基于多样化局部注意力网络的行人重识别
2022-02-24徐胜军刘求缘孟月波刘光辉韩九强
徐胜军 刘求缘 史 亚 孟月波 刘光辉 韩九强
①(西安建筑科技大学信息与控制工程学院 西安 710055)
②(人工智能与数字经济广东省实验室(广州) 广州 510320)
1 引言
行人重识别(Re-IDentification, Re-ID)旨在从非重叠多摄像机获取的图像或视频数据库中查询特定行人,即给定一幅行人图像后在图像库中跨设备检索其所有图像,在视频监控、安防等领域有重大应用价值。近年来,基于深度学习的Re-ID方法能够获得显著优于传统方法的识别性能,成果丰硕[1,2]。然而,跨摄像机场景下行人图像存在视角和姿态变化,加之光照、遮挡等因素影响,Re-ID技术离实用尚有很大距离。
局部遮挡和姿态变化是影响Re-ID性能的两大因素。遮挡不仅造成了行人部分身体信息的丢失,还引入了额外干扰,不利于行人特征的有效提取;行人姿态的多变性及行人检测算法的误差会造成身体各区域不能很好地对齐,进而导致特征匹配时存在较为严重的未对齐问题。因此,在复杂应用场景下,全局式表示学习[3]和度量学习[4]的鲁棒性与泛化能力较弱。为了获得更加精细且完整的行人特征,基于“全局+局部”思想的判别式特征学习日益流行,可分为基于姿态估计、基于图像分块、基于注意力机制等的Re-ID方法。
基于姿态估计的方法利用行人的姿态信息缓解未对齐问题。Zhao等人[5]先用改进的CPM(Convolutional Pose Machines)算法获取14个人体关节并将其分成7组(对应7个身体区域),由此实现对齐;然后将整幅行人图像和各身体区域作为输入,依次通过特征提取和特征融合网络,将全局和局部特征有机地结合起来。Zheng等人[6]先用CPM获得14个关节和14维置信度向量,并按关节分成10个身体区域,进而将其组合为多种PoseBox,在空间结构上实现了对齐;接着将整幅图像、PoseBox和置信度向量输入网络获取姿态不变特征。这两种方法均需进行姿态估计,从而带来额外的计算开销。因此考虑计算效率,Li等人[7]以离线训练方式进行关节定位和身体区域生成。利用姿态估计可精确定位人体关键部位,但模型的训练成本一般较高。基于图像分块的方法将行人图像刚性地划分为多个局部块并从各块中学习特征表示。Sun等人[8]提出PCB(Partbased Convolutional Baseline)模型,其首先将行人特征图从上至下均匀地划分成6块,然后对各块分别计算分类损失以便学习局部特征。PCB模型未充分考虑未对齐问题,因此Luo等人[9]对特征图分块后,通过计算两幅图像局部特征之间的最小距离实现块与块之间的动态匹配,从而在不引入附加监督信息的情况下缓解未对齐问题。Wang等人[10]提出MGN(Multiple Granularity Network)模型,其具有多个网络分支且各分支采用不同的分块数用以提取粗略的全局特征和细粒度局部特征。虽然分块法可以获得丰富的局部特征表示,但刚性划分方式可能把具有完整语义信息的特征强制分成不同部分,造成匹配错误。基于注意力机制的方法利用注意力机制引导模型关注判别特征。Song等人[11]利用图像分割方法分离行人与背景并生成对应的二值掩码,继而提出MGCAM(Mask-Guided Contrastive Attention Model)算法从人体和背景区域学习对比特征,从而抑制背景干扰。Zhang等人[12]设计了RGA(Relation-aware Global Attention)模块,先计算特征图中所有特征点之间的成对相关性并将相关向量堆叠后作为全局结构信息,然后结合特征点本身所包含的外观信息推断注意力强度,有助于遮挡或姿态变化时的语义推理。王粉花等人[13]直接将注意力模块嵌入骨干网络以增强特征学习能力,并对不同深度的特征进行采样融合,使网络具有较强的预测能力。Yang等人[14]采用多分支网络,各分支利用类激活图定位人体的不同区域,并提出一种重叠激活惩罚损失函数约束不同分支类激活图的激活区域,引导各分支关注身体不同部位的语义信息,挖掘局部特征。注意力机制法无需额外的定位模块和图像刚性分块即可获取行人的显著性特征,是当前Re-ID研究的热点方向。
上述基于注意力机制的Re-ID方法虽然性能良好,但都只利用了蕴含人体结构信息的全局特征或蕴含语义信息的局部特征,而从整体上挖掘最显著的区域特征容易忽略部分关键局部细节和次显著的区域特征,不能有效应对遮挡、姿态及视角变化等问题。鉴于此,本文提出一种基于多样化局部注意力网络(Diversified Local Attention Network,DLAN)的行人重识别模型。首先,利用多个局部注意力网络(LAN)自适应定位行人图像中的多个显著区域,从而使网络学习到不同的语义信息。然后,构造了一致性激活惩罚(Consistency Activation Penalty, CAP)函数来确保多个局部注意力网络的高激活区域不重叠,从而使得网络所学到的局部特征保持多样化。最后,将全局特征和多样化的局部特征进行集成,得到按人体结构上对齐的行人特征表示。针对遮挡、姿态及视角变化问题,所提模型能够有效提取最具判别力的“全局+局部”特征。为验证算法性能,在几个广泛使用的Re-ID数据集上开展了实验,结果表明DLAN的总体性能优于对比方法。
2 多样化局部注意力网络
基于注意力机制,本文提出多样化局部注意力网络(DLAN)模型如图1所示,其包含主干网络、多分支LAN、分类识别网络和CAP网络4个模块。图1中,Fg表示全局分支的输入,Fk表示第k(k ∈{1,2,...,K},K为分支总数)个LAN分支的输入(为简化绘图,图1给出的是K=3的示例),F*′′表示全局或局部分类识别网络的输入,f*表示归一化特征,w*表示LAN生成的激活图,L*表示各种损失函数;GAP(Global Average Pooling)代表全局平均池化,BN(Batch Normalization)代表批量归一化。关于图1 中各符号的详细阐述见后文。此外,为便于算法描述,假设训练集为S={(xi,yi)}Ni=1,其中xi表示第i幅行人图像,yi ∈{1,2,...,C}为xi的标签,C和N分别表示行人个数和训练集大小。下面分别对每个模块进行详细介绍。
2.1 主干网络
对于深度学习网络,随着深度的增加,网络的学习能力理论上也会增强。但由于退化问题,网络越深梯度消失现象越明显,训练误差也越大。为此,He等人[15]提出了残差网络(Residual network,Resnet)架构,其易于优化,且很好解决了退化问题。由于深层特征蕴含丰富的语义信息,所以现有Re-ID方法首选Resnet作为骨干网络,本文亦是如此,如图1(a)所示。Resnet50包含1层卷积层(Conv1)和4个残差模块(Conv2~Conv5),每个残差模块又包含了多个卷积层、BN层和ReLU(Rectified Linear Units)激活函数。为了获得更全面的行人特征表示,在Conv4后将网络分成多个分支,分别作为全局分支和局部分支的输入,并且在Conv5中不再进行下采样操作。具体地,将行人图像输入骨干网络后,所获得的特征图记作F ∈RD×H×W,其中D,H和W分别表示特征的通道数、高和宽,Fg和Fk均等于F。
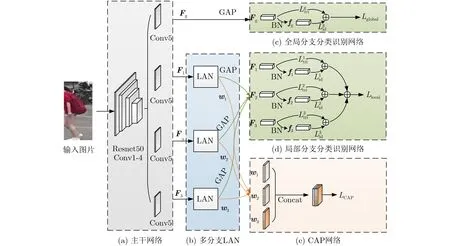
图1 DLAN模型架构
2.2 多分支LAN

2.3 分类识别网络

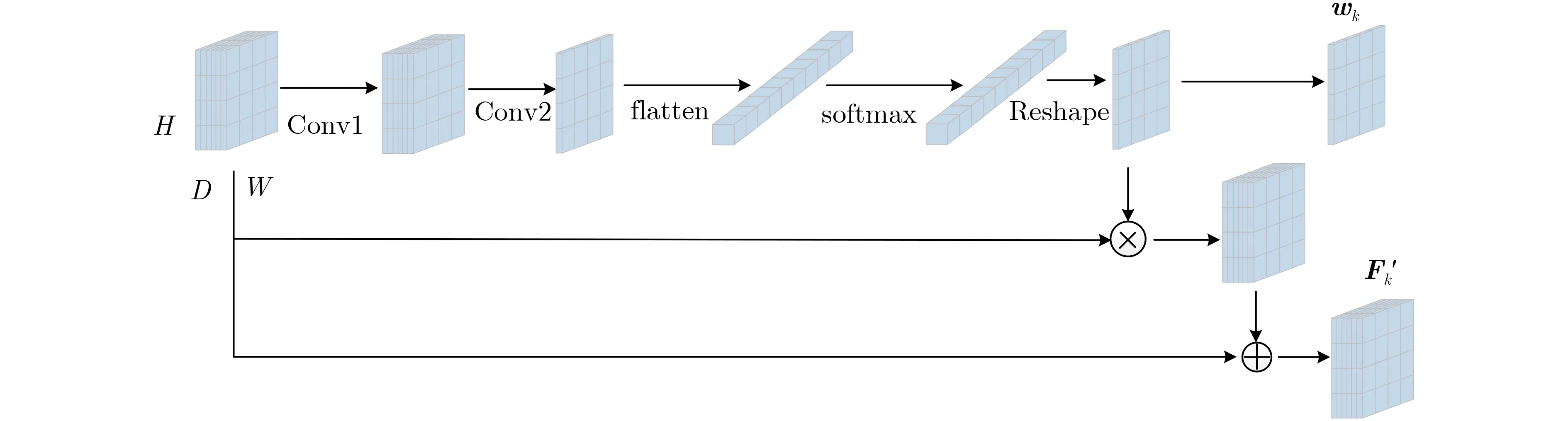
图2 LAN结构图

2.4 CAP网络
对于给定行人图像,若对多分支LAN模块不加约束,会造成各分支趋同化,即多个LAN模型很容易关注到相同的显著区域,从而忽略其他同样具有判别能力的次显著区域。所以,在模型训练过程中需确保K个分支各自关注图像的不同区域,即每个局部分支特征响应的高激活区域不同。为此,提出了CAP网络以实现局部特征多样化,这正是DLAN模型的核心所在。简言之,CAP网络利用LAN输出的空间注意力权重wk引导各局部分支聚焦于人体不同的显著区域。具体地,本文采用海林格[17](Hellinger)距离H(·)度量任意两个LAN分支输出的wi和wj的一致性,即

2.5 DLAN模型的目标函数
综合图1(c)—图1(e)模块的损失,DLAN模型的总目标函数为
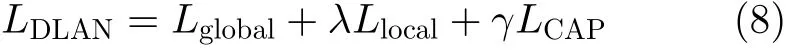
其中,λ和γ是各损失项之间的平衡参数(实验部分将讨论二者的取值对模型性能的影响)。通过求解上式,DLAN模型能够同时学习到全局和局部特征,并且由CAP网络确保所学局部特征的多样化。测试阶段,采用欧氏距离计算查询图像与图像库中各图像之间的相似度,并对齐按降序排列,从而得到重识别精度。
3 实验结果与分析
本节将通过各类实验验证所提算法(DLAN)的有效性。所有实验采用PyTorch深度学习框架,GPU工作站的配置为:Intel Core i7型CPU,32 GB内存以及12 GB显存的1080Ti显卡。
3.1 数据集和评价标准
本文利用4个常用的Re-ID数据集开展实验,即M a r k e t 1 5 0 1[18], D u k e M T M C-r e I D[19],CUHK03[20]和Partial REID[21]。每个数据集事先划分为训练集和测试集,而测试集又分成图像库和查询集两部分。其中,Market1501共包含6个摄像头下1501个行人的12936张训练图像和23100张测试图像,DukeMTMC-reID共包含8个摄像头下16522张训练图像和19889张测试图像,CUHK03共包含10个摄像头下7365张训练图像和6732张测试图像,Partial REID则共包含300张训练图像和300张测试图像。
Re-ID方法的标准性能评价指标包括平均精度均值(mean Average Precision, mAP)和累积匹配特性曲线(Cumulative Match Characteristic,CMC)的第1匹配率Rank-1,因此本文也采用这两种指标衡量DLAN模型从图像库中检索待查询行人图像的能力。
3.2 网络参数设置
对于DLAN模型,输入图像的大小为256×128;模型训练过程中,采用随机水平翻转和随机擦除实现数据增强。批大小设置为64,共学习120轮,三元组损失参数δ设为0.3,初始学习率设置为5×10—4,在第40轮和第70轮时分别衰减为5×10—5和5×10—6。为保证比较的公平性(算法比较见3.4节和3.5节),超参数λ与其他同类方法[10,22]保持一致,设置为1。为确定分支数k和超参数γ的最优或较优取值,以Market1501数据集为例,图3和图4分别给出mAP和Rank-1指标随k值(1~6)和γ值(0.01~10)的变化曲线图。

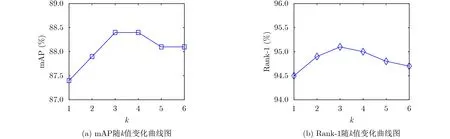
图3 Market1501数据集上mAP和Rank-1随k值变化曲线图
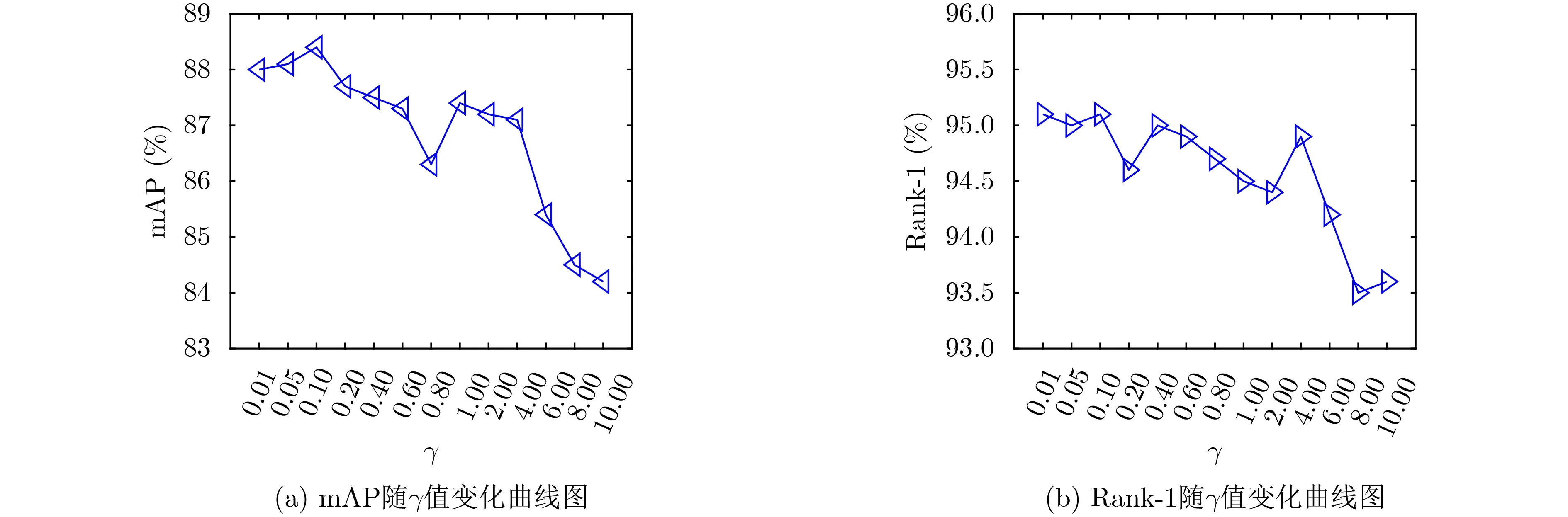
图4 Market1501数据集上mAP和Rank-1随γ 值变化曲线图

3.3 消融实验
为验证DLAN模型各模块的作用,本小节在Market1501数据集上开展消融实验,表1给出各网络变种的详细配置(“G”表示全局分支,“3L”表示3个局部分支,“—”表示无)。以文献[3]中搭建的网络作为基线模型(Baseline,只含全局结构),各变种的相关参数设置和训练策略均相同,结果如表2所示。
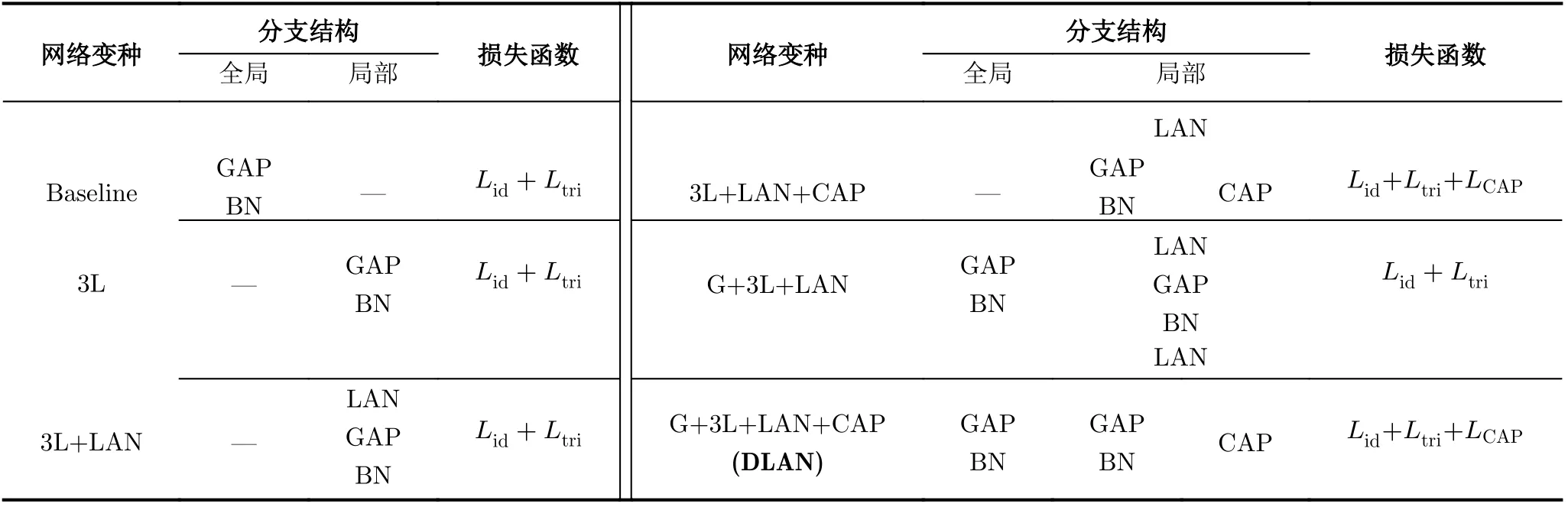
表1 DLAN模型网络变种结构表
分析表2可得:
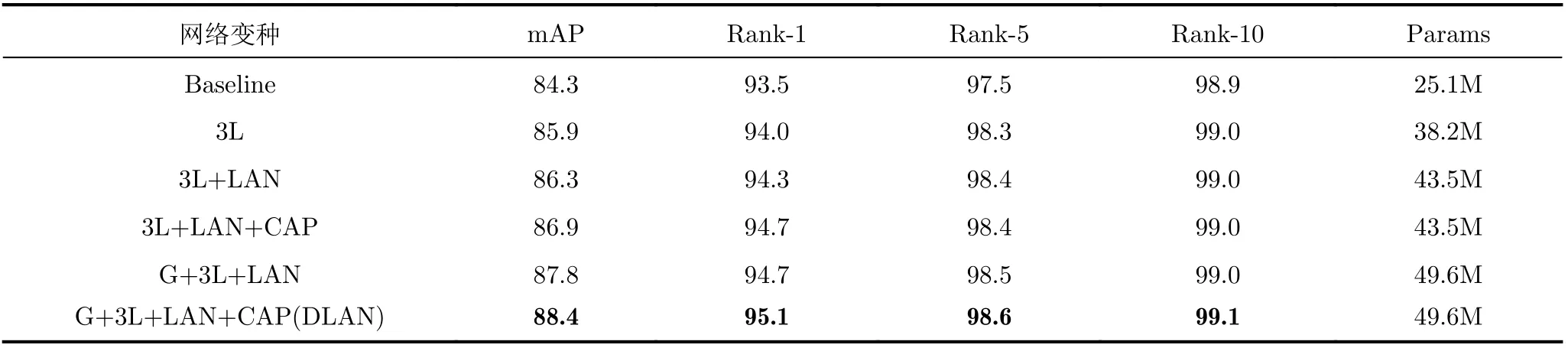
表2 消融实验结果(%)
(1)对比Baseline, 3L和3L+LAN的性能,单一的多分支网络(3L)比仅学习全局特征的Baseline模型提高约0.5%(Rank-1)和1.6%(mAP),表明多分支之间的互补性有利于形成更完整的行人表示。嵌入LAN模型的多分支网络(3L+LAN)比3L网络提升了0.3%(Rank-1)和0.4%(mAP),证明LAN模型能有效地增强网络定位判别信息的能力,因此能学习到更利于辨别行人身份的判别信息。
(2)对比3L+LAN和3L+LAN+CAP的性能,后者较之前者在Rank-1和mAP上分别提升0.4%和0.6%。单一的3L+LAN模型缺乏多样性约束,因此容易造成各分支学习到相同的显著特征。CAP损失能有效地促使多个LAN模型关注非重叠的显著区域(详见3.4节的可视化验证实验),所以性能有所提升。
(3)对比Baseline, 3L+LAN+CAP和G+3L+LAN+CAP(DLAN)的性能,全局网络与多分支LAN联合学习的策略最优。多分支空间注意力网络可以学习到不同身体区域间的互补视觉特征,而全局分支可以学习到人体的整体空间结构关系,从而抑制未对齐和局部遮挡(详见3.5节)的影响。
(4)对比所有网络变种与DLAN网络模型的参数量,模型参数量随着局部分支数量增加而增加,但CAP网络不引入额外参数;DLAN网络模型在具有代表性的Market1501数据集上,模型大小中等,在不考虑部署到终端的情况下,DLAN一定程度上牺牲了空间和时间复杂度,但综合考虑仍然是一个优质方案。
3.4 可视化实验
为进一步验证CAP网络的作用,本小节对Baseline, 3L+LAN+CAP, G+3L+LAN和DLAN模型以及DLAN模型的各个分支的特征图(图1中模块b的输出)进行可视化分析。具体地,在数据集Market1501和DukeMTMC-reID中选出3对图像,分别包括姿态变化、行人未对齐和局部遮挡等行人重识别中常见问题,期望观察到DLAN模型关注人体多个不同部位。如图5所示,DLAN的3个局部分支分别关注人体肩胸、胯和脚等部位,而这些部位的细粒度特征通常十分有利于辨别行人身份。例如,肩部能学习到衣领和背包肩带等语义特征,胯部能提取到上衣与裤子的差异特征,脚部则能得到行人走路的姿态特征和鞋子的语义特征,并且这些部位的特征无论在行人正面、侧面亦或是背面图像中都能提取到。因此,即使行人姿态或摄像头视角发生改变,CAP仍然能够保证DLAN提取特征的多样性、有效性和鲁棒性。
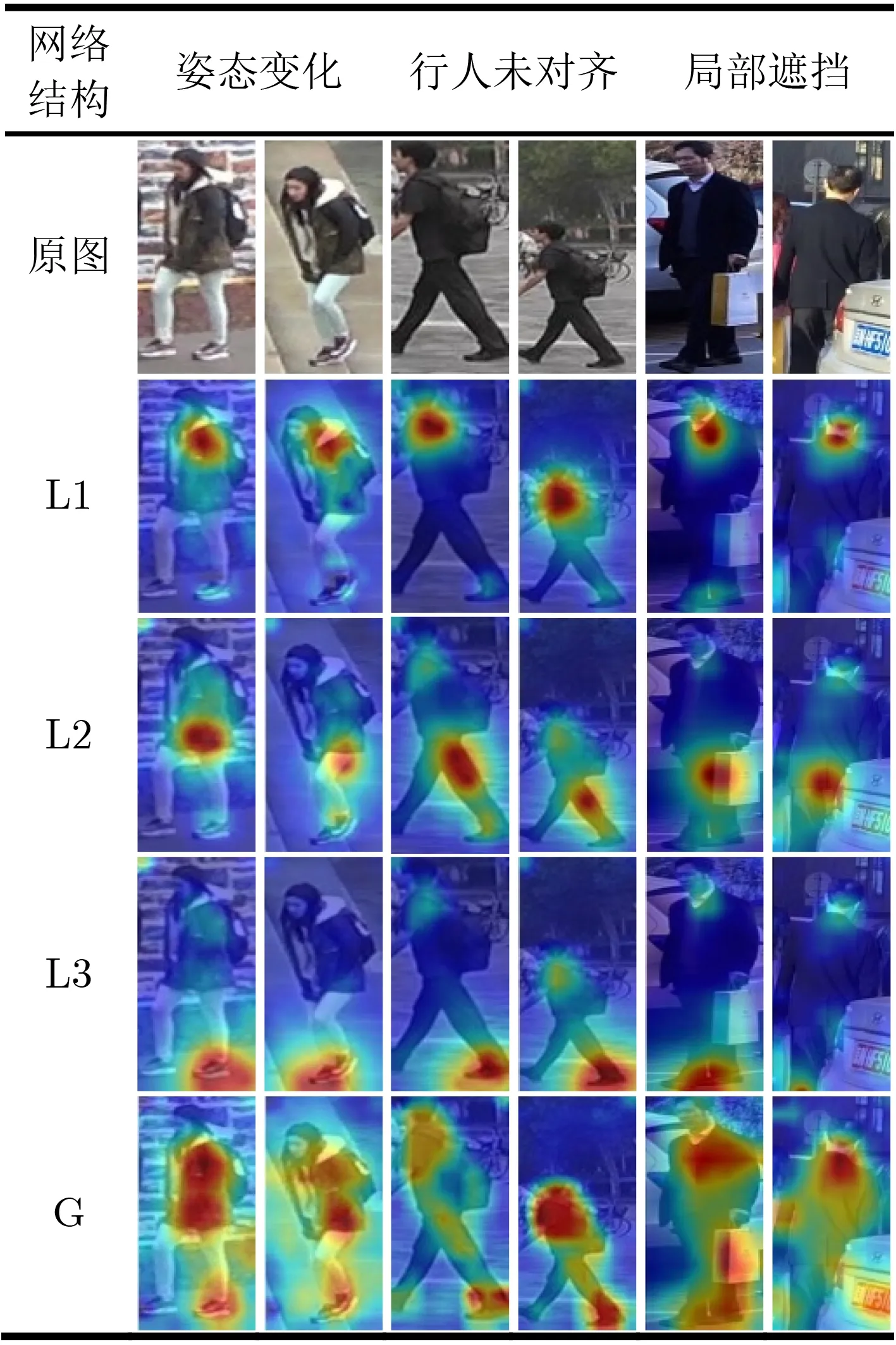
图5 DLAN模型各分支可视化图
如图6所示,与消融实验中的其他网络结构相比,DLAN模型的高激活区域分布范围更集中,并且DLAN模型的次激活区域更准确地覆盖了几乎整个人体区域,能够学习到更完整的行人特征,同时还增强了各局部特征之间的空间关联性。通过特征融合后,DLAN将得到特征对齐的行人特征表示,实现从上到下精准的特征对齐。此外,如图5和图6局部遮挡一栏可视化图所示,当某一局部分支关注的显著区域发生遮挡时,将自适应地变成空分支,减小遮挡物的干扰作用;而其余分支仍然能够学习到足够用以辨别行人身份的特征,并且进行有效特征对齐。结合3.3节和3.5节的定量结果,这些可视化结果验证了CAP网络的功效,既保证了行人特征的多样化和有效性,同时也验证了DLAN模型对于局部遮挡具有较强鲁棒性。

图6 主要网络结构可视化图
3.5 局部遮挡实验
本小节专门针对局部遮挡问题进行实验,以验证DLAN模型在该问题上的有效性。参照文献[23]的做法,对于Market1501和DukeMTMC-reID数据集,我们在查询图像中随机遮挡某区域(高宽比记作s)来模拟真实的局部遮挡场景。将本文提出的DLAN模型与文献[23]提到的方法进行比较,对比算法具体包括NPD, XQDA, IDE, TriNet, PAN,RNLSTMA等(详见文献[23]的引用文献,本文不再列出),其中前两种方法为传统手工特征和度量学习结合的方法,其余均为深度学习法。DLAN模型与对比算法的实验设置保持一致,我们分别比较了不同算法在原始图像(s=0)和随机遮挡图像(s=0.3和s=0.6)上的识别结果,如表3所示(最优性能用粗体表示,对比算法的结果直接从文献[23]获得)。
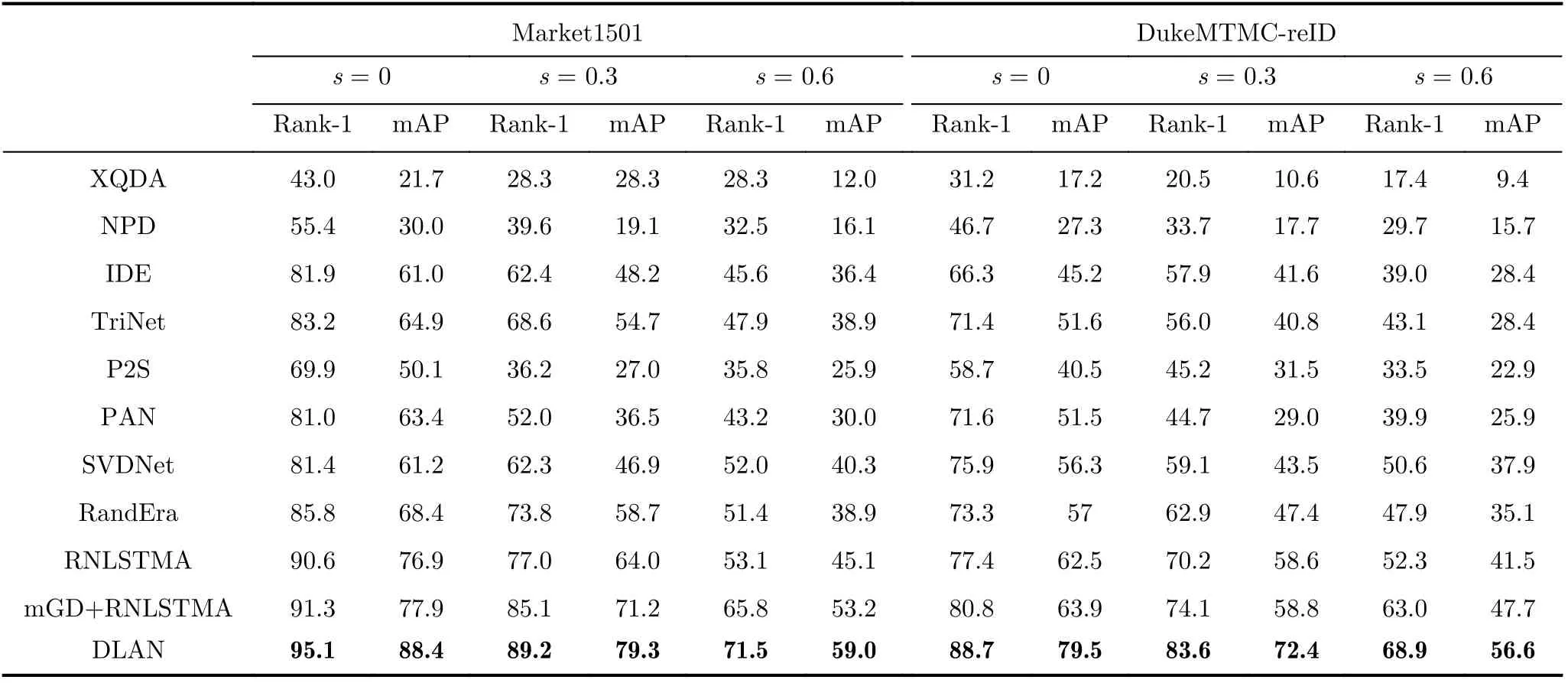
表3 DLAN模型及各对比算法在不同遮挡水平下的重识别结果(%)
分析结果:与基于softmax损失的IDE方法和基于三元组损失的TriNet方法相比,DLAN因联合采用了softmax损失和三元组损失而对遮挡问题具有更好的鲁棒性;与局部式P A N 方法相比,DLAN模型利用多分支局部注意力网络学习细微的局部语义信息,同时还集成了人体的结构信息,所以在遮挡情况下性能更佳;DLAN利用基于海林格距离的CAP网络学习不同区域的特征表示,在小遮挡情况下优于基于空间依赖关系的RNLSTMA方法。对比方法中mGD+RNLSTMA的性能仅次于DLAN,它是基于生成式对抗网络(Generative Adversarial Network, GAN)修复图像的方法,虽然在局部遮挡模拟实验中表现良好,但其效果极度依赖GAN网络的性能,且在实际的遮挡问题中几乎不存在图像修复问题,所以实用性较弱。
此外,本文还在真实且具有挑战性的Partial-REID遮挡数据集上进行了实验。Partial-REID数据集包含不同类型的严重遮挡,实验时遮挡图像作为查询图像,全身无遮挡图像作为图库图像。对比方法包括MTRC[24]、SWM[21]、DSR[25]、SFR[26]、PGFA[27]和VPM[28],图7给出各方法的Rank-1柱状图。由于DLAN学习区域级的特征,即可以实现区域级对齐,从而可以消除来自非共享区域的干扰噪声。所以,在真实的遮挡场景下,本文所提方法具有优异的性能。
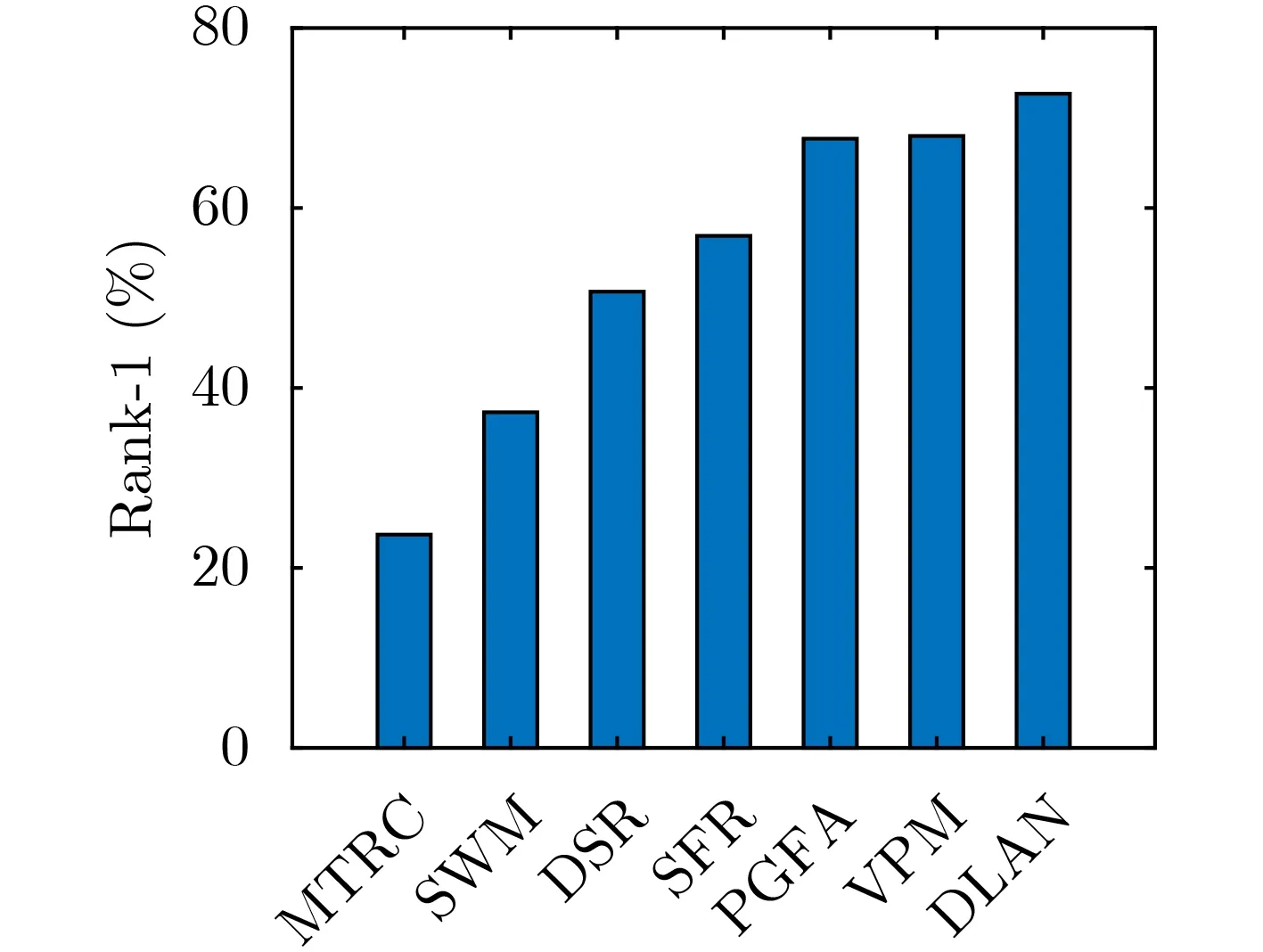
图7 Partial-REID数据集上各算法性能对比图
3.6 与现有方法的比较
本节将提出的DLAN方法与现有的一些先进Re-ID方法进行比较。对比方法包括基于全局特征学习(SVDNet[29], SGGNN[30], MHN[31])、基于局部特征学习(PCB[8], CAM[14])以及全局和局部特征联合学习(CCAN[22], BDB[32])的方法,实验结果如表4所示(加粗表示最优结果,“—”表示无)。

表4 DLAN方法与现有Re-ID方法的性能比较(%)
可见,DLAN模型具有最佳性能。全局法所学习的特征表示通常集中在人体的主干部位,而肢体、腰、足等的信息容易被忽略。局部法则关注某些特定部位,因而在主干部位上的特征学习有所欠缺。此外,局部法在很大程度上依赖所采用的划分机制,基于预定义分区策略的方法往往优于缺乏语义信息的支持而难以确定适当的分区数,由此导致性能提升有限。DLAN模型采用了全局特征与局部细粒度特征联合学习的方法,各分支学习不同的细粒度特征,同时各分支还互相协作,从而将局部区域的判别线索补充到共同的主体部分,使得网络学习到的特征表示具有更优的判别性。
4 结束语
在实际应用场景中,行人重识别面临姿态变化和局部遮挡问题。为此,本文提出了一种基于全局和局部联合学习的多样化局部注意力网络(DLAN)模型,其倚靠空间注意力网络定位和增强显著区域的激活响应,并通过多样化正则约束使得各局部分支聚焦于非重叠的人体部位,从而提升重识别精度。在4个公共数据集上,相继开展了消融实验、可视化实验、遮挡实验以及与现有先进方法的全面比对实验,充分验证了所提方法的鲁棒性和优异的识别性能。在未来工作中,将进一步利用一致性约束获得全局分支的多粒度特征,并考虑学习各特征之间的空间关系,从而获得更高的精度。
