基于图注意力网络的多标签图像分类模型
2022-02-24张辉宜
张辉宜, 张 进, 黄 俊
(安徽工业大学 计算机科学与技术学院,安徽 马鞍山 243000)
0 引 言
传统监督学习中每个样本只含有一个语义信息,但是现实世界的数据往往含有多个类别的语义信息,即单个样本关联着多个语义标签。例如,一幅天空的图像可以同时标注“蓝天”、“白云”等语义标签;一段新闻文档可以同时属于“时事”、“政策”等多个类别。针对这些含有多个语义标签的多标签数据,如果只考虑单一语义标签对其进行学习,就很难获得很好的分类效果。多标签学习的应用领域十分广泛,包含了图像分类[1]、文本分类[2]、音乐分类[3]以及生物学分类[4]等多个领域。随着现实生活中多标签图像数量越来越多、种类越来越复杂,多标签学习在图像分类上的应用也显得更加重要。利用标签之间的相关性可以提升多标签模型的分类性能[5]。根据标签相关性挖掘的程度,可以将多标签分类模型分为3类:没有利用到标签相关性的一阶方法[6-7];挖掘标签对之间关系的二阶方法[8-9];和利用所有标签或类别标签子集中标签关系的高阶方法[10-11]。初期采用浅层分类模型[12-13]对多标签图像进行分类,在人工干预提取数据特征的情况下,浅层模型一般都能取得较好的分类结果。近十年来应用深度学习理论[14]尤其是卷积神经网络(Convolutional Neural Network, CNN)构建了一批经典深度卷积神经网络模型,例如AlexNet[15]、VGG[16]、ResNet[17],这些模型可以对大量多标签图像样本进行有效的深层特征学习,但单独利用卷积神经网络对多标签图像进行分类缺乏对标签相关性的利用,这会影响模型的分类性能,因此多标签分类的现有工作往往会利用标签相关性以提高性能。在标签相关性中标签的共现关系可以通过概率图模型很好地表述,在以往的研究工作中,有很多基于这种数学理论的方法可以对标签关系进行建模[18,19],但是概率图模型的计算成本过高,为了解决这个问题,使用递归网络将标签编码为嵌入向量,以实现标签间相关性建模的方法被提出[20],该方法也存在着递归神经网络模型依赖于预定义或学习的标签顺序的不足,且无法很好地获得标签全局依赖性。2019年Chen等提出了ML-GCN模型[21],ML-GCN利用训练数据集中所有标签类别的标签共现关系建立了整体的标签相关性,在最终分类阶段使用图卷积网络(Graph Convolutional Network,GCN)[22]传播标签共现嵌入并将标签共现嵌入与CNN特征合并,但是ML-GCN学习到的标签共现嵌入维度远远高于需要分类的标签类别数,这会影响模型的分类性能。提出基于图注意力网络(Graph Attention Network,GAT)[23]的多标签图像分类模型ML-GAT,ML-GAT采用降维[24]的方法对ML-GCN中标签共现嵌入维度过高的问题进行改进,同时采用图注意力网络对标签之间的关系进行更加精确的建模。
1 多标签图注意力网络模型架构
针对通过图卷积神经网络得到标签共现嵌入维度过高的问题,ML-GAT采用词嵌入降维模块对高维双向Transformer 的表征编码器(Bidirectional Encoder Representation from Transformers,BERT)[25]标签语义嵌入表示矩阵进行降维,得到低维标签语义嵌入表示矩阵。为了学习标签之间非对称的关系特征,将低维标签语义嵌入表示矩阵和标签类别共现图输入GAT,获取标签共现嵌入模块,得到维度合适的低维标签共现嵌入。同时ML-GAT采用图像特征提取模块提取图像特征。为了匹配低维标签共现嵌入维度,图像特征需要经过图像特征降维模块进行降维,在降维的同时也减少了图像特征中的冗余部分。最后,将标签共现嵌入与降维后的图像特征通过图像特征与标签共现嵌入融合模块进行融合,得到多标签预测评分。多标签图注意力网络模型结构如图1所示。
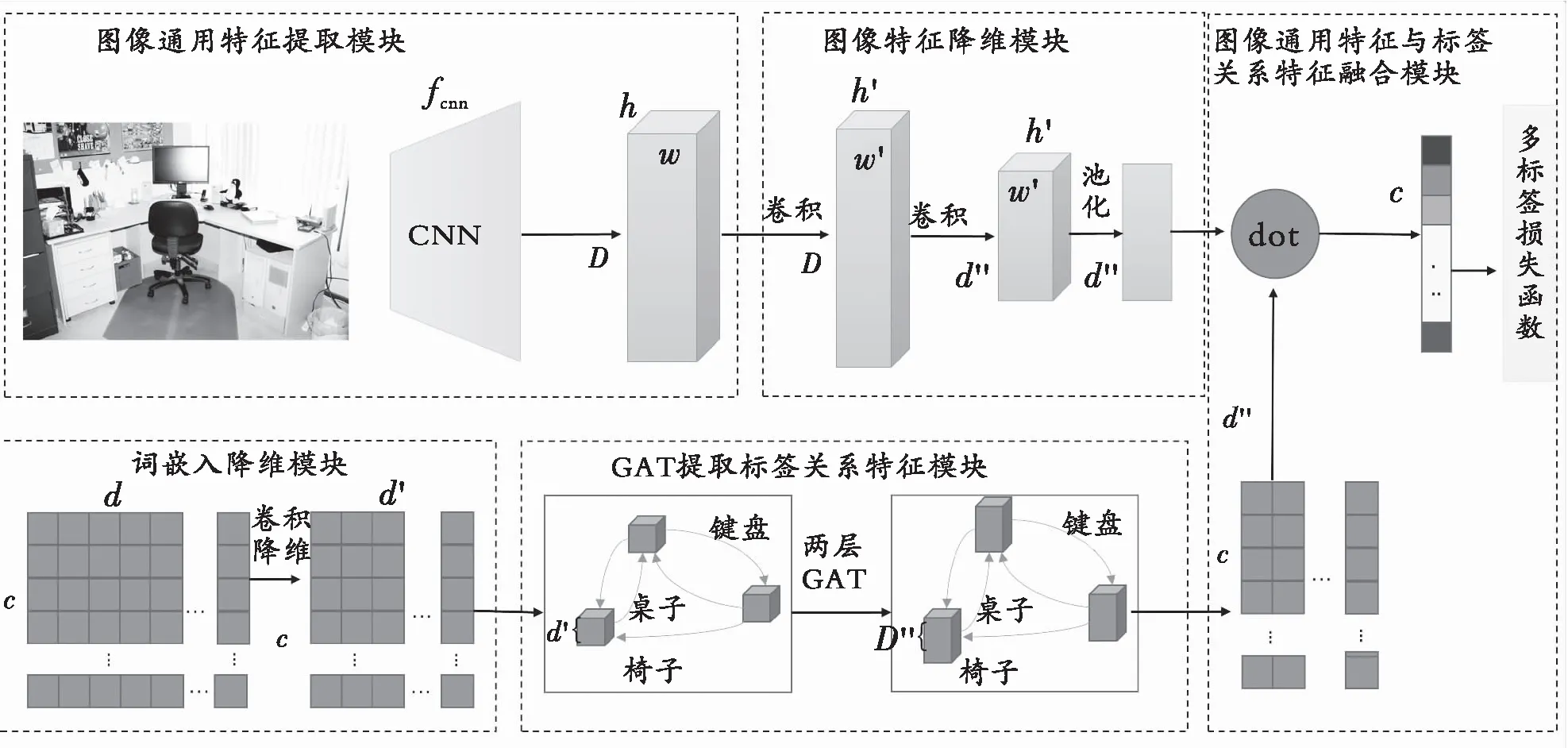
图1 多标签图注意力网络模型结构Fig. 1 Model structure of multi-label graph attention network
1.1 图像特征提取模块
ML-GAT中图像通用特征提取模块使用101层ResNet,即ResNet-101模型。ResNet-101是目前主流的CNN之一,其优点是易于调整,可以比较方便地利用在多标签图像分类任务上,并且有较强的特征提取能力。因为ML-GAT采用的是在ImageNet上预训练的ResNet-101,所以需要去除用来对ImageNet进行分类的全连接层,为了控制图像维度,需要同时去除ResNet-101的自适应池化层,这样可以得到多标签图像特征提取器。将解析度为448×448的多标签图像样本I输入多标签图像特征提取器,可提取多标签图像的特征图F:
F=fResNet(I;θResNet)∈RW×H×D
其中,特征图F的长宽为W、H,通道数为D,fResNet表示图像通用特征提取模块,θResNet是ResNet-101模型参数。
1.2 图像特征降维模块
因为在图像通用特征与标签共现嵌入融合模块中需要将图像特征与标签共现嵌入维度进行匹配,同时对图像特征进行降维,可以一定程度上提高图像特征的判别力,故在ML-GAT中采取以下步骤对对特征图F的长宽W,H以及通道数D进行降维,F首先通过卷积层conv1下采样,得到F′∈RW′×H′×D,W′和H′代表降维后特征图F′的长与宽,再通过一层卷积层conv2对特征图F′的通道数D进行降维,得到F″∈RW′×H′×d″,d″为降维后F″的通道数,最后经过全局最大值池化层GMP,提取多标签图像的特征纹理,去除无用特征。这样可以为每一张图像提取一个维度为Rd″的图像特征向量x:
x=fGMP(fconv2(fconv1(F);θconv1);θconv2)∈Rd″
其中,fGMP为全局最大值池化运算,fconv1和fconv2分别为卷积层conv1与conv2进行的卷积运算,θconv1,θconv2分别为卷积层conv1与卷积层conv2的模型参数。
1.3 词嵌入降维模块
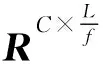
1.4 GAT获取标签共现嵌入模块
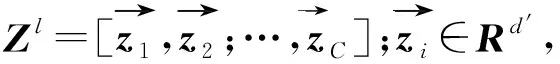
GAT首先针对每一个标签节点i,计算标签节点i与包括自身节点自身在内的所有邻居节点j之间的相关系数eij:
其中,W∈RM×d′是共享参数,对标签节点i的特征zi和标签节点j的特征zj进行增维,增维后的维度为M,在ML-GAT中最后一层M=d″,[·‖·]表示对标签节点i,j的特征进行拼接可以将两个维度为RM的向量拼接为R2M的向量,j∈Ni是与标签节点i存在共现关系的一跳邻居节点。a∈R2M运算将拼接特征映射到一个实数上。
对相关系数采用归一化运算得到注意力系数:
其中,LeakyReLU是激活函数。用注意力系数aij用来计算每个节点的最终输出特征:
其中,σ为非线性激活函数。因为通过计算得到的标签i对标签j的注意力系数与标签j对标签i的注意力系数不同,所以GAT得到的标签节点特征可以一定程度上表示多标签学习中标签与标签之间的非对称关系,例如"飞机”和“天空”这一对标签,有“天空”这一标签时“飞机”有着很小的概率同时出现,而“飞机”标签出现时则会大概率伴随着“天空”标签的出现。ML-GAT采用GAT可以单独为每一对标签计算注意力系数,得到能更加准确表达标签之间关系的标签共现嵌入。
在GAT获取标签共现嵌入模块,经过两层GAT的计算,可以得到一个带有类别标签间非对称关系,维度为RC×d″的标签共现嵌入Zl+2。每一层的GAT计算为
Zl+1=fGAT(Zl,U)+Zl
其中,fGAT表示一层GAT计算,U∈RC×C表示标签节点从标签类别共现图中获得的相关矩阵建立方式与ML-GCN中相同,U中元素uij取值取决于类别标签i与类别标签j之间的共现次数,为了能更好地将上一层的信息传递到下一层,因此在计算时将加上之前一层GAT的计算结果Zl。
1.5 图像通用特征与标签共现嵌入融合模块
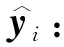
对于一张多标签图像样本,本模型使用的多标签分类损失函数(Multi-label Soft Margin Loss):
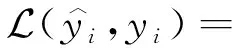
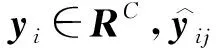
2 模型参数设置与评价指标设计
2.1 实验平台及模型参数设置
实验所采用的软硬件环境为Intel Pentium G4560 @ 3.50 GHz,NVIDIA GeForece GTX 1080Ti 11 GB显卡,12 GB内存,操作系统为Ubuntu 16.04,编程语言为Python,深度学习框架为Pytorch 1.5。
ML-GAT在两种常用多标签图像数据集上进行对比实验,分别是:Microsoft COCO 2014(MS-COCO 2014)[26]和PASCAL Visual Object Classes Challenge(VOC 2007)[27]。MS-COCO 2014拥有80个类别的多标签图像,包含82 081张图像组成的训练集和 40 504张图像组成的验证集,平均每张图像都拥有2.9个类别标签。VOC 2007数据集包含9 963张图像组成的训练集、验证集和测试集,包含20个常见物体类别标签。
在ML-GAT中,将维度为RC×L的高维BERT标签语义嵌入矩阵Z0输入到词嵌入降维模块,预训练BERT标签次嵌入矩阵维度L取值为1 024,经过一层卷积核长度4宽度为1的卷积层进行下采样,水平步长为4垂直步长为1,得到低维标签语义嵌入表示矩阵Zl∈RC×d′,d′此时为256,将Zl输入GAT获取标签共现嵌入模块,经过两层GAT计算得到标签共现嵌入Zl+2∈RC×d″。为了将标签共现嵌入应用在图像特征上,将多标签图像解析度设置为448×448,将其输入图像通用特征提取模块,得到多标签图像特征图F∈RW×H×D,D为2 048,W、H均为14,针对VOC 2007数据集模型,采用的卷积层conv1不改变其W、H,使W′、H′与W、H相等。MS-COCO 2014数据集中W,H通过长宽为5卷积核的conv1计算得到值均为10的W′、H′,在两种数据集上均经过长宽为1的卷积核的卷积层conv2,对特征图通道数D进行降维,得到F″∈RW′×H′×d″,最后采用池化核大小为W′×H′的全局最大值池化层GMP得到维度为Rd″的图像特征向量x,d″是图像特征向量x的维度,同时也是标签共现嵌入的列维度,在VOC 2007数据集上的取值分别为{300,512,768},而在MS-COCO 2014数据集上设置d″为{1 024,1 280,1 536},d″参数设置由参数搜索和数据集中的标签类别标签个数共同决定,参数搜索策略为试错法,由于MS-COCO 2014所含有的类别标签数是VOC 2007中所含类别标签数的4倍,因此d″也同步增加。设置初始学习率为0.005,采用随机梯度下降作为优化器,权重衰减设置为10-4,动量设置为0.9,总共训练100轮。
2.2 评价指标
测试采用的评价指标有:平均每类精度(CP)、平均每类召回率(CR)和平均每类F1(CF1)值。另外针对整体分类结果使用平均整体精度(OP),平均整体召回率(OR),平均整体F1(OF1)进行评价。针对每个类别的分类准确度,取平均值得到平均精度均值(mAP)[28],评价指标定义如下:
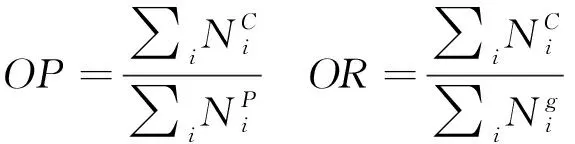
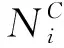
3 实验结果及分析
在MS-COCO 2014数据集的实验中,因为实验设备条件有限,且数据集中样本相对较多,故进行实验时,采用随机抽取部分训练样本用作训练模型,再将训练出的模型在全部测试样本上进行测试的方法。对于ML-GCN和ResNet-101进行同样的采样、训练、测试方法进行实验,在MS-COCO 2014训练样本列表中采用Python的Random模块,从82 081张训练样本中随机抽取4 000个样本,采样3次,训练出3个模型分别测试,对所有测试产生的评价指标,取3次测试的均值作为实验结果。VOC 2007数据集采用全部训练样本和测试样本进行实验。实验结果中各评价指标中最佳值均已加粗。
ML-GAT在VOC2007上的测试结果如表1所示,经过与近几年来的主流深度多标签图像分类模型进行对比(实验数据来源中除ResNet-101、ML-GAT,其他方法数据均来自各论文中给出的测试结果),在d″设置为512的情况下,ML-GAT在mAP这一指标上达到了94.3,在14个类别的分类上为最佳值。在MS-COCO 2014数据集上ML-GAT的测试结果如表2所示,此时d″设置为1 280,在所有标签上的预测与前3个标签上的预测结果中,有7个主要分类指标超过或持平ML-GCN,说明ML-GAT模型可以在多个常用数据集上取得较好的分类结果。
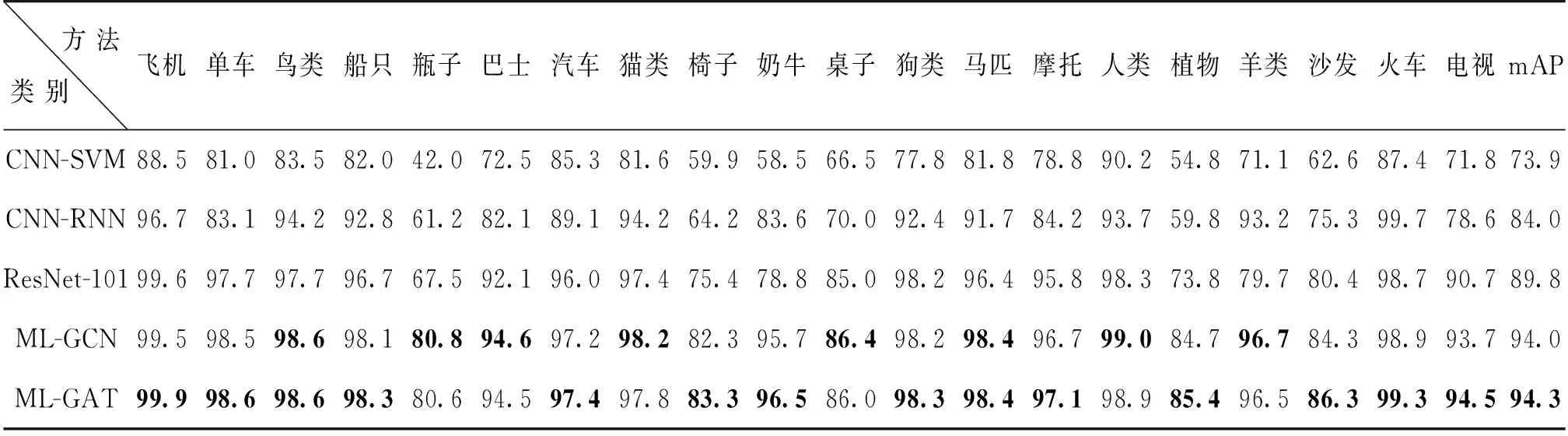
表1 在VOC 2007上的实验结果Table 1 Experimental results on VOC 2007

表2 在MS-COCO 2014上的实验结果Table 2 Experimental results on MS-COCO 2014
为了比较不同数据集上标签共现嵌入列维度d″对分类性能的影响,分别对两个数据集设置不同的d″进行对比实验,如图2所示,在VOC 2007数据集中,d″取值为512时,ML-GAT在mAP评价指标上达到最佳,在MS-COCO 2014数据集上进行一次采样测试,d″大小为1 280时得到最佳mAP,这说明MS-COCO 2014数据集中的标签类别更多,标签共现嵌入中冗余部分较少。而VOC 2007因为标签类别较少,因此标签共现嵌入冗余部分较多。通过在这两种数据集上进行对比实验,验证了ML-GAT在标签共现嵌入降维,与对标签之间非对称关系的提取上采取的策略是有效的。
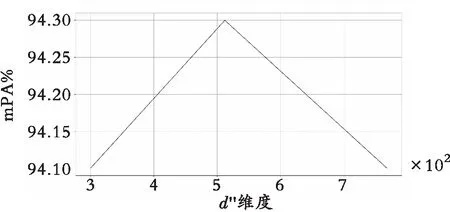
(a) VOC 2007
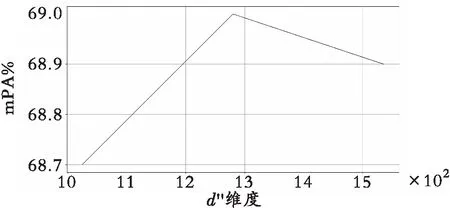
(b) MS-COCO 2014
4 结束语
图卷积神经网络与CNN结合的深度多标签图像分类模型ML-GCN在多标签图像的分类上取得了很好的效果,但是ML-GCN中通过GCN获取到的标签共现嵌入维度过高,标签共现嵌入没有很好的反应标签之间非对称关系,针对ML-GCN存在的这两点不足,提出一种基于图注意力网络的多标签图像分类模型ML-GAT。ML-GAT通过对输入GAT的高维标签语义嵌入表示矩阵进行降维,解决了ML-GCN利用GCN获取标签共现嵌入时,冗余部分降低模型分类准确度问题,同时GAT可以对标签邻居之间计算不同注意力系数,学习标签之间非对称关系特征,促进模型分类。通过在主流数据集上与多标签深度学习经典模型进行对比实验,ML-GAT模型在多标签图像分类主要评价指标上,相较经典深度多标签图像分类模型有一定的改进,实验证明了ML-GAT模型的有效性。
