基于YOLOv4的车辆检测与识别研究
2022-02-22王嘉璐钱立峰施恺杰谢剑锋杨昊天
王嘉璐,王 颖,钱立峰,施恺杰,谢剑锋,杨昊天
(南昌工程学院 信息工程学院,江西 南昌 330022)
0 引 言
随着经济的发展,交通拥堵问题凸显,严重影响人民生活水平的提高,构建智能化的交通监测系统对减少交通拥堵、提高交通运输效率具有重要意义。对车辆目标进行准确、实时的检测是智能交通系统的核心,在现有车辆检测算法研究中,基于深度学习的检测算法成功引起了学者们的关注,特别是针对复杂场景中多个车辆的检测更具挑战性。
目前基于视频图像的车辆检测研究领域算法众多,大致可以分为2类,分别为目标检测算法和深度学习算法。传统目标检测算法通过阈值处理、形态学处理等方法提取车辆信息,然后拟定阈值通过滑动窗口对车辆进行检测。2001年,ViolaP和Jones M.Rapid通过对目标特征增强级联实现目标检测;2002年,Lienhart R和 Maydt J.An对haar类特征扩充实现快速目标检测。上述传统目标检测算法存在特征泛化能力低以及运算过于复杂等问题。随着深度学习等人工智能技术的飞速发展,YOLO系列、SSD、Faster R-CNN以及Fast R-CNN等基于深度学习的目标检测算法出现。Lipikorn等提出了一种基于SIFT描述子和神经网络的车辆标志识别方法。尽管该方法成功消除了照明强度和角度变化的影响,但该方法的准确性较低且计算复杂,导致实时性较差;Xia等提出一种将CNN和多任务学习结合从而识别车辆的方法,该方法采用自适应权重训练,提升了多任务模型的收敛。上文提到的深度学习方法能较好地提取车辆的相关特征,但对于目标检测的精度较低,速度较慢,不能满足实际中实时检测的需求。
针对上述现有的目标检测问题,本文采用基于YOLOv4的车辆检测与识别算法,收集了来自2005 PASCAL视觉类挑战赛(VOC2005)中相关的车辆数据集,通过Mosaic数据增强算法扩充数据集,采用K-means++聚类算法得到适应本数据集的锚框坐标,采用CIOU损失函数进一步提升模型的识别精度,提升算法的鲁棒性,提高车辆检测识别精度。
1 YOLOv4算法
YOLO模型的多尺度检测算法相比其他算法能够更加有效地检测目标,其在许多目标检测任务中表现良好。通常将输入网络分为S×S网格,如果目标的中心在网格上,则该网格负责目标的检测。
YOLOv4模型相比YOLOv3更加复杂,其在精度与速度方面均有极大提升。该模型采用Label Smoothing平滑和学习率余弦退火衰减等技巧提升训练精度。Mosaic数据增强算法每次随机从数据集中抽取4张图片,分别对图片进行旋转与缩放等操作,将4张图片组合在一张图片上,以扩充目标检测的背景。YOLOv4模型在YOLOv3的DarkNet53框架上进行了改进,实现了以CSPDarkNet53为主干的特征提取网络,SPP与PAN为特征金字塔的模型框架,其网络结构如图1所示。
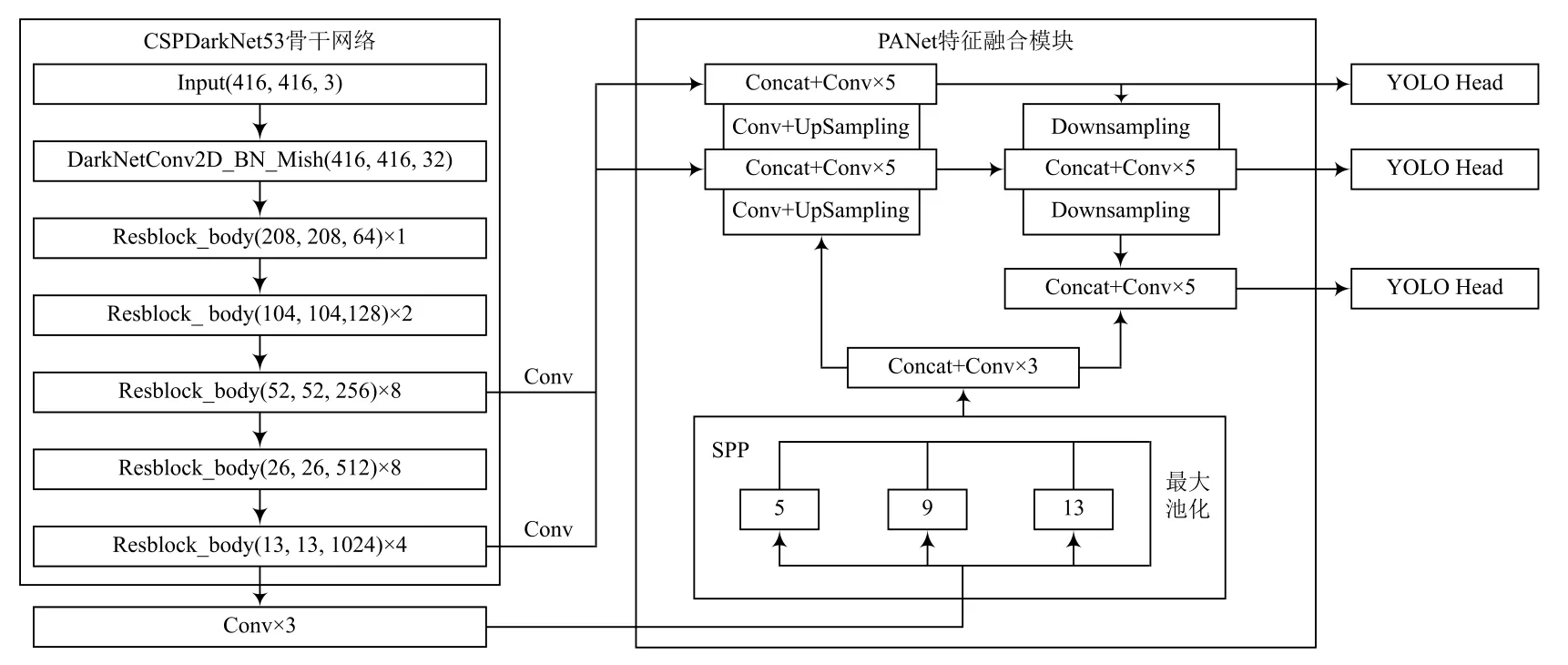
图1 YOLOv4特征结构
YOLOv4模型图片输入为416×416 px和608×608 px,本文采用416×416 px的输入特征结构图。首先对输入图片进行1次卷积操作,然后通过5次残差网络对其下采样以获取更高语义的特征信息。由于最后3种shape特征层具有更高的语义信息,故后续对这3种特征层进行操作。选取13×13的特征层进行3次卷积操作,分别使用4种不同尺度的最大池化进行处理,其池化核为5×5、9×9、13×13以及1×1(即无处理)。SPP模块可以通过增加感受野分离出图片中较为显著的特征信息。将池化后的图片与池化前的图片进行融合,对融合后的特征层进行2次上采样,分别与主干特征提取网络中26×26,52×52的特征层融合并进行5次卷积,将处理后的52×52特征层进行2次下采样,分别融合对应大小的特征层。通过YOLO Head对处理后的13×13、26×26、52×52结果特征进行类别预测。
2 YOLOv4网络模型改进
2.1 锚框(Anchor Box)聚类算法
本文主要研究提升算法的精度问题,通过聚类算法找到适合该数据集Anchor Box(锚框)的坐标,可以较快定位目标的位置,从而提升车辆检测的精度与速度。采用K-means算法获得Anchor Box存在2个问题:
(1)采用K-means聚类算法对本文车辆数据集进行分类时,从其中随机选取K个数据点作为样本。如果有2个点在1个簇当中,这使得聚类后的结果不具有鲁棒性。
(2)K-means聚类算法以样本数据间的距离为指标,对车辆数据集中的K个簇进行划分,每个簇的质心点根据所有数据点的均值得到。该聚类算法将距离公式中不同属性的权重视为相同,并不考虑在不同属性下会对聚类效果造成的影响。当簇中存在噪声点或者孤立点时,它们会远离数据的质心,从而使计算簇质心时产生较大的误差,对均值计算产生较大影响,甚至导致聚类质心严重偏离数据集的密集区域,使聚类结果出现偏差。
对K-means算法中存在的2个问题进行分析。本文采用K-means++算法对数据集的Anchor框进行聚类分析,选取适合该数据集目标检测的Anchor框。K-means++算法会从车辆数据集中确定K个数据样本,选取的聚类质心间离得越远越好,互不干扰。
2.2 损失函数
损失函数通常用来对训练模型的真实值与预测值间的差异程度进行分析与评价,损失函数与训练模型的性能呈正相关。由于目标检测过程中Anchor的回归损失优化与IOU(Intersection over Union,IOU)优化并不等价,并且对物体的比例较敏感,因此IOU无法优化未重叠部分,故本文引入损失函数CIOU(Complete Intersection over Union,CIOU)。IOU以比值的形式存在,对检测目标的scale不敏感,相比IOU,CIOU更加符合Anchor Box回归机制。由于考虑了检测目标与Anchor Box之间的距离、重叠率以及尺度等因素,使得目标框的回归更加稳定,因此不会像IOU与GIOU(Generalized Intersection over Union,GIOU)等损失函数那样在训练过程中出现发散的问题。相关公式如下所示:

式中:α表示权重函数;v表示度量长宽比的相似性;ρ(b,b)表示预测框与真实框中心点的欧式距离;C表示能同时包括预测框与真实框最小闭包区间对角线的距离;IOU为真实框与预测框的交并比,是目标检测中最常用的指标;CIOU损失函数在梯度方面类似于DIOU,在其基础上还需考虑v的梯度。长宽通过归一化处理后处于区间[0,1]时,w+h常常很小,导致梯度爆炸现象出现,因此需将其替换为1。相比之下,CIOU作为度量时具有以下优点:
(1)CIOU具有对称性、随机性、尺度不变性;
(2)CIOU考虑了非重叠区域,能够更好地反映出2个Anchor框重叠的方式;
(3)IOU的取值范围为[0,1],而CIOU的范围为[-1,1],具有对称性。在得到的各Anchor框互相重合时,取最大值1,而在Anchor框无交集且互相无限远离的情况下取值-1。因此相对于其他损失函数而言,CIOU又是一个非常好的距离度量指标。
3 实验结果与分析
3.1 数据集创建
本实验在网上收集来自2005 PASCAL视觉类挑战赛(VOC2005)中的车辆数据集,并通过旋转、缩放及加入噪声等数据增强算法,将样本数据集扩充至1 310张,本次实验测试集所占比重为0.3。图2所示为部分数据增强后的数据集。

图2 部分数据集
通过labelimg软件在收集的图片上标注出机动车的位置(如图3所示),类别有出租车、面包车、吉普、SUV等,并将标注好的结果以.txt文件保存。

图3 标注位置
3.2 实验环境
本实验基于Windows环境,通过Python语言编写实现,利用深度学习框架Pytorch 1.6.0和OpenCV-Python 4.1.2,NumPY等库搭建网络模型,硬件环境为IntelCorei5-8300H CPU@2.30 GHz、16 GB内存、NVIDIA GeForce GTX 1060。
3.3 实验过程
本实验首先通过K-means++聚类算法得到适合该数据集的Anchor Box(见表1所列),修改train中的cfg等参数构建网络。实验参数设计:batch(批数)设置为1,初始学习率为10,最小学习率为10,动量参数为0.9,采用随机梯度下降法(Stochastic Gradient Descent,SGD)。本实验训练过程是在YOLOv4权重下进行微调,对其迭代5 000次完成该过程。IOU检测结果见表2所列。
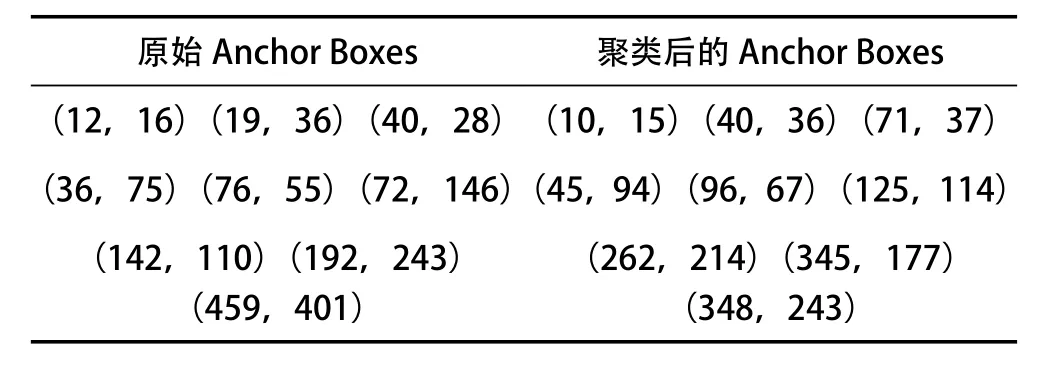
表1 聚类后的锚框坐标

表2 IOU检测结果
表1中的数据分别表示原始的Anchor Boxes坐标点,以及对本实验数据集使用K-means++聚类后得到的Anchor Boxes坐标点,得到的3行数据分别适用于本实验数据集中小型目标、中型目标以及大型目标的坐标。根据物体大小,选取有效的Anchor Boxes坐标,能提升算法速率与精度。从表2可以看出,经本文设计的聚类后,得到的Anchor Boxes较好提升了车辆检测的平均IOU,进一步提升了车辆检测与识别的精度。
3.4 评价指标
在对目标检测训练后的模型进行评估时,衡量的指标往往采用精准率P(precision)和召回率R(recall),其公式如下:

式中:TP(True Positives)表示正样本被正确识别为正样本;FP(False Positives)表示负样本被错误识别为正样本;FN(False Negatives)表示正样本被错误识别为负样本。本文采用mAP指标对训练结果进行评估,其中AP是Precision和Recall为2个轴作图所围成的面积,m表示取平均值。图4与图5分别表示了优化前后训练的结果。
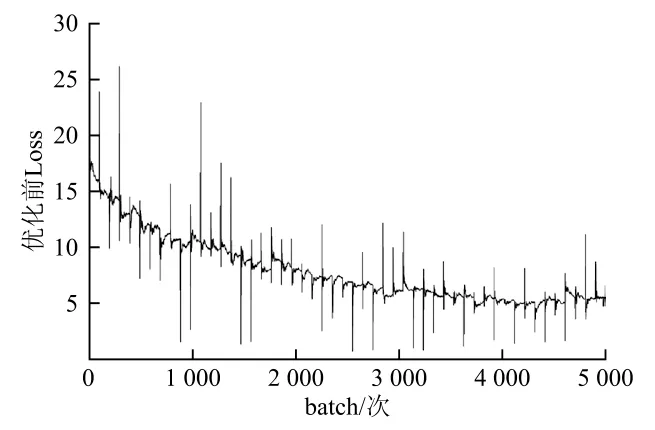
图4 优化前训练结果
图4、图5分别表示为优化前的实验训练结果,以及对其采用本文所述方法优化后的实验训练结果。从训练结果的曲线图中可以明显看出,实验优化前,训练时的损失值起伏较大,下降较慢。并且在训练结束时,损失值始终在5左右大幅波动,损失值较大,精度较低。而在实验改进后,可以明显发现训练损失值收敛较快,起伏较小,在3 500次后逐渐平缓,损失值在2.5左右波动,较优化前的Loss大幅减少。从数据可以得出结论,经本文对实验Anchor Boxes和损失函数的改进,数据训练的效果最好,损失值较快达到饱和且降低至2.5左右,并且其他评价指标也得到了良好的提升。

图5 优化后训练结果
对车辆进行测试的结果见表3所列。
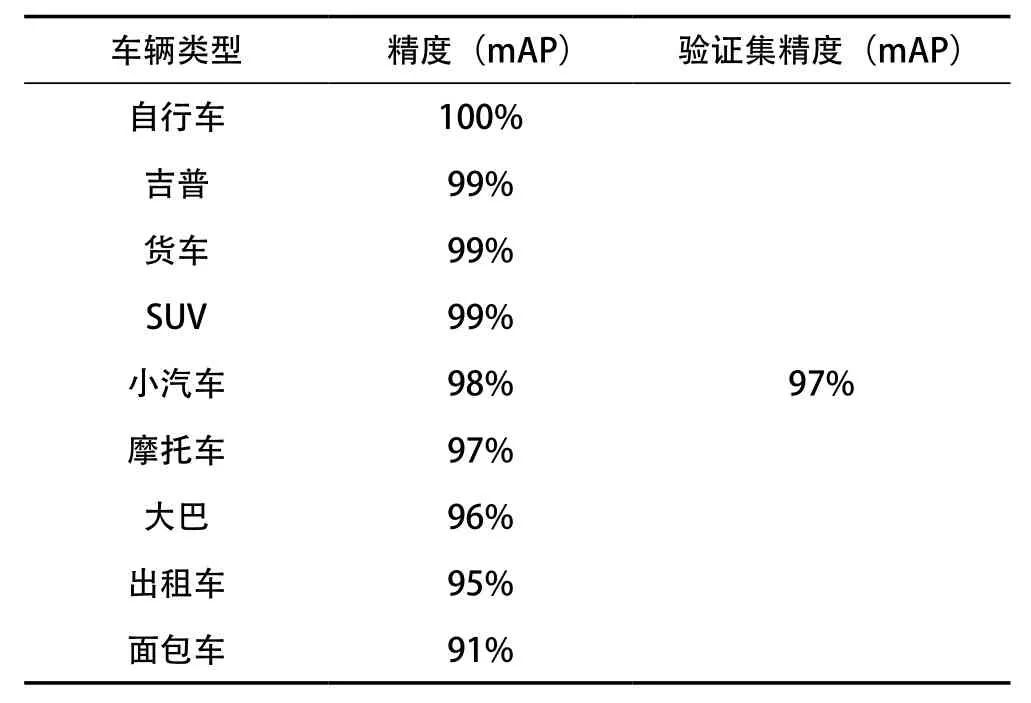
表3 测试结果
表3展示了本实验各类车辆mAP,可以看出,各类车辆都有较好的精度,整体验证集的mAP达到了97%,满足实际应用需要。
4 结 语
本文基于目标检测中的YOLOv4模型,通过研究K-means++算法的相关作用原理,对数据增强后的数据集进行聚类分析,求取适应于本文车辆数据集的Anchor Boxes坐标,并采用CIOU损失函数在收集并标注好的数据集上进行模型的训练与测试。实验数据表明,改良后的YOLOv4模型的性能得到了大幅提升,车辆检测准确性较高。
