基于信用等级划分的医疗数据安全共识算法
2022-02-24陈友荣刘半藤王章权任条娟
陈友荣 陈 浩 韩 蒙 刘半藤 王章权 任条娟
①(浙江树人大学信息科技学院 杭州 310015)
②(常州大学计算机与人工智能学院 常州 213164)
③(浙江大学计算机科学与技术学院 杭州 310013)
④(美国肯尼索州立大学计算与软件工程学院 玛丽埃塔 30060)
1 引言
随着科学技术和通信技术的发展,智慧医疗凭借交互式医疗保健服务的特点,正逐渐成为未来医疗发展中不可或缺的一部分。其中,医院信息系统是智慧医疗的重要组成部分,可将电子病历、住院记录、处方、私人健康信息等医疗数据电子化[1,2],并具有管理便捷和高效的特点。但是目前医院信息系统大多采用集中式构架,且各个医疗机构建设自身的医院信息系统,不仅存在数据孤岛问题,同时还面临被人为篡改、隐私信息泄露、政府监管困难等安全问题,因此需要一种新的医疗数据共享安全技术。区块链技术是一种无限冗余去中心化的共享账本式分布数据库,具有不可篡改的特性,因此可将区块链引入医院信息系统中,实现去中心化和安全的医疗数据共享系统,解决患者的隐私信息保护、电子病历篡改的快捷可追溯等医疗数据共享问题[3,4]。在区块链技术中,共识算法是决定区块链能否有效应用的关键。但目前主流共识算法存在以下两个问题,较难直接应用到当前的医院信息系统:(1)虽然区块链能一定程度抵御恶意攻击,但恶意节点仍可以通过干扰区块共识的方式发动攻击,实现降低共识效率、窃取隐私信息等目的。由于医疗数据共识需要具有隐私性、高效性等要求,因此需要及时发现恶意节点,尽早降低恶意节点对共识的影响。但目前主流共识算法较少考虑恶意节点的攻击。(2)由于大量患者选择在白天到医疗机构进行治疗,因此医疗数据的区块共识需要较高的交易吞吐量和较低的交易时延。但目前主流共识算法的共识效率较低,无法应对医疗数据的交易。
因此针对上述问题,本文基于数据节点、共识节点和监管节点组成的医疗区块链模型,提出一种基于信用等级划分的医疗数据安全共识算法(Security Consensus Algorithm of Medical Data based on credit rating, SCA_MD)。本文的具体贡献如下:(1)针对数据节点与共识节点存在身份被盗用的风险,SCA_MD提出一种新颖的节点身份验证机制,从而实现快速验证。(2)考虑到现有节点的信用等级划分较难发现恶意节点,SCA_MD根据节点的当前累积信用值、历史信用等级、成为代表节点次数和提供无效区块次数等信息,提出一种基于海洋掠食者的自我优化信用等级划分算法(Self-optimizing Credit Rating Division algorithms,SCRD)实现等级划分,从而尽可能限制恶意节点共识权力,降低恶意节点对共识的影响。(3)考虑节点的类型情况,提出一种代表节点选举机制,并简化实用拜占庭容错(Practical Byzantine Fault Tolerance, PBFT)共识算法原有的一致性协议,且在视图切换协议中采用备用代表节点,以应对代表节点故障等情况,从而尽可能避免存在恶意节点成为主节点的同时提高共识的效率。因此SCA_MD不仅能快速完成恶意节点的剔除,避免恶意节点对区块共识所带来的效率降低等危害,而且降低交易时延,提高交易吞吐量,从而提高共识效率。
2 相关工作
目前,具有中心化、集体维护和不可篡改等性质的区块链广泛应用于智能金融、智能家居、智能医疗和智慧交通等领域[5,6]。Azaria等人[7]首次将区块链技术用于患者的医疗记录,提出基于区块链的医疗数据共享系统,从而保证数据共享的安全性。其中,该系统采用工作量证明(Proof Of Work,POW)共识算法保证区块共识的可靠性,但对节点的设备要求过高,且需要耗费大量的计算资源,因此部分学者研究应用到医疗领域的共识算法。有些学者侧重将主流的共识算法应用于分布式医疗数据管理系统和模型,如文献[8]为减少共识节点的算力负担,选择委托权益证明(Delegated Proof Of Stake, DPOS)共识算法来保证区块的一致性,并提出基于区块链的并行医疗系统框架,建立包括患者、医院和政府监管部门的医疗联盟链。文献[9]将PBFT共识算法应用于医疗区块链系统,提出一种联盟式医疗区块链系统,实现系统安全稳定的运行。但是上述文献[7—9]没有考虑主流共识算法存在一定的安全隐患,如难以应对“富者更富”与累积攻击等问题[10]。这些共识算法无法直接适用于实际的医疗领域,因此部分学者侧重改进主流的共识算法,建立医疗数据管理系统和模型,如文献[11]在权益证明(Proof Of Stake, POS)共识算法基础上,根据节点的恶意行为制定惩罚机制来限制其收益,并提出一种医疗数据的授权全框架,合理分配不同用户的访问级别。为了避免部分节点权力过大,文献[12]在PBFT共识算法的基础上,通过节点投票的方式选取主节点,并提出一种基于区块链的信息管理系统,提高节点数据共享的效率。但上述文献[11,12]中节点的信用值与投票计算方式过于简单且代表节点存在被恶意入侵的风险。同时部分学者侧重研究面向智能医疗领域的安全共识算法,如文献[13]提出权值认证拜占庭容错共识算法。该算法根据节点的身份认证情况设置不同的权重,并通过轮盘赌的方式随机选择节点负责当前区块的共识。文献[14]提出一种基于以太坊的未来可证明的疾病证明共识算法。该算法由医疗专家组担当矿工角色,验证并确认结果,最后提交到区块链中。文献[15]提出一种适用于医疗环境的身份证明共识算法。该算法在不同医疗机构中随机选择代表节点来实现区块的验证,并在节点间建立相互监督关系,防止代表节点被恶意节点攻击。虽然上述文献[13—15]可以在一定程度上有效降低恶意节点的攻击,但存在恶意节点难以识别和剔除、共识效率低等问题,难以安全且高效地实现医疗数据的共识。
3 SCA_MD共识原理
如图1所示,SCA_MD考虑由数据节点、共识节点和监管节点组成的医疗共识模型。其中,数据节点能够产生医疗数据,但是其算力无法实现快速区块共识。监管节点不产生任何医疗数据,但是其算力和防护等级较高,能够实现快速区块共识和监管医疗数据。共识节点能够产生医疗数据且其算力能够实现快速区块共识,但是其防护等级较低。在上述共识模型的基础上,SCA_MD的原理如图2所示。首先各节点经过节点身份验证,获得自身节点身份信息。其次节点根据其表现分情况,计算出各自的信用值,并结合其具体行为表现,通过SCRD算法将其信用等级划分为3类中的某一类,并获得其共识过程中相应的权利。接着,通过代表节点选举,确定代表节点和备用代表节点。最后,实现医疗数据共识。但是SCA_MD仍需要解决以下4个问题:一是如何考虑对共识节点和数据节点进行身份验证问题,实现节点的快速身份验证。二是如何结合节点的信用值等信息,合理安排信用等级划分与共识权限给予。三是如何考虑节点的累积信用值、节点类型等因素,实现代表节点选举,从而快速剔除恶意节点。四是如何选举代表节点和改进其共识机制,提高共识效率。这4个问题的具体解决如下。
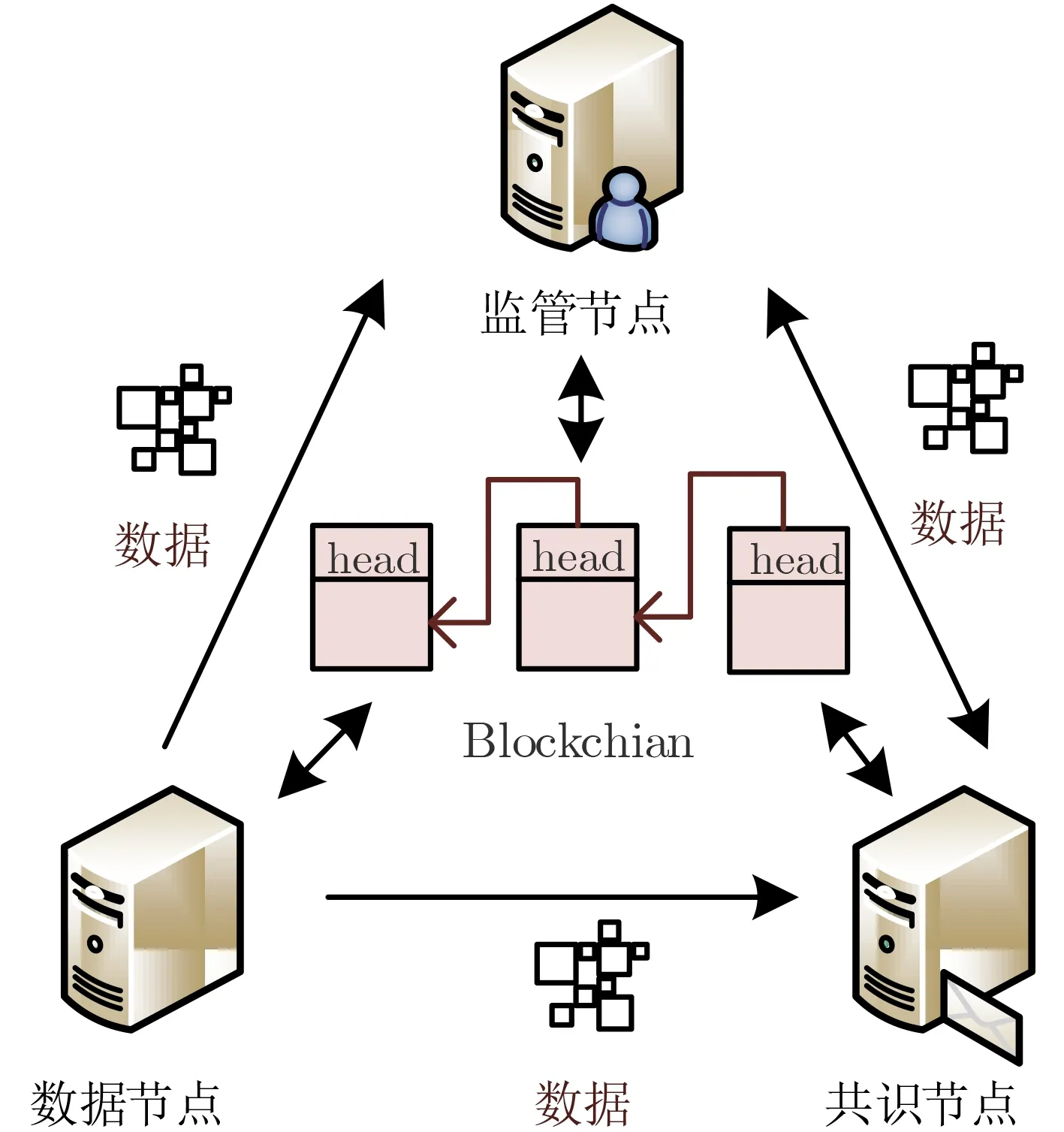
图1 医疗区块共识模型
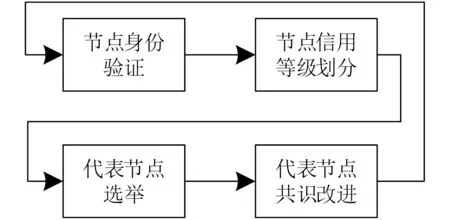
图2 SCA_MD共识算法原理
3.1 节点身份验证
由于数据节点和共识节点负责医疗数据的产生,因此这两类节点存在容易被恶意节点假冒的风险。SCA_MD提出节点的身份验证机制,通过随时间动态变化的验证组成员快速验证数据节点和共识节点。首先节点尝试与周围节点进行通信,若成功建立通信过程,则将成功通信的节点添加到可通信列表中,并从可通信列表中随机选择ϖ个节点作为实际通信节点,其剩下的节点作为备用可通信节点。同时,为保证验证组的可靠性,由代表节点随机挑选N个信用等级为good的节点与M个监管节点组成验证组。其中,已经入选成为验证组的节点在下次随机组合过程中将不会被考虑,直到遍历过所有可能的组合。针对共识节点和数据节点的身份验证描述如下:代表节点向验证组内的全部节点发送验证请求。其中,验证组中只要1个监管节点或n1个节点的可通信列表能够查询到该节点信息,即认为通过验证。若该节点通过验证,则表明该节点具有唯一性,该节点可以参与区块的共识流程。若未能满足上述情况,则该节点停止其参与区块共识的权利,并过一段时间重复上述验证过程直到完成该节点的身份验证。
3.2 节点信用等级划分
由于医疗数据包含医生根据自身经验所作出的医疗决策与医疗检查所产生的个人隐私数据,因此在选择节点来完成区块共识时需要综合考虑节点的历史行为,从而保证节点的可靠性。
3.2.1 奖惩机制
每当有区块成功上链后,根据节点的区块共识行为执行奖惩机制,通过式(1)计算每一个节点的累积表现分
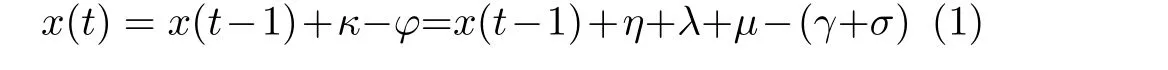
其中,x(t)表示当前时刻t的累计得分,κ表示当前轮的奖励分,φ表示当前轮的扣除分,η表示本轮区块共识成功的情况下,对代表节点投出赞成票的节点奖励其表现分,λ表示本轮区块共识失败的情况下,对代表节点投出反对票的节点奖励其表现分,μ表示对参与并完成节点身份验证的节点奖励其表现分,γ表示本轮区块共识成功的情况下,对代表节点投出反对票的节点扣除其表现分,σ表示本轮区块共识失败的情况下,对代表节点投出赞成票的节点扣除其表现分,且γ与σ的值都远大于η,λ和μ。
为增加节点参与区块共识的积极性和提供节点等级划分的评价标准,提出一种信用值模型,即
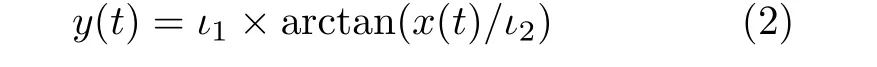
其中,y(t)表示当前时刻t的每一个节点累积信用值,ι1与ι2表示模型参数。
3.2.2 信用等级划分
在完成上述的节点信用值计算后,需要对节点进行等级划分。首先,代表节点采集具体包括当前累积信用值、历史信用等级、成为代表节点次数和提供无效区块次数等评估要素。定义如式(3)所示的节点信用等级与数值的对应关系,重新计算节点的历史等级数值
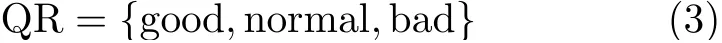
其中,QR表示信用等级集合。
由于代表节点需要处理大量的数据信息,而常规聚类算法[16]对半径等关键参数过于敏感,且需要通过主成分分析(Principal Components Analysis,PCA)和线性判别分析(Linear Discriminant Analysis,LDA)等算法进行特征降维[17],导致其聚类效果不够理想和算法运行时间过长,无法满足信用等级划分的实时性需求。海洋掠食者算法(Marine Predators Algorithm, MPA)[18]在整体优化过程中可划分多个阶段并模拟布朗运动的方式来避免陷入局部最优解,且采用模拟莱维(Lévy)运动提高寻找全局最优解的能力,但是其在优化过程中仅根据当前迭代次数实现不同的优化阶段,无法保证算法的收敛速度。因此改进节点间距离计算方法、判断半径的适应度值和不同优化阶段的切法方法,并提出一种基于改进海洋掠食者的自我优化信用等级划分算法(SCRD),实现节点信用等级的快速划分。
为了能更好地区分恶意节点,SCRD考虑到不同的评估要素所带来的影响,在计算样本间的差异距离时,设置不同的权重参数,从而使得恶意节点与正常节点间表现出明显的差异,具体公式为



在获得半径最优解的基础上,SCRD算法通过式(12)计算每个节点的评价值,从而将样本分别划分为bad, normal和good等级。当节点的信用等级为good时,代表节点给予其被选举权、投票权和身份验证权。当节点的信用等级为normal时,代表节点给予其被选举权和投票权。若节点信用等级为bad,则代表节点认为该节点为恶意节点,不给予其任何权利,从而避免其影响区块共识。当完成上述权利给予后,代表节点将节点的累积信用值和累积得分进行清除,开始新一轮的累积得分获取。
3.3 代表节点选举
由于医疗数据区块的共识存在时效性要求,因此SCA_MD通过节点选举的方式选择代表节点来达成区块共识,提高区块共识效率。在代表选举过程,需要执行代表候选节点确定和投票统计两个阶段。在代表候选节点确定阶段,上一轮的代表节点通过式(13)计算每个节点的得分,并从高到低选取e个节点成为代表候选节点。

其中,scorel表示第l个节点的得分情况。如果出现多个节点的得分情况相同,则随机选择一个节点成为代表候选节点。在投票统计阶段,为了在投票过程中加强对恶意节点的剔除,允许节点通过广播的方式投出赞成票与反对票。同时考虑到不同类型的节点所代表的重要性不同,节点通过式(14)采用不同的权重统计票数,获得投票结果。

3.4 代表节点共识改进
虽然通过代表节点来达成区块共识能够提高区块共识效率,但随着代表节点数量增加,医疗数据区块的共识效率会逐渐无法满足时效性要求,而且代表节点被恶意入侵的风险也会明显提高。因此在PBFT共识算法的基础上,SCA_MD改进一致性协议和视图切换协议,从而在保证节点可靠性的同时提高区块共识效率。在一致性协议的改进方面,SCA_MD从代表节点中选择信用值最高的τ(1<τ<<NRN)个节点组成主节点群,并通过随机的方式完成区块构建。而主节点群主要负责将预准备消息发送到其他代表节点,统一收集其返回的认可消息。若主节点群收到的认可消息超过2f个(f为NRN的1/3),则统一发送认可消息到其他代表节点进行验证。若其他代表节点的验证通过,则共识达成,并将区块写入到全局主链,否则重新执行协议。而在视图切换协议的改进方面,当代表节点出现问题时,SCA_MD立刻从备用代表节点中随机选择节点进行替换。
4 算法设计
本共识算法在尽可能提高共识效率的同时避免恶意节点对区块共识的影响,如表1。其中,令全网节点数量为θ,数据节点和共识节点数量为c,获得选举权节点数量为b和候选节点数量为e。在SCA_MD中,每一个节点的伪代码如下所示:首先初始化全网节点数量θ等关键参数;然后,本节点广播自身投票信息。若本节点收到全部节点的投票信息,则根据投票结果,选择NAN个代表节点,并将选择结果进行广播;其次,当本节点无法成为代表节点时,本节点仅从网络中同步区块信息,并根据网络要求进行投票,否则本节点对c个节点执行节点身份验证机制,确定节点的身份;紧接着,当本节点成为代表节点时,若为第1次区块共识,则直接采用改进一致性协议和视图切换协议完成区块共识,否则根据前一次共识结果,执行奖惩机制,并采集每个节点的评估要素,利用自我优化信用等级划分算法实现节点的信用等级划分;接着,当本节点成为代表节点且需要重新进行代表节点选择时,则根据式(13)分别计算b个节点的得分,并将自身投票信息与候选节点信息进行广播。若本节点收到全部节点的投票信息,则根据式(14)分别计算e个节点的投票结果,选择NAN个代表节点,并广播其信息;最后,本节点采用改进一致性协议和视图切换协议完成区块共识。

表1 基于信用等级划分的医疗数据安全共识算法 (SCA_MD)
5 实验分析
5.1 实验设计参数和实验性能评估参数
为了验证SCA_MD的性能,选择实验环境为Intel i5-9400F CPU 2.20 GHz, 16 GB内存和GTX1660显卡,并使用Golang语言实现一个由医疗机构、政府监管部门和患者组成的电子病历数据共享原型系统。在该原型系统中,考虑到不同医疗机构的设备性能差异较大,医疗机构以数据节点与共识节点的方式参与区块共识,并通过该系统的区块链获得患者的历史电子病历数据,对患者的新电子病历数据进行区块共识,保证患者医疗数据的实时更新。政府监管部门监督各医疗机构对医疗数据的使用情况,以监管节点的方式参与区块共识,保证患者电子病历数据的安全性。患者作为医疗数据的拥有者,可通过该系统的区块链查询到自身的所有电子病历数据。
在实验中,结合上述医疗环境下的电子病历数据共享原型系统,并选择以下参数:共识成功表现分奖励η为80,共识失败表现分奖励λ为80,身份验证表现分奖励μ为20,共识成功表现分扣除γ为180,共识失败表现分扣除σ为180,共识节点投票权重ε1为1,监督节点投票权重ε2为0.8,数据节点投票权重ε3为0.5,评价值参数ψ1为0.5,评价值参数ψ2为0.5,评价值参数ψ3为4,评价值参数ψ4为2。研究信任值模型系数对交易吞吐量的影响,研究恶意节点攻击下的恶意节点查准率与查全率,同时分别采用POS[10], DPOS[19], CDBFT(Credit-Delegated Byzantine Fault Tolerance)[20]和SCA_MD,研究恶意攻击下的交易吞吐量、平均交易时延和平均节点通信开销。其中,查全率定义为SCA_MD检测出的真实恶意节点数量与网络中存在的恶意节点总量的百分比。查准率定义为SCA_MD检测出的真实恶意节点数量与算法认为是恶意节点总数量的百分比。交易吞吐量定义为交易发起到写入区块链中的总交易数除以总时间。平均交易时延定义为全部交易从发起到写入区块链的总时间(包括交易广播传输时间、共识算法的执行时间和区块广播时间)除以交易数。平均节点通信开销定义为完成所有交易数时平均每个节点需要发送的通信包数量。由于在真实的环境中正常节点存在被恶意节点身份盗用的风险,因此恶意节点可通过身份盗用的方式发起累积攻击或信任值攻击,即考虑到POS与DPOS主要通过币龄来完成区块共识,因此选择恶意节点发起累积攻击。CDBFT与SCA_MD是考虑节点的信任值来给予区块共识权利,实现区块共识,因此选择恶意节点发起信任值攻击。
5.2 实验结果分析
5.2.1 参数选择分析
选择信用值模型参数ι1为选取范围0~500的6个典型值为0, 100, 200, 300, 400, 500,参数ι2为选取范围0~250的5个典型值50, 100, 150, 200,250,节点数量为350,恶意节点数量为30,分析信任值模型参数对交易吞吐量的影响。如图3所示,随着模型参数ι1和ι2的增加,SCA_MD的交易吞吐量在前期逐渐上升,且当模型参数ι1和ι2分别为400和200时达到最大值(5.32)。这是因为:随着模型参数ι1的增加,信用值模型拥有更高的上下限,导致恶意节点更容易被区分,且便于后期综合评价节点的信用等级,因此SCA_MD的交易吞吐量逐渐上升。同时随着模型参数ι2的增加,信用值模型在前期的上升速度放缓,导致恶意节点以合理的速率完成节点的累积信用值,且有效鼓励正常节点参与多轮区块的积极性,降低交易的时间,因此SCA_MD的交易吞吐量逐渐上升。但当SCA_MD模型的参数ι1为500时,会导致信任值模型的上下限过高。当参数ι2为250时,其信任值模型的上升速度过缓,因此上述参数设置均会影响节点参与区块共识的积极性,交易吞吐量出现一定程度的下降。因此在后续实验中,我们选择信用值模型的参数ι1为400,参数ι2为200。
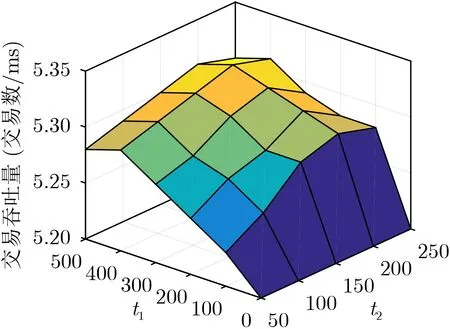
图3 信任值模型参数对交易吞吐量的影响
选择恶意节点数为10, 20, 30, 40, 50, 60,节点数为350,分析恶意节点数量对查全率与查准率的影响。如图4所示,随着恶意节点数量的增加,SCA_MD的查全率与查准率基本维持在一个较高的水平,且恶意节点的查全率略低于查准率。这是因为:SCA_MD在区块共识过程中,采用节点身份验证机制,尽可能剔除发起攻击的恶意节点,且在信用等级划分方面,不仅结合奖惩机制与信用值模型,同时根据当前累积信用值、历史等级数值、成为代表节点次数、提供无效区块次数和提供分叉区块次数,完成节点等级的综合评价,从而实现恶意节点与正常节点的区分。但由于该算法采用代表节点来完成区块共识,因此网络中部分恶意节点没有获得直接攻击的机会,其行为没有表现出与正常节点的差异,导致其在共识过程中没有被认为是恶意节点。

图4 恶意节点数量对查全率与查准率的影响
5.2.2 算法性能比较
选择恶意节点数为10, 20, 30, 40, 50, 60,节点数为350,分析恶意节点数量对交易吞吐量的影响。如图5所示,随着恶意节点数量的增加,DPOS,CDBFT和POS的交易吞吐量逐渐下降,而SCA_MD基本保持不变且明显高于DPOS, CDBFT和POS。这是因为:在DPOS和CDBFT中,由于进行投票选择代表节点,当恶意节点数远小于代表节点数时,算法被成功攻击次数较少,但随着恶意节点数上升且接近代表节点数量,成功攻击次数逐渐增加,因此DPOS和CDBFT的交易吞吐量逐渐下降。而POS根据币龄选择构建区块的节点,随着恶意节点数量上升,其受到攻击次数一直上升,因此其交易吞吐量逐渐下降。SCA_MD不仅采用节点身份验证机制,剔除身份盗用的恶意节点,并针对恶意节点采用SCRD实现共识权利限制,尽可能由正常节点来完成区块共识,降低了恶意节点的成功攻击次数,因此其交易吞吐量基本保持不变且始终高于DPOS, CDBFT和POS。
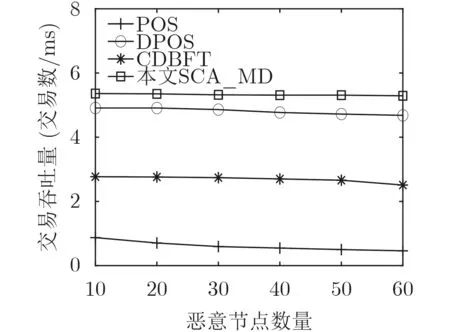
图5 恶意节点数量对交易吞吐量的影响
选择恶意节点数10, 20, 30, 40, 50, 60,节点数为350,分析恶意节点数量对平均交易时延的影响。如图6所示,随着恶意节点数量的上升,DPOS, CDBFT和POS的平均交易时延逐渐上升,而SCA_MD基本保持不变且低于DPOS, CDBFT和POS。这是因为:在POS中,随着恶意节点数量增加,成功攻击次数逐渐上升,且成功攻击后每个节点均需要重新参与区块共识,因此其平均交易时延也逐渐上升。而在DPOS和CDBFT中,通过代表节点完成共识,当恶意节点数量增加时,成功攻击次数也逐渐上升,且攻击成功后需要重新发起投票选举,因此其平均交易时延同样出现上升。SCA_MD不仅引入节点身份验证机制与节点信用等级划分来限制恶意节点的权利,同时在代表选举中设置反对票与投票系数,尽可能避免了恶意节点成为代表节点,降低了成功攻击次数,因此其平均交易时延基本保持不变且低于DPOS, CDBFT和POS。
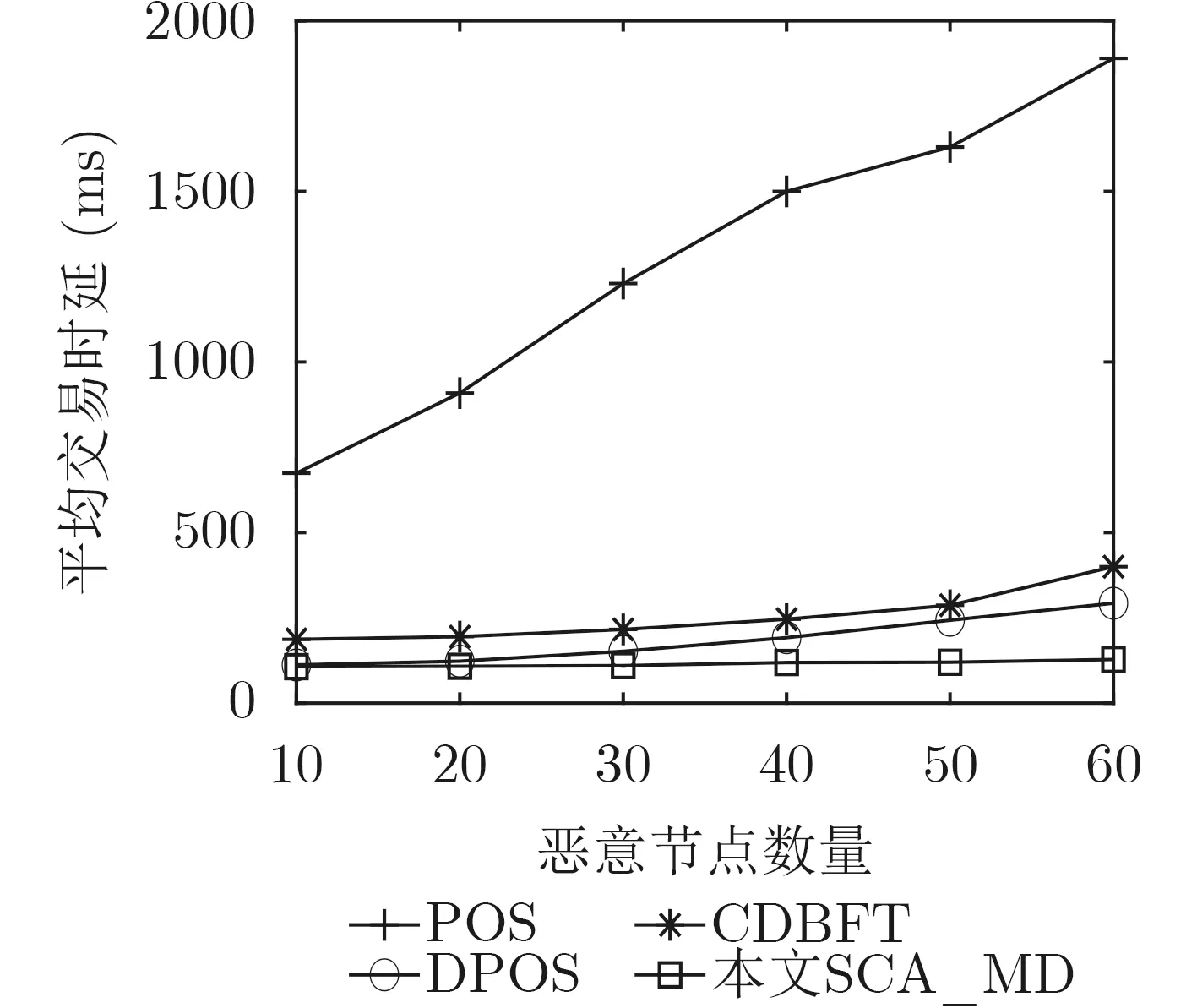
图6 恶意节点数量对平均交易时延的影响
选择恶意节点数为10, 20, 30, 40, 50, 60,节点数为350,分析恶意节点数量对平均节点通信开销的影响。如图7所示,随着恶意节点数量的增加,DPOS,CDBFT和POS的平均节点通信开销逐渐上升,而SCA_MD基本保持不变且低于DPOS, CDBFT和POS。这是因为:在POS中,随着恶意节点数增加,恶意节点攻击成功次数上升,使得每个节点需要多次广播交易和币龄等信息,因此其在平均节点通信开销方面的效果最差。而在C D B F T 和DPOS中,当恶意节点数量大于50时,其成功攻击次数急剧上升,且每个节点需要重新广播投票与信誉值等信息,因此其平均节点通信开销同样出现明显上升。但是SCA_MD不仅针对一致性协议进行简化,避免了大量节点的广播过程,有效减少节点的网络通信开销,同时在视图切换协议中设置备用代表节点的措施,避免恶意节点持续影响区块共识,提高了区块共识效率,因此其平均节点通信开销基本保持不变且低于DPOS, CDBFT和POS。
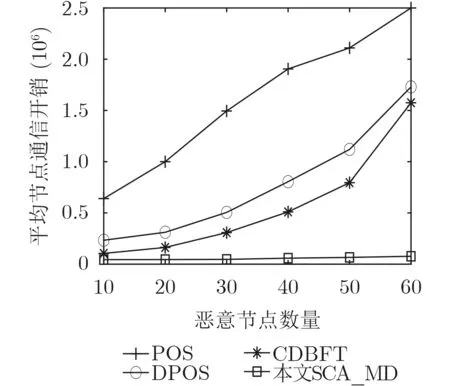
图7 恶意节点数量对平均节点通信开销的影响
6 结束语
该文提出一种基于信用等级划分的医疗数据安全共识算法(SCA_MD)。首先,将节点分为数据节点、共识节点和监管节点3类。考虑到数据节点与共识节点存在身份被盗用的风险,提出一种节点身份验证机制。其次,根据节点的参与区块共识情况,提出奖惩机制、信用值模型和基于海洋掠食者的自我优化信用等级划分算法(SCRD)。考虑节点的类型情况,提出一种代表节点选举机制。接着,改进一致性协议和视图切换协议,提出代表节点共识机制。实验结果表明:不管与恶意节点数量如何变化,SCA_MD能够避免恶意节点对区块共识的影响,从而提高交易吞吐量,降低平均交易时延和平均节点通信开销,比POS, DPOS和CDBFT更优。但是SCA_MD没有考虑到节点的数据存储能力有限且异构,因此下一阶段的目标是研究医疗环境下异构节点存储空间中的区块更新,提出适用于医疗环境的区块有效存储和更新算法。
