深度森林研究综述
2022-02-22乔俊飞
夏 恒, 汤 健, 乔俊飞
(1.北京工业大学信息学部, 北京 100124; 2.计算智能与智能系统北京市重点实验室, 北京 100124)
深度神经网络(deep neural network, DNN)以强大的学习能力成为当前研究热点[1-2]. DNN通过对初始样本的逐层变换将初始特征转换到新的特征空间,最终获得层次化的深层特征表示. 目前DNN在Alphago[3]、关系推理[4]和视觉互动网络(visual interaction network,VIN)[5]等许多单应用场景中的认知能力已超越人类,但其黑箱模型的本质、对训练数据的要求和大量超参数的调整等因素限制了在理论和可解释性分析等方面的深入研究,以及在小样本数据应用场景的推广.
近年来,在计算机视觉等领域中,先采用卷积神经网络(convolutional neural networks, CNN)[6-7]提取深度特征,再采用随机森林(random forest, RF)作为分类器的模型结构被称为深度森林(deep forest,DF)[8-9],但这类方法在本质上并不具有完全非神经网络模式的深度结构. 基于DNN存在的上述问题,文献[10]首次提出了由多粒度扫描和级联森林组成的DF算法,初步探索了基于非微分基学习器集成的深度学习模型,开启了非神经网络结构的深度学习模式. 与此同时,文献[11]提出了采用决策树(decision tree, DT)替换DNN中神经元的前瞻性深层随机森林(forward thinking deep random forest, FTDRF)算法,降低了级联森林模型的算法复杂度. 上述这些研究工作表明,基于DT的深度集成模型能在无反向传播策略的情况下进行有效学习,并取得令人满意的预测性能.
目前,对DF结构的改进主要集中在其2个组成部分,即多粒度扫描和级联森林. 一部分的本质是数据预处理,主要任务是将原始数据信息转换成可供级联森林模型学习的有效信息. 基于建模数据特点进行改进的典型方式包括采用主成分分析(principal component analysis,PCA)预处理原始光谱数据[12]和采用深度玻尔兹曼机(deep Boltzmann machine, DBM)预处理工业过程变量[13]等. 另一部分的本质是构建学习模型,其主要任务是利用预处理后的数据构建深度集成预测模型,典型改进方式包括增加实例权重的提升级联深度森林(boosting cascade deep forest, BCDForest)[14]、基于子森林权重分配的加权深度森林(weight deep forest, WDF)[15]和基于密集连接网络DenseNet思想[16]的密度自适应级联森林(dense adaptive cascade forest, daForest)[17]等.
此外,DF作为集成学习家族的深度结构模式,增加其基学习器的多样性也是研究学者热衷的方向之一. 面向学习器数量所表征的差异性,文献[18]采用XGBoost和RF作为基学习器;文献[19]采用柔性神经树(flexible neural tree, FNT)[20]构建级联森林层等. 面向学习器类型所表征的差异性,文献[21]采用多示例RF和多示例极限随机树[22]构建级联森林层模块;文献[23]在每一级联层中采用4个旋转森林等. 上述改进的DF算法主要是从基学习器组合设计的角度增加深度集成模型内部的多样性,同时也促进了深度集成模型结构的多元化研究.
与此同时,针对DF所固有的高内存消耗和时间成本等问题,众多学者从不同角度进行了研究. 例如:文献[24]基于分布式并行平台实现了级联森林模块的并行计算;文献[25]利用特征贡献率对DT进行剪枝,并通过简化基学习器降低DF模型的复杂度;文献[26]通过在DF的框架中引入置信度筛选机制减少级联层森林模块的训练和测试时间. 此外,针对级联森林的结构设计,文献[27]将初始DF中每层4个森林(4×1)拆分成2个子层(2×2)以获得改进结构的DF.
基于上述DF研究进展,本文首先介绍DF的基本结构及其性质,然后将其现状分为引入特征工程、改进表征学习、修改基学习器、修改层级结构和引入权重配置等方向并进行综述和分析,接着介绍DF的应用领域并指出主要面临的挑战及未来研究方向,最后总结本文工作.
1 DF的结构与性质
DF算法由多粒度扫描和级联森林2个模块构成,其针对三分类任务的结构如图1所示.
图1中各模块的主要功能如下.
1) 多粒度扫描模块:以滑动窗口尺寸s为例,首先,用尺寸为s的滑动窗口将M维原始特征向量变换成大小为(M-s)+1维的特征向量;然后,利用RF和完全随机森林(completely random forest, CRF)进行特征转换以获得类分布向量;最后,将其串联以获得增强特征向量. 重复上述步骤,获得多个增强特征向量. 在初始DF算法中,多粒度扫描的次数一般设置为3.
2) 级联森林模块:每个级联层采用CRF和RF两种类型的森林算法作为基学习器进行建模,然后采用Stack策略[28]实现逐层训练. 为了防止特征在逐层传递中造成过拟合现象,级联层间利用转换特征向量与原始特征向量串联作为下一级联层模型的训练数据. 同时,级联森林模块采用交叉验证的方式进行级联层数(即深度)的自适应调整.
基于非微分基学习器的DF算法具有良好的表征学习能力,在训练数据较少时也具有良好的泛化性能,其主要优点如下:1) 级联层数随训练过程自适应调节;2) 超参数少且对超参数的调节不敏感,一组超参数甚至可用在不同数据集上;3) 具有并行处理的结构;4) 相对于DNN的黑箱模型,DF更易进行理论分析.
2 RF研究现状
目前DF主要应用在分类领域,本文将其研究方向分为5个子方向,即引入特征工程、改进表征学习、修改基学习器、修改层级结构和引入权重配置,如图2所示. 其中,在引入特征工程子方向主要综述以多粒度扫描为代表的数据预处理;在改进表征学习子方向综述增加类分布向量、类分布向量降维和特征优化3个方面;在修改基学习器子方向综述改变基学习器种类以及种类与数量均改变2个方面;在修改层级结构子方向综述改变级联层排列;在引入权重配置子方向综述赋予实例和学习器权重2个方面.

图2 DF研究方向分类Fig.2 Classification of DF research directions
2.1 引入特征工程
由基于不同领域数据的特征空间和样本空间假设的差异以及“没有免费的午餐”理论[29]可知,难以构建在不同情况下均获得较佳泛化性能的模型,这使得特征工程成为建模前的必要步骤. 因此,多粒度扫描模块作为一类特征工程方法,在很大程度上决定着DF模型的泛化性能. 目前,特征提取或样本采样等预处理方法在DF中的研究策略包括:直接替代多粒度扫描模块、将预处理后的数据输入至多粒度扫描模块和在多粒度扫描模块后进行特征处理等.
在实际应用场景中获取的原始数据普遍存在异常值、噪声和类分布不平衡性等问题. 因此,研究人员基于数据特性采用预处理方式取代DF中的多粒度扫描模块. 在图像识别领域,文献[15]采用PCA预处理原始光谱数据,如图3所示. 图中,其原始光谱数据的特征空间T(m×h)×b被压缩成R(m×h)×n以获得特征向量X1D,然后训练级联森林模型以实现卫星遥感图像分类.

图3 PCA处理光谱数据流程图[15]Fig.3 Flow chart of PCA processing spectral data[15]
随后,文献[30]在此基础上采用t分布随机相邻嵌入方法(t-distributed stochastic neighbor embedding,t-SNE)对高维光谱数据进行预处理,将其映射到低维空间中并保持在原始特征空间的概率分布不变,最终应用于水稻种子冻害程度的识别.
针对软件缺陷中的源数据由抽象逻辑符号组成的特殊性,文献[31]通过Z-Score标准化策略获取特征信息,其过程如图4所示.

图4 基于Z-Score标准化的DF结构[31]Fig.4 DF structure based on Z-Score standardization[31]
在图4中,N维标准缺陷特征被Z-Score标准化处理后得到N维转换特征,接着将其作为级联森林输入构建软件缺陷检测模型.
此外,也有研究学者采用先预处理原始数据,再采用多粒度扫描模块,最后训练级联森林模型的策略. 文献[32]采用基于带通滤波器和局部颜色迭代矫正的连通域提取图片文字信息特征,然后通过使用随机蕨[33]构建的多粒度扫描模块生成转换特征向量,最后构建级联森林模型. 为了从复杂背景中提取船舶的形状和结构,文献[34]设计了基于梯度特征向量训练的区域建议网络并用于提取热遥感图像中的船舶区域特征,其过程如图5所示.
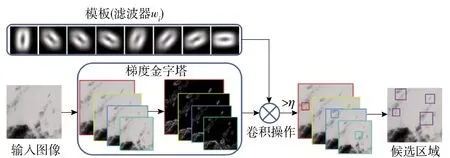
图5 船舶的形状和结构特征提取过程[34]Fig.5 Shape and structure feature extraction process of the ship[34]
图5所示处理过程可简述为:首先定义8个用于检测不同方向的船舶滤波器,其中每个滤波器由线性支持向量机训练且对应某个方向;然后通过卷积操作进行模板匹配,进而对梯度金字塔中的子窗口进行评分;如果任意一个滤波分数大于阈值η,则被作为后续判别的候选区域,否则当前窗口被识别为海洋背景;重复多次运行后得到候选区域数据,最后构建DF模型以实现船舶识别.
针对工业过程分布式控制系统(distributed control system, DCS)采集和存储的工业大数据,文献[16]在多粒度扫描前引入深度玻尔兹曼机(deep Boltzman machine,DBM)将过程数据转换成二进制向量,如图6所示.

图6 DBM特征提取[16]Fig.6 Feature extraction process of DBM[16]
图6所示的处理过程可描述为:原始400维输入特征向量被DBN模型转换为不同维度大小的二进制向量,实现了利用二进制特征向量替代原始特征向量,进而极大地减小了DT处理连续属性数据的计算困难;然后,二进制特征向量被多粒度扫描模块转换成2 400维的转换特征向量,进而用于训练级联森林模块以获得故障诊断模型. 该模型在田纳西州伊士曼化工过程的故障诊断实验结果表明,其分类精度优于传统的DBN方法.
在处理幼儿注意缺陷多动障碍样本中的类不平衡问题中,文献[35]采用合成少数过采样技术(synthetic minority over-sampling technique, SMOTE)[36]和最近邻编辑器(edited-nearest neighbor, ENN)[37]的策略进行数据预处理,构建基于DF的幼儿多动障碍诊断模型. 随后,针对癌症基因组图谱数据的样本类不平衡问题,文献[38]首先采用SMOTE策略对癌症基因组图谱数据中的少数不平衡类样本进行扩充,然后采用Tomek Link方法[39]剔除样本扩充过程中所引入的噪声以实现原始样本的类间相对平衡,最后构建DF模型.
不同于上述的数据预处理方式,文献[40]在文献[12]的基础上,通过引入平均池化层实现转换特征向量的维数约简,其过程如图7所示.
图7所示处理过程可描述为:首先采用PCA处理光谱数据获得(2w-1)×(2w-1)×p维的特征空间,接着利用多粒度扫描生成2类尺寸为w×w×c的特征空间,然后在平均池化层中进行约简以获得(w/2)×(w/2)×c的新特征空间,扁平层叠后作为级联森林的输入.

图7 基于平均池化的光谱数据处理过程[40]Fig.7 Spectral data processing process based on average pooling[40]
研究表明,上述特征工程方法均能提升DF模型性能,但无法确定哪种特征工程方法适用于所有领域的实际问题. 未来研究中,特征工程方法的选取存在3种策略:基于实际数据特性、基于实验判断和基于经验确定.
2.2 改进表征学习
级联森林模型以多粒度扫描或特征工程预处理后的转换特征向量为输入进行逐层训练,级联森林层与层之间利用类分布概率信息实现表征学习. 本文将其分为增加类分布向量、类分布向量降维和特征优化3个子方向.
1) 增加类分布向量. 在不采用自适应层数调整策略时,级联层误差随着深度的不断增加会出现剧烈跳变的现象. 文献[41]认为,级联层的稀疏连通性导致特征向量所携带信息不断退化,为消除这一现象,提出daForest算法. 其创新性体现在:当前级联层的表征特征中包含之前所有层的表征特征信息,主要特点是在级联层中增加了类似DenseNet[42]的连接方式,研究表明该结构针对高维稀疏数据和低维数据均能有效防止级联层间的信息流削弱. 与此同时,文献[43]根据Wolpert的堆叠泛化思想[44],提出了深度堆叠森林结构(deep stacking forest, DSF),其结构如图8所示.

图8 基于堆叠泛化的级联层结构[43]Fig.8 Cascade layer structure based on stacked generalized[43]
由图8可知,该结构与原始DF的明显区别是:将级联森林中已构建级联层的输出和原始特征向量组合作为新级联森林层的输入.
上述研究虽然从不同思想获得灵感,但最终级联层森林模型的结构却具有一致性.
2) 类分布向量降维. 由于堆叠级联模型的表征特征向量维度随着级联层深度的增加而逐渐变大,进而增加了模型的时间复杂度. 为了解决上述问题,文献[45-46]提出一种降低类分布向量堆叠的方法,其结构如图9所示.
由图9可知,该方法将原始特征向量与之前每级联层输出的类分布向量的平均值进行重组,进而获得增强特征向量以训练下层模型.

图9 基于增强特征向量的级联层结构[45]Fig.9 Cascade layer structure based on augmented feature vector[45]
为降低DF的空间复杂度和提高其收敛速度与运行效率,文献[47]以同类森林模型输出的同类分布概率结果的均值作为输入,以达到对类分布向量进行降维的目的.
3) 特征优化. 以降低级联森林模型时间消耗为目的,文献[48]在级联层中加入特征优化模块,其结构如图10所示.

图10 加入特征优化模块的级联层结构[48]Fig.10 Cascade layer structure with feature optimization module[48]
由图10可知,级联层中的4 024维的增强层向量通过特征优化模块后再输入至下一层. 该特征优化模块依据预测误差度量原始特征向量和类分布向量的重要性,选取最具区别性的特征进行逐层训练以实现删除不重要特征的目的,进而降低计算时间成本.
2.3 修改基学习器
DF作为一种深度集成结构,其性能取决于作为基学习器的森林算法之间的差异性和自身精度[49]. 目前,已有众多研究学者对基学习器的种类和数量进行了研究,以提高其多样性.
1) 改变级联层中基学习器种类. 考虑到基学习器间的差异性,文献[21]在级联森林模块中采用多示例RF和多示例极限随机树[22]取代RF和CRF. 针对遥感图像分类中RF与CRF性能相似而导致多样性较弱的问题,文献[50-51]采用旋转森林[52]与RF构建级联层模型. 随后,文献[53]为提高建模精度,在级联森林层采用4个旋转森林. 与此同时,采用不同基学习器组合的策略相继被提出,例如,基于逻辑回归[54-55]、XGBoost[56]、Extratrees和LightGBM[57]等,其一般性结构如图11所示.

图11 改变基学习器种类的一般性结构[57]Fig.11 General structure of changing the type of base learner[57]
由图11可知,级联森林中每层均由不同类型的基学习器组成,共包含了LightGBM、RF、XGBoost和Extratrees四种类型.
2) 改变级联层中基学习器数量和类型. 该研究主题主要包括2种相反的研究方向. 其中一个研究方向是减少基学习器数量或类型. 针对网格结构化数据分类问题,文献[18]仅采用XGBoost和RF作为基学习器构建级联层. 在工业过程故障检测中,文献[58]采用XGBoost、RF和Extratrees共3种类型的基学习器构建级联层. 在癌症亚型分类中,文献[19]采用6个FNT构建级联森林层. 上述研究结果表明,基学习器数量或类型的减少并未导致模型性能下降. 另一个研究方向是增加基学习器数量或类型. 在电力系统暂态评估中,文献[59]采用基于信息增益比RF、基于基尼指数的RF、基于信息增益比的CRF、基于基尼指数的完全随机树森林和极端随机树共5种不同类型的基学习器. 在雷达高分辨率距离剖面自动目标识别中,文献[60]所提方法的级联森林层包含RF、Extratrees、XGBoost和梯度提升树(gradient boosted decision trees,GBDT)[61]各2个基学习器,共8个基学习器. 上述这些研究表明,基学习器类型或数量的增加能明显提高模型的泛化性能,其一般性结构如图12所示.

图12 改变基学习器种类和数量的一般性结构[60]Fig.12 General structure of changing the type and quantity of base learners[60]
由图12可知,每层级联森林均由不同类型和数量的基学习器组成,其包含2个RF、2个Extratrees、2个Xgboost和2个GBDT学习器.
以上研究虽然对基学习器的多样性进行了不同程度的探索,但还存在以下问题有待深入研究:1) 由于增加级联层子森林数量(宽度)会增加模型的训练成本,故级联层宽度与深度的动态调整需进一步研究. 2) 对如何增加基学习器种类的研究缺乏相关性分析. 因此,对如何分析基学习器的贡献以及避免其增加的主观随意性均有待于深入研究.
2.4 修改层级结构
DF作为深度学习领域的新成员,如何对其深度结构进行设计是减少模型冗余以提高运行效率的主要手段之一. 目前,针对级联层的结构设计的研究仅限于文献[30,62]提出的层级调整策略,其结构如图13所示. 由图13可知,其策略为将每一级联森林层中的4个森林模型(2RF+2CRF,4×1)拆分成2个子层(2×2). 笔者认为,图13所示结构的改进动机源于DNN框架中的“层数比神经元数量更重要”的思想. 本质上,虽然通过局部结构调整提高了整体模型的性能,但从表征学习的视角出发可将上述结构归类为局部密度连接.

图13 修改层级结构的级联森林[30]Fig.13 Cascading forest of modification of the hierarchical structure[30]
2.5 引入权重配置
一般来说,数据空间潜在的不平衡性和基学习器的差异性是降低集成模型性能的主要原因之一. 针对上述问题,引入权重配置是广为认可的解决策略. 在面向DF的权重配置研究中,主要集中在面向实例和学习器2个子方向.
1) 赋予实例权重
针对DF算法拟合性能弱和多样性缺失等问题,文献[14]根据Boosting思想提出了提升深度森林(boosting cascade deep forest, BCDForest). 其依据多粒度扫描模块中森林算法的袋外误差(out-of-bagging)[64-65]获得权重系数W=(ω1,ω2,…,ωn),再以所产生的类分布向量X=(x1,x2,…,xn)为实例分配权重,公式为
(1)

针对级联结构逐层传递所有实例导致模型时间复杂度增大的问题,文献[66]利用置信筛选机制[26]为实例xi分配权重ωi,策略是:当ωi≠0时,实例xi进入下层训练;反之,实例xi停留在当前层. 因此,根据第i个实例在前一级联层森林中生成的类分布向量的平均值vi为实例xi分配权重
ωi=f(d(vi,oi))
(2)
式中:oi表示标签向量;d(vi,oi)表示vi向量与oi之间的距离.
针对实例中特征对模型性能的影响,文献[45]根据特征对模型的贡献度提出了自适应DF算法,主要通过引入AdaBoost思想为特征赋予权重,进而减小对分类结果影响较大的特征权重,其特点是在训练过程中重点关注对训练效果影响较小的特征.
2) 赋予学习器权重
针对建模样本的类间不平衡问题,文献[67-68]基于DT模型引入权重概念,以缩小相同类实例间的距离和扩大不同类实例间的距离为准则,定义损失函数

(3)
式中:zij表示xi向量与xj向量是否属于同一类,若属于同一类,则zij=0,否则zij=1;d(xi,xj)表示xi向量与xj向量之间的距离;τ为微调系数;λ‖w‖2表示正则项,其中λ是控制正则化强度的系数.
为提高DF模型性能,文献[69]利用Pari-mutuel模型[70]对类概率分布向量进行权重配置,即
(4)
式中:pt表示子森林类分布向量;pk,t表示决策时的类分布向量;ωj表示DT权重.
针对级联层数逐渐增大导致DT的错误预测降低模型泛化性能的问题,文献[15]提出加权平均策略,其步骤为:首先,依据
ak=Acc(Predict(·),Y(·))
(5)
计算DT的准确率. 式中ak表示针对训练样本集的预测准确率.
然后,根据每棵DT的预测精度计算其权重
(6)
最后,对DT的预测概率向量进行加权求和以提高预测精度和降低级联层数.
为进一步提高DF在具有小样本、高维和类不平衡等特性数据中的适用性,文献[71]提出利用森林算法对预测贡献度进行权重配置,进而改进DF模型,其步骤为:首先,通过采用Wilcoxon-Mann-Whitney Statistic[72]计算接收者操作特征(receiver operating characteristic,ROC)曲线下方的面积[73]A来评价森林算法的性能,且
(7)
式中:xi表示分类器输出为正类,1≤i≤m;yi表示输出为负类,1≤j≤n.
然后,采用标准化的A值计算权重
(8)
(9)
式中:α1表示RF的权重;α2表示CRF的权重.
研究表明,基于实例和学习器的权重配置在提高DF算法性能同时也导致模型超参数和算法复杂度的增加. 模型复杂度过高容易出现过拟合,进而导致泛化误差偏大,反之则会欠拟合导致泛化误差减小. 显然,这需要结合实际应用领域进行均衡.
3 DF应用
DF相较于DNN具有明显的独特性,目前在很多领域都已涌现出大量相关研究.
3.1 DF在图像识别中的应用
在文献[10]提出DF之初,其就在图像分类、人脸识别、语音识别和情感分类等领域与CNN、深度信念网络[74]、ResNet[75]和AlexNet[76]等深度学习方法进行对比,并取得了不弱于或优于这些方法的结果. 此外该模型克服了目前深度学习需要大量训练样本的缺点,进而减少了样本真值标注的成本. 随后,众多研究者在计算机视觉领域对DF进行了广泛应用.
文献[12]针对高光谱图像分类问题,采用PCA降低维数后利用DF构建分类模型,实验结果表明,该模型与CNN相比具有更少的超参数和更快的训练速度. 在此基础上,文献[77]提出基于CNN的迁移学习方法,利用在最后一个卷积层中提取的特征训练DF模型,基于遥感图像数据集的结果表明,与全层训练、微调和最先进CNN等方法相比该模型在预测精度和训练时间方面均具有优越性.
针对火焰检测问题,文献[78]建立了基于双视角和深层多粒度扫描的DF模型,通过采用帧频提升的高斯混合模型构建图片背景,减少了火焰自身光亮变化以及周围环境对目标检测和识别的干扰,其在不同场景的平均火焰检测率达到95.99%.
针对车辆行为分析问题,文献[79]提出将DF和结构化标签融合的结构化深度森林(structured deep forest, StruDF),结果表明其具有与传统方法相媲美的识别精度.
3.2 DF在故障诊断中的应用
针对工业过程故障诊断问题,文献[13]提出了基于DBM和DF的模型,其采用DBM获取数据与潜在故障之间的复杂映射,先将特征转换成二进制数据后建立DF诊断模型,在不同实验条件下的实验结果表明其分类准确率优于主流深度学习算法. 理论上,DNN的不可解释性是其在实际智能诊断应用中的主要难题. 对此,文献[80]提出应用于滚动轴承故障诊断的DF模型,结果表明该模型具有高准确率的故障识别性能. 随后,针对铁路道岔系统故障识别问题,文献[81]通过分析故障类型的结构和输出功率曲线,提出了基于DF的诊断模型,其充分考虑了铁路道岔系统的强时序性、有限故障数据量等数据特点,最终故障诊断准确率达到97%.
在面向医疗健康领域中,文献[82]提出基于无监督特征提取与DF结合的方法,首先采用无监督特征选择策略去除冗余特征,然后引入k-means算法获取退化过程的阶段知识以实现有监督学习,最后采用DF构建在线诊断监测模型,在美国航空航天局(National Aeronautics and Space Administration,NASA)数据集中的测试结果表明了该策略的有效性和可行性.
面向软件检测领域,文献[83]提出基于DF的恶意软件行为检测机制,其首先提取恶意及良性样本中的敏感权限、服务和应用程序接口(application programming interface,API)调用特征等数据,然后确定恶意软件行为,最后训练DF模型进行检测,通过与其他深度学习方法的对比证明DF方法具有明显的优越性.
其他相关领域的应用还包括慢性胃炎中医问诊证候诊断[84]、窃电行为检测[85]和卫星姿态控制系统的执行机构与传感器故障诊断[86]等.
3.3 DF在指标预测中的应用
针对电力系统短期负荷预测,文献[87]提出了基于DF的预测模型,其首先对缺失数据利用线性插值法进行填补,然后以连续N天的负荷数据、气象因素数据以及日期类型数据作为输入,以次日的实际负荷数据作为输出构建DF模型,结果表明其具有最低预测误差.
针对人脑注意力识别问题,文献[88]建立基于DF的脑电注意力识别模型,其利用小波分析法对原始脑电信号进行去噪处理,然后采用DF进行分类识别. 在注意和非注意2种状态下的测试结果表明识别准确率达到95%以上.
为预测糖尿病患者住院率,文献[89]提出了基于小波变换和DF的模型,其首先利用小波变换从10万例糖尿病患者中提取55个特征属性,再训练基于DF的分类模型,实验结果与RF相比在ROC指标上提高了5%.
综合上述研究可知,DF正以不可估量的速度在不同领域得到应用. 本文虽然仅对常用领域的DF典型应用进行了介绍,但这些结果在一定程度上表明DF具有独特的优势和适应不同数据集的良好性能.
4 DF的挑战及未来研究方向
作为深度学习领域中的新成员,近几年DF在众多分类识别领域取得了优异成绩. 本质上,DF灵感源于DNN,是由非微分基学习器深度集成的一种深度学习方法,开启了非神经网络结构的深度学习模式的先河. 笔者认为,DF在未来研究中存在如下4个挑战和潜在研究方向:
1) 面向小样本的高精度DF建模. 一般来说,大量标注样本仍然是DF实现高精度识别的有效手段. 然而,在实际问题中,尤其在工业应用中,时间、人力和经济成本等因素导致标记样本的获取难度大,这使得小样本数据成为主要建模对象. 若在现有DF级联结构中采用更好的算法进行特征表征,例如森林自编码器[90],则可以大大提高DF模型的预测精度,同时避免DF模型出现过拟合现象.
2) DF深度结构设计. 作为初步探索的非微分性质的深度学习结构,其框架具有良好的伸缩性. 现有研究中,级联层的宽度拉伸与层结构拆分等结构设计均能有效提高DF模型的性能. 与此同时,研究表明,利用剪枝策略进行结构设计也能显著提升集成模型的泛化性能. 笔者认为,基于非微分基学习器深度集成的结构设计,若要获得良好性能需要从集成泛化的角度出发设计更为紧凑且高效的DF结构.
3) 深度集成结构中的多样性. 集成多样性,即基学习器个体之间的差异性,是集成学习领域的基本问题. 一般而言,期望每个基学习器都是准确的且多样化的. 然而,仅集成强基学习器的模型性能往往不如既存在准确又存在较弱基学习器的集成模型,因此,集成模型中基学习器的互补性成为关键. 此外,单一领域的集成策略往往存在一定的局限性,如何融合其他领域方法提升DF模型多样性是深度集成学习未来的研究方向之一.
4) 缩减DF结构的时间成本. 在实际建模过程中,更深更宽的DF结构能够获得更好的泛化性能. 然而,训练更大的DF模型,则使得计算性能成为至关重要的因素. 实际上,DNN的成功很大程度上归功于图形处理器(graphics processing unit, GPU)的加速,但DF结构却并不适合当前主流的GPU加速. 因此,针对如何加速和减少DF结构的内存消耗是未来需要解决的重要问题和主要挑战. 目前,以分布式计算实现高性能DF加速运算[91]的研究已经实现,这为后续缩减DF结构的时间成本提供了很好的借鉴意义.
