IGBP云检测网格产品升尺度方法及精度评价
2022-03-01谢涛任佳昊王超
谢涛,任佳昊,王超
(1.南京信息工程大学 遥感与测绘工程学院,南京 210044;2.南京信息工程大学 电子与信息工程学院,南京 210044)
0 引言
遥感影像数据受大气密度、云层变化的影响,常存在云层遮盖区,会对其他大气产品和陆地产品生成造成不利影响[1-2]。因此,云检测产品的主要作用是作为其他大气产品和陆地产品反演的辅助数据,同时也是目前很多云检测研究的检验依据[3-4],其主要任务就是区分有云(包括部分有云)像元和晴空(或基本晴空)像元[5]。本文的目的是在已有的云检测产品的基础上,对其进行升尺度处理,尽可能地保证升尺度后产品的精度,为其他不同尺度云参数和定量产品反演提供可靠的辅助数据。
近年来,研究者们对卫星数据的云检测展开了一系列研究,以EOS/MODIS和风云卫星等数据为代表的云检测产品被广泛使用[6]。
尽管如此,当前现有可获取的云检测产品通常存在尺度单一的局限,无法满足全球或不同区域尺度的气象、水文和生态等研究[7];此外,随着高分辨率遥感技术的发展,现有的云检测产品一直在朝着高分辨率的趋势发展,而当进行某些全球或者大洲级研究,高分辨率成为一种负担时,就会缺乏相应的粗分辨率产品作为支撑[8];最后,目前尚缺乏针对云检测产品的升尺度方法及精度评价方法。因此,有必要围绕这些问题展开研究,以提供高精度、高可靠的云检测升尺度产品。
围绕遥感数据的升尺度方法,学者们已经取得了一系列的成果。根据对聚合窗口中类别值处理方式的不同,常见方法有众数聚合法、随机抽样法。但这两种方法都存在着一定的缺陷,没有考虑到数据中不同类别之间存在着的空间结构关系,会造成升尺度后产品中对应类别的空间结构发生变化。比如众数聚合法会导致弱势类别的减少甚至消失,随机抽样法会使空间结构趋于离散[9-10]。在精度评价方面,由于仅有升尺度前产品,缺乏升尺度标准结果作为参照,因此通常仅通过比例变化来判断升尺度结果的优劣[11]。这种指标虽然在一定程度上能够评判升尺度后结果相对原数据各类别的占比变化情况,但比例是否变化无法直接反映升尺度结果的精度及可靠性。
鉴于此,本文提出了一种迭代聚类方法,诣在能够更好地保持升尺度前后各类别的空间结构一致性。在此基础上,基于欧式距离(Euclidean distance,ED)提出了两种新的度量方法,分别为类内欧氏距离(inner class ED,ICE)和类间欧氏距离(ED between classes,EBC)的精度评价方法,并结合占比法、相似度、互信息和均方根误差对众数聚合、随机抽样和迭代聚类法的性能进行综合评估。结果表明,本文提出的迭代聚类法可行有效,在总体和单类精度中均显著优于其他对比方法。
1 云检测产品介绍
国际地圈生物圈计划(international geo-biosphere program,IGBP)云检测网格产品中每个网格的数值代表是否有云的4级可信度:云、可能是云、可能是晴空和晴空。其数据的存储方式是按照8位二进制bit位进行存储定义[12],每比特位所代表的含义如表1所示。

表1 云检测数组bit位存放内容的具体内容
在本文的升尺度算法研究中,会对原始数据进行8位二进制化预处理,主要用到前3位bit位,共分为5类:000(无效值)、001(有云)、011(可能有云)、101(可能晴空)、111(晴空)。
2 算法的设计与实现
聚类法是一种无监督的分类方法,其中最常用的是划分聚类算法,有EM 算法、k-medoids 算法、k-means算法、CLARA 算法、CLARANS 算法等[13-16]。划分聚类算法的优点是简单快捷,针对原始数据,先设定好聚类中心或者聚类数目,然后选取一种迭代方法进行反复的迭代对初始分组进行改进,减小误差。然而,一方面划分聚类算法难以直接应用到升尺度中;另一方面,聚类后对各个聚类中心的定义难以与原始数据中的类别进行对应。在本文中,针对以上两点,依据云检测数据的特性,将划分聚类算法的特点运用到了升尺度算法中,设计了一种迭代聚类法。
采用所提出的迭代聚类方法对云检测数据进行升尺度的流程如图1所示。

图1 迭代聚类法流程图
实现步骤如下所示。
步骤1:统计所有5×5窗口内0的像素个数,若数量大于等于13个,则该窗口被判定为无效,并不参与后续计算。
步骤2:对剩余5×5窗口内的每个像素进行8位二进制化处理。
步骤3:先保留8位二进制数的前3位(第0、1、2位)且第一位不为0条件下的3位数字001、011、101、111,对应十进制标签为1、3、5、7。
步骤4:将任意一个窗口作为一个样本,统计该窗口内具有1、3、5、7标签的像素个数,并构建直方图,作为该样本的特征空间;遍历所有步骤1处理后剩余的窗口,可得到等待进行迭代聚类的所有样本集合D,以及每个样本所对应的特征空间。此时,迭代聚类寻优模型输入是D={xi,i∈1,2,…,m},其中xi是第i个样本所代表的特征向量,m为样本个数。
步骤5:从D中随机选择4个样本作为初始的4个质心μj,j∈1,2,3,4。设定输出簇划分C初始化为Ct=∅,t∈1,2,3,4。


步骤8:重复步骤6~步骤7,直到所有的4个质心向量都没有发生变化,即模型收敛得最优解后,可以得到初步的4种分类结果Ct={C1,C2,C3,C4}。但此时还不知道4类样本分别对应的3位二进制数。
步骤9:统计这4种分类结果中所有像素所对应的升尺度前的窗口内的像素均值,按照从小到大的顺序进行排列后,则分别对应001、011、101、111,可得到初始的云检测结果。
步骤10:在步骤8的基础上,对8位二进制中的后5位bit位在5×5聚合窗口中采用众数聚合规则进行决策,与步骤2~步骤9得到的前3位组合后转为十进制,得到最终的分类结果。
3 升尺度结果评价指标
为了在无真实参考数据条件下对不同升尺度方案进行有效的定量分析,本文设计了两种精度评价指标ICE、EBC。其依据在于:每个升尺度后像素都可以看成由5×5窗口内的混合像元而来,因此每个像素实际可以看成一个5×5的图像,因此计算两个窗口之间的欧氏距离,能够反映被赋予相同类别标签像素之间的关联程度,也可以反映被赋予不同类别标签像素之间的差异大小。
3.1 ICE
升尺度之后,属于同一类别像素之间的欧氏距离越小,则每个类别像素之间的联系就越紧密,升尺度结果中各个类别的划分就越准确。ICE的具体步骤如下。
步骤1:在升尺度结果基础之上,以全部属于“有云”的像素为例,遍历计算每两个“有云”像素之间的ED,得到“有云”像素之间的平均相似程度ICEcloud-cloud。依次类推,获得所有类别的内部像素ICExxx-xxx。
步骤2:对全部类别的ICExxx-xxx求均值,得到类内可分性精度指标,如式(1)所示。
(1)
步骤3:进而求得加权类内可分性指标,其中Pi为升尺度结果中类别i所占比例,如式(2)所示。
(2)
3.2 EBC
升尺度之后,不同类别的像素之间的欧氏距离越大,则不同类别之间的区别就越大,升尺度结果中各个类别的划分就越准确。EBC的具体步骤如下。
步骤1:在升尺度结果基础之上,以全部属于“有云”的像素为例,遍历计算每个“有云”像素与其他非“有云”像素之间的ED,得到“有云”与其他类别像素的平均相似程度EBCcloud-other。依次类推,获得全部类别与其他类别之间的EBCxxx-other。
步骤2:对全部类别的EBCxxx-other求均值,得到类间可分性精度指标,如式(3)所示。
(3)
步骤3:进而求得加权类间可分性指标,其中Pi为升尺度结果中类别i所占比例,如式(4)所示。
(4)
4 实验结果分析
4.1 数据选取
本文以风云三号D(FY-3D)气象卫星的云检测产品为实验数据。该产品其采用了中等分辨率光谱成像仪(medium resolution spectral imager,MERSI)数据,空间分辨率为5 km,存储为HDF格式,大小为7 200像素×3 600像素,数据覆盖全球。共对3组实验数据进行实验,产品拍摄时间分为2019年的3月21日、3月23日和3月27日。
4.2 目视结果分析
采用5×5的聚合窗口,分别采用众数聚合(方案一)[17]、随机抽样(方案二)[18]、本文提出的迭代聚类法3种方案进行实验。由于全球结果图不利于细节展示,因此仅展示局部区域的原图及对应3种方案的升尺度结果图,如图2至图4所示。

图2 2019年3月21日局部图及升尺度结果

图3 2019年3月23日局部图及升尺度结果

图4 2019年3月27日局部图及升尺度结果
通过目视分析可以看出,本文提出的迭代聚类(方案三)在整体上要优于方案一和方案二。分别对图2、图3和图4进行分析,方案三的各个类别在空间结构的保留程度上都要优于其他两种方案。升尺度后,方案一会造成小众类别的结构遭到减少和破环。因为算法的随机性,方案二虽然较好地保持了整体的空间格局,却会造成整体的分类变得不连续,破坏了单类别的结构。
4.3 定量评价
为了能够定量分析3种方案的优劣,通过占比法精确度(percent accuracy,PA)指标[19]和本文提出的ICE、EBC指标进行升尺度后的单类和总体评价。此外,为了验证所提出评价指标的有效性,从整体上分别对3种方案进行了相似度、互信息和均方根误差的评价。其中,占比法是在对云检测数据进行升尺度处理前后进行。理想的升尺度算法应不改变每个类别像素所占比例。占比法评价结果如表2至表4所示。
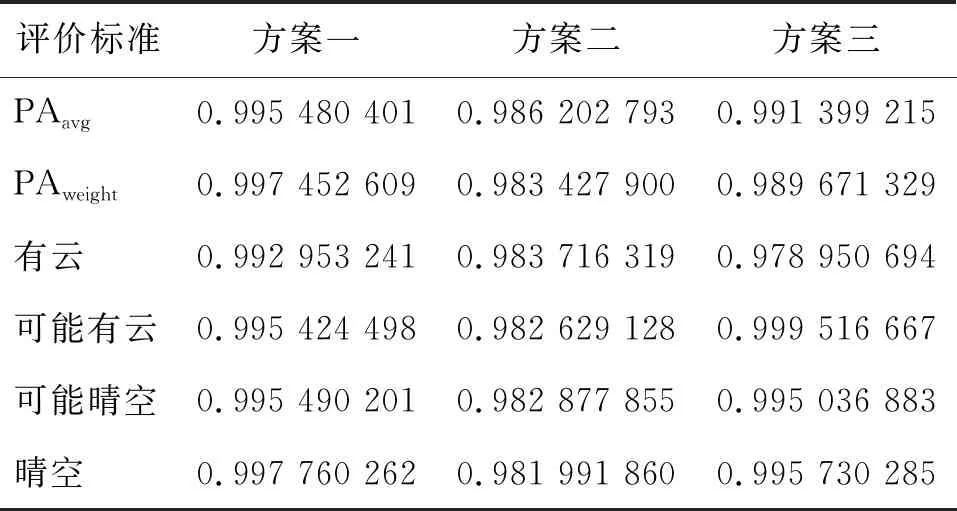
表2 2019年3月21日年数据占比法评价结果

表3 2019年3月23日年数据占比法评价结果
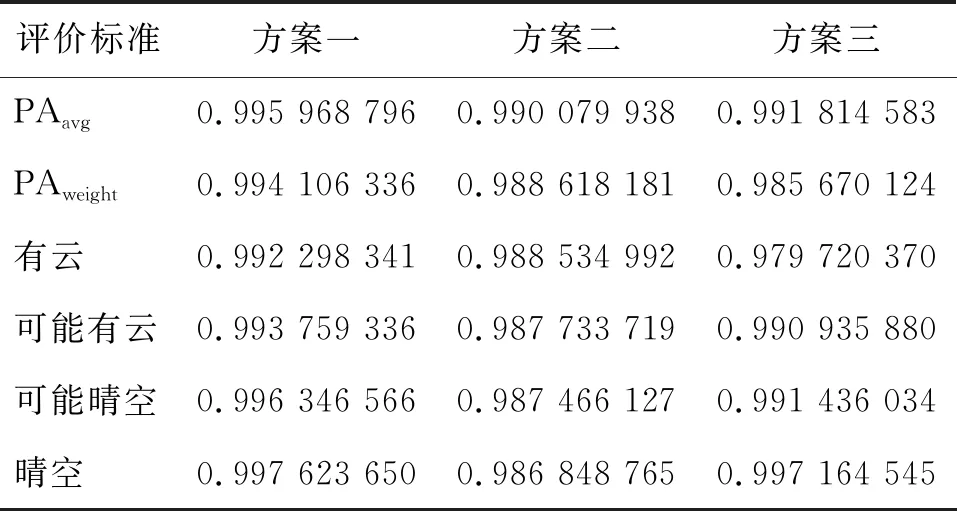
表4 2019年3月27日年数据占比法评价结果
从占比法的评价结果来看,不论是总体精度、加权总体精度还是各个类别的单类精度,3个方案的精度都很高,且数据比较接近。这是因为全球范围的云检测数据量大,很难从比例变化上去评判不同升尺度方案的好坏,也不能反映升尺度后数据的结构完整度。采用ICS指标的评价结果如表5至表7所示。
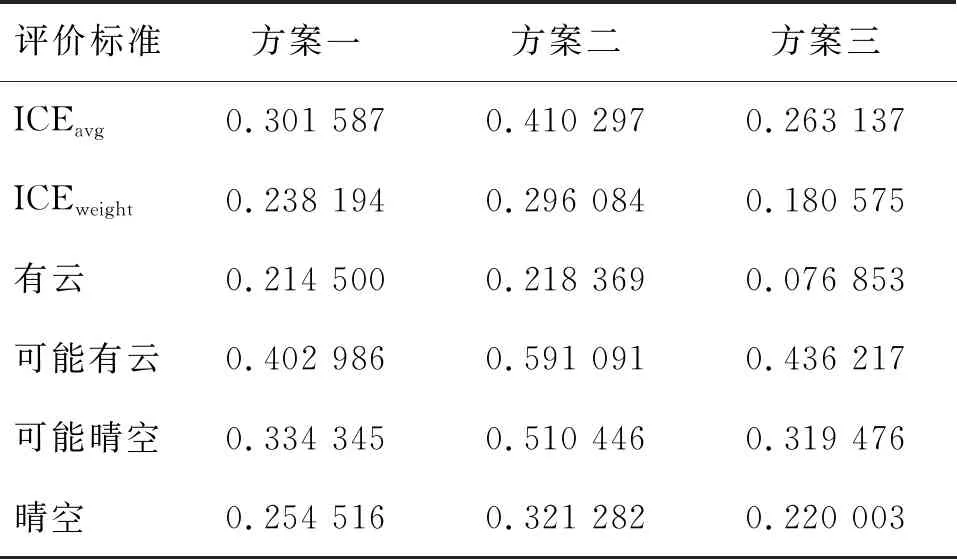
表5 2019年3月21日年数据ICE评价结果

表6 2019年3月23日年数据ICE评价结果

表7 2019年3月27日年数据ICE评价结果
从表5、表6和表7中的数据结果可以看出,非加权类内可分性精度指标的表现形式为:方案三>方案一>方案二(“>”代表优于)。加权类内可分性精度指标的表现形式:方案三>方案一>方案二。从单类精度的角度,方案三的精度也都要优于其他两个方案。结合目视分析结果和ICE来看,方案二采用的随机抽样原则使得单个类别在空间结构上变得不连贯,要明显弱于其他两个方案。方案三因为没有局限在聚合窗口中的类别值,而是以每个聚合窗口作为样本空间进行整体上的迭代聚类,不存在考虑类别优先级使得优势类别占优,弱势类别占劣的情况,从而在ICE中精度也要高于方案一。
采用EBC指标的精度评价结果如表8至表10所示。
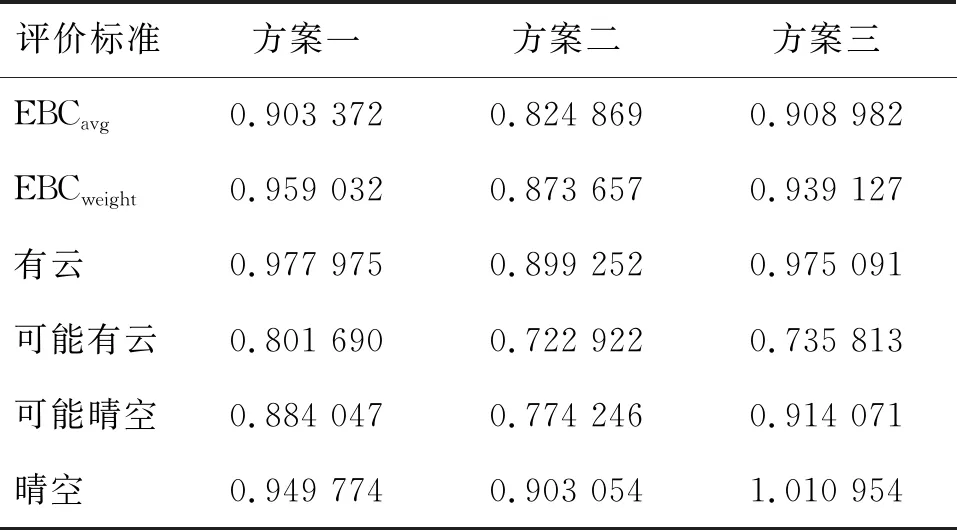
表8 2019年3月21日年数据EBC评价结果

表9 2019年3月23日年数据EBC评价结果

表10 2019年3月27日年数据EBC评价结果
从表8、表9和表10中的数据结果可以看出,非加权类间可分性精度指标的表现形式为:方案三>方案一>方案二(“>”代表优于)。加权类间可分性精度指标的表现形式:方案一>方案三>方案二。从单类精度的角度来看,方案一在优先级较高的两类(有云和可能有云)的精度都要高于其他两种方案,而在优先级别较低的两类(可能晴空和晴空),方案三的精度要高于其他两种方案。我们分析是因为方案一采用了众数聚合的规则,能很好地保护优先级高的两类的空间结构保留度,相反会破坏优先级低的两类空间结构保留程度,而且在本实验中,优先级高的两类相比于其他两类的占比都要远高于其他两类,所以在EBC中呈现的结果来看,方案一在非加权类间可分性精度要低于方案三,而在加权类间可分性精度却要高于方案三。
对3种方案的相似度、互信息和均方根误差的综合评价见图5。
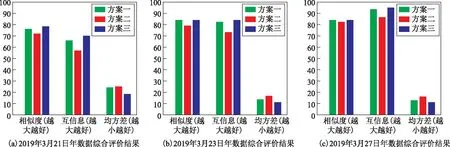
图5 3组数据的综合评价结果
由图5的3组实验数据可知,在整体性能评价上,方案三 >方案一 >方案二(“>”代表优于),与ICE和EBC的评价结论一致,证明了本文设计的两种精度评价指标的有效性。
5 结束语
云检测产品数据升尺度方法中,众数聚合法存在众数情况下弱势类别的减少甚至消失导致类别空间结构变化的问题,随机抽样法存在会使空间结构趋于离散的问题。针对以上问题,本文设计了一种迭代聚类法。在此基础上,因为缺少真实参考数据作为对比,为对升尺度后的结果进行有效评价,设计了两种精度评价指标,分别为基于类内欧氏距离和类间欧氏距离的精度评价方法。实验证明,所设计的迭代聚类法在类内欧氏距离中达到0.263(越小越好),低于众数聚合法3%,低于随机抽样法近10%;在类间欧氏距离中达到0.908(越大越好),高于众数聚合法约0.05%,高于随机抽样法近6%。
