基于分层欠采样和Bi-GRU的恶意行为检测模型
2022-03-01周娅,李赛
周 娅,李 赛
(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
0 引 言
越来越多的人倾向于在网络上发表意见和表达情感,也因此产生了各式各样的数据。但其中却隐藏很多攻击性甚至骚扰的恶意评论,如文献[1]对4248名美国成年人进行的一项新的全国性调查发现,近41%民众曾在网上受到过个人骚扰行为,近18%民众在互联网收到不同程度的骚扰和威胁。这些问题引起了学术界、媒体和社交平台的高度关注。如何更好利用最新技术对这些短文本进行分类,经成为相关研究者研究的热点之一[2]。文献[4]提出基于LSTM的分类器集合,讨论了用户的种族主义或性别歧视倾向等。采用来自维基百科对话页面的评论数据来构建检测模型。虽然数据集包含大量的标注,针对此数据集特点总结出现有检测模型还存在一些待改进之处:
(1)现有评论文本检测模型针对性较强,不适用于本文恶意评论数据集;
(2)评论文本自身有类不平衡的问题存在,加大了检测的困难度,在实际检测中低频的恶意评论将很难被及时识别。不易及时训练出行之有效的检测算法,也是恶意行为检测难度增大和效率低的原因;
(3)现有模型拟合能力弱,传统机器学习模型不仅结构简单,同时在特征提取和学习能力也比较弱。不能很好处理一些特殊文本和大规模数据集,更无法对数据分布形成有效映射。
所以针对以上问题,提出一种基于样本分层欠采样算法和Bi-GRU网络的网络恶意行为检测模型(SSU-BG)。
1 相关工作
文中恶意评论检测与现有的一些其它评论检测相比存在一些不同之处,本文所述的恶意评论只是针对人自身存在的恶意攻击行为进行的检测,比如一些恐吓、骚扰、谩骂、猥亵、侮辱等不良行为。恶意评论数据集本身在内容和结构上也与其它数据集大相径庭。在此次实验的数据集中总共包含7个大类,通过统计很容易发现一些非常明显的问题,比如这7类数据之间存在严重的类不平衡问题,其中正常的评论有143 346条,其它6种不正常的评论加在一起也与正常评论相差甚远,在6种不正常的评论中同样也存在类不平衡问题,这一问题将严重影响评论文本的整体检测效率。
若想提高恶意评论的检测率首先要缓解类间数据相差巨大问题,即类不平衡问题。类间距过大问题及现有检测模型的局限性使得改善类间距过大问题的分类模型应时而生。如下针对类间距过大问题的研究做了一些总结和分析。在文献[5]中研究者们针对类不平衡问题分析探讨了在聚类、大数据分析与应用、回归、数据流及分类等7个应用领域上目前所面临的一些新的问题和挑战,同时针对各个领域给出了一些针对性的意见和建议。
目前解决该问题的方法主要分为算法层面、数据层面以及混合方法。
算法层面:是指通过提出新算法或对一些现有的算法进行修改,以降低其对高频类的偏移量,从而侧面缓解类不平衡问题。目前主流的有两种改变策略,代价敏感策略[6]及决策输出补偿策略[7]。在文献[8]中,研究者们通过将数据清洗与代价敏感学习策略结合的方法改进了BP算法,这一算法的创新不仅解决了类不平衡问题还一定程度上缓解了类间重叠的问题。而在文献[9]中,研究者们采用了决策输出补偿技术,提出了加权ELM算法,此算法的目的是为每一个类赋予大小不同的权值。此算法虽然一定程度上提高了低频类的检测率,但因为其对同类样本赋予了相同的权值,导致其不能很好考虑到样例的闲言信息分布。
数据层面:是指针对现有模型特点,修改现有数据集,以使其适应现有的算法模型。此方法相对修改算法而言大大降低了时间复杂度,同时也避免了选择哪一种分类器的问题。可细分为过采样和欠采样两种解决办法,且存在各自的优缺点。很多研究者也做了进一步的探讨,文献[10]中研究者采用雅虎中用户针对财经新闻栏目的评论采用专家手动标记的方法识别出其中的一些仇恨言论。文献[11]中采用和本文中来自相同的数据集,他们同样提出一些改善类不平衡问题的策略,他们采用数据增强的方式,首先将检测问题转换成分类问题,先对输入的评论进行恶意倾向的判断,进一步将其判定为哪一类恶意行为,并取得了很好的实验结果。在文献[12]中,研究者们提出了线性不平衡和阶梯不平衡两种形式,同时采用相同的评价指标分别做了4组实验作为对比。实验结果显示:采用线性不平衡形式不适合随机欠采样方法,在随机过采样数据集上能取得较好的结果;而采用阶梯不平衡方式时,原始数据集检测效果依然不如随机过采样效果好。
混合方法:是指结合算法和数据处理两者的优点,采用一种集成的思想,将分类器与数据策略集成在一起形成一种新的分类模型。如文献[6]和文献[13]中的研究者们都提出了敏感代价策略与采样技术结合的形式组合成新的分类模型[13],并取得了不错的分类效果。
2 SSU-BG检测模型介绍
通过分析恶意评论数据集的内容及结构得的特点,提出了SSU-BG恶意行为检测模型。SSU-BG模型的结构具有一定的层级关系,根据各层结构在整个模型中所起的作用将其划分为三个模块,首先,顶层是数据预处理模块,中间一层为模型的核心模块,即不平衡处理模块,最底层为分类器模块。其中在数据预处理模块最重要的过程是特征的选择和归一化,归一化的目的是加速模型的收敛速度和简化模型的运算过程,通过分析发现大多数的恶意词汇都出现在句子的末尾,所以为增强模型检测的准确率,本文考虑将句末词加入向量化。考虑到恶意评论数据集数据结构单一,为更好发现评论的特征,本文为每一条评论都构造一个多维的特征模型,随后依据每个特征与预测值之间的相关性,筛选出关联性相对较强的来作为刻画评论内容真实性特征。而在数据不平衡模块,本文提出一种基于样本最高密度点的随机欠采样算法(SSU)对高频的样本进行适当的减法操作。在分类器模块,本文采用基于Bi-GRU网络来实现,Bi-GRU比Bi-LSTM神经网络结构简单,且具有Bi-LSTM神经网络可以捕捉到评论文本的上下文的优点。
2.1 样本分层欠采样算法
为了解决恶意评论文本的类不平衡问题,首先分析了随机欠采样算法及一些研究现状,发现采用随机欠采样算法时的采样比例设定相对比较简单,仅依据样本之间的比例设定,且不能解决采样的随机性和样本直接的重叠问题,导致最终的实验效果并不是很理想。而本文在此算法的基础上提出了一种检查模型,基于最高密度点的样本采样算法SSU-BG模型。
SSU算法核心思想是,首先通过统计和计算出各个标签对应的不平衡度,然后计算出这些不平衡度的均值并将其赋值为样本的整体采样比例;随后采用传统欧氏距离算法计算出各个类的类内平均欧氏距离及高频类的最高密度点,依据这个两个值将高频类区域划分为3个模块,分别为稀疏区、稠密区及稀疏区的边界层,以类内平均欧式距离为半径,以最高密度点为圆心画一个圆,此时,将圆以内的区域称之为稠密区,将圆以外区域称之为稀疏区;根据样本需求,我们选择从稠密区、稀疏区的边界层获取样本数据,而对于稀疏区边界层以外的区域,我们将其定义为非采样区。为了使获取的样本能具有一定的均衡性,本文做了进一步的探讨,将获得的稠密区进行再次划分,最终将其划分为不同个数的等距圆环,而此时圆环范围被定义在1到N+1个,按照设定好的采样比例分别在每个圆环里随机采集样本点,得到模型训练数据集。样本模拟平面分布图如图1所示。

图1 样本模拟平面分布
此算法减少了样本的总数,从而降低后续所提模型的训练量和训练时间。算法流程如下:
(1)输入训练集X={(x1,y1),(x2,y2),…(xn,yn)} 及所需参数,其中xi∈Rq,yi∈{-1,1},(i=1,2,…n)。
在上述表述中,X为包含n条评论的样本点,yi=1表示标签属性为1的低频类样本点,yi=-1表示标签属性为0高频类样本点,分别记为:S={(x1,1),(x2,1),…(xs,1)} 和M={(x1,-1),(x2,-1),…(xm,-1)}。
(2)从高频类样本点中随机选出的两个样本点xi,xj,q表示样本点对应的特征数,两点之间的欧氏距离,记为D(xi,xj)
(1)
(3)根据(2)中得出的结果,统计高频类的类内平均欧式距离,记为:Avg_dist
M={(x1,-1),(x2,-1),…(xm,-1)}
(2)
(3)
(4)根据(2)中计算的结果,统计各样本点的平均密度,记为Avg_density(xi)

(4)
(5)D(xi,xj) 的值越大则表明样本越不密集, Avg_density(xi) 的值越大则表明样本越密集,根据Avg_density(xi) 计算高频类样本的最高密度点,记为xsup_den
xsup_den=argsup(Avg_density(xi)),xi∈M
(5)
(6)根据(5)计算的xsup_den值及(3)计算的Avg_dist,根据M={(x1,-1),(x2,-1),…(xm,-1)} 样本,分别以xsup_den、Avg_dist两个值为圆心和半径画一个圆,稠密区和稀疏区分别记为:Lay_den和Lay_spa
Lay_den={xi|D(xi,xsup_den)≤Avg_dist,xi∈M}
(6)
Lay_spa={xi|D(xi,xsup_den)≥Avg_dist,xi∈M}
(7)
(7)随机选择两个点xt,xj∈Lay_spa, 同时结合(2)和(5)计算出稠密区的边界域,记为margin
margin=max(D(xsup_den,xj))-max(D(xt,xj))
(8)
(8)根据(7)可以计算出稀疏区的边界层,记为Mar_lay
Mar_lay={xk|max(D(xi,xsup_den))≤margin,xi∈Lay_den,xk∈Lay_spa}
(9)
(9)设每个样本对应的标签数为N,结合样本对应的标签数统计出1到N个标签数对应的样本的不平衡度及均值,分别记为αi、α_mean
αi={α1,α2,…αN}
(10)
(11)
(10)根据(6)中计算结果,将稀疏区边界层及稠密区定义为采样区,而将稀疏边界层以外的区域划分为非采样区,为了均衡采样,将稠密区划分成不同个数的等距圆环,圆环范围为1到N+1个,按照既定的采样比例分别在每层上随机采样,划分圆环个数记为δ
δ={δ1,δ2,…δN+1}
(12)
(11)根据(10)计算的结果,得到N+1组相同比例,不同样本点的数据集,记为Tnew
Tnew={T1,T2,…TN+1}
(13)
2.2 Bi-GRU网络
Bi-GRU模型与Bi-LSTM模型结构非常类似,Bi-GRU模型包括前向GRU和后向GRU,两个GRU单元与同一个输出层相连,因为GRU单元可以对历史信息进行选择性记忆,因此其参数学习过程也比较快,双向GRU可以保留从前往后的信息和从后往前的信息。
Bi-GRU即为两层的GRU网络,其基本网络结构如图2所示。
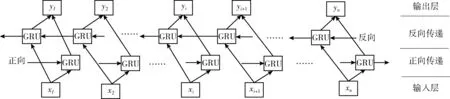
图2 Bi-GRU网络结构
Bi-GRU模型将已学习到的特征向量输入到分类器中,即先将检测问题转化成一个多分类问题。
3 实验设置
3.1 实验数据集
本次实验数据集相对比较权威,由Kaggle官网提供的一些评论文本,数据集获取网址为:https://www.kaggle.com。
此数据集总共包含7个标签,总评论条数为159 571条,分别被标记,如表1。

表1 标签
根据图3所示,它们分别所占比例为:89.6%、9.6%、1.0%、5.3%、0.3%、4.9%及0.9%。从这里也能明显看到它们之间存在严重的类不平衡问题。如图3所示。
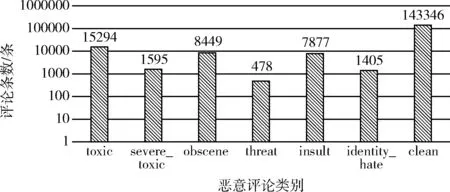
图3 评论类别分布
为了更好分析每条评论的结构和信息,本实验还分别对每条评论长度的平均值、方差及最大值进行了统计,分别为:67.86、100.52及2273。且统计出每天评论所包含1的数量,1的值越多表明恶意的程度越严重,如果所有的值都是0,则说明此条评论不存在恶意行为。图4中纵坐标表示对应的评论条数,横坐标表示每条评论标签存在1的数量。如图4所示。
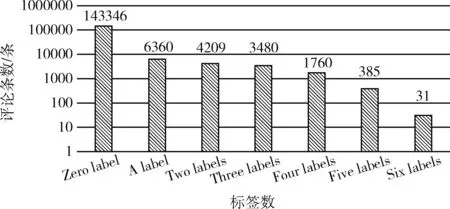
图4 评论标签数分布
分析图3和图4统计结果,可以发现各类评论之间存在较严重的类不平衡问题,因此,为了缓解这一问题,本文提出了一种基于最高密度点的SSU欠采样采样算法。该算法虽然减少了样本数量,降低了样本的利用率,但是提高了分类准确率,同时提高了分类效率。
3.2 评价指标
为了较好评估衡量SSU算法效率,及更好的与其它算法做对比,本文采用了较传统高效的准确率(Acc)和错误率(Loss)、F-measure及AUC 4个比较常用评价指标。具体见表2。
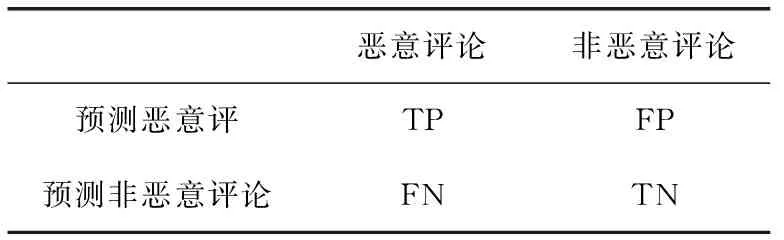
表2 性能评估列联表
精确率(Precision)计算公式
(14)
分类器错误率(false positive rate,FPR)
(15)
准确率(Accuracy,Acc)
(16)
F-measure值的计算
(17)
式(17)中:β可以较好调节Precision和Recall的权值,通常情况下将其赋值为1,F-measure是一个广泛应用于不平衡分类的评价指标,其既可以兼顾查全率又可以兼顾查询率。
AUC是ROC曲线下面的面积[14,15],也对分类器性能评估起到至关重要的作用,ROC曲线的X轴表示FPR,Y轴表示TPR即公式TPR=FP/(TN+FP)。
3.3 特征选择
通过对此次实验用到的数据集进行分析统计发现,此数据集于正常评论文本之间存在较大的差别,为了量化两者之间的差别,本文将总结的11个特征加入训练模型,11个特征见表3所示:

表3 特征
表4中,为了验证我们新加入的11个特征的影响度,本文计算了特征与每个预测值之间的相关程度,通过对比分析选择出了对预测值贡献度高的特征,见表4。

表4 特征与预测值相关性
为了筛选出影响程度较高的特征,我们又分别统计11个特征对每个类别的相关性值的绝对值之和,通过对比各个相关性值的绝对值之和的大小,发现Question_mark、Smilies以及Symbols 3个特征对评论文本的类别影响程度相对较小,因此本文考虑将不再引入这3个特征到训练模型中,此时实际引入特征为其余8个。
4 实验和结果分析
为了验证SSU算法与Bi-GRU网络结合模型,即SSU-BG模型相比其它模型的优点,本文将基于在随机下采样数据集、SMOTE算法过采样、SSU分层欠采样数据集上分别做对比实验,同时分别与表5中3种传统模型算法及表6中的3种深度学习模型算法分别在上述3类数据集上做对比实验。
表5所示为3中传统算法的对比实验结果:
表5中XG-Boost、LR、NBSVM这3种模型分别在3种数据集上进行了9组实验。每组实验都采用了4个相同的评价指标。在数据居选取层面上可以发现,SSU欠采样数据集在3大组实验中整体表现较好。虽然SMOTE算法在AUC指标上表现略好一些,比SSU算法的AUC值高出0.0127,比随机欠采样算法的AUC值高出0.0063,但综合考察3种模型中的Acc、Loss、F-measure这3个评价指标,可以发现在SSU算法下整体实验结果最好,为了验证这一点,我们可以做进一步的分析,例如对SSU算法下表现较好的NBSVM模型下的实验结果分析可得,SSU欠采样算法在准确率上比随机欠采样算法高出0.0453及比SMOTE算法高出了0.014;在错误率上比随机欠采样算法降低0.1289,相比SMOTE算法降低0.048;F-measure值比其它们分别高出0.0256和0.008。因此可以发现SSU算法在3种传统采样算法中整体表现最好。
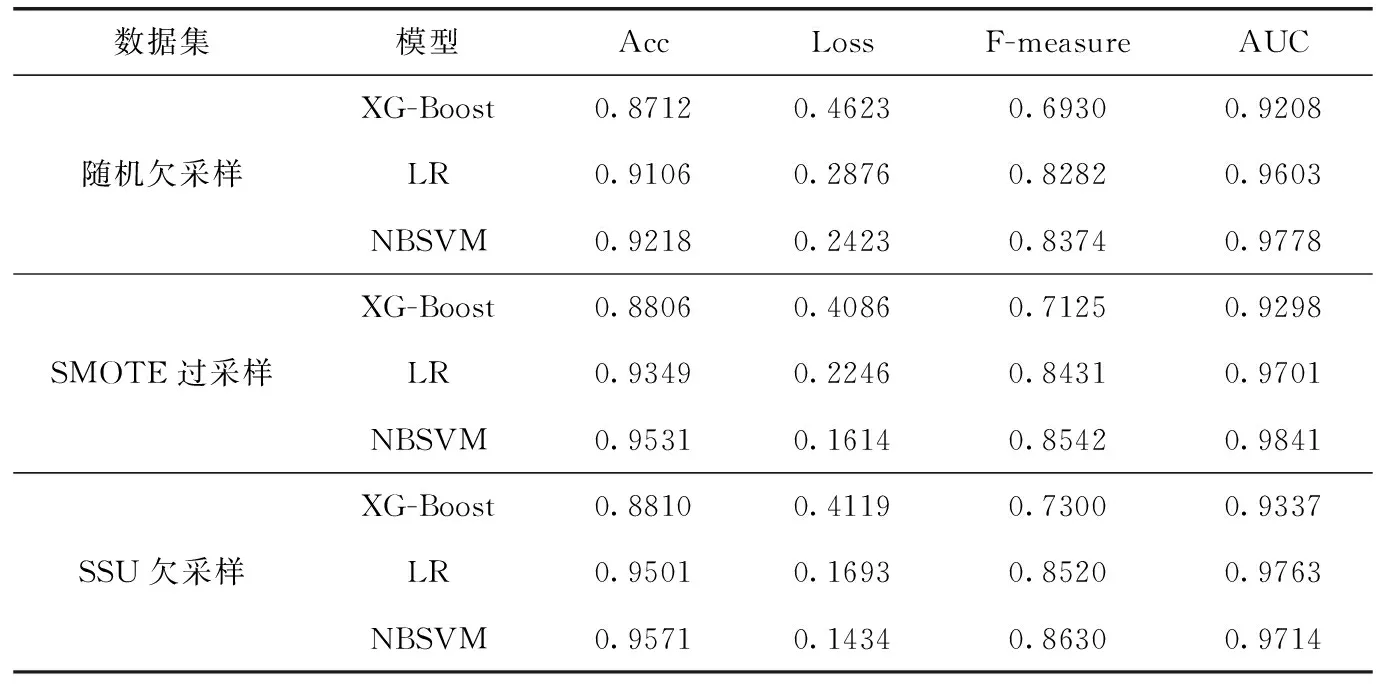
表5 传统算法实验结果
本文还做了其它12组针对4种深度学习算法的实验,实验结果见表6。

表6 深度学习算法实验结果
在表6中展示了3种数据集与4种结构类似的深度学习模型组合的对比实验结果,采用同上一组实验相同的评价指标。通过分析随机欠采样算法可发现,随机欠采样算法中只抽取了少量的数据集做为输入,大量的数据被选择放弃使用,最终导致实验结果并不理想。通过SMOTE算法过得的数据集可发现,此算法可以是整个数据集进行扩增,使得输入模型中的数据增多。在SMOTE算法算法下,Bi-LSTM网络表现较好一些,但如果从整体实验结果上来看,SSU算法表现略胜一筹。本文着重对比了SSU算法分别与这4种深度学习模型组合的实验结果。通过对比可以得出SSU-BG模型在4种评价指标下表现较好一些,得出结果如下:
(1)Acc值比其它最小值高出0.0228;
(2)Loss值比其它最高值降低0.0408;
(3)F-measure值比其它最小值高出0.0788;
(4)AUC值比其它最小值高出0.0157。
最后,结合表5和表6的实验结果对比和分析,可以得出如下结论:①SSU-BG评论检测模型提高了低频类的检测率;②SSU-BG评论检测模型没用损失高频类的检查准确率;③SSU-BG评论检测模型对比其它检测模型,整体样本检测率有所提高。
5 结束语
通过统计和分析恶意评论文本的结构特点,得出该数据集内容比较单一,且7类评论数量差距较大,使得各类之间存在严重的类不平衡问题,这将严重影响恶意评论的检测效果。为此,本文提出了SSU-BG检测模型来一定程度上缓解以上问题,同时提交检测效率。为验证SSU-BG模型的效果,本文分别与其它6个模型在3种数据集上做对比实验,总共21组实验。同时为了验证本文提出的SSU算法及SSU-BG模型优势,对比实验设计时考虑到在相同分类器下不同算法获取的数据集做对比实验及在相同数据集下不同分类器做对比实验。最终的实验结果显示,SSU算法相比其它两种采样算法表现较好,同时SSU-BG模型在处理不平衡问题上相比其它几种模型表现较好。在未来的研究工作中我们将验证该模型在更多应用领域上的表现效果,同时从考虑改进分类器角度进一步提高检测效率。
