基于PCA-MP-BP的智能电网数据融合方法
2022-02-21赖伟平林笔星
赖伟平, 林笔星
(国网信通亿力科技有限责任公司,福建,福州 350000)
0 引言
随着智能电网和大数据技术的发展,通过挖掘电网大数据的价值,为提高电力系统安全水平和服务质量带来了便利,电网大数据的研究对于社会发展具有重要意义[1]。但是随着电网大数据的增长,如何对多源数据进行整合,从中挖掘出对提高企业的管理水平和客户服务质量的信息,是一个十分困难的问题[2]。
随着智能电网技术的飞速发展,带来了海量的数据,如何在电网大数据中挖掘出对当前服务质量有价值的信息,众多学者进行了越来越深入的研究。文献[3]提出针对智能电网产生的海量数据,采用数据融合和分析方法为智能电网的规划提供数据支撑,提高了智能电网的服务质量。文献[4]对电网调度站的智能告警系统上传的数据,进行数据的压缩,融合后进行分析,并判断出电网的故障点,提高了故障处理效率。文献[5]为了提高智能电网的隐私保护水平,提出了一种签名融合方法,以提高电网的效率和安全特性。文献[6]针对智能电网中的海量数据问题,提出了4种数据融合算法,提出了智能电网广域测量数据融合方法,降低了信息开销,提高了网络传输效率。文献[7]针对电网中存在的多维异构数据,设计了一种数据融合方法,对数据进行了深入挖掘和特征分析,提高了数据的应用效率。文献[8]采用受限玻尔兹曼机对电网大数据进行数据融合,该方法对异常信息的准确率,误报率和偶爆率等方面优于其他传统异常检测方法。文献[9]提出了智能电网数据仓库架构,建立了大数据应用体系的5级架构,提高了数据的分析效率。
针对如何提高智能电网采集到的大数据利用率问题,提出了采用PCA方法对电力大数据进行降维处理,然后采用MapReduce和BP算法相结合的数据融合方法,实现对风电功率预测,相比于其他传统方法,具有更快的数据处理速度和更高的预测精度。本文按如下结构进行组织,第一章对智能电网大数据的背景和意义进行了分析;第二章对智能电网大数据技术和数据融合技术进行了研究;第三章提出了基于MapReduce和BP算法的并行融合预测技术;第四章对所提的数据融合算法进行了算例仿真;第五章对全文进行了总结。
1 智能电网大数据融合
1.1 智能电网大数据
随着智能电网的飞速发展,从发电,输电,变电,配电等各个环节产生了海量数据,企业对数据进行有效分析带来了巨大挑战。大数据指的是在特定时间内的海量,结构各异的复杂数据集。大数据的特征包括:(1)规模性,数据的来源包括电力生产,传输和使用的各个环节,而且数据量达到了EP级别。(2)多样性,数据的格式包括文本、图像、视频等,且具有结构化半结构化和非结构化的数据特性。(3)高速性,电力大数据具有动态,快速,及时的特点,而且数据间存在网络化的关联。(4)价值密度低,对电力大数据进行挖掘,可以为生产,运行,管理等方面提供建设指导。
电力系统的大数据来自于生产,运行,管理等方面,包括发、输、变、配、调、用等各个环节,数据类型存在结构化和非结构化数据,因为设备类型和执行标准的不同,数据之间还存在异构特性,从电网的业务来看,包括了发电侧,输变电侧和用电侧的数据[10]。
1.2 智能电网数据融合技术
存在于智能电网中的数据,由于来源于不同系统和数据特征不同的原因,需要采用信息融合技术,对数据的海量化、冗余、异构等方面进行处理,实现数据的统一利用[11]。采用信息融合的方法对智能电网大数据进行处理,信息融合指的是从多个信息源提取对决策有价值的数据,以提高决策的准确性。信息融合包括数据层、特征层和决策层。数据层融合指的是如果对原始数据进行处理,消耗的计算资源较多,需要对数据进行预处理[12]。特征层融合指的是提取数据的主要特征,能够表征数据的属性,不影响数据使用价值。决策层融合指的是整合有价值信息得到最终的决策结果。
在电网中,从发电、输电、配电、用电等采集至平台的数据是分散的,互异的,直接对数据进行挖掘,不利用分析结果的准确性,也增加了系统的计算复杂度[13]。为了提高数据挖掘价值,对结果有价值的数据进行融合,提高数据使用效率。智能电网数据融合分析框架如图1所示。

图1 智能电网数据融合流程图
智能电网大数据处理需要采用大数据处理平台。大数据处理平台包括传感量测层、数据管理层和应用层。传感量测层采集的信息包括电力、温度、气象等数据。数据管理层主要用于实现特征融合,剔除冗余,噪声,不一致的数据,实现数据的清洗。应用层主要是根据采集的数据为电力企业和客户进行服务。
2 基于PCA-MP-BP的数据融合方法
2.1 主成分分析(PCA)
本文采用主成分分析法(PCA)提取智能电网大数据特征因子[14]。实现过程:设有N个样本,每个样本n个参数,表示为X=(xij)N×n。
(1)对X进行标准化处理。
(2)构建相关系数阵:R=(rij)n×n=XTX。
(3)求取R的特征根,记为λ1≥λ2≥…≥λn,对应的特征向量如下:
(1)
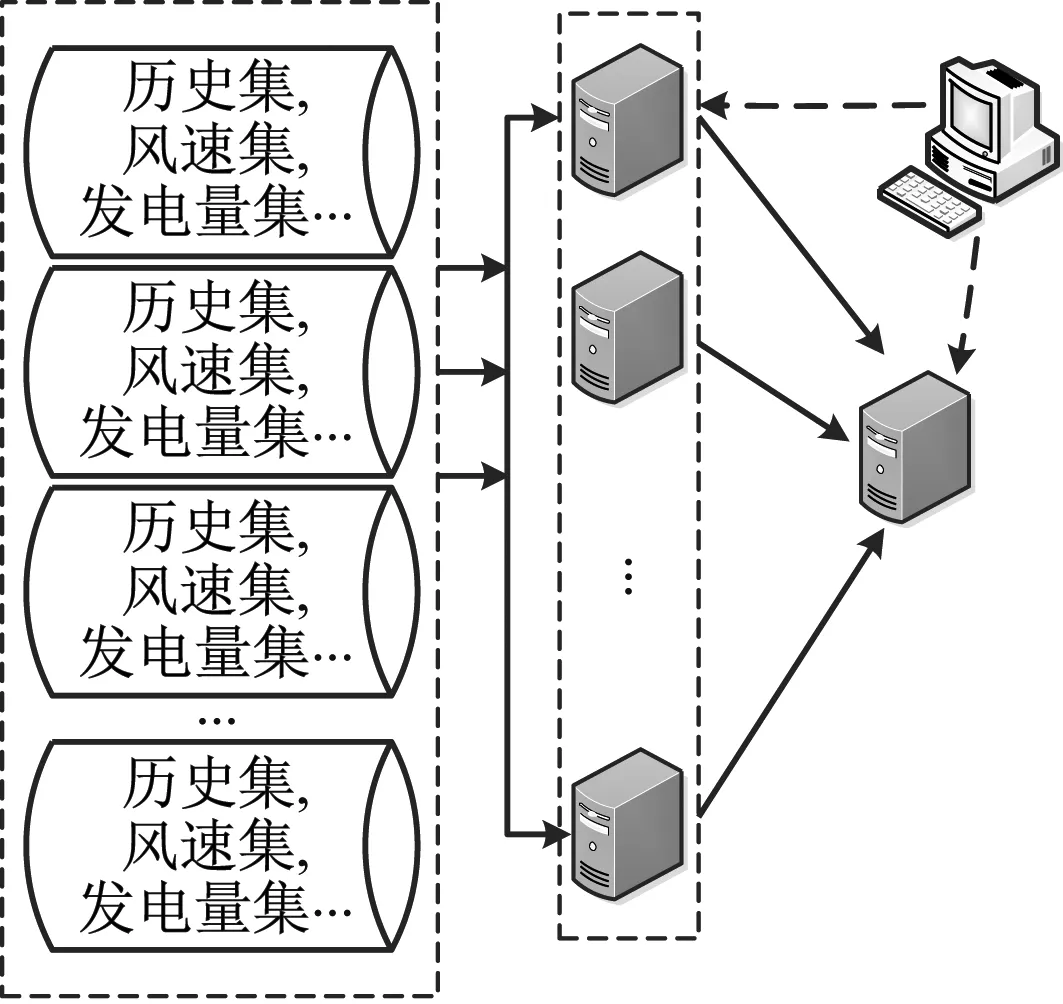
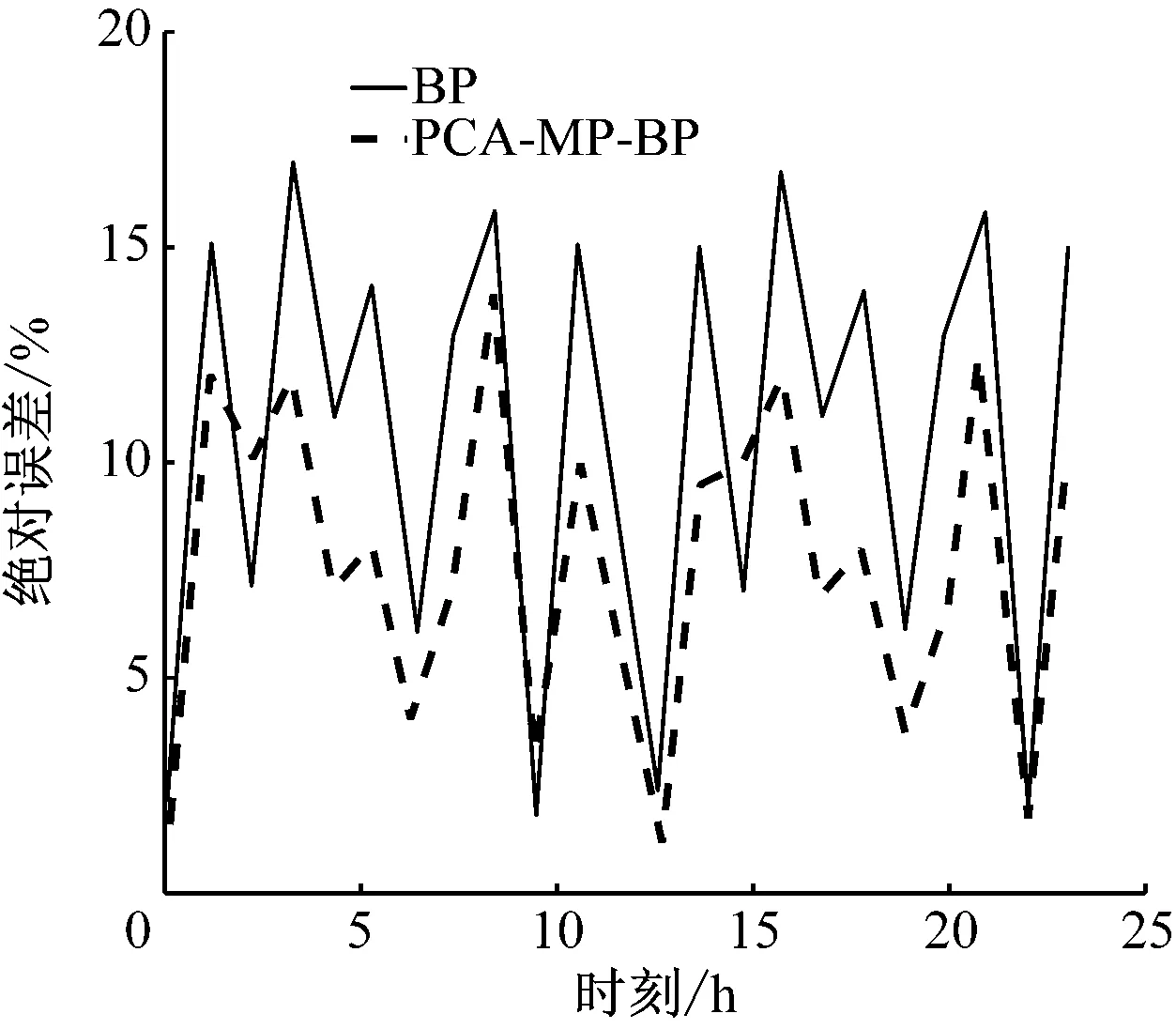
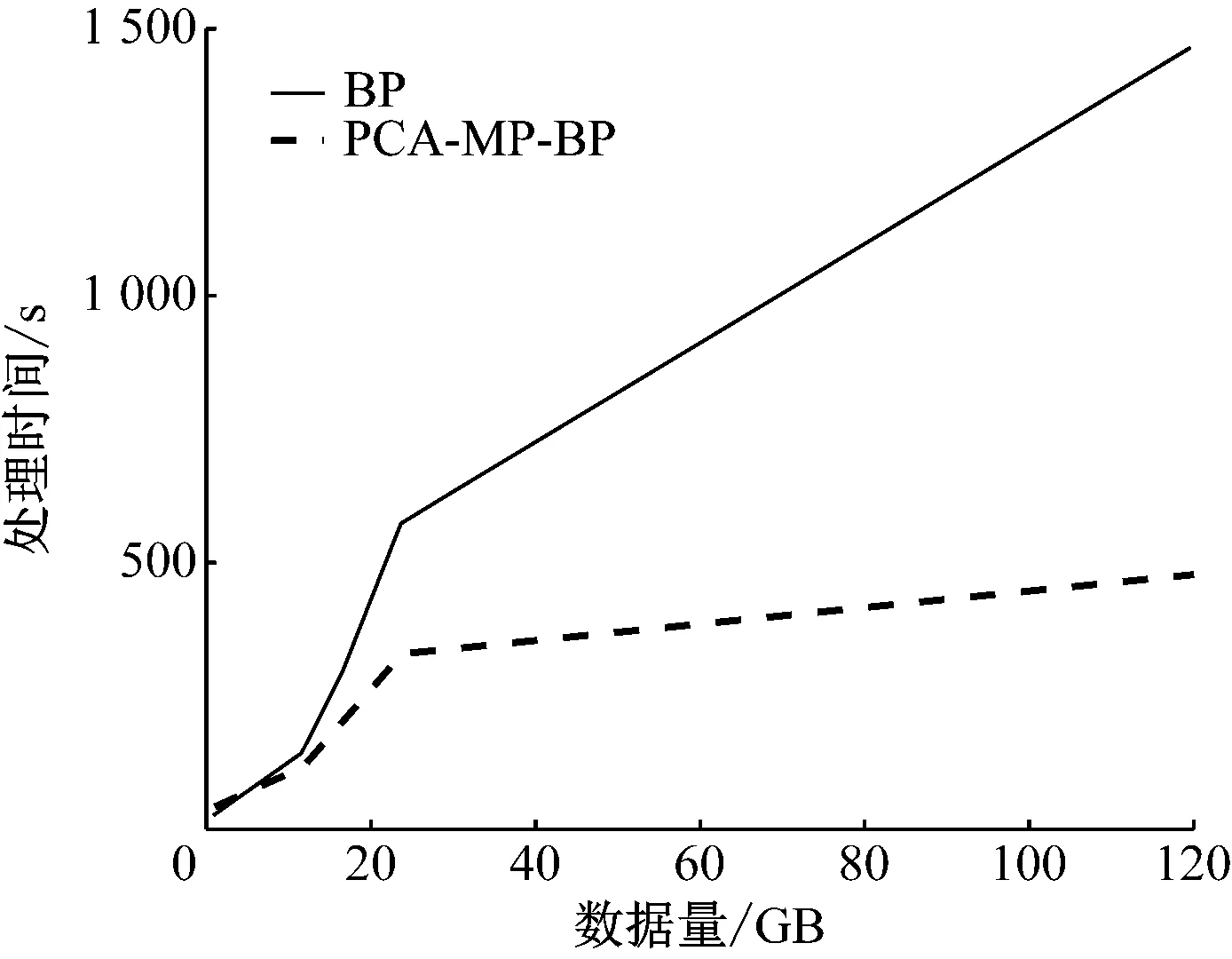
(4)提取主成分,取m个特征代替原始数据(m Fi=a1iX1+a2iX2+…+aniXn(i=1,2…,n) (2) XPCA=[F1,F2,…,Fm]=X[a1,a2,…,am] (3) (5)计算每个参数的贡献率,如式(4), (4) 反向传播(Back Propagation,BP)算法是通过输入层,隐含层,输出层之间的连接,实现正向传播信息和反向误差传播调整网络,最终得到网络输出。BP神经网络的结构图如图2所示。 图2 BP网络拓扑结构 假设输入为X=(x1,x2,…,xn)T,输出为Y=(y1,y2,…,ym)T。其中,n,m分别是输入层和输出层神经元数量。隐层和输出层激活函数为Sigmoid函数,如式(5), (5) 对k层的第i个神经元输入如式(6), (6) 该神经元的输出如式(7), (7) 误差反向传播时,假设期望输出为Yj,j∈[1,N]。误差计算用式(8), (8) BP网络的均方误差记作式(9), (9) 其中,Y是预测输出集,Yq是实际输出值。则k层权值调整方法如式(10), (10) 其中,η是学习率。 当预测输出值与实际输出值误差大于设定阈值的时候,求取误差值并反向传播,按照梯度下降法调整权值,经过多次调整,获得期望的网络结构。 由于传统的BP网络计算时间较长,不适用于解决大数据问题。并行计算是同时处理多个问题,每个问题由一个处理器求解,最终将复杂问题分解成若干个子问题计算,加快了处理效率。并行计算可以按时间方向和空间方向进行划分。 本文将BP和MapReduce相结合,以提高智能电网大数据处理效率。MapReduce将复杂问题分解成若干个Job,每个Job都存在Map和Reducer[15]。MapReduce能够高效处理大数据,具有快速收敛,精度高的特点。BP算法和MapReduce并行化的方法如图3所示。 图3 BP网络并行化流程图 将训练集数据分块传送给各个接收节点,在Map过程中对样本进行训练,求取权值,在Reduce过程调整权值并判断是否需要循环。Map的过程:从HDFS读取网络权值矩阵,根据网络权值得到神经网络模型,对样本的输入、输出进行归一化处理,根据误差值循环迭代算法,最终得到输出权值对,如图4所示。 图4 Map函数流程图 Reduce的过程:接收Map输出的键值对,求取平均权值,并判断是否需要循环,如图5所示。 图5 Reduce函数流程 智能电网的大数据处理要求具有实时性,保障电网运行的安全性。采用Hadoop方案,HDFS用于存储数据,MapReduce方法实现数据的快速处理。本文所提的基于MapReduce和BP的融合算法(PCA-MP-BP)对风电功率进行预测的流程如图6所示。 图6 并行融合处理算法 PCA-MP-BP算法的融合流程如下所述。 (1)数据离散化。采用K-means算法对采集的数据进行聚类处理。 (2)将监测的数据矩阵化。E作为风机某时刻监测矩阵,E=(d1,d2,…,dm,t)。M为维度,di是第i维数据值,t是采样时间。 (3)对采集的数据进行特征提取。 (4)采用MapReduce和BP并行化方法训练网络。 为了验证本文所提方法的有效性,在Hadoop平台上,采用风电场数据预测风电输出功率。建立了10台配置相同的节点进行实验分析,平台如图7所示。 图7 基于大数据融合的功率预测平台 选取某风电场2017年5月风机历史数据,共1 GB。定义风速(m/s)(X1),有功功率(kW)(X2),无功功率(kW)(X3),温度(℃)(X4),齿轮油温温度(℃)(X5),齿轮箱轴承温度(℃)(X6),相电流(A)(X7),发电机温度(℃)(X8),相电压(V)(X9),机舱温度(℃)(X10),风向(°)(X11),总电量(kWh)(X12)为输入。经过PCA-MP-BP处理后,得到的预测输出为风电功率。本文的预测误差检验方法为均方根误差(Root Mean Square Error,RMSE),如式(11), (11) 其中,Yt为预测结果,yt为实际值,n为样本数量。 t检验是求取两个平均值差异,如式(12), (12) 加速比用于评价并行算法处理性能,如式(13), S=t/T (13) 其中,t为单机耗时,T为集总耗时。 本文分别采用BP算法和PCA-MP-BP算法分别对风电功率进行预测,均为单隐层神经元。采用PCA算法提取出影响输出的主要特征,当特征集为X1,X2,X4,X8,X10,X11,X12的时候,贡献率为87.63%,所以将该特征作为输入特征。经过3种算法预测得到的功率预测对比曲线如图8所示。 图8 功率预测对比曲线 通过BP算法和PCA-MP-BP算法的预测结果,可以得到RMSE,MAPE对比结果如图9和表1所示。 图9 RMSE对比曲线 表1 误差对比结果 对算法的计算效率进行分析,将传统的方法与MapReduce方法进行对比,结果如图10所示。 图10 数据处理速度对比图 从图8可以看出,本文所提的PCA-MP-BP算法相比于传统的BP算法具有更高的预测精度。由于PCA方法消除了冗余变量,提取了主要特征因子,使网络结构更紧凑,建立的模型更准确。 从表1和图9可以看出,PCA-MP-BP算法的RMSE,MAPE和t检验结果均低于传统的BP算法。验证了本文所提方法的有效性。 从图10可以看出,在处理相同数据量的数据时,本文所提的PCA-MP-BP算法比传统的BP算法具有更快的处理效率。 为了提高智能电网大数据的处理效率,提出了PCA-MP-BP算法。对提取的电网大数据,采用PCA方法进行特征提取,对数据进行降维处理,然后采用MapReduce和BP算法相融合的方法对采集的数据进行分节点处理。通过风电功率预测仿真对比,验证了本文所提的方法相比于传统的BP算法,具有更高的功率预测精度,而且具有更快的处理效率,说明本文所提的智能电网数据融合方法适用于解决电网大数据问题。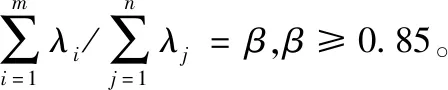
2.2 BP算法

2.3 基于MapReduce的BP算法
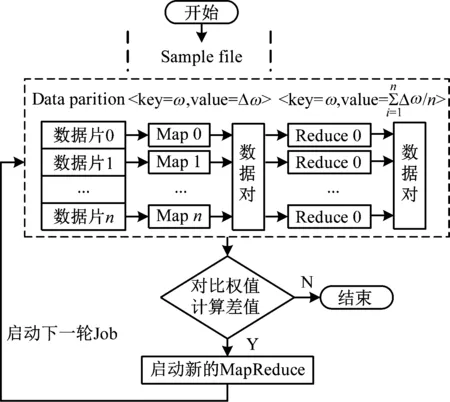

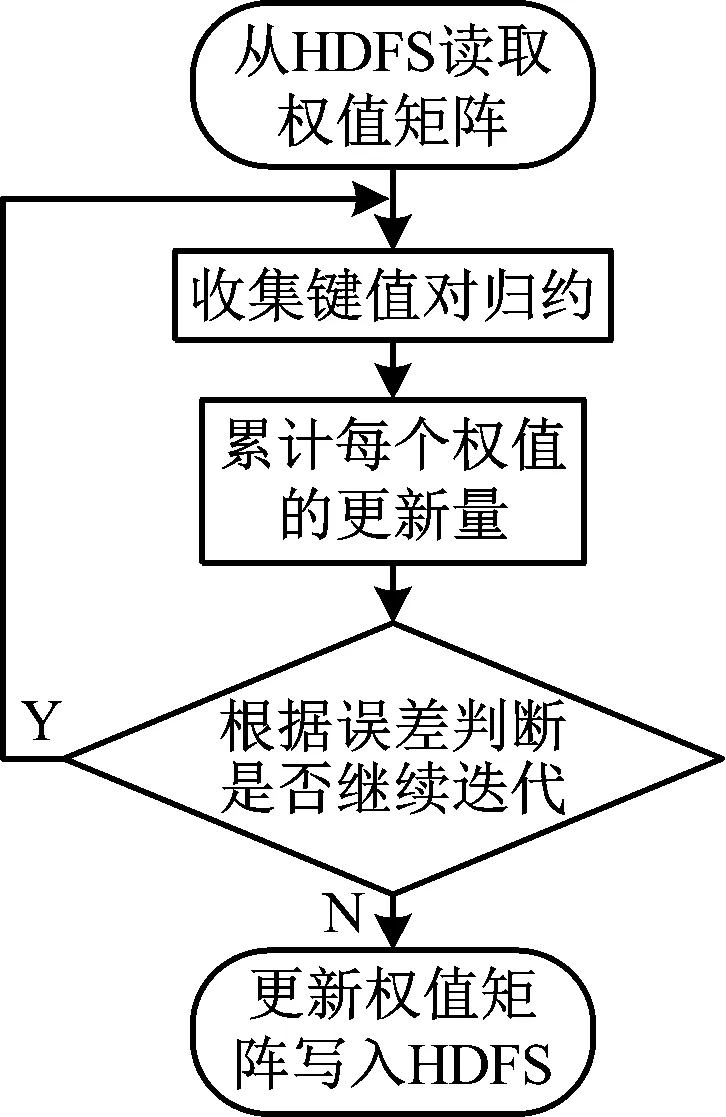
2.4 基于MapReduce的融合处理
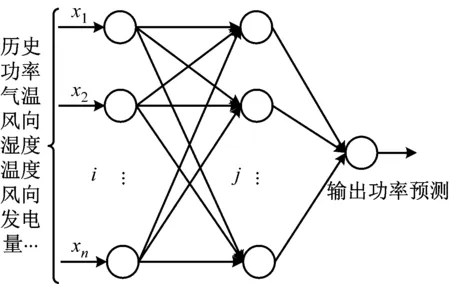
3 算例仿真
3.1 实验设置


3.2 结果分析
4 总结
