基于非对称双路识别网络的步态识别方法
2022-03-02周潇涵王修晖
周潇涵,王修晖
中国计量大学 信息工程学院,浙江省电磁波信息技术与计量检测重点实验室,杭州310018
步态是指人在行走过程中有规律的姿态变化,是一种行为生物特征。已有大量的医学和物理证据表明每个人的步态都具有差异性。相较于其他生物特征,如面部和虹膜,步态更适合长距离和非合作的情形。但是步态也由于自身的局限性,对多种因素敏感,包括视角、衣服和携带物等。由于不同视角而引入外观差异,其被称为跨视角问题,是步态识别中的难点之一。
为了解决跨视角问题,研究者们尝试过不同的步态模板。步态能量图(gait engery image,GEI)[1]是沿时间维度的轮廓图加和求平均的时空步态特征,可以减少轮廓噪声,但会相应减少动态信息。与此相反,步态轮廓图是许多帧人在行走时轮廓随时间变化的图片,轮廓图很好地保存了步态的动态信息,但是受硬件条件限制,会受到采样时的噪声影响。在单一视角问题上,计算基于GEI 图片的L2 距离经常能得到较优结果,然而在跨视角或多视角问题上,序列轮廓图更有助于防止类内差距大于类间差距。
目前,步态识别领域的方法可分为基于模型和外观两个类别。基于模型的方法有:试图重建人体的3D 模型[2],这通常依赖于多个高分辨率相机,成像距离也受约束,大大限制其潜在用途;其次是传统的视角转换模型,将步态模板从一个视角转换至另一视角,如利用转换一致性度量[3]和基于质量度量[4]的视角转换模型,然而计算量大,转化过程中无法避免噪声的传播,因此很难达到极好的识别效果。基于外观的方法可以进一步区分成两类:判别法和生成法。属于判别法的模型有:Shiraga等[5]提出GEINet,使用GEI作为输入,Softmax用于分类;Wu等[6]提出DeepCNN,直接学习一对GEI 或者轮廓序列之间的相似度;Feng等[7]提出一个结合非局部分块特征的跨视角网络,基于GEI图片使用非局部注意力模块增强局部信息;Wolf等[8]提出利用3D卷积捕捉步态序列中的时空信息,将步态轮廓序列作为网络输入;Tong 等[9]提出一个新型用于提取步态时空特征的深度学习网络STDNN(spatial-temporal deep neural network);Chao 等[10]提出GaitSet,将轮廓序列看成一个集合,并增加多层全球通路(multilayer global pipeline,MGP)形成两路网络,得到不同的时空特征,使用三元组损失进行分类。生成式的方法通常将步态模型从不同的场景转换到相同的场景,包括:He等[11]提出多任务生成对抗式网络来学习具体角度下的特征表示;Yu等[12]提出步态生成对抗式网络GaitGAN来模拟不同角度对步态特征的影响;Zhang等[13]提出GaitNet,基于自编码-解码器网络分离出姿态和外形的特征,并用LSTM(long short-term memory)网络产生姿态特征的时序动态信息。
上述方法的提出,虽然对步态识别的发展产生了较大的推进,但是大部分研究主要关注提取步态的全局时空特征,缺少针对步态轮廓图中细粒度信息运用方法的研究。本文利用步态轮廓图可以更好地保存人体步态的时空特征信息的优势,使用卷积神经网络(convolutional neural networks,CNN)进行步态特征建模,并针对步态全局特征和局部特征表现的不同,提出非对称的双路网络结构。其中用于提取步态全局时空特征的网络称为全局通路,而用于检测识别显著性局部特征的网络称为局部通路。此外,在局部通路中插入显著性特征检测器模块,以保证对步态中细粒度信息的有效提取和识别。最后,本文方法在CASIA-B 和OU-ISIR-LP 两个公开步态数据集上进行了对比实验。
1 方法
本文提出的非对称双路网络的整体架构如图1 所示,采用随机抽样的方式输入帧数固定的步态轮廓图,网络整体框架总体上分为共享网络和非对称双路网络两大部分。其中,共享网络设置为7层,参数共享,具体参数如表1所列,用于提取一般步态特征。最后一层卷积层的通道数设置为k×classes,k为超参数,表示有效局部信息的个数,classes 为行人类别,从而使得提取的局部特征更具有逻辑上的针对性。卷积层后增加了归一化操作,使得步态特征更稳定。
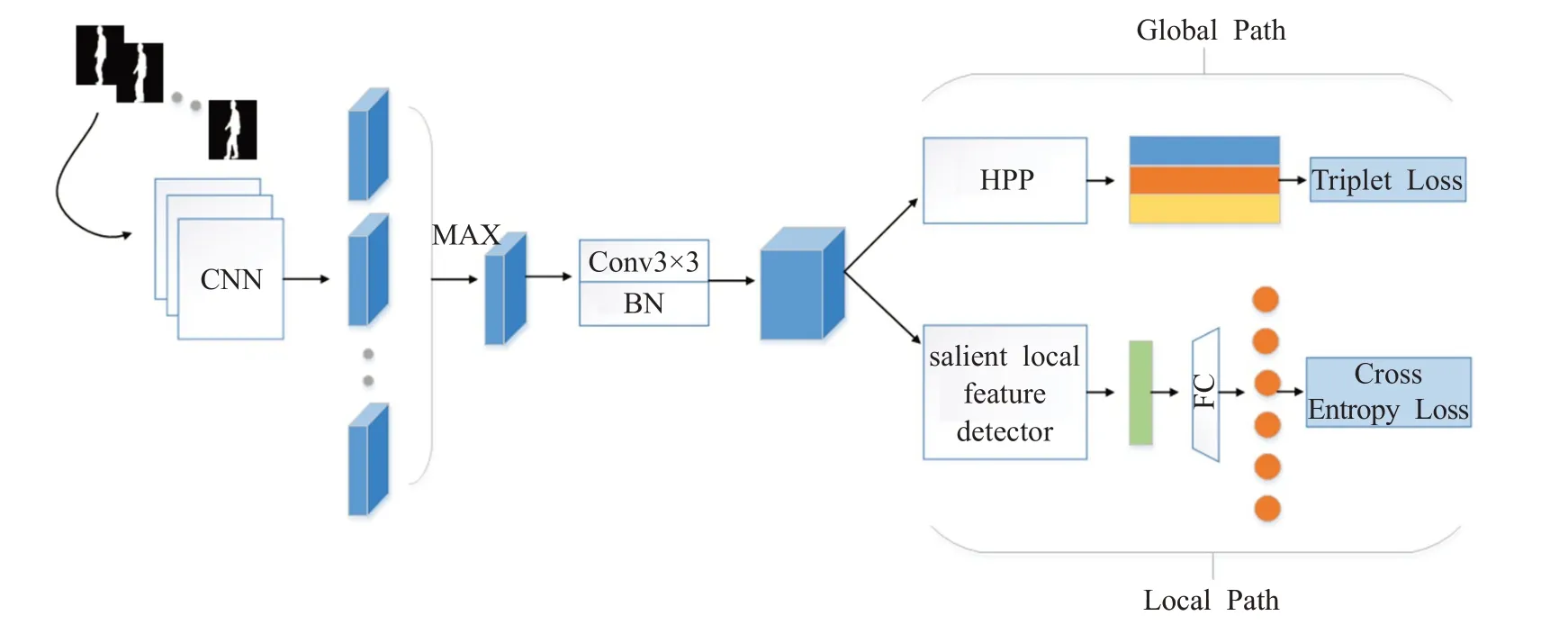
图1 双路网络的整体框架Fig.1 Whole framework of two-path network
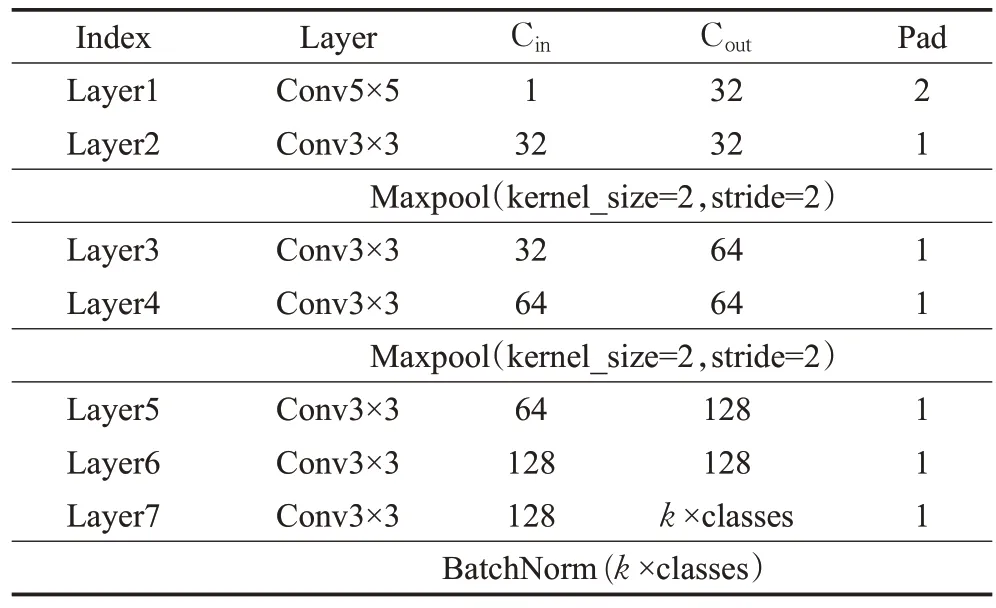
表1 共享CNN网络Table 1 Shared CNN
经共享网络提取出含有语义的步态特征,接着特征将进入非对称双路网络。非对称双路网络由全局通路(global path)和局部通路(local path)两部分组成,网络之间不共享参数。全局通路中使用了金字塔水平池化(horizontal pyramid pooling,HPP)[14],生成步态全局特征,配合三元组损失函数计算不同类别间特征的距离,确保类间差距更大;局部通路中设计显著性特征检测器,关注步态特征中的细粒度信息,生成步态局部特征,并结合交叉熵损失函数基于局部特征直接做分类,交叉熵损失会使得类内差距更小。最后,局部通路将辅助全局通路产生更具有判别力的全局特征。训练阶段将两支网络计算的损失值融合在一起,测试时仅使用全局通路输出的全局特征。
1.1 双路网络结构
步态特征识别与一般分类识别不同点在于,步态特征既包含人物行走时的姿态变换特征,称为全局时空特征(以下简称全局特征),又包含不同人体某些部位的特定形状,称为显著性局部特征(以下简称局部特征)。一般地,基于轮廓图的步态识别往往仅专注于全局特征的提取方法,仅有少数研究者开始重视步态的细粒度信息。因此,在局部特征的提取上受细粒度识别的启发,可以通过设计模块专注于一类物体的具有较大差别的细粒度信息,获得具有判别力的特征。依据这一思路,本文设计出含有全局通路和局部通路的两路网络,具体结构如图2。

图2 双路网络结构Fig.2 Two-path network structure
全局通路中,HPP广泛应用于步态行人重识别(ReID),原理如图3,可以有效获得多尺度下的全局信息;局部通路网络用于检测出步态特征中关键部位。步态细节识别与细粒度识别一大明显区别在于,细粒度识别中显著性区域建模的方法,大多要增加额外的标注,此种方式被称为强监督学习方式[15],而步态识别仅有标签,故属于弱监督学习,此时显著性区域检测器的构造更重要。已有研究[16]在细粒度识别领域提出用于建模局部显著特征的方法。本文在其基础上,针对步态轮廓的特点构造了适用于步态图片的显著性区域检测器,局部通路最后使用全连接层作为分类器,并增加BN层以减小过拟合,最终的分类将完全基于检测器识别出的局部显著性特征。在反向传播时,由损失传回的梯度继而改变共享网络的参数,会提高整个网络提取特征的能力,使得全局特征更具有判别力。训练时,网络的损失为两类损失的加权平均值。
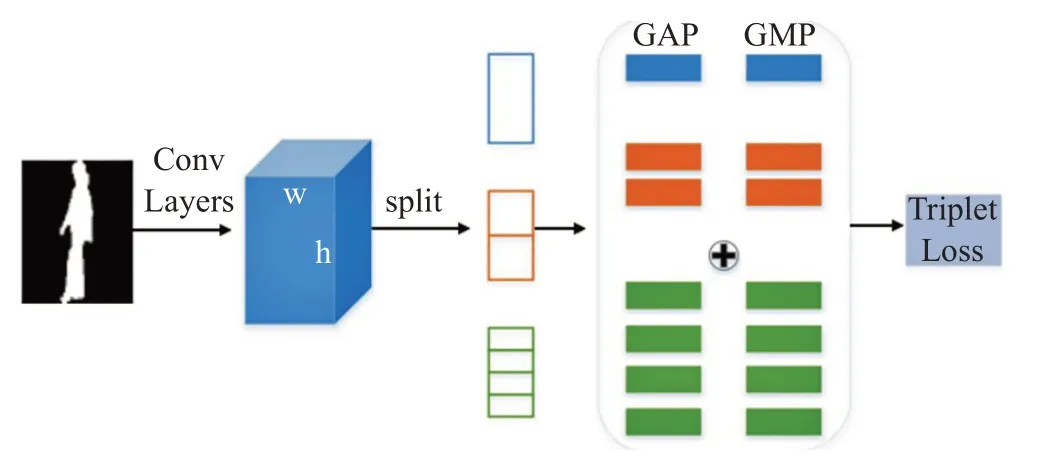
图3 水平金字塔池化Fig.3 Horizontal pyramid pooling
1.2 显著性网络检测器
显著性特征检测器的内部,由两个并行的独立结构组成,第一层为一个3×3 卷积层,第二层为Mlpconv[17]层,最后一层分别设置全球平均池化和全球最大池化,输入特征即可产生像素为1 的局部显著信息。传统意义上的卷积层结构为卷积加池化,即可使用具有局部感受野的神经元(如3×3卷积核)提取特征并由池化降维,同时获得各通道上的显著信息。但这种方法感受野大,提取的图案模式粗糙,容易忽略掉步态特征图中具有分辨力的细节。Mlpconv在传统卷积后增加1×1卷积核和ReLU激活函数,从跨通道池化的角度来看,这样等效于在一个正常的卷积层上实施级联跨通道加权池化,使得模型能够学习到通道之间的关系,对局部信息进行更好的建模,Mlpconv层公式如下:
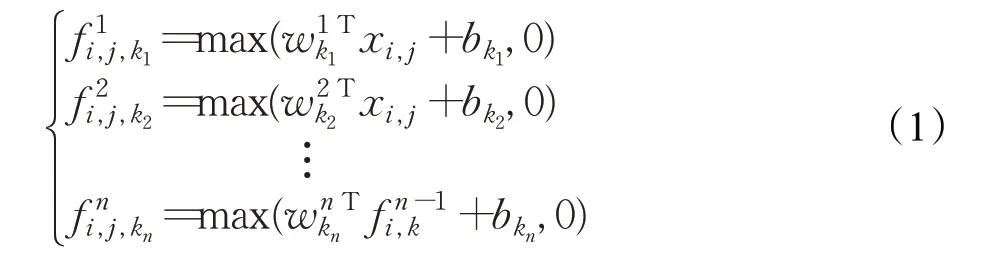
其中,(i,j)表示特征图像素的索引,xi,j代表以位置(i,j)为中心的输入块,k用来索引特征图的颜色通道,n表示多层感知器中的层数。由于本文步态识别使用的是连续的多帧图片,步态的局部显著性信息理应也处在连续多帧的动态变化中,跨通道学习因此理论上更适用于步态场景,1×1 卷积核感受野更小,也更易于捕捉步态中动态变化的细节信息。基于步态轮廓图是灰度图,具有样式简单等特点,本文建构的Mlpconv与原始结构不完全相同,如图4所示,由Mlpconv提取的局部特征经过不同的池化,相叠加后送入分类器分类,这样的好处一是减少了网络参数,二是有效强化了局部特征。

图4 显著性特征检测器Fig.4 Salient local feature detector
1.3 双损失函数
本文采用两种损失函数,一个是三元组损失函数,另一个是交叉熵损失函数。三元组损失函数使用Hermans等[18]提出的公式。随机抽取P个人,K个不同场景下的样本组成一个batch的内容,每个样本取固定帧数f帧。对于batch内的每个样本a,选择关于它的所有正样本和负样本组成三元组,共有PK(PK-K)(K-1)个组合,具体公式为:

使用三元组损失函数用于保证类间差异大于类内差异。
交叉熵损失函数基于Softmax 函数和对数函数,Softmax 可将卷积网络输出的向量特征映射成取值在(0,1)之内的概率分布,会约束PK个样本的局部显著性特征对应到正确的类别,有助于减小类内差距,具体公式为:

使用不同的损失函数,用于针对不同的任务:三元组损失可以将属于不同类别的相似样本的距离拉大,更适合全局特征的形成;交叉熵会将特征向量直接映射成类别的概率值,理论上对特征向量的大小有限制,故更适合约束局部特征的形成。最终,训练时网络使用两类损失的权重叠加,总损失的计算如下式所示:

其中,λ1和λ2为超参数。
2 实验结果及分析
为了验证本文方法的有效性,在CASIA-B[19]和OU-ISIR-LP[20]两个数据集上进行了测试。
CASIA-B是目前步态识别最常用的数据集之一,共有124位行人的步态影像,分成3个场景,每个场景下的行人有11 个视角,视角为(0°,18°,36°,…,180°),在每个视角下,为每人拍摄10个步态序列,其中包括正常步行(NM)6个,携带背包(BG)2个,身穿外套(CL)2个,即每位行人含有11×(6+2+2)=110个序列。
OU-ISIR-LP 是目前人数最多的数据集之一,该数据集拍摄的对象年龄跨度广泛,性别比例均衡。数据集提供同一场景下跨视角的人物行走序列,共设立4个观测角度(55°,65°,75°,85°),每个对象的行走序列划分为Gallery 和Probe。所有图片均为轮廓图,且统一归一化处理成128×88大小。
实验时,两个数据集的序列轮廓图在输入网络前经过对齐,并归一化成尺寸为64×44大小的图片,批量尺寸设置为128,训练环节输入帧数预置为30 帧,测试环节使用所有帧进行测试。优化器选择Adam[21],两损失所占比重设置为λ1=0.85,λ2=0.15,学习率设置为0.001,初始化权重采用Xavier 初始化方式,偏置初始化为0。在CASIA-B 数据集上,共享网络最后一个卷积层的k设置为4,HPP的切块数设置为3,三元组损失函数的边距大小设置为0.2,训练迭代100 000次左右;OU-ISIR-LP数据集的训练迭代次数为80 000 次,其他参数设置类似。计算第一次命中率(Rank1)评判模型效果,实验环境为一块NVIDIA GeForce GTX TITAN X显卡,代码基于Pytorch深度学习框架编写。
2.1 跨场景实验对比结果
沿用Wu 等[6]提出的实验设置,CASIA-B 数据将前74人设置为训练集,剩余50人设置为测试集,在测试时NM#1-4用作Gallery集,后两个序列用作Probe集;而针对跨场景下的模型测试,BG#1-2和CL#1-2皆用作Probe集。
表2 为各方法在CASIA-B 所有视角下的Rank1 识别率对比,对比方法有ViDP[22]、VTM-SVR[23]、C3A[24]、3DCNN[6]、CNN-集成[6]和GaitNet[13],其中前3 项为步态识别经典方法。经过实验对比可以看出,深度学习方法在识别领域的明显优势。本文方法隶属于深度学习,由数据反映其在0°~36°和144°~180°范围内的识别效果显著高于其他深度模型。表3、表4 为BG 和CL 场景下Rank1识别率对比,发现上述数据规律在不同场景下仍然适用。这说明本文网络提取出的步态全局特征更具有判别性,可反映出不同场景下步态的关键要素,即针对不同环境更具鲁棒性。对比仅含Global Path与完整Two-Path 的实验数据,可以初步得出结论:局部通路网络确实有助于整个模型生成更有判别力的步态全局特征。
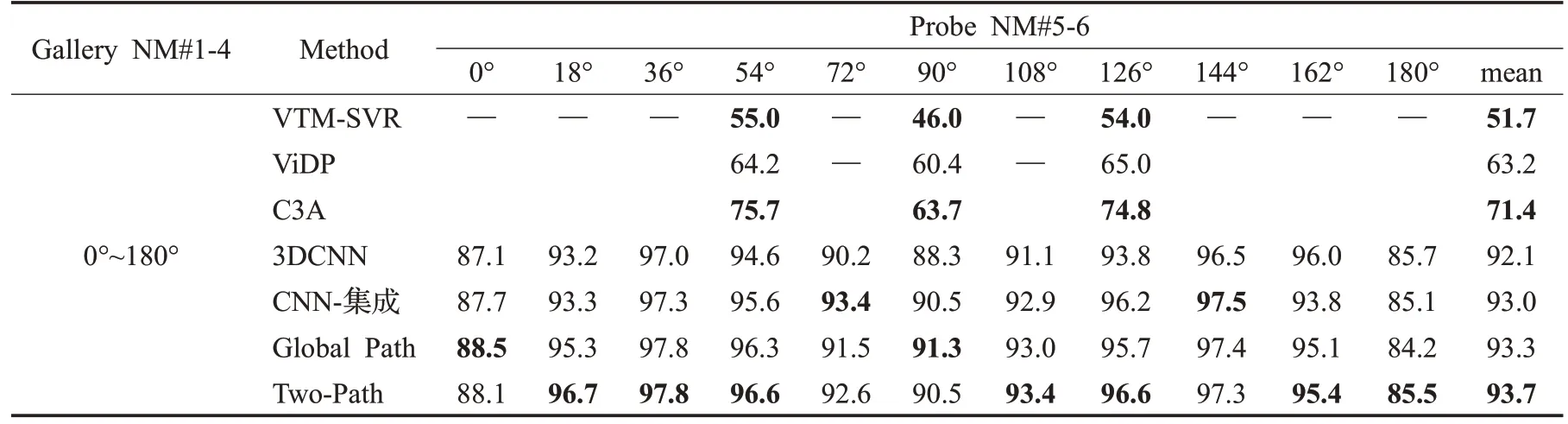
表2 若干方法在CASIA-B数据集NM上全视角的Rank1识别率Table 2 Rank1 full-view accuracies of different methods under NM on CASIA-B dataset %

表3 若干方法在CASIA-B数据集BG上全视角的Rank1识别率Table 3 Rank1 full-view accuracies of different methods under BG on CASIA-B dataset %

表4 若干方法在CASIA-B数据集CL上全视角的Rank1识别率Table 4 Rank1 full-view accuracies of different methods under CL on CASIA-B dataset %
2.2 跨视角实验对比结果
为了进一步展示模型在跨视角上的突出性能,继续进行了不同视角差下的对比实验。在OU-ISIR-LP 上,实验将数据集中1 912 个角度齐全的子集分为2 份,其中956个ID用于训练,另外956个ID用作测试。表5为不同方法在OU-ISIR-LP 数据集上的Rank1 识别率对比,对比实验中传统方法有WQVTM[4],深度学习方法有GEINet[5]、CNN-CGI[6]以及Non-Local[7],数据引自文献[7]。和上述方法对比,Two-Path 的识别效果更优,且随着视角变化识别率变化小。原因可能有二:一是输入数据的形式不同,对比方法多以GEI 作为数据输入,本文方法使用的轮廓图数据量更大,可能带来识别率提升;二是模型结构较上述方法更优。因此,为了消除第一个原因可能造成的影响,验证模型的有效性仍然需要其他实验。

表5 不同方法在OU-ISIR-LP上跨视角的Rank1识别率Table 5 Rank1 cross-view accuracies of different methods based on OU-ISIR-LP %
在CASIA-B上进行跨角度实验,实验设置为100人训练,余下24 人测试,场景固定为NM。表6、表7、表8分别展示了NM 场景下,视角差为18°、36°、54°时跨视角的Rank1 识别率结果对比。对比方法有3DCNN[6]、STDNN[9],数据输入皆为轮廓图,实验数据引自文献[9]。通过实验数据可得,Rank1识别率不随视角差的显著增加而降低,变化稳定。这说明本文方法使用全局和局部两条通路可以提取出更有效的步态特征,并且模型具有泛化性,对跨视角的鲁棒性更好。
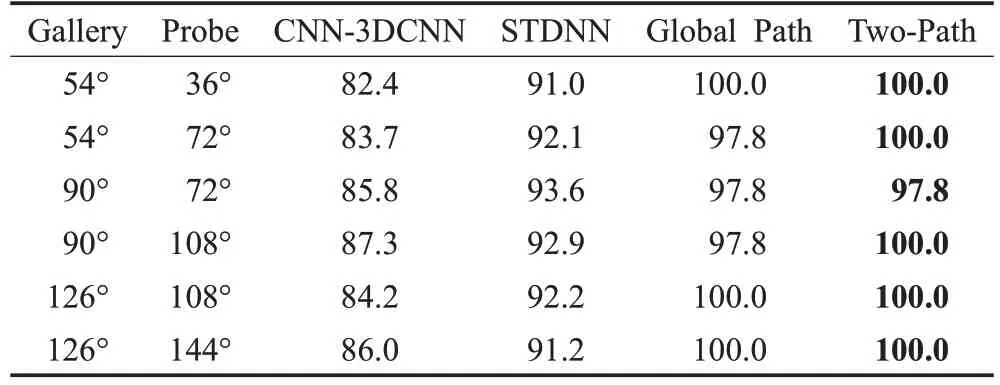
表6 基于CASIA-B不同方法在视角差18°时的Rank1识别率Table 6 Rank1 accuracies of different methods at angular difference of 18° based on CASIA-B %
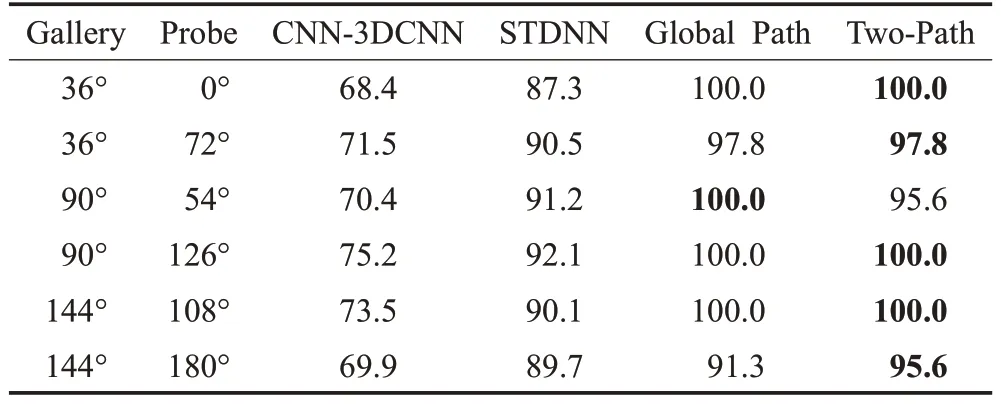
表7 基于CASIA-B不同方法在视角差36°时的Rank1识别率Table 7 Rank1 accuracies of different methods at angular difference of 36° based on CASIA-B %
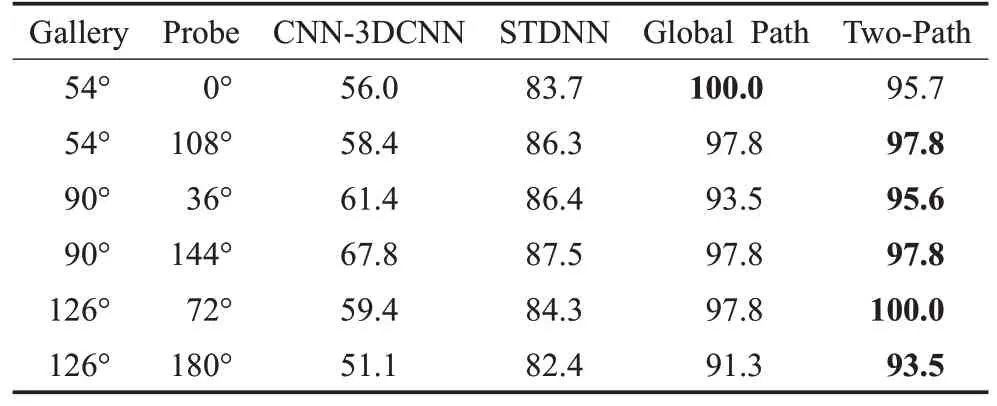
表8 基于CASIA-B不同方法在视角差54°时的Rank1识别率Table 8 Rank1 accuracies of different methods at angular difference of 54° based on CASIA-B %
3 结束语
本文为了更有效地提取步态特征,研究了步态中细粒度信息的有效利用方式,提出了非对称的双路结构,并设计了一个新型模块显著性检测器用于局部显著性特征的提取与识别。经过实验得到验证:通过设置合适的损失函数,增加神经网络对步态轮廓图细粒度信息的识别,有利于整个网络提取出更具有判别力的全局特征。这在一定程度上探索了步态识别目前在深度学习领域,除设计直接提取全局特征的模块外其他思路的可能性。另一方面,本文方法也是一次细粒度识别领域的研究思路向步态识别迁移的实验,通过实验数据可以得到较为客观的结论:步态识别可以与细粒度识别方法相结合。但文中只做了初步的尝试,今后还需后续更多深入的研究,以期未来将细粒度识别技术与步态识别深度结合。
本文使用多张轮廓图作为步态识别网络的输入,模型参数的体量和训练耗时仍需要进一步优化。此外,在不同场景下,模型在NM、BG、CL 上的识别率差别依然较大,说明模型的鲁棒性仍然未达到理想状态,模型精度仍有待提升,今后要继续致力于步态识别模型在复杂场景下的应用研究。
