红外与可见光图像注意力生成对抗融合方法研究
2022-02-23武圆圆王志社王君尧邵文禹陈彦林
武圆圆,王志社,王君尧,邵文禹,陈彦林
〈图像处理与仿真〉
红外与可见光图像注意力生成对抗融合方法研究
武圆圆,王志社,王君尧,邵文禹,陈彦林
(太原科技大学 应用科学学院,山西 太原 030024)
目前,基于深度学习的融合方法依赖卷积核提取局部特征,而单尺度网络、卷积核大小以及网络深度的限制无法满足图像的多尺度与全局特性。为此,本文提出了红外与可见光图像注意力生成对抗融合方法。该方法采用编码器和解码器构成的生成器以及两个判别器。在编码器中设计了多尺度模块与通道自注意力机制,可以有效提取多尺度特征,并建立特征通道长距离依赖关系,增强了多尺度特征的全局特性。此外,构建了两个判别器,以建立生成图像与源图像之间的对抗关系,保留更多细节信息。实验结果表明,本文方法在主客观评价上都优于其他典型方法。
图像融合;通道自注意力机制;深度学习;生成对抗网络;红外图像;可见光图像
0 引言
可见光图像具有丰富的细节信息,易于判读,但是其对良好的光照条件和天气情况有较强的依赖性;红外图像反映目标与背景的辐射特性,红外辐射透过霾、雾及大气的能力比可见光强,它可以克服部分视觉上的障碍而探测到目标,具有较强的抗干扰能力,但目标的结构特征和纹理信息缺失。红外与可见光图像融合,使融合图像既具有红外图像的辐射特性,又具有可见光图像的结构特征和纹理信息,有利于人眼的观察和后续图像处理,在遥感探测、医疗诊断、智能驾驶、安全监控等方面具有广泛应用[1]。
目前红外与可见光图像融合方法包括传统融合方法与基于深度学习的融合方法[2-3]。传统的融合方法包括:基于多尺度变换的融合方法[4]、基于稀疏表示的融合方法[5]、基于显著性的融合方法[6]、基于混合模型的融合方法[7]等。其中,多尺度变换融合方法利用图像变换模型对源图像进行分解,再利用特定的融合规则合并不同尺度的特征,重构得到最终融合图像。稀疏表示方法利用多尺度变换分析字典或在线学习构造学习字典,其在一定程度上改进了多尺度融合方法,提高了融合效果。显著性方法可以很好地评判图像重要信息,使保留显著的图像特征,通常包含两种方式,即基于显著区域提取的图像融合和基于权重计算的图像融合[8]。混合模型联合多种模型的优点,克服单一模型缺陷,提高融合效果,常用的混合模型包括基于多尺度和稀疏方法的混合模型[7,9-10]、基于显著性和多尺度的混合模型等[11]。目前这些传统融合方法已经取得了一定的成果,但此类方法通常采用固定的数学模型提取图像特征,对模型敏感的特征才可以被有效提取。而不同源图像成像特性不同,图像特征复杂多变,固定的变换模型无法提取图像全面的特征信息。此外融合过程计算复杂且需要根据先验知识确定分解方法和融合规则,具有较大的局限性。因此,基于深度学习的融合方法广泛应用于红外与可见光图像融合领域,该方法可以有效挖掘图像复杂特征,克服了传统算法缺乏学习特征能力的缺陷。其包括基于卷积神经网络的图像融合与基于生成对抗网络的图像融合两部分[12]。其中,Liu等[13]通过卷积神经网络获取决策图整合红外图像与可见光图像的像素活动信息,该方法不需要考虑融合规则的设计与权重分配问题,但其特征提取能力有限。Li等[14]利用卷积核自动提取图像复杂特征,克服了之前单一模型只能提取图像敏感特征的局限性,但该方法是单输入单输出过程,故特征融合时需要设计复杂的融合规则或者使用现存的单一融合规则进行特征合并,而无法实现端对端的过程。新近,一些学者利用卷积神经网络实现了红外与可见光图像端到端的融合,并取得良好的效果[15-17]。但红外与可见光图像融合方法是多输入单输出的过程,它没有标准的融合图像监督网络参数学习的过程,因此,生成对抗思想的引入,实现有监督的图像融合过程。生成对抗融合方法利用生成损失函数控制生成器保留源图像的特征信息,再利用生成器与判别器之间的对抗损失使融合图像获取源图像更多细节信息,提高融合质量,如FusionGAN[18],首次将生成对抗思想引入图像融合领域,获得较好的融合效果,它利用卷积神经网络搭建端对端网络的同时,实现了源图像对网络学习的监督。随后,Ma等在FusionGAN的基础上改进网络,提出了ResNetGAN[19]与DDcGAN[20],并取得良好的融合效果。生成对抗融合方法以卷积神经网络为框架,通过其强特征提取能力与大数据驱动,极大地提高了融合质量,其次通过源图像与生成图像的对抗,实现源图像对学习参数的监督。但是因卷积核大小以及网络深度的限制,单一尺度深度特征表征空间信息能力有限;其次,卷积核所提取的特征依赖图像某一位置相关性最强的局部区域,而没有考虑特征图通道之间的相关性。
为了解决上述问题,提高图像融合质量,本文提出了红外与可见光图像注意力生成对抗融合方法。该方法将Res2Net[21]模块引入编码器中,作为卷积模块,增加了网络各层不同尺度的特征数量,提高了特征表示能力。其次,考虑到特征图自身通道之间的相关关系,采用通道自注意力机制,增强不同尺度、不同通道特征之间的依赖性,克服了卷积的局限性。最后,利用公开数据集,对本文方法与一些典型方法进行大量实验,从主观、客观的角度分析融合结果,验证本文方法的融合性能。
1 融合方法
1.1 融合模型结构
本文所提网络结构如图1所示。网络主要有两个部分,编码器(Encoder)和解码器(Decoder)构成的生成器以及两个判别器。编码器包含一个卷积层(C0),两个多尺度残差块(Res2Net1, Res2Net2)与一个通道自注意力机制(channel-self-attention, CA),该编码器在不影响网络深度的情况下,增强输出特征的多尺度表达能力,提高网络性能,同时建立特征通道之间的联系,增强了多尺度特征的全局特性;解码器由4个卷积层(C1, C2, C3, C4)构成,用于重构融合图像。生成器参数设置如表1所示。判别器包含4个卷积层(L1, L2, L3, L4)与一个全连接层(L5),其中红外判别器与可见光判别器具有相同的结构但不共享权重。在训练过程中,判别器提取图像特征,通过计算特征间的Wasserstein距离,感知特征差异,以鉴别源图像与生成图像。此外通过生成器与判别器之间的对抗关系,保留更多源图像细节。判别器参数设置如表2所示。
1.2 Res2Net模块
为了提高卷积神经网络多尺度特征提取能力,Gao等[21]提出了Res2Net模块,一种新颖的多尺度卷积网络架构,其结构如图2所示,它将传统的单一滤波器替换为一系列更小的滤波器组,该滤波器组以类似残差分层的模式进行连接,以增加不同尺度的特征数量。该模块先将输入特征图分为几组,每一组的输入特征图与先前组经过滤波器生成的特征图拼接在一起,并送入下一组卷积核进行处理。以此类推,将所有的特征图处理完毕。为了使不同尺度的信息融合得更好,Res2Net将拆分处理后的特征图拼接在一起,并通过1×1卷积核进行各尺度特征的信息融合。
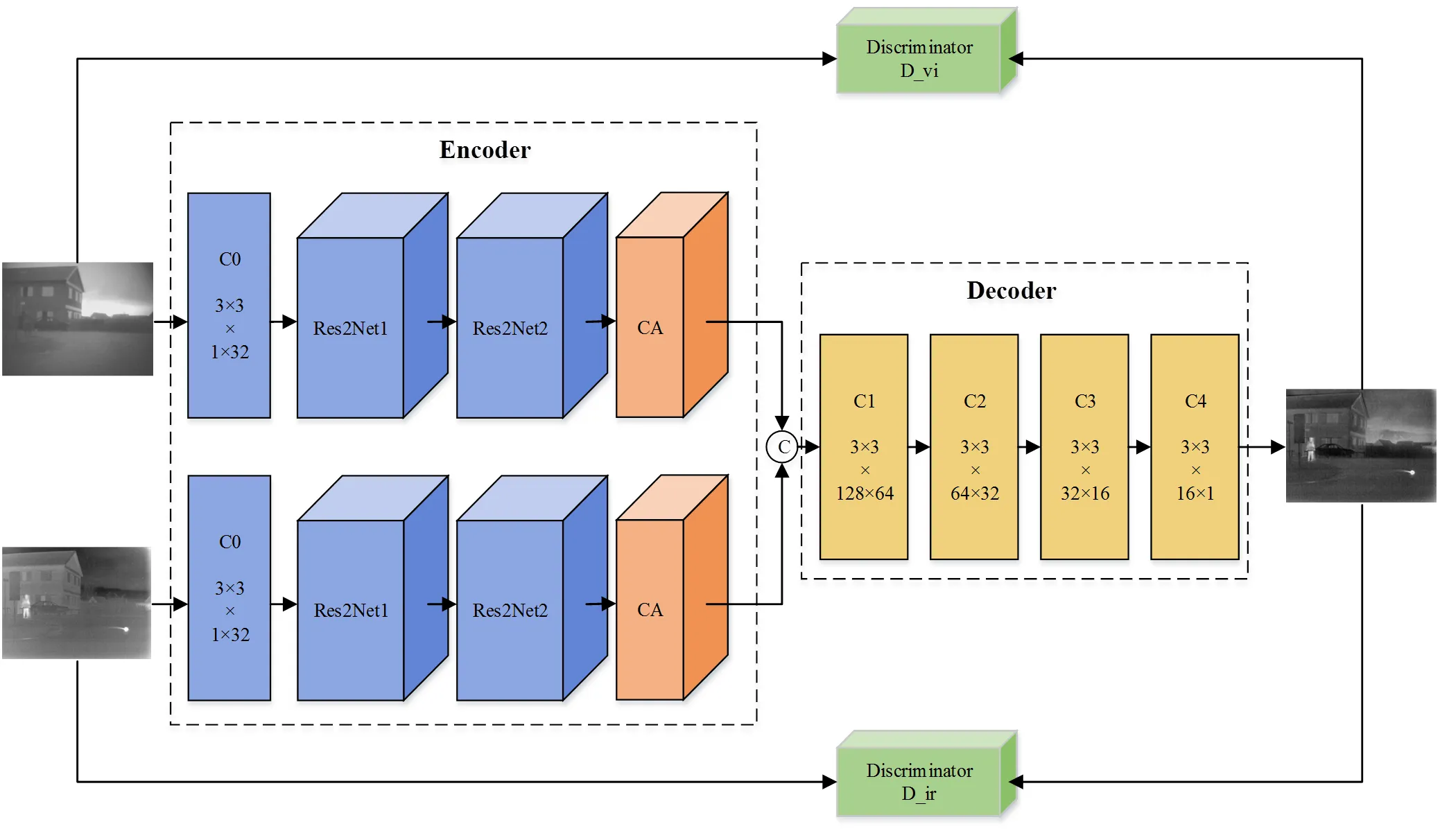
图1 本文方法网络结构
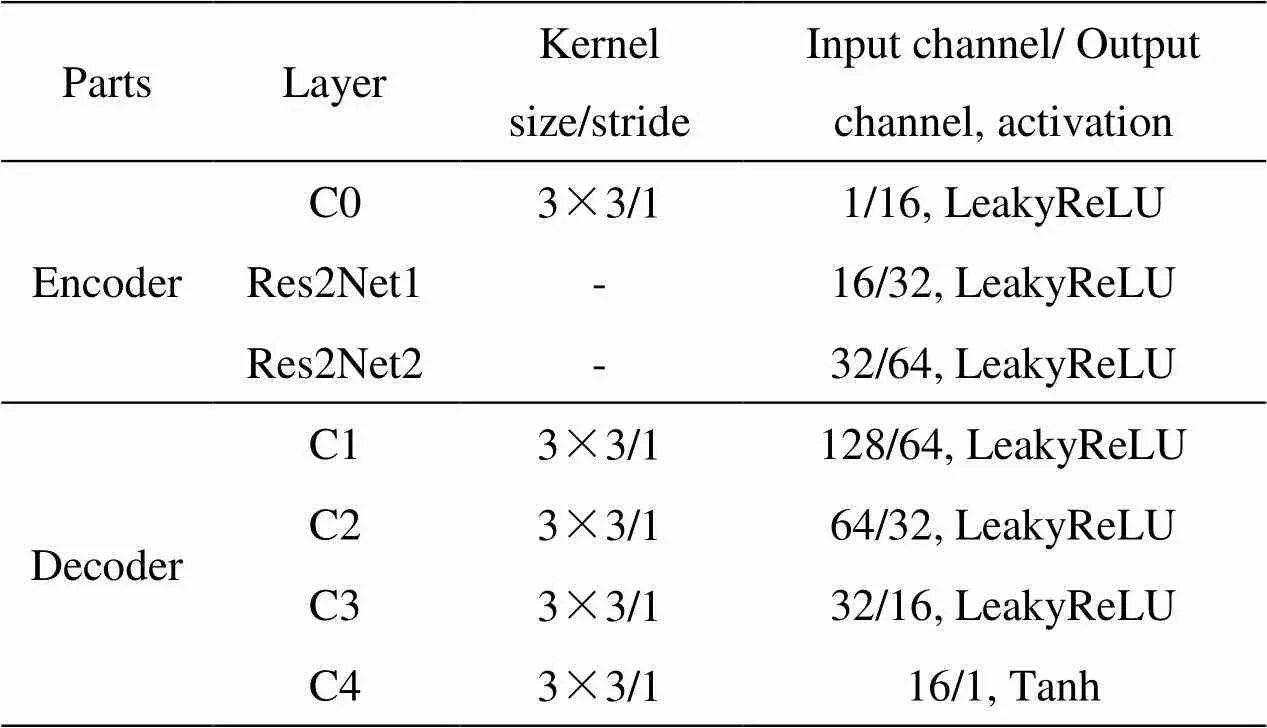
表1 生成器参数设置
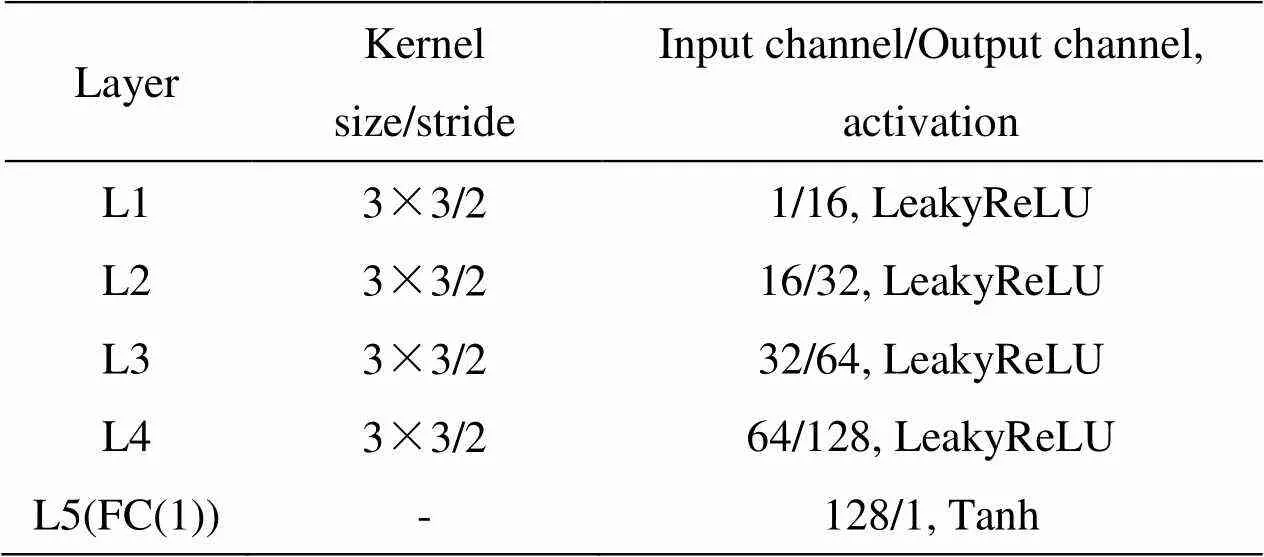
表2 判别器参数设置
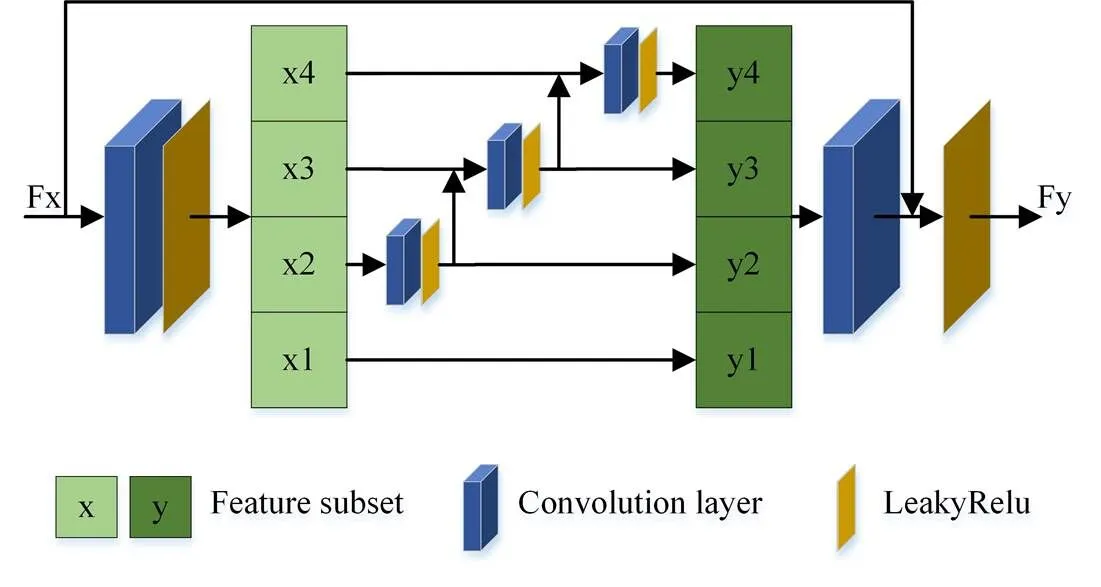
图2 Res2Net结构
本文将Res2Net引入编码器中,作为一个卷积模块,提取图像多尺度特征。此外,本文采用卷积层与LeakyReLU激活函数,并去除其中的BN层。
1.3 通道自注意力机制模块
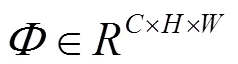
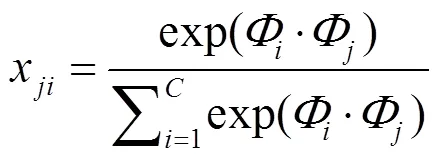
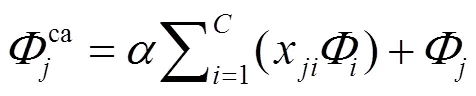
式中:权重因子从0开始学习。
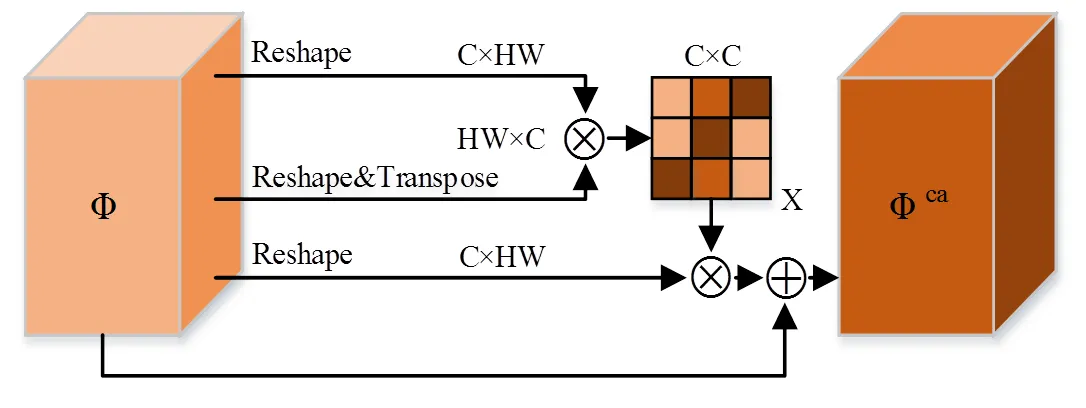
图3 通道自注意力结构
1.4 损失函数的设计
生成器损失函数由两部分组成,分别是生成对抗损失和语义损失,生成器损失函数如公式(3)所示:
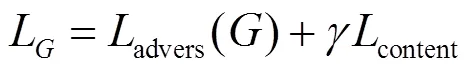
式中:第一项advers()表示生成器对抗损失;第二项content表示语义损失;表示平衡因子,用于平衡两项损失,本文中=1。
1)语义损失:语义损失促使生成器构造与源图像相似的数据分布。该损失主要有均方误差损失和边缘损失两部分,如式(4)所示。其中均方误差损失以图像像素为单位进行计算,分别估计融合图像与红外图像、融合图像与可见光图像之间数据分布的相似度,可以尽可能地保留红外图像的目标信息以及可见光图像像素级别的细节信息,如式(5)所示。但是均方误差容易造成融合图像模糊现象。故引入红外与可见光图像边缘损失,如式(6)所示,实现融合图像的锐化,补偿这一问题。其中,=5,vi=0.49,ir=0.51。
午后的太阳偶尔也会唱着火辣辣的歌曲,不减夏日势头地炙烤着大地,但这些丝毫不影响我们做运动。同学们似乎变得比平时更认真,个个头顶着烈日,随着激昂的音乐做起了广播体操。倘若来一场秋雨,同学们就会聚集在室内体育馆活动。瞧!那几位女同学还在跳高难度的长绳呢!还有几位生龙活虎的男同学正在进行如火如荼的羽毛球比赛。这一切,让秋日的校园增添了勃勃生机!
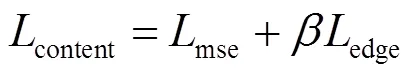
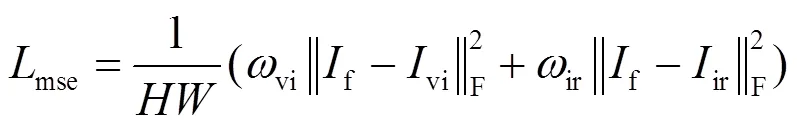
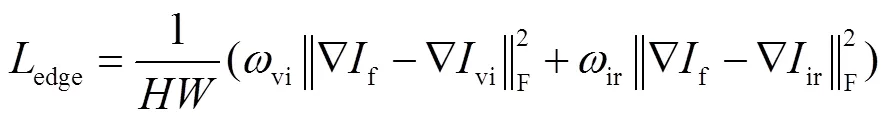
2)生成对抗损失:本文的网络模型中,设计了两个判别器,即红外判别器ir与可见光判别器vi。。它们分别使融合图像保留更多的红外、可见光的细节信息,因此生成对抗损失包含两部分,如式(7)所示:
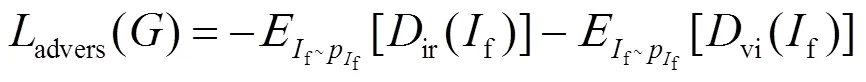
判别器损失函数用于训练判别器,使其可以有效鉴别生成图像与源图像,进而与生成器形成对抗,如式(8)所示:
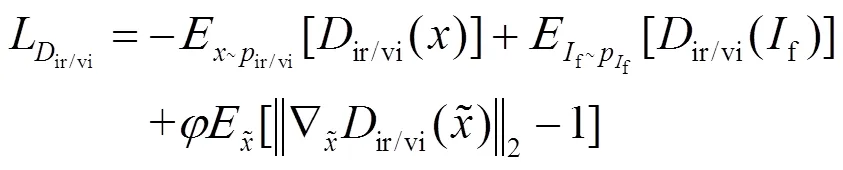
1.5 数据集与参数设置
在训练过程中,本文采用TNO的数据集,从TNO中选取49对不同场景的红外与可见光图像,由于49对图像无法训练一个良好的模型,因此,对源图像做预处理以扩大训练集。本文将源图像对做裁剪,裁剪大小为120×120,裁剪步长为12,以获取54594对红外与可见光图像,并将其归一化为[-1,1],以加快计算速度,减少内存占用。
此外,本文从训练集中选取batchsize=18的图像对。首先对红外判别器与可见光判别器分别训练次;其次再对生成器训练一次,生成器与判别器均采用Adam优化器。整个训练过程即重复上述过程次。在实验过程中的参数设置=2,=20。本文训练以及测试硬件平台为NVIDIA GeForce RTX 3090 GPU,Intel(R)Core(TM) i9-10850K CPU;软件环境为Windows10,Python3.7.10,Pytorch1.8.1。
2 实验结果与分析
2.1 实验说明
本文采用6个指标对融合结果作客观评价。客观指标包括信息熵(entropy, EN)、标准差(standard deviation, SD)、相关系数(correlation coefficient, CC)、相关差异和(the sum of the correlation differences,SCD)、结构相似度(multi-scale structural similarity index measure,MS-SSIM)、融合保真度(the visual information fidelity for fusion,VIFF)。其中,EN反映融合图像纹理信息的丰富程度,其熵值越大,则说明其保留了更丰富的源图像信息;SD表示各像素灰度相对于灰度平均值的离散情况,值越大,则所融合的图像对比度越高;CC描述融合图像与源图像的相似程度;SCD是表征图像质量的指标;MS-SSIM反映图像间的亮度、对比度、结构失真水平的差异性;VIFF反映视觉效果,其结果与主观评价结果具有一致性,值越大,则所融合的图像视觉效果越佳。
2.2 消融实验
为了验证网络结构中不同模块对融合结果的影响,本文对Res2Net模块与通道注意力模块分别进行实验,首先保留Res2Net模块并去除通道自注意力模块(记作No-CA);其次网络使用普通卷积层代替Res2Net模块,同时保留通道注意力模块(记作No-Res2Net)。
实验采用Roadscene数据集的105组红外可见光图像,分别对各类模型进行实验,客观指标评价如表3所示。由表3可知,本文模型的EN,SD,SCD,MS-SSIM,VIFF指标最高,仅在CC指标上略低于其他模型,表明Res2Net模块可以有效提取多尺度特征,同时通道注意力机制有效建立了特征通道之间的远程依赖关系,增强了多尺度特征的全局特性,提高融合结果性能。相比于其他模型,本文模型融合的结果包含较丰富的源图像信息,具有较高对比度以及较好的视觉效果。

表3 消融实验的定量比较
2.3 TNO数据集实验
本文从TNO数据集中选取20组图像定性定量分析融合结果,展示其中4组图像并做主观评价分析,分别包括“Nato_camp”、“helicopter”、“bench”以及”Movie_18”。
第一组对“Nato_camp”图像做融合,其图像及融合结果如图4所示,(a)中人影目标突出,而背景模糊;(b)中可以观察到树木纹理,房檐色彩、边缘以及围栏,背景清晰,但无法观察到人影;(c)(e)(g)(h)方法的融合结果纹理信息较好,但图像目标与背景区域对比度不高,导致图像一些纹理不易被观察,如围栏上的铁丝;(d)方法的融合结果边缘细节丰富,可以清晰的观察到烟囱的形状与围栏边缘等细节;(f)的融合结果目标对比度高,如人影,但背景纹理模糊,目标边缘信息丢失;本文方法增强了目标与背景区域的对比度,比其它方法更容易观察到图像细节,如树木纹理、围栏上的铁丝以及房檐色彩分布与轮廓等,视觉效果良好。
第二组对“helicopter”图像做融合,其图像及融合结果如图5所示,在(c)(d)(e)(g)(h)方法融合图像中,直升机边缘以及雨水细节保存较好,但目标与背景的对比度略低,不容易观察天空中云的分布,此外,直升机发动机亮度不高;(f)方法的融合结果保留雨水细节的同时,提高发动机亮度,螺旋桨转动细节清晰,但机身细节丢失;本文方法发动机亮度略高于(c)(d)(e)(g)(h)方法,且不影响机身细节,如窗户、起落架等,同时雨水细节没有丢失,又因对比度较高,容易捕捉到云的分布。

图4 “Nato_camp”实验结果
第3组对“bench”图像做融合,其图像及融合结果如图6所示,(c)(e)(g)(h)方法的融合结果存在“朦胧感”,背景对比度不高,长凳目标保留但不易观察;(f)方法的融合图像保留了人影的亮度,但其边缘模糊,背景细节丢失,如长凳以及背景色彩分布等。本文方法较好地保留了红外与可见光的信息,如人影,水中倒影以及长凳。

图5 “helicopter”实验结果

图6 “bench”实验结果
第4组对“Movie_18”图像做融合,其图像及融合结果如图7所示,(a)中可以观察到明显的人影、车子的轮廓、马路栏杆以及路牌,远景目标清晰,如树木、围墙,且房子对比度高,结构鲜明,如房顶、墙面与门窗;(b)中房子边缘较好,天空细节突出,但看不到人影以及远景树木等;与其他融合方法相比,本文方法的融合结果目标突出,如人影、车子、马路栏杆以及远景树木,此外边缘细节清晰,如天空,房檐边缘、色彩分布以及窗子开合等。总体视觉效果良好。
主观评价是根据人类视觉系统评估融合图像的质量,但仍会存在一定的偏差,为了更全面地评估融合图像的质量,本文使用6个指标对各方法融合结果进行客观评价。TNO数据集定量评价指标如图8所示,从图中指标来看,本文方法在EN,SD,CC,SCD,MS-SSIM,VIFF指标中平均数值最高,表明本文融合结果相比于其他方法包含更丰富的源图像信息,较高的对比度以及更好的视觉效果。

图7 “Movie_18”实验结果
2.4 Roadscene数据集实验
为了进一步验证本文方法融合性能,将从Roadscene数据集中选取20组图像做定性定量分析,展示其中两组图像并做主观评价分析,该两组图像分别命名为“example1”、“example2”。
第一组与第二组分别对“example1”、“example2”图像做融合,其图像及融合结果如图9、图10所示,与之前TNO四组融合结果主观评价一致,本文方法在不丢失红外目标的情况下,尽可能多地保留可见光的细节信息。此外,本文使用6个指标对各方法融合结果做客观评价,Roadscene数据集定量评价指标如图11所示,从图中指标来看,相比于其他方法,本文方法在EN,SD,CC,SCD,MS-SSIM,VIFF指标中平均数值最高,表明本文融合结果包含与源图像更相似的结构,具有较高的对比度以及更符合人眼的视觉系统,有利于人眼观察。

图8 “TNO”数据集定量评价指标

图9 “example 1”实验结果

图10 “example 2”实验结果
为了进一步评价本文方法与其他融合方法的时间效率,采用TNO、Roadscene数据集的红外可见光图像进行实验。时间效率比较如表4所示,其中基于传统融合方法CVT、ASR与WLS在CPU上运行,基于深度学习融合方法DenseFuse、FusionGan与IFCNN在GPU上运行。由表4可知,其计算效率仅次于IFCNN与DenseFuse,不同于它们的平均规则融合,本文融合方法利用多尺度模块代替普通卷积层,同时与通道自注意力模块级联,计算量较大。因此,与其他方法相比,所提方法具有较高计算效率同时能保持良好的融合效果。
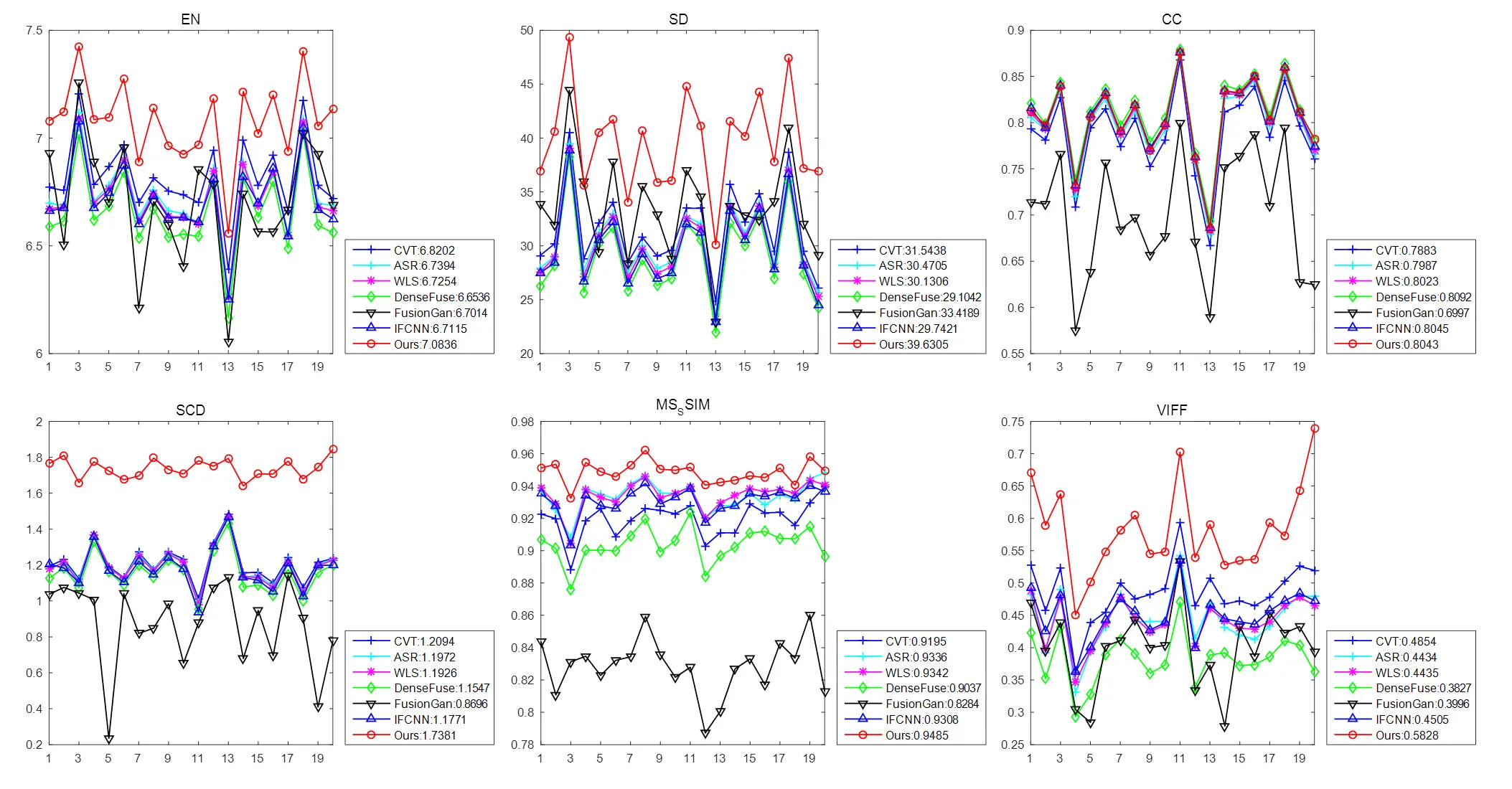
图11 “Roadscene”数据集定量评价指标
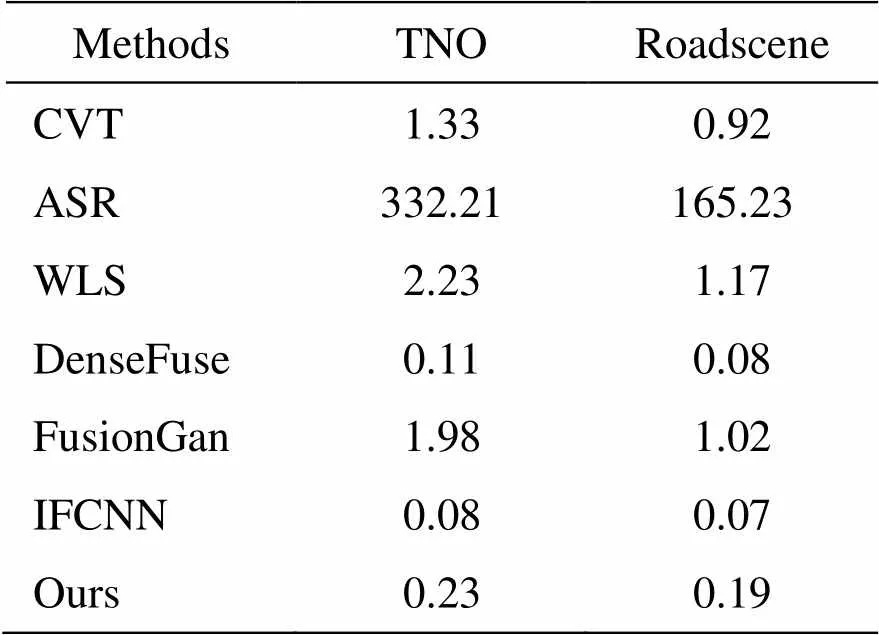
表4 时间计算率比较
3 结语
本文提出了一种红外与可见光图像注意力生成对抗融合方法,该方法使用多尺度模块代替传统卷积层,将传统的单一滤波器替换为一系列更小的滤波器组,在不影响网络深度的同时提高网络的宽度,增加了网络各层不同尺度的特征数量,增强网络特征表达能力;其次,将通道自注意力机制引入编码器中,增强不同尺度、不同通道特征之间的依赖性,克服了卷积的局限性;与其他典型融合结果相比,本文方法在主观客观上都有良好的融合效果。但同时本方法在目标显示上不是特别突出,背景纹理略带虚影,且模块带来指标提升较为微弱。因此优化模型,最大限度提高多尺度模块与自注意力机制模块的作用;同时使融合结果保留清晰的可见光细节信息、突出目标区域对比度将是下一阶段研究的重点。
[1] MA J, MA Y, LI C. Infrared and visible image fusion methods and applications: a survey[J]., 2019, 45: 153-178.
[2] LI S, KANG X, FANG L, et al. Pixel-level image fusion: a survey of the state of the art[J]., 2017, 33: 100-112.
[3] LIU Y, CHEN X, WANG Z, et al. Deep learning for pixel-level image fusion: Recent advances and future prospects[J]., 2018, 42: 158-173.
[4] LI S, YANG B, HU J. Performance comparison of different multi-resolution transforms for image fusion[J]., 2011, 12(2): 74-84.
[5] ZHANG Q, LIU Y, Rick S Blum, et al. Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: a review[J]., 2018, 40: 57-75.
[6] ZHANG Xiaoye, MA Yong, ZHANG Ying, et al. Infrared and visible image fusion via saliency analysis and local edge-preserving multi-scale decomposition[J]., 2017, 34(8): 1400-1410.
[7] YU L, LIU S, WANG Z. A general framework for image fusion based on multi-scale transform and sparse representation[J]., 2015, 24: 147-164.
[8] HAN J, Pauwels E J, P De Zeeuw. Fast saliency-aware multimodality image fusion[J]., 2013, 111: 70-80.
[9] YIN Haitao. Sparse representation with learned multiscale dictionary for image fusion[J]., 2015, 148: 600-610.
[10] WANG Zhishe, YANG Fengbao, PENG Zhihao, et al. Multi-sensor image enhanced fusion algorithm based on NSST and top-hat transformation[J]., 2015, 126(23): 4184-4190.
[11] CUI G, FENG H, XU Z, et al. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition[J]., 2015, 341: 199-209.
[12] LI Q, LU L, LI Z, et al. Coupled GAN with relativistic discriminators for infrared and visible images fusion[J]., 2021, 21(6): 7458-7467.
[13] LIU Y, CHEN X, CHENG J, et al. Infrared and visible image fusion with convolutional neural networks[J]., 2018, 16(3): 1850018.
[14] LI H, WU X J. DenseFuse: a fusion approach to infrared and visible images[J].:, 2019, 28(5): 2614-2523.
[15] XU H, MA J, JIANG J, et al. U2Fusion: A unified unsupervised image fusion network[J]., 2020, 44(1): 502-518.
[16] HOU R. VIF-Net: an unsupervised framework for infrared and visible image fusion[J]., 2020, 6: 640-651.
[17] HUI L A, XJW A, JK B. RFN-Nest: An end-to-end residual fusion network for infrared and visible images[J]., 2021, 73: 72-86.
[18] MA J, WEI Y, LIANG P, et al. FusionGAN: a generative adversarial network for infrared and visible image fusion[J]., 2019, 48: 11-26.
[19] JM A, Pl A, WEI Y A, et al. Infrared and visible image fusion via detail preserving adversarial learning[J]., 2020, 54: 85-98.
[20] MA J, XU H, JIANG J, et al. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion[J]., 2020, 29: 4980-4995.
[21] GAO S, CHENG M M, ZHAO K, et al. Res2Net: A new multi-scale backbone architecture[J]., 2021, 43(2): 652-662.
[22] FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation[C]//2019, 2020: DOI: 10.1109/cvpr. 2019.00326.
[23] Nencini F, Garzelli A, Baronti S, et al. Alparone, remote sensing image fusion using the curvelet transform[J]., 2007, 8(2): 143-156.
[24] LIU Y, WANG Z. Simultaneous image fusion and denoising with adaptive sparse representation[J]., 2014, 9(5): 347-357.
[25] MA J, ZHOU Z, WANG B, et al. Infrared and visible image fusion based on visual saliency map and weighted least square optimization[J]., 2017, 82: 8-17.
[26] YU Z A, YU L B, PENG S C, et al. IFCNN: A general image fusion framework based on convolutional neural network[J]., 2020, 54: 99-118.
Infrared and Visible Image Fusion Using Attention-Based Generative Adversarial Networks
WU Yuanyuan,WANG Zhishe,WANG Junyao,SHAO Wenyu,CHEN Yanlin
(School of Applied Science, Taiyuan University of Science and Technology, Taiyuan 030024, China)
At present, deep learning-based fusion methods rely only on convolutional kernels to extract local features, but the limitations of single-scale networks, convolutional kernel size, and network depth cannot provide a sufficient number of multi-scale and global image characteristics. Therefore, here we propose an infrared and visible image fusion method using attention-based generative adversarial networks. This study uses a generator consisting of an encoder and decoder, and two discriminators. The multi-scale module and channel self-attention mechanism are designed in the encoder, which can effectively extract multi-scale features and establish the dependency between the long ranges of feature channels, thus enhancing the global characteristics of multi-scale features. In addition, two discriminators are constructed to establish an adversarial relationship between the fused image and the source images to preserve more detailed information. The experimental results demonstrate that the proposed method is superior to other typical methods in both subjective and objective evaluations.
image fusion, channel self-attention mechanism, deep learning, generative adversarial networks, infrared image, visible image
TP391.4
A
1001-8891(2022)02-0170-09
2021-05-29;
2021-07-20.
武圆圆(1997-)女,硕士研究生,研究方向为光学测控技术与应用。E-mail:yywu321@163.com。
王志社(1982-)男,副教授,博士,研究方向为红外图像处理、机器学习和信息融合。E-mail:wangzs@tyust.edu.cn。
山西省面上自然基金项目(201901D111260);信息探测与处理山西省重点实验室开放研究基金(ISTP2020-4);太原科技大学博士启动基金(20162004)。
