基于Hadoop平台的一种改进K-means文本聚类算法
2022-02-21潘俊辉王辉张强王浩畅
潘俊辉, 王辉, 张强, 王浩畅
(东北石油大学,计算机与信息技术学院,黑龙江,大庆 163318)
0 引言
目前随着互联网的发展,加快了数据量的积累,而其中的文本数据维度高、数据量大,同时又记录着有价值的信息,因此,可采用文本聚类方法将相似的文本进行归类处理,提取文本中的关键信息可以为智能化推荐等众多领域提供基础,从而实现资源的有效利用[1]。传统的串行文本聚类方法对于海量的文本数据难以进行高效的处理。随着云计算技术的出现,在Hadoop平台下实现分布式文本聚类是一个值得研究的方向。
国内外的诸多学者为提高聚类算法的性能进行了大量的研究。国内的黄剑等学者在Hadoop平台下并行实现了K-means聚类算法[2];高见文等通过MapReduce对海量数据以迭代的方式进行了并行聚类的实现[3];国外的Shikai Jin等提出了一种并行化的改进K-means方法,实验表明该方法既可减少开销,同时可提高效率[4];文献[5]的作者通过采用最大最小距离确定聚类方法的初始中心,从而可消除K-means对初始值敏感的缺点,同时在Hadoop平台下得以实现,可消耗更少的时间。
针对经典K-means算法中每个属性对样本的影响均相同,而许多改进算法中对于属性权值的确定需要依赖先验知识的缺点,本文通过引入属性权重提出了一种改进型的K-means聚类算法(ImprovedK-means Algorithm,IKA),同时为了提高该算法的效率,应用Hadoop平台完成了实现。通过实验对该算法进行了测试,结果表明Hadoop平台下实现的文本聚类改进型算法具有良好的聚类效果。
1 Hadoop平台及文本聚类
1.1 文本聚类
文本聚类是指通过对文本进行预处理后,将得到的结构化数据进行聚类在一起成簇,从而使同一簇中的文本尽可能地相似,而不同簇的文本尽可能不同。其中文本预处理阶段的工作主要是通过提取出文本中的特征词并计算其权重,从而得到结构化的数据,并且该阶段的结果直接影响整个文本聚类的结果;而聚类分析阶段的工作则是通过聚类算法将文本数据划分到不同类别的文本集合中[6]。
1.2 Hadoop平台
Hadoop平台是实现分布式计算的一种开源框架,该平台主要包括两部分,分别是HDFS和MapReduce编程框架[7]。
HDFS主要的工作就是以分布式的形式存储大规模的海量数据。HDFS中的NameNode主要负责分布式文件系统的命名空间。DataNode则是HDFS的工作节点,主要负责数据的存储和读取。
MapReduce核心是Map函数和Reduce函数。Map函数可将输入数据以〈key,value〉的形式切分成独立的小数据块,并以〈key,value〉的形式输出,并同时提供给Reduce函数;Reduce函数接收到Map处理的中间结果后,将相同的键值进行合并,最后输出结果并写入到HDFS[7]。
2 Hadoop平台上实现文本聚类的改进型算法
2.1 K-means算法
K-means算法通过将距离作为相似性的评价指标,采用式(1)的误差平方和作为K-means算法的聚类准则函数。由于算法中初始聚类中心的选取是随机的,因此会直接影响文本聚类的结果。
(1)
K-means算法的执行流程如下。
Step1:随机从数据集中选取K个样本作为算法的初始簇心。
Step2:使用距离计算式,计算每个样本与K个聚类中心的欧式距离。
Step3:按照距离远近,将样本归入到距其最近的聚类中心所在簇中。
Step4:对各簇的样本均值进行计算,从而得到新的聚类中心。
Step5:若算法迭代次数达到最大值,或评价指标值与上次的评价指标值的差小于最小精度确定的值,算法结束,否则转向Step2,执行相关操作。
2.2 改进型K-means聚类算法
使用K-means算法进行聚类时,假设数据集为X,具有P个属性,要将数据集分成K类,通过不断调整聚类簇心,从而使式(1)具有最小值,其中uj,j=1,2,…,K为簇心,如式(2)。
(2)
式中,d(Xi,uj)是指样本Xi与簇心uj间的欧式距离,权重系数为1,意味着在算法中每个属性的作用是同等的,而在实际中每个属性对样本的作用是不同的。由此为了把每个属性对样本的作用不同的特点体现出来,使算法具有更好的聚类效果,本文在K-means算法中引入了权值,从而使聚类准则函数发生变化,新的函数如式(3)。
(3)
(4)
由式(4)可知,当各类中的类内样本与簇心的距离和最小且不发生变化时,V(P,λ)具有最小值。由此本文通过分析采用拉格朗日函数法计算在约束条件下每个属性的权重。
构造拉格朗日函数如式(5),
(5)
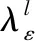
(6)
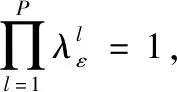
(7)
由此可得到基于属性权重的改进算法IKA的实现步骤如下。
Step 1:随机从数据集中选择K个样本作为簇心;
Step 2:计算出每个样本与K个簇心间的距离,从中得到距离最小的簇心(uj,j=1,2,…,K),然后归入该类中;
Step 3:根据权值计算式(7)计算得到每个属性的权值;
Step 4:根据计算得到的各类的属性权值,重新对各类的簇心进行计算;
Step 5:若算法迭代次数达到最大值,或评价指标值与上次的评价指标值的差小于最小精度确定的值,算法结束,否则转向Step2,执行相关操作。
2.3 基于Hadoop平台的改进型文本聚类算法(H-IKA)
通过IKA算法的实现步骤可看出该算法是串行迭代的,而计算每个样本的最近簇心却是独立的,因此可对其并行执行,由此在Hadoop平台下对IKA算法并行进行了实现。在H-IKA算法中,有3个关键函数需要执行,分别为Map、Combine和Reduce函数。其中属性权重的引入是在Reduce函数中进行的,因此对Reduce函数进行了改进。
改进后的Reduce函数其功能是用来计算各类的属性权重,然后利用得到的属性权重计算新类的簇心。Reduce函数的输入中key表示样本所在类的序号,value值代表样本属性值;Reduce函数的输出中key’表示样本所在类的序号,value’则代表新种群的簇心。以下为Reduce函数的伪代码:
reduce(〈key,value〉,〈key’,value’〉)
{
初始化存储各维坐标累加值的数组,分量初值均为0;
初始化记录相同簇的样本个数Num=0;
while(value.hasNext()){
解析得到num和样本的各维坐标;
累加各维坐标到数组(va)对应的分量中;
将求得的各维坐标与类簇心各维坐标差的平方和累加到数组(va1)对应的分量中;
将求得的各样本与类簇心间距离的平方累加到分量(va2)中;
Num+=num;}
相乘va中各坐标分量,然后开p次方;所得值与分量va2相除,得到各类属性权重;
va1中每个分量除以Num,将结果与属性权重的各维分量相乘,得到新中心点坐标;
key’=key;
构造具有新中心点各维坐标信息得字符串,value’=字符串;
输出〈key’,value’〉
}
3 实验结果
实验采用8台相同的计算机搭建了实验平台。构造了大小分别为16G和32G的48维的数据集,在构造的数据集中,数据的属性对分类的影响较大。实验分别从收敛速度和聚类精度两方面对基于Hadoop的K-means算法和基于Hadoop的IKA算法进行了测试,表1和表2分别给出了收敛速度和聚类精度的比较结果。

表1 收敛速度比较

表2 聚类精度比较
由表1和表2可见,分别对16G和32G的数据集进行操作时,基于Hadoop的IKA算法的平均迭代次数最小,聚类结果的准确性更高,表明基于Hadoop的IKA算法优于基于Hadoop的K-means算法,更适合处理大数据集的数据,其原因为在H-IKA算法中考虑了属性权重的影响。
4 总结
本文针对K-means算法中由于每个属性作用均等而导致聚类效果受到影响的缺点,通过引入属性权重提出了一种改进型的K-means聚类算法,同时为提高算法效率,将其迁移到Hadoop平台上进行实现。最后通过实验对算法进行测试,实验结果表明Hadoop平台下实现文本聚类的改进型算法在收敛速度和聚类精度上具有较大的提高。
