基于三维图像特征的矸石含煤率在线检测方法
2022-02-25邱照玉窦东阳刘钢洋
邱照玉,沈 宁,窦东阳,刘钢洋
(1.中国矿业大学 化工学院,江苏 徐州 221116;2.宁夏煤业洗选中心,宁夏 银川 750409)
随着“工业4.0”的热潮及“中国制造2025”的提出与实施,自动化和人工智能在矿物加工领域中得到广泛关注。选煤后矸石产品的矸石含煤率是选煤厂生产的关键指标之一。矸石含煤率高则选煤精度低,导致精煤产量下降,降低了企业的经济效益,而且浪费了运输资源,增加了生产成本,更浪费了稀缺的煤炭资源。
一般矸石含煤率的测定是通过浮沉实验,过程中需要人员大量采样矸石,消耗人力物力,且检测过程耗时过长,使得检测滞后。为此需要一个新的检测方法来快速、准确地检测矸石含煤率。
目前基于机器视觉的图像处理技术逐渐步入成熟,已经在智能化选煤领域中得到运用。刘金平等[1]提出了一种基于尺度不变特征变换(SIFT)和改进的卡尔曼滤波的在线泡沫速度场测量方法,该方法可以准确获得流到浮选池刮板的各种泡沫的速度场。林小竹等[2]利用分水岭算法有效分割煤泥浮选泡沫图像,计算出各个煤泥气泡的横截面积、周长、形状等物理特征参数。何敏等[3]采用自动阈值法分割煤矸石图像并二值化,提取其灰度与灰度共生矩阵等特征,采用支持向量机SVM实现煤与矸石的自动识别。同样鲁恒润等人[4]提出基于BP神经网络的纹理和灰度特征的综合分类方法来提高煤与矸石的识别率。Aldrich等[5]使用机器视觉系统来测量传送带上煤的粒度分布。张泽琳等[6]提出一种将对比度受限自适应直方图均衡法(CLAHE)和SUSAN边缘检测算法相结合的方法来检测煤堆图像中的煤粒边缘,又结合图像识别和神经网络对煤质进行分析,包括煤粒质量预测、煤堆粒度组成预测、煤堆密度组成预测和煤堆灰分预测,并建立煤粒图像识别系统[7]。窦东阳等[8,9]详细说明了在原煤外表面干燥、原煤外表面潮湿、外表面覆盖干煤泥和外表面覆盖湿煤泥条件下煤和矸石的图像识别。沈宁等[10]研究了表面条件混合时煤与矸石的图像识别。王家臣等[11]研究了不同光照度下煤矸图像的灰度及纹理特征对煤矸识别的影响。受现场操作人员和上述成果的启发,提出利用机器视觉代替人眼,对矸石含煤率进行快速检测的方法。
1 二维图像分割与特征提取
矸石含煤率是指矸石胶带中煤的重量占所有重量的百分数,本质上为一个质量指标,考虑到通过单目相机提取的特征均为二维特征参数,在判断立体的混合状态下的煤与矸石的含煤率会导致偏差偏大,所以在单目相机旁边增加双目相机用于提取图像的高度信息,在原有二维特征参数中增加三维特征参数,以提高模型预测的准确度。
1.1 图像分割
为了从图片中分割出胶带上的煤和矸石,采用了基于Hessian矩阵的多尺度图像分割算法[12]。首先,使用对比度受限的自适应直方图均衡化(CLAHE)恢复图像的边缘信息,用最小最大值滤波器来减少图片的无关信息;然后通过基于Hessian矩阵和Gaussian函数的多尺度线性滤波器获得图像的边缘强度;最后,使用双阈值运算和形态学运算获得图像的边缘,并通过分水岭分割获得各颗粒区域。
1.2 二维特征提取
提取分割区域的尺寸特征用于预测煤和矸石的体积。尺寸特征包括投影面积、周长、最小外接矩形的长和最小外接矩形的宽。其中,获取颗粒区域的最小外接矩形是采用王伟星[13]提出的方法,该方法基于简单的旋转不变性原理,适用于涉及固体颗粒如压碎的骨料颗粒的应用中。利用拍摄带有标尺的图片,计算图像中每个像素的面积和边长,用累加的方式计算投影面积和边长特征。
煤矸石在不同密度下亮度和颗粒质地都会不同,因此使用灰度图像的均值、方差和偏度作为灰度特征,使用灰度共生矩阵(GLCM)的特征来描述图像的灰度空间相关性和亮度的变化,提取了灰度共生矩阵的对比度、相关性、能量、同质性和熵[7,14]这五个特征。Tamura纹理适合于人的视觉感知,其特征更加直观显眼,所以提取了Tamura纹理的粗糙度、对比度和方向度[7,15]这三个特征。
将灰度特征、灰度共生矩阵特征和Tamura纹理特征作为分割区域的密度特征来表征煤和矸石的密度。本文使用的尺寸特征和密度特征见表1。

表1 煤与矸石的图像特征
双目相机与普通单反相机相比,成像质量低,图片较为模糊,如图1所示,左侧为单反相机成像图,右侧为双目相机成像图,不适宜提取图像的均值、偏度以及粗糙度等特征,所以仍利用普通单反相机拍摄的图片进行图像分割和二维特征提取。

图1 单目图像(左)与双目图像(右)
2 第三维特征提取
2.1 双目匹配算法
双目立体匹配SGBM算法是一种半全局匹配算法,由Hirschmuller[16]等学者提出,SGBM算法以互信息为基础,类似于全局二位平滑度约束算法的核心是通过两个单张图像的信息阈(图像的分割基准)H1、H2和这两张图像的联合信息阈H1,2进行定义互信息MI1,2的任务,互信息MI1,2则为算法的基础,可用具体公式定义:
MI1,2=H1+H2-H1,2
SGBM算法的关键步骤包括:
1)步骤1:逐像素匹配计算。在此步骤中可以用函数p(xi,yi,IL,IR)来表示一对双目图像中,左右两张图像内任意两点为同名像点的可能性,函数具体公式可表示为:
式中,xi、yi分别表示左右两张图像任意两个在相同扫描线上的像点;IL(xi)为左边图像在不同扫描线上的一系列像点的灰度特征信息;IR(yi)则为右边图像在不同扫描线上的一系列像点的灰度特征信息,这些信息能够使用采集样本像点进行线性内插差值的方法得到。
2)步骤2:图像边缘约束。将二维约束匹配运算通过目标点图像边缘约束可以实现扫描线上一维相关计算。
3)步骤3:视差计算。视差计算通过迭代的方式得到。首先,用随机的视差影像来纠正右影像,然后进行匹配,生成新的视差影像[17]。
4)步骤4:误匹配的剔除。左右影像同名点匹配完成后,利用右影像中的点去匹配左影像中的同名点。如果两次匹配得到的视差不相同,则视为无效匹配。
利用SGBM算法对双目相机的左右目图像进行匹配计算即可得到包含高度信息的深度图,3D可视化后的深度图像如图2所示,其中颜色越浅代表高度越高,从深度图可以直观地看到图像的第三维特征,通过对深度图的分割计算即可得到图片的三维特征参数(SD)。
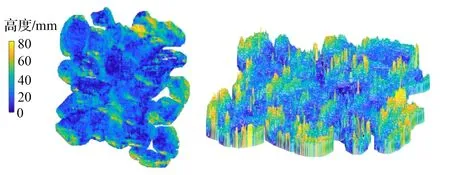
图2 3D可视化深度图
3 PSO-SVM方法
支持向量机理论是由Vapnik[18]等人首先提出的。以统计学理论为基础,在最小化样本点误差的同时,最小化结构风险,提高了模型的泛化能力,且没有数据维数限制。有效避免了在其他学习方法中存在的“过学习”的情况发生。支持向量机在分类识别和非线性回归方面都有着广泛的应用。由于支持向量机的输入参数集(核参数γ,惩罚参数C,终止训练误差e)会影响特征空间的框架和分类的成功率,因此在应用支持向量机之前必须对输入参数进行优化。手动调节这些参数不仅耗时耗力,往往未必能够得到最优参数。利用PSO优化SVM的目的就是通过PSO算法对参数寻优。粒子群优化算法(PSO)使用粒子群在目标函数的解空间中搜索最优解,粒子群优化算法已在各个领域中被用于优化支持向量机模型,进而形成PSO-SVM算法[19,20]。
SVM读取训练数据后,随机生成一组向量作为初始坐标,并根据该坐标进行训练,并计算误差的均方差,并将均方差折算成适应度,然后根据PSO算法搜寻更好的参数值重新训练,直至适应度满足终止条件,终止迭代输出最优参数,得到最优SVM模型。具体流程如图3所示。
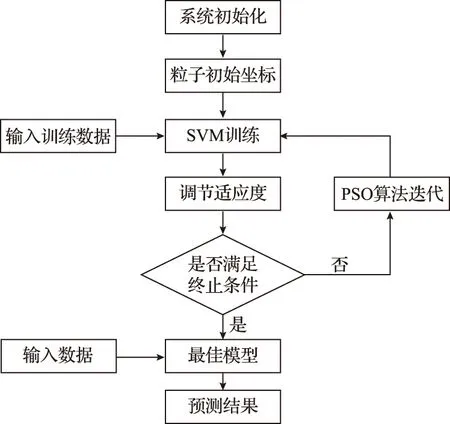
图3 PSO-SVM训练过程流程图
4 矸石含煤率检测步骤
基于图像分析和PSO-SVM的矸石含煤率检测流程如图4所示。首先对样本进行拍照,得到样本的单目图像和双目图像,并通过浮沉实验测量样本的矸石含煤率实际值。然后,通过单目图像利用图像分割技术,根据图像边缘将图片分割为各颗粒区域。将各颗粒区域进一步分类为矸石区域、煤区域和无用的胶带区域,删除胶带区域并计算提取出其他区域的15个二维特征参数。通过深度图提取图像的三维特征参数高度比(SD),最终提取包括二维特征参数在内共16个特征参数。
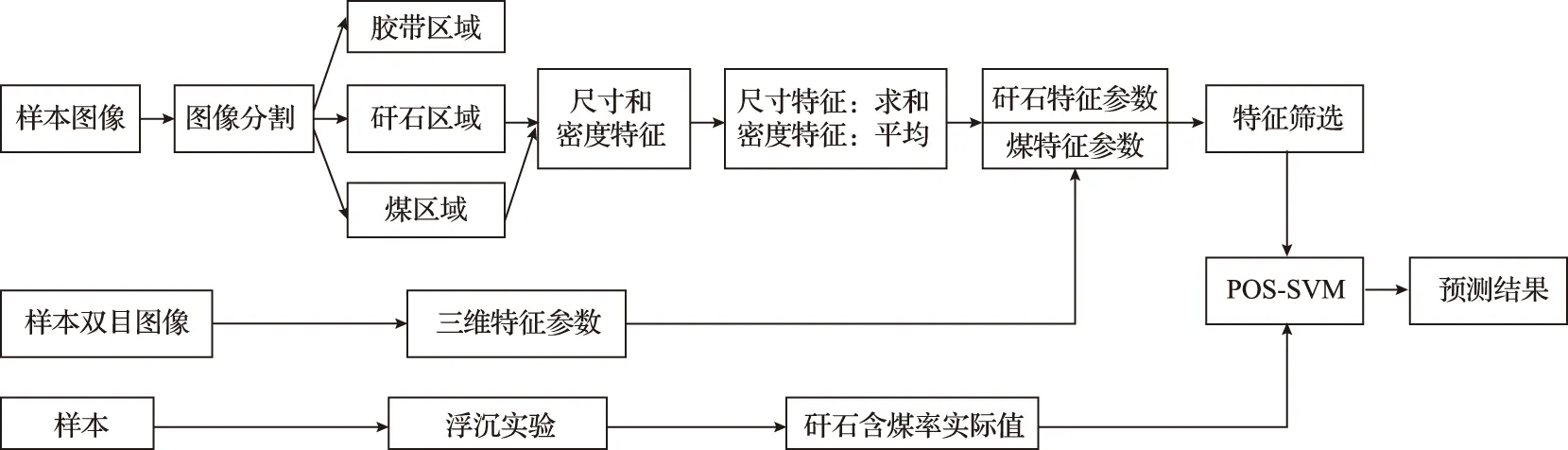
图4 基于图像分析和PSO-SVM的矸石含煤率检测流程
由于支持向量机的输入参数过多会导致模型泛化能力不佳,所以在建模之前需要从最终特征参数中筛选出最优输入参数,再通过PSO-SVM算法建立最佳检测模型。
5 矸石含煤率实验
5.1 实验过程
使用图5所示试验台进行矸石含煤率的检测实验。
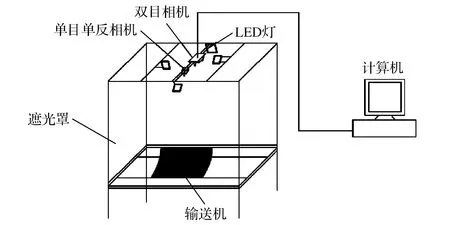
图5 矸石含煤率实验台
实验样品来自红柳选煤厂,从浅槽分选的产品胶带上采集实验样品。从现场胶带中共采集600kg样本,分选过后的物料经过初筛,煤矸粒级的范围为25~100+(mm),仅保留400kg可用样本,经过缩分混合后,保留实验样品约120kg,制备成51份样本并依次放入胶带中,在相同的照明环境下采集相应样本的单目图像和双目图像,部分样本图像如图6所示。图片采集完成后,通过浮沉实验获得各样本矸石含煤率的实际值。将单张图片上的煤和矸石放入密度为1.9kg/L的重液中,分别捞出悬浮于上层的煤和下层的矸石,晾干后分别称重,用煤的质量除以煤矸总质量即为矸石含煤率。矸石含煤率的部分结果见表2(GHM列)。
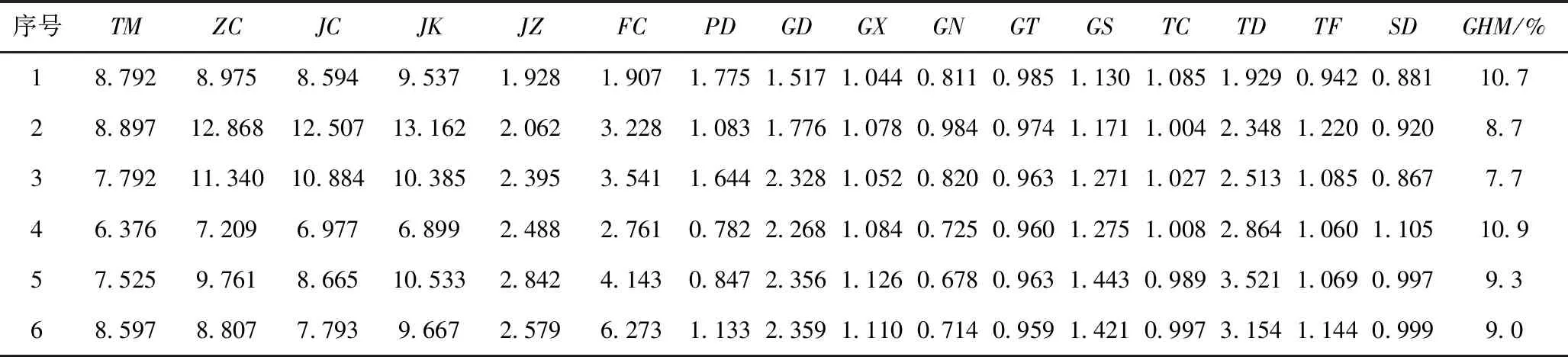
表2 图像特征参数示例

图6 部分样本示例
样本图片进行图像分割后的结果如图7所示,其中1、2和6为煤粒区域,3和4为胶带区域,5表示矸石区域。对分割后的图片进行特征提取,对分割后的图片进行特征提取,计算除胶带区域3和4以外的各区域,通过各个特征提取算法提取出每个分割区域尺寸特征参数和密度特征参数。对于尺寸特征参数,将同一类别区域的每个特征参数相加求和,例如投影面积特征参数,在此图片中,将区域1、区域2和区域6的投影面积特征参数相加,最终获得煤的投影面积特征参数;对于密度特征参数,则进行平均运算。之后,将从矸石区域获得的特征参数除以煤区域的特征参数,获得该图片的最终的二维特征参数。同理利用双目图像得到的煤和矸石的平均高度,用矸石的平均高度除以煤区域的平均高度可以得到三维特征参数高度比(SD)。

图7 煤矸石的图像分割
该图片的分割结果中出现了过度分割,如区域5。但是,特征提取过程的求和与平均运算使得过度分割对最终结果影响较小。表2为最终获得的特征参数示例,其中GHM表示矸石含煤率的实验值。
输入参数过多有时会导致支持向量机模型的拟合性较差,因此通过计算Pearson相关系数对最终特征参数进行筛选。根据Pearson相关系数计算公式:
如果Corr>0,表示特征与矸石含煤率为正相关;如果Corr<0,则为负相关。Corr的绝对值越大,表明该特征对预测矸石含煤率(GHM)的贡献越大。
将表2中列出的每个特征进行Pearson相关系数计算。计算的Corr结果见表3。排除Pearson相关系数极小的特征参数后,实验最终选择8个特征作为支持向量机模型的输入参数,见表4。

表3 Pearson相关系数

表4 模型的最终输入
为了验证最终输入参数的合理性,将16个特征完整输入PSO-SVM模型进行训练,设置对照组,最终对照组模型的预测结果见表5对照组,对照组的预测准确性明显低于平面特征模型和三维特征模型,在一定程度上验证了选取最终输入参数的合理性。图像的纹理特征多用于煤矸识别,对本文涉及的体积预测帮助较小。
5.2 结果与讨论
将51个样本集按2∶1的比例随机分为训练集和测试集。使用PSO-SVM算法在训练集上建立最佳模型,并使用测试集来验证模型的预测效果。
使用POS-SVM算法建立模型时,分别利用去除三维特征的训练集和完整的训练集建立平面特征模型和三维特征模型,以检验图像的高度信息对模型预测结果的影响。
两个模型的预测结果见表5,平面特征模型的最小相对误差达到4.1%,最大相对误差达到47.2%,平均相对误差为16.3%,而三维特征模型的平均相对误差仅为7.57%,远远小于平面特征模型,在增加图像的三维特征信息之后,模型预测的准确性提高明显。
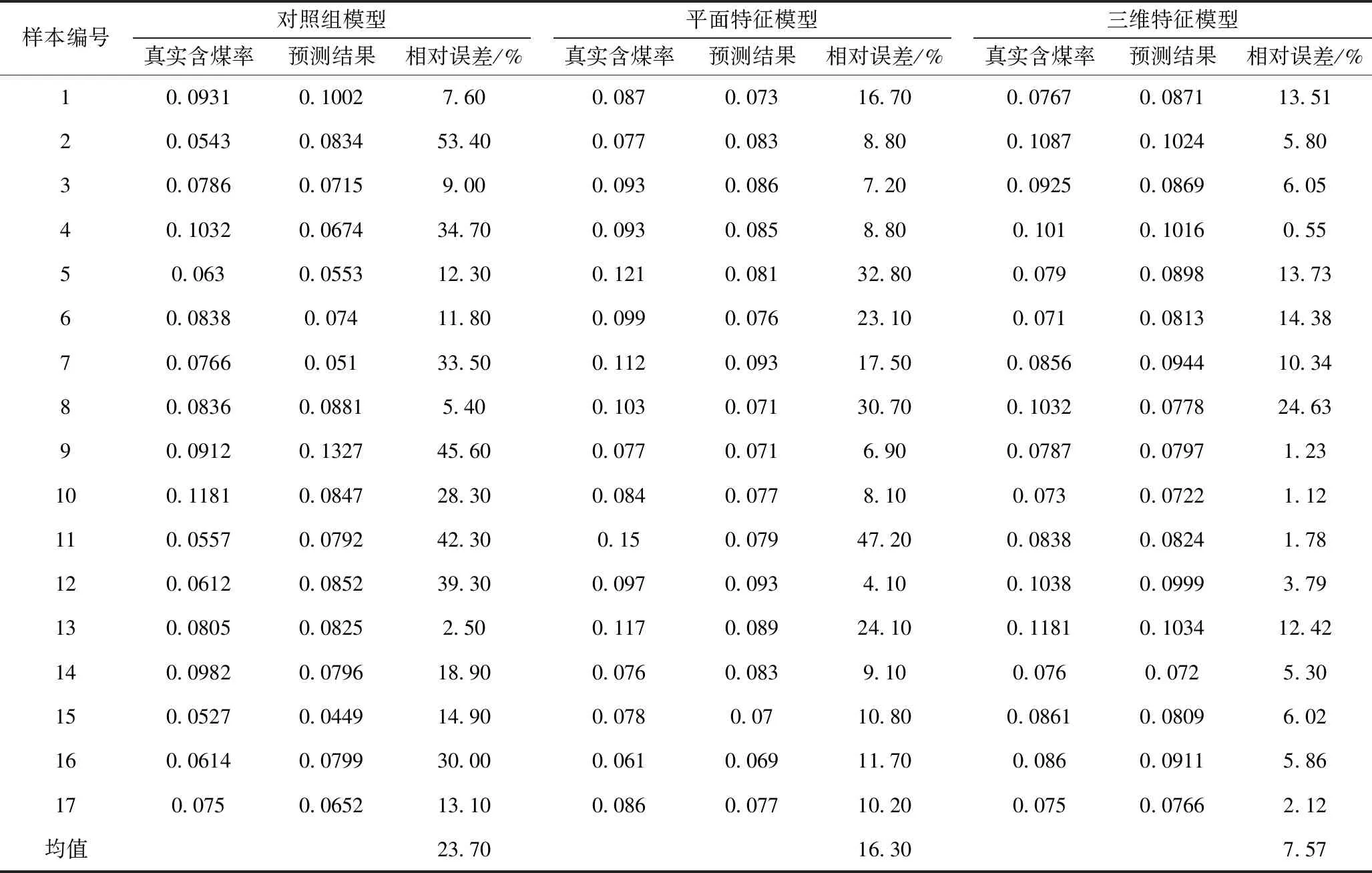
表5 模型预测结果
三维特征模型的预测结果最大相对误差为24.63%,最小相对误差0.55%,平均相对误差为7.57%低于现场规定的平均10%的需求,能够代替人工方法进行检测。
在图像分割期间,欠分割和过分割的现象将影响煤块区域的尺寸特征,尺寸特征作为模型的最终输入参数将影响模型的准确性。下一步可以改进图像分割方法,进一步提高模型的预测精度。
6 结 论
为了检测矸石含煤率这一现场迫切需要的指标,提出了一种基于图像处理和PSO-SVM算法的矸石含煤率检测方法:
1)首先,根据单目图像和双目图像分别提取图像的15个二维特征参数和1个三维特征参数。基于Pearson相关系数的特征选择法筛选出八个最优特征作为支持向量机的输入参数。同时通过设置对照组模型,验证了选取输入参数的合理性。
2)依据有无高度特征参数分别建立平面特征模型和三维特征模型,并依据检测集的测试结果评估了两个模型的性能。平面特征模型的平均相对误差为16.3%,远大于三维特征模型的7.57%。三维特征模型的性能远优于平面特征模型,引入高度特征参数极大提升了模型预测的准确率。
3)分析三维特征模型误差产生的主要原因为图像分割的精准度欠佳,导致尺寸特征参数的提取存在偏差,同时下一步将针对上述问题开展深入研究,提高预测的精度。
4)三维特征模型预测结果的平均相对误差能够满足现场需求,证明了该方法对矸石含煤率的测量是有效的,有助于突破选煤厂重要指标在线检测难的瓶颈,促进智能化选煤的发展。
