面向本征图像分解的高质量渲染数据集与非局部卷积网络
2022-02-28王玉洁樊庆楠李坤陈冬冬杨敬钰卢健智DaniLischinski陈宝权
王玉洁,樊庆楠,李坤,陈冬冬,杨敬钰,卢健智,Dani Lischinski,陈宝权
1. 山东大学, 青岛 266237; 2. 腾讯AI Lab, 深圳 518057; 3.天津大学, 天津 300072;4. 微软云人工智能,华盛顿 98052,美国; 5. 广东三维家信息科技有限公司, 广州 510000;6. 耶路撒冷希伯来大学,耶路撒冷 91904,以色列; 7.北京大学, 北京 100091
0 引 言
图像的物理成分,如反照率和阴影,对于许多计算机视觉和图形应用来说十分关键。提取这些关键成分是一个重要的中级视觉问题,称为本征图像分解,该问题由Barrow和Tenebaum(1978)首次定义。在理想的漫反射环境中,一幅输入图像的每个像素可以分解为反照率和亮度的乘积。
由于未知量的数目是已知量的两倍,从单个输入图像恢复场景的反照率成分和亮度成分是高度不适定的。但由于其巨大的应用潜力,这项任务一直受到学者们的广泛关注。之前的工作提出了各种基于先验和统计的模型,包括Retinex模型(Land和McCann,1971)、非局部纹理线索(Zhao等,2012)和全局稀疏先验(Gehler等,2011;Shen和Yeo,2011)。
与许多其他具有挑战性的问题一样,基于深度学习的方法逐渐被用以克服本征图像分解任务的不适定性。在基于深度学习的本征图像分解方法中,通常使用一个编码器—解码器的深度学习网络结构从输入的图像中恢复场景的本征成分 (Fan等,2018;Li和Snavely,2018a,b; Narihira和Gehler,2015b;Shi等,2017)。为了实现反照率图像的局部平滑性质,这些方法通常引入后处理的滤波模块(Fan等,2018;Li和Snavely,2018a;Nestmeyer和Gehler,2017)或在目标函数中加入正则化项(Li和Snavely,2018a,b)来实现平滑先验。然而,一般的卷积神经网络结构较为擅长保持滤波器的空间局部性,从而由于其感受野大小的限制,可能会影响本征图像分解任务的性能,因为从图像中分解本征成分需要利用整幅图像的信息。
受到图卷积神经网络在形状和语义理解任务中的成功应用,以及经典的本征图像分解算法(Bi等,2015;Chen和Koltun,2013;Shen等,2008;Shen和Yeo,2011;Sinha和Adelson,1993;Zhao等,2012)中所采用的非局部稀疏性先验的启发,本文提出了一种适合于本征图像分解任务的非局部图卷积网络。提出的非局部图卷积运算的设计借鉴了用于形状分类的图卷积网络(graph convolutional neural network, GCN)(Simonovsky和Komodakis,2017),但针对2D图像结构进行了修改。提出的图卷积网络将特征图中的点视为图中的一个顶点,对特征图像中的每个点,与在整幅特征图上定义的非局部邻域点之间建立连接,进行特征融合,从而使得图卷积层学习更多的全局知识。
另一方面,数据集对基于深度学习网络的方法非常重要(沙浩和刘越,2021)。一旦训练数据和测试数据之间存在较大的差别,基于学习的方法往往泛化能力较差。并且,目前现有的本征图像数据集均存在缺陷,例如数据量不足(MIT (Grosse等,2009))、场景不够逼真(MPI-Sintel (Butler等,2012))、仅包含单个物体的简单场景(ShapeNet (Shi等,2017)), 或只用于弱监督的稀疏注释(IIW(intrinsic images in the wild)(Bell等,2014),SAW(shading annotations in the wild)(Kovacs等,2017))。这些缺点使得深度学习技术在本征图像分解这个任务上无法充分发挥其性能。Li和Snavely(2018a)提出了一个基于SUNCG室内场景数据集(Song等,2017)渲染的逼真的本征图像数据集。尽管该方法提出的数据集在场景的逼真度和渲染图片的质量上均有明显提升,但是该数据集中的图片中仍然具有明显的噪声,以及该数据集中并未提供逐像素的亮度图标签,并在使用时默认亮度图中光照是白光。
为了克服上述局限性,提出了一个新的基于真实感绘制的本征图像数据集,该数据集中的渲染数据来自大规模设计精细的3维室内场景模型,并结合高质量的纹理和光照来模拟真实环境。提出的本征图像数据集提供了逐像素的亮度图标签,且亮度图中没有使用白光光照。实验结果表明,所提出的数据集比现有的本征分解数据集具有更好的图像质量,有效地缓解了基于学习的方法在真实图像上的泛化能力。
此外,对所提出的方法与前沿的本征图像分解方法进行了综合比较,不仅在主流的本征图像评价基准(IIW/SAW测试集)上进行了比较,而且在各种图像编辑应用场景中更加直观地对比了不同方法产生的本征分解结果的质量。
本文的贡献可总结如下:
1)提出了第一个针对本征图像分解问题的图卷积网络,在网络设计中显示利用了非局部图像信息。
2)通过大规模真实感渲染,提出了一个新的场景级本征图像数据集, 并在亮度图像标签中提供了非白光光照,使亮度图像分量更加逼真,从而使得在本文数据集上训练的深度学习网络具有更好的泛化能力。
3)对提出的方法及数据集在基准评价指标上进行了测试和对比,并在一系列应用任务上对比分析了本文方法所产生的分解结果的质量。
1 相关工作
20世纪70年代,从图像中分解场景的物理属性就开始引起学术界的关注(Barrow和Tenenbaum,1978;Land和McCann,1971)。Barrow和Tenenbaum(1978)介绍了本征图像的定义,此后众多的本征图像分解算法相继提出,包括一系列经典算法(Chen和Koltum,2013;Shen和Yeo,2011;Shi等,2015;Zhao等,2012)和最近的深度学习方法(Fan等,2018;Li等,2018a;Li等,2018b;Ma等,2018)。由于对单幅图像进行本征分解的不适定性,一部分方法探索使用额外的信息来缓解这种困难,例如使用同一场景下的图像序列、深度信息(Chen和Koltum,2013;Wang等2017) 和用户涂鸦等。本文主要研究基于单幅图像的本征图像估计,适用于最常见的没有提供额外信息的真实场景。
1.1 方法
1.1.1 传统方法
在传统方法中,Retinex理论(Land和McCann,1971)影响深远,它假设反照率图像是分块平滑的,亮度图像内整体变化比较平缓,成为之后许多基于先验的本征图像分解模型的基石。为了进一步减少问题的不适定性,此前的方法引入了许多其他先验,其中最常用的是非局部先验(Chen和Koltum,2013;Shen等,2008;Zhao等,2012)和稀疏性约束(Gehler等,2011;Shen和Yeo,2011)。例如,Shen等人(2008)结合了非局部相关性——不相邻的两点,如果它们具有相似的纹理,那么它们仍然极有可能具有相同的反照率值。Shen和Yeo(2011)基于自然图像中通常只包含几种颜色的假设,提出了一种全局稀疏性约束。一些方法通过聚类的算法实现稀疏先验:Garces等人(2012)使用K-means算法在CIELab色彩空间内将像素聚类为一些像素组,Meka等人(2016)在构建本征图像分解模型时使用了较为简单的直方图聚类。此外,一些方法(Bell等,2014;Chen和Koltum,2013)在整个图像内构建点对之间的连接,以利用非局部先验。综上,非局部先验在传统的本征图像分解模型中得到广泛使用,并被验证是有效的。
1.1.2 基于深度学习的方法
如Barron和Malik(2015)所述,对真实世界中的光照和几何分布的统计,对于解决本征图像分解中的歧义性是有效的。2009年以来,随着本征图像数据集,包括MIT、MPI-Sintel、IIW、SAW等的发布,以及深度学习技术在计算机视觉任务中取得的进展,越来越多的工作使用深度学习技术来构建本征图像分解模型(Fan等,2018;Ma等,2018;Narihira等,2015a,b;Shi等,2017;Zhou等,2015)。为了提高反照率分量的分块平滑性,一些方法探索将传统方法与深度学习方法结合,如后处理滤波操作(Li和Snavely,2018a;Nestmeyer和Gehler,2017)、联合学习的引导滤波器(Fan等,2018)和平滑度损失函数(Li和Snavely,2018a,b)。这些方法大多只考虑反照率图像的局部平滑性,而没有显式地考虑反照率图像的全局信息。
1.1.3 图卷积网络
图卷积网络(GCN)在需要处理非规则结构数据的任务中,取得了明显的提升,如点云上的任务(Yi等,2017;Wang等,2018)。基于谱图论,Bruna等人(2013)设计图卷积的变体,该工作是GCN领域的先驱工作。之后,GCN被其他工作提升或扩展,包括基于谱图卷积的工作(Henaff等,2015;Li等,2018a),以及一些基于空域的图卷积工作(Hamilton等,2017;Monti等,2017)。Simonovsky和Komodakis(2017)提出了基于边的图卷积,它在每个点周围的邻域上进行加权聚合,并根据边上标签确定连接权重。对于本征图像分解任务,本文方法将特征图中的每一个点视为一个节点,通过将空间距离相近的点以及距离较远但局部特征近似的点选取为邻域,在节点(特征)间建立非规则的图。然后,本文方法将图卷积扩展到建立的图结构上。
1.2 数据集
当给定足够多样的训练数据时,深度学习方法能够从数据中学习到比手工先验更复杂的先验知识。然而,由于现有的本征分解数据集均存在不足,使得深度学习技术无法充分发挥出优势。例如,MIT数据集(Grosse等,2009)是通过拍摄几百个物体级的场景构建的,获得的图像没有背景,而且样例较少。Bell等人(2014)在亚马逊平台上让用户在真实图像的稀疏点对上标注相对的反照率关系,从而构建了IIW本征数据集。Kovacs等人(2017)通过众包形式收集了多种形式的亮度图标注,该数据集命名为SAW。最近,一些大规模渲染的本征图像数据集相继提出,包括从开源的3D动画电影中提取的数据集(Butler等,2012)、室外环境的渲染数据集(Baslamisli等,2018)和在一些3D形状上渲染的数据集(Shi等人,2017)。与本文所提数据集最相近的本征分解数据集是CGIntrinsics(Li和Snavely,2018a),它是基于3D室内模型数据集SUNCG(Song等,2017)进行渲染的,包含约20 K幅图像。此外,Li等人(2018b)提出了一个大规模渲染数据集InteriorNet,它包含了更多(20 M)的图像。但是,在该数据集中,为每个场景渲染了约1 000幅图像,因此该数据集在图像多样性上和CGIntrinsics数据集、本文数据集接近。同时,以上两个数据集中都不提供渲染的亮度标签图像,而是通过使用输入图像与反照率图像计算而来,从而造成亮度图像中的伪影,且图像中有明显的噪声。
2 本文方法
首先描述如何在图像中构建和进行图卷积、提出的整个本征分解网络框架以及本文算法中设计的损失函数。
2.1 图卷积层
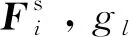

图1 非局部图卷积层Fig.1 Non-local graph convolutional layer

(1)
式中,M=h×w,是特征图中点的总数,V表示Fin中所有点的集合,N(pi)是pi的邻域点的集合,E表示建立的所有连接的集合,ei,j表示点pi与点pj建立的连接。gnl分支计算为
(2)

(3)
式中,⊙表示将两个向量的对应元素进行相乘,权重向量wi,j是根据pi与pj之间的特征差异和位置上的距离进行计算,即
(4)
式中,⊕表示将两个向量连接,gnl是通过一个多层感知机实现的,di,j是pi与pj之间的距离,计算为
(5)
式中,(xi,yi)和(xj,yj)是pi与pj在特征图Fin中的2维坐标。得到3个分支的输出后,图卷积层的最终输出计算为
(6)
2.2 本征图像分解网络

在编码器和解码器中,每个卷积层或反卷积层之后均使用批标准化层(batch normalization)和ReLU激活层。并且,由于编码器和每个解码器之间的结构是对称的,在编码器和解码器的对应特征尺度间,分别建立对应的跳过连接(skip connections)。

图2 本文所提本征分解网络结构图Fig.2 Structure of the proposed intrinsic decomposition network
从图像中推理场景中的本征属性需要对整个图像的整体理解。例如,图3中左侧的例子中,地砖上呈现的粉色(图3中蓝色圈中的区域)是由较远的粉色橱柜间接反射而来的(图3中绿色圈中的区域)。为了正确地恢复地板区域的本征信息,深度神经网络需要利用整幅图的全局信息。对于图3中右面的例子,蓝色圈中的区域和绿色圈中的区域都属于地板区域,是由相同的材质制成的,因此它们具有相同的反照率信息。然而,由于阴影的存在,使得它们在输入图中的像素信息相差较大。因此,为了正确地估计绿色圈中区域的反照率信息,需要利用图片中相隔较远的区域的信息,如蓝色圈中的区域的信息。

图3 全局理解对本征属性感知的必要性Fig.3 Requirement for global understanding of intrinsic property perception
然而,通常的卷积网络所产生的感受野大小是有限的,因此只能学习较为局部的特征,并且没有显式地考虑图像中距离较远的点之间的联系。为了克服这个限制,在编码器—解码器结构中引入了由4个连续的图卷积层构成的非局部注意力模块hnlm,从而使得网络框架可以显式地利用图中的非局部信息。因此,3个编码器接收到的是经过hnlm处理的特征,由于它们所预测成分的不同,其输出层的通道数分别被设置为3、3、1。
2.3 反照率优化模块
此外,所提的本征分解框架还包括一个反照率图像优化模块hr,该网络由20层卷积核为3×3、步长为1的卷积层构成。每一层卷积层之后使用实例规范化层(instance normalization)和ReLU激活层。第1层的输入通道数为4 (由输入图像和引导边缘图像构成), 最后一层的输出通道数为3,中间层的输入/输出通道数均为64。此前,一些基于学习的方法均利用了后处理的滤波模块对神经网络预测得到的反照率图像albedo进行优化(Fan等,2018;Li和Snavely,2018a;Nestmeyer和Gehler,2017);另一些工作在损失函数中引入了稀疏先验以生成干净平整的反照率图像。受这些工作的启发,所提的网络框架引入一个优化模块对解码器预测的反照率图像进行优化。与之前工作不同的是,所提框架中引入的优化模块是基于神经网络的优化模块。
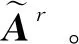
由于本文所提网络框架中的反照率图像优化模块是由一个深度学习网络实现的,相比于一个固定的传统滤波算法,它支持更加复杂的图像操作,从而实现了更好的优化效果,其作用在本文的消融实验中得到了验证。
2.4 损失函数
对本文网络框架中所设计的损失函数进行描述。为了训练所提出的网络框架,建立一个具有照片真实感的本征分解数据集。在该数据集中,为了减小合成图像与自然图像之间的差异,除了逐像素的反照率标签(A)和亮度标签(S),也渲染了4个其他的光照成分,包括:高光成分(SP)、反射成分(RE)、折射成分(RA)和自发光成分(SI)。这些其他成分的渲染使得输入图像更接近自然图像,但是在训练本文网络框架时,由于这些其他成分不包含在反照率图像和亮度图像中,在损失函数中需要将这些区域排除。首先计算一个蒙版图像
(7)
式中,i表示像素索引,Mi是该像素的蒙版值。对于蒙版值为1的区域,损失函数定义为
(8)

(9)
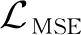

(10)
(11)
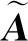
(12)
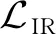
(13)
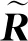
3 合成数据集
为了实现更高质量的本征分解效果,提出一个具有照片真实感的渲染数据集,提供逐像素的反照率和亮度标签。该数据集中包含21 478组由输入图像、反照率图像和亮度图像组成的数据样例。在训练所提出的本征分解网络时,数据集中18 256组数据用于训练,其他数据用于测试。如图4和图5所示,提出的数据集具有更高的逼真度,主要来源于以下因素:
1)场景布局。为了建立该数据集,从其室内设计平台收集了5 730个合成的3维室内场景模型,类型包括客厅、卧室、厨房和浴室等。它们由数百名专业设计师/艺术家设计,场景内物体的摆放与真实室内场景高度吻合。
2)光照设置。在渲染数据集中的图像时,本文数据集中使用了来自多种光源的光照,以模拟真实世界的视觉效果。除了常见的全局光照和相互反射之外,本文数据集中的图像还包含由透明物体、镜子和自反光物体引起的折射、镜面反射和灯光等效果。如图4所示,这些其他的光照成分,使得渲染后的图像更接近日常室内场景拍摄的图像。

图4 其他光照成分对图像渲染的影响Fig.4 Comparison between rendered images with and without the extra illumination effects((a) specular; (b) self-illumination;(c) refraction; (d) reflection; (e) input image; (f) input image (without other illuminations); (g) enlarged regions)

图5 本文所提数据集与CGIntrinsics数据集的比较Fig.5 Comparison between the proposed dataset and CGIntrinsics dataset((a) the proposed dataset;(b) CGIntrinsics))
3)纹理多样性。为了使得渲染得到的数据包含丰富的纹理,数据集中所包含的场景中的物体表面的纹理是从约80万张材质贴图中随机采样得到的。如图4所示,本文数据集所渲染的图像具有较高的纹理多样性。
4)渲染设置。本文数据集中的图像是采用Embree4渲染引擎,使用确定性蒙特卡罗(deterministic Monte carlo, DMC)算法渲染得到的。图像的分辨率是1 280×960像素,每个像素的采样数为3 228。使用普通台式机渲染一张具有照片级真实感的图像需要数小时的计算,十分耗时。为了加速渲染过程,本文通过32台服务器进行分布式渲染,平均每张图的渲染时间为90 s。
对此前提出的本征图像分解数据集和本文数据集进行了对比,比较结果总结于表1中。
如表1所示,MIT(Grosse等,2009)和ShapeNet intrinsics (Shi等,2017)这两个数据集,仅提供了物体级别的图像及对应的逐像素标签,与真实环境中的场景有较大的差距。MIT数据集受限于数据集的大小, Shi等人(2017)数据集中的图像与真实图像差别较大。IIW(Bell等,2014)数据集和SAW数据集(Kovacs等,2017)是建立在真实场景拍摄得到的照片上的,但是两者均只提供基于人类判断的稀疏标注。此外,MPI-Sintel(Butler等,2012)数据集提供了场景级的图像及逐像素的本征属性标签,但是其中的场景均来自于与现实环境差别很大的动画场景。与本文数据集最相关的数据集是CGIntrinsics数据集(Li和Snavely,2018a)。与该数据集相比,本文数据集提供了更高分辨率和带有非白光光照的亮度图像标签,而CGIntrinsics数据集只提供反照率标签图像,亮度图像通过使用输入图像除以反照率图像计算得到。由于该公式只对漫反射的区域满足,那么在非漫反射的区域,计算得到的亮度图像会引起误差。为了直观地体现本文数据集与CGIntrinsics数据集的差别,图5 (a) 中提供了来自本文数据集的4组样例,图5 (b)中展示了来自CGIntrinsics数据集的3组样例,从上到下依次展示了输入图、反照率标签图像、亮度标签图像和放大的局部区域。如图5所示,相较于CGIntrinsics数据集,本文数据集展现了更逼真的视觉效果,具有更丰富的纹理,在场景布局上更加复杂,并且图像中噪声更少。本文数据集中的亮度图像中的光照是非白光的,更加符合真实室内场景的光照。
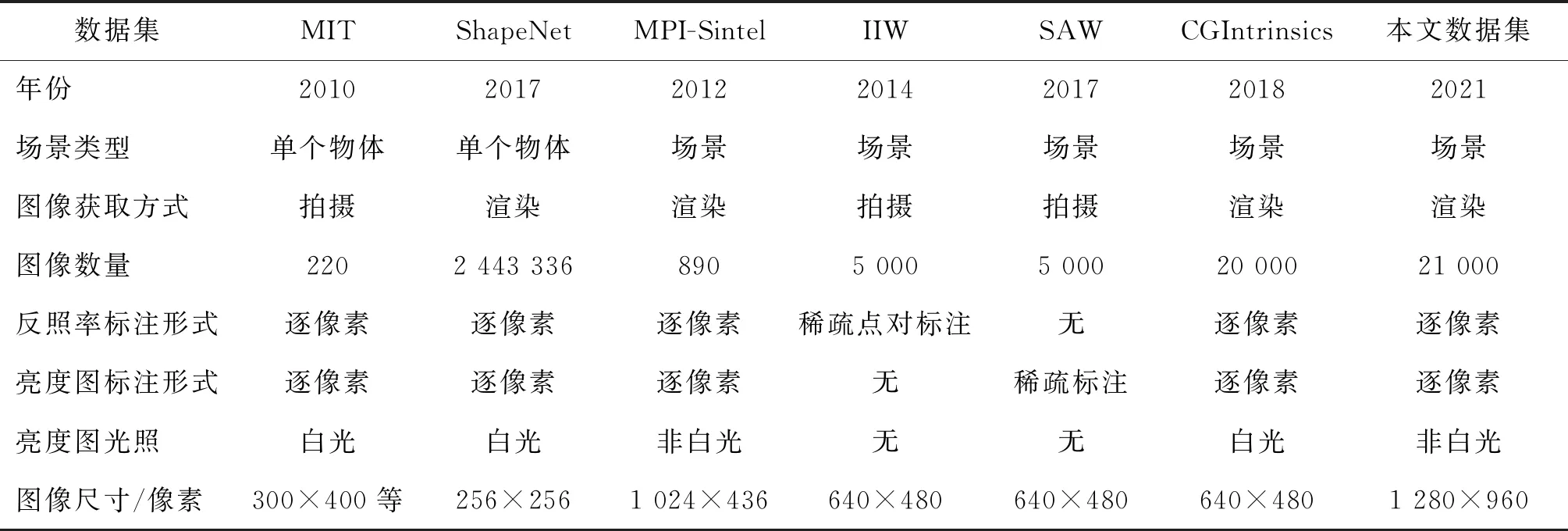
表1 不同本征分解数据集的对比Table 1 Comparison between different intrinsic datasets
4 实验结果
IIW/SAW数据集中只提供了人工标注的一些稀疏标签,并未提供逐像素的反照率图、亮度图标签,因而无法计算如MSE(mean squared error)、PSNR(peak signal-to-noise ratio)、SSIM(structure similarity index measure) 等图像质量评价指标上的数值结果。因此,本文使用了基于IIW、SAW数据集的标签类型而设计的评价指标WHDR (weighted human disagreement rate),该指标越低越好,AP (average precision),该指标越高越好。
4.1 实现细节
本文本征图像分解网络模型使用PyTorch框架实现,批大小为6,使用Adam算法进行优化。在训练过程中,初始学习率设置为0.01,在IIW/SAW数据集上进行微调时更改为0.000 5。优化网络模块单独训练,学习率设置为0.01,批大小设置为4。
4.2 数据集的有效性
通过将所提数据集与该数据集进行详细比较,来验证本文数据集对提升本征分解结果的有效性。首先,在所提出的数据集和CGIntrinsics数据集上分别训练了3种目前效果领先的本征分解深度学习网络,然后在IIW/SAW数据集的测试集上对训练之后的网络的分解结果进行测试,得到的测试结果汇总在表2中。
为了公平比较不同数据集的质量,在测试时,对所有方法均去掉了其中的后处理优化模块,在训练时均使用作者提供的开源代码和参数设置。如表2中所示,与使用CGIntrinsics训练相比,使用本文数据集训练的3种方法的平均测试结果取得了更高的性能。具体表现为:对于3种方法上的平均结果, 使用本文数据集,WHDR降低了8.87%,在SAW测试集上的准确率AP提升了2.74%。这表明在不同的网络框架和损失函数设置的情况下,使用本文数据集进行训练,均可以获得更高的分解质量。同时,IIW/SAW数据集中的输入图片是真实拍摄的图像,表明在本文数据集上训练的网络具有更好的泛化能力。
在使用Shi等人(2017)的方法和Li和Snavely(2018a)的方法提出的网络结构进行训练时,本文数据集使得网络在IIW测试集、SAW测试集上产生的结果,相较于使用CGIntrinsics数据集训练的结果,均有显著提升。在使用Fan等人(2018)的方法进行训练时,本文数据集使得网络在IIW测试指标WHDR有显著提升,但是在SAW测试集上与使用CGIntrinsics数据集训练的版本有较小的差距(0.9%)。这是由于本文数据集提供的亮度图标签图像为三通道的彩色图像,与使用CGIntrinsics的单通道亮度标签图像相比,神经网络预测得到的亮度图在局部区域内相邻像素的数值之间存在一些差异的可能性增大,该现象可以通过简单引入现有的图像滤波模块进行解决。

表2 不同本征分解数据集的有效性对比Table 2 Comparison of the effectiveness of different datasets
4.3 在IIW/SAW 数据集上的测试结果
对本文本征分解网络框架与之前最优的本征分解算法进行了对比。沿用Li和Snavely(2018a)中的做法,对所提出的网络框架在IIW/SAW训练集上进行了微调。在微调阶段中,使用了Fan等人(2018)和Li和Snavely(2018a)方法中使用的训练/测试集划分,并使用了在Li和Snavely(2018a)方法中提出的顺序反射损失和基于SAW数据集标注形式设计的亮度损失。此外,为了充分利用IIW数据集中的标注,使用了由Li和Snavely(2018a)方法提供的数据增强之后的标签。最后,IIW/SAW测试集上的测试结果汇总在表3中。
如表3所示,在仅使用本文数据集训练的情况下,本文方法在IIW测试集上的WHDR为17.92%,在SAW测试集上的准确率为96.17%,即取得了优于之前所有传统方法的结果,并且超越了大部分的基于深度学习的方法。特别地,在没有微调的情况下,本文方法在SAW测试集上的结果接近于Li和Snavely(2018a)方法在微调后的结果,这表明本文方法具有较好的泛化能力。通过在IIW和SAW数据集中的训练数据上微调,本文方法最终取得了较好的数值结果。不同于Li和Snavely(2018a)方法及Fan等人(2018a)方法,本文方法仅在IIW和SAW数据集上微调,没有在整个训练阶段中使用IIW和SAW数据。这可能使得本文方法的WHDR误差略高于以上两种方法。
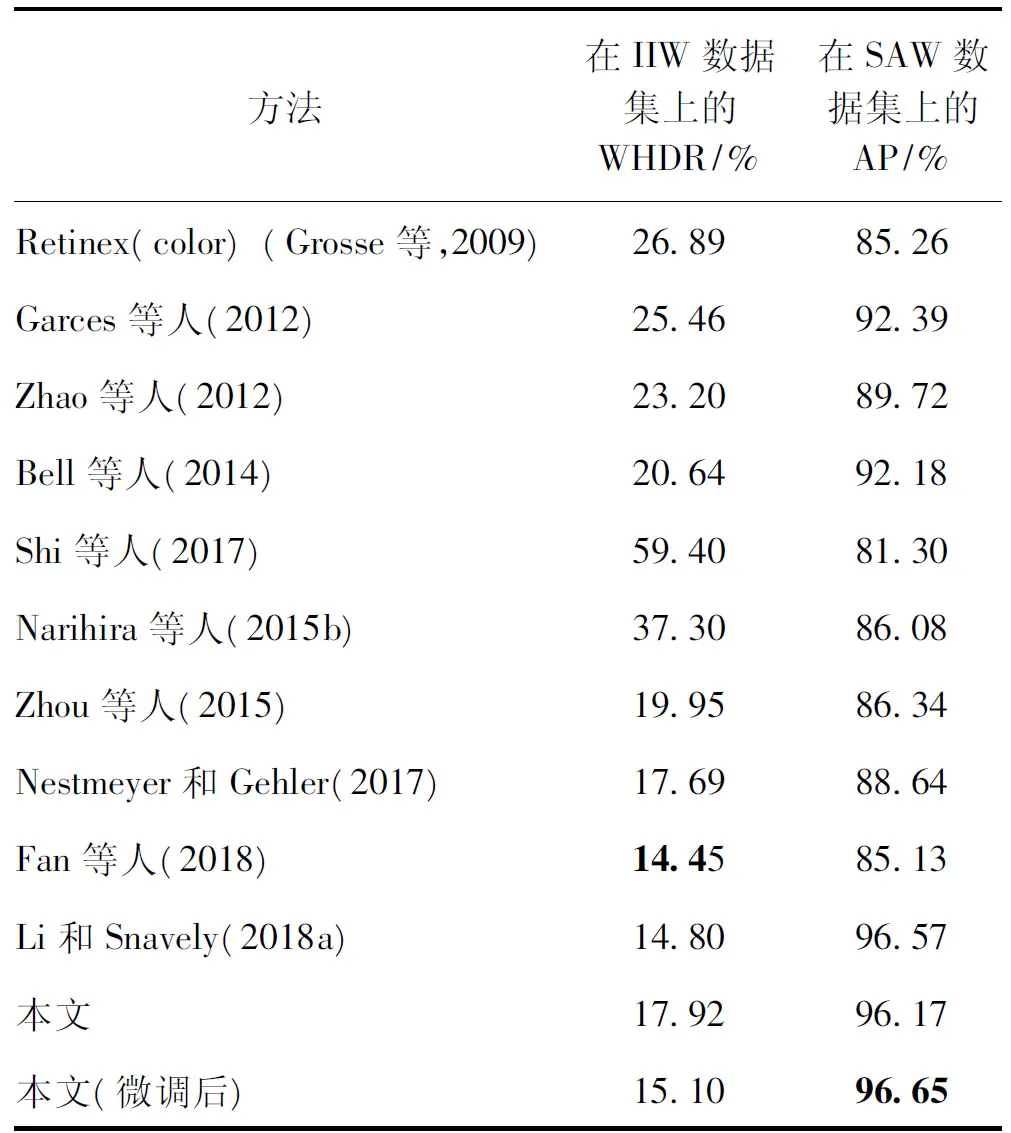
表3 在IIW/SAW测试集上的定量结果Table 3 Quantitative comparison on IIW/SAW test sets
在图6中,展示了本文方法和另外两种方法(Fan等,2018;Li和Snavely,2018a)在IIW和SAW测试集上的分解结果。如图6所示,本文方法的本征分解性能优于其他方法。不同于Li和Snavely(2018a)方法、Fan等人(2018)方法与Nestmeyer和Gehler(2017)方法,本文方法产生的亮度图的结果是具有彩色光照的。对于预测的反照率图像,如图6所示,本文方法的结果颜色更自然。相较于本文方法产生的结果,其他方法的结果没有将光照的颜色和物体表面的材质颜色分开。因此,本文方法产生的分解结果质量更高。
在Fan等人(2018)方法及Nestmeyer和Gehler(2017)方法中,深度学习网络只预测反照率图像,亮度图像由输入图像除以预测的反照率图像得到。

图6 不同方法在 IIW/SAW 测试集上的分解结果Fig.6 Intrinsic decomposition results on images from IIW/SAW test sets for different methods((a) input image; (b) Nestmeyer and Gehler(2017);(c) Fan et al. (2018);(d) Li and Snavely(2018a);(e) ours;(f) ours (finetuned))
因此,反照率图像结果中不准确的区域,会影响以上两种方法产生的亮度图像结果。由于Li和Snavely(2018a)方法在损失函数中施加了平滑约束项,使得该方法产生的结果十分平滑,甚至无法体现场景中的很多几何信息。但是,在本文方法产生的结果中,以上问题都未出现。
此外,Nestmeyer和Gehler(2017)以及Zhou等人(2015)指出,在IIW数据集中的相对反照率标注中,由于标注为具有相同反照率关系的点对占据了所有标注的2/3,使得该数据集中的标注向具有相同反照率的点对倾斜。例如,在不对输入图像进行本征分解的情况下,简单地将输入图像的数值从[0,1]范围缩放到[0.55,1]之间,即简单地将输入图像的像素之间的对比度降低,在IIW测试集上得到的WHDR误差值为25.7%,甚至优于很多本征分解方法产生的结果。这个观察进一步表明了IIW测试集的标注中相等反照率的点对所占比例更高,如Nestmeyer和Gehler(2017)所述。因此,直接在IIW和SAW数据集上训练可能会导致深度学习网络过拟合到其数据集所体现的数据分布,即倾向于预测更平滑的反照率图像。
由于上述原因,本文方法首先在本文提出的合成数据集上训练,然后在IIW和SAW数据集上进行微调,从而避免在IIW和SAW数据上的过度拟合。使用本文的训练策略,提升了本征图像分解的视觉结果,但可能使得本文方法在数值结果上的提升不如在视觉结果上的提升显著。
4.4 在其他数据上的测试结果
基于深度学习的算法,在训练数据与测试数据的分布相差较大时,性能极可能显著下降。由于本文方法使用合成数据集训练,验证它在一般自然图像上的本征分解结果是十分必要的。因此,本文在图7中提供了3组不同方法在一般自然图像上的分解结果。图7中显示,本文方法产生的结果明显优于其他3种方法产生的分解结果。

图7 不同方法在其他图片数据上的分解结果Fig.7 Intrinsic decomposition results on unseen images for different methods ((a) input; (b) Nestmeyer and Gehter(2017);(c) Fan et al.(2018);(d) Li and Snavely(2018a); (e) ours))
如图7第1行所示,由对比方法(Fan等,2018;Li和Snavely,2018a;Nestmeyer和Gehter,2017)所产生的反照率图像,被场景中光照颜色严重影响,并且丢失了瓷器表面的花纹细节。相反,本文方法产生的结果将光照颜色从反照率图像中分离出去,并且保留了瓷器表面的纹理细节。在图7中第2个例子中,场景中有较强的相互反射,其他3种方法都没有将这些彩色的相互反射分解到亮度图中,但本文方法成功地将这些成分分解到亮度图结果中。图7中最后一个示例展示了室外场景的情况,这种类型的数据是没有出现在训练数据中的。本文方法产生的结果可以正确地将船体上的字母分解到反照率图像中,避免它出现在亮度图中,而其他方法的结果均将这些纹理错误地引入到对应的亮度图结果中。综上,本文方法产生的本征图像分解结果体现出较高的质量。
5 应 用
作为一个中级视觉任务,本征图像分解的结果只有在用于下游应用时才更有价值。将在几个基于本征图像分解结果的应用场景上,进一步验证本文方法产生的本征分解结果的质量。
5.1 纹理编辑
在进行纹理编辑任务时,首先利用本征分解算法将输入图像分解为反照率图像和亮度图像,然后在反照率图像中将需要修改的纹理进行编辑,之后用编辑后的反照率图像和原始的亮度图像一起合成新的编辑过的图像。这个任务的最终效果十分依赖分解得到的亮度图,因此可以直观地比较不同方法分解得到的亮度图的质量。
在图8的第1个示例中,在3种方法分解得到的反照率图像中,3只小猪的眉毛分别被修改,然后使用修改过的反照率的图像乘以对应的亮度图像,得到对应的编辑结果。如图8所示,Fan等人(2018)方法由于错误地将眉毛的纹理引入到亮度图像中,使得对应的编辑结果中存在原始眉毛图案的伪影。Li和Snavely(2018a)方法所产生的编辑结果中在原来图案的附近也存在伪影,是由该方法产生的亮度图中存在的纹理复制现象引起的。对于图8中第2个示例,墙上两幅画的位置在对应的反照率图像中分别被交换,然后与对应的亮度图结果相乘得到输出图像。图8中显示,第2个示例产生了与第1个示例类似的现象:利用Fan等人(2018)方法和Li和Snavely(2018a)方法产生的分解结果得到的编辑结果中,两幅画中原始内容依然存在于原来的位置,这是由残留在亮度图像中的纹理造成的。此外,Li和Snavely(2018a)方法产生的反照率结果过度平滑,因此第2个示例中,基于该方法的分解结果得到的编辑结果中缺少画中的细节。

图8 基于不同方法的本征分解的材质编辑结果对比Fig.8 Comparison between results for texture editing using intrinsic components from different methods ((a) input; (b) Fan et al.(2018); (c) Li and Snavely(2018a); (d) ours)
5.2 光照编辑
光照编辑是通过修改本征分解结果中的亮度图像,然后与未经修改的反照率图像相乘得到输出结果来进行,它可以用来体现反照率图像的质量。
图9中展示了光照编辑任务的两个示例。在第1个示例中,不同方法预测得到的亮度图中,由台灯照亮的区域被平滑。由于Fan等人(2018)方法以及Li和Snavely(2018a)方法均未能去除其预测的反照率图像中的光照,因此这两种方法产生的编辑结果中仍然存在台灯照亮的区域。相反,本文方法产生的编辑结果中,该区域的光照已被去除。在第2个示例中,通过将产生的亮度图变为灰度图,再与原始的反照率图像相乘得到输出结果,达到去除场景中光照颜色的目的。显然,基于其他方法产生的结果中仍然保留着原始输入图像中的整体光照颜色。
然而,基于本文方法产生得到的编辑结果中,原始场景中的整体光照颜色则被全部去除。这是由于其他两种方法估计的亮度图本身是灰度图,默认亮度图中的光照为白光,导致输入图中的彩色光照信息都被错误地分解到了反照率图像中。
此外,按照Zhou等人(2015)方法中的实验设置,从Boyadzhiev等人(2013)以及Li和Snavely(2018a)方法提供的数据集中选取了特殊的图像序列数据,序列中的每幅图像中的纹理是严格一致的,只有光照不同。对于提取到的图像序列,基于不同的本征分解方法,进行了重光照任务,将序列中的两幅图像首先进行本征分解,然后对两幅图的亮度图像进行交换,再与两幅图像对应的原始反照率图像进行相乘,得到最终的光照编辑结果。由图10中的两个示例显示,在视觉上,基于本文方法的分解结果所得到的重光照结果,最接近与交换后的亮度图所对应的原始输入图像。而对于其他两种方法,重光照的结果总是存在颜色偏差,这是由于以上两种方法没有将光照颜色从反照率图像去除。

图9 基于不同方法的本征分解结果的光照编辑结果对比Fig.9 Comparison between results for light editing using intrinsic components from different methods ((a) input;(b) Fan et al. (2018);(c) Li and Snavely (2018a);(d) ours

图10 基于不同方法的本征分解结果的光照交换结果对比Fig.10 Comparison between results for light exchange using intrinsic components from different methods ((a) input;(b) Fan et al. (2018);(c) Li and Snavely (2018a);(d) ours
6 消融实验
通过消融实验对本文方法的各个模块的作用进行分析。在消融实验中,所有的变体都在不经过微调的情况下,在IIW/SAW测试集上进行测试,数值结果汇总在表4中。
6.1 非局部图卷积模块的有效性
为了验证本文方法中图卷积模块hnlm的有效性,将hnlm从本文设计的图卷积神经网络中去掉后进行训练,该变体表示为表4中的“本文(去掉hnlm)”。
如表4所示,与本文方法的完整模型相比,去掉hnlm之后,在反照率图像和亮度图像上的定量结果均显著下降,验证了图卷积模块hnlm的有效性。
6.2 反照率图像优化模块的有效性
表4中第2行展示了变体“本文(去掉hr)”的测试结果,该变体是通过将反照率图像优化模块hr从本文方法的框架中去掉得到的。如表4所示,去掉hr之后,WHDR误差增加至20.89%,即反照率图像的预测结果显著下降,这体现了本文网络框架中反照率优化模块hr对提升反照率图像结果的贡献。
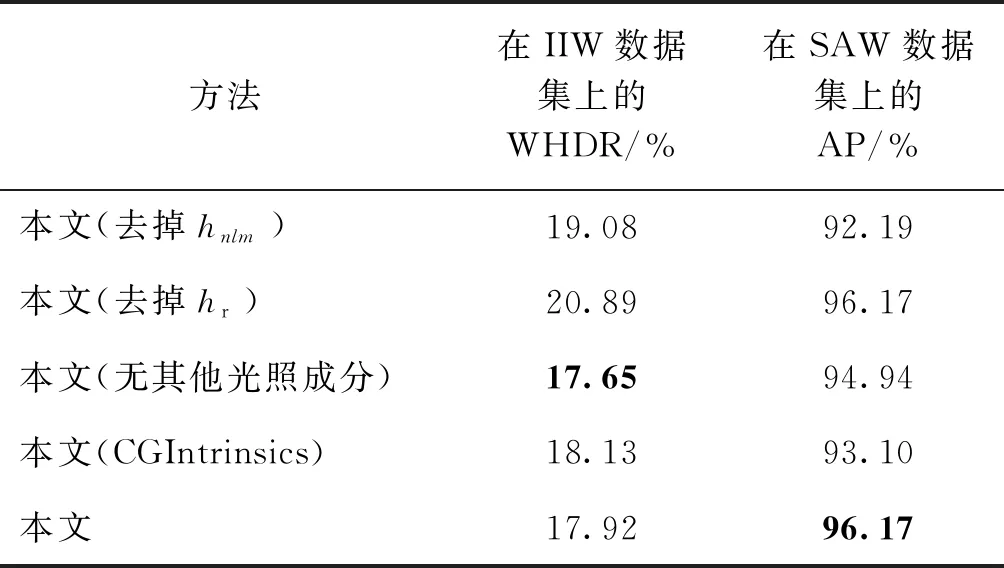
表4 消融实验结果Table 4 Ablation study results of the proposed method
6.3 在输入图像中渲染其他光照成分的作用
如第3节中所述,本文数据集在输入图像中渲染了多种光照成分,以增加输入图像的逼真度。为了验证渲染这些成分对提升本征分解结果的作用,此处设计了一个变体——“本文(无其他光照成分)”:即使用标签图像的反照率图像和亮度图像进行相乘合成出只有漫反射成分的输入图像,然后对本文方法在这些数据上进行训练。该变体的测试结果汇总于表4,其中SAW测试集上的结果明显下降。这表明,在输入图像中渲染非漫反射光照成分对亮度图的预测的有效性。
6.4 本文所提数据集对本文方法的作用
为了探究本文数据集对本文方法的贡献,变体“本文(CGIntrinsics)”被训练和测试,即在Li和Snavely(2018a)提出的数据集CGIntrinsics上训练本文提出的图卷积神经网络。如表4所示,相较于使用本文提出的数据集训练相比,该变体在反照率图像和亮度图像的数值结果上均变差,这进一步表明了本文所提数据集对提升本征图像分解质量的的有效性。
7 结 论
提出了一个基于非局部图卷积神经网络的本征分解算法,引入的图卷积模块以显式的方式利用特征图中的非局部线索。为了克服现有数据集的 局限性,提出了一个新的高质量的本征图像数据集,其中提供了反照率图像和亮度图像的逐像素 标签。并且,本文数据集中在亮度图中考虑 了非白光光照,使得本文本征分解模型可以 更好地将输入图像中的材质颜色和光照成分分开, 特别是由漫反射表面之间相互反射所引入的光照效果。通过将不同方法在本文数据集与之前的数据集上分别训练并进行测试与对比,验证了本文数据集对提升本征图像分解质量的有效性。此外,通过将本文本征图像分解网络与之前的方法比较,在定量结果上实现了较好的结果,在视觉效果上有较大的提升。此外,通过将本文方法和其他两种前沿的本征分解方法的分解结果应用于一系列图像编辑任务中,进一步直观地展示了每种方法产生的分解结果的质量及其应用价值。
在场景中有大面积的颜色变化剧烈的复杂纹理时,本文方法所产生的亮度图结果中仍存在纹理信息。这是由于在不利用几何信息的情况下,网络对由纹理产生的边缘和由阴影产生的边缘的区分能力有限。同时,由于将图像分解成为反照率图像和亮度图像所能支持的编辑任务有限,未来的工作中考虑将场景的几何信息、光照信息和材质信息进行联合估计或优化,提升分解的质量并支持更丰富的应用。
