文字知识图谱构建及应用
2022-02-25安波
安 波
(中国社会科学院民族学与人类学研究所,北京 100081)
0 引言
数千年来中华大地上诞生了很多不同的语言和文字,有些文字目前还在广泛地使用,如汉字、藏文等,也有些文字已经很少有人使用或濒临灭绝,如西夏文、金文等。这些文字对于研究中华民族的历史、文化、传统习俗和语言发展的规律具有重要价值。为了更好地保护和研究中华民族文字,且保护与挖掘这些文字的价值,近年来国家立项了多个与文字相关的重大文化科技工程,如“中华字库工程”“语保工程”[1]等。 其中,中华字库工程是目前最为系统和完整地进行中华民族文字整理工作的工程。“中华字库工程”[2]汇集了包括中国科学院软件研究所、中版集团数字传媒有限公司、首都师范大学、北京中标中易电子信息技术有限公司等在内的国内从事文字处理的科研机构和公司,尝试利用信息化、数字化手段进行原始数据的采集、整理,建立准确的字际关系,形成标准的国际编码、字体文件、输入法、字符属性数据集等,并利用云计算技术将采集的成果数据对外提供字型云服务、属性云服务和输入法云服务,且基于这3 种服务提供成果字库和其他数据的输入、显示和属性查询服务。“中华字库工程”的研发建设,为研究中华文字的产生、发展和演变提供数据基础,是提高中国文化“软实力”的一项重要举措,对于中华文明的普及与传播具有重大的战略意义。目前,已经收集整理了包含楷书汉字、古汉字、少数民族语言等语种并针对每种文字形成了对应的字体文件、编码空间、字图,并针对每个字符收集整理了相对应的属性信息。迄今已有一些在线的文字资源库可以使用,如“在线新华字典”等。然而,中华字库工程的数据存储采用的是传统文件系统(字体、输入法、字图)、关系型数据库(属性),不同类型的数据之间是隔离的,没有建立合理的关联,致使这些文字资源主要以现代汉字为主,缺少古汉字、少数民族文字的相关内容。因此无法很好地进行数据融合、查询、挖掘与推理等工作,不利于对文字整理成果数据的深入研究与应用。
知识图谱(Knowledge Graph)[3]是一种语义网络(Semantic Network)[4],最早是谷歌于2012年提出的且应用于搜索引擎[5]、推荐[6]等,取得了很好的效果。知识图谱使用结构化的网络结构描述概念、实体(Entity)及关系(Relation),实体之间通过关系建立关联,形成图状结构的知识结构,更加接近人类对世界的认知形式,提供了一种更好的组织、管理和使用知识的方式。知识图谱技术是指知识图谱的构建与应用的技术,融合了认知计算[7]、表示学习[8]、查询与推理等技术的交叉方向。知识图谱的构建通常包括本体(Ontology)[9]设计和知识抽取两个阶段。其中,本体定义了知识图谱的实体、关系的类型等信息,限定了知识图谱的范围,本体设计是由领域专家与知识图谱专家人工设计的。而知识抽取则主要基于模型、规则等计算机技术实现。知识抽取常见的任务包括知识表示与建模、知识表示学习、实体识别与链接[10]、实体关系识别[11]、事件抽取[12]等。为了进一步提升知识图谱的覆盖率,知识补全和知识融合[13-15]也是常用的技术。典型的知识图谱的应用有知识查询与推理、智能搜索、知识问答、对话系统等。
鉴于知识图谱能够支持知识的快速查询与推理,本文将针对中华字库工程研发建设中存在的问题,采用知识图谱的方式对字库工程的成果数据进行组织,挖掘数据中的知识,形成中华字库成果数据知识图谱,利用图数据库进行数据的存储,并基于实体识别、关系抽取和三元组抽取等步骤,构建一个包含60 万个实体、1 000 万个三元组的大规模文字知识图谱。在该文字知识图谱的基础上,构建智能问答系统[16],回答用户以自然语言形式提出的问题。
1 中华文字知识图谱构建
1.1 文字数据
通过前期积累,整理形成了超过50 万字的成果字符,以及这些字符对应的编码、字形、输入法、扫描图档、属性等信息。在很大程度上满足了新闻出版行业的文字标准化的迫切需求,加快了国家尤其是民族地区的信息化进程,增强了国家文化“软实力”。
然而,目前这些数据以字体文件、文本、关系数据库等不同的形式进行存储,数据之间没有建立关联,限制了成果数据的进一步挖掘和应用。针对该问题,本文提出使用更为先进的知识图谱的方式进行数据的重新组织和存储,建立数据之间的关联,为后续的字库数据挖掘和应用提供支撑。
1.2 知识图谱本体设计
本体是知识图谱的知识表示的基础,是知识图谱的抽象概念集合,是某个领域的概念框架,如“人”“地”“事件”等。知识图谱是在本体基础上的具象,在本体中通常包含实体概念和关系概念。如在人物知识图谱中,“人”是一个实体概念,“姚明”则是一个具体的实体。“妻子”是一个关系的概念,三元组(姚明,妻子,叶丽)则是关系“妻子”的一个具体实例。知识图谱最终是由三元组构成。三元组包含头部实体、关系和尾部实体3 个元素。在前面的例子中,“姚明”为头部实体,“妻子”为关系,“叶丽”为尾部实体。通过这些三元组可以构建实体之间的相互关系,支持查询、推理等操作。
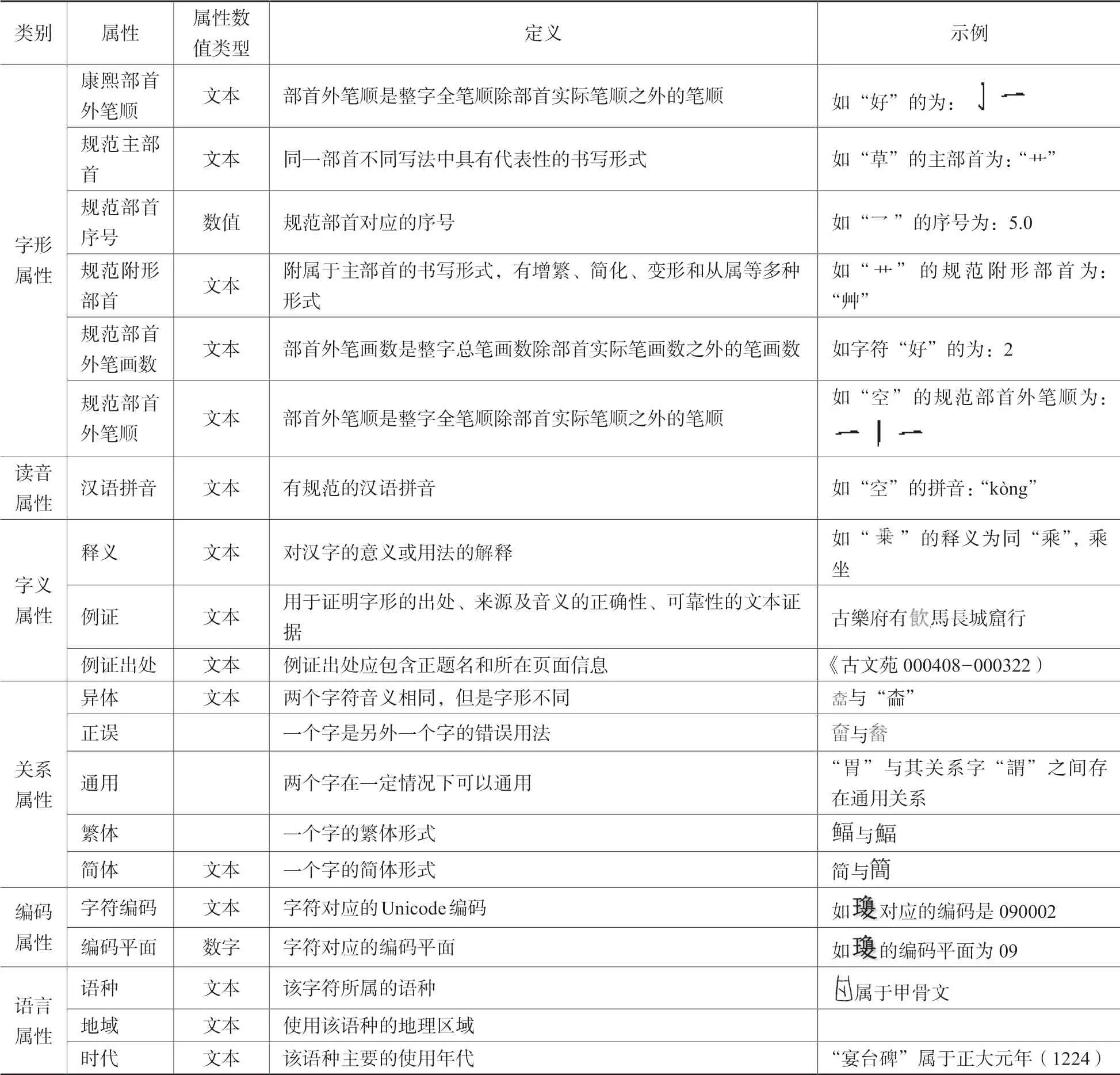
中华文字知识图谱主要涉及字符、语种、地域和文献四类实体。在中华文字知识图谱中对关系和属性不做严格地进行区分,均采用三元组的方式进行存储。如字符编码属性和字符之间异体关系均采用三元组进行存储。关系和属性在该知识图谱中不进行区分,均以关系的形式进行存储和使用。目前,中华文字知识图谱中的主要关系类型如表1所示。同时,中华文字知识图谱不仅针对现代汉语,而且针对古汉语、傣文、西夏文等少数民族文字。中华文字知识图谱包含的部分语种见表2。

表1 中华字库关系/属性列表

表2 中华文字知识图谱包含的部分语种
1.3 知识图谱构建
基于上述本体定义的实体和关系类型,本文设计信息抽取系统实现从文本、图片、字体、数据库等信息中抽取文字对应的实体、关系和三元组构建知识图谱。文字知识图谱抽取的整体框架如图1所示。该系统主要包括数据预处理、实体抽取、关系抽取、实体链接和三元组抽取。主要对不同模态的数据进行数据处理,形成能够进行统一信息抽取的数据形式。然后再进行实体和关系的识别。同时,由于相同实体在不同的数据中有不同的模态和形式,需要对这些实体进行链接,实现实体的归一化处理。如利用字符编码将文本形式、图片形式和字体文件中的同一字符关联起来,便于后续的三元组抽取。

图1 文字知识图谱构建流程
续表
利用上述信息抽取系统,本文抽取了超过60万个实体和超 1 000 万个三元组,构成了当前最大规模的中华文字知识图谱。本文利用Neo4j构建三元组数据,形成可视化的数据查询接口,具体的示例如图2所示。

图2 以“人”作为部首的字符
2 基于文字知识图谱的智能问答
知识图谱将知识通过关系串联起来,形成网状结构,能够支撑很多智能应用,典型的应用主要包括智能问答、智能客服、推荐系统等。本文在文字知识图谱的基础上构建了一个智能问答系统,实现了在文字知识图谱上的智能问答,并实现了支持自然语言的方式进行文字相关关系/属性的查询。该系统的整体架构如图3所示。主要包括实体抽取、意图识别、知识图谱查询与推理和回复生成4 个模块。本文基于这4 个模块,利用中华文字知识图谱实现一个较为完整的智能问答系统,以完成针对该知识图谱的自动查询,满足该知识图谱的基本查询需求。

图3 基于文字知识图谱的智能问答
2.1 实体抽取
实体抽取模块的主要任务是从用户提出的问题中准确地识别实体词。在文字知识图谱中,实体词主要为字符、语种、地域和文献。本文基于Bert+CRF[17](预训练语言模型+条件随机场)实现实体识别。该模型将实体识别转换为序列标注问题,通过给问题中的每个字预测不同的标签实现对实体的识别。具体的例子如图4所示,其中“S”表示为一个实体字,“O”表示为其他字符。该模型能够基于大规模预训练语言模型实现。预训练语言模型的微调机制使得该模型具有更好的鲁棒性,所需要的标注数据也更少,尤其适合于文字知识图谱这种缺少标注数据的模型。

图4 实体识别示意
2.2 意图识别
意图识别是在实体识别的基础上,判断用户的意图。如图4 中的问题对应的意图是“异体字”。本文将意图识别建模为一个分类问题,将用户的问题分类为不同的关系/属性的查询需求。本文利用Bert+FC[18](预训练语言模型+全连接分类器)作为文本分类模型,用于实现意图识别。
2.3 知识图谱查询与推理
当识别了用户问题中的核心实体和意图后,可以生成知识图谱的查询命令,实现单跳和多跳的查询。所谓“单跳”指的是通过一次关系查询操作即可满足用户的需求。如图4 的问题可以通过查询目标字的所有异体字来满足用户查询。“多跳”是那些不能通过单一的关系来满足用户需求的问题,如问题“字符顸对应语种有多少字?”需要通过“语种”和“字符列表”两个关系来满足用户查询。在多跳场景下识别用户的意图后与知识图谱中的关系组合进行相似度计算,最终得到查询的关系组合。本文基于SentenceBert[19]模型实现意图与关系组合的相似度计算。该模型在大规模语言模型的基础上计算句子/短语/词汇之间的相似度,能够充分利用上下文信息。
2.4 回复生成
基于上述模块,系统完成对用户问题的理解和知识的查询与推理,得到用户所需要的信息。为了能够以更自然的交互方式与用户进行问答交互,本文实现了基于规则结合文本生成模型T5[18]进行回复生成。
3 结语
本文在中华字库成果数据的基础,采用知识图谱技术和数据组织方式构建了一个大规模的中华文字知识图谱。文字知识图谱涵盖了楷书汉字、古汉字、少数民族文字等多种语言文字,包含了字形、字音、字义、编码空间等多种模态和类型的属性数据。本文采用实体抽取、关系识别、三元组抽取等技术构建了知识图谱。并利用深度学习在文字知识图谱的基础上实现了一个智能问答系统,满足了用户对文字知识查询的需求。
