地源热泵系统长期供能模式提取方法与多案例分析
2022-02-23张舒阳张小松
张舒阳 张 伦 张小松
(东南大学能源与环境学院, 南京 210096)
地源热泵作为一项节能减排和环境效益显著的技术,近年来在全球各地的应用呈现增长态势,从装机容量和年用能量来看,中国已处于世界前列[1].为掌握相关建筑应用项目的实际运行效果,多个省市已建立了监测平台,通过远程传输等手段,实现系统运行数据的统一接入和实时监测[2-3].
系统实际运行数据是性能分析评估、仿真模拟、故障检测诊断、标准制定的重要依据.虽然现在有很多方法可对系统运行进行模拟或预测,但所得结果与实际仍有一定差异,在直接度、准确性方面,实际运行数据具有不可替代性.随着建筑自动化系统的不断发展,包括地源热泵系统在内的不少建筑空调系统都建立了运行数据库,其中所存储的数据体量也随着时间推移越来越大.如何从中提取出有效信息,并利用其评估运行效果,指导将来的运行管理,更好地服务相关行业,对相关研究和从业人员而言意义非凡但也充满挑战.
受气候和用户行为影响,运行数据具有一定的周期性,因此将系统运行参数作为时间序列进行挖掘具有可行性.通常数据的挖掘分析包含以下步骤:采集与入库、集成、清洗、数据挖掘的实施、知识运用.其中较为常用的挖掘方法就是通过有监督或无监督的机器学习来进行分类、聚类、关联规则的发现等[4].其中,聚类无需预备知识就可以发现数据中隐藏的规律和模式,是一种简便有效的降维方法,在不少研究中都得到了应用[5-6].
例如,Liu等[7]对模糊k-modes法进行了改进,对建筑电耗数据进行了聚类分析.徐青山等[8]采用近邻传播算法对包括空调在内的建筑主要设备的用电数据进行了聚类,构建了室内典型用能场景.Ruiz等[9]对8栋公共建筑的能耗数据进行了聚类,并研究对比了层次法、高斯混合模型、k-means、k-Medoids等算法的聚类效果.Yu等[10]通过k-means法对某空调系统中空气处理机组的运行参数聚类并识别运行模式,涉及参数有冷却盘管出口压力、进口空气压力、空气流量等,结合能耗分析,获得了能效更高的模式作为后续节能运行的参考.同样采用k-means法,梁志豪等[11]分析了广州某办公楼变频空调一天内常见的功率变化模式;李冠男[12]对多联机空调能耗数据进行了聚类,指出能耗和能效水平与制冷剂充注量相关;谢宜鑫[13]基于某冰蓄冷系统的能耗数据,分析了不同模式下的机组运行情况和各模式的全年分布.
从以上文献来看,受数据可得性、完整性的影响,聚类分析多以建筑整体电耗数据为对象,以空调系统参数为对象的较少;空调系统相关研究中,针对用电数据的挖掘较多,针对供能量、温度、水流量等其他参数的较少;用数据点作为聚类基本单元的较多,用数据集合的较少.此外,不少研究选用了k-means法,该算法中初始点的随机选择会引起聚类结果不稳定,而层次聚类法可以较好地避免这一弊端.
聚类的关键步骤之一是计算相似度,随着技术发展,数据采集传输系统所能处理和记录的数据在时间尺度上也越来越精确,当数据记录步长缩短后,时间轴上些许的偏移会导致欧式距离产生较大的变化[14],需采用一种在时间尺度上敏感度较低的距离计算方法进行度量.动态时间规整(DTW)基于动态规划思想,是一种适用的时间序列距离度量方法[15].
总的来说,建筑空调系统运行数据传统分析一般针对的数据体量小,以单系统的典型日数据的形态特征描述为主;典型样本的选取受到客观条件的限制较多,在此基础上获得的结论缺乏代表性.结合空调运行数据的特点,本文选用了无监督学习中的层次聚类法,并采用DTW算法计算相似度,在此基础上形成了一套移植性较强的运行数据模式提取流程,完成了对4个地源热泵系统的长期供冷供暖的数据分析,并获得了若干个具有共性的典型日模式.
1 数据来源与处理方法
1.1 系统基本信息
本文选取了4个住宅建筑的地源热泵系统运行数据作为分析对象,所有项目均位于江苏省扬州市,热源侧均为地埋管,相关信息详见表1.

表1 系统基本信息表
各个系统所采集的主要数据有:用户侧总进、出口水温,地源侧总进、出口水温,用户侧总流量,地源侧总流量.对这4个系统的数据追踪时间均为4 a,各包含4个供冷季和4个供暖季.
1.2 数据处理流程构建方法
本研究基于MATLAB搭建了数据处理程序.从数据库中导出的原始数据需要对其进行格式的转换,将其存储为便于程序快速调用的数据格式.参考数据挖掘基本流程,包括框架搭建和目标明确、数据获取和预处理、数据挖掘和获得知识的应用[4],结合实际数据中存在的问题,主要针对数据预处理进行了具体流程的定制.
本文视同一天数据为处理的基本单位,即00:00—23:00的逐时数据.首先,受现实条件约束,如测量误差、传输错误、传输不稳定等因素,从实际系统中获得的原始运行数据通常包含部分噪声,需在了解噪声特点后,制定对应方案对数据进行清洗.本研究数据中噪声主要有:重复、缺失和不合规律的异常值.
由于某个时间刻度上,其对应的各个参数应当满足3个条件:存在、唯一、合理,因此对应制定了以下预处理规则.基于标准时间轴,如同一时间出现多个数据,通常这些值应当相同,此时仅需保留其一即可.如不同,则需依照3σ准则判断其是否为异常值,如为异常,则删除并标记成空值;如果不是异常值,则取所有重复值的平均作为该时刻的值.如果该时刻没有数据,则采用平均移动窗格法对数据进行补齐.补齐时为防止结果偏离,如待补齐的数据量占所在序列数据量的比值超过15%,则不执行补齐.在执行完清洗和补齐后,需按天对数据进行标准分割,并根据所需研究的参数特征及目标选取合适的时间步长,常用的步长有5 min、10 min、1 h、1 d,选取的时间步长通常为采集数据时的时间步长的整数倍,取值为该步长内所有采集值的平均值.最后标记所属年份和所属的供冷/暖季,存储成标准数据格式.完成上述数据预处理步骤,则可将数据导入到聚类模块中.
1.3 聚类与模式提取
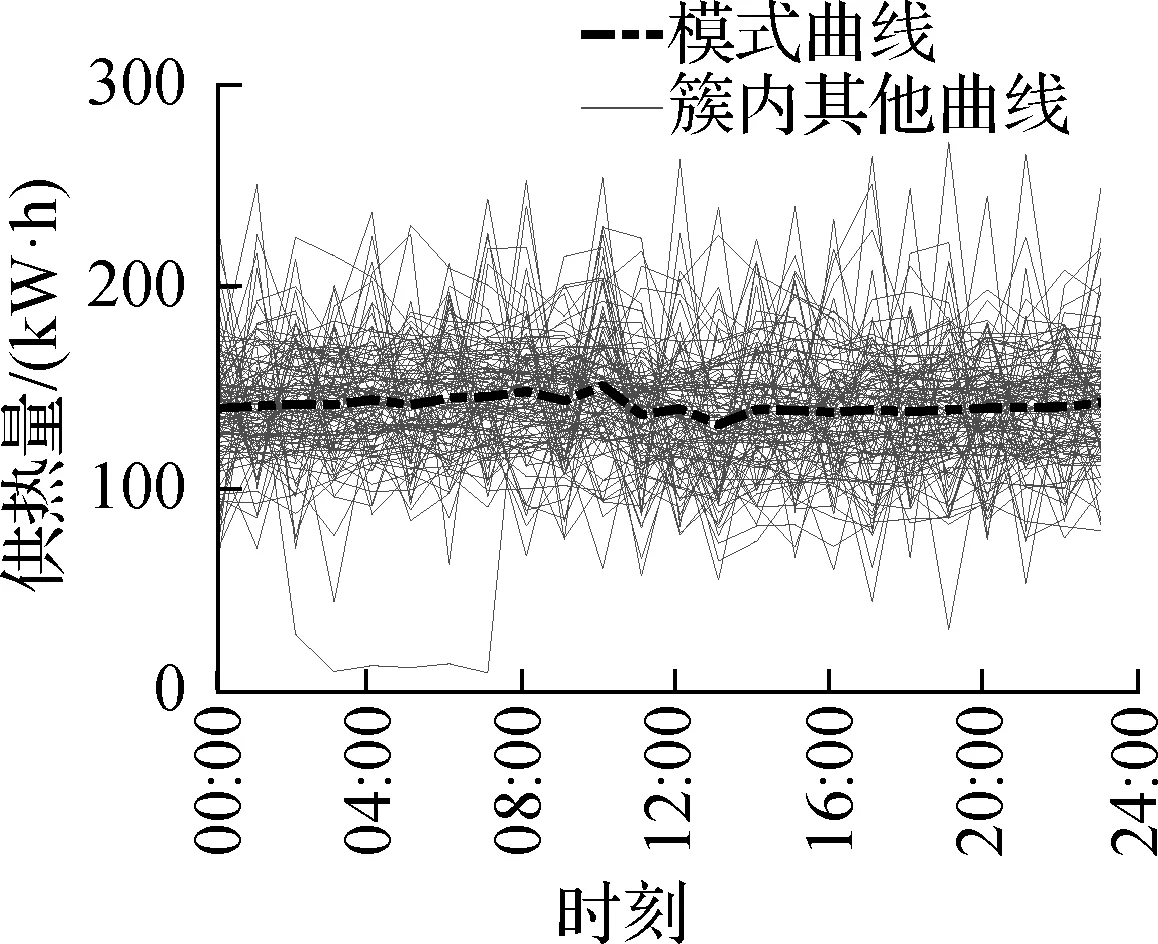
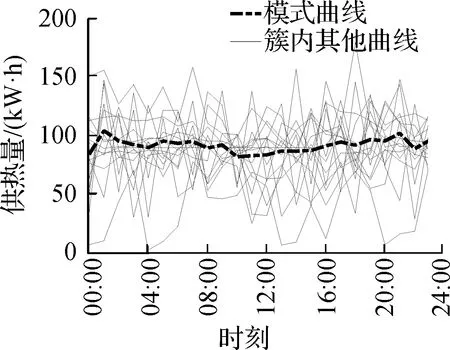
层次聚类法的基础是计算数据集中各个对象之间的距离,并据此衡量元素之间的相似度.本文采取动态时间规整方法,用满足一定条件的时间规整函数W描述测试模板和参考模板间的时间对应关系,求解2个模板匹配时累计距离最小所对应的规整函数[14].假设有2个参数序列A和B,序列中的元素分别记为an和bm,其中n= 1,2,…,N,m= 1,2,…,M,通过构造一个N×M的网格,计算序列A中每一个点到B中每一个点的距离,用动态规划方法寻找一条通过所构造的网格中若干个点的路径,使得沿该路径从A到B的累计距离达到最小,该距离记为DDTW(A,B),这条路径即为规整路径W,其第k个元素wk=(n,m)k为序列A到B的映射,其中k= 1, 2, …,K, 且min(m,n) ≤K W=(w1,w2,…,wk,…,wK) (1) (2) 采用上述算法完成对日序列间两两距离的计算后,可获得一个距离矩阵,基于该矩阵将距离最近的对象合并为一簇,再计算新产生的簇与其他各簇的距离并形成新的距离矩阵,重复上述两步不断将最近的簇进行合并直至所有数据被合并成一个簇. 为获得典型模式,需判断最佳聚类数量.由于本文的聚类是基于DTW距离的,参照基于欧式距离的误差平方和(SSE),引入基于DTW距离的组内平方和SSEDTW作为聚类数量的评价指标,计算方法如下: (3) SSEDTW是其组内离散程度的指征,是簇内各对象到簇内平均值的距离平方和.通常簇数越多,则划分越细,获得的簇所含对象集中程度越高、离散程度越低.但当簇数增加到一定程度后对离散程度的降低效果也会越不明显,SSEDTW随簇数量变化的曲线肘部对应值即为最佳聚类数. 根据最佳聚类数可完成对所有序列的划分并获得对应数量的簇.由于一个簇中包含的曲线在形态上和数值水平上应当是具有共性的,因而此处采取去掉最值的求平均方法提取典型模式曲线.即,将簇内所有序列按照时间轴对齐后,取同一时刻平均值获得初始平均曲线,去掉距离该初始平均曲线最远的一条曲线后,分别求逐时平均值,所得平均值按照时间顺序组成的曲线即为该簇的模式,用来表示该簇内包含的序列平均的形态与数值大小特征. 基于上述方法,本文最终形成了以下数据处理流程(见图1),主要包括数据采集、数据预处理、聚类和模式提取4个步骤.其中,数据预处理主要包含格式和时间轴的标准化、去重、去异常值和缺失数据补齐等.完成预处理之后,数据被传送到聚类模块中,进行距离计算、聚类和最佳聚类数判别,最终根据聚类结果获得典型模式. 图1 实际运行数据的处理分析流程图 以系统1为例,该系统的数据记录步长为每次5 min,共计追踪4 a,包含420 480行原始数据.由于本文仅分析供给用户的冷热量特性,因此每行数据只取用户侧总进、出口水温和用户侧总流量这3个参数,考虑到建筑的热惰性,取1 h作为步长. 以该系统某供冷季为例,该供冷季原始数据中含有6.2%异常值及1.0%空值,在去除异常值之后对符合条件的数据进行补齐.完成上述预处理之后,即可计算用户侧的供冷量.按照上述流程可对所有供冷季的供冷量数据进行预处理,并按天进行标准分割获得共184条时间序列.将所获得的序列进行聚类,并对簇数从3~15计算对应的SSEDTW,可获得如图2所示的折线图,根据肘部法则,最佳聚类数应为6. 图2 最佳聚类数量判断(系统1) 对该系统1供冷季数据聚类后可获得图3(a)~(f)所示结果.其中,图3(a)为所有模式的汇总,图3(b)~(f)分别为簇1~5包含的所有曲线,各图中虚线为该簇的模式.聚类所得各簇内的序列趋势基本一致,所得各模式能够较好表示该簇的平均特征.由图可知该系统夏季供给用户的冷量形态结构主要分2类,一类是如图3(b)~(e)所示的波动模式,另一类则是如图3(f)所示的平缓模式,从簇1到簇5的波动幅度则不断增大.而从数值水平来说,从簇1到簇5,其供冷量水平是不断升高的. 类似地,对供暖季数据应用上述方法后可获得如图4(a)~(g)所示结果.该系统冬季供热量包含6种有效模式,其中图4(a)为供暖季所有模式的汇总,图4(b)~(g)为各簇中包含的所有曲线以及从中提取出的模式曲线.从形态结构来看,相对供冷量来说供热量的日变化幅度较小,无明显的波谷,从簇1到簇6的波动幅度递增,从数值水平来说,从簇1到簇6的供热量水平逐渐上涨. (a) 系统1供冷季模式汇总 (b) 簇5与模式5汇总 (c) 簇4与模式4汇总 (d) 簇3与模式3汇总 (e) 簇2与模式2汇总 (f) 簇1与模式1汇总 (a) 系统1供暖季模式汇总 (b) 簇6与模式6汇总 (c) 簇4与模式4汇总 (d) 簇4与模式4汇总 (e) 簇3与模式3汇总 (f) 簇2与模式2汇总 (g) 簇1与模式1汇总 对同一个系统同一个季度的数据来说,簇编号越大,对应的供能量越高,日波幅也越高,簇之间的差异则主要是由天气变化导致的负荷变动所引起. 将4个系统的所有供冷季和供暖季数据按上述方法处理所得结果分别如图5和图6所示.图中,编号x-y中x为系统编号,y为所在簇的编号. 如图5(a)~(d)所示,各系统供冷模式数量分别为5、4、5、8.系统1的供冷模式为单峰型,系统2~系统4的供冷模式较为接近,为双峰型.单峰型供能模式中,系统供能高峰出现在中午前后,全天只有一个波峰.双峰型供能模式中,系统供能高峰在12:00前后和22:00前后各出现一次,全天有2个波峰.如以峰谷差来衡量各模式的日波幅,通过对比同一系统的不同模式可发现,随着其数值水平的增大,其波幅也逐渐增大. (a) 系统1供冷季模式汇总 (b) 系统2供冷季模式汇总 (c) 系统3供冷季模式汇总 (d) 系统4供冷季模式汇总 (a) 系统1供暖季模式汇总 (b) 系统2供暖季模式汇总 (c) 系统3供暖季模式汇总 (d) 系统4供暖季模式汇总 图6(a)~(d)所示为供暖季主要模式,各系统供暖模式数量分别为6、8、7、7.相对供冷季,这些系统的供暖季曲线都更平缓,全天无明显波峰,系统2和系统3在中午前后出现一个波谷,4个系统的供热量在午后均出现不同程度的小幅降低.与供冷各模式相同,供暖各模式的波幅与其数值水平呈正相关关系,且供能曲线的波动与室外温度有关.当室外温度升高时,对应的供暖负荷和供热量也会降低;同时对于居住建筑而言,工作时段对供暖的需求也会降低. 供冷量和供热量反映建筑负荷水平,建筑空调负荷水平则主要受到室外天气和人行为的影响.系统1的末端是毛细管,用户自主控制性较差,因此夏季时,系统1的供冷量表现出单峰的形态,接近室外气象参数的波动.系统2~系统4的末端则是风机盘管,有较高的用户自主性,在炎热和室内人员活动较多的时候,末端对冷量的需求也会增多,因此在午间高温时,会出现第1个峰,晚间人员负荷增加时出现第2个峰.冬季时,系统1和系统4末端都是辐射式供暖,用户调控自主性较差,供暖水平较为稳定,而系统2和系统3的末端是风机盘管,受到室外气象参数变动和用户调控等综合因素的影响,它们的供热量波动则会更大. 1) 从4个项目中依次提取了5、4、5、8个供冷量模式和6、8、7、7个供热量模式.供冷模式日波动较明显,按波形可分为单峰型和双峰型.供暖模式日波幅较小,存在一个波谷或全天基本无波动.供能量波动与末端形式有关,用户自主性较差的辐射式末端波幅小、波动少,用户自主性较高的风盘式末端则相反. 2) 本文借助DTW进行相似性度量,以日数据作为基本聚类单元,所得聚类和模式提取结果可体现1天内的供能水平变化特征.此处,基本聚类单元的时长不限于天,可根据实际需求进行调整(例如1周).由于算法中采用了无监督机器学习中的层次聚类法,无需预备知识和聚类中心初始化,可避免由不同分析人员引入的主观差异. 3) 需注意的是不同参数的属性不尽相同,应结合数据特性决定是否可以聚类和具体的算法,这是本文方法局限性之所在.但对常规空调系统而言,多数运行参数受气候和人行为等的影响,呈现出非严格的波动性和周期性.因此不论数据来自何种系统,也不论其参数类型,只要其周期性较好且数据质和量满足需求,都可用本文流程进行时间轴上的聚类分析,从这一点来看本文方法具有较强移植性. 4) 由于实际的末端负荷难以直接测量,因此通过典型供能模式,可了解到实际运行中系统向用户供应冷热量的主要规律.样本量足够时,通过本文方法,进行单项目分析时可了解供能情况的总体分布和逐年变化,进行多项目分析时可横向对比其供能模式,总结一般性规律.根据本文方法所得模式是统计学意义上的平均值,相比传统典型日或短期测量方法获得的数据,可为能效评估、能耗对比分析、节能策略制定等相关研究,提供较为完善和可靠的分析场景.针对特定模式进行能效评估和节能策略制定将是未来研究方向.
2 结果分析
2.1 数据处理流程

2.2 单案例供冷供热量模式分析












2.3 多案例模式对比








3 结论
