融合深度情感分析和评分矩阵的推荐模型
2022-02-24李淑芝余乐陶邓小鸿
李淑芝 余乐陶* 邓小鸿
①(江西理工大学信息工程学院 赣州 341000)
②(江西理工大学应用科学学院 赣州 341000)
1 引言
随着互联网的蓬勃发展,电子商务也流行开来,相应的产品和服务层出不穷,对于用户而言,很难处理提供的大量信息。因此,推荐系统在缓解信息超载方面发挥着越来越重要的作用,它可帮助用户根据他们的喜好、需求和过去的购买行为在平台上展示他们可能感兴趣的产品或服务。如今,推荐系统成为日常生活中不可缺少的部分,如网上购物、听音乐以及看电影等方面。为了提供更好的个性化推荐服务,如何准确地预测用户对商品的评分是推荐系统需要解决的关键问题[1]。
协同过滤(Collaborative Filtering, CF)是目前主流的推荐方法,它侧重于通过历史记录对用户偏好和物品特性进行适当的建模[2]。矩阵分解是协同过滤中最常用的算法,它直接从用户对项目的评分矩阵中学习他们的潜在向量,不仅能发现用户项目之间隐藏的因素,还能了解这些因素对用户的重要性以及与项目之间的联系。隐语义模型(Latent Factor Model, LFM)[3]是目前矩阵分解中使用比较多的模型,找出潜在的主题进行分类,通过隐含特征联系用户偏好和物品属性来进行推荐,但是用户偏好仅通过物品评分来度量是不准确的。对此,物品评分可结合近邻用户的影响力来度量,通过云模型[4]计算用户间评分的相似性得到近邻用户。但是当评分矩阵非常稀疏时,这类模型的发展也会受到制约。为了缓解数据稀疏性,有大量研究学者使用文本评论信息来提高评分预测性能[5,6],如基于隐因子主题(Hidden Factors and hidden Topics, HFT)的推荐模型[7],基于社交的回归推荐(social Collaborative Viewpoint Regression, sCVR)模型[8]。这些模型将主题模型集成到框架中,得到用户和项目的评论文本的潜在因子,通过对评论文本的短词语进行情感分析,提取用户偏好和项目特征。然而,这些基于用户评分和评论的模型也具有一些局限性:评论的情感分析和特征提取只是从评论文本简单地提取词语或短语,学习文本的浅层线性特征,未挖掘深层非线性特征,从而破坏了评论的完整性;另外,上述模型也未考虑到上下文的语义联系,导致评论在语义层面上会存在相似之处。
深度神经网络在自然语言处理、计算机视觉方面取得了突破性的进展,其中有一些研究尝试将不同的神经网络结构与协同过滤相结合,从而克服了传统推荐方法的局限性,并提高了推荐性能。2017年文献[9]提出了深度协同神经网络(Deep Cooperative Neural Networks, DeepCoNN)模型,该模型使用卷积神经网络(Convolutional Neural Network, CNN)分别处理用户评论和物品评论,通过最后一层共享层耦合两个评论的并行部分,达到联合建模,最后进行评分预测。2018年文献[10]提出了在文献[9]的基础上结合双向长短期记忆结构网络(Long Short-Term Memory, LSTM)处理用户和物品的评论文本,在预测评分的同时生成用户的偏好,提高了提取隐性特征的质量。深度神经网络保留了文本的词序信息,并且可以结合注意力机制提高提取特征的质量,文献[11]结合注意力机制对评论文本的特征进行加权,提取对评分预测有用的特征,用来提高预测结果的可解释性。但是上述方法未能利用评分矩阵进行评分预测,提取用户和物品的隐因子,仅仅利用评分矩阵会受到评分矩阵稀疏性的影响,导致推荐结果精度不高,从而不能真正体现用户的偏好。因此,文献[12]提出了评论文本结合评分矩阵的模型(Neural Attentional Regression model with Review-level Explanations,NARRE),该模型主要探讨评论的有用性,使用Word2Vec模型[13]得到用户、物品评论的隐向量,通过并行的神经网络得到隐含因子特征,最后将隐含因子特征和评分矩阵作为隐含因子模型的输入,进行评分预测。但是该模型中Word2Vec产生的词是静态的,未考虑上下文。由于相同的词在不同的语境中表示的信息是不一样的,因此忽略上下文信息会导致模型对单词语义的理解有偏差。
对此,本文提出了一种结合评论文本和评分矩阵的深度模型(a depth model combining Review Text and Rating Matrix, RTRM)。首先,RTRM模型使用预训练的Electra模型[14]得到每条评论的隐表达,并结合深度情感分析及注意力机制实现从上下文语义层面对评论文本的分析,度量每条评论对用户、物品的贡献度;其次,使用基于近邻用户影响力的矩阵分解模型对评分矩阵进行特征分解,得到用户和物品的隐因子;最后,在融合层模块中,用户(物品)评论的深层特征和评分矩阵的浅层特征进行交互,使它们在其他模块中相对独立。在6组数据集上进行实验,与多种经典和当前的先进算法进行性能对比,采用均方误差进行性能评价。
2 RTRM商品推荐模型
2.1 RTRM模型结构
推荐系统问题可定义为给定一个包含N个样本的数据集D,其中每个样本(u,i,Ru,i,Wu,i)表示用户u对物品i的评论Wu,i以及相应的评分Ru,i,模型可以利用用户u的评论集、物品i的评论集、用户和物品自身的属性来预测出评分rˆu,i,使得rˆu,i与ru,i之间的误差最小。本文提出的RTRM模型的目的是推荐给用户合适的商品,该模型由两个并行的网络模块NETu, NETi以及矩阵分解模块组成,它们分别通过输入用户评论文本和物品评论文本对用户和物品进行建模,得到用户和物品的深层特征向量,再和矩阵分解模型分解得到浅层特征向量相结合,得到预测模型,如图1所示。
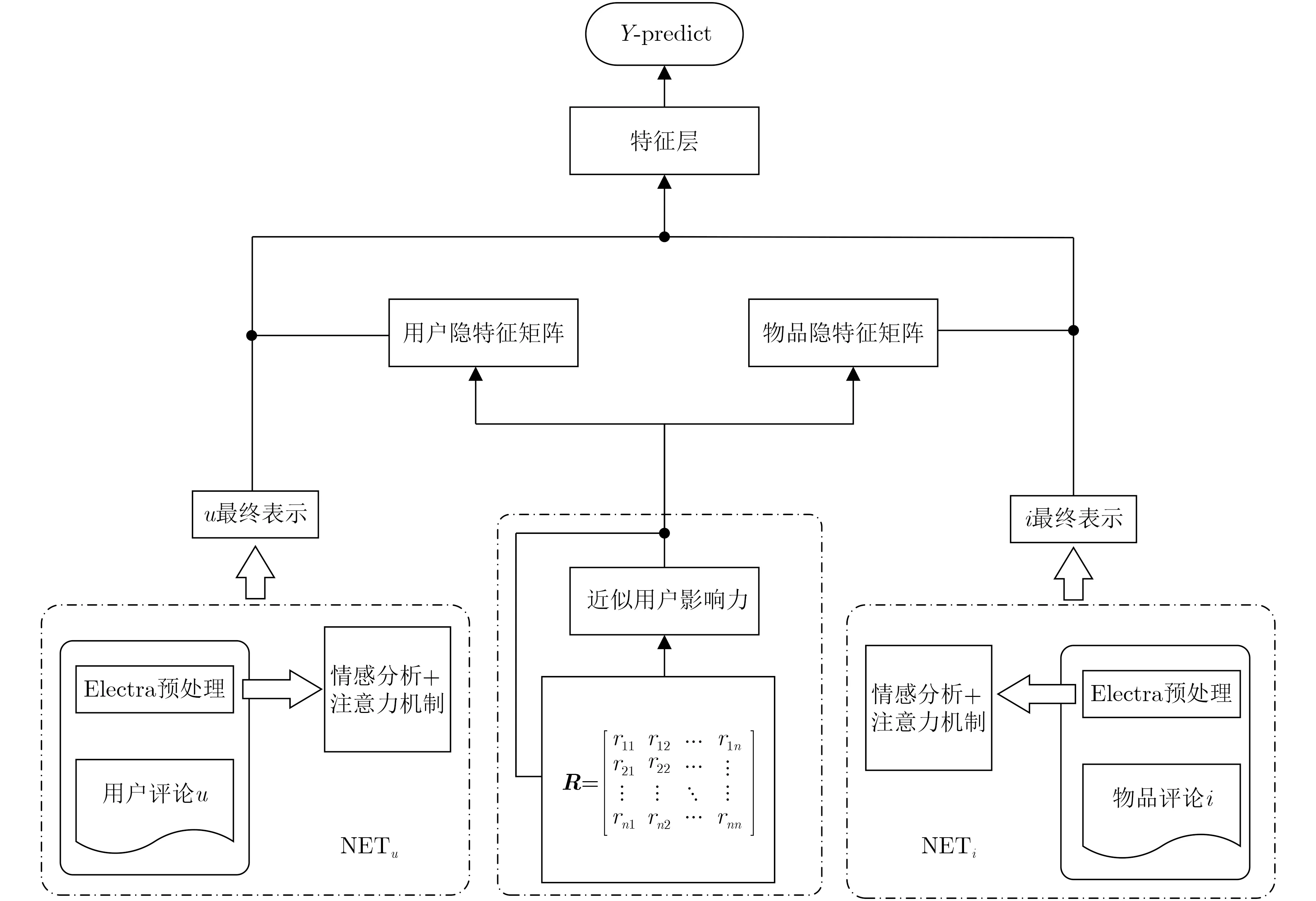
图1 RTRM模型结构
2.2 评论情感建模
评论情感分析模块由两个并行的神经网络NETu,NETi组成,它们分别通过输入用户评论文本和物品评论文本对用户与物品进行建模,得到用户和物品的深层特征向量,如图2所示。由于NETu,NETi结构相似,只是输入向量不同,因此本小节主要介绍对物品评论建模的网络NETi(对用户评论进行建模的NETu同理),建模过程有以下步骤:

图2 评论情感分析模型
(1) 给定某物品i的评论集,即该物品各条评论组成的列表{Wi1,Wi2,...,Win},其中n表示模型输入该物品的最大评论数,若物品的历史评论数少于模型输入最大的评论数,模型会先映射这些评论,再使用零向量填充得到输出列表;若物品的历史评论数大于模型输入最大的评论数,则模型只会映射前n条评论。本文采用Electra模型[14]执行替换令牌检测任务,将每条评论组成的序列输入到Electra模型映射为上下文化的c维向量表示,得到了每条评论的隐表示,输出向量序列表示为S={Oi1,Oi2,...,Oin}∈Tn×c。
(2) 得到每条评论的隐表示后,普遍做法[4]是利用加权平均的方式对向量进行处理,更先进的做法是采用注意力机制将它们汇聚为评论集的隐表示。但是这些处理方法会忽略词语间的排列顺序以及各个评论的内在联系,因此本文采用自注意力机制结合双向LSTM技术来生成可解释句子向量。将Electra模型映射的输出序列输入到一个双向LSTM中,可获得句子中相邻单词之间的依赖关系,第t个单词对应的前向和后向隐藏状态的计算方法如式(1)、式(2)所示

2.3 融合近邻用户影响力的矩阵分解
2.3.1 近邻用户相似度
本文采用云模型[4]计算用户间评分的相似性,模型中定义u:U →[0,1]∀i ∈Ui →u(x)U为具有数值的定量论域,C为U的定性概念,期望 EX是定值i在U分布的期望,熵 EN是C的可度量性,超熵HE表示熵的不确定性。因此,C(EX,EN,HE)为云的特征向量。若用户间的云模型是相似的,则他们的云的特征向量也是相似的。由于考虑到空间性等问题,本文采用距离表达式来量化相似性,一般的两个向量之间的距离与相似度成反比,假设两个向量为X(EX1,EN1,HE1),Y(EX2,EN2,HE2),则X和Y的距离表达式如式(5)所示

2.3.2 矩阵分解模型
通过上述步骤得到的近似用户影响力的反馈W,本文将它融入到矩阵分解模型中,使用LFM模型[3]根据用户和物品将评分矩阵分解成两个低维度矩阵向量PT和Q,又因为用户对物品的评分不仅仅取决于用户和物品之间的关系,还取决于用户的偏好和物品的性质。并且,得到一个新的评分模型
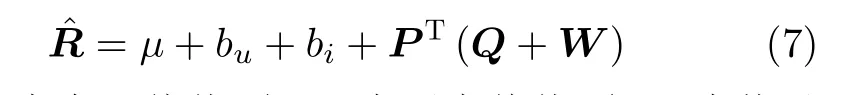
2.4 评论文本和评分矩阵的融合层模块
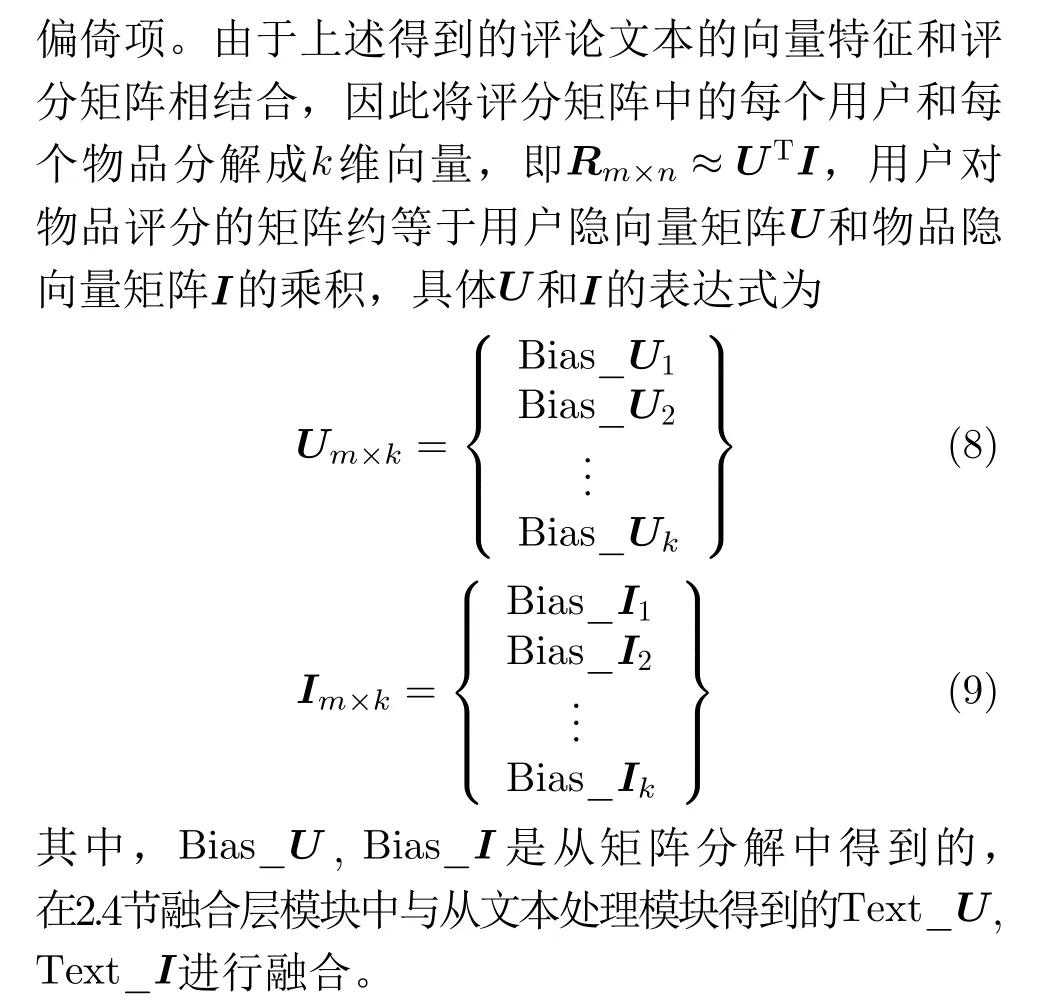
为了将评论文本特征和评分矩阵特征映射到相同的特征空间,本文使用融合层进行耦合得到深度特征,最后通过线性回归得出预测评分。评论文本通过预训练Electra模型、情感分析模型和注意力机制得到了深层次非线性特征向量Text_U, Text_I,评分矩阵通过LFM模型分解得到浅层次线性特征向量Bias_U, Bias_I,为了将两种特征向量进行融合,本文采用因子分解机(Factorization Machine,FM)[15],首先将用户的两种特征Text_U和Bias_U拼接为一个向量z=Text_U⊕Bias_U,其次引入因子分解机计算用户的2次项特征U

2.5 评分预测
根据融合层模块得到的用户和物品的2次项特征,通过全连接层进行线性组合,得到最终的预测

3 实验结果与分析
3.1 数据集
本文使用的数据集来自https://nijianmo.github.io/amazon网站,它是Amazon.com电商网站评论公共数据集中的6个类型的子数据集,分别为Arts and Crafts, Digital Music, Software, Kindle Store,Luxury Beauty, Video Games。该数据集的主要内容包括用户编号、商品编号以及用户对商品的评分(1-5分)、评论,其中Kindle Store是个大型数据集,共包含2.22×106多条评论;Software数据集最小,含有1.2×104多条评论。具体统计数量见表1。

表1 数据集基本信息
为了让本文模型与对比模型在同一方法下进行性能评估,本文使用MSE作为模型性能的评价指标,它广泛用于推荐系统的评分预测[9]。MSE的值越低,模型性能越好。定义如式(14)所示
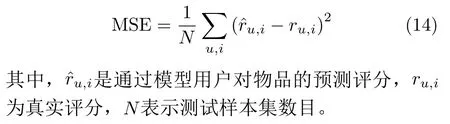
3.2 实验设计
为了评估模型预测评分的性能,本文提出的RTRM模型与以下5种传统方法进行对比实验。
(1) 奇异值分解(Singular Value Decomposition,SVD++)[2]:基于隐语义模型的改进算法,融入用户对物品的隐式行为的奇异值分解模型。该模型没有用到评论文本信息。
(2) HFT[7]:融合评论文本和评分矩阵较为经典的模型,将用户的评论文本集或者物品的评论文本集输入到文档主题生成模型(Latent Dirichlet Allocation,LDA)进行处理,得到了主题后与LFM分解后的用户隐因子和物品隐因子相结合,得到预测评分。该模型的评论文本没有使用深度学习。
(3) DeepCoNN[9]:首个利用深度学习技术对用户和物品的评论文本进行联合建模的模型,性能显著改善。该模型未使用评分矩阵。
(4) NARRE[10]:该模型在DeepCoNN模型的基础上加入注意力机制以区分无用的评论,有效结合了评分矩阵和评论文本,使得模型预测更准确。该模型使用了评分矩阵和评论文本。
(5) 引导偏好的矩阵分解模型(Preference Guided in Matrix Factorization, PMF)[16]:该模型将评论文本输入到LDA得到的主题偏好作为用户潜在因子的引导项,与用户的评分偏好相关联,得到预测的评分。该模型使用了评分矩阵和评论文本。
(6) RTRM模型:本文提出的RTRM模型能够提取评论文本和评分矩阵的深层次特征,并且有效地使用因子分解机将两者结合,使得性能进一步提升。
在实验设置上,本文将数据集随机分成训练集(80%)、测试集(10%)以及验证集(10%),测试集用于模型的性能评估,验证集对各个超参数进行调优。针对以上5种对比模型,本文根据其对应论文所提供的实验代码进行复现,并且根据原文设置初始化参数,使其实现最优的性能。对于为了防止过拟合化,本文使用格子搜索法从[0.1, 0.3, 0.5, 0.7,0.9]中寻找最佳的正则项系数,从[50, 100, 150]中寻找训练的样本数,从[8, 16, 32, 64]确定最佳隐因子数量。对于矩阵分解模型SVD++,经过调优过程后隐因子数k为10。对于HFT以及PMF,隐因子数设置5或10时,大部分的误差趋于稳定,因此本文将隐因子数设置为5,正则参数为0.5。基于深度学习的DeepCoNN, NARRE模型以及本文模型RTRM,在[0.005, 0.01, 0.02, 0.05]范围内寻找最佳学习率。由于超参数过多,针对不同的超参数的设置,实验效果往往不同,所以本文在3.4节对这些参数进行灵敏度实验分析。对于DeepCoNN,NARRE模型使用预先训练好的glove中300维词向量,将CNN组件中卷积核的大小设置为3,个数为100;RTRM使用Electra模型的版本为Electrasmall,隐藏单元数为256,层数为12,为了更好地对比,本文参照NARRE模型的一些参数的设置,每个用户和每个商品的评论集文本截取长度覆盖90%的用户,用户和商品拥有最多的评论分别为10条和20条,注意力向量权重a的维度设为400,因子分解机中参数yi的维度为6,近邻用户个数设置为60。
3.3 模型性能对比
本文模型和对比模型的评分预测结果如表2所示,可以看出融入评论的模型(除了SVD++模型)通常比只考虑评分矩阵作为输入的协同过滤模型(SVD++)性能更好,因为评论文本是对评分矩阵的补充,能够提高潜在因子的表现质量;其次,融合评论文本中利用深度学习技术的模型(DeepCoNN,NARRE, RTRM)也会优于利用传统方法的模型(HFT, PMF)。研究[9,17]表明使用神经网络分析文本信息比主题模型分析能获得更好的性能,然后传统方法只能使用线性特征,而深度学习可以以非线性的方式对用户和物品进行建模,还能避免一些影响精度的问题从而提高性能,比如使用dropout抑制过拟合,因此融合评论文本和评分矩阵是一个值得研究的重要领域;本文模型对比结果优于其他模型,评论文本虽然能帮助提高性能,但是如何利用文本使评分结果最优化也是需要考虑到的,比如和NARRE模型进行对比,平均预测误差提高了2.385%,NARRE模型采用Word2Vec和CNN进行结合,而Word2Vec产生的词是静态的,不考虑上下文,从而不能解决一词多义的问题,使得准确度不高,而本文提出的RTRM模型使用预训练的Electra解决静态词向量的问题,并结合深度情感分析及注意力机制实现从上下文语义层面对评论文本的分析,融合带有近影响力的评分矩阵,实验结果表明RTRM模型具有更优的性能。
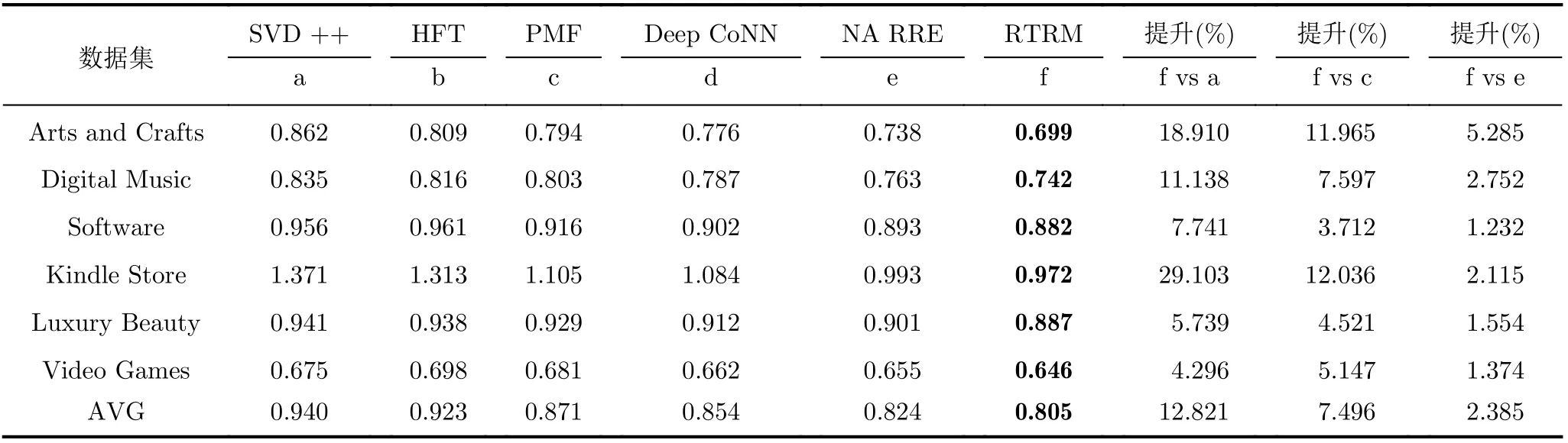
表2 RTRM模型与其他模型的性能比较
3.4 参数灵敏度分析
本节主要讨论验证集中参数设置的问题,由于篇幅有限,本文只展示两个数据集的表现,即Digital Music和Software数据集。以下将从4个方面来验证本文模型的有效性:不同隐因子数量对RTRM模型的影响;不同dropout比率对RTRM的性能的影响;RTRM模型在不同近邻用户个数条件下的差别;获取近邻用户个数时采用余弦相似度和云模型的影响。
首先讨论隐因子数量对模型的影响,在设置的对比模型中,对于HFT, PMF等主题模型而言,隐因子的数量等于主题的个数,但是隐因子对主题模型影响不大[16],因此在实验中省略;对于SVD++,DeepCoNN, NARRE, RTRM等矩阵分解模型和深度学习模型,用户和物品的隐向量长度就是隐因子个数。隐因子数量对模型的影响的实验结果如图3所示,明显看出,RTRM模型在两个数据集上的不同隐因子数下性能优秀,在隐因子数为16时性能最好。并且SVD++模型的性能随着隐因子数量的增加显著下降,出现过拟合现象。

图3 不同隐因子个数对模型性能的影响
其次,讨论不同dropout比率对RTRM的性能的影响,dropout是基于深度学习的技术,如果设置恰当的值可以缓解过拟合现象,会使性能得到提升。图4显示了DeepCoNN, NARRE, RTRM在不同的dropout比率的表现,可以看出RTRM模型在两个数据集上的最佳dropout比率为0.5,并且比率在Digital Music上表现更稳定,本文认为原因是Digital Music的数据长度大于Software,模型可以学习到更稳定的参数。
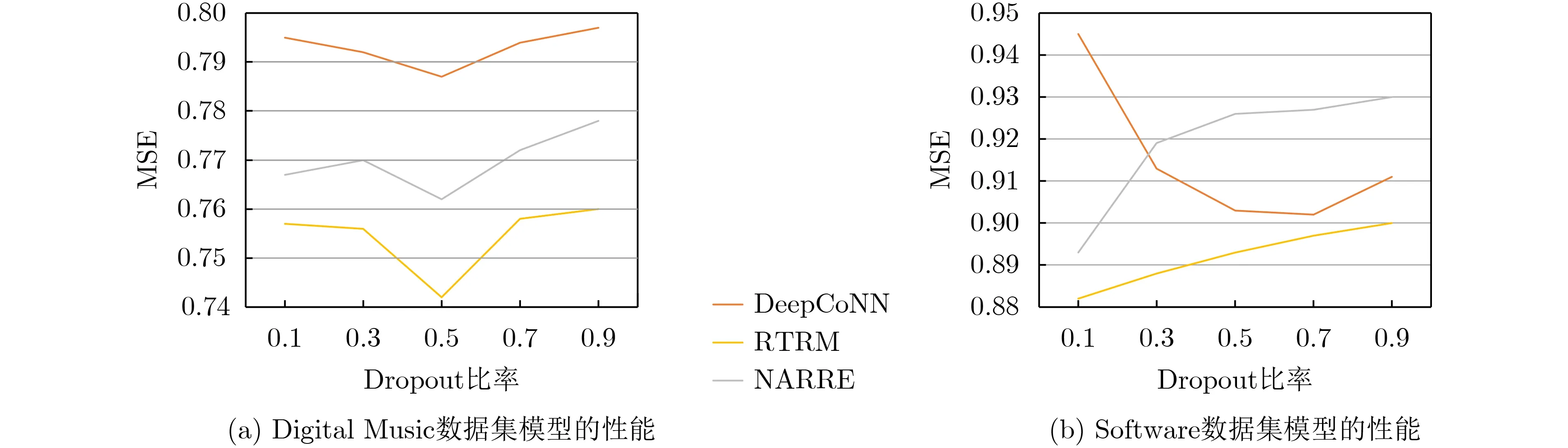
图4 Dropout比率对模型性能的影响
由于对比模型都未使用近邻用户的因素,RTRM模型与基于用户相似度的协同过滤方法(Collaborative Filtering Method Based On User Similarity,UBCF)[2]进行对比,验证不同近邻用户个数对它们的影响,如图5所示,直观看出在近邻个数为60个时,RTRM模型显示的MSE指标最低,并且RTRM模型性能优于UBCF算法,所以增加近邻用户的影响力潜在地提高用户推荐准确性,但是推荐精度不会随近邻用户的数目增加而提高。

图5 不同近邻个数对模型性能的影响
最后,在获取近邻用户个数时比较采用余弦相似度(cosine similarity, cos)和云模型(cloud model,cm)对模型的影响,如图6所示,在近邻个数为60时取得最优的性能,并且RTRM模型相对于余弦相似在使用云模型时性能更好,因为对于“冷门”物品,用户间的共同的评分较少甚至没有共同的评分,使用余弦相似度得到目标用户的近邻用户准确性会降低,但是云模型是从统计学的角度根据用户的评分趋势来求得近邻用户,从而有效地避免了冷启动问题。

图6 余弦相似度和云模型对模型性能的影响
4 结束语
本文提出了融合评论文本和评分矩阵的RTRM推荐模型,首先使用深度情感分析对评论文本进行深层特征提取,解决了短文本语义难以分析的不足;然后结合近似用户影响力的矩阵分解模型对评分矩阵进行浅层特征提取,其次将深层特征和浅层特征进行融合,有效地缓解了数据稀疏性的问题,提高了推荐精度;最后在6组亚马逊数据集上与多种相关的模型进行性能对比实验,结果表明,本文提出的RTRM模型能降低实验的误差,推荐质量有进一步的提升。
对于今后的工作,有几个方向可以做进一步研究:(1)在矩阵分解中本文加入近似用户影响力解决冷启动问题,但是用户影响力是具有时效性的,研究关于时效性影响力的模型改进矩阵分解模型;(2)对于评分矩阵还可考虑融入社交网络进行特征提取,或者采用深度学习模型来提取评分矩阵中的动态特征。
