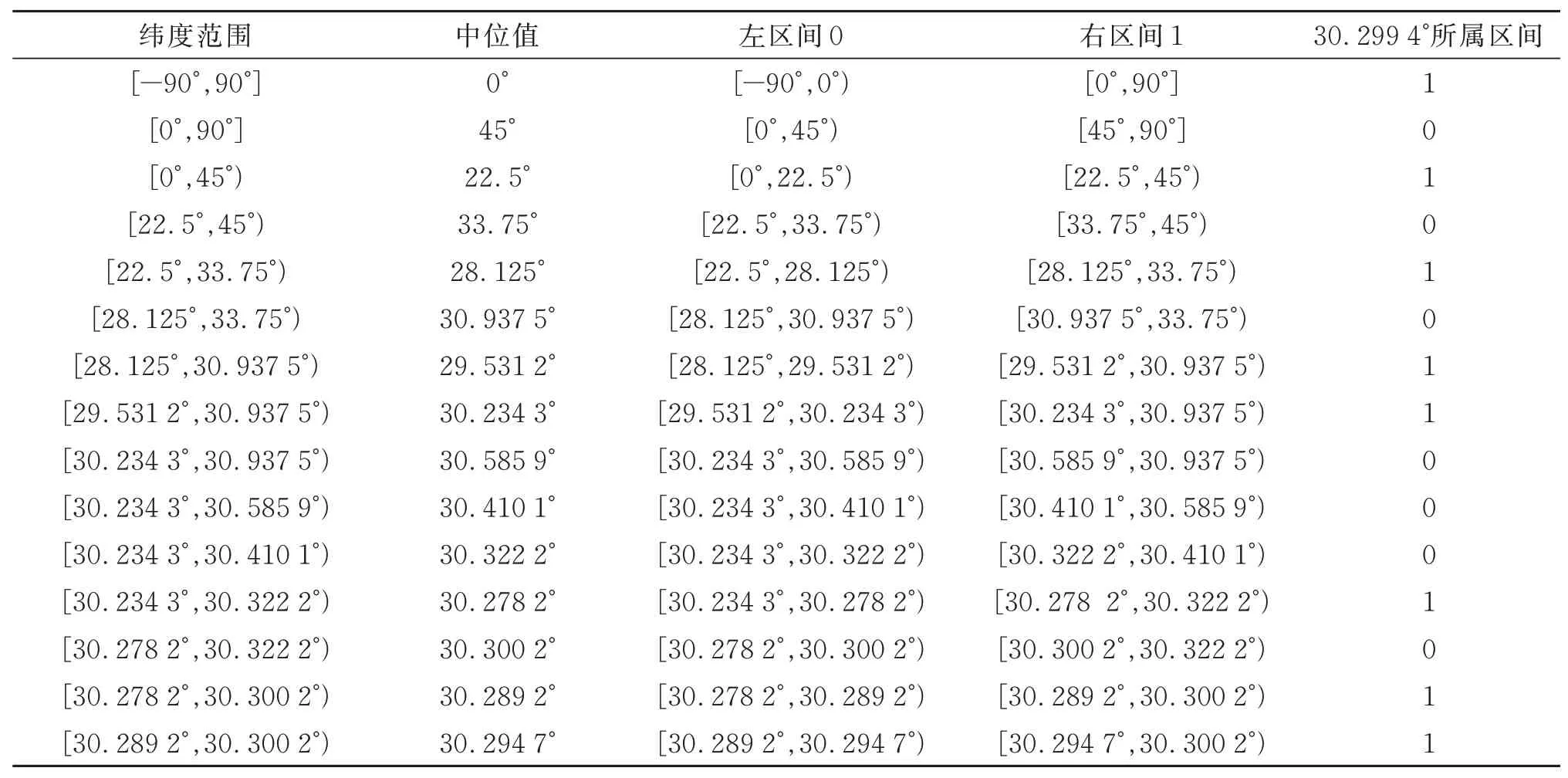
表1 纬度编码Table 1 Latitude Encoding

表2 经度编码Table 2 Longitude Encoding
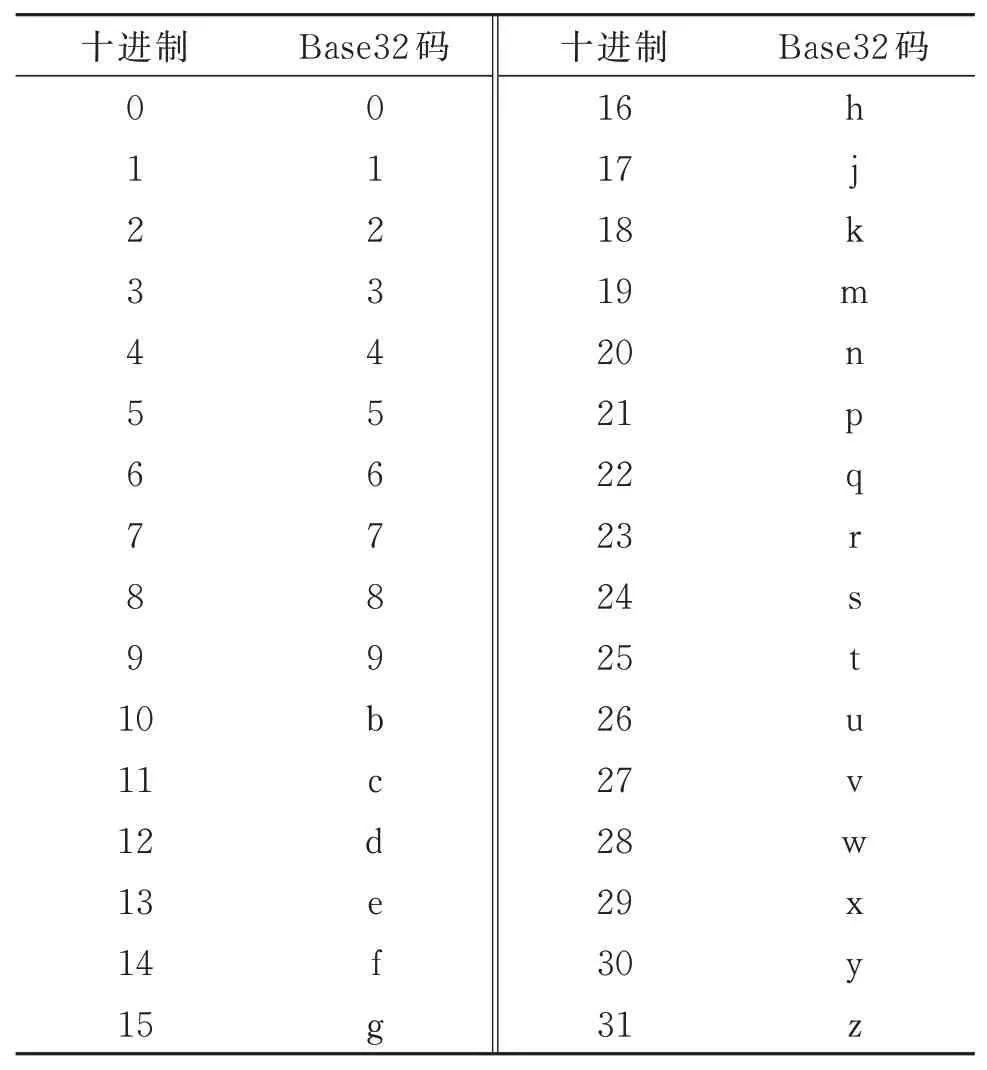
表3 Base32编码表Table 3 Base32 Elphabet
Geohash编码代表的是一个矩形区域,编码的长度越短,矩形区域越大;编码的长度越长,矩形区域越小。当纬度相同时,经度每隔0.000 01°,宽度相差大约1 m;每隔0.000 1°,宽度相差大约10 m。以此类推,每隔0.1°,宽度相差大约10 000 m。当经度相同时,纬度每隔0.000 01°,宽度相差大约1.1 m;每隔0.000 1°,宽度相差大约11 m。以此类推,每隔0.1°,宽度相差大约11 132 m。可见,Geohash编码长度越长,所表示的范围就越精确。例如,编码长度为5时,精度大约为4 900 m;编码长度为8时,精度大约为19 m。Geohash编码长度取决于位置隐私保护的强度,由用户指定。用户想获得较高的位置隐私保护强度,矩形区域需要较大,对应的编码长度就短一些。
1.3 双线性映射
对于阶为q的加法循环群G1和乘法循环群GT,双线性映射e:G1×G1→GT具有如下性质:
1)双线性:任意的Q1,Q2∈G1,x,y∈ℤp,满足e(x Q1,yQ2)=e(Q1,Q2)xy;
2)可 计 算 性:任 意 的Q1,Q2∈G1,均 可 计 算e(Q1,Q2);
3)非退化性:任意的Q1,Q2∈G1,满足e(Q1,Q1)≠I,I为GT中的单位元;
4)对称性:任意的Q1,Q2∈G1,满足e(Q1,Q2)=e(Q2,Q1)。
1.4 双线性映射的相关问题假设
1)椭圆曲线离散对数(elliptic curve discrete logarithm,ECDL)问题
椭圆曲线上阶为q的循环群G,P为G的生成元,给定Q=x P∈G(随机数x∈ℤ*q值未知),敌手在多项式时间内计算x。若满足AdvECDLA=Pr[A(Q,P)=x]≥ε,则说明:不存在概率多项式时间算法A,以不可忽略的概率ε解决ECDL问题。
2)双线性Diffie⁃Hellman(bilinear Diffie⁃Hell⁃man,BDH)问题
对于阶为q的加法循环群G1和乘法循环群GT,P为G1的生成元,双线性映射e:G1×G1→G T,给定输 入(P,x P,yP,zP)∈G1(随 机 数x,y,z∈ℤ*q值 未知),敌手在多项式时间内计算e(P,P)xyz∈GT。若满足

则说明:不存在概率多项式时间算法A,以不可忽略的概率ε解决BDH问题。
3)判定双线性Diffie⁃Hellman(decisional bilinear Diffie⁃Hellman,DBDH)问题
对于阶为q的加法循环群G1和乘法循环群GT,P为G1的生成元,双线性映射e:G1×G1→G T,给定输入(P,x P,yP,zP,C)(随机数x,y,z∈ℤ*q值未知,C∈GT),敌手在多项式时间内判断等式C=e(P,P)xyz是否成立。若满足
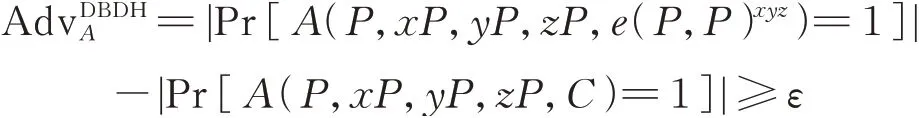
则说明:不存在概率多项式时间算法A,以不可忽略的概率ε解决DBDH问题。
1.5 位置熵
匿名区域AA中包括k个候选位置,假设各个候选位置被检索的概率分别为Q i(i∈[1,k]),则每个候,位选位置成为真实位置的概率为如果候选位置熵[18]为置的位置熵越大,隐私度就越高。
2 k匿名位置隐私保护方案
本文提出的位置隐私保护方案由两类实体:移动终端用户(mobile user,MU)和LBS服务器组成,如图2所示。
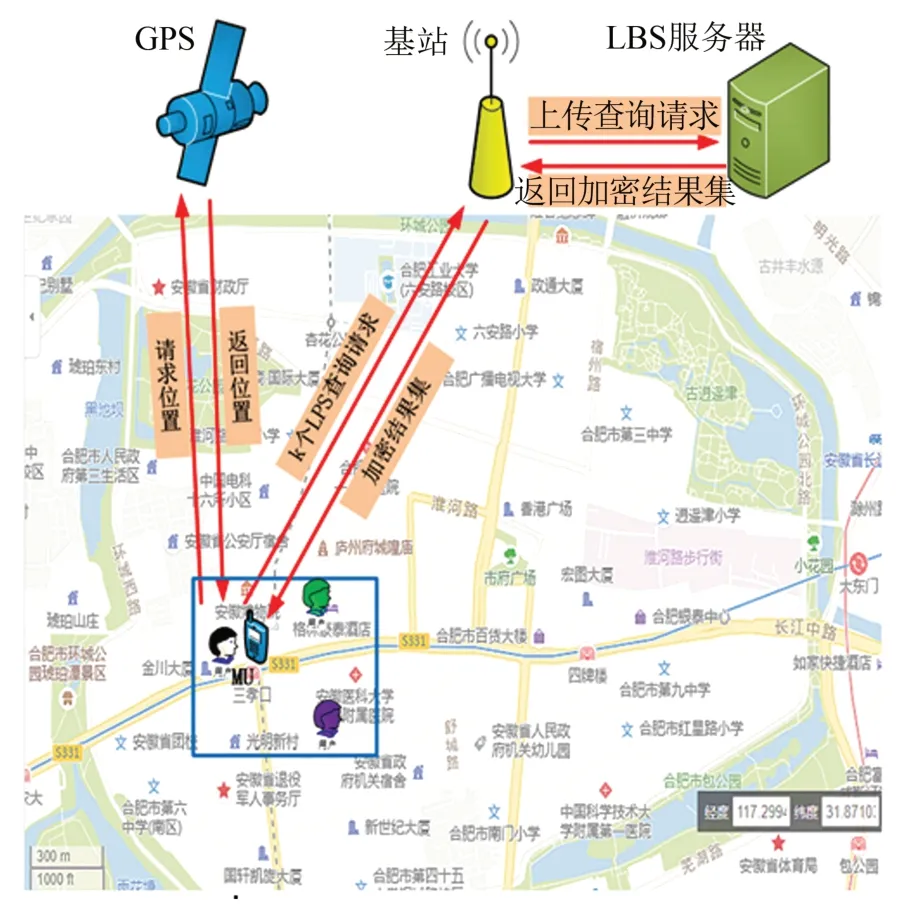
图2 位置隐私保护系统模型Fig.2 System model of location privacy preservation
位置隐私保护方案采用k匿名机制,两类实体之间的操作步骤和信息交流如下。
Step 1MU通过智能手机向GPS请求自身位置,获得经纬度坐标(lat,lng)后,在周围生成k-1个虚假位置和虚假查询,然后将自身位置、真实查询和k-1个虚假位置、虚假查询,组成k个查询请求,发送给LBS服务器。
Step 2LBS服务器收到查询请求后,获取k个查询结果,加密查询结果并通过基站返回给MU。
Step 3MU收到加密的查询结果后,解密获得想要的查询结果。
2.1 系统初始化
对于LBS服务器,按照下面的步骤获取系统私钥,公开系统公共参数。
Step 1选择一个大素数p,q是p-1的大素因子,阶为q的加法循环群G1和乘法循环群G2,P为G1的生成元,存在双线性映射e:G1×G1→G2。
Step 2设置3个哈希函数H2:G2→{0,1}n,H3:SHA 256哈希函数。其中,n是一个整数,{0,1}*是任意长度的二进制字符串。
Step 3选取一个随机数s∈ℤq*作为系统的私钥并保密存储,计算对应的公钥PK=s⋅P。Step 4g是ℤq*上的q阶元素,将S=g smodp保密,计算验证参数SPK=S⋅P,以便用户验证注册信息。
Step 5公 开 系统 公 共 参 数:{G1,G2,H1,H2,q,P,e,n,PK,SPK}。
2.2 用户注册
移动终端用户MU需要向系统注册,注册过程如下。
Step 1MU将k个身份信息组成的集合ID={ID1,ID2,…,IDu,…,IDk}发送给LBS服务器进行注册申请。其中,IDu作为MU的真实身份,隐藏在集合ID中,u∈[1,k],其值由MU指定。
Step 2LBS服务器选择随机数IDanony∈ℤq*,为每个IDi计算假名PIDi=H3(IDi+IDanony)、公钥PKIDi=H1(IDi)和私钥SKIDi=S⋅PKIDi,生成信息Reg={(PID1,PKID1,SKID1),(PID2,PKID2,SKID2),…,(PIDk,PKIDk,SKIDk)},并通过安全信道反馈给MU。
Step 3MU收到Reg后先计算PKIDu=H1(IDu),然 后 验 证 等 式e(SKIDu,P)=e(PKIDu,SPK)是否成立。若成立,则MU收到了正确的假名、公钥和私钥;否则,MU转Step 1重新注册。
2.3 位置泛化
MU通过GPS获得自己的经纬度坐标位置(lat,lng)后,将坐标位置泛化到一个区间区域内。MU根据自身所处的位置是在人口密集的城市还是在稀疏的乡村,选择不同大小的随机数来构建区间区域。若处在人口较为稀疏的乡村,为了提高位置隐私保护的强度,MU匿名的泛化区域设置大一点,随机数选择也大一些。反之,若处在人口较为密集的城市,为了提高查询服务的精度,MU匿名的泛化区域设置小一点,随机数选择也小一些。
1)人口较为稀疏的乡村:从[0°~0.025°]区间中随机选择4个随机数r1,r2,r3,r4,为了避开区间的对称性猜测,泛化区间时不同时向前或向后波动随机数,泛化后的区间区域可以表示为([lat-r1,lat+r2],[lng-r3,lng+r4])。从1.2节可知,经度0.025°大约对应2.5 km的距离,纬度0.025°大约对应2.75 km的距离。若经纬度向前后各波动0.025°,泛化的区间范围大约为(0.025×2/0.025)×2.5×(0.025×2/0.025)×2.75=27.5 km2。通常,随机数的产生遵循正态分布,即在区间的中位值(0°+0.025°)/2=0.0125°左右波动,而接近区间的端点0°和0.025°较少。因此,按照平均波动0.012 5°来计算,泛化的区间范围平均为(0.0125×2/0.025)×2.5×(0.0125×2/0.025)×2.75=6.875 km2。
2)人口较为密集的城市:从[0°~0.01°]区间中随机选择4个随机数r1,r2,r3,r4,泛化后的区间区域([lat-r 1,lat+r 2],[lng-r 3,lng+r 4])。经度0.01°大约对应1 km的距离,纬度0.01°大约对应1.1 km的距离。若经纬度向前后各波动0.01°,泛化的区间范围大约为(0.01×2/0.01)×1×(0.01×2/0.01)×1.1=4.4 km2。通常,随机数在区间的中位值(0°+0.01°)/2=0.005°左右波动,而接近区间的端点0°和0.01°较少。因此,按照平均波动0.005°来计算,泛化的区间范围 平均为(0.005×2/0.01)×1×(0.005×2/0.01)×1.1=1.1 km2。
2.4 反向检索位置
MU按照1.2节的方法生成Geohash编码,其对应一个矩形区间,如图3所示。该区间内的所有位置,其Geohash编码相同。
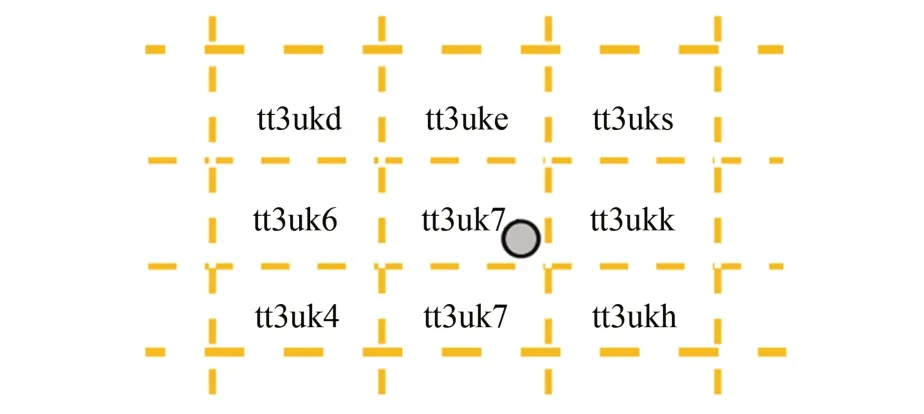
图3 Geohash位置区间Fig.3 Geohash location interval
检查相同Geohash编码的位置个数,如果与k值相等,则返回这k个位置组成的匿名位置集C。如果小于k值,则扩大到相邻的8个矩形区域。倘若扩大区域后匿名位置的个数仍然小于k值,可以再扩大一圈矩形区间,当然这种情况一般很少出现。如果大于k值或经过扩大区域后大于k值,转筛选多余位置。
2.5 筛选多余位置
如图4所示,将匿名位置的分布区域等分为8×8的位置单元,根据历史查询概率[19],每个位置单元填充不同的灰度。其中,灰度越深,代表历史查询概率越高;反之,灰度越浅,代表历史查询概率越低。

图4 匿名位置的分布Fig.4 Distribution of anonymous locations
假设k=5,则除了MU自身位置外,还需要再筛选出k-1=4个匿名位置。在t时刻,MU位于位置单元C1中,其历史查询概率为P(C1)。而C2~C10各个区间的历史查询概率P(Ci)=P(C1)(i=2,3,…,10)。若在t-1时刻,MU刚刚在C5处发起过相似查询。当两个时刻之间的差值Δt足够小时,攻击者会发现MU在短时间内搜索过C5处的服务,从而使得该位置被泄露的概率由1/5增加到1/4,提高了隐私泄露的风险。因此,排除查询过的C5位置,匿名查询位置集C={C1,C2,C3,C6,C10}。
2.6 请求位置服务
假设经过反向检索后,MU得到的匿名位置集C={C1,C2,…,Cu,…,Ck}。其中,Cu是MU的真实位置,隐藏在集合C中,只有MU知道u的值。MU请求位置服务过程如下。
Step 1LBS服务器随机选择n(n≥k)个随机数d i∈ℤq*,计算Pi=d i⋅PK,将{P1,P2,…,Pn}作为选择基点公布。
Step 2MU随机选择k个基点和k个随机数ai∈ℤq*,计算V i=ai⋅Pi,i=1,2,…,k。Step 3MU结合注册阶段获得的k个假名集合,反向检索阶段获得的k个匿名位置集合,以及伪查询内容集合,生成查询信息Msg={(PID1,C1,Q1,V1),(PID2,C2,Q2,V2),…,(PIDk,Ck,Qk,V k)}发送给LBS服务器请求位置服务。其中,Qu是Cu的真实查询请求。
Step 4LBS服务器收到Msg后,获取k个查询结果的集合M={m1,m2,…,mu,…,mk},选取随机 数b∈ℤq*,计 算Y0=b⋅PK,Y i=b⋅V i,ni=mi⊕H2(e(Pi+S⋅PK,PKIDMU)b)将 Res={Y0,(Y1,Y2,…,Y k),(n1,n2,…,nk)}反馈给MU。
Step 5MU收到Res信息后,判断e(V u,Y0)=e(Y u,PK)是否 成立。若成立,计算乘法逆元au
-1∈ℤq*和解密密钥A u=au-1⋅Y u,计 算mu=nu⊕H2(e(A u,PKIDMU),e(Y0,SKIDMU)),获取需要的查询结果。
3 方案分析
3.1 性质分析
定理1正确性:用户可以通过计算mu=nu⊕H2(e(A u,PKIDMU),e(Y0,SKIDMU))获 得 正 确的查询结果。
证

则
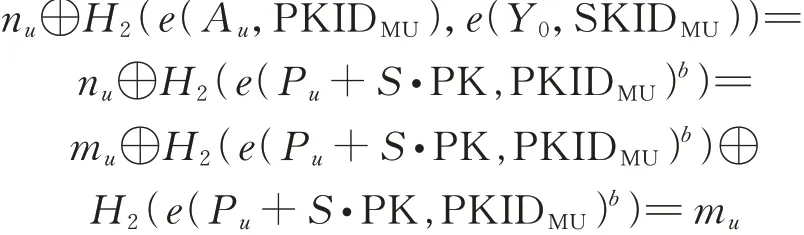
因此,用户可通过计算nu⊕H2(e(A u,PKIDMU),e(Y0,SKIDMU))获得查询结果mu。
定理2验证性:用户可以验证来自LBS服务器信息的真伪。
证在用户注册阶段,为了防止LBS服务器发来的信息Reg={(PID1,PKID1,SKID1),(PID2,PKID2,SKID2),…,(PIDk,PKIDk,SKIDk)}中(PIDu,PKIDu,SKIDu)被篡改,用户MU先计算PKIDu=H1(IDu),再验证等式e(SKIDu,P)=e(PKIDu,SPK)是否成立。因 为e(SKIDu,P)=e(S⋅PKIDu,P)=e(PKIDu,S⋅P)=e(PKIDu,SPK),可见,在用户注册阶段,MU可以验证来自LBS服务器信息的真伪。
在请求服务阶段,当MU收到来自LBS服务器发来的信息Res={Y0,(Y1,Y2,…,Y k),(n1,n2,…,nk)}后,判断e(V u,Y0)=e(Y u,PK)是否成立。因为e(V u,Y0)=e(V u,b⋅PK)=e(b⋅V u,PK)=e(Y u,PK)。因此,在请求服务阶段,MU可以验证来自LBS服务器信息的真伪。
综上所述,用户可以验证来自LBS服务器信息的真伪。
定理3匿名性:用户位置服务满足匿名性。
证假设攻击者A从LBS服务器发送给用户MU的信息res={Y0,(Y1,Y2,…,Y k),(n1,n2,…,nk)}中,获取了k个密文结果{n1,n2,…,nk},其中,nu=mu⊕H2(e(Pu+S⋅PK,PKIDMU)b)。A企图获得MU的真实查询结果mu,需要通过mu=nu⊕H2(e(Pu+S⋅PK,PKIDMU)b)=nu⊕H2(e(d u⋅PK+S⋅PK,PKIDMU)b)完成计算,这就需要获取u、d u、s和b这4个数值。如果A可以获得这4个数值,就能获得MU的真实查询结果,用户失去匿名性保护。反之,A不能获得MU的真实查询结果,用户保持匿名性。下面的任务就转换到A能否获得上述4个数值。A获得的k个密文结果{n1,n2,…,nk},其中,nu是与MU的真实身份和真实位置相关联的,u的值是由用户指定的,A并不知道,u值被猜测出来的概率为1/k。另外,s、d u和b是LBS服务器从Zq*中选择的随机数,对A保密。如果A试图从公开的PK=s⋅P中获得s,信息Res的Y0=b⋅PK中获得b,LBS服务器公布的基点Pu=d u⋅PK中获得d u,就需要攻克ECDL难题,而在现阶段这种计算是不可行的。综上所述,本文方案满足匿名性。
3.2 安全性分析
攻击1伪装攻击:①攻击者企图通过获得的信息,伪装成用户MU的身份,获得位置请求服务。②攻击者企图伪装成LBS服务器,完成用户的注册申请和请求位置服务。
攻击①:攻击者A企图将自己的查询服务信息隐藏在用户MU的查询请求信息Msg={(PID1,C1,Q1,V1),(PID2,C2,Q2,V2),…,(PIDa,Ca,Qa,V a),…,(PIDk,Ck,Qk,V k)}中,发送给LBS服务器申请位置服务。LBS服务器反馈加密的查询结果信息Res={Y0,(Y1,Y2,…,Y k),(n1,n2,…,na,…,nk)},A需要通过ma=na⊕H2(e(Pu+S⋅PK,PKIDMU)b)或ma=na⊕H2(e(A u,PKIDMU),e(Y0,SKIDMU))=na⊕H2(e(au-1⋅Y u,PKIDMU),e(Y0,SKIDMU))获 取解密的查询结果。通过3.1节分析可知,A无法获得b和s,因而无法通过ma=na⊕H2(e(Pu+S⋅PK,PKIDMU)b)获得解密的查询结果。同理,A无法获得MU选择的au和私钥SKIDMU,因而无法通过ma=na⊕H2(e(au-1⋅Y u,PKIDMU),e(Y0,SKIDMU))获得解密的查询结果。因此,攻击者不能伪装成用户MU的身份,获得位置请求服务。
攻击②:攻击者A企图伪装成LBS服务器,完成用户的注册申请和请求位置服务。在用户注册阶段,A为了伪装成LBS服务器,需要将Reg={(PID1,PKID1,SKID1),(PID2,PKID2,SKID2),…,(PIDk,PKIDk,SKIDk)}反馈 给 注 册 用户,则 需要 计 算 出SKIDi=S⋅PKIDi。由于S=g smodp是保密的,并且A在现阶段很难攻克ECDL难题,便不能从SPK=S⋅P求出S,继而计算出SKIDi。当无法计算出SKIDi,A可能伪造一对PKIDu和SKIDu,试图通过e(SKIDu,P)=e(PKIDu,PK)验 证,则 需 要 解 决DBDH难题,而在现阶段仍无法攻克DBDH难题。因而,攻击者无法伪装成LBS服务器完成用户注册申请。在请求位置服务阶段,A为了伪装成LBS服务器,需要将Res={Y0,(Y1,Y2,…,Y k),(n1,n2,…,nk)}反馈给请求用户,则需要计算出Y0=b⋅PK,Y i=b⋅V i,ni=mi⊕H2(e(Pi+S⋅PK,PKIDMU)b),这时,A同样需要面临ECDL难题。当无法计算出Res,A可能会伪造数据,企图通过e(V u,Y0)=e(Y u,PK)验证,则同样需要攻克现阶段无法攻克的DBDH难题。因而,攻击者无法伪装成LBS服务器完成用户请求位置服务。
综上所述,本文方案可以抵抗伪装攻击。
攻击2重放攻击:假设攻击者截获了已注册用户MU的注册请求信息和请求位置服务信息,重新发送给LBS服务器,企图获得与MU同样的服务。
攻击者A可以获得的信息:①系统的公共参数{G1,G2,H1,H2,q,P,e,n,PK};②用户MU的注册请求信息ID={ID1,ID2,…,IDu,…,IDk};③LBS服务器公布的基点信息{P1,P2,…,Pn};④MU的查询请求信息Msg={(PID1,C1,Q1,V1),(PID2,C2,Q2,V2),…,(PIDk,Ck,Qk,V k)};⑤LBS服务器反馈的查 询 结 果 信 息Res={Y0,(Y1,Y2,…,Y k),(n1,n2,…,nk)}。
当A将MU已注册的请求信息ID={ID1,ID2,…,IDu,…,IDk}重新发送给LBS服务器申请注册时,LBS服务器会重新选择一次性随机数ID′anony∈ℤq*,生成不同的假名PIDi′=H3(IDi+ID′anony)。因而,即使A使用雷同的身份信息再次注册,LBS服务器也不会返回相同的假名,即不会获得相同的注册请求结果。
当A将MU已请求的查询信息Msg={(PID1,C1,Q1,V1),(PID2,C2,Q2,V2),…,(PIDk,Ck,Qk,V k)}重新发送给LBS服务器申请位置服务时,LBS服务器会重新选择一次性随 机数b′∈ℤq*,计算mi⊕H2(e(Pi+S⋅PK,PKUMU)b′),生成不同的服务结果因而,即使A使用雷同的请求查询信息再次请求服务,LBS服务器也不会返回相同的服务结果,且A也 无 法 解 密 其中的密文信息(n1′,n2′,…,nk′)。
综上所述,攻击者不能通过重放已注册的请求信息和请求位置服务信息,获得与已注册用户同样的服务,本文方案可以抵抗重放攻击。
攻击3共谋攻击:攻击者企图与位置服务器或某些恶意用户共谋,猜测出用户MU的真实身份。
假设攻击者A与位置服务器LBS服务器共谋。由于本文方案在泛化区间时使用了4个随机数,且不同时向前或向后波动,防止了区间对称性猜测。可见,泛化区间的生成存在随机因素,匿名位置的产生没有任何规律。A或LBS服务器也只能从MU发送的请求位置服务信息中猜测MU的真实身份,概率为1/k。因此,本文方案可以抵抗攻击者与位置服务器的合谋攻击。
假设攻击者A与恶意用户共谋。本文方案将用户MU的经纬度坐标位置泛化到一个区间区域内,并进行Geohash编码。如果相同Geohash编码的位置个数等于k,直接组成匿名位置集,这时攻击者猜测出MU真实身份的概率为1/k。如果相同Geohash编码的位置个数小于k,则扩大到相邻的8个矩形区域。扩大区域后,匿名位置的个数一般会大于k。MU剔除自己刚刚查询过的位置,筛选出历史查询概率相同的k-1个位置,再融入自身位置,构成k个匿名位置集。在这个过程中,攻击者A只能获得共谋用户的历史查询概率,并不能获得被攻击用户MU的历史查询概率,攻击者猜测出MU真实身份的概率为1/k。因此,本文方案可以抵抗攻击者与恶意用户的合谋攻击。
4 仿真分析
基于位置隐私保护的系统模型,从处理数据的时间开销和匿名隐私度两个方面进行仿真分析。仿真实验硬件环境i3-8100T CPU、8 GB RAM,软件 环 境Windows 10 64bit OS、codeblocks-17.12软件。
4.1 处理数据的时间开销
本文方案采用Geohash编码技术来生成匿名位置集,匿名位置集还可以通过曼哈顿距离[20]或欧氏距离[21]的计算来构造。实验位置数据集选用Geo⁃life数据集[22],其中,第一条位置数据作为用户的真实位置,然后采用三种不同方法生成匿名位置集。
如图5所示,当数据量增加时,三种方法的时间开销都在增加。其中,欧氏距离方法存在乘法运算,时间开销增长最快;Geohash编码方法只是将二维的位置数据转换成一维的字符串,相比较而言,基本没有计算量,时间开销增长很小。

图5 生成匿名位置集的时间开销比较Fig.5 Comparison of the time cost of constructing anonymous location set
4.2 匿名隐私度
用户位置匿名保护的程度常用位置熵来度量,熵值越大,隐私保护度就越高,当匿名位置集里的所有位置点查询概率均相等,熵值将达到最大。匿名熵与用户选择的匿名度k值有关,k值越大,用户真实位置的隐藏效果就越好,但会增加系统的通信开销和效率。
仿真实验k值取[10,80],效果如图6所示。当k值增加时,位置熵会增大,但k值增加到一定数值后,位置熵增长的速度会趋于平缓,说明在一定的匿名区域内,假位置过于密集,混淆能力也趋于饱和,这时再增加假位置的数量,对用户真实位置的保护效果欠佳。在本文方案中,当匿名位置的个数小于k,选用查询概率相同的k-1个位置构成匿名位置集,位置熵达到最大,隐私保护度较高。
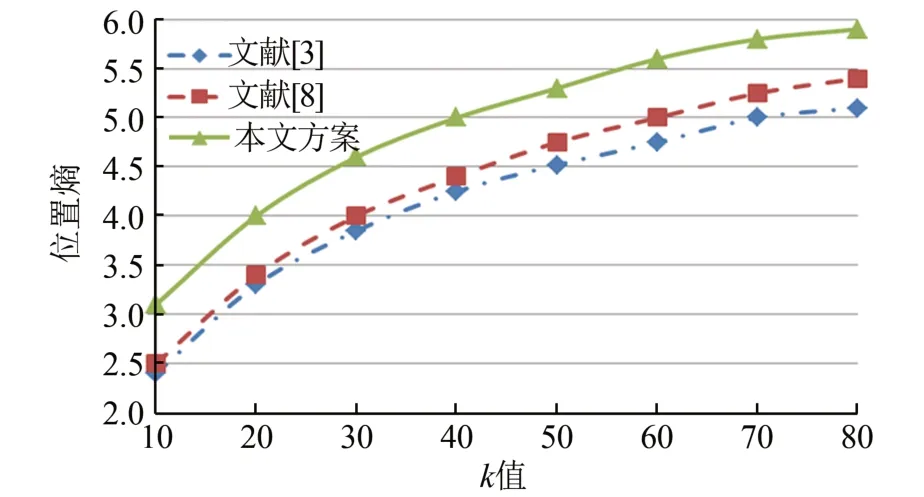
图6 位置熵与k值的关系Fig.6 Relationship between position entropy and k value
5 结语
现有的很多k匿名位置隐私保护方案因为检索历史数据库的时间开销较大,位置服务失去了即时的优越性。本文方案通过Geohash编码,将用户的真实位置泛化到一个区间区域,该区域内所有位置的Geohash编码相同,通过反向检索构成匿名位置集,筛选多余位置时兼顾历史查询概率,这样可以避免检索的时间滞后性,给用户提供即时的位置服务。通过性质分析,在双线性映射的相关问题假设前提下,方案满足正确性、验证性和匿名性,可以抵抗伪装攻击、重放攻击和共谋攻击。仿真实验显示,在处理数据的时间开销和匿名隐私度上,本文方案具有更好的优越性。位置数据不是一个离线的静态数据,而是一段持续的动态数据,未来的工作还需要处理运动用户的位置请求匿名服务。
