心衰专病数据库的建设与应用
2022-02-25宓林晖潘常青袁骏毅李榕沈兰汤钦华
宓林晖, 潘常青, 袁骏毅, 李榕, 沈兰, 汤钦华
(上海市胸科医院(上海交通大学附属胸科医院), 上海 200030)
0 引言
随着我国人口老龄化程度的不断加深,心衰患病率也逐渐增长。据最新流行病学调查结果显示,在2005年至2020年的15年间我国心衰患病率增加了44%,心衰患者增加了约900多万人[1]。为提升心衰患者的预后和生存质量,我国开展了大量关于心力衰竭的临床科研工作,但在科研数据采集方面仍存在一定困难。许多数据由科研人员人工填报而并非客观获取,不仅增加医疗机构的劳动负荷,而且数据质量也有待提升[2],因此,如何通过信息技术手段为临床科研提供数据支撑显得至关重要。本研究以上海市胸科医院为背景,通过构建标准化、高质量的心衰专病数据库,为科研人员提供丰富的临床及科研数据资产,并能满足临床多样化的科研数据采集需求。
1 系统架构
心衰专病数据库以行业的标准规范为指导,利用多源异构数据采集、分布式存储、数据抽取、转换、治理等信息技术手段,统一集成心衰患者的临床数据样本,建立结构化、标准化的专病数据库,实现专科数据的互联互通,系统总体架构见图1。

图1 系统架构设计
为了实现不同系统间异构数据源的采集、存储、加工,且保证临床业务系统自身的稳定和独立,本系统采用分布式SOA(Service Oriented Architecture,SOA)架构,从上到下分共为5个部分,分别是业务数据层、采集汇聚层、数据资源与治理层、应用支撑层和应用服务层。业务数据层中包括医院信息系统(Hospital Information System,HIS)、电子病历系统(Electronic Medical Record,EMR)等临床业务系统,以及生物样本库、基因组学库。采集汇聚层采用企业服务中心(Enterprise Service Bus,ESB)方式与各业务系统对接,既兼容了多源异构数据的采集,又保障了各系统自身的稳定性、安全性[4]。数据资源与治理层则对采集到的数据进行二次加工,利用患者主索引、自然语言处理(Natural Language Processing,NLP)结构化、数据质控等措施,生成高质量、标准化的心衰专病数据中心。应用支撑层提供统一认证、数据展现、数据分析、数据检索等服务,以API的方式供前端调用,支持JSON、XML等多种格式。应用服务层则根据不同的业务需要,为临床应用、科研分析、质量管控等业务场景提供了多样化的技术与数据支撑。
2 关键技术
2.1 分布式并行处理数据库
心衰专病数据库目前已存储数据总量约为1.46TB,后续每年增长量约在0.27TB,为满足大量临床数据实时查询处理的需求,采用大规模并行处理的MPP(Massive Parallel Processing,MPP)分布式并行数据库,其支持行存储与列存储,提供PB级别数据量的处理能力[3],数据库架构如图2所示。
它有别于传统数据库中二维表的存储结构,将数据按照用户需求划分为多个片段,存储于不同的数据节点中,节点之间通过网络通道实现通讯交互。当业务应用发起请求后,首先到达协调节点,该节点根据查询类型、数据分布方式、数据规模等进行自动评估,生成分布式执行计划,并下发到各个数据节点执行。在生成计划时,分布式并行执行引擎会依据数据分布情况,合理利用集群资源,产生最佳的查询路径,从而避免无意义的数据处理[4]。单个数据节点收到计算任务后,利用现代计算机的多核计算理论,采用流水线方式对数据库常用算子进行并行处理,如扫描、关联、排序、聚合等,从而实现了高度并行的计算能力[5]。同时,通过全局事务管理器生成全局事务ID,实现全局时间戳分配,从物理上保证了事务ID的有序性。

图2 分布式并行数据库架构
2.2 心衰专病数据模型
传统科研数据的采集主要以研究目的为主导,因此大多采用自定义形式构建模型抽取数据,导致数据标准的不统一,在后续开展多中心研究时容易产生共享障碍。为解决这一问题,本研究参考了国内外行业标准和规范,通过建立标准化、动态化的心衰数据模型,使临床数据在存储、发布、交换过程中遵循统一标准,保证数据的可比性和一致性[6]。心衰数据模型由通用数据集和疾病特征数据集组成,通用数据集是指普遍适用于各类心血管疾病的数据项,疾病特征数据集则用于描述心衰专病所独有的数据项。这种构建方式不仅便于对其他心血管病种的横向拓展,同时也支持对心衰专病数据维度的纵向延伸。心衰数据模型构建技术路线如图3所示。

图3 数据模型建设技术路线
在制定通用数据集时,选取了观察性健康医疗数据科学与信息学组织(Observational Health Data Sciences and Informatics,OHDSI)发布的通用数据模型(Common Data Model,CDM),并在此基础上参考国内相关行业规范,如中国卫生信息数据元值域代码WS364.X-2011、电子病历基本数据集WS445.X-2014,对数据元、值域等,并进行本地化定义。构建疾病特征数据集时,以相关疾病诊疗指南为指导,对医院现有疾病队列数据进行分析归纳,梳理出心衰专病的特征指标,如特征性心电图结果、心脏生物学标记物等。最终,将通用数据集与疾病特征数据集两者相结合,汇总构建成心衰专病数据模型。
2.3 基于NLP的数据处理技术
在临床数据中,高质量的结构化数据较为有限,大多用于记录患者的基本情况、诊断、医嘱等重要信息,其余则多是以文本为主的非结构化数据,如主诉、现病史、检查报告等[7]。针对这一数据特点,建立了一套以自然语言分析为基础的数据处理系统,用于将大段自然语言转化为标准字段和阈值。以心脏超声报告为例,处理流程如图4所示。
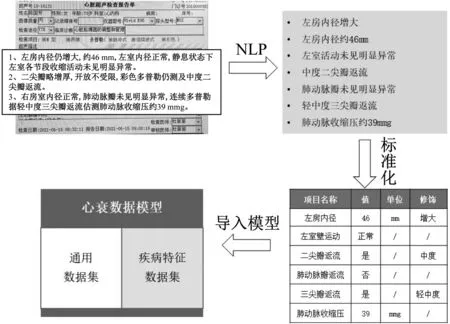
图4 心超报告NLP处理流程
首先,基于NLP(Nature Language Processing)技术对心超报告中的非结构化数据进行处理,通过分词、句法分析、词性标注、命名实体识别等环节,对大段文本进行预处理,得到较为干净的文本内容[8]。如超声描述中“左房内径仍增大,约46 mm”,经预处理后,转化为“左房内径增大,左房内径约46 mm”。其次,基于NLP技术耦合集成机器学习算法,将预处理后的文本拆解为项目名称、值、单位、修饰等字段,解决传统NLP技术在医疗领域使用效果不佳、拓展性不足的问题[9]。在此基础上,利用术语映射引擎对已结构化的数据进行标准化转换,如诊断编码与ICD-10映射,临床所见、医疗操作、微生物等与SNOMED-CT映射等,为后续数据的利用和共享打下基础。最后,将标准化、归一化的心超报告数据导入专病数据模型的疾病特征数据集中,实现心衰患者的数据展示,满足科研数据分析需求。
3 应用效果
目前,本研究已完成心衰专病数据库建设,共纳入2015年至2020年间4388名患者的数据,包含5192人次的就诊记录、799 423条用药信息、93 180份检验检查报告、74 971份病历文书等。并且形成了标准化的心衰专病数据模型,该模型分为通用数据集和疾病特征数据集2个部分,其中通用数据集包括基本信息、就诊资料、危险因素、诊疗费用等共14个模块498个数据项,疾病特征数据集则纳入了心脏超声、CRT治疗2个模块共95个数据项,如表1所示。

表1 心衰专病数据模型
在专病数据库中,医生可选择不同的研究变量,自由组合进行检索,检索范围包括各类病历文书、医嘱、检验检查报告、随访记录等内容。此外,为进一步提高可及性,该数据库还支持直接利用自然语言作为筛选条件,通过NLP技术自动解析临床研究者的筛选条件,融合不同来源的知识进行概念的语义扩展,并使用关联规则、贝叶斯推理等技术对临床数据进行挖掘,尽可能筛选出跟医生所述条件相符或接近的患者。
4 结论
在传统的临床科研过程中,患者病例数据的采集通常要花费医生大量的时间和精力,而且人工手动的方式效率低下,容易造成记录错误[10]。本研究结合大数据及自然语言处理技术,以患者为中心对多源异构临床数据进行整合,形成完整的、标准化的、高结构化的心衰专病数据库,为临床科研提供丰富的基础数据支持。该数据库的建立不仅提高了临床科研人员的工作效率,而且有效避免了人工采集所带来的失误,进一步保障了科研数据质量。未来,随着科研要求的不断提升,将对心衰专病数据模型进行持续优化和扩展。在数据利用方面,后续将以数据库中的海量数据为基础,结合深度学习、知识图谱等人工智能技术,开展心衰治疗和预后风险预测模型的研究,以实现心衰预防、诊断和治疗的智能化,从而全面提升临床的救治能力和技术水平。
