基于XGBoost和SHAP的急性肾损伤可解释预测模型
2022-02-24叶文玲
罗 妍 王 枞 叶文玲
①(北京邮电大学计算机学院(国家示范性软件学院) 北京 100876)
②(北京邮电大学可信分布式计算与服务教育部重点实验室 北京 100876)
③(中国医学科学院中国协和医科大学北京协和医院肾内科 北京 100730)
1 引言
急性肾损伤(Acute Kidney Injury, AKI)的特点是在48h内肾功能迅速下降[1],患者主要表现为血清肌酐(Serum Creatinine, Scr)升高或尿量减少[2]。根据2012年改善全球肾脏病预后组织(Kidney Disease: Improving Global Outcomes,KDIGO)提出的诊断标准,AKI被定义为48小时内Scr增加至少26.5μmol·L—1(0.3 mg·dL—1)或达到基线值的1.5倍及以上,且明确或经推断上述情况发生在7d之内,尿量减少小于 0.5mL·(kg·h)—1,且时间持续6h以上[3]。AKI在各种临床环境中都会经常遇到,占重症监护病房(Intensive Care Unit, ICU)患者的20%~50%[4—6],住院患者的5%~7%[7,8]。此外,AKI还与高死亡风险相关,与无AKI的患者相比,患有AKI患者的死亡风险增加了7倍[9]。有研究称在ICU,AKI患者的死亡率高达10.3%~26.5%[10—14]。美国的住院数据显示,AKI造成每年估计47~240亿美元的费用[15]。
有研究表明,AKI分期越高,需要肾脏替代治疗的患者越多,病死率越高[16—18]。也有越来越多的证据表明,即使AKI在症状上治愈,其长期慢性肾病、心血管疾病和死亡的风险也会增加[19—21]。因此,早期识别AKI风险患者,并对AKI高风险患者进行早期干预,对于减少AKI的发病率、有效缩短疾病进展并降低死亡率上具有重大意义。
在AKI概念出现之前,常用的概念是急性肾功能衰竭(Acute Renal Failure, ARF),为了强调早期肾损害在诊断标准中的重要性才被AKI取代[22]。而早期诊断和干预可延缓AKI进展为严重阶段和出院后慢性肾病的发展[23]。考虑到AKI的高死亡率和早期发现的重要性,临床医生需要新的方法在显著肾损害发生之前早期预测AKI。
近年来,机器学习(Machine Learning, ML)算法在疾病预测模型中应用广泛,有研究发现可以利用Scr水平和现有的临床指标来预测AKI的发生。Flechet等人[24]对252名危重患者进行了前瞻性研究,并将医生对AKI预测的结果与基于随机森林算法的AKI预测模型进行了比较,发现AKI预测模型能筛选出高危患者和减少假阳性率,并能比医生更早提供预测。
但目前流行的AKI风险预测模型主要关注提高模型的准确性,而对模型解释的关注较少,这阻碍了机器学习模型在临床实践中的应用[25,26]。因此,为了支持临床医生的决策,有必要在保持准确预测的同时理解和解释这些关系。然而,同时实现良好的可预测性和可解释性是具有挑战性的,因为许多预测模型通常是“黑箱”的,而可解释的模型通常具有较差的预测性能[27]。为此,本文的目标是开发一个可进行AKI早期预测的可解释模型,重点是模型解释,并期望该模型能广泛应用于临床。
本文的结构如下:第2节介绍本研究的相关工作。第3节将深入讨论XGBoost(eXtreme Gradient Boosting)和SHAP(SHapley Additive exPlanation)。第4节和第5节对AKI风险预测模型的结果和性能进行分析和讨论,并通过SHAP提供综合特征解释。最后,对研究结果、优势和局限性进行详细的讨论。
2 相关工作
疾病的早期预测可以在支持医疗卫生专业人员方面发挥重要作用,据统计,11%的医院死亡是由于未能及时识别和治疗病情恶化所致[28]。近5年来,ML方法在准确、及时预测AKI高危患者方面发挥了重要作用。例如,Flechet等人[29]开发并验证了随机森林预测模型,成功预测了成年ICU患者的AKI,受试者工作特征曲线下面积(Area Under the receiver operating characteristics Curve,AUC)达到0.84。
Mohamadlou等人[30]使用梯度提升算法以生命体征和Scr为特征预测重症AKI,AUC值在第48小时和72小时分别为0.76和0.73。次年,Lei等人[31]也使用同样的机器学习模型来识别术后出现AKI的患者,最终模型的AUC为0.82。此外,Koyner等人[32,33]开发并在最近对其梯度提升算法模型进行了外部验证,该预测模型对48小时内1期AKI的预测AUC值为0.67。
Simonov等人[34]利用来自同一卫生保健系统中3家医院的169859名成人住院患者的回顾性数据开发了一个简单的逻辑回归模型,并证明基于现有实验室数据的简单模型可以准确预测AKI, AUC为0.74。
Xu等人[35]用ML模型(逻辑回归、随机森林和梯度提升算法) 对58976例重症监护病房AKI患者的死亡风险进行预测,发现梯度提升算法的AUC为0.75,在预测死亡率方面优于其他模型。
Zimmerman等人[36]对23950例成年危重病患者进行了研究,建立了逻辑回归预测模型,用于入ICU 72 h后AKI的早期预测,AUC为0.78。
Rashidi等人[37]开发并内部验证了ML模型,比较了50名烧伤和51名创伤患者的AKI早期识别。他们的递归神经网络模型能够提前62h准确预测AKI,AUC为0.92。
如前所述,大多数模型的AUC表现一般[30,32—35],而一些研究集中于特定的患者群体,如心脏手术患者[31],或研究样本量小[37],从而限制了这些模型的使用。此外,从表1可以看出,目前大多数研究中使用的特征向量非常繁琐,收集和计算也很复杂。这些研究大多缺乏模型可解释性,只有有限的解释提供简单的特征重要性结果。相比之下,本文在前期研究的基础上,使用公开可访问的包含超过46000名患者的去识别健康数据的重症监护医学信息数据库MIMIC(Medical Information Mart for Intensive Care)III进行数据分析和模型开发[38],最后基于XGBoost算法构建了重症监护病房患者的AKI早期预测模型,并比较了XGBoost与其他4种流行的机器学习技术的性能。模型中仅使用常见的生命体征和实验室检测指标,通过有效的数据预处理和XGBoost模型参数调整,取得了良好的AKI早期风险预测性能。然后,利用SHAP 估计的Shapley值从全局和局部两个角度对预测模型进行解释。解释结果不依赖所使用的预测模型,这保证了结果的可靠性并为解决临床问题提供更多的证据支撑。这些成为这项工作的主要贡献。
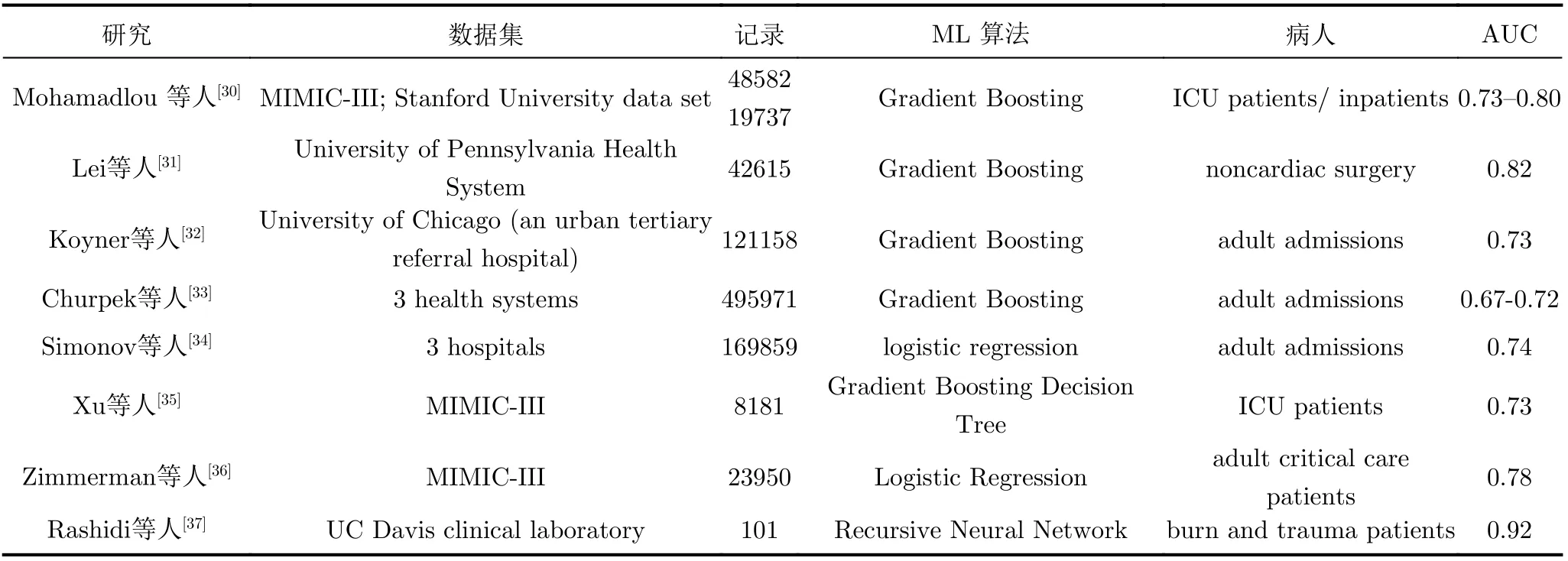
表1 既往研究结果表明ML技术可以有效地用于AKI预测
3 方法
3.1 数据源
本研究中属于回顾性队列研究,数据来源于一个公开的、大规模的重症医学数据库——MIMICIII。该数据库由麻省理工学院计算生理学实验室开发,整合了2001年至2012年贝斯以色列女执事医疗中心46520例成年ICU患者所有连续的匿名综合临床数据,为重症医学科医生开展临床研究提供了极大的便利[38]。
本研究的目的是预测ICU患者AKI的发生。我们使用KDIGO诊断标准对AKI进行定义[3],在48 h内Scr水平达到基线值的1.5倍及以上或增加0.3 mg/dL。考虑到AKI分期的特异性较差[39],以及我们的数据集中缺乏足够符合要求的尿量数据,因此本研究排除了尿量标准。基线值定义为入院后24 h内首次Scr测量值。为明确早期、亚临床的患者生理基线恶化是预测AKI的重要原因,使患者得到及时的治疗,本研究主要使用第1天的生理变量检测值来预测未来48 h内ICU住院患者发生AKI的风险。在19001例ICU记录中,共提取出4532例满足以上条件的AKI病例。
3.2 特征变量提取
本研究的主要结果是入院后3 d内AKI的发生率。其时间窗示意图如图1所示,Pt(Prediction time)表示预测时间,Et(Event time)表示AKI发生时间,即Pt发生后48 h。

图1 数据提取时间间隔示意图(AKI的确诊时间窗为ICU入院24 h后)
其中Et的预测结果被编码为一个二元分类的因变量,分为两类:0(患者在Et期间未出现AKI)和1(患者在Et期间出现AKI)。为了预测AKI的发生,本文根据ICU常用的疾病风险预测评分系统(如Apache, SAPS等)、专家意见和数据集可用变量情况,从MIMIC III数据库中提取了患者的24 h临床资料记录,包括患者的年龄、性别、Scr、生命体征和实验室化验结果,以及每小时尿量、24 h尿量等。为了更好地理解数据,表2列出了AKI疾病组和正常对照组两组变量的分布情况(百分比)。该分析是在预处理任务之前进行的。
3.3 数据预处理
由于AKI事件的发生与时间相关,这给数据提取和使用带来了障碍。在MIMIC-III数据库中,一些与时间相关的特征测量结果缺失,缺失值的百分比高达60%以上。此外,表2的数据表明,AKI患者和非AKI患者的类别比例极不平衡。这两个问题使得AKI早期预测模型的准确预测和解释变得更加困难。因此,处理缺失的值并解决类别的不平衡十分重要。

表2 各变量在基础数据集中的分布情况(%)
与大多数临床和实验室数据集一样,本文的基础数据集包含缺失值,例如,与平均动脉压、心率、体温、肺泡-动脉氧梯度、红细胞比容、白蛋白和胆红素相关的时间序列有55%~90%的数据缺失。考虑到这些变量的重要性,我们仍然保留着它们。对于这些缺失值,我们首先分别用均值和中位数来填充,但两者的效果都很差。在严重缺失的情况下,中位数甚至更不可靠。使用平均值填充的优点是不会造成严重的数据失真,并且可以保证填充后的平均值不会发生太大的变化。但在严重缺失数据的情况下,这种填充会导致整个样本信息量大幅减少,破坏数据的随机性。因此,当严重缺失的特征很重要时,将缺失的特征作为一个类别来处理是十分有效的,这样可以既保留特征又保证数据的无偏估计。本文没有对缺失的数值进行任何插补,因为缺失值的估算并不能都为以电子健康记录为基础的预测模型提供一致的改进效果[40]。
如表2所示,正常组纳入14469条病例,AKI病例入选仅4532条。非AKI比AKI的比率接近3:1,即该数据集的分布是高度不平衡的。目前一般采用过采样和欠采样技术来处理不平衡数据。并且由于欠采样技术往往会导致大量数据的丢失,从而导致模型精度的下降[41]。所以,过采样方法通常是首选。SMOTE(Synthetic Minority Oversampling Technique)是一种常用的过采样方法,它通过线性插值的方法在两个少数类样本间合成新的样本,从而有效缓解由随机过采样引起的过拟合问题。本研究使用了Chawla等人[42]提出的SMOTE方法来平衡数据。
最后,由于本文使用的数据集中原始数据的取值范围已经确定,为了保持原始数值之间的关系,我们选择了Min-max归一化方法将我们的数据特征值归一化到[0,1]的范围。
3.4 预测模型
本研究使用XGBoost算法对ICU患者发生AKI的风险进行建模。XGBoost最初由Chen和Guestrin在2016年提出[43]。XGBoost是一个集成分类器,它通过将多个决策树模型进行集成来增强分类能力。也就是说,需要将多棵树的得分相加得到最终的预测得分(每次迭代,都在现有的树上添加一个新的函数,拟合上一轮预测结果与真实值之间的残差)。为了尽可能大地降低目标函数,XGBoost使用了2阶泰勒展开来自定义损失函数,可以在不选定损失函数具体形式的情况下,仅通过输入数据值就能进行叶子分裂优化计算,即将损失函数的选取和模型算法优化分开了。这种去耦合增加了XGBoost的适用性,可以使其更为精准地逼近真实的损失函数。XGBoost在许多领域都有出色的表现[44,45],并显示出更高的预测精度和更快的处理时间,同时计算成本更低,复杂性更低[43,46]。这些特性正好适合在预测AKI时应对稀疏和高维临床数据的需要。XGBoost在应用机器学习方面的优势在于其极高的精度和速度。在本研究中,我们还将XGBoost与其他4种常用的ML算法,包括逻辑回归(Logistic Regression, LR)、支持向量机(Support Vector Machine, SVM)、随机森林分类器(Random Forest, RF)和人工神经网络(Artificial Neural Network, ANN)的性能进行了比较,以验证XGBoost是否能够提供最佳性能。
3.5 参数调整
根据Chen等人[43]的研究,XGBoost模型的性能可以通过调整参数来最大化。参数调优对于XGBoost防止过拟合很重要,由于本研究中使用的方法是监督学习,而网格搜索是监督学习中调整参数和提高模型泛化性能的有效方法[47],所以我们选择了网格搜索来调整参数以获得最优性能。
网格搜索是执行超参数调优以确定给定模型最优值的过程。手动执行此操作可能会花费相当多的时间和资源,因此我们使用GridSearchCV来自动化超参数的调优,其中“CV”代表“交叉验证”。GridSearchCV 可对估计器的指定参数值穷举搜索,使某些估计器更加有效。在本文中,交叉验证后的最佳XGBoost超参数值是:learning_rate: 0.05,max_depth: 6, n_estimators: 700, min_child_weight: 1, gamma: 0.6, colsample_bytree: 0.7, subsample: 0.9, reg_alpha: 0.1,reg_lambda: 3。
本研究中所有的预测模型和相关分析都是使用Python3.7中的开源库(scikit-learn, XGBoost和SHAP) 在Jupyter notebook平台上进行的。
3.6 模型评估
本文将数据集随机分为训练集(70%的队列)和测试集(30%的队列),预测AKI风险的模型仅使用来自训练集的数据建立,针对训练集进行不重复抽样随机分为5份。每次都用其中4份来训练模型,余下的1份用来验证4份训练出来的模型的准确率,重复该步骤5次,直到每个子集都有一次机会作为验证集,其余机会作为训练集。计算5组测试结果的平均值作为模型精度的估计,并作为当前5折交叉验证下模型的性能指标。交叉验证可以在一定程度上减小过拟合,并从有限的数据中获取尽可能多的有效信息。在模型开发过程中,为模型性能的测量提供了一种更加稳定可靠的方法[48]。最后,我们利用剩余的30%测试集进行内部验证,这有利于我们评估训练好的模型在新数据上的表现。
KDIGO定义的1期AKI预测结果是本文的主要结果,本文使用指标受试者工作特征曲线(Receiver operating characteristic curves)下面积AUC评估模型性能。除此之外,我们还引入了以下4个常用指标:准确性(ACC)、敏感度(Sen,真实阳性率,即召回率)、精确率(Pre,阳性预测值)和F1值[49]。其计算方法为


TP,FP,TN,FN分别表示真阳性、假阳性、真阴性、假阴性。AUC为受试者操作特征曲线下面积,而该曲线图是反映敏感性与特异性之间关系的曲线。横坐标X轴为1-特异性,也称为假阳性率(误报率),X轴越接近零准确率越高;纵坐标Y轴称为敏感度,也称为真阳性率(敏感度),Y轴越大代表准确率越好[50]。值得注意的是,考虑到模型的AUC值对预测建模和决策有显著意义,主要表现为高特异性较少引起干预,而高敏感性更容易触发干预[51],因此我们在模型选择和最终报告中使用的主要指标是AUC。此外,为了了解模型性能的不确定性,我们计算了95%置信区间。
3.7 模型解释
尽管机器学习在许多领域取得了巨大的成功,但因缺乏可解释性严重限制了其在现实任务尤其是安全敏感任务中的应用。可解释性在医学领域中是非常重要的。医疗辅助诊断系统必须是可理解的、可解释的,理想情况下,它应该能够向所有相关方解释提供对应决策的完整逻辑,才能获得医生的信任。由于医学数据自有的特点,构建用于医学结构化数据分析的可解释深度学习模型与其他领域中的应用是不同的。本文重点关注SHAP可解释方法在AKI早期辅助诊断模型中的应用。SHAP基于博弈论[52]和局部解释[53],属于经典的事后解释框架,可以提供Shapley值来估计每个特性的贡献。Shapley值是一种描述模型在对特定数据点进行预测时特定特征的“权重”或“重要性”的方法,是SHAP的核心所在。与传统的特征重要性方法(如XGBoost的特征重要性)相比,SHAP具有更好的一致性,可以呈现各预测因子相对于目标变量的正/负关系,用于局部和全局解释[54,55]。对于局部可解释性,每种特征都有自己的一组Shapley值。因此,它可以用来解释每个样本每个特征对预测的贡献,增加了透明度,便于临床医生分析预测模型的可靠性。将所有样本中对应该变量的Shapley值取平均值作为该特征的重要性值,即可得到全局解释。在本文中,通过计算各ICU临床指标的Shapley值来分析各特征与AKI风险的相关性,并结合相关临床研究结果和临床实际表现情况来进行模型解释。
因为Shapley值是解释特征重要性的唯一方法,满足局部准确性和一致性的数学特性,而Tree Explainer 是专门解释树模型的解释器,通过树集成和加法方法激活Shapley值用于特征归因。因此,本文采用mean|Tree SHAP|,一种基于个性化的启发式SHAP平均的全局属性方法,对特征进行排序,以明确模型中的重要预测因素。
4 结果
本研究使用MIMIC III进行数据提取和模型验证。表1为研究样本的统计结果,需要注意的是,在MIMIC III数据集中,我们使用icustay ID作为唯一标识。阴性样本数量通常远远多于阳性样本数量,这是临床数据集普遍存在的问题。基础数据集中包含19001例患者,其中发生AKI的患者4532例,约占23.85%。在这个数据集中,他们的平均年龄(标准差[SD])为64.15(15.96)岁,其中女性为8110例(42.68%)。与非AKI患者相比,AKI患者年龄平均大3岁,女性较少(40.73% vs 43.29%)(表1)。从表1中我们发现AKI患者基础肾功能差,格拉斯哥昏迷评分(GCS)加重,更常伴发糖尿病、肝细胞功能障碍。
4.1 XGBoost 模型
在本研究中,XGBoost是在13001例(70%)随机选择的数据上进行训练的,其余的6000例(30%)用于模型测试。图2为XGBoost模型五折交叉验证的AUC结果。我们可以看到AUC在0.828和0.844之间变化。总的来说,这些指标明显偏高,说明XGBoost可以用于AKI风险检测的建模。XGBoost最终在30%的测试集上测试,最终得到的性能指标为:准确性为0.816,AUC为0.839,再次表明该模型性能稳定,表现显著。XGBoost稳定的高AUC(高灵敏度和高特异性)在其他研究中得到了进一步的检验和验证[56]:如Zimmerman等人[36]认为大多数预测模型的AUC在0.75左右。此外,与Gong等人[27], Zimmerman等人[36]和Li等人[57]的工作相比,本文的模型获得了更好的AUC结果(Gong等人:0.781;Zimmerman等人:0.783;Li等人:0.779)。并且其中两项研究没有进一步研究各特征向量间的详细关系并提供对应的模型解释。

图2 XGBoost模型5折交叉验证的AUC值结果
此外,本文还比较了XGBoost与其他4种流行的ML算法的性能,结果见表3(各模型五倍交叉验证的平均值;括号中的值为95%置信区间)和图3。从测试的5种算法中,XGBoost表现最好。实验结果也表明,其余4种模型各有优缺点。总体而言,集成学习算法的性能优于基分类器,特别是在灵敏度方面。这说明基础算法不适合解决这类复杂的分类问题。
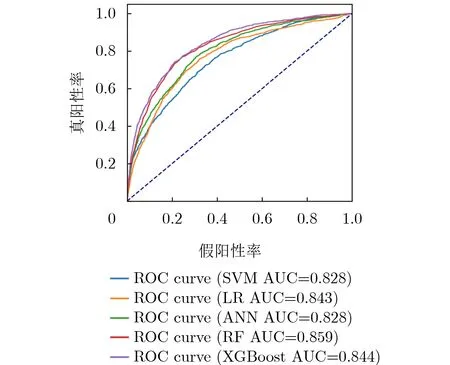
图3 由测试集计算得到的各模型AUC结果

表3 5种AKI风险预测模型的性能比较
4.2 特征重要性分析
除对AKI预测模型的预测能力进行评估外,本文还进一步分析了训练模型提供的关于特征重要性的信息。根据ICU常用的Apache, SAPS等风险预测评分系统,结合临床专家的意见,从MIMIC III数据库中提取了与AKI发生、发展高度相关的特征,并在每个患者入院后最初24小时内取平均值。最终共筛选出21个变量组成基本数据集,包括年龄、性别、生命体征和临床实验室结果。
图4显示了可引起AKI的前20个结构化临床指标。根据结果,入院当天基线Scr在AKI风险预测中发挥了关键作用。总尿量(Total Volume Urine in 24 hours, TVU)是影响肾功能最重要的变量之一,其次是动脉血氧分压(partial Pressure of Oxygen,PO2)、体温和血尿素氮(Blood Urea Nitrogen,BUN)。预测AKI的关键信息集中在权重排名前5位的预测因子中。这一结果符合AKI病理生理学发展[58],即Scr、尿量和BUN与AKI发生高度相关。PO2和体温也是AKI的危险因素,表示这两个指标的异常可能增加ICU患者罹患AKI的概率。我们希望这些发现的关键变量能够引起重视,进而为协助临床医生更快地判断ICU患者发生AKI的风险,缩小临床检查和检测的范围。
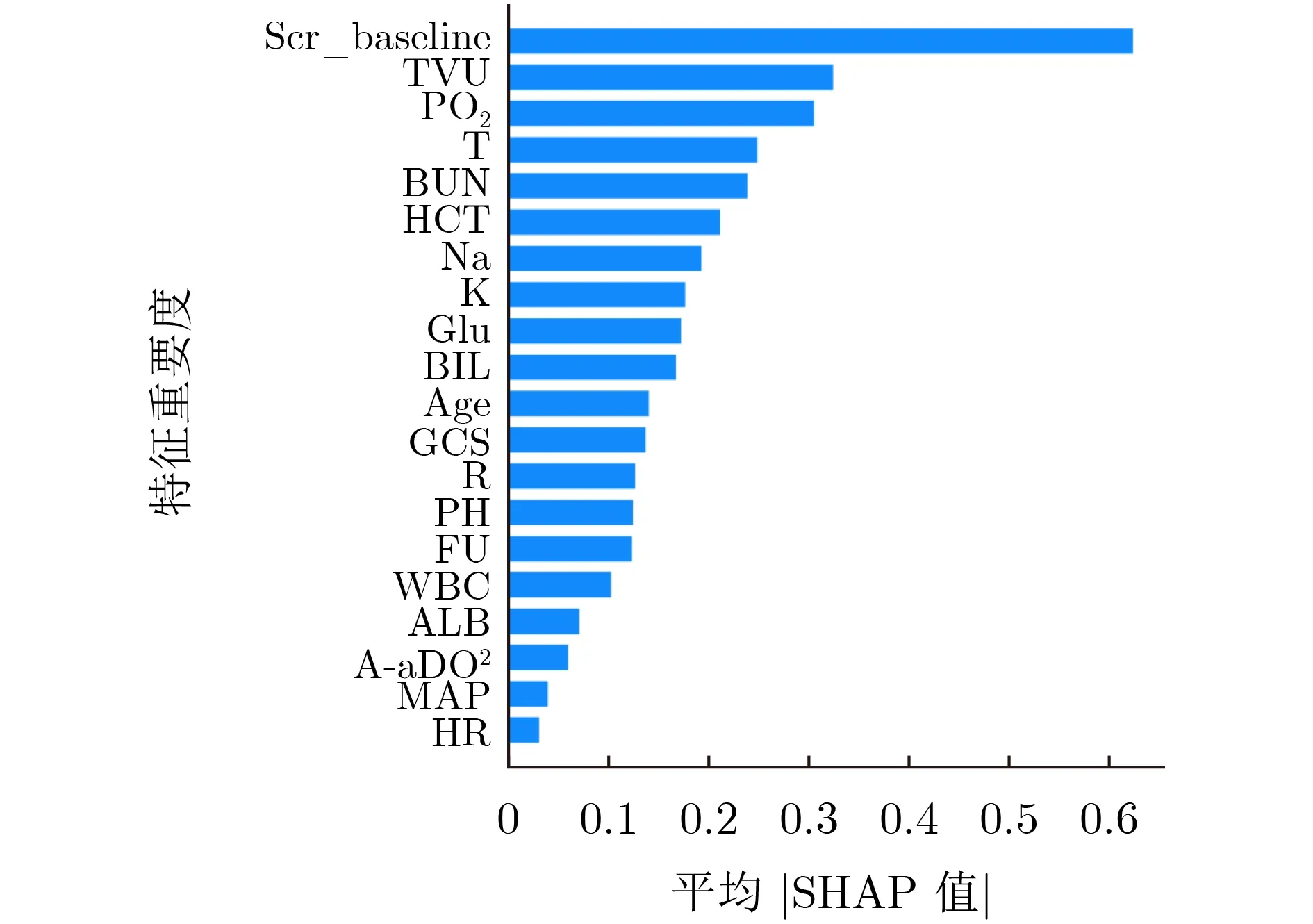
图4 预测模型中前20个变量的排名
4.3 解释模型结果
为了进一步明确各指标相对于目标变量的正/负关系,本文使用SHAP的特殊变体,TreeSHAP用于模型解释。图5为AKI风险预测模型特征重要性排序的SHAP摘要图。该摘要图结合了特征重要度和特征的影响。摘要图上的每个点都是一个特征和一个实例的Shapley值,y轴上的位置由特征决定,x轴上的位置由Shapley值决定,颜色代表特征值从小到大,重叠点在y轴方向上浮动,因此我们可以了解每个特征的Shapley值的分布。
我们可以看到入ICU 24h内首次SCr测量值(Scr_baseline)对模型的影响最大。此外,该特征值越高,Shapley值越高,发生AKI的概率就越大。总尿量是第2个最重要的特征,该特征值越低,发生AKI的概率就越高,与GCS相同。在生命体征特征方面,图5也显示较高的体温和呼吸频率的患者发生AKI的概率增高。此外,尽管胆红素(Bilirubin, BIL)的重要性明显低于上述特征,但它对部分患者而言影响最大,且对AKI的发生有积极的影响。此外,在实验室检查方面,红细胞比容(Hematocrit, HCT)和白蛋白(Albumin, ALB)越高越容易发生AKI,但它们的重要性也明显较低。上述实验结果与临床及相关研究结果一致[59],进一步证实了GCS, BIL, HCT和相关生命体征对AKI风险的影响。尽管图5的摘要图可以简要说明特征对AKI风险的正面或负面影响,但信息仍然有限。为了帮助医生更好地了解各变量之间的交互效应,有待进一步研究各预测指标之间的关系。图6给出了两个SHAP特征依赖图的例子。
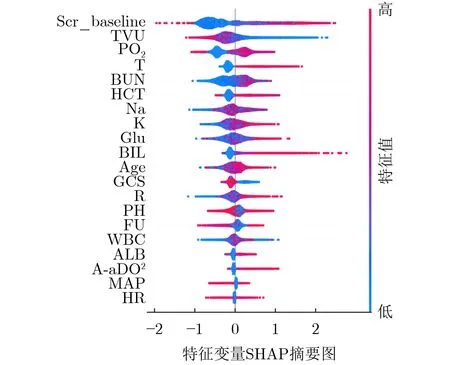
图5 平均排名前20的特征变量SHAP摘要图
如图6(a)所示,我们选择TVU作为特征来确定Scr从0.5增加到3.5时的影响。红色的点代表Scr的高值,蓝色的点代表低值。当TVU较低时,Scr的SHAP值会增加,说明增加TVU会降低AKI发生的可能性。即降低TVU,增加Scr会导致AKI的概率增加。而Scr较低时的SHAP值小于零,说明增加TVU而Scr较低时,AKI发生的概率较低。
图6(b)显示了BUN和Scr对预测AKI带来的影响。忽略图形的颜色,关注BUN变化对模型输出的影响。尽管存在噪声,但在BUN值为25之前,SHAP值大多为负值。在25~75范围内,Shapley值逐渐增大并为正,当BUN约为150时,SHAP值再次逐渐减小并为负。BUN的高度非线性影响证明了只看一个参数(例如,它是正的还是负的)往往是不够的。从本质上看,SHAP值表明BUN的主要影响为正;即当BUN升高超过25时,AKI风险增加。在BUN较高时,红点出现越多;说明Scr和BUN呈正相关。从图6可以看出,TVU降低,BUN升高,说明AKI风险增加。一些研究报道BUN和尿量是AKI、终末期肾脏疾病和死亡率的重要指标[60,61]。本研究给出的结果也验证了这一结论。

图6 重要指标的SHAP特征依赖图示例
值得注意的是,这些依赖图说明的是相关性,而不是因果关系。基本上,它们提供了特定范围下的信息,可以提醒特定环境下可能出现的结果变化趋势。因此有必要将这些信息与医生的经验和患者的病情相结合,以确定该特征是否可以作为干预的选择。
最后,为了评估本文中的XGBoost模型,我们检索了利用MIMIC III数据集进行AKI预测的最新研究,并进行了对比。如表4所示,本研究获得了优越的性能,这说明我们提出的模型非常有效。

表4 MIMIC-III数据集上的最新研究(仅用于AKI预测)不同模型性能的比较
5 讨论
在本研究中,使用从MIMIC III数据库中提取的一组数据,训练XGBoost模型对AKI的早期预测进行建模。共纳入13001个病例进行模型训练,准确率为0.816,AUC为0.839。此外,模型训练中AUC值(即五倍交叉验证)也证实了该算法在预测AKI方面的高性能。该结果优于文献中报道的基线模型[36]。本研究还构建了基于RF,ANN,SVM和LR算法的AKI风险预测模型。将XGBoost模型与上述模型的性能进行比较,结果表明,在所有评价指标中,XGBoost模型的预测性能最好。相比之下,支持向量机在所有5种模型中表现出了最弱的性能。
由于支持向量机模型等基础算法背后的数学逻辑对临床医生来说很难理解,除了预测结果之外,它不能给临床医生提供更多的信息。然而,作为一种基于决策树的集成机器学习算法,XGBoost的另一个好处是它不受多重共线性的影响。因此,即使两个变量在模型中的作用相同,我们也可以保留两者,因为我们可以通过SHAP进行特征重要性分析。因此,我们认为XGBoost模型具有良好的模型性能和临床可解释性,在AKI风险预测方面具有很大的潜力。
利用SHAP对最终的XGBoost模型进行特征重要性分析,发现肾功能相关特征(尤其是Scr)对模型中AKI发生的概率有实质性影响。相比之下,心率是除性别外最不重要的特征,我们注意到数据集中缺失了大量的心率数据(83.4%),这可能是导致该结果的原因之一。该模型的结果也可以为临床决策提供信息。以温度为例,温度对AKI的发生概率有积极的影响,可能对高温患者采取更多的降温措施可以缓解AKI的发生。血钾水平升高可能是肾脏损伤早期电解质紊乱的表现[64]。而Glu的特征表明糖尿病共病和程序风险可能导致AKI发病,与文献一致[65]。特征变量重要性排序结果证实,临床记录中有临床意义的关键词可以用于预测AKI,我们所建立的模型确实捕捉到了这些特征变量。进一步进行SHAP依赖分析,获取并描述两对特征对模型的影响(图6),该方法不仅能够评价特征对模型输出影响的重要性和方向,还可以提取特征对模型输出的复杂非线性影响[66]。值得注意的是,在这项工作中,TVU和BUN的交互影响提供了有意义的信息,这是大多数其他技术无法捕捉到的。
我们的研究还有以下几个优势。首先,本研究使用的数据库是一个公开的、大规模的ICU数据库,样本量充足。其次,我们采用XGBoost算法构建预测模型,该模型能够容纳大量特征变量的数据,并对影响AKI预测的变量进行重要性排序。第三,本文采用了五倍交叉验证,以获得更性能更稳定的模型。第四,我们所使用的预测变量可以在临床实践中得到,这就保证了该模型的临床可用性。最后,本模型具有临床可解释性,预测模型的可靠性,且可以帮助医生更好地了解各变量与目标变量之间及两变量相互之间的交互效应。
这项回顾性研究仍有一些局限性。首先,本文使用的数据是从单中心数据库中提取的。因此,本研究获得的结论仍需进一步的外部验证,以进行泛化和前瞻性试验,评估其临床效用。其次,有许多因素可导致或促成AKI,包括有效循环血量不足、肾毒性药物和败血症[5,67]。 然而,本研究使用的数据集仅包含了部分在MIMIC III数据库中定义的结构化信息,而其他急性肾损伤危险因素,如脓毒症、烧伤、创伤、心脏手术、肾毒性药物等[3],也可能有助于提升我们模型的性能。第三,由于我们没有获得ICU入院前的SCr数据,因此只能以ICU入院后第1次SCr检测值作为基线。最后,本研究中发现的重要特征和拐点可作为AKI风险的早期体征,但在其推荐范围是否可作为对照的参考还需进一步验证。
6 结论
由于AKI与不良临床结果和额外的医疗资源消耗相关,本文开发了一个高性能的XGBoost预测模型,通过使用入ICU后的前24 h数据,早期预测所有危重成人患者患AKI的风险。虽然基于XGBoost算法的AKI风险预测模型的临床适用性还需要在实际的临床实践中进行检验,但我们认为XGBoost模型由于其性能和临床可解释性,在未来ICU的临床工作中具有很大应用价值,有助于ICU临床医师避免延误高危AKI患者的治疗,这对改善AKI患者的预后至关重要。
