基于类别转移加权张量分解模型的兴趣点分区推荐
2022-02-24刘桂云何熊熊
李 胜 刘桂云 何熊熊
(浙江工业大学信息工程学院 杭州 310023)
1 引言
随着社会信息化进程的不断加速,位置信息服务在社会各行各业中越发普及,这使得基于位置的社交网络(Location Based Social Networks, LBSN)服务成为一项具有重要价值的应用,比如Foursquare、去哪儿网等都是以提供类似服务为主的产品。POI推荐是基于位置的社交网络服务研究中的一项重要内容,它不仅可以一定程度地解决大数据时代用户面临的信息过载问题,而且能够帮助商家快速找到目标用户,实现精准营销[1]。
在如此良好的发展机遇面前,推荐系统面临着许多挑战,比如用户的POI决策过程建模困难、数据稀疏等。传统的推荐算法主要是协同过滤算法,在此算法基础上衍生出了许多推荐模型,例如基于POI排名的因式分解[2]、矩阵分解[3]等。现有研究多利用高阶张量模型代替传统的用户定位矩阵,这有助于解决用户动态签入随时间变化的时间依赖性[4]。但高维张量分解会增加系统的负担,如何权衡信息的维度成了研究的一大难题。
在推荐系统中,用户的显式偏好是结合用户历史行为和地点信息进行分析计算得到的[3],如偏好的时间、类别、位置标签等。除此之外,还有一部分隐式信息需要挖掘,这些隐式反馈往往存在于交互关系中,如连续行为偏好[5]、隐式社交关系[6]等。为此,一些研究会把隐式反馈转化为权重以此降低矩阵维度[6,7],或者把从信息中提取的影响因素纳入模型中减少数据稀疏[8,9]。
事实上,使用隐式反馈来探索POI推荐是具有挑战性的,因为学习过程需要一种有效的策略。例如在挖掘用户连续行为偏好时,利用不同层次上的类别转换来对用户的偏好转换进行建模[5],能减缓利用POI之间的转换进行建模[10]带来的稀疏性。但是由于用户的移动性,推荐区域多有不同,此类模型在捕获POI的语义相关性上需要考虑更全面的影响因素才能给游客带来更多便利。
在一个不熟悉的区域中,旅行者和POI之间的交互是非常稀少的,但其兴趣在家乡与所到城市之间存在着漂移和转移的现象。将兴趣漂移和兴趣转移结合起来,利用用户跨城市的访问行为可以改善所到城市的POI推荐[11,12]。其次,通过引入POI的显式信息[4,8]或者借鉴朋友的偏好影响[6],也可以缓解所到城市用户POI交互的稀疏性问题。那么,为了有效地利用社会和空间相关性,可以把兴趣的漂移和转移现象同显式和隐式信息中提取的影响因素结合起来,根据当前位置进行分区域推荐。
综上所述,对推荐系统的现有研究可以在模型、类别转化、影响因素以及分区域推荐4个方面进行突破。本文提出一种新型的基于加权张量分解模型的兴趣点分区推荐算法,主要贡献有以下3点:(1)对签到信息中蕴含的显式信息和隐式信息进行用户标签和地点标签的划分,改善时间、类别和朋友特征的提取方法,更好地把影响因子融合到不同的推荐区域中。(2)对张量构造进行改进,把隐式反馈中的用户连续行为偏好与类别信息结合作为模型的权重信息,加入到用户-时间-类别张量中,此做法不仅综合了用户、时间和类别这3维信息,又充分考虑到历史访问信息的权重影响。(3)基于用户的移动性特征,把候选类别与提取的特征相融合进行分区POI推荐:依据用户当前位置与常驻地之间的距离把推荐场景细粒度化,划分出本地推荐和异地推荐,再匹配不同的影响因素做不同区域的推荐。发挥各类影响因素特点的同时,也使得预测用户的下一步偏好更精准。
2 预备知识
2.1节分析如何改善从显式和隐式信息中抽取特征的方法。2.2节是文章整体框架的图示。
2.1 相关性分析
2.1.1 时间特征分析
人们的行为在特定时间会有特定变化,即实时性,而且具有持续性[13],因此在兴趣点推荐中加入时间分析是必要的。大多数文章对于时间区域的划分为均匀24段[14],这忽略了用户出行习惯的不确定性及事件的持续性,而且会额外增加数据维度。从种类信息中选取6个具有时间象征性的类别,如图1(a)横轴坐标所示,分别对应为:1→专业场所(professional & other places)、2→办公楼(office)、3→博物馆(museum)、4→体育场(stadium)、5→户外休闲(outdoors & recreation)、6→夜生活场所(nightlife spot),可以看出,用户在工作日和休息日的类别访问占比有所不同,这说明在工作日和休息日,用户的兴趣侧重不同。由Foursquare数据集中用户的访问分布可知,人们的活动轨迹大多集中在3个时间段,示例如图1(b)所示。本文把用户每天的时间活跃范围划分成3个时间段:“7:00~15:00”,“15:00~21:00”,“21:00~7:00(次日)”。综上所述,本文根据工作日、休息日和3个时间段划分6个时间标签,既减少数据稀疏性,又具有兴趣针对性。比如用户1会在休息日7:00~15:00时间段运动,用户2会在工作日21:00~7:00(次日)时间段现身酒吧。
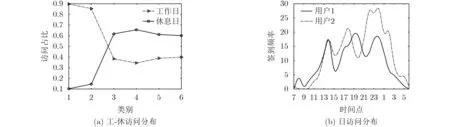
图1 时间特征划分示例
2.1.2 类别特征分析
本文将类别信息和连续行为结合作为类别预测模型的权重信息,在捕获用户兴趣的同时可以简化信息维度。在连续POI推荐的问题上,以往的研究多使用1阶马尔科夫链来建模[10],但此模型仅依赖用户最后访问的兴趣点,不考虑其历史访问。而实际中,每个用户有其独特的历史访问序列,对新兴趣点的访问概率也参考历史访问信息。因此本文引用一种基于高阶序列的模型—加权马尔科夫链模型来研究用户的连续行为,为此构造基于加权马尔科夫链的类别转移权重,定义为WTC,它将考虑签到历史中所有签到点对新兴趣点访问概率的影响。
加权马尔科夫链是在转移图的基础上构造的,而基于类别访问序列的转移图相对于地点转移图更具有泛化度[9]。在类别转移图中,把一个节点的转出频率定义为Cout,转移频率定义为CTrans。如图2所示,对于酒店这个节点,其转出频率有8次(Cout为8),转入餐饮节点5次,转入大型交通工具节点2次(CTrans为7)。给出目标用户的类别访问序列,用户对新兴趣点的转移权重如式(1)所示

图2 类别转移图示例
2.1.3 朋友特征分析
随着网络科技的发展,人们社交中“朋友”间的交互不断地丰富着个人的兴趣偏好,因此隐式社交关系在推荐系统中应用的越发频繁,且用户与“朋友”间的信任关系有助于提高推荐系统的性能[15]。“朋友”的签到频率z遵循幂律分布[6](Powerlaw Distribution, PD),其概率密度函数如式(3)所示

兴趣朋友指社交网络中兴趣相投的人群,其位置分布广,但在同一时间段有相似的爱好。兴趣朋友的定义是为适应异地推荐的场景,如式(6)所示

2.1.4 位置特征分析

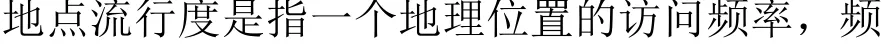

2.2 框架构造
本文的整体框架分为3部分,如图3所示。
图3 框架图
3 类别预测
本文构造用户-时间-类别3维张量,并且从隐式反馈信息中提取用户连续行为偏好,将其作为类别转移权重加入张量分解中,然后优化分解过程得到类别预测列表。
3.1 张量构造
张量构造可解决用户动态签入行为的时间依赖性[16],本文根据用户在某个时间场景下的特定喜好,分析出时间类别对,构造用户-时间-类别张量R。
3.2 张量分解模型
本文采用张量分解中的Tucker分解,其原理是通过分解高维张量,生成稠密的预测张量来逼近原始张量,填补空缺值,从而生成推荐,如图4所示。
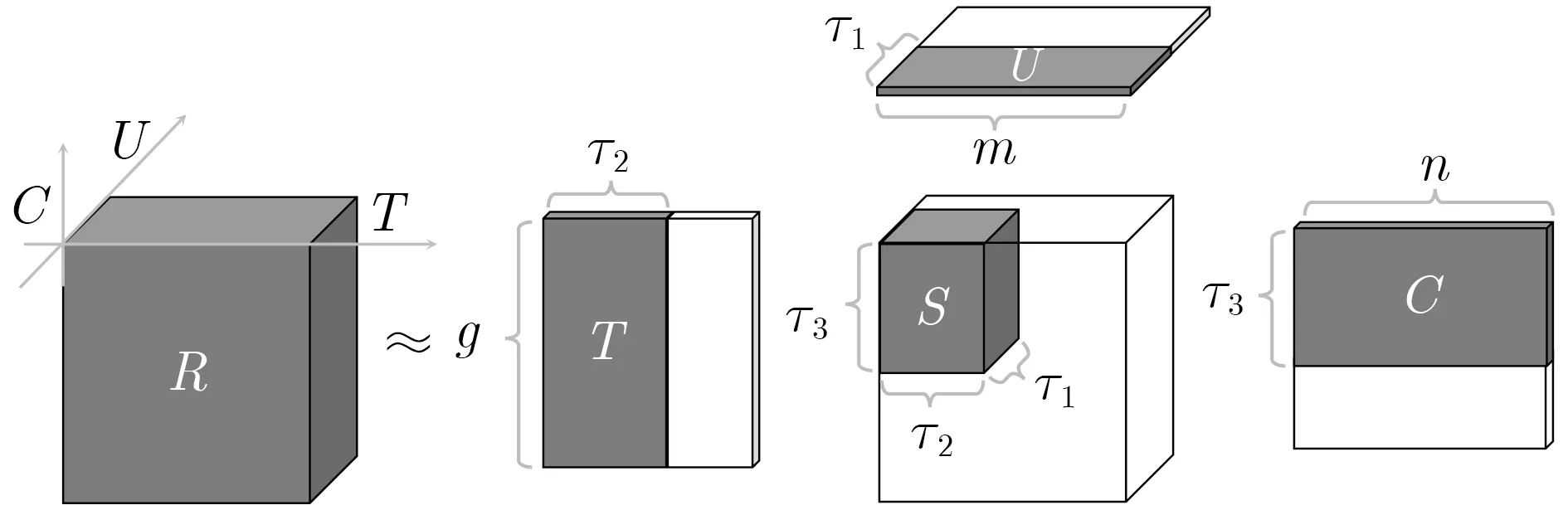
图4 截断Tucker分解:秩-(τ1,τ2,τ3)近似

4 分区推荐
用户访问位置的概率不仅受距离影响,而且还受到位置固有特性的影响[11]。因此,用户的实际签到位置分布在不同区域,且潜在影响因子多有不同。本文将POI推荐细粒度化:本地推荐和异地推荐。
本文用K-means聚类算法将每个用户签到信息中的经纬度聚类得到一个中心作为每个用户的常驻地 loc;然后以此中心设置距离阈值f,若当前位置cur与常驻地l oc的距离小于该阈值,则推荐场景为本地推荐,否则为异地推荐。如图5所示,这是某个用户的历史访问记录,虚线圈之内定义为此用户的本地范围,之外则为异地范围。
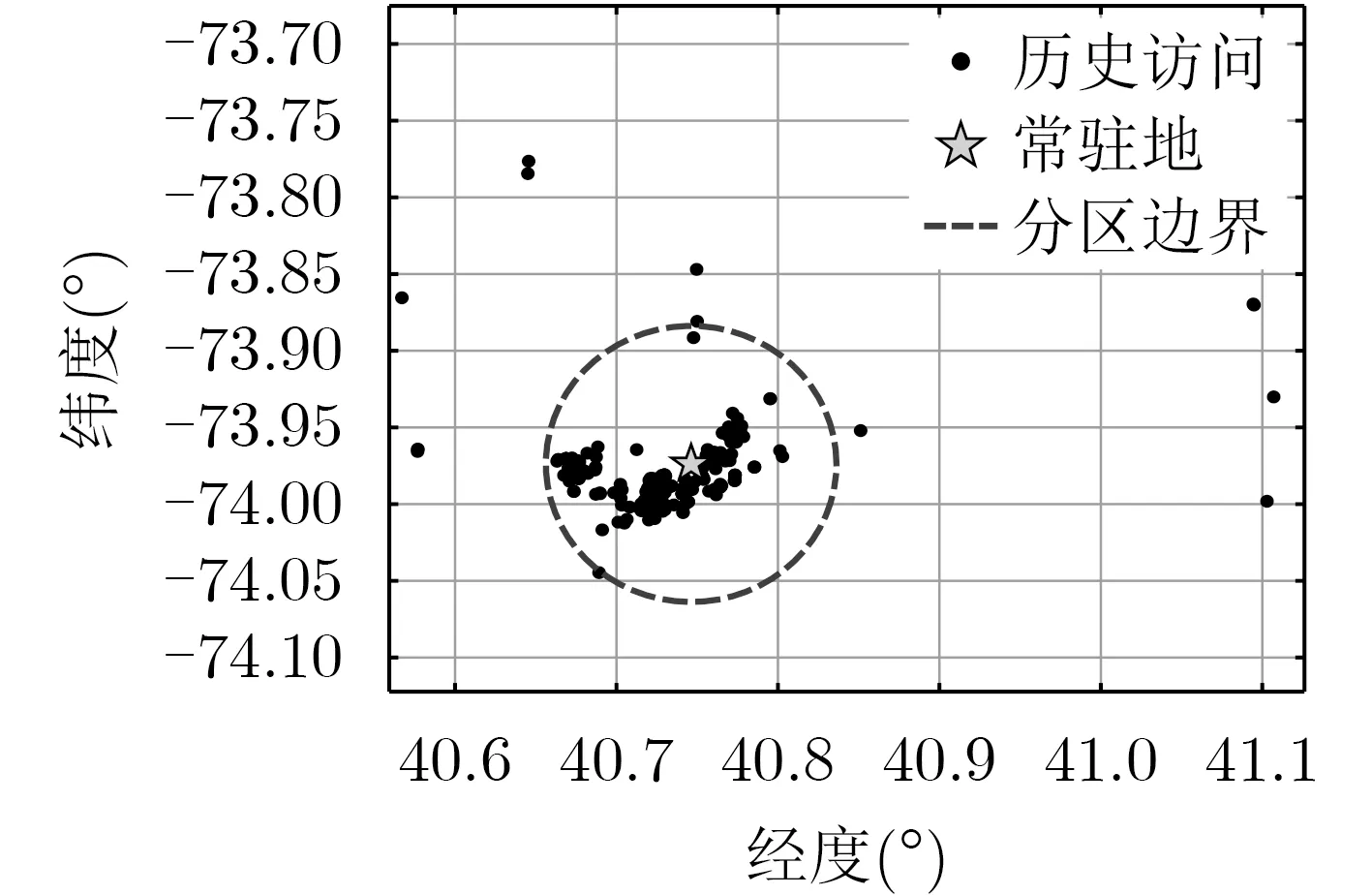
图5 用户区域划分示例
首先,将式(12)的类别预测分数进行排序,获得目标用户的类别预测列表C。再构造目标用户的二分图[18]BG=(U~,Vc,E),其中U~表示目标用户的朋友集合用户,Vc是U~中用户在预测类别列表中访问过的位置,E表示用户和位置之间的关系连接,如图6所示。
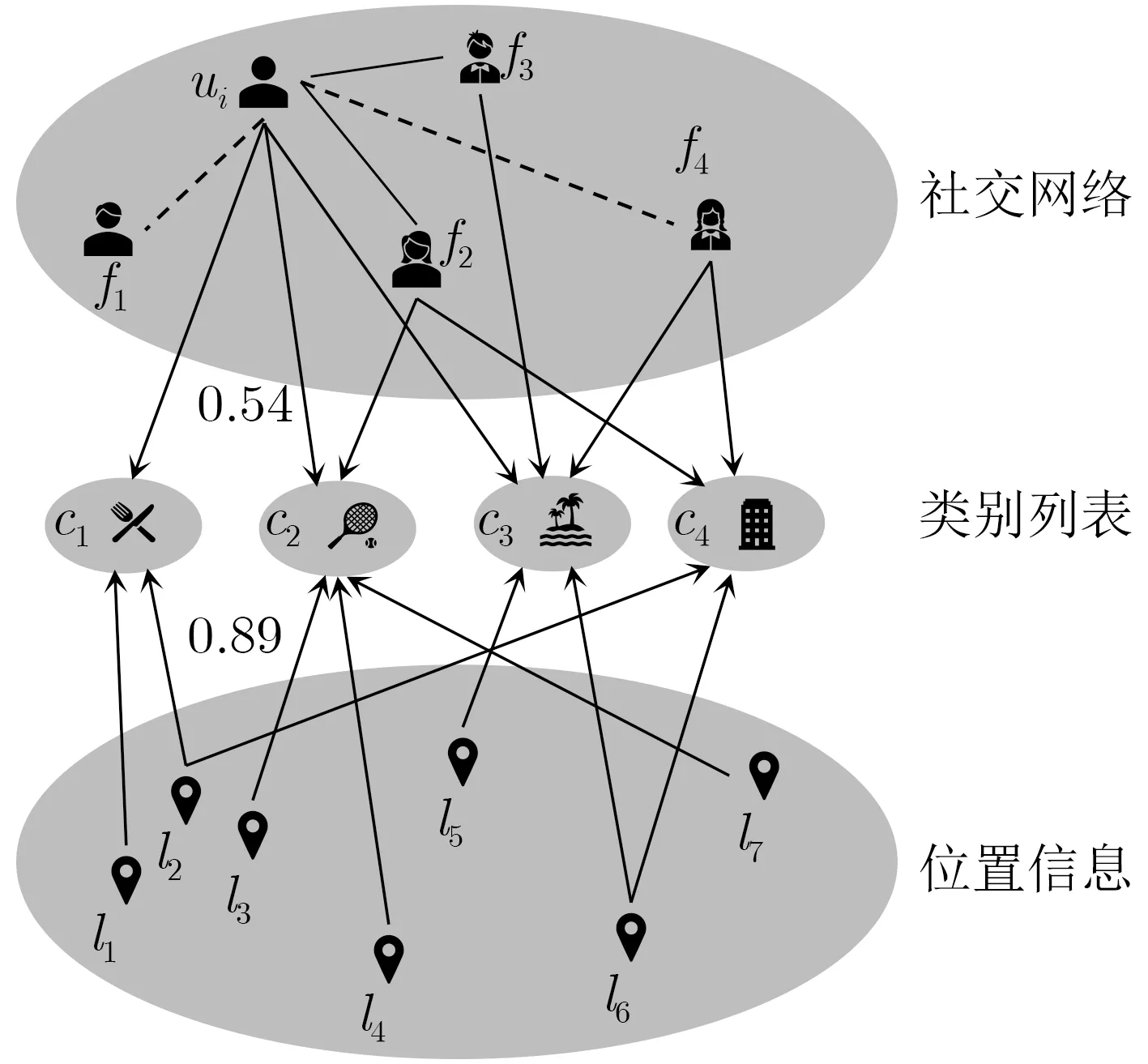
图6 二分图示例

表1 类别预测算法
然后在不同的区域,匹配不同权重的影响因素。最后,结合式(5)—式(8)和二分图 BG,得到用户对下一个地点的访问概率Score如式(13)所示


5 实验总结
5.1 数据集
Foursquare是一种基于地理位置信息的社交网络,它记录了用户的签到信息,例如用户信息、地点经纬度等,而且基于此网络的数据集多用于推荐系统的评测。本文的两个数据集是由Foursquare用户在加州(CaliforniA, CA)和纽约州(New York, NY)两个特大地区生成的,包含了用户在2012年4月至2013年4月期间发布的信息,其中同时包含的类别信息和具体的时间信息,符合本文实验所需要的数据标签且方便数据预处理,分布如表2所示。在数据的预处理阶段,去掉签到记录少于10条的用户以及少于5个用户访问的地点,以此缓解用户的朋友关系。然后在每个用户中随机选择70%的签到信息作为实验的训练数据,30%作为实验的测试数据。

表2 数据集统计分布表
5.2 评价指标

5.3 实验结果对比分析
本文提出的基于类别转移加权张量分解模型的兴趣点分区推荐算法(Weighted Tensor Decomposition Partition Recommendation algorithm,WTD-PR)将与以下5种算法作对比:
(1) Augmented Square error based Matrix Factorization (ASMF)[6]:基于平方误差的矩阵分解算法,该算法融合了3种朋友影响以及地理影响。
(2) Geographical Factorization Model based on POI Ranking (Rank-GeoFM)[2]:基于POI排名的因式分解算法,并且融入地理和时间因素。
(3) POI recommendation based on Tensor Decomposition model (TD)[4]:基于张量分解模型并融合多维信息的兴趣点推荐算法。
(4) A LOcation REcommendation algorithm that incorporates Geography, Friends and Popularity factors (GFP-LORE)[8]:融合了序列信息、地理、朋友和流行度因素的推荐算法。
(5) Location neighborhood-aware Weighted pro-babilistic Matrix Factorization (LWMF)[7]:位置邻域感知加权概率矩阵分解算法,从位置的角度挖掘地理特征,将其作为隐式反馈权重。
为了验证本文算法在兴趣点分区推荐上的有效性,我们进行了无差别推荐、本地推荐和异地推荐这3种验证实验,其在k为5、10、15、20、25、30的情况下的精确率和召回率如图7所示。相比于无差别推荐,本地推荐和异地推荐的推荐性能在不同的k值上都处于领先状态,这说明本文的模型在推荐层面更具有针对性,不同的场景中融入合适的影响因素,提高了推荐数据的有效性,缓解数据稀疏问题的同时提升人们的旅行体验度。
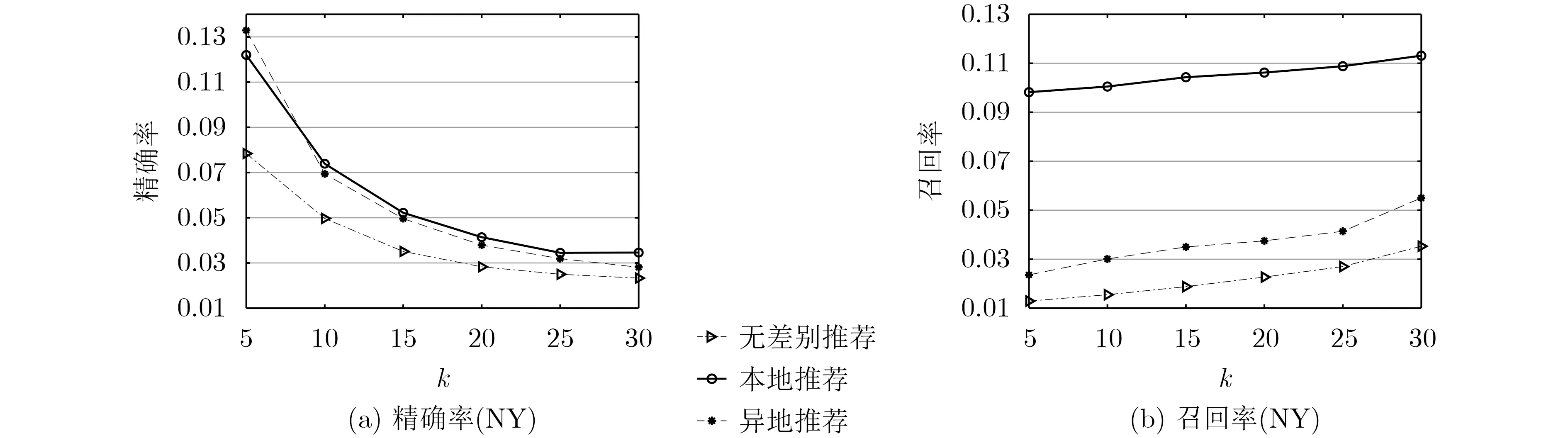
图7 分区推荐的优势对比
在不分区推荐中,本文训练出一个α值,满足与其他算法的性能对比方式,α取0.69。实验数据如图8所示,无论是在哪一个区域,本文算法的性能都有较大的优势,且相对于POI的直接推荐,类别预测在系统冷启动问题上更有话语权。本文算法与LWMF和GFP-LORE这两种算法作对比,证明了高阶张量分解应用于推荐系统的优势:张量填补减缓了数据稀疏性,且降低了信息的维度。TD模型和WTD-PR模型的对比,充分地显示了权重的重要性,本文的权重分析是依据加权马尔科夫链的序列转移原理,这同时说明用户连续行为的特征和历史访问记录对于人们的下一步访问有着很大的主导作用。
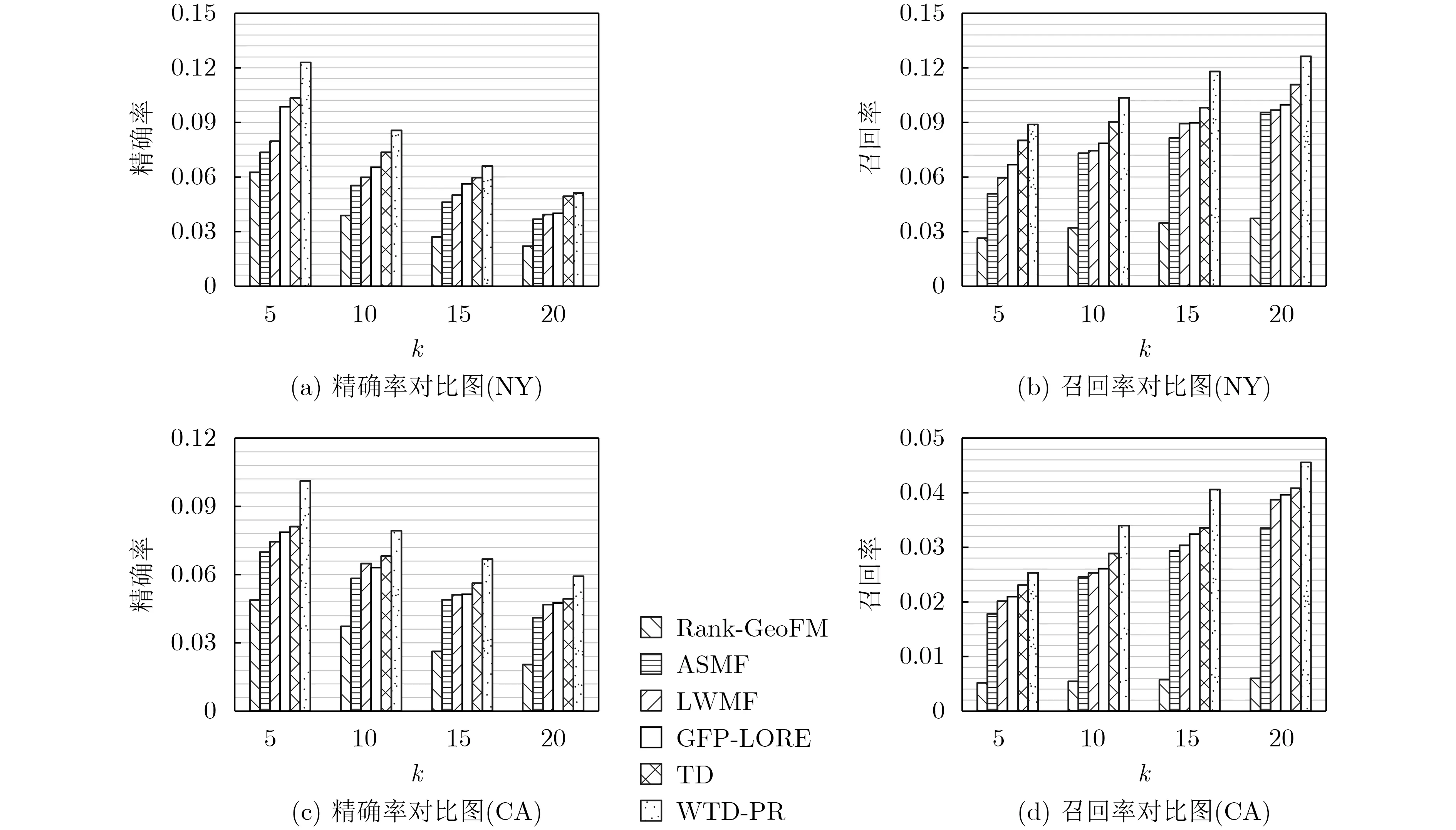
图8 算法性能对比
除了以上两种实验场景,本文还做了消融实验。其中对比算法分为2类5种:(1)在类别预测模块消除信息维度:不融入时间信息(WTD-T),不融入类别信息(WTD-C);(2)在类别预测列表的基础上融合不同影响因素:融合朋友和距离因素(WTD-FL),融合朋友和地点流行度因素(WTD-FP),融合位置和地点流行度因素(WTD-LP)。对比结果如表3所示,第1类算法的性能指标没有第2类的高,这表明时间和类别信息对模型性能的影响较大,与现实中人们在不同的时段会有不同的喜好侧重现象相吻合。在第2类算法中,WTD-LP算法的指标相对较低,这说明社交关系在推荐模型中有很大的权重占比。相对于这两类算法,WTD-PR考虑多维上下文信息,分配其合适的权重,获得了最优的性能,这表明推荐系统中上下文信息的重要性。此外,在该实验中,去掉不同的数据标签,本文模型仍具有较好的性能,这说明本文模型能适应标签种类不同的相关数据集。

表3 多维因素有效性验证
6 结束语
本文研究了一种基于类别转移加权张量分解模型的POI分区推荐算法。在类别因子上融入加权马尔科夫模型,生成类别转移权重;构造基于用户-时间-类别的加权张量,利用梯度下降算法进行迭代更新,推选出候选类别;再把位置信息中隐藏的距离因素、流行度因素以及朋友因素与候选类别进行融合,作基于用户当前位置的POI分区推荐,并在无差别推荐、不分区推荐和消融实验中做了对比分析。实验表明,本文算法在多维信息融合和张量改进方面做了很大的突破,提升了性能也增加了通用性。
