多特征融合的越南语关键词生成方法
2022-02-21陈瑞清高盛祥余正涛张迎晨
陈瑞清,高盛祥**,余正涛,张迎晨,张 磊,杨 舰
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
随着“一带一路”倡议推进,中国与越南在政治、经济、文化等方面的交流日益密切.当今社会,互联网新闻报道作为信息传播的重要载体,成为人们了解越南国家的主要方式.面对互联网每天产生数以百万计的新闻,语言理解成为了艰巨挑战.如何从海量越南新闻报道中获取关键信息,提高信息使用率,对面向越南新闻舆情分析、跨语言新闻事件检索等领域具有重要研究价值.
在自然语言处理任务中,越南语关键词通常作为多词单元以简短的文本总结了越南语文档的基本思想,对文本摘要、信息检索和文本分类等下游任务非常有利[1-2].越南语关键词生成任务的主要目标是在给定源文档的情况下自动生成简洁凝练、代表文档主要内容的关键词.根据关键词的生成方式不同,可将关键词生成的方法分为两种类型:抽取式方法和生成式方法[3].目前越南语关键词研究大多使用抽取式方法,首先利用词汇特征(词性标签)、词频特征(Term Frequency-Inverse Document Frequency,TF-IDF)、外部信息特征(标题)等得到候选关键词集合,然后通过排序算法对候选词集进行排序,排名最高的候选词最终选择作为关键词[4].文献[4]基于本体论提出了针对特定领域的关键词提取算法,该算法基于本体自动提取文档的关键词,并使用提取出的关键词来计算两篇文章的相似度,在越南劳工和就业报纸在线网站上取得了不错的效果.文献[5]提出了一种结合卷积神经网络(Convolutional Neural Networks,CNN)和长短期记忆网络(Long Short-Term Memory,LSTM)的混合深度学习解决方案用于越南语文本中的关键字提取,提出的模型具有更高的准确性和F1 得分.文献[6]利用基于规则的方法从越南单语文档中自动提取英语−越南语双语术语.抽取式方法在越南语上的研究取得了不错的进展,但仍存在一定的局限性,例如,对于不存在于源文档中的关键词,抽取模型就无法预测这些词语[1].
与抽取式方法相比,生成式方法不仅可以提取源文档中出现的关键词,还可以生成源文档中不存在的关键词.它与人类思考方式更接近,通过理解整个文档后,重新组织语言生成源文档中已出现的关键词和不存在的关键词.文献[1]采用了编码器−解码器结构,注意力机制和复制机制相结合的CopyRNN 模型,并在大规模数据集上训练关键词生成模型.带有门控循环单元的双向RNN 在从大多数数据集中提取文档已出现的关键词时效果没有非深度学习方法好,但是CopyRNN 也有不错的性能.文献[7]提出了基于卷积神经网络的CopyCNN模型,提高了关键词的生成速度.尽管如此,Copy-RNN 和CopyCNN 网络将标题和正文平等对待,将标题和正文连接为唯一的源文本作为输入,而忽略了标题和关键词之间的语义相似性.文献[8]将标题信息用于指导编码,显著提升了生成关键词的质量.文献[9]通过引入主题模型使关键词生成模型能够挖掘文档中的潜在主题,提高了关键词与源文本的主题契合度.文献[10]通过强化学习方法,增加了生成关键词的多样性.文献[11]选择transformer作为编码器和解码器,利用跨文档注意力机制获得相关文档的潜在主题,以帮助在解码器生成更好的关键词.实验证明,与基于CNN、RNN 的生成模型相比,基于transformer 的关键词生成模型能够产生高度准确和多样的关键词,说明了transfomer 在关键词生成方面的强大能力.现有研究通常依赖大规模关键词训练数据,在英文关键词生成任务中取得的良好结果[8].
虽然英语关键词生成已经取得了很好的进展,但由于越南语高质量关键词新闻数据集稀少,远低于英文训练样本规模,生成过程中考虑的特征信息不足,同样的生成方法在越南语上效果却不理想.在表1 利用CopyRNN 方法生成的present keyphrases中,信息)”在此篇新闻中并不属于重要信息,不能作为关键词.飞机)”与真实关键词飞机制造商)”属于不同实体,也不能作为准确的关键词使用.此外,手机)”、“美国人)”等关键词均与参考标准关键词(ground truth)无关,无关的关键词占比53%.

表1 越南语关键词生成举例Tab.1 Example of Vietnamese keyphrase generation
越南语构词的主要特点是每一个音节作为独立的单位,具有实际语义,又可作为构成多音节词的基础.越南语兼类词具有多个词性,主要集中在名词、动词、形容词和量词等词性之间的转化上[12],例如困难、困难的,名词兼形容词),盐,名词兼动词),一斤盐),腌菜);在某些词前出现其他词时,这些词的词性会发生转变,例如动词前有事)事情)”时,该动词会变成名词使用.兼类词在不同语境下显示的词性不同,所表达的含义也不一样,对越南语关键词生成效果有重要影响.
越南语新闻与中文新闻结构相似,由标题、新闻内容等信息组成.越南语新闻标题表述完整,具有实际的语义,通常是主谓结构或动宾结构并且包含了能够凸显新闻核心内容的关键词语.新闻的正文通常在第一段交代新闻事件的时间、地点、人物、动作和对象等关键信息,后续段落则围绕这些关键信息进行展开.
为了提升生成的越南语新闻关键词与新闻文档的相关性,本文提出了一种多特征融合的越南语生成模型.通过融入越南语词性、新闻实体、词汇位置、新闻标题等特征,模型能够在生成关键词的过程中考虑更多的特征信息,以提高生成越南语新闻关键词的准确率.本文的主要贡献有:
(1)利用越南语词性、新闻实体、词汇位置、新闻标题等特征进行越南语关键词生成,有效缓解了越南语关键词数据集稀缺,训练样本不足导致生成关键词不准确的问题;
(2)通过双向注意力机制对上下文和新闻标题的语义向量进行融合,有效增强了新闻标题在生成过程中的指导作用,保持新闻标题与生成关键词语义上的一致性.
1 基于越南语新闻特征的词汇表示
关键词生成任务中的主要挑战就是要确定文档所围绕的关键概念和关键实体.为了实现此目标,我们使用了基于词嵌入的表示形式并融入了其他特征比如越南语词性特征、新闻实体特征、词汇位置特征[13]等.
1.1 越南语词性特征词性是词汇基本的语法属性,决定了词汇的语义倾向性[14].词性能够提供词语的抽象表示,对解决词语歧义问题具有重要的作用.兼类词的词性会受到前后两个词的词性影响,如果子)”有量(单位)词和名词两种词性,在一个球)”中,由于一)”是数词,“bong”是名词,从而可以判断是量词.与其他词性的词汇相比,在关键词生成任务中名词和动词通常包含了文档关键信息,对越南语新闻关键词数据集词性分布统计如图1 所示.可以看出,越南语新闻关键词数据集中的词性组成不是均匀分布,而是主要集中在几类词性上,这说明词性对关键词生成具有较强的指示作用.本文采用VnCoreNLP 越南语自然语言处理工具包[15]对越南语新闻关键词数据集进行词性标注,共26 种词性.以句子为例,词性标注结果如图2 所示.将词性向量化表示后与词向量拼接,使词向量包含词性特征.
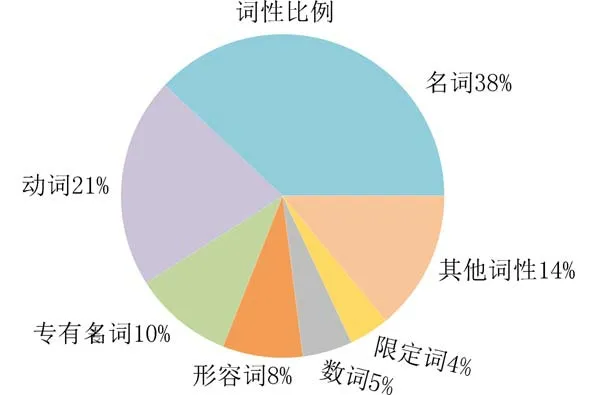
图1 越南语新闻关键词数据集词性分布Fig.1 Part-of-speech distribution of Vietnamese news keyphrases dataset

图2 VnCoreNLP 解析结果Fig.2 The analysis results of VnCoreNLP
1.2 新闻实体特征实体是人们最关注的词汇,往往是信息抽取的焦点,通常包括人名、地名、机构名、时间、专有名词等具有特定意义的实体[14].在关键词生成任务中,新闻实体包含了代表新闻文档主题的关键信息.本文用VnCoreNLP 越南语自然语言处理工具包对越南语新闻关键词数据集进行新闻实体识别,标注的实体共计9 类:“B-LOC”,“I-LOC”,“B-MISC”,“I-MISC”,“B-ORG”,“IORG”,“B-PER”,“I-PER”,“O”,B 表示开始,I 表示内部,O 表示非实体,如B/I-XXX,其中B/I 表示这个词属于实体的开始或内部,XXX 表示实体的类型,分为人名PER、地名LOC、组织机构名ORG、其他MISC 4 类.以句子为例,实体识别结果如图2 所示.将实体向量化表示后与词向量拼接,使词向量包含新闻实体特征.
1.3 词汇位置特征新闻文档的第一句或第一段通常涵盖整篇文章的主旨信息,文档的前半部分内容比后半部分内容更重要[13].越南语新闻文档采用倒金字塔写作方式,最重要的信息在标题中就会体现出来,新闻主题在第一段出现的可能性最大,最后一段往往属于对前面几段内容的总结.因此计算词汇的位置特征来表示不同位置词汇的重要性,计算公式如下:

其中,l代表词汇的位置特征,i代表新闻文本中第i个词汇的位置,n代表该新闻文本中总的词汇数目.l的值越大,说明该位置的词汇越重要.
本文将词转化为原始词向量,通过词向量拼接的方式在原始词向量后面添加向量化后的词性、新闻实体、位置等特征,最终输入编码器的词向量表示为:

其中,w、p、n、l 分别代表词、词性、命名实体、词位置,rw代表原始词向量,rp代表词性标注后的词向量,rn代表新闻实体识别后的词向量,rl代表词的 位置特征.
2 多特征融合的越南语关键词生成模型
2.1 模型总体架构关键词生成模型将给定的上下文x=(x1,···,xn)作为输入,得到一组关键词序列y=(y1,···,yn)作为输出.模型如图3 所示,分为拼接层、编码层、双向注意力层、合并层和解码层.首先将通过越南语词性标注工具和命名实体工具得到对应词性标签和新闻实体,并将词性,新闻实体以及位置特征向量化表示后与词向量拼接;然后双向注意力层为每个上下文中的单词收集相关的标题信息,以反映上下文的重要部分.该层的输入是上下文X=(x1,x2,···,xi)和标题T=(t1,t2,···,tj)的上下文向量表示,输出是上下文的标题感知向量表征G=(g1,g2,···,gi);最后,合并层将汇总的标题信息合并到每个上下文单词中,从而产生最终的融合标题信息的上下文表征.在得到标题感知的上下文表征之后,我们使用基于注意力的解码器[16]并结合了复制机制[17]来生成关键词.
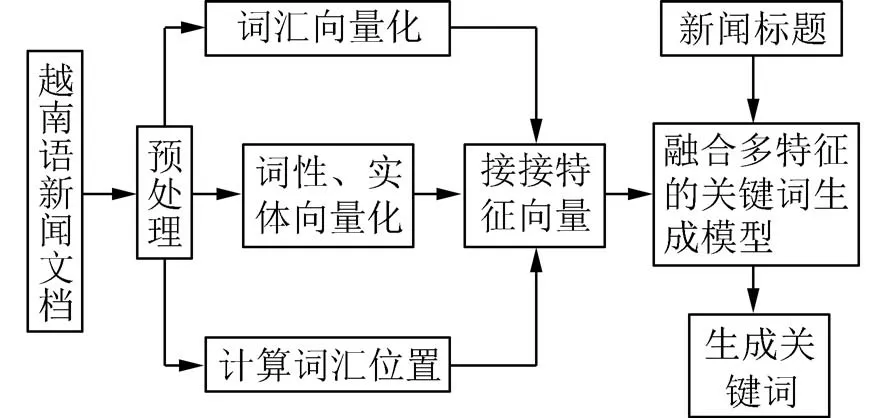
图3 越南语关键词生成框架Fig.3 The framework of Vietnamese keyphrase generation
2.2 融合越南语新闻特征的关键词生成本模型在输入层添加了一个拼接层,用于将原始词向量与词性、新闻实体、词汇位置等语言特征拼接后生成最终输入模型的词向量.原始向量进入特征拼接层,拼接层根据式(1)计算该文章中词汇的位置信息,将每个词汇的词性标记和新闻实体标记映射为词性嵌入和新闻实体嵌入.将每个词汇的词性嵌入、新闻实体嵌入、词汇位置l与原始词向量拼接在一起,最终构成一个512 维的向量
门控循环单元网络(Gated Recurrent Unit networks,GRU)单元结构[18]具有更新门和重置门,更新门决定是否使用候选隐藏状态来更新隐藏状态,重置门决定前一层的隐藏状态信息有多少被遗忘.计算公式如下:
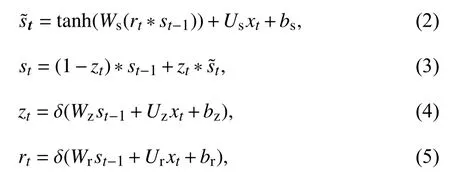
其中,*表示元素乘积,Wz和Wr分别更新门zt和重置门rt的权重矩阵,Ws为输出时的权重矩阵,xt为t时刻的输入向量,s˜t和st表示t时刻的候选状态和输出状态bs、br、bz为常数,δ 为sigmoid 激活函数.

其中,G 表示GRU 网络,xi和tj是第i个上下文词和第j个标题词的词向量,双向GRU 对应的最终隐状态由两个方向的隐状态拼接表示为hi=
标题对于生成能够准确描述文档的关键词提供了很好的参考信息.为了有效利用标题中的相关信息,我们采用了类似BIDAF[19]的双向注意力机制来建模标题与上下文的交互.对于每一个上下文词,标题可看作类似查询的输入.
双向注意力层的输入分别是上下文和标题的向量表征hi和qj.在这一层中,通过从上下文到标题以及从标题到上下文两个方向计算注意力.首先计算相似度矩阵S,计算公式如下:

其中,Sij表示第i个上下文词和第j个标题词的相似度,α 是一个可训练的标量函数,对其两个输入向量相似性进行编码,hi是H的第i个列向量,qj是Q的 第j个列向量.我们选择 α(H,Q)=其中“;”表示向量拼接,“ ◦”表示矩阵乘法,W(s)是可训练参数,T 表示转置.
(1)从上下文到标题的注意力:上下文到标题的注意力表示哪一个标题词与上下文词最相关.ai代表标题词与第i个上下文词的注意力权重,其中注意力的计算公式如下:

其中,softmax 为归一化指数函数,µi为归一化后上下文文本第i个词与标题文本中每一个词的相似度,ai为标题相对于上下文最重要的词加权求和后的注意力.
(2)从标题到上下文的注意力:标题到上下文的注意力表示哪一个上下文词与标题词最相关.注意力权重的计算公式如下:
补机(重联机车)自动制动手柄应用销子固定在重联位,单独制动手柄应放置在运转位。此位置为本机机车在运转位时,补机(重联机车)受机车间制动管软管、总风软管、平均软管压力控制,而发生作用的位置,其缓解应和本机同步。

其中,col(S)为相似度矩阵中相似度最大的列,v为归一化后标题词与最相关上下文词的相似度,hi为上下文向量,bi为上下文相对于标题最重要的词加权求和后的注意力.
最后,将上下文词向量和注意力向量组合在一起产生G=[g1,g2,···,gi],G的定义如下:

合并层对上下文向量hi和聚合相关标题信息的向量gi进行编码,最后得到融合标题信息的上下文表示,计算公式如下:

解码层使用了一个基于注意力的单向GRU[16]进行解码,计算公式如下:

其中,t=1,2,···,Ly,Ly是生成的关键词长度,et-1是第t-1 个预测关键词的词嵌入,e0是起始符的词嵌入,attn 代表注意力权重计算,tanh 是双曲正切激活函数,为融合标题信息和上下文信息的向量,ht为时间步长t的隐状态向量,为注意力向量,w为参数矩阵.
计算当前步骤在预定义词汇表v上的预测概率分布的公式如下:
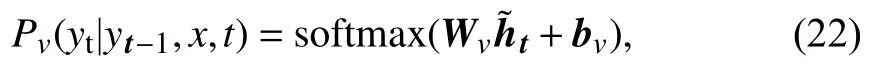
其中,Pv为关键词生成的概率,x为上下文序列,t为标题序列,yt−1=[y1,···,yt−1] 是先前的预测单词序列,bv∈R|v|是可训练的参数向量.
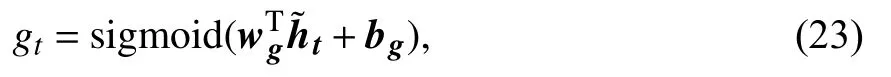
其中,sigmoid 为激活函数,wg和bg是可训练的参数.
接下来,gt用于确定是否将源文档中的单词复制为第t个目标关键词.gt对词汇分布和注意力分布进行加权平均,得到了扩展词汇表上的以下概率分布,使用Pv(yt)和P(yt)来分别表示Pv(yt|yt−1,x,t)和P(yt|yt−1,x,t),计算公式如下:
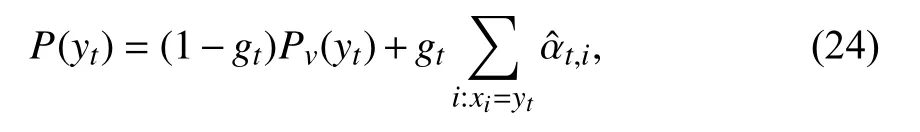
2.3 训练本模型选择负对数似然损失作为损失函数,计算公式如下:
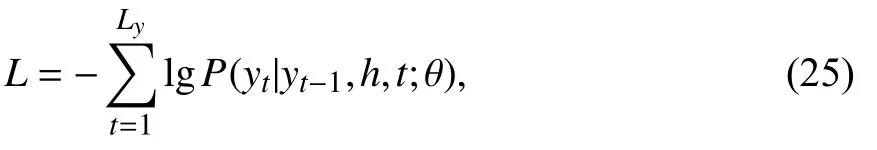
其中,Ly是目标关键词y的长度,yt是y中的第t个 词语,θ 代表所有可训练的参数.
2.4 关键词生成流程关键词生成流程如图4 所示,具体步骤如下:
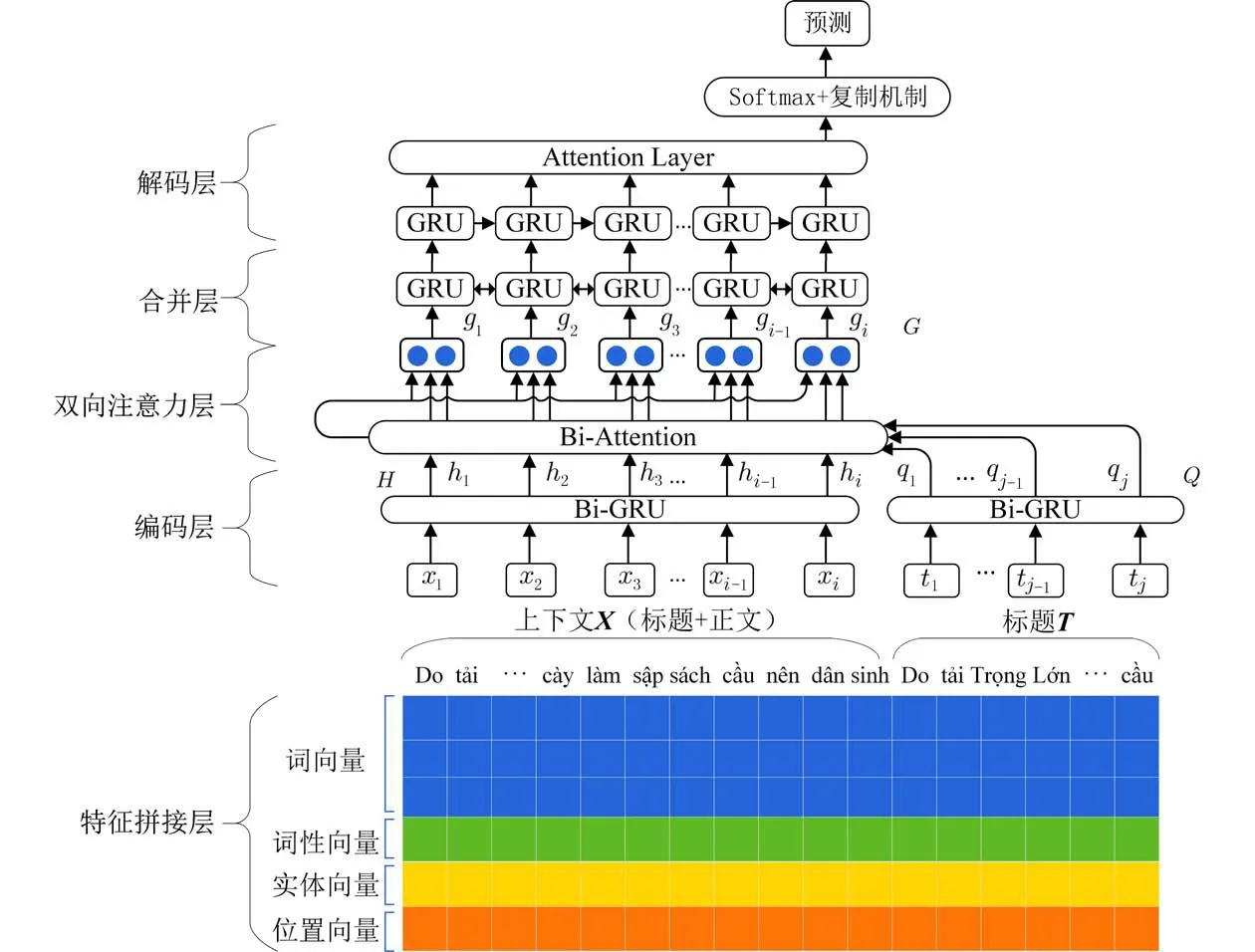
图4 越南语关键词生成流程Fig.4 The process of Vietnamese keyphrase generation
步骤 1读取越南语新闻文档,分为上下文(标题+正文)和标题信息.
步骤 2预处理.对越南语新闻文档进行分词,得到分词后的词汇表vocab,并为词汇表中的词生成词性标志和新闻实体标志.
步骤3 将词汇表中的词汇、词性标志和新闻实体标志向量化,获得原始词向量rw、词性标志向量rp和新闻实体向量rn,并根据式(1)计算词的位置特征值rl并拼接语言特征向量
步骤 4计算编码层、双向注意力层、合并层的隐藏状态,根据式(18)计算输出yt的概率,利用波束搜索算法选择top10 分数迭代预测关键词.
步骤 5输出最终关键词.
3 实验
3.1 数据准备我们从3 个具有高质量关键词的越南语新闻网站爬取了20 000 篇越南语新闻文档,新闻文档中的关键词由作者分配,但这样的新闻文档数量有限.经过数据清洗后,选择篇幅字数在200~450,关键词数量大于4 个的新闻文档,最终留下13 000 篇新闻.其中9 000 篇用作训练集,2 000篇用作验证集,2 000 篇用作测试集.验证集和测试集是随机选择的.具体数据如表2 所示.数据以json 的格式储存,每篇新闻包含3 个字段:{title,content,keyphrases}
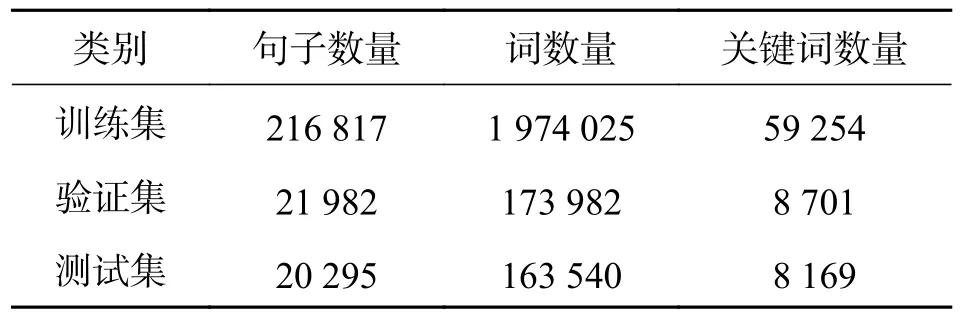
表2 越南语新闻关键词数据统计Tab.2 The statistics of Vietnamese news keyphrase dataset
参照文献[1]的方法对数据进行相同的预处理,并将所有数字替换为
3.2 实验设置在训练阶段,根据词频排序选择前50 000 个单词构成词表,词嵌入维度设置为100,隐藏层维度设置为256,λ 设置为0.5.除了h0初始化为GRU 单元的初始状态均为全零向量.标题、上下文和关键词共享嵌入矩阵,包括嵌入矩阵在内的所有可训练变量均以[−0.1,0.1]的均匀分布随机初始化.采用Adam 优化器[20],设置训练批次大小为64,初始学习率为0.001,dropout 率为0.1.最后使用波束搜索生成多个关键词,波束大小设 置为50,最大序列长度设置为40.
3.3 评价指标给定一篇越南语新闻文档,模型预测出n个关键词,最重要的词在第一位,按照重要性依次排列.本文采用准确率,召回率,F1 值作为评价指标.参与评估的关键词数量对评估的质量有着重要影响,通常选择前k个预测的关键词用于评估[21].F1 值是基于召回率和准确率来计算的,其中准确率定义为前k个预测正确的关键词的数量(M)与前k个预测关键词总数(K)的比值.召回率定义为前k个预测正确的关键词的数量(M)与参考标准关键词(ground truth)总数(N)的比值.预测得到的关键词准确度与F1 值呈正相关,如果模型预测出的关键词与参考标准关键词完全相同,F1值将接近1.
准确率P,召回率R和F1 值的计算公式如下:

3.4 实验设计与结果分析我们选择了具有复制机制的两个编码器−解码器模型作为CopyRNN 和CopyCNN 以及TG-Net 作为关键词生成任务的基准模型.
3.4.1 已出现的关键词预测 在越南语新闻关键词数据集上我们比较了不同基准模型在现有关键词预测的能力.表3 列出了每个模型的前5 个和前10 个预测的F1 值.

表3 在测试数据集上已出现的关键词预测结果Tab.3 Keyphrase prediction results that have appeared on the test dataset
本文提出的融合语言特征的模型与其他3 种模型相比,取得最佳性能.可以看出,融合词汇特征的模型在基于Seq2Seq 框架的基础上,增加词汇特征融合要比不融合词汇特征的模型在F1 值上的指标均有所提升.在越南语训练数据规模远小于原始实验中英语数据规模的条件下,CopyRNN、Copy-CNN 和TG-Net 性能直线下降,性能远低于在大规模英语数据集上训练的模型.说明在训练数据不足的情况下,普通RNN、CNN 网络已不再适用于关键词生成,由于TG-Net 利用标题等外部信息指导生成,一定程度上缓解了训练数据不足造成的影响.我们的模型比TG-Net 模型提高了13.2%(F1@10分数).与CopyRNN 和CopyCNN 相比,我们的模型分别提高了22.1%和20.7%(F1@10 分数).实验表明在标记数据不足的情况下,与不融合语言特征的模型相比,融合语言特征的模型能够有效利用文档中的特征信息,具有更好的关键词提取能力.
3.4.2 未出现的关键词预测 生成未出现的关键词是生成模型的基本特征,预测未出现的关键词需要理解上下文语义的能力.在这部分只考虑参考标准关键词(ground truth)中未出现的关键词和预测出的未出现的关键词用作评估.一般将前20 和前50 个预测关键词的召回率用于度量预测未出现的关键词准确度.表4 列出了每个模型的前20 个和前50 个预测的召回率.

表4 在测试数据集上未出现的关键词预测结果Tab.4 Keyphrase prediction results that did not appear on the test dataset
可以看出,我们的模型在越南语新闻关键词数据集上始终优于先前的序列到序列模型.与最佳模型TG-Net 相比,我们的模型性能提高了17.1%(R@50 分数).总体而言,结果表明我们的模型能够捕获上下文内容的底层语义.类似于已出现的关键词预测,融入词性、新闻实体、位置、标题等特征为未出现的关键词预测提供了显著的提升,这些特征有助于在解码过程选择合适的单词.删除复制机制不会影响预测未出现关键词的性能,这是因为复制机制只能选择输入文档中的单词,而这些单词不可能包含在未出现的关键词中.
3.4.3 消融实验 为了验证词性特征、新闻实体特征、位置特征融入词向量和利用双向注意力机制融入标题的效果,设置了消融实验.
从表5 中可以看出,与位置特征和新闻实体特征相比,融入词性特征更能提升生成关键词的准确率.相比较在词向量中融入新闻实体、位置和词性特征,利用双向注意力机制引入标题信息,能够使准确率更高.同时在词向量中融入新闻实体特征、位置特征、词性特征和通过双向注意力机制利用标题特征的方法取得了最好的效果.实验结果表明,对于像越南语等低资源语言训练样本不足的情况下,融入词特征可以提高关键词生成模型性能,而提出的融入多特征的越南语关键词生成模型达到了最好的效果.

表5 融入不同特征生成关键词效果对比Tab.5 The comparison of the effect of integrating different features for keyphrase generation
3.4.4 实例分析 为了说明我们所提出的模型与TG-Net 模型之间的生成关键词差异,表6 展示了从越南语新闻文档测试集中选择的一个例子.在这个例子中,一共有12 个参考标准关键词(ground truth).对于已出现的关键词(present keyphrases)预测,可以发现两个模型都能从标题中预测关键词奥地利企业)”,但是对于另外一个标题中的关键词越南投资机会)”,我们的模型能够成功预测,而TG-Net 只预测到该关键词的一部分越南)”.阮春福总理)”作为人名实体,TG-Net 无法预测该关键词.对于未出现的关键词(absent keyphrases)预测,注意到TG-Net不能预 测未出 现的关键词经贸关系)”,但我们的模型可以利用经济商业)”等名词成功生成未出现的关键词.总体来看,位于文章开始和结尾的关键词,我们的模型都能够成功预测,而TGNet 没有预测到位于文章结尾的关键词投资活动)”.这些结果表明了我们的模型能够有效利用越南语新闻标题、越南语词性、新闻实体、词汇位置等相关信息生成关键词,在已出现的关键词预测和未出现的关键词预测方面取得了更好的结果.但是由于本方法比较依赖词性标注和命名实体识别准确率,对于词性标注和命名实体识别方法准确度不高的其他小语种,例如泰语、老挝语、缅甸语,可能无法达到良好效果.

表6 越南语新闻关键词数据集下模型预测关键词结果对比Tab.6 The comparison of keyphrase prediction results of models under the Vietnamese news keyphrase dataset
4 结语
为了解决样本不足条件下生成越南语新闻关键词的准确性不高的问题,提出一种多特征融合的越南语关键词生成方法,提高了生成越南语关键词的准确率以及与越南语新闻文档的相关性.该方法在现有的标题指导的关键词生成网络中,利用双向注意力机制融入越南语新闻标题,有效挖掘出越南语新闻标题中的关键信息.所提出的方法能够结合越南语中越南语词性、新闻实体、词汇位置等特征以及越南语新闻标题中高度汇总的信息来指导关键词的生成,在越南语新闻关键词数据集上进行了实验和验证工作,结果表明,该方法对于生成已出现的关键词和未出现的关键词均具有显著优势,所提模型在F1@10 和R@50 分数的预测上,最多比TG-Net 提高了13.2%和17.1%.未来的主要工作如下:①探索利用越南语句法结构对关键词生成的影响;②将本模型扩展到越南语其他领域,例如越南语学术文档领域等;③考虑将该方法应用在更多的低资源语言上.
