基于注意力机制的轻量级RGB-D图像语义分割网络
2022-02-22孙刘杰张煜森王文举赵进
孙刘杰,张煜森,王文举,赵进
图文信息技术
基于注意力机制的轻量级RGB-D图像语义分割网络
孙刘杰,张煜森,王文举,赵进
(上海理工大学,上海 200093)
针对卷积神经网络在RGB-D(彩色-深度)图像中进行语义分割任务时模型参数量大且分割精度不高的问题,提出一种融合高效通道注意力机制的轻量级语义分割网络。文中网络基于RefineNet,利用深度可分离卷积(Depthwise separable convolution)来轻量化网络模型,并在编码网络和解码网络中分别融合高效的通道注意力机制。首先RGB-D图像通过带有通道注意力机制的编码器网络,分别对RGB图像和深度图像进行特征提取;然后经过融合模块将2种特征进行多维度融合;最后融合特征经过轻量化的解码器网络得到分割结果,并与RefineNet等6种网络的分割结果进行对比分析。对提出的算法在语义分割网络常用公开数据集上进行了实验,实验结果显示文中网络模型参数为90.41 MB,且平均交并比(mIoU)比RefineNet网络提高了1.7%,达到了45.3%。实验结果表明,文中网络在参数量大幅减少的情况下还能提高了语义分割精度。
RGB-D图像;语义分割;深度可分离卷积;通道注意力
图像语义分割是计算机视觉的一项基本任务,已经得到了广泛的研究,其目的是为图像中的每个像素都分配一个语义标签,使图像上的不同种类的物体被区分开来。如今语义分割网络有较多的应用场景,如自动驾驶、医学诊断和机器人等领域。由于RGB-D图像比二维图像多提供了深度信息,所以基于RGB-D图像的语义分割对复杂环境适应性较强。随着RGB-D传感器的价格下降,RGB-D图像获取方便,将深度图像和RGB图像结合进行语义分割成为当前计算机视觉领域的研究重点。
现有的语义分割算法分为2种,一种是传统的语义分割算法,另一种是基于深度学习的语义分割算法。传统的语义分割算法中,利用分类算法、图像特征和区间信息等方法对图像进行语义分割。Karsnas等[1]利用基于区域的分割方法,把整张图像分割成小的区域,这些区域是有着相同的性质。Zhang等[2]提出隐式马尔可夫随机场模型来分割图像。Felzenszwalb等[3]提出将HOG特征用于进行图像语义分割。Cohen等[4]通过利用不同的彩色模型例如Lab、YcBcr、RGB等来对图像进行分割任务。Yang等[5]利用SVM分类器,提出了一种分层模型的图像分割算法。Kumar等[6]提出了将条件随机场(CRF)模型用于图像的语义分割,通过将隐马尔可夫模型的特点和最大熵模型的特点融合,使语义分割网络的分割效果得到很大提升。以上传统的语义分割方法主要基于RGB图像。现实场景中物体都是三维的,从三维物体到二维的投影成像会丢失一部分信息,另一方面,在投影成像的过程中光照和噪声对其影响很大,这些因素都会导致图像分割结果的不准确。
随着深度学习时代的到来,基于深度学习的语义分割算法成为现在研究重点。全卷积神经网络FCN[7]的提出并在图像语义分割领域的成功运用,使利用CNN网络来完成语义分割任务成为发展趋势。FCN网络主要是使用卷积层替换VGG-16[8]网络中原有的全连接层,去掉最后的分类层,使网络能适应任意尺寸的输入。Ronneberger等[9]提出了U-Net网络,使用多次跳跃连接,增加低层特征,提高网络精度;Noh等[10]基于FCN网络提出了DeconvNet网络,其结构采用编码-解码。Badrinarayanan等[11]提出了SegNet网络,其结构类似于DeconvNet,并使解码网络的反池化操作更平滑。在RGB-D图像语义分割网络中,将物体深度信息引入语义分割任务,作为颜色信息的补充,有利于区分图像中容易混淆的区域,从而提高语义分割精度。McCormac等[12]将深度信息和RGB信息组合成4个通道信息,提高分割的精度,但没有对两者特征融合的方法进行深入探究,所以分割精度提升有限。RDFNet[13]将色彩信息以及深度信息分别输入2个编码网络中,通过特征融合模块,将2种特征有效融合,最终获得了较好的分割结果,但这样会增加网络的参数量和计算量,提高了使用者的计算机硬件门槛。过大的计算量降低了分割的实时性,限制了语义分割网络的应用,因此语义分割网络的轻量化设计尤为重要。
注意力机制[14](Attention Mechanism)近年来被广泛使用在图像识别、语义分割、自然语言处理等方面,旨在提高网络模型的性能。注意力有2种方法,一种是基于强化学习方法,通过收益函数来激励,让网络更加关注与任务相关度更高的信息上;另一种是基于梯度下降方法,通过目标函数和相应的优化函数来实现。在计算机视觉领域,2种方法都有使用,其核心思想就是基于输入的全部特征,找到特征间的关联性,增加与任务相关度高的特征权重。比如通道注意力,空间域注意力,像素注意力,多阶注意力等。文中使用的就是一种基于强化学习方法的通道注意力机制。
文中通过改进网络结构并进行轻量化设计,在分割精度损失较小或保证精度的同时,减少网络的参数量和计算量。同时提出一种特征融合模块,将RGB图像特征和深度特征融合,更有效地利用RGB-D图像进行语义分割,并且文中引入ECA-Net(Efficient Channel Attention)[15]高效的通道注意力机制,使用局部跨通道交互信息的策略,重新调整特征通道的权重,赋予特征通道不同的权值,有效地利用高层特征来指导低层特征的学习,使网络聚焦于对该任务更重要的特征,从而提高语义分割网络的性能。
1 语义分割网络模型
文中以RefineNet[16]网络模型为基础,构建一种轻量级网络结构,通过使用深度可分离卷积对原始网络进行轻量化设计,旨在减少网络的参数量,使得网络所需的训练时间变少;通过在网络中融合高效的通道注意力机制,旨在提高语义分割网络的分割性能,从而弥补在轻量化设计时网络分割性能的损失。该网络分为编码器网络和解码器网络,编码器使用融合了高效通道注意力模块的ECA-MobileNet-V2网络,用来进行深度图像和RGB图像的特征提取,然后通过特征融合模块将2种特征进行融合,得到2种特征的最优融合特征;解码器是经过轻量化设计的RefineNet*模块,同时在解码网络中也加入高效的通道注意力模块,对编码器提取的特征进行卷积、融合、池化,使得多尺度特征的融合更加深入,得到更好的分割效果。网络总体结构见图1。
该网络数据源为色彩信息和深度信息。输入的深度信息是HHA图像,将深度图编码成HHA[17],即水平差异、离地高度、像素局部表面法向量与中立方向的夹角3个通道,这种预处理方式会从RGB-D图像的深度数据提取更丰富的空间信息,更有利于图像的语义分割任务,能提高网络的分割性能。

图1 网络总体结构
1.1 特征融合模块
基于RGB-D的语义分割的关键在于有效地提取RGB图像特征和深度特征,并且2种特征的融合方式对网络后续进行的语义分割尤为重要。文中提出了一种特征融合模块,用来融合不同层次的特征,文中网络的特征融合模块见图2。
文中的特征融合模块是由2个分支组成,分别对RGB特征和深度特征进行处理。每个分支都是先通过一次1×1卷积进行降维,用来减少参数量,然后接着2个残差块来为2种特征进行非线性转换,方便后续进行特征融合。紧接着一个3×3卷积用来训练学习控制各模态特征重要性的参数,最后通过一个残差池化给融合后的特征加入上下文信息。除残差块外的1×1卷积和3×3卷积的其他卷积对控制特征维度进行求和,以及自适应地融合2种特征都起到了重要作用。因为深度特征对语义分割主要起辅助作用,并且语义分割网络对RGB特征的识别能力更强,所以主要通过融合模块利用深度特征对RGB特征进行补充,来减少颜色模糊、光照等的影响。
1.2 轻量化设计
RefineNet网络架构的参数数量和浮点运算数量主要来自RCU模块(Residual Convolution Unit)、MRF模块(Multi-resolution Fusion)、CRP模块(Chained Residual Pooling)中的3×3卷积。文中将RefineNet与Inverted residuals block结构[18]融合,替代原有的标准3×3卷积操作,利用深度可分离卷积(Depthwise separable convolution)来减少原始网络的参数量和计算量。深度可分离卷积与标准卷积有所不同,标准卷积的每次卷积操作,包含了特征映射的空间信息和通道信息。深度可分离卷积把标准卷积分为2步,分别为深度卷积(Depthwise)和逐点卷积(Pointwise),从而分2步提取特征映射信息。如图3所示,在Depthwise卷积中,对输入个通道特征图单独做卷积,输出个特征图。Depthwise卷积主要是对空间平面特征的提取,通道之间的信息不发生融合。在Pointwise卷积中,Depthwise卷积输出的个特征图被看作一个整体,通过一个标准1×1×卷积操作输出一个特征图,因为在Pointwise卷积中有个1×1×卷积核,所以最终输出个通道特征图。
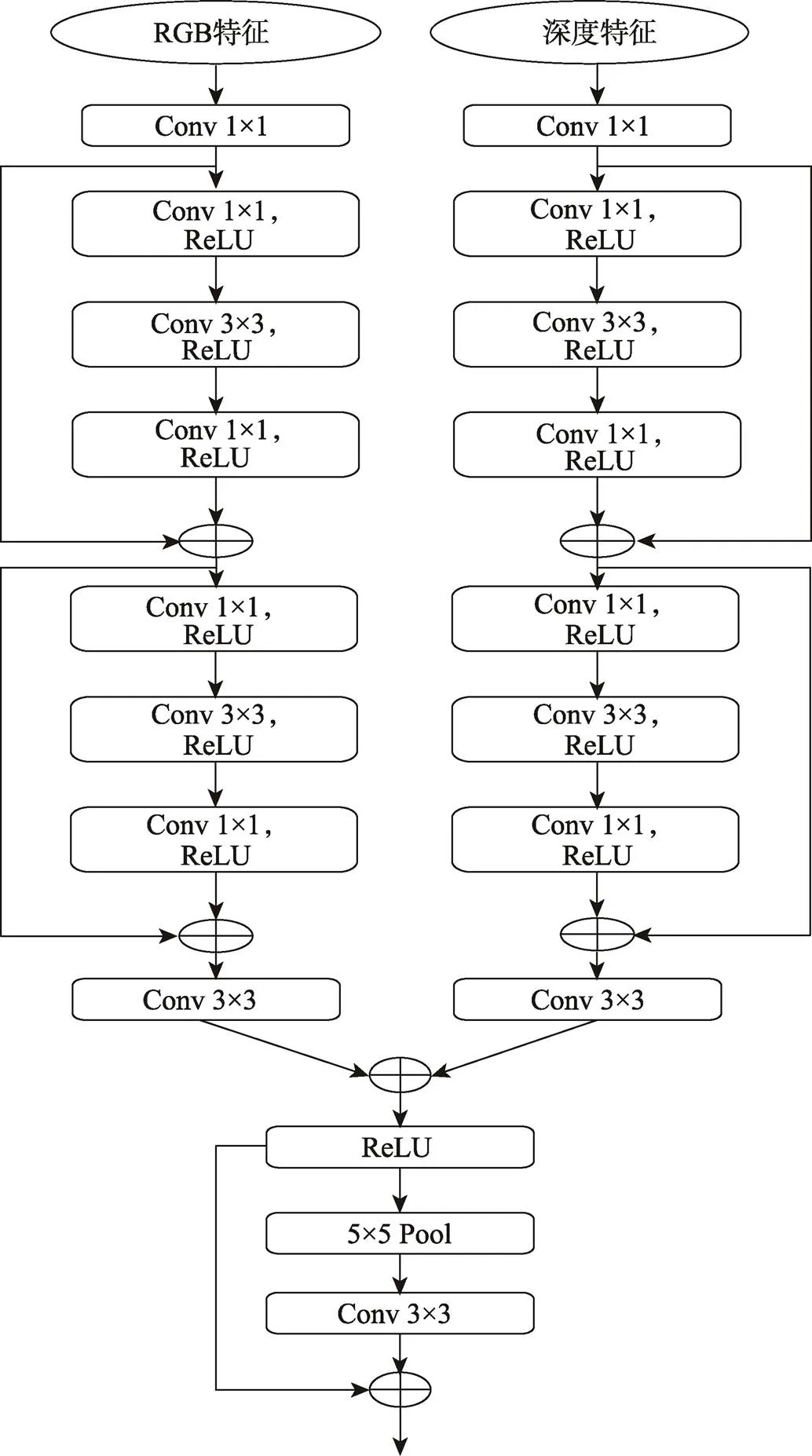
图2 特征融合模块

图3 深度可分离卷积

图4 卷积对比
标准卷积与深度可分离卷积对比见图4。假设标准卷积输入的特征张量为××1,其中,、、1分别为特征张量高度、特征张量宽度、通道数,输出特征张量为××2,卷积核的大小为×,则标准卷积的参数量为212,计算量为212。当此特征张量输入深度可分离卷积时,则其参数量 为21+12,其中Depthwise卷积的参数量为21,Pointwise卷积的参数量为12。其计算量为21+12。深度可分离卷积与标准卷积的计算量之比为:
(1)
参数量之比为:
(2)
当卷积核的大小>1时,深度可分离卷积的计算量和参数量都小于标准卷积,并且深度可分离卷积可以达到与标准卷积对图片处理相近的效果,因此文中参考MobileNet-V2对深度可分离卷积的应用,用深度可分离卷积替代RefineNet网络中标准的3×3卷积,以达到网络轻量化目的。
RefineNet中RCU模块为原始ResNet中的卷积单元,为2个3×3标准卷积,主要任务是将预训练后编码器网络的权重进行微调。为了减少参数量和计算量,将RCU模块改进为倒残差结构[18]:首先使用一个1×1卷积扩张特征维度,紧接着使用一个3×3的深度卷积,最后使用一个1×1逐点卷积进行压缩,并且最后一个激活层函数为线性激活函数,前面2个激活层函数为ReLU。将RCU-LW模块设计为此结构是为了避免深度卷积只在低维特征上进行卷积操作导致效果不好,这样就可以得到更高维度的特征,使网络有更丰富的特征来满足预测。
MRF-LW模块中为2组3×3的深度卷积和1×1逐点卷积。此模块主要先进行输入自适应,生成相同特征维数的特征映射,然后将所有特征映射上采样到输入的最大分辨率,最后通过求和融合所有特征图。CRP-LW模块主要为从大的图像区域捕获其上下文背景信息,能够有效地将具有多种尺度特征集合起来,并将可学习的权重与它们融合在一起。RCU-LW模块、MRF-LW模块、CRP-LW模块见图5。
RefineNet网络的编码器是ResNet-101。由于ResNet-101网络深度达到101层,参数量和计算量较大,为了减小语义分割网络的参数量和降低对计算机性能要求,文中使用了轻量级网络MobileNet-V2作为编码器网络,提高了特征提取的速度。MobileNet-V2与ResNet-101模型大小对比见表1。
1.3 通道注意力机制
通道注意力机制在改善深度卷积神经网络性能方面体现了很大的优势,广泛应用于图像分类、语义分割、目标检测等多个方面,能够使网络在训练中学习到对特征通道和背景等信息的建模能力,有效地提升了网络模型的性能。因为不同的通道是从不同的角度对目标深度信息进行建模,所以对于不同的目标任务各个通道的重要性不同,而通道间也存在联系。大多现有的方法在提高的网络性能的同时,也相应地增加了网络模型的复杂程度。
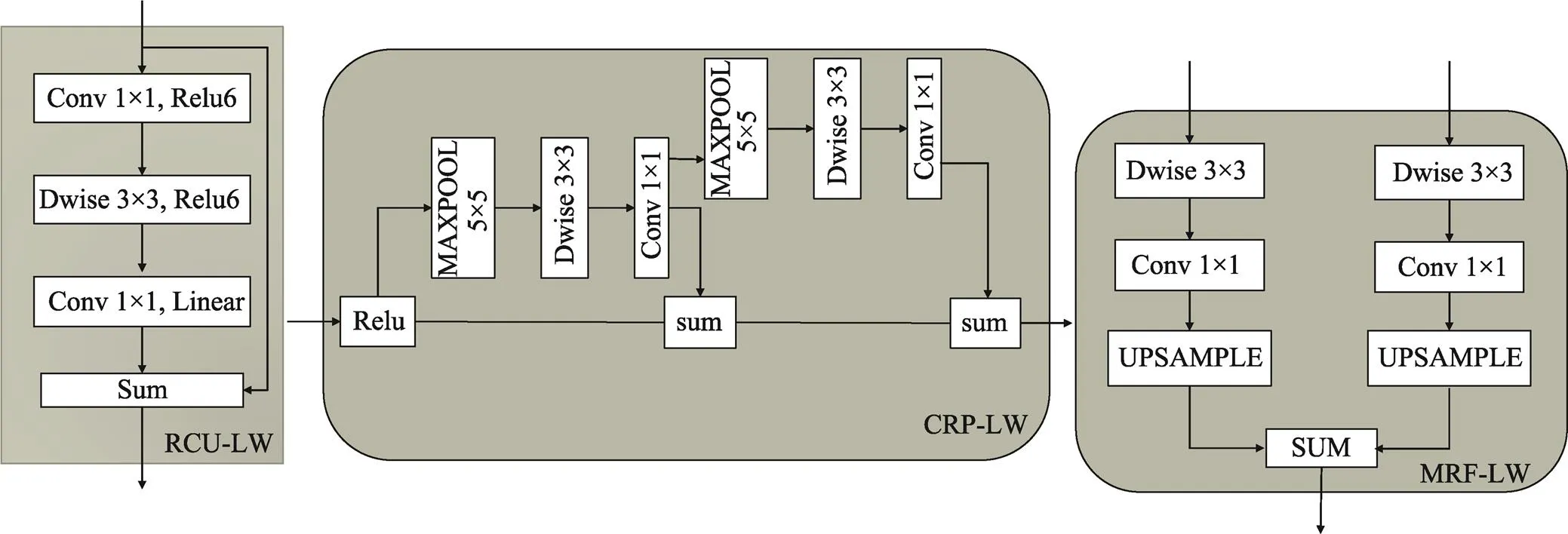
图5 LW-RefineNet中各个模块
表1 特征提取网络在网络参数量(Params)、浮点运算次数(FLOPs)比较

Tab.1 Comparison of feature extraction network in network parameters (Param) and floating-point operation times (FLOPS)
文中使用的ECA-Net高效通道注意力模块只涉及少量参数,同时对网络性能的增益明显。ECA-Net注意力模块是由经典的SENet[19]改进而来。当特征信息输入时,SENet中的通道注意力模块首先独立地对每个通道采用全局平均池化操作,然后使用2个非线性全连接(FC)层和1个Sigmoid函数来生成通道权重,其中2个全连接层用于捕捉跨通道交互信息,并且SENet还通过降低维度的方式来降低模型复杂性,但是此方式会使通道特征首先投影到低维空间,然后再映射回来,使通道与其权重之间成为间接的对应关系。另外所有通道的相关性对通道注意力预测不是必要的。ECA-Net注意力模块使用卷积核大小为的1×1卷积来替代通道注意力模块的全连接层,以实现本地跨通道交互信息。其中表示把每个通道的依赖关系提取依据特征维度限定在个通道以内。该注意力模块不需要使通道维度降低,并在进行跨通道交互信息时考虑每个通道的相邻通道,这样可以降低注意力模块的计算量,提高网络整体运行速度并且保证了网络效果。
跨通道交互信息的覆盖范围值自适应地确定原理为:根据群卷积在卷积神经网络中的成功应用,提升了卷积神经网络的结构[20],其中高维通道涉及长范围的卷积,低维通道涉及短范围的卷积,给定了固定数量的分组。同理,交互作用的覆盖范围(即一维卷积的核尺寸)与通道维数成正比,也就是说,在与之间可能存在一个映射:
(3)
最简单的映射是为线性函数关系,即()=∗–,但是用线性函数表示的关系存在局限性。通常将通道维数也就是滤波器的数量设置为2的幂,因此,将线性函数()=∗–扩展为非线性函数,即:
(4)
在给定信道维数的条件下,可以通过式(5)自适应地确定卷积核值的大小,即:
(5)
式中:||odd为最接近的奇数。在实验中分别将和设为2和1,最终值取3,即文中加入ECA-Net利用的1×1卷积的核为3,因此通过映射,高维通道的相互作用距离较长,而低维通道的相互作用距离较短。
将高效的通道注意力机制加入到编码器网络和解码器网络中。编码器网络为融入了高效通道注意力的MobileNet-V2,在MobileNet-V2的倒残差结构中的残余层融合了通道注意力机制ECA-Net。这样使网络提取的特征通过GAP和自适应1×1卷积确定相应的特征通道的权重,并根据上述跨通道交互信息的覆盖范围值自适应地确定原理,捕捉了特征通道和其相邻3个通道的相互依赖关系,从而使整个网络在端到端的训练中学习到对不同特征通道的权重,提高编码网络的特征提取能力。ECA-MobileNet-V2 block见图6。
为了更好地比较各编码网络的复杂性,将各个网络模型体积对比见表2。根据表2所示的数据可知,ECA-MobileNet-V2的模型体积和计算量都远小于SE-ResNet-101网络,ECA-NET作为一种高效通道注意力机制融合到网络后,该网络的模型大小不变,并且增加的计算量很少。

图6 ECA-MobileNet-V2 block结构
表2 融合不同通道注意力机制网络在网络参数(Params)、浮点运算次数(FLOPs)比较
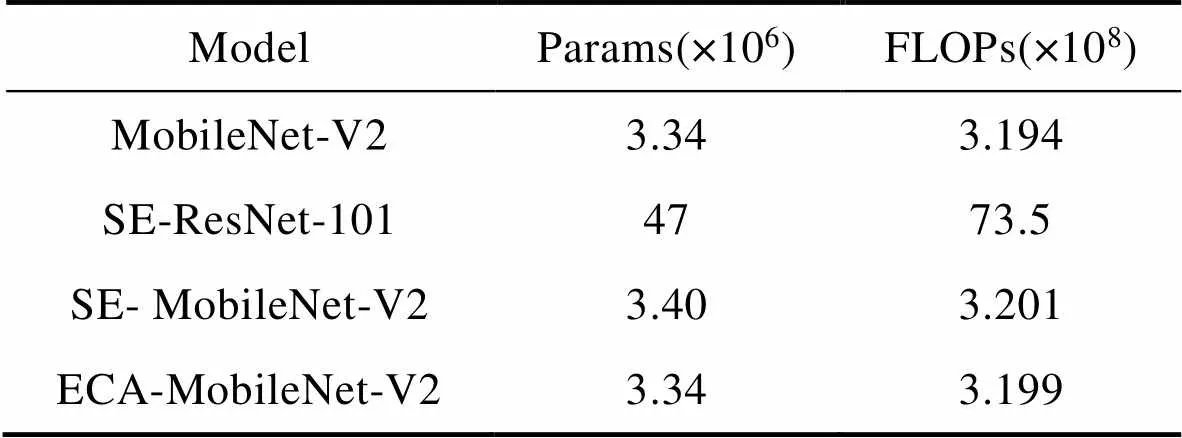
Tab.2 Comparison of network with different channels attention mechanism networks in parameters (Params) and floating-point operation times (Flops)
文中解码器网络是在基于RefineNet上进行轻量化设计,并加入高效的通道注意力机制。对于图像的语义分割,图像的低层特征有助于分割出轮廓清晰的目标,但缺乏具有丰富语义信息的高层特征容易产生错误分割。语义分割的重点在于利用好低层的外观信息和深层的语义信息,RefineNet将不同深度的特征图融合起来,使语义分割网络的性能提升。这样直接融合的操作,忽略了2种层次特征的权重对语义分割的影响,并不能充分利用好低层特征信息和高层特征信息。为了解决此问题,文中在网络中融合了高效的通道注意力模块,在2种特征融合前先经过注意力模块,用具有丰富语义信息的高层特征指导低层特征,以达到更好分割效果。融合了高效通道注意力模块的RefineNet*网络结构见图7。
2 实验结果与分析
实验平台硬件配置为:Inter(R) core(TM)i9- 10920X CPU 3.50 GHz,内存64 G、NVIDIA GeForce RTX 3070显卡,软件配置为Ubuntu 18.04系统,PyTorch深度学习框架。
2.1 实验数据集
基于RGB-D图像的语义分割常用的数据集为NYU Depth v2[21]和SUN-RGBD[22]数据集,这2个是经典的RGB-D数据集,绝大多数RGB-D语义分割网络都会在这2个数据集上训练和评估,并进行性能对比。NYU Depth v2数据集一共包含1449张室内场景的RGB-D图像,语义标签一共分为了40类。所有数据是由Microsoft Kinect采集。在该实验中,使用了795个实例用于网络训练,654个实例用与网络测试。SUN-RGBD数据集一共10 335张RGB-D图像和语义标签,每个像素被分配一个语义标签。所有图像一共被划分为37个语义类别。在该实验中使用了5285个图像进行训练,5050个图像进行测试。
2.2 评价指标
实验采用了图像语义分割常用的3个性能评价指标:平均交并比(mIoU)、像素精度(pixel accuracy)、平均精度(mean accuracy)。上述评价指标定义如下所述。
1)平均交并比(mIoU)。在图像的语义分割中物体经过分割区域与物体本身正确的区域的交集占两者并集的百分比称为交并比(IoU),则平均交并比即是(mIoU)对每类物体的交并求均值,计算式为:
(6)
式中:Pii为属于物体i类被分类为i类的像素数量,称为真正;Pij为属于i类物体却被划分为j类物体的像素数量,称为假负;Pji为属于j物体被分类为i类的像素数量,称为假正;Pjj 为属于j类物体被分类为j类物体的像素数量,称为真负;i类为正类,非i类为负类,K+1为分割类别的总数量,1为1个背景类。图像语义分割性能指标具体见图8。
图7 LW-RefineNet*模块结构
Fig.7 LW-RefineNet* module structure
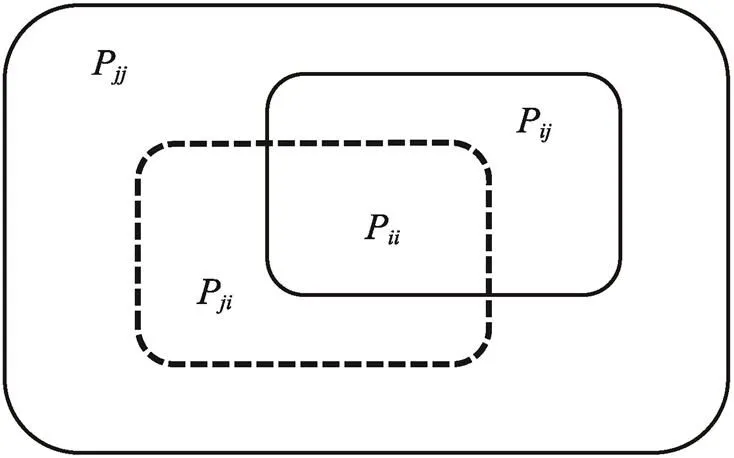
图8 语义分割性能指标
2)像素精度(Pixel Accuracy)、平均像素精度(Mean Pixel Accuracy)。像素精度为所有像素中分类正确的精度百分比,平均精度为各类物体像素精度的平均值,计算式分别为:
(7)
(8)
式中:P为属于物体类也被分类为类的像素数量;P为原本属于类物体的像素却被划分为类物体的像素数量;+1为分割类别的总数量,1为1个背景类。
2.3 实验结果分析
为验证文中网络模型轻量化设计的效果以及融合通道注意力机制对语义分割性能的提升作用,实验将文中网络与原始网络的模型参数量进行对比,并在NYU Depth v2数据集上进行多组对照实验,实验结果见表3。其中原始网络的编码网络采用ResNet-101,文中网络的编码网络采用ECA-MobileNet-V2即ECA-V2。
实验结果表明,文中网络模型仅为90.41 MB,并且文中网络的平均交并比(mIoU)比原始网络提高了1.7%。在对解码网络RefineNet进行轻量化设计时,整个网络模型大小减少了253.30 MB,计算量减少了1.783×1011,但同时网络的平均交并比(mIoU)降低了0.9%。在LW-RefineNet-101中融合通道注意力机制后,该网络的模型大小基本不变,平均交并比(mIoU)提高了2.8%。说明融合通道注意力机制对整个语义分割网络起到了提高分割性能的作用,另一方面说明ECA作为一种高效的通道注意力机制融合到网络不会影响网络模型的大小,且增加的计算量只有1.1×108。由于ResNet-101网络结构深等特点,所以其特征信息提取的能力高于MobileNet-V2,从而导致文中网络的平均交并比低于LW-RefineNet*-101,但是ResNet-101的模型也比MobileNet-V2大149.38 MB,达不到网络轻量化设计的目的,因此文中采用的编码网络是ECA-MobileNet-V2。在编码网络中融合通道注意力机制是为了减小将ResNet-101更换为MobileNet-V2对网络分割性能产生的影响。
为了更详细地分析文中网络在各个语义类别上的分割情况,将文中网络和原始RefineNet-101网络在SUN-RGBD数据集进行实验。实验结果见表4。
如实验结果表4所示,文中网络在32个类别的交并比上明显超过RefineNet-101网络,在“照片”、“窗帘”、“地毯”、“电冰箱”、“纸张”5个类别上语义分割精度与原网络近似。具体来说,文中网络因为利用了物体的深度信息,辅助RGB信息进行语义分割,提高了几何特征明显以及一些轮廓复杂、重叠的物体的分割准确率。因为“纸张”类别的厚度很小,轮廓简单,其在基于RGB图片分割时交并比(IoU)就低,所以文中网络“纸张”类别的交并比(IoU)会低于RefineNet-101;同时网络中高效的通道注意力机制有效的利用了空间信息和语义信息,通过加强对有效特征的学习,提高对物体分割的准确率,例如对“橱柜”、“柜台”、“沐浴器”、“浴缸”等类别物体的分割交并比提高了约6%。
文中网络与其他语义分割算法在NYU Depth V2数据集上的对比实验结果见表5,语义分割结果可视图见图9。
表3 网络模型参数量和性能对比
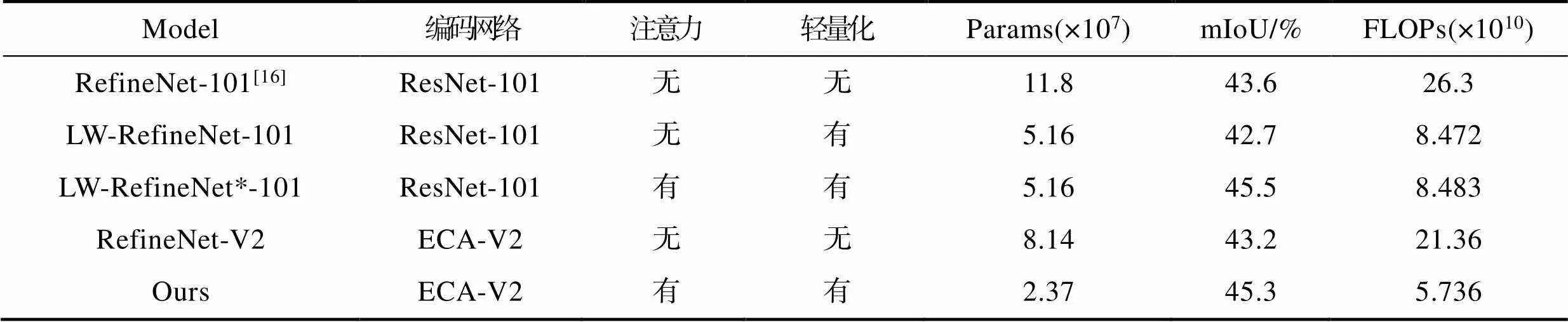
Tab.3 Comparison of number of network model parameters and performance
表4 在SUN-RGBD数据集37个类别的交并比(IoU)的比较

Tab.4 Comparison results of IoU of 37 categories in SUN-RGBD dataset %
表5 不同网络算法在NYU Depth V2上性能对比

Tab.5 Comparison of performance of different network algorithms on NYU Depth V2 %
由实验结果可知,文中网络比FuseNet网络像素精度(Pixel Acc)提高了4.5%,平均精度(Mean Acc)提高了5.8%,平均交并比(mIoU)提高了7%,比同样使用了通道注意力机制的MMAF-Net- 152[25]的平均交并比(mIoU)高了0.7%,平均精 度(Mean Acc)提高了5.8%。文中网络与主流 语义分割网络RefineNet-101相比不仅在模型参 数量减少了,而且比原始网络RefineNet-101的 像素精度(Pixel acc)提高了1.4%,平均精度 (Mean acc)提高了1.8%,平均交并比(mIoU)提高了1.7%。
从语义分割可视化结果来看,文中网络将物体的边界分割得更为清晰,轮廓分割得更为明显,特别是当分割一些体积较小的物体时,文中网络分割的准确率更高。这说明在网络中融合通道注意力机制后,网络把对语义分割重要的特征通道的权重增大,这样使网络聚集于对该分割任务更重要的特征,达到了更好的语义分割效果。

图9 语义分割结果
3 结语
文中提出了一种基于RGB-D图像的语义分割网络,其通过深度可分离卷积对RefineNet网络进行轻量化设计,在保证分割性能的前提下,使模型参数量降低为90.41 MB;通过使用特征融合模块将RGB特征和深度特征进行多层次融合,更有效地利用了RGB-D信息,提升了语义分割网络的性能;在网络中融合高效的通道注意力机制,在低层特征和高层特征融合前先经过注意力模块,用具有丰富语义信息的高层特征指导低层特征,有效地利用低层特征,提升了网络的边缘分割效果,同时有效利用高层特征增加分割准确率,使文中网络比RefineNet-101网络平均交并比(mIoU)提高了1.7%。基于RGB-D图像的语义分割网络的性能还有提升空间,特别是在深度信息与RGB信息融合方法还需进一步探究,更好地利用深度信息提升语义分割精度,以及提高语义分割网络的实时性,都是未来研究的方向。
[1] KÅRSNÄS A, DAHL A L, LARSEN R. Learning Histopathological Patterns[J]. Journal of Pathology Informatics, 2011, 2: 12.
[2] ZHANG Y, BRADY M, SMITH S. Segmentation of Brain MR Images through a Hidden Markov Random Field Model and the Expectation-Maximization Algorithm[J]. IEEE Transactions on Medical Imaging, 2001, 20(1): 45-57.
[3] FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D, et al. Object Detection with Discriminatively Trained Part-Based Models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
[4] COHEN A, RIVLIN E, SHIMSHONI I, et al. Memory Based Active Contour Algorithm Using Pixel-Level Classified Images for Colon Crypt Segmentation[J]. Computerized Medical Imaging and Graphics, 2015, 43: 150-164.
[5] YANG Yi, HALLMAN S, RAMANAN D, et al. Layered Object Models for Image Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(9): 1731-1743.
[6] KUMAR S, HEBERT M. Discriminative Random Fields: A Discriminative Framework for Contextual Interaction in Classification[C]// IEEE International Conference on Computer Vision, Nice, 2003: 1150- 1157.
[7] SHELHAMER E, LONG J, DARRELL T. Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651.
[8] SIMONYAN K, ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition[EB/OL]. 2014: arXiv: 1409.1556[cs.CV]. https:// arxiv.org/abs/1409.1556.
[9] RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional Networks for Biomedical Image Segmentation[C]//Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015, 2015: 1520-1528.
[10] NOH H, HONG S, HAN B. Learning Deconvolution Network for Semantic Segmentation[C]// IEEE International Conference on Computer Vision, Santiago, 2016: 1520-1528.
[11] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
[12] MCCORMAC J, HANDA A, DAVISON A, et al. SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks[C]// IEEE International Conference on Robotics & Automation, Singapore, 2017: 4628-4635.
[13] PARK S J, HONG K S, LEE S. Rdfnet: Rgb-d Multi-Level Residual Feature Fusion for Indoor Semantic Segmentation[C]// International Conference on Computer Vision, Venice, Italy, IEEE, 2017: 4980-4989.
[14] CHAUDHARI S, MITHAL V, POLATKAN G, et al. An Attentive Survey of Attention Models[J]. ACM 37, 2020, 4: 20.
[15] WANG Qi-long, WU Bang-gu, ZHU Peng-fei, et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks[C]// Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2020: 11531-11539.
[16] LIN Guo-sheng, MILAN A, SHEN Chun-hua, et al. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation[C]// Computer Vision and Pattern Recognition, IEEE, Honolulu, Hawaii, 2017: 1925-1934.
[17] GUPTA S, ARBELAEZ P, MALIK J. Perceptual Organization and Recognition of Indoor Scenes from RGB-D Images[C]// Computer Vision and Pattern Recognition, IEEE, Portland, Oregon, 2013: 564-571.
[18] SANDLER M, HOWARD A, ZHU Meng-long, et al. Mobilenetv2: Inverted Residuals and Linear Bottlenecks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt lake, Utah, 2018: 4510-4520.
[19] HU Jie, SHEN Li, SUN Gang. Squeeze-and-excitation Networks[C]// Computer Vision and Pattern Recognition, IEEE, Salt Lake City, Utah, 2018: 7132-7141.
[20] IOANNOU Y, ROBERTSON D, CIPOLLA R, et al. Deep Roots: Improving CNN Efficiency with Hierarchical Filter Groups[C]// EEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 2017: 5977-5986.
[21] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor Segmentation and Support Inference from RGB-D Images[C]// Proceedings of the IEEE Conference on Computer Vision, Florence, 2012: 746-760.
[22] SONG S, LICHTENBERG S P, XIAO Jian-xiao. SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, 2015: 567-576.
[23] LIN G, SHEN C, VAN DEN HENGEL A, et al. Exploring Context with Deep Structured Models for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1352-1366.
[24] HAZIRBAS C, MA Ling-ni, DOMOKOS C, et al. FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-Based CNN Architecture[C]// Computer Vision-ACCV 2016, 2017: 213-228.
[25] FOOLADGAR F, KASAEI S. Multi-Modal Attention-Based Fusion Model for Semantic Segmentation of RGB-Depth Images[EB/OL]. arXiv: 1912.11691, 2019. https://arxiv.org/abs/1912.11691.
Lightweight Semantic Segmentation Network for RGB-D Image Based on Attention Mechanism
SUN Liu-jie, ZHANG Yu-sen, WANG Wen-ju, ZHAO Jin
(University of Shanghai for Science and Technology, Shanghai 200093, China)
The work aims to propose a lightweight semantic segmentation network incorporating efficient channel attention mechanism to solve the problem of large number of model parameters and low segmentation accuracy when Convolutional Neural Network performs semantic segmentation in RGB-D images. Based on RefineNet, the network model was lightened by Depthwise Separable Convolution. In addition, an efficient channel attention mechanism was applied to the encoding network and the decoding network.Firstly, the features of RGB image and depth image were extracted by the encoder network with channel attention mechanism. Secondly, the two features were fused in multiple dimensions by the fusion module. Finally, the segmentation results were obtained by the lightweight decoder network and compared with the segmentation results of 6 networks such as RefineNet. The proposed algorithm was tested on public datasets commonly used in semantic segmentation networks. The experimental results showed that the parameters of the proposed network model were only 90.41 MB, and the mIoU was 1.7% higher than that of RefineNet network, reaching 45.3%. The experimental results show that the proposed network can improve the precision of semantic segmentation even when the number of parameters is greatly reduced.
RGB-D images; semantic segmentation; depthwise separable convolution; channel attention mechanism
TP391
A
1001-3563(2022)03-0264-10
10.19554/j.cnki.1001-3563.2022.03.033
2021-06-11
上海市科学技术委员会科研计划(18060502500)
孙刘杰(1965—),男,博士,上海理工大学教授,主要研究方向为光信息处理技术、印刷机测量与控制技术、数字印刷防伪技术、图文信息处理技术。
