基于RF和SVM模型的东川泥石流易发性评价研究
2022-02-21赵俊三林伊琳
李 坤,赵俊三**,林伊琳,陈 轲,毕 瑞
(1.昆明理工大学 国土资源工程学院,云南 昆明 650093;2.智慧矿山地理空间信息集成创新重点实验室,云南 昆明 650093;3.云南省高校自然资源空间信息集成与应用科技创新团队,云南 昆明 650211)
泥石流是山地地区常见的一种地质灾害,由水和大量的沉积物、碎屑、泥沙等松散物质混合形成,具有很大的破坏力[1].据中国地质调查局发布的全国地质灾害通报[2],2019 年全国共发生泥石流灾害599 起,占地质灾害总数的9.69%,严重阻碍着经济发展和社会稳定.因此,通过泥石流易发性评价研究预测泥石流发生的空间概率,对于泥石流灾害预警和防治具有重要的意义[3].
国内外针对泥石流易发性评价研究方法主要是启发式法[4-5]、物理模型方法[6-7]和机器学习方法[8-10].启发式方法主要是依靠主观经验筛选诱发泥石流的指标因子,然后对研究区进行泥石流易发性描述.物理模型方法试图复现地质灾害发生时刻坡体所承受的各种条件,从而确定斜坡的绝对安全系数[7].但是,在建模过程中模型参数调整需要花费大量的时间精力,且该方法对于单个泥石流灾害预测效果比较突出,而在预测区域性泥石流易发性仍有较大的局限性.近年来,随着数据量的爆发和算法的创新,越来越多的算法应用于泥石流易发性评价研究并取得了良好的预测性能,例如人工神经网络[11]、决策树[12-13]、逻辑回归[14]等机器学习算法.相比人工神经网络和决策树算法,在灾害易发性评价时,随机森林和支持向量机可以直接计算每个评价单元内泥石流易发性指数,避免了人为主观因素的干扰.两种算法已经成功运用在某些灾害的研究中,如滑坡[15]、洪水[16]、森林火灾[17]等.由于泥石流与指标因子之间存在着复杂的非线性关系,在对泥石流进行区域性易发性评价还存在着很多问题[18].在评价单元上,多是基于栅格单元[19]进行泥石流易发性评价,虽然栅格单元在计算统计方面具有很强的优势,但是流域单元既保证了流域的完整性,又反映出泥石流与指标因子之间的联系.
本文以典型高原山区的东川区为例,综合考虑研究区复杂的自然条件,从地形地貌、水文气象、地质条件、植被覆盖和人类活动等5 个方面选取泥石流易发性评价指标因子.以流域单元为评价单元,结合RS 与GIS 技术,采用支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest,RF)两种机器学习模型,分别建立东川区泥石流易发性评价模型,并对东川区泥石流易发性进行分析.研究结果旨在提高地质灾害的预报能力,为山区泥石流防灾减灾提供科学依据,让决策者可以更好地了解东川区地质灾害发生的空间概率,进而更加准确地对地质灾害进行监测、预测并且能够及时对灾害进行预警,将地质灾害所带来的损失降至最低,以期为国土空间规划提供决策参考.
1 研究区域和数据来源
1.1 研究区域东川区位于云南省东北部,昆明市最北端,东与会泽县接壤,南与寻甸县相接,西与禄劝县相靠,北与四川省的会东县和会理县隔金沙江相望,介于102°47′~103°18′ E,25°57′~26°32′ N之间,总面积约为1 865 km2(图1).研究区域内主要为小江流域,小江由南向北贯穿整个研究区,属于金沙江南岸的一级支流.区域内沟谷纵横,高山对峙,海拔介于695 m 至4 344.1 m 之间,相对高差达到3 649.1 m.由于其独特的气候和环境,降雨和地质等因素造成研究区内地质灾害频发,主要有泥石流、滑坡等.其中,泥石流灾害最为严重,主要分布于小江流域和金沙江流域,素有“世界泥石流天然博物馆”之称.

图1 东川区泥石流点位分布及单元划分Fig.1 Distribution of debris flow points and division of units in Dongchuan District
1.2 数据源
1.2.1 泥石流数据集 泥石流数据集是建立泥石流易发性评价模型的重要前提,有助于了解泥石流发生的位置,辨明指标因子与泥石流发生的关系[8].泥石流在遥感影像上有着明显的地貌特征,具体可区分出泥石流形成区、流通区和堆积区[20](图2(a)).因此,本文依托东川区2017 年高分二号卫星影像、现场调研(图2(b)~(c))等方法,地图的底图结合从中国科学院资源环境科学与数据中心(https://www.resdc.cn/)获取的分辨率为30 m×30 m的DEM 数据及研究区地质灾害点空间分布数据,分别对泥石流点进行解译,最终在研究内共解译出110 个泥石流点(图1).

图2 东川区部分泥石流灾害遥感影像和现场照片Fig.2 Remote sensing images and field photos of debris flow disaster in Dongchuan District
1.2.2 评价单元 评价单元的选择是地质灾害易发性建模的重要前提,通常包括栅格单元、斜坡单元、特殊条件单元和流域单元[21].其中,流域单元既能比较全面地表达泥石流的几何属性,又能反映出泥石流与其指标因子之间联系.本文选用流域单元作为评价单元,运用ArcGIS 10.2 软件水文分析工具对研究区30 m 的DEM 数据进行划分,再结合高分二号卫星影像对所划分的小流域进行校正,最终将研究区划分为242 个流域单元(图1).
1.2.3 评价指标 泥石流的爆发是一个复杂的系统过程,其影响因素有很多[22].本文从地形地貌、水文气象、地质条件、植被覆盖和人类活动5 个方面选取泥石流指标因子.①地形地貌数据,基于研究区空间分辨率30 m 的DEM 数据派生得到坡度、流域高差、平均高程、剖面曲率、平面曲率、沟壑密度;②水文气象数据,根据全国气象站日值数据(http://data.cma.cn/site)获取会泽站、昆明站和宜良站2019 年降水量数据,发现研究区降水基本集中在雨季(5—10 月),利用Kriging 插值得到空间分辨率30 m 的雨季降水量和雨季降水量≥10 mm 天数.从东川区2019 年第三次全国国土调查数据中获取研究区河网信息,通过ArcGIS10.2 软件处理后得到河网密度与距河网距离2 个指标因子;③地质条件数据,从中国科学院资源环境科学与数据中心(http://www.resdc.cn/)获取研究区断裂带与地层岩性数据,经坐标转换得到断裂带密度,距断裂带距离、地层岩性数据,其中距断裂带距离利用ArcGIS10.2 软件的欧氏距离得到;④植被覆盖数据,采用研究区2019 年7 月植被最为茂盛时30 m 分辨率的Landsat 8 近红外和远红外波段计算得到归一化植被指数(NDVI);⑤人类活动数据,从东川区2019 年第三次全国国土调查数据中获取研究区道路信息,经ArcGIS10.2 软件欧氏距离处理后可得到距道路距离.
利用ArcGIS 10.2 软件的区域统计功能根据所划分的流域单元对共15 个指标因子进行离散化处理,其中河网密度、剖面曲率、距河网距离、距道路距离、沟壑密度、坡度、雨季降水量≥10 mm 天数、高程、平面曲率、NDVI、距断裂带距离、流域高差、雨季降水量和断裂带密度取平均值作为流域单元中相对应因子的值,地层岩性取流域单元内的频数最多的值作为流域内地层岩性的取值.所有栅格图层的空间分辨率均为30 m×30 m.
2 研究方法
2.1 随机森林模型随机森林分类(RF)是由很多决策树分类模型 {h(X,Θk),k=1,···,n}组成的组合分类模型,且参数集 {Θk}是独立分布的随机向量,在给定自变量X下,每个决策树分类模型都由一票投票权选择最优的分类结果,随机森林输出的分类结果最终由每颗决策树投票产生[23].
随机森林算法能够很好地处理高维度的泥石流数据集,并且在训练过程中能够通过多棵决策树对任意一个指标因子计算出多个贡献率指数,对该数取平均即为该因子的贡献率.与基尼变量贡献率相比,尤其是在变量之间存在潜在相关性的情况下,使用随机森林对因子贡献率评估更加稳定.为了得到可靠稳定的泥石流灾害预测模型,在模型训练时采用GridSeachCV 模块对模型进行超参数调优.
2.2 支持向量机模型支持向量机(SVM)是一种有监督的最大似然方法,它是从结构风险最小化的概念发展而来的一种相对较新并且很有前途的分类模型.支持向量机理论的基本思想是将学习机器与有限的训练样本相适应,通过内积函数定义非线性变换将输入空间变换到一个高维特征空间,在这个高维特征空间中求取最优分类超平面,使得在原输入空间中不可分的数据变得线性可分[24].
假设给定一个训练样本集D={(x1,y1),(x2,y2),···,(xm,ym)},yi∈{−1,+1},支持向量机的分类思想是基于训练集D在样本空间中找到一个最优的划分超平面.为了解决二元分类和回归问题,SVM的决策函数表示如下:
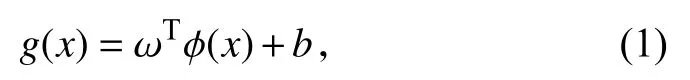
其中,ϕ(x)表 示泥石流样本x从输入空间到高维特征空间的映射;ω=(ω1,ω2,···,ωd)为法向量,决定了超平面的方向;b为位移项,表示超平面相对于原点的偏移;显然,法向量 ω和 位移b的最佳值通过求解优化函数获得:
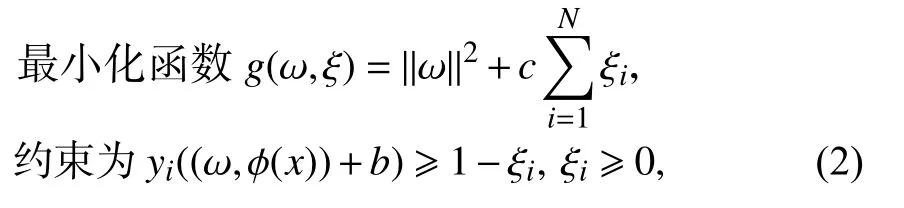
其中,ξi表示松弛变量,c>0 表示误差的正则化变量,核函数由下式计算:
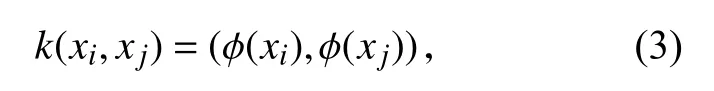
其中,xi与xj是训练样本变量.
在SVM 中常用的核函数包括线性核函数、多项式核函数、径向基核函数(Radial Basis Function,RBF)、Sigmoid 核函数.在非线性分类问题中,径向基核函数通常比其他核函数能获得更好的结果.
2.3 模型精度评价泥石流易发性评价应该具有有效地预测研究区未来泥石流发生概率的能力.为了能有效地评估随机森林和支持向量机模型对于泥石流易发性的预测能力,本文采用受试者工作特征曲线(Receiver-Operating Characteristic,ROC)以及曲线下面积(Area Under Curve,AUC)和准确度(Accuracy,ACC)对模型的性能进行评价.ROC 曲线越靠近左上方越好,越往右下方越糟糕,曲线如果在虚线的下方,证明模型完全无法使用;AUC 值介于0~1,值越高表明模型的精度越好.其中,ACC 值依靠混淆矩阵计算.如表1 所示,混淆矩阵揭示了模型的预测结果与真实结果之间的关系.ACC 值的计算式如下:

表1 混淆矩阵评价ACC 值Tab.1 The confusion matrix evaluates ACC values

ACC 值是用来度量样本被正确分类的比例.其中,TP(True Positive)和TN(True Negative)是指被正确分类的流域数量,FP(False Positive)和FN(False Negative)是指错误分类的流域数量.
3 泥石流易发性分析
3.1 泥石流评价指标贡献率分析由于数据集中的指标因子对泥石流形成的贡献率大小可能不同,进一步分析时应去除贡献率较小的因子,因此有必要对泥石流指标因子的贡献率重新进行评估.本文使用逆向淘汰方法,即基于随机森林模型选择最优指标因子,提高模型的预测能力.首先,建立一个包含所有指标因子的随机森林模型,对模型进行最优参数调整,并记录模型的性能和各个因子的贡献率;然后,按照指标因子的贡献率,从低到高逐个消除指标因子,每消除一个指标因子就利用剩余的因子构建新的随机森林模型,根据模型的AUC 值确定截止位置,最终得到最优指标因子组合,可减少数据集中由于因子而产生的误差.
结果显示,建立包含所有指标因子的随机森林模型并经过超参数调优后,AUC 值达到0.852 1,并且获得各个指标因子的贡献率(图3).可以清楚地看到,在15 个指标因子中的断裂带密度是诱发泥石流贡献率最大的因子,其次是流域高差、平面曲率和平均高程,雨季降水量和距断裂带距离排在第5 位和第6 位.排在最后面的几个指标因子对泥石流的贡献率最小(尤其是河网密度).根据指标因子贡献率程度,从低到高逐个消除因子,获得最佳因子组合.最终,筛选出断裂带密度、流域高差、平面曲率、平均高程、雨季降水量(5—10 月)、距断裂带距离、距道路距离、坡度、剖面曲率、地层岩性及NDVI 共11 个指标,作为研究区泥石流易发性指标因子.取消了河网密度、沟壑密度、雨季降水量≥10 mm 天数和距河网距离4 个因子,模型的AUC 值达到0.900 4,相比精度提升了0.048 3.
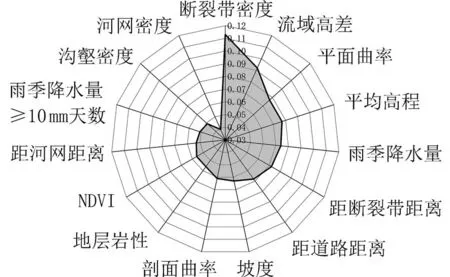
图3 东川区泥石流灾害各指标因子贡献率Fig.3 Contribution rate of each index factor of debris flow disaster in Dongchuan District
3.2 多重共线性分析多重共线性是指在多元回归模型中用于评价两个或多个变量之间高度线性相关的一种统计评估方法.一般采用容差和VIF(方差膨胀因子)评价各变量之间共线性情况,若容差大于0.2 并且方差膨胀因子VIF 值小于5,表明不存在多重共线性问题;反之,则存在多重共线性问题.本文使用SPSS 20.0 软件对筛选后的各指标因子进行多重共线性分析(表2),其中坡度因子的容差为0.163,VIF 值为6.132,与其他指标因子之间存在着共线性问题,根据上文指标因子贡献率分析结果,故将贡献率较低的坡度因子从指标体系中剔除.如表2 所示,剔除坡度因子后新指标体系中容差最小为0.265,VIF 值最大为3.777,新指标因子体系中不存在共线性问题.
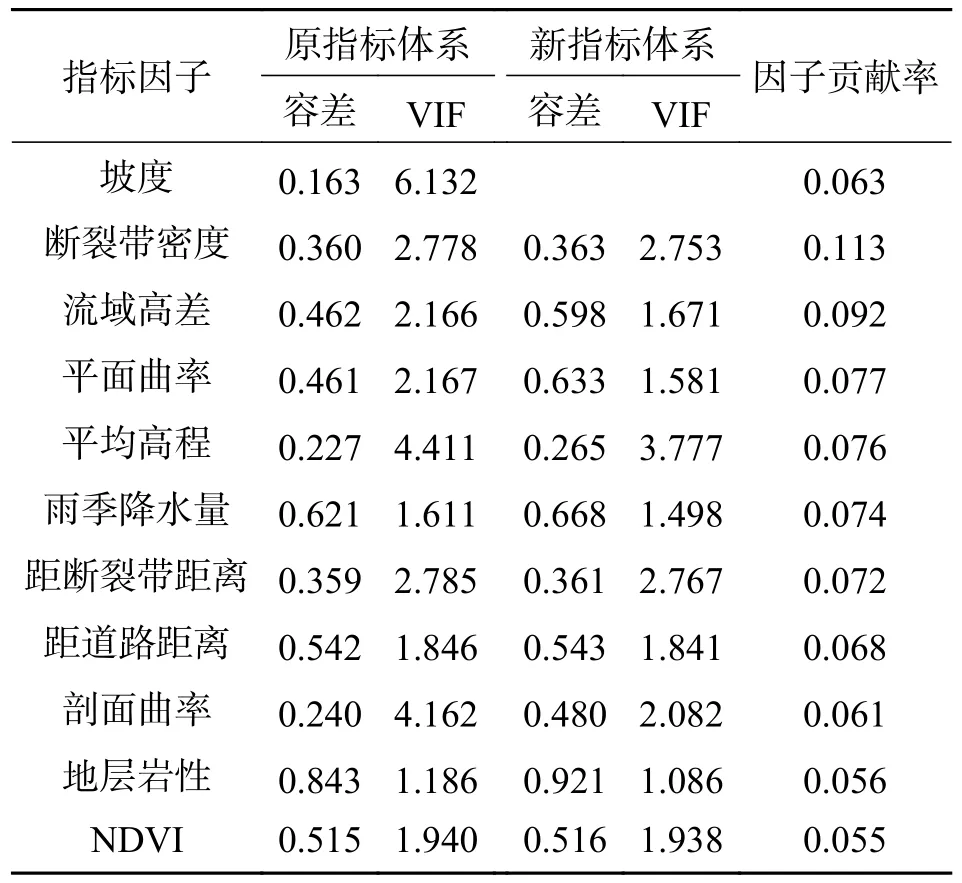
表2 各指标因子多重共线性分析及贡献率评价Tab.2 Multi-collinearity analysis and contribution rate evaluation of each index factor
3.3 构建模型本文共解译出研究区110 处泥石流点,根据随机森林模型与支持向量机模型的分类要求,将发生过泥石流的流域划分为一类,记为“1”,未发生过泥石流的流域划分为另外一类,记为“0”,以此将泥石流易发性研究问题转变为二分类问题.在研究区242 个小流域单元中,89 个小流域发生过泥石流,剩下的153 个小流域未发生泥石流,采用欠采样方法处理数据集不平衡问题,最终用于构建模型的基础数据集为178 个.在划分基础数据集为训练集与测试集的过程中,训练集与测试集的比率划分不恰当会影响模型的预测精度,因此参考相关文献研究[25-26],本文将基础数据集按照7∶3 的比例,划分为训练数据集(70%)和测试数据集(30%)用于泥石流易发性模型的训练与测试.
随机森林模型和支持向量机模型均采用Python语言通过Scikit-learn 框架构建,并通过GridSeachCV模块对模型进行超参数调优,在GridSeachCV 模块中的交叉验证方法也能用于搜索最优参数.调优后随机森林模型的决策树数目为50、最大深度为7、最小节点样本分割数为3、最小样本叶片和最大特征数均为1;支持向量机模型的核函数选择径向基核函数(RBF)、惩罚参数为0.5、Gamma 参数为0.109 85.
根据最优参数,分别建立基于随机森林和支持向量机的东川区泥石流易发性评价模型,并求取每个评价单元内的泥石流易发性指数,绘制泥石流易发性分级图进行易发性评价.
4 研究结果
4.1 易发性模型制图分析在基于随机森林和支持向量机模型建立的泥石流易发性模型平稳运行之后,通过模型计算研究区内各个评价单元的泥石流易发性指数,基于ArcGIS 10.2 软件中的自然断点法,将泥石流易发性指数划分为3 个等级,从低到高依次为低易发区、中易发区和高易发区(图4).由图4 可知,在泥石流易发性指数采用GIS 平台绘制研究区泥石流易发性分级图中,发现东川区现有泥石流点与高易发区的范围大致吻合.
根据图4 结果显示,研究区泥石流高易发性空间分布特征呈现出斜“I”字形,主要集中在小江流域,少部分集中在金沙江南岸.两个模型均显示出研究区内泥石流高易发区和低易发区分布均较为集中,高易发区主要分布于小江河谷和金沙江南岸,低易发区主要集中在研究区的西部,包括红土地镇、乌龙镇、汤丹镇和因民镇西部、舍块乡南部,少部分分布于阿旺镇南部.

图4 东川区泥石害易发性等级图Fig.4 The susceptibility grade of debris flow in the study area in Dongchuan District
泥石流易发性的评价结果也可以采用统计方法分析.表3 统计了3 个易发性等级的评价单元数量包括其所占的面积以及每一个易发性等级所对应的泥石流个数,并计算每个易发性等级泥石流数的占比与对应易发性等级面积占比之间的比值,获得各易发性等级内的泥石流密度.从表3 结果可以直观地看出,在高易发等级中,基于RF 模型的预测结果所占的流域数量为90 个,研究区内高易发区面积为756.35 km2,90%的泥石流点分布在高易发等级中,泥石流密度达2.22.基于SVM 模型的预测结果所占的流域单元数量为89 个,研究区内高易发区面积为667.41 km2,有70.91%的泥石流点分布在高易发性等级中,泥石流密度达1.98.在中易发等级中,RF 模型中泥石流点占比为10%,泥石流密度为0.36,均低于SVM 模型的预测结果.在低易发等级中也得出相似的统计结果.
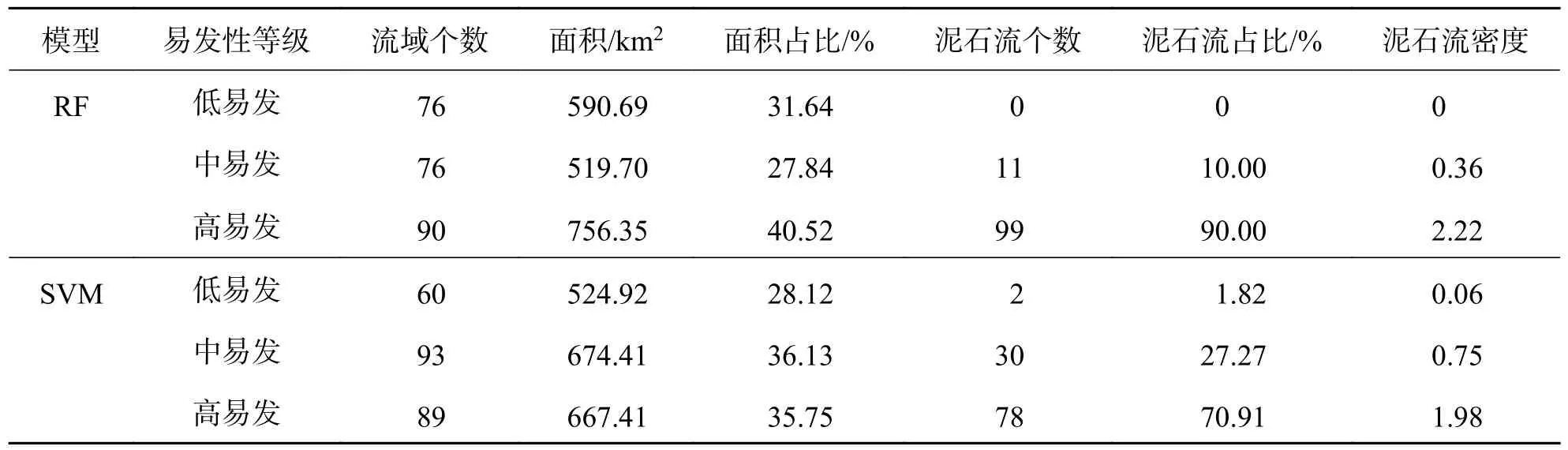
表3 东川区不同模型易发性等级及泥石流密度Tab.3 Vulnerability level and debris flow density of different models in Dongchuan District
通过对比两个模型,发现在随机森林模型中泥石流点主要集中在高易发等级流域单元内;对于支持向量机模型中有相当一部分的泥石流点分布于中易发等级和低易发等级区域.因此,根据泥石流点分布和泥石流密度可以看出,随机森林模型的预测结果比支持向量机模型的预测结果更加合理.
4.2 模型精度验证根据前文所述,本文分别使用训练数据集(70%的数据)和测试数据集(30%的数据)验证泥石流易发性模型的性能.采用ROC 曲线下面积的AUC 值对泥石流易发性模型性能进行评估,基于AUC 值的模型精度可分为以下几个级别:0.5~0.6(差),0.6~0.7(中等),0.7~0.8(好),0.8~0.9(优秀),0.9~1.0(接近完美)[23].结果显示,使用训练数据集的两种泥石流易发性评估模型的ACC值(表4)和AUC 值(图5(a)),随机森林模型的ACC值和AUC 值分别达到0.854 8 和0.958 7,支持向量机模型ACC 值和AUC 值为0.750 0 和0.886 1.使用训练数据集进行精度验证,可以帮助确定泥石流易发性模型与现有的泥石流灾害区域的吻合程度,但是泥石流易发性模型是基于这些训练数据进行训练的,因此该方法不适合用于对泥石流易发性模型预测性能评价;使用测试数据集的两种泥石流易发性评估模型的ACC 值(表4)和AUC 值(图5(b)),两种易发性模型均表现出良好的预测性能,随机森林模型的ACC 值和AUC 值分别达到0.833 3 和0.929 9,高于支持向量机模型的ACC 值(0.722 2)和AUC 值(0.851 5).综上得出,采用流域单元作为评价单元,随机森林模型对泥石流易发性预测表现出非常优秀的性能.
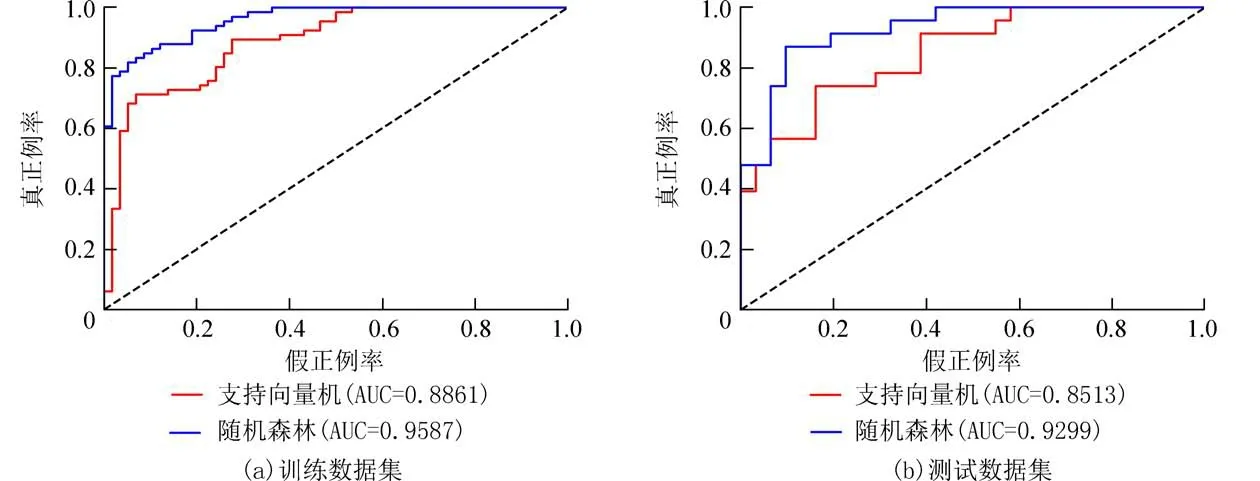
图5 基于训练数据集和测试数据集的模型ROC 曲线Fig.5 Model ROC curve based on training data set and test data set

表4 训练数据集和测试数据集上模型ACC 与AUC 值Tab.4 ACC and AUC values of the model on the training data set and test data set
5 结论
(1)采用流域单元作为评价单元,本文构建随机森林和支持向量机模型对东川区进行泥石流易发性分析.经对模型进行参数调优和对数据集优化,最终随机森林模型的ACC 值和AUC 值分别达到了0.833 3 和0.929 9,优于支持向量机模型的ACC值(0.722 2)和AUC 值(0.851 5),表明随机森林模型更适用于山区泥石流易发性评价研究.
(2)本文采用7∶3 的比例对数据集进行划分,以178 组数据为基础数据结合15 个指标因子构建的随机森林模型,采用逆向淘汰法筛选诱发泥石流的主控因子,并对指标因子进行多重共线性分析.结果表明,采用断裂带密度、流域高差、平面曲率、平均高程、雨季降水量、距断裂带距离、距道路距离、剖面曲率、地层岩性及NDVI 共10 个因子作为基础构建预测模型.其中断裂带密度、流域高差、平面曲率、平均高程为泥石流形成的主控因子.雨季降水量、距断裂带距离、距道路距离、剖面曲率、地层岩性及NDVI 在泥石流评价过程中也起到了重要作用.
(3)分析统计模型的预测结果发现,在高易发等级中,RF 模型所占的流域数量为90 个,面积为756.35 km2;SVM 模型所 占的流 域单元 数量为89 个,面积为667.41 km2.根据GIS 制图结果,两个模型都显示出研究区泥石流的高易发区主要呈现出斜“I”字形分布,即泥石流主要集中在小江河谷,少部分集中分布在金沙江南岸.低易发区主要集中在研究区西部,包括红土地镇、乌龙镇、汤丹镇和因民镇西部、舍块乡南部,少部分分布于阿旺镇南部.
本文在指标因子选取和处理过程中仍存在些许不足之处.在指标因子选取过程中具有一定的主观性,今后需要更进一步地分析诱发泥石流发育的指标因子,将可能存在的指标因子纳入初选因子中.
