基于MongoDB数据库的智能医疗分布式数据提取算法
2022-02-21李鑫
李鑫
(鄂州市中心医院,湖北,鄂州 436000)
0 引言
智能医疗利用无线网络实现患者与医生、医院以及医疗设备之间的互动,通过采用无线传感网络技术、条码识别技术,实现特殊患者、医疗器械以及废弃药品的识别与管理。我国政府非常重视智能医疗体系的发展,尽管如今我国的健康体检中心的数量快速上升,规模较大的专业体检机构主要有美年大健康、爱康国宾、瑞慈体检、九华体检等,但是针对整个市场的格局来说,国内智能医疗健康产业基本停留在体检阶段[1]。目前看来,国内一些机构开始打造感知健康工程项目,构建智能医疗信息平台,使智能医疗体系更富有智慧[2];国外也在智能医疗分布式数据提取方面将数据融合技术与路由技术相结合,构造了智能医疗分布式数据融合树,从而提高了智能医疗分布式数据的融合效率,彰显了智能医疗分布式数据提取算法的地位[3]。
基于用户影响力的数据提取算法首先利用模拟技术获取用户之间的关系,在这种关系基础上,构建用户影响力网络,根据用户影响力计算方法,计算出用户影响力,并建立与智能医疗分布式数据特征相符的影响力模型,挖掘出最具传播力的智能医疗分布式数据节点,实现医疗数据的提取,实验证明了该算法可以提高智能医疗分布式数据的获取质量[4];基于Tribon模型的数据提取算法采用Tribon模型框架,将智能医疗分布式数据进行系统化的处理,利用分段分析方法,测试智能医疗分布式数据的质量和性能,保证智能医疗体系始终处于最佳状态,仿真结果显示该算法可以扩大数据提取范围[5]。
基于以上背景,本研究将MongoDB数据库应用到了智能医疗分布式数据提取算法中,解决了智能医疗分布式数据的提取难度。
1 智能医疗分布式数据提取算法设计
1.1 预处理智能医疗分布式数据
智能医疗分布式数据的预处理工作主要由2部分组成,一是通过智能医疗词库和MongoDB数据库构建智能医疗分布式数据自定义词库,二是读取智能医疗分布式数据集并进行子句的切分,提取分布式数据的标本名和中文分词,最后输出智能医疗分布式数据集<标本名,标本描述>[6]。具体预处理过程如图1所示。
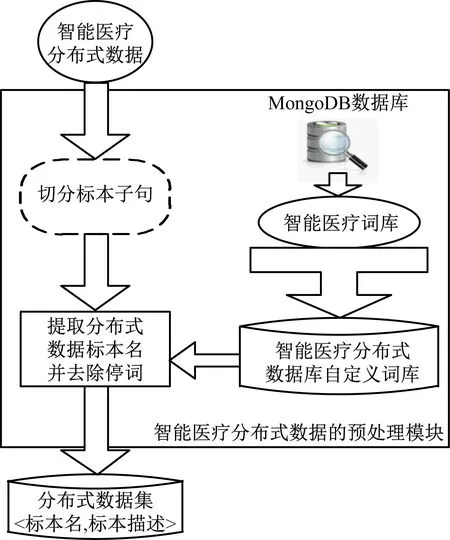
图1 智能医疗分布式数据预处理过程
在数据预处理过程中可以明确,构建自定义词库是预处理的第一步。进行中文分词的智能医疗分布式数据就是智能医疗分布式文本,具有医学概念上的层次结构,不能使用高通用性的工具来建立分布式数据库自定义词库,为了解决分词效果不理想的现状,将MongoDB数据库集群结构引入到了自定义词库中[7]。
在引入MongoDB数据库集群结构的基础上,从智能医疗网络中搜索出分布式数据的相关词汇,将智能医疗标准词库和相关词汇合并,共同构成分布式数据的自定义词库。
智能医疗分布式数据预处理的第二步是提取分布式数据的标本名。首先根据智能医疗体系文本,书写分布式数据的结构特点,获取到分布式数据的切分规则,其次是利用MongoDB数据库集群结构分词数据库,并进行去噪处理,最后根据标本名提取规则,从数据库分词序列中获取分布式数据的标本名[8]。提取到的分布式数据标本如图2所示。
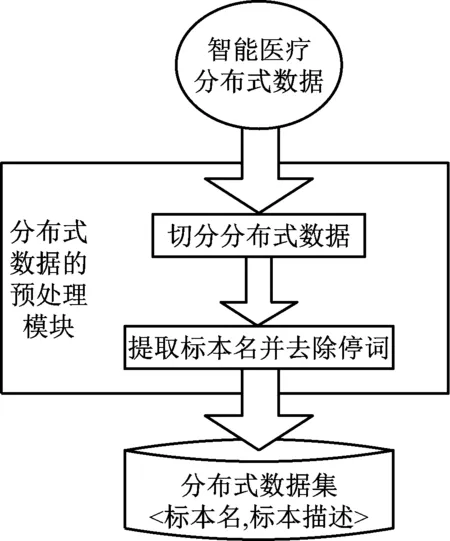
图2 标本名提取流程
在智能医疗分布式数据的预处理阶段,以上引入了MongoDB数据库集群结构,构建了分布式数据的自定义词库,同时提取出分布式数据的标本名,完成了智能医疗分布式数据的预处理[9];接下来通过建立分布式数据的动态簇,获取完整的分布式数据。
1.2 建立分布式数据的动态簇
建立分布式数据动态簇的过程中,采用多跳方式集成分布式数据到簇头之间的传输,分布式数据动态簇的建立步骤做如下描述。
Step1:配置智能医疗网络,通过智能医疗网络基站使分布式数据节点可以获取到医疗数据的信息,利用信息交换获得分布式数据相邻节点的信息。
Step2:将智能医疗网络中所有分布式数据节点的状态都设置为休眠状态,等待数据提取驱动器被唤醒[10]。
Step3:当智能医疗网络出现突发事件时,休眠的分布式数据节点就会被唤醒,其状态变成数据收发模式,该数据节点将成为簇头,并播报成簇信息,采用全新的监测数据MD来更新原有的NHT数据,将分布式数据节点成簇信息广播的跳数记作K,计算式如下:
K=ε|MD-NHT|
(1)
式中,ε表示传播系数,通常作为一个常数使用。
Step4:休眠节点接收到簇头的广播信息后,分布式数据节点的状态就会变成活跃状态,当接收广播包的AETT值和ID值与前一次相同,表示接收到的分布式数据信息是重复的,可以将该广播包丢弃。
Step5:当智能医疗网络出现突发事件时,在突发事件区域就会立即形成相应的动态簇,这一动态簇是以首个接收的分布式数据节点为中心,当已经成簇的分布式数据节点再次遇到网络故障时,休眠的分布式数据节点不会进入活跃状态,已经成簇的节点也不会再次出现冗余成簇现象[11]。
Step6:释放分布式数据的动态簇。
当分布式数据簇头的活跃时间结束后,就会将该动态簇释放,并将簇头与簇内分布式数据节点转变成休眠状态,等待下一次事件响应,重新参与动态簇头的竞选。
上述分布式数据动态簇的建立过程,可以减少智能医疗网络中的冗余数据,提高分布式数据准确性的同时还可以平衡智能医疗网络的能耗[12]。分布式数据动态簇的形成过程如图3所示。
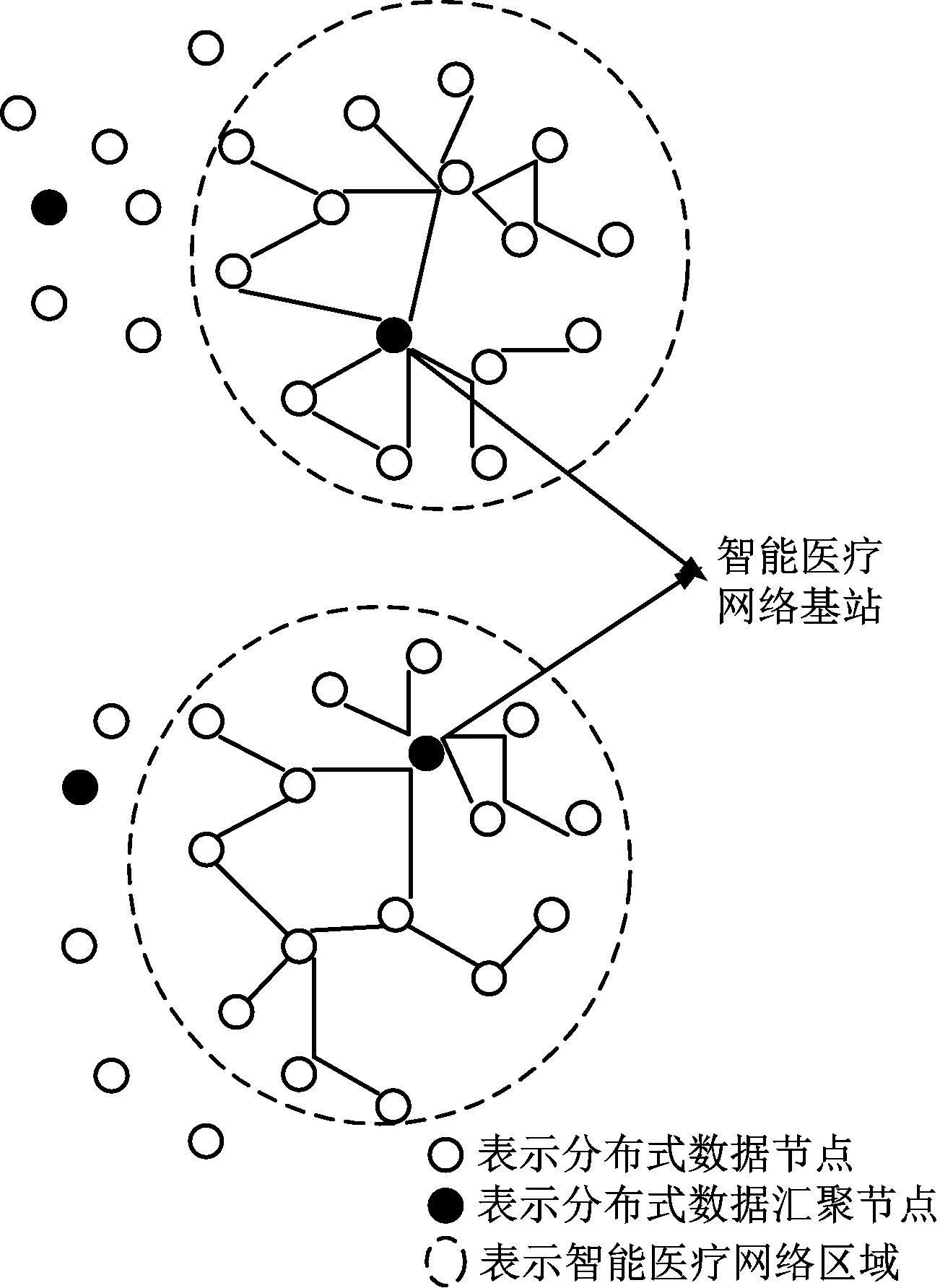
图3 分布式数据的成簇过程
以上利用分布式数据动态簇的建立步骤,设计了分布式数据的成簇过程,完成分布式数据动态簇的建立,接下来通过智能医疗分布式数据提取算法程序设计,来实现分布式数据的提取。
1.3 设计智能医疗分布式数据提取算法
DB波是智能医疗分布式数据波形变化最强烈的部分,DB波的斜率与其他波形之间的差距较大,DB波反映了分布式数据的极化过程[13]。在智能医疗分布式数据提取算法程序中,首先采用单位时程的方式,每3 s分割一次分布式数据,并读取单位时程内的分布式数据,将该数据保存在RG数组中,另外建立RG-diff和RG-all 2个数组,将分布式数据的初值设置为0[14]。利用数据差分算法扫描分布式数据,用式(2)计算数据的差分值[15]。
Δyi=yi-yi-1
(2)
式中,yi表示i时刻的分布式数据。将Δyi保存在RG-diff数组中,判断Δyi的正负值,如果相邻分布式数据Δyj到Δyj之间所有数据都为正值,可以令
(3)
如果相邻分布式数据Δyj到Δyj之间所有数据都为负值,则令
(4)
式中,ak、aj都是RG-all数组中的分布式数据,RG-all数组中元素保存的是分布式数据连续正差值之和以及负差值之和。
智能医疗分布式数据提取算法程序如图4所示。
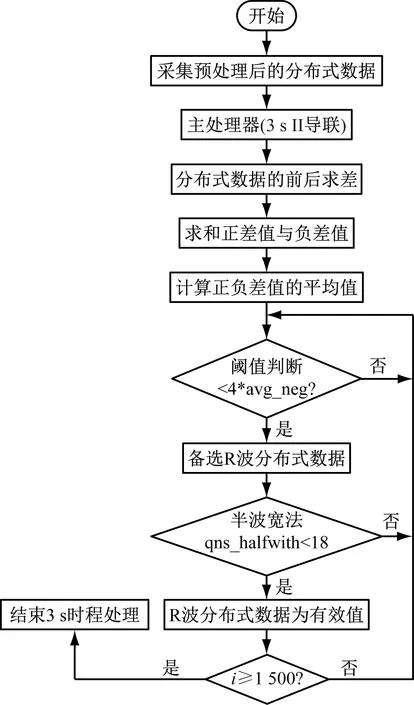
图4 智能医疗分布式数据提取算法流程
综上所述,将MongoDB数据库集群结构应用到了分布式数据的预处理中,建立了分布式数据的动态簇,通过智能医疗分布式数据提取算法设计,实现了智能医疗分布式数据的提取。
2 实验对比分析
2.1 设置实验参数
本实验的数据提取算法源代码来自中国生物医学文献服务系统(http://www.sinomed.ac.cn//index.jsp),实验参数设置如表1所示。

表1 实验参数
2.2 实验过程
可在10 000 m2的区域内随机分布120个分布式数据节点,在此区域内模拟智能医疗网络如图5所示。
图5 智能医疗网络模拟图
在智能医疗网络模拟图中,圆圈代表一个智能医疗网络基站,坐标是(50,50),星点代表一个分布式数据节点,用10个动态簇来演示实验场景。智能医疗网络模拟图中,群组划分用实体黑线表示,每个网格区域用群组表示。假定智能医疗网络中分布式数据节点的位置信息是确定的,那么每个分布式数据节点都加入一个动态簇。簇头选择是以动态簇内能量最慢的分布式数据节点为基础,以每个簇内最慢节点为选举规则。假定网络中所有节点都与智能医疗网络基站相连,分布式数据节点的初始能量为100 J,感应半径为20 m。
2.3 算法性能分析
2.3.1 网络生存期对比分析
在2.1和2.2的基础上,分别采用基于用户影响力的数据提取算法、基于Tribon模型的数据提取算法以及基于MongoDB数据库的数据提取算法,对比分析了3种算法的网络生存期。实验结果如图6所示。

图6 网络生存期对比结果
从图6的实验结果可以看出,基于Tribon模型的数据提取算法和基于MongoDB数据库的数据提取算法的网络生存期,都是随着智能医疗分布式数据节点数目的增加而增大,但是基于Tribon模型的数据提取算法的网络生存期还远远低于本研究算法,而基于用户影响力的数据提取算法随着分布式数据节点数目的增多,网络生存期越来越短,由此可以看出基于MongoDB数据库的数据提取算法具有较好的网络生存期。
2.3.2 算法能耗对比分析
在2.1和2.2的基础上,分别采用基于用户影响力的数据提取算法、基于Tribon模型的数据提取算法以及基于MongoDB数据库的数据提取算法,对比分析了3种算法的能耗。实验结果如图7所示。

图7 算法能耗对比结果
从图7的实验结果可以看出,基于用户影响力的数据提取算法的能耗最高,其次是基于Tribon模型的数据提取算法,基于MongoDB数据库的数据提取算法的能耗最小,在分布式数据节点数目固定的情况下,基于MongoDB数据库的数据提取算法明显比基于Tribon模型的数据提取算法更节省能耗,原因可以从两方面分析,一是基于MongoDB数据库的数据提取算法对分布式数据节点路径不进行重复查询,而其他2个算法会在增强路径之前,查询整个智能医疗网络的情况,二是基于MongoDB数据库的数据提取算法会随着能耗的变化,找到最优路径。
基于用户影响力的数据提取算法的动态簇格式是固定的,当智能医疗网络中分布式数据节点数目增加时,更多的分布式数据节点在监测到智能医疗体系的突发事件时,就会向动态簇头节点传输分布式数据,因此造成了该算法在数据节点比较密集的智能医疗网络中会消耗大量的能量。
2.3.3提取延时对比分析
分布式数据提取算法在减少算法能耗的同时,也会产生一定的延时,采用基于用户影响力的数据提取算法、基于Tribon模型的数据提取算法以及基于MongoDB数据库的数据提取算法,对比分析了3种算法的数据提取延时。实验结果如图8所示。
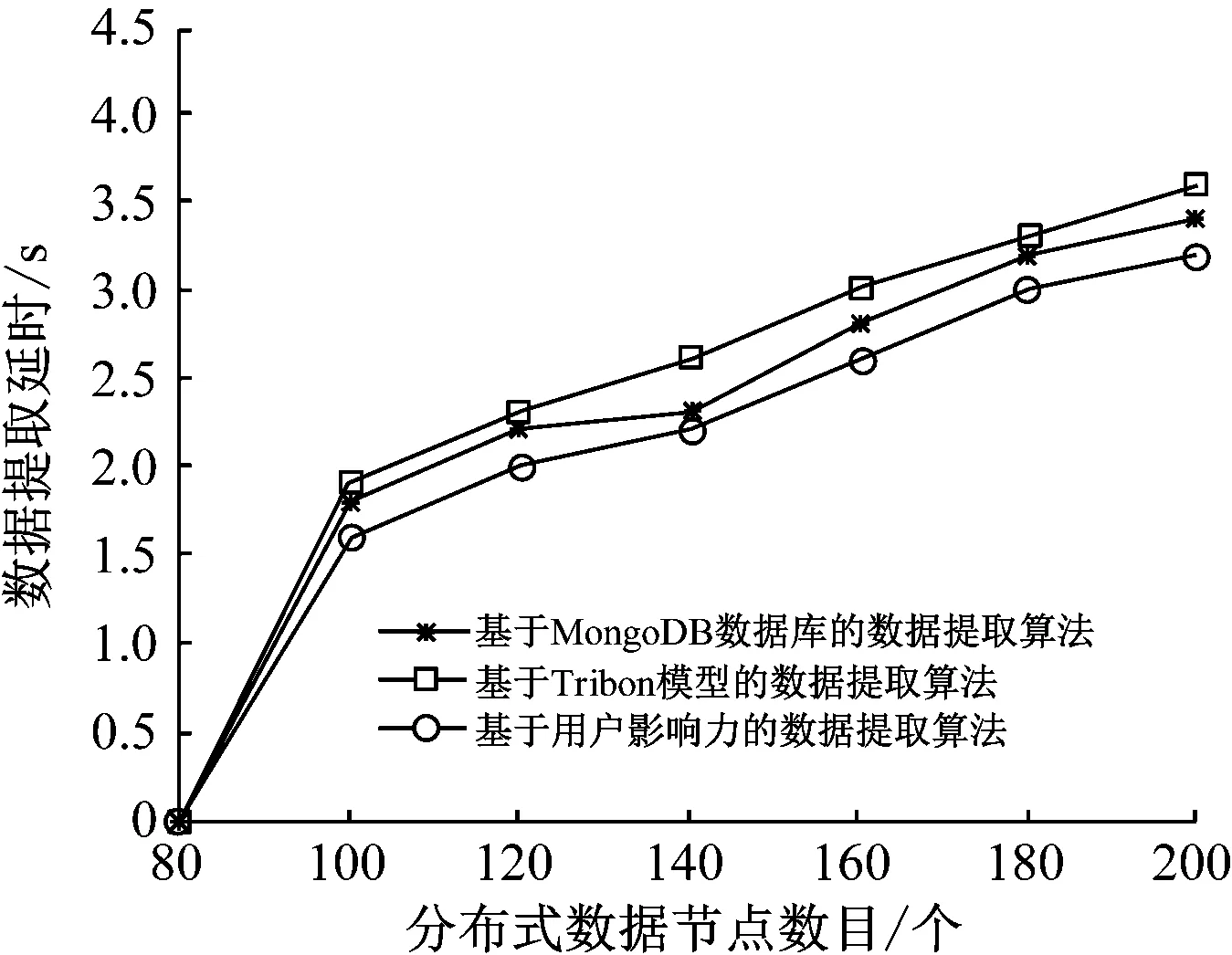
图8 提取延时对比结果
从图8的实验结果可以看出,3种提取算法中基于用户影响力的数据提取算法的数据提取延时最小,这是由于基于用户影响力的数据提取算法中所有分布式数据节点都是以单跳模式来向动态簇头传输分布式数据的,动态簇头再按照数据提取周期进行处理,并发送给汇聚节点,该算法的延迟时间主要是在动态簇头发生,但是对于智能医疗体系中出现的突发事件,基于用户影响力的数据提取算法并不适用;基于MongoDB数据库的数据提取算法的延时就远远小于其他2种算法,从整体上分析,基于MongoDB数据库的数据提取算法是一个可以平衡能耗和延时的算法,具有非常高的应用价值。
综合以上实验结果,无论是在网络生存期、算法能耗还是提取延时方面,基于MongoDB数据库的数据提取算法的性能远高于其他2种算法。
3 总结
本研究提出了基于MongoDB数据库的智能医疗分布式数据提取算法。在MongoDB数据库集群结构的基础上,对智能医疗分布式数据进行了预处理;利用分布式数据动态簇的建立步骤,设计了分布式数据的成簇过程,并建立了分布式数据动态簇,最后设计智能医疗分布式数据提取算法,实现了智能医疗分布式数据的提取。实验结果显示,基于MongoDB数据库的智能医疗分布式数据提取算法在网络生存期、算法能耗还是提取延时方面的性能更好。但如果运算数据过大的话,本算法可能会产生一定偏差,为此在以后的研究中,将会加强对该方面的改进。
