基于深度学习的高分辨率食管测压图谱中食管收缩活力分类
2022-02-24贺福利戴渝卓李钊颖王姣菊戴燎元侯木舟
贺福利 戴渝卓 李钊颖 粟 日 曹 聪 王姣菊戴燎元 侯木舟* 汪 政②
①(中南大学数学与统计学院 长沙 410083)
②(湖南第一师范大学科学与工程学院 长沙 410205)
③(湖南省计算机用户协会 长沙 410205)
1 引言
食管动力障碍性疾病(Esophageal Motility Disorder, EMD)主要是指由食管胃动力障碍引起的以各种消化道症状为临床表现的食管疾病[1,2]。食道动力障碍可产生一系列不良症状,如胸痛、烧心、吞咽困难、胃酸反流恶心等,从而严重影响人们的生活质量。近几年,EMD的研究引起了社会各界的广泛关注。
高分辨率食管测压技术(High-Resolution Manometry, HRM)是在传统食管压力测量的基础上于20世纪90年代发展起来的一项新型固态压力测量技术[3]。它被认为是动力障碍的主要诊断方法,也是一些食管动力障碍诊断的“金标准”。HRM的原理是通过检测患者吞咽过程中食管上括约肌(Upper Esophageal Sphincter, UES)、食管、食管下括约肌( Lower Esophageal Sphincter,LES)、膈肌的压力变化,同时生成食管压力图(Esophageal Pressure Topography, EPT),以供医生诊断症状[4—6]。目前,HRM结合芝加哥分类(Chicago Classification, CC) v3.0诊断标准[7],为EMD的研究提供了病理生理学基础,成为辅助医生临床预防、诊断和治疗EMD的重要手段,广泛应用于临床试验中[8]。然而,现阶段的HRM图像分析工作都是由医生用肉眼完成的,存在以下问题:(1)由于医生专业水平的局限性和HRM图像分析与诊断的复杂性,临床上HRM图像诊断结果存在异议和误诊的问题时有发生;(2)随着医学图像数据呈井喷式增长,医务人员的工作量急剧增加,在医生精力有限的情况下,繁琐的诊断工作极可能导致医生工作效率低下并伴随误诊、漏诊风险。因此,如何借助计算机智能分析HRM图像以提高临床上EMD的诊断准确性,已逐渐成为智慧医疗的研究重点和热点。
深度学习(Deep learning, DL)技术作为人工智能的热门研究领域,在挑战图像的目标分类、分割和检测任务上取得的巨大成功为以上问题的解决带来了希望。DL网络可理解为传统神经网络的延伸,是通过深层非线性网络结构无限逼近复杂函数获取数据的原始特征,进而取代传统的由人工提取数据特征的方法,实现了让机器自主学习数据特征的智能化[9]。同时,由于网络模型具有层次深、运算量大、表达能力强等特点,DL适用于处理大数据,尤其是图像这类直观但高级语义信息不显著的数据[10]。所以DL几乎可以应用于各类医学影像的诊断工作。
为了减少从HRM图像中提取的特征偏差并进行特征分类,Kou等人[11]提出了变分自动编码器(Variational Auto-Encoder, VAE),以协助医生诊断食管动力障碍[11]。他们基于降维的方法从HRM图像中寻找有用的特征(收缩模式)。作者发现,在训练和测试集上仅对收缩强度、收缩模式和括约肌松弛[7]的潜在变量进行编码时,分类误差较小。此外,他们在考虑损失函数时,模型只有加入正则化参数的混合L2才能选择收缩和松弛过渡期间的重要特征。同样,为了识别贲门失弛缓症亚型的痉挛(III型)和非痉挛(I型和II型),Carlson等人[12]使用了有监督的机器学习(Machine Learning, ML)方法,如决策树和随机森林算法。其实验结果表明:使用训练数据对痉挛(III型)和非痉挛(I型和II型)进行分类的准确率为90%,而测试数据的准确率仅为78%;使用训练和测试数据的贲门失弛缓症亚型I, II和III的准确率分别为71%和55%。上述方法的局限性在于3类贲门失弛缓症的HRM图像数量往往是不平衡的,这可能导致数据量较少的病症在分类准确性上存在偏差。而且他们没有考虑这些特征之间存在的相关性。
HRM图像的成像特殊性[13]、诊断复杂性和疾病多样性使得DL在HRM图像诊断任务中的应用较少。因此,基于DL技术的 EMD分类研究无论是对智慧医疗技术的未来发展还是对EMD临床诊断工作都具有重大价值。然而HRM图像诊断的复杂性和部分典型数据的稀缺性给本研究工作带来了一定局限,以至于本研究目前无法一次性完成EMD的全部分类工作。由于食管收缩活力是衡量食管动态特征的重要指标之一[7],收缩活力异常将直接影响食管功能的健康,本文将基于DL技术研究计算机对食管收缩活力的全自动分割、分类方法,为EMD计算机辅助诊断(Computer Aided Diagnosis,CAD)系统的搭建工作奠定基础。CC v3.0将收缩活力分为5类:失收缩、弱收缩、无效收缩(失收缩或弱收缩)、正常收缩和高幅收缩。在临床实践中高幅收缩病例难以收集,其数据量远小于其他病例而导致了类别失衡问题,并且极小样本量是不足以支撑DL在诊断任务中获得高精度结果的。因此,本文只针对食管收缩活力的失收缩、弱收缩和正常收缩进行智能诊断。
本文将利用深度学习的卷积神经网络(Convolutional Neural Network, CNN)作为主要研究方法,创造性地提出了一个多任务模型Proposal of Swallowing frame-Classification Network (PoS-ClasNet)用于食管收缩活力的鉴别诊断工作。PoS-ClasNet是由Proposal of Swallowing frame network (PoSNet)和Swallowing frame Classification Network (SClasNet)相结合的感兴趣区域(Region of Interest,ROI)分类器,承担了分割和分类两阶段任务。在本工作中,HRM图像的吞咽框为研究的感兴趣区域,由PoSNet提取得到;S-ClasNet负责对吞咽框的收缩活力进行分类。研究结果表明,食管收缩活力分类器PoS-ClasNet在训练集、验证集和测试集上都表现出了优异的分类性能,在测试集上最终诊断阶段的准确率为93.25%,对3类收缩活力分类的平均精度为93.18%,平均召回率为93.24%,平均F1得分为0.9321。
2 实验数据
2.1 数据来源
本文使用了中南大学湘雅医院于2019年采集的实验数据集。该数据集包含4000幅HRM图像,由固态高分辨率测压系统—ManoScan 360TM(Sierra Scientific Instruments)检测,并由采集和分析软件—Mano View ESO3.0生成[14]。其中失收缩图像1450幅,弱收缩图像1050幅,正常收缩图像1050幅。所有图像的真实标签由中南大学湘雅医院消化科专家基于CC v3.0标准和Mano View ESO3.0的分析报告对每幅HRM图像的食管收缩活力类型进行深入探讨得出。这些实验数据的患者来自中国各地,具有很强的代表性。
2.2 数据展示
数据集如图1所示,图像颜色代表食管内压力,每幅HRM图像代表一位患者的一次性吞咽过程。HRM图像是一个“3维彩色压力地形图”,纵轴反映高分辨率食管测压导管的深度,水平轴反映压力测量时间,颜色代表导管上每个压力传感器的平均压力水平[15]。偏蓝的色度代表较低的压力,偏红的色度代表较高的压力。HRM图像可以简单、直观、详细、有效地检测食管的动态状态。
图2显示了4种类型的食管收缩活力。食管收缩活力类型可由DCI指标确定[7]:DCI<100 mmHg·s·cm时失收缩(Failed)(图2(a));100<DCI<450 mmHg·s·cm时弱收缩(Weak)(图2(b));450<DCI< 8000mmHg·s·cm)时正常收缩(Normal)(图2(c));DCI>8000 mmHg·s·cm时高幅收缩(Hypercontractile) (图2(d))。我们用白色虚线框突出的局部图像显示了食管平滑肌传导波和食管下括约肌蠕动压力波的收缩强度,用于评价食管收缩活力。从图中可以看出,随着收缩活力的增强,图像色度也由蓝色向红色过渡。4类收缩活力在白色虚线框内的图像特征有显著性差异。虽然现阶段我们没有足够的高幅收缩数据来进行分类训练,但是高幅收缩的图像特征与图2的其他收缩活力类型特征明显不同。一旦收集了足量的数据, CAD系统就能完成食管收缩活力的全分类任务。
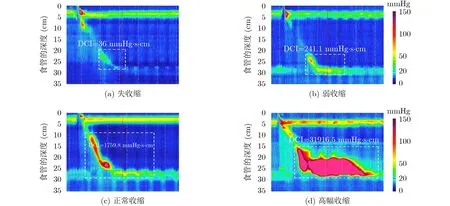
图2 食管收缩活力类型
2.3 数据预处理
从图1可看到HRM图像中有多条垂直的白色虚线和1条红色的实线。这些是由Mano View ESO3.0软件生成的辅助工具,可帮助医生更准确地分析图像。但计算机对HRM图像进行分类时无需这些辅助工具,甚至于它们的存在将影响模型的分类精度。此外,由于压力测量设备的磨损和压力测量时设备操作不当, HRM图像特征会受到一定的噪声污染,如图3所示。为了去除噪声干扰得到有用的像素信息,以便准确地分析食管收缩活特征,需要对数据进行预处理。噪声是像素强度相对于真值的突然变化。在时域上,高斯滤波可以对像素强度突变的点进行平滑处理,使其与周围相关点的强度保持相对一致,减少突变的影响,去除图像中的高频噪声。同时,HRM图像的形成与时间有关,其横坐标代表压力测量时间。因此,本文采用基于高斯核的卷积去噪方法对HRM图像进行预处理,可以得到更清晰的实验图像。图4展示了使用高斯核卷积去噪滤波平滑处理前后的两幅H R M 图像。
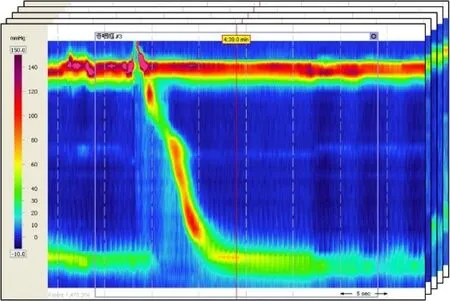
图1 高分辨率食管测压图谱数据集
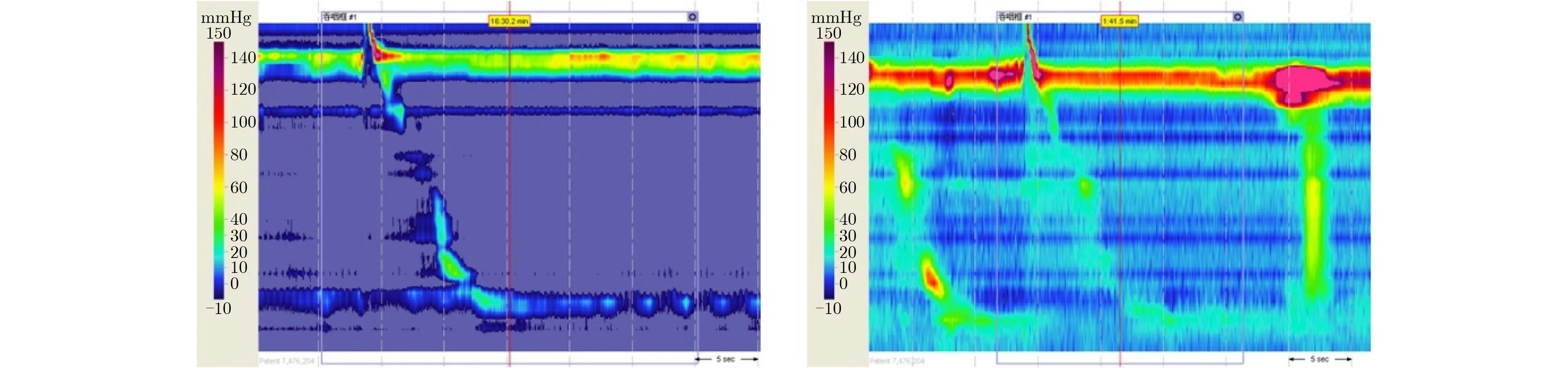
图3 受噪声污染的HRM图像
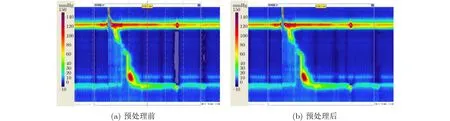
图4 预处理前后的HRM图像
3 基于深度学习的食管收缩活力分类模型
3.1 研究方法
卷积神经网络(CNN)在有足够多标记数据的情况下显示出巨大的成功,它是一种有监督的深度学习方法[16,17]。在过去几年中,它在计算机视觉和医学成像的不同模式中显示了最先进的性能[18]。CNN学习输入对象和类标签之间的关系,由两个部分组成:提取特征的隐藏层和预测类别的全连接层(Fully Connected, FC)。对于CNN来说,医学图像可以作为网络最低层的原始输入,然后依次传输到下一层。每一层通过带有池化层的一对卷积核(或过滤器)提取图像的最显著特征,如边缘或形状和纹理。最后分类器输出类别概率或类别标签的分类结果[19]。
CNN在医学图像识别方面有许多显著的优势[20]。一方面,很多医学图像看起来非常相似,很难用专家的肉眼分辨出差异。CNN解决了这一问题,其网络结构能够学习非显著信息。这是因为CNN从原始数据中学习特征,并利用损失函数得到的误差信号进行反馈,以不断优化其特征提取能力。这种多层学习模型有助于发现数据的复杂结构,提高医学图像的识别精度[21]。另一方面,早期的医学图像识别技术通过图像分割得到疑似病变组织,人工提取其特征,并与分类器结合实现对病变图像的识别。这不仅步骤繁琐,而且识别率低,训练时间长。通过将特征提取和分类集成到一个结构中,CNN避免了传统算法中人工提取特征的复杂过程,节省了时间和精力,提高了准确性[22]。
3.2 PoS-ClasNet在食管收缩活力分类任务中的应用
本文提出了一个食管收缩活力分类器PoS-ClasNet。这是一个卷积神经网络模型,如图5所示,由PoSNet和S-ClasNet组成。前者用于提取HRM图像中的吞咽框,后者识别吞咽框的食管收缩活力类型。将PoSNet分割出的吞咽框映射到S-ClasNet通过卷积得到的HRM特征图上,以此得到吞咽框的特征图,并实现了PoSNet和S-ClasNet的融合。PoSClasNet是基于U-Net[23], VGGNet[24], Fast-RCNN[25]和Faster-RCNN[26]改进的多任务模型。该模型的2阶段结构适应于需要先分割后分类的医学图像识别任务。
3.2.1 PoSNet结构
PoSNet是一个稳定的编解码网络,专门用于对有限的数据进行特征学习,特别是医学图像[27]。本文改进了Ronneberger等人[23]提出的标准U-Net结构,使其更好地完成吞咽框分割任务。由于我们需要提取的ROI位于图像的中心,这意味着模型无需精确地分割图像边缘的像素。与标准的U-Net结构不同,本文没有使用overlap-tile策略[8],而是使用零填充来保持下采样和上采样路径的所有卷积层的输出维数相同,从而使输出图像的分辨率与输入图像的分辨率相同。
如图5所示,PoSNet最重要的结构是由编码路径、中心块和解码路径组成的编码-解码模型。编码路径有4个下采样块。每个块有两个卷积层(含有步长为1的、3×3大小的滤波器和修正的线性单元ReLU激活函数),它使得特征通道的数量增加1倍,并通过一个步长为2的2×2最大池化层进行下采样。通过对编码路径的深度卷积,我们不仅得到了图像的颜色、纹理、形状等浅层特征,而且得到了抽象高层语义等深层特征[28]。接下来,为了避免过度拟合,PoSNet在编码器和解码器块之间设计了一个中心块。该中心块由与编码路径中相同的两个卷积层组成。

图5 PoS-ClasNet的模型结构图
对于上采样操作,解码路径中的每个模块包括一个2×2的反卷积层(将特征图谱的尺寸大小减半)、特征融合(与编码路径中对应的特征图谱相互融合)以及两个3×3的卷积核(将特征通道的数量减少一半),每个卷积后面都伴随ReLU激活函数来增加网络的非线性表达能力。其中,特征融合的关键是跳跃连接,它将解码子网的深层、语义、粗粒度特征映射与编码器子网的浅层、低层、细粒度特征映射相结合。跳跃连接有助于恢复网络输出时的全空间分辨率,使全卷积方法适合语义分割[29]。
最后用1×1的卷积层将特征图减少至两个,分别反映前景和背景的分割。PoSNet中没有调用FC层。
3.2.2 S-ClasNet结构
S-ClasNet用于吞咽框的分类任务,其模块结构与VGGNet相似,但尺寸较小,本文称为Smaller VGGNet。VGGNet在医学疾病识别方面表现很好,是医学图像分类中最常用的网络之一。一般来说,医学图像数据量较小,为了确保模型的泛化能力,浅层网络在医学图像应用中是首选的。同时基于奥卡姆剃刀原则,本文选择了参数较少、性能相当的Smaller VGGNet,并对其进行了改进,使SClasNet和PoSNet能够更好地连接起来,完成收缩活力分类任务。
如图5所示,S-ClasNet的结构框架有以下几层:
卷积层:包括一个CONV=>RELU=>POOL的模块和两个CONV=>RELU=>CONV=>RELU=>POOL的模块。卷积核具有非常小的感受野:3×3(这是捕捉图像所有方向特征的最小尺寸),它将通道数从32个增加到64个到128个。卷积步长固定为1像素,空间填充不变,保持了卷积后的空间分辨率。最大池化层是一个2×2的像素窗口沿着空间维度向下采样。本文用上述CNN作为特征提取器。
映射:经过密集卷积操作后,得到图像的特征图谱。根据原始图像与其特征图谱的映射关系,将PoSNet分割出的ROI映射到特征图谱上,得到吞咽框的特征框PoS。
PoS池化:PoS池化的目的是对输入进行最大池化,以获得固定大小的特征图谱(例如7×7)。PoS最大池化层的工作原理是将PoS分成大小相等的几个部分(其数量与输出的维度相同),然后在每个部分中找到最大特性值并将这些最大值复制到输出缓冲区[25]作为修正后的吞咽框特征图PoS。通过PoS池化层,修正后的吞咽框特征图谱与网络模型的第1个FC层维度兼容。
分类:网络通过两个FC层和1个Softmax分类器来实现图像的分类。第1个FC层有1024个神经元,后面接1个ReLU激活函数,它将修正后的PoS的所有局部特征映射合并到特征向量中。在最后一个FC层中,我们将神经元减少到3个,这与本文研究的图像类别数相同。最后应用Softmax分类器给出每个类别预测标签的概率。
4 实验结果
4.1 实验环境设置
实验使用了戴尔XPS8930服务器(16GB RAM,HEXACORE3.20 GHz处理器和1个NVIDIA GeForce GTX 1070显卡),在Python环境的Keras框架和Tensorflow后端中实现。本文将原始图像(224×299)的大小调整为输入图像(128×128),这两个比例的图像只在分辨率上不同,而在内容/布局上没有差别,这使得网络模型更容易处理图像。为了减少偶然性,本文随机分配70%的标记数据集作为训练集来训练模型,20%作为验证集来调试超参数并选择最佳模型,10%作为测试集来测试模型的分类准确性和可靠性。
训练神经网络最重要的是对超参数进行调试和优化。为了更好地调试和优化超参数,本文在验证集上进行了超参数敏感性测试,并选择了一组最优的超参数。所有网络都是从0开始训练的。在每次卷积运算后加入批正态化(Batch Nomalization,BN)[30],同时在训练过程中对网络中所有神经元设置了以0.3的概率随机失活即dropout正则化操作,以达到加快训练速度,防止模型过度拟合的目的。由于本文的网络使用了ReLU激活函数,所以采用了kaiming初始化[31]对网络权值进行初始化,这样不仅可以加快网络的收敛速度,而且可以防止反向传播中的梯度消失和爆炸。所有偏差(bias)都初始化为0。每次取batchsize为16的样本量来训练一次网络,训练轮数epoch设置为50,并采用自适应矩估计器(Adam)[32]作为参数优化器。Adam中的初始学习率设置为0.0001。然而,使用恒定学习速率来估计参数可能会导致模型性能不佳或网络收敛速度过慢等问题。在训练过程中,使用Keras中的回调函数ReduceLROnPlateau不断调整学习速率,并且利用Earlystoping函数停止训练,防止模型过度拟合。其中,在回调函数中设置了一些参数:学习率缩放因子为0.8,最小学习率为0.0001。
4.2 代价函数
在本研究工作中,除了PoSNet使用Dice相似性系数指导网络进行参数更新,所有分类网络都使用交叉熵(Cross-Entropy)作为代价函数来确定模型的最佳性能。
Dice相似性系数不仅能较好地度量ROI与真实标签的差异程度,最重要的是它作为分割网络的代价函数在迭代优化模型的过程中能有效抑制由于大面积背景区域引起的分割偏差问题。鉴于Dice相似性系数十分适用于HRM图像分割背景区域较大的情形,本文选择了Dice相似性系数作为代价函数。其二分类任务的数学表达式为

4.3 评价指标
对于医学影像分类模型,可以通过准确率(Accurcy,Acc)、精度(Precision, Pre)、召回率(Recall,Rec)、F1得分(F1-Score, F1)、灵敏度(Sensitivily,Sen)和特异度(Specificity, Spe)等典型性能指标来评价其性能。准确率是衡量分类器性能最常用的评估量,其定义为被正确分类的对象所占的百分比;F1得分是一个全面的评估指标,是数据集中不同类数据不平衡时的合理度量。F1得分越大,模型性能越好。这些度量的计算公式如下
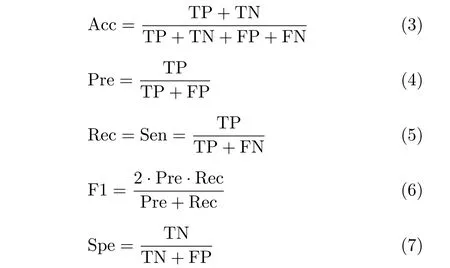
其中,TP, TN, FP, FN分别表示真阳性、真阴性、假阳性、假阴性的预测值。
此外,本文还绘制了受试者操作特征(Receiver Operating Characteristic, ROC)曲线来评价我们的分类模型。通过绘制Sen相对于1 - Spe的ROC曲线。ROC曲线越靠近左上角,模型的性能越好。ROC曲线下面积(Area Under the ROC curve,AUC)也是一个适合模型的总体测量方法。
4.4 实验结果
4.4.1 多模型比较分析
选择合适的网络结构对医学影像的准确分类非常重要。不同的神经网络结构,由于隐藏层的深度和/或单元数不同,具有不同的优势和劣势。本文训练和比较了几种常用于医学图像分类任务的网络:Inceptionresnetv2, Inceptionv3, Resnet50,Xception,同时提出了一种分类网络(S-ClasNet)。在这里,我们只比较了用于分类食管收缩活力类型的吞咽框网络(S-ClasNet),所有吞咽框都使用PoSNet进行分割提取。因为PoSNet的准确率高达94.86%,已经满足了提取吞咽框的需要。网络训练基于相同的训练集和验证集,按照4.1节(实现环境设置)中的实现细节进行实现。
表1给出了几种网络的定量分析结果。值得一提的是,根据表1实验结果发现除Inceptionresnetv2外,其他网络在验证集上的准确率略高于在训练集上的准确率。出现该现象的原因有以下两点:(1)该实验的HRM数据样本总量较小,划分后的验证集样本远小于训练集的样本,当样本量较少时会出现较高的准确率。加之HRM图像成像依赖医生临床操作,它很容易带有噪声污染。即使随机划分了训练集和验证集,但也会存在带噪图像分布不均匀的问题。这就造成了训练集的内部方差大于验证集,换言之训练集出现较大分类误差。该问题是可以通过增大样本数据量来解决的。但因为收集专家标记好的HRM图像数据所需的人力和时间成本较高,本文的实验工作存在样本量较小的局限性。(2)利用L2和dropout正则化的方法增强了模型的泛化能力。尤其在训练过程中,本文利用dropout操作让部分神经元随机失活以精简网络结构防止过拟合,这会使得训练精度受损。相反,验证过程中所有神经元都正常工作,因此预测精度有所提高。尽管本文工作存在一定样本量不足的局限性,但上述实验结果仍然具有较大参考价值。所有网络模型的评估指标在验证集上的数据值十分接近训练集。该结果表明,所有模型没有出现过拟合现象,并且在验证集上的模型精度可以从一定程度反映模型的泛化能力。因此下文根据各模型在训练集和验证集上的表现进行性能对比分析是可行的。
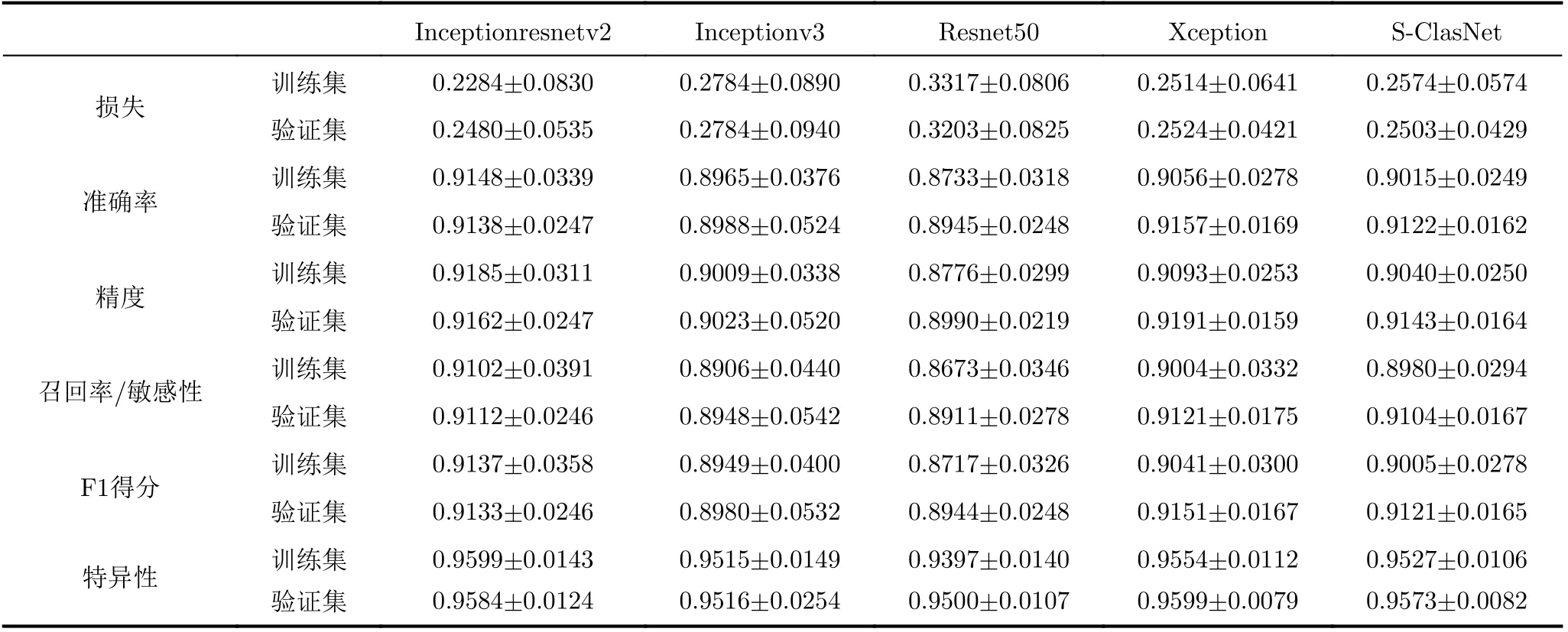
表1 不同分类模型对食管收缩活力分类的结果比较(均值±标准差)
将各模型的精度可视化为图6进行对比分析,其中横坐标代表模型的网络结构深度,从左到右依次增加。Inceptionresnetv2, Xception和本文的网络在训练集和验证集上的准确率高达90%。这3种网络模型的分类表现能力相当。但就网络深度而言,Inceptionresnetv2和Xception是深度网络,需要经过大量训练才能收敛。但是,本文提出的网络结构小,训练速度快,对内存要求少。虽然网络深度的增加可以提高分类精度,但当3种模型的性能相当时,深度网络会导致在数据集较小时(过拟合)的非最优学习,空间和时间复杂度更高,增加了分类模型的优化难度,更重要的是会导致模型泛化能力较差。
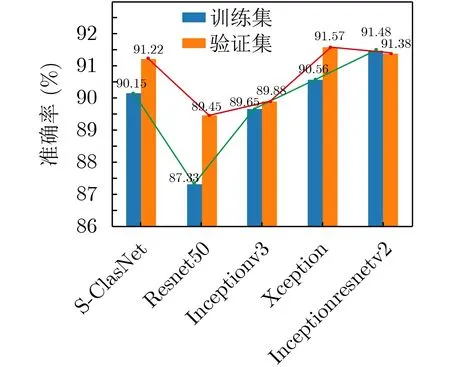
图6 所有分类模型的分类准确率柱状图
此外,本文所提出的食管收缩活力分类模型具有很好的鲁棒性。该算法在训练集和验证集上均取得了显著的分类效果,其取值分别为90.15%±2.49%和91.22%±1.62%。结合图7可知,在验证集上,SClasNet的AUC值最大,其ROC曲线更接近图形左上角,这进一步证实了本文的网络具有良好的分类性能。根据实验结果,我们发现所提模型在吞咽框的食管收缩活力分类任务中有最优的综合性能:准确率、鲁棒性和泛化能力都表现突出。

图7 各网络模型的ROC曲线
4.4.2 食管收缩活力分类模型的评价
为了进一步验证本文的网络在吞咽框分类任务上的优异性能,本文绘制了折线图来反映网络在训练期间平均损失值和准确率随着训练轮数增加的变化情况。在图8中,随着epoch的增加,S-ClasNet的精度增加,损失减小。在经过大约39次迭代后,它们都收敛到一个较为固定的狭小区间范围。这说明该网络经过了充分的训练后能够快速收敛。
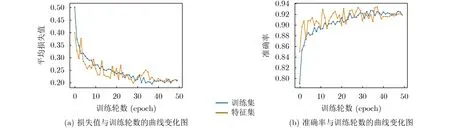
图8 S-ClasNet的学习曲线
接着,我们在测试集上进一步验证了模型的泛化能力。如图9所示,S-ClasNet对于3个收缩活力类别的分类具有较高的准确率。其中,失收缩分类和弱收缩分类的AUC值达到了0.99和0.98,而正常收缩分类的AUC值更是高达1。与此同时,我们可视化了在测试集上的混淆矩阵(图10)来考察S-Clas-Net对于每个类别样本分类预测的标签和真实情况的差异。从混淆矩阵中可以看出:失收缩和弱收缩分类的AUC值之所以未达到1,主要是因为S-Clas-Net将弱收缩样本与正常收缩、失收缩样本的特征弄混淆了。这种误分类现象出现的原因在于:一些弱收缩特征与正常收缩、失收缩特征较为相似,加之训练和测试样本数量不足,毕竟样本量的缺少或者类别样本量的不均衡都可能会影响卷积层学习图像特征的能力。但失收缩和正常收缩的分类错误率较低。由表2各类别的预测结果也能得到与上述ROC曲线一致的结论。并且本文的模型的准确率高达93.25%,在平均精度、平均召回率和平均F1得分上的分类表现也较为优异,分别达到了93.18%,93.24%和0.9321。

图9 测试集上的3类收缩活力分类的ROC曲线
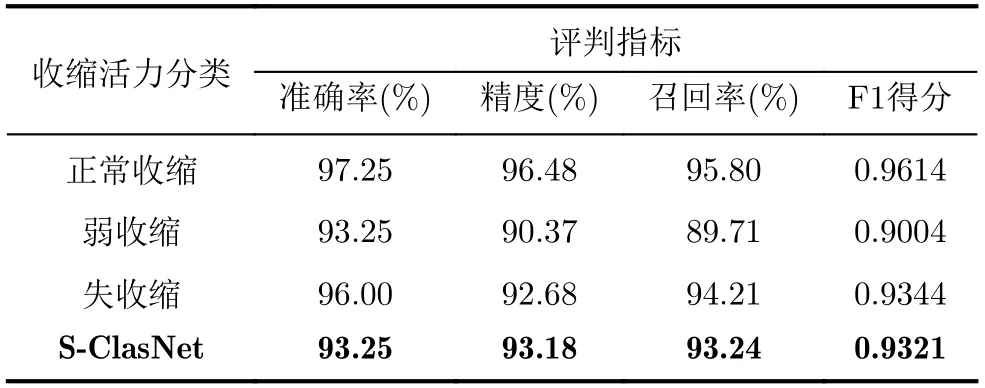
表2 S-ClasNet在测试集上对食管收缩活力分类的结果比较
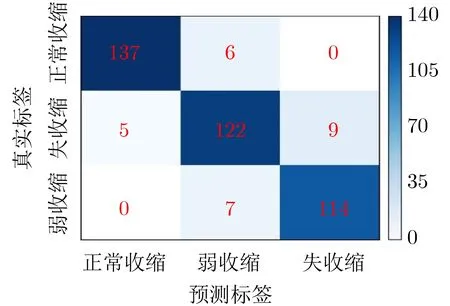
图10 测试集上的混淆矩阵
综上所述,本文提出的分类模型不仅对训练集有很好的拟合效果,而且在测试集上也有较强的泛化能力。因此,本文提出的PoS-ClasNet在智能识别HRM图像中食管收缩活力类型的任务中是切实可行的。
5 结束语
食管收缩活力异常可引起多种食管运动障碍(EMD)。本文基于DL方法分析了高分辨率食管测压(HRM)图像,并提出了一种全自动多任务分类模型(PoS-ClasNet)来诊断食管收缩活力类型。为了测试PoS-ClasNet性能,本文将其与先进的医学影像分类网络在去噪后的HRM图像数据集上进行了一系列对比实验分析。结果表明,PoS-ClasNet在食管收缩活力分类任务中的综合表现是最优的。它在测试集上最终诊断阶段的准确率为93.25%,对3类收缩活力分类的平均精度为93.18%,平均召回率为93.24%,平均F1得分为0.9321。
本文阐述了DL应用于HRM图像食管收缩活力诊断分析的研究工作,为今后实现EMD的自动诊断奠定了研究基础。PoS-ClasNet是第1个尝试结合2阶段任务(分割和分类)的食管收缩活力分类器,其中基于U-Net的PoSNet用于提取HRM图像的吞咽框,而基于Smaller VGGNet的S-ClasNet用于食管收缩活力的分类。该方法不仅可以在不受人工干扰的情况下对食管收缩活力进行准确的分类,为CAD在临床医学中的推广应用提供了参考,而且PoS-ClasNet作为轻量级模型,其结构简洁、占用内存小的优势为智慧医疗系统在用户终端装置上的成功部署和稳定运行提供了切实可行的方案。
同时,这项研究也存在一些局限性。本文的工作局限于小数据集。首先,本文的模型只对食管收缩活力的失收缩、弱收缩和正常收缩3个类型进行了自动分类。本文没有足够的样本让模型学习高幅收缩的图像特征,未达到可以预测所有食管收缩活力类型的预期。但高幅收缩的图像特征与其他收缩类型存在较大差异,如果本文有足够多的数据,PoS-ClasNet很容易实现收缩活力的完整分类。另外,由于有限的计算资源,本文的实验工作没有系统地搜索最优超参数,这导致模型是不饱和的。并且样本量的局限也导致了模型在验证集和测试集上的实验结果不足以强有力地支撑其性能表现优异的结论。总的来说,本文使用的模型是强大的,它的性能可以通过使用更多的计算资源来提高,而不需要显著改变网络结构。在未来的研究中,我们会尝试实现EDM的自动化诊断,并逐步将该模型应用到临床实践中,真正做到惠及人类社会。
