基于客运大数据平台的铁路客流预测系统
2022-02-19卫铮铮单杏花王洪业吕晓艳张军锋
卫铮铮,单杏花,王洪业,吕晓艳,张军锋
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
客流预测是铁路路网规划、线路及场站设计、铁路运营等工作的重要基础[1]。客流预测研究领域有许多分支和分类,通常按预测对象的不同,将铁路客流预测划分为区域客流预测、线路客流预测和列车客流预测。
我国幅员辽阔、地广人多,铁路网纵横交错,铁路运营情况复杂,市场影响因素较多,客流预测工作难度较大。在铁路客流预测工作中,目前存在的主要问题有:
(1)影响铁路客流需求的因素较多,若仅运用铁路客运业务历史数据进行预测,当遇到客运需求出现较大变化的情况时,预测模型无法感知外部相关因素对铁路客流的影响,造成预测误差较大。
(2)针对不同的预测对象,一种铁路客流预测方法往往会得到不同的预测结果,没有哪一种预测方法适用于不同层面的铁路客流预测应用需求。实际应用中,从事客流预测业务的工作人员往往依赖直觉与经验,每一种预测方法对于不同使用者及不同预测业务,预测准确性会有很大的波动。
针对多层面、不同时期、不同类型的铁路客流预测应用需求,结合近几年的应用经验,提出铁路客流预测系统的总体架构、模型及铁路客流预测系统的基本功能,以利于为相关研究提供丰富、便利的数据资源和分析评价工具,基于统一的系统平台集成各类铁路客流预测算法模型,更好地满足中国国家铁路集团有限公司(简称:国铁集团)及各铁路局集团公司各类铁路客流预测业务需求。
1 系统建设目标
1.1 构建客流预测所需共享数据资源
在客运大数据平台支撑下,除了充分利用客运数据外,采集和整合影响铁路客流的其它相关数据,如舆情数据、天气数据、竞争市场的运力数据及价格数据等,为各类预测算法模型的应用提供丰富的数据资源和便利的数据处理环境。
1.2 建立精准的客流预测算法模型库
客流预测是做好开行方案、收益管理的基础,是做好铁路客运运营决策的重要基石。面向铁路多层面(国铁集团、铁路局集团公司、站段)、不同时期(即期、近期、中远期)、不同类型的客流预测业务需求,研究基于大数据技术的铁路客流预测方法和分析模型,构建较为完备的铁路客流预测算法库,逐步提高铁路客流预测准确性[2]。
1.3 建立客流预测测试环境与评价体系
为各类客流预测算法模型[3]提供便利的测试环境,可对预测算法模型的效果和适用性进行定量分析,建立客流预测结果分析评价体系[4],逐步形成预测方案应用规范、业务涵盖广泛、功能日趋完善的铁路客流预测系统。
2 总体架构
铁路客流预测系统由沙盘演练数据区与预测算法平台2 部分组成,其总体架构,如图1 所示。沙盘演练数据区以线下方式部署运行,主要是运用单机版的仿真平台、分布式在线算法库、分布式离线算法库,对客流预测方案进行测试和评估;通过沙盘演练数据区测试和评估的客流预测方案,经开发后集成到预测算法平台中,预测算法平台以线上方式部署运行。
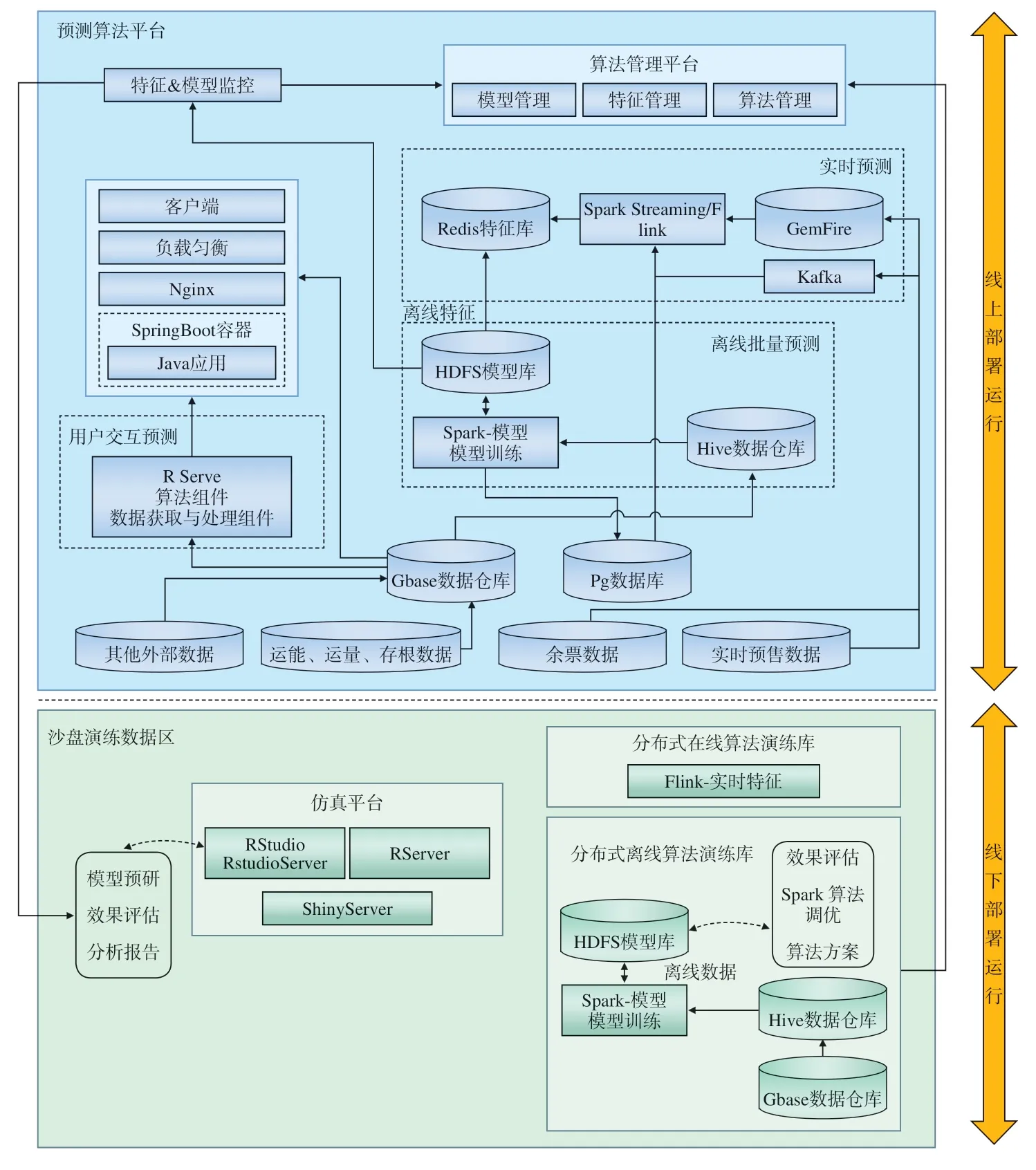
图1 客流预测系统总体架构示意
2.1 沙盘演练数据区
沙盘演练数据区主要包括仿真平台、分布式在线算法演练库(客流预测结果是通过在线运行算法模型即时计算得到)、分布式离线算法演练库(客流预测结果是通过离线运行算法模型计算生成,并存储在数据库中)。
其中,仿真平台基于RStudio 环境创建,运用R 语言编写的脚本来调用运行在RServer 上的客流预测算法组件,并运用ShinyServer 实现算法可视化,对预测效果进行评估,生成客流预测分析报告,用以确定最终的客流预测方案。
在分布式在线算法演练库中,预测算法所使用的训练数据是从相关业务系统中以切片为单位获取的实时数据,如客票营销系统中的余票数据、实时用户点击日志流数据等,运用实时大数据处理框架Storm,对这些预测算法组件进行实时演练。
分布式离线算法演练库基于Spark 大数据平台创建,运用SparkR、PySpark、Scala 改为分布式算法实现;在分布式离线算法演练库中,预测算法所使用的训练数据是从相关业务系统中获取的、以天为单位的时间切片数据,如客票营销系统中的运能、运量数据等。
2.2 预测算法平台
预测算法平台包含人机交互预测和定时批量离线预测2 类算法组件。
其中,人机交互预测算法组件采用R、Python、Java 语言开发,由前端应用模块使用Java 接口来调用。
定时批量离线预测算法组件的运行过程是:(1)由用户在数据维护模块中定义并设置好定时预测对象;(2)由Gbase 每天批量处理好预测算法所需运能、运量数据,并将数据推送到Hive 中;(3)由预测算法平台通过Spark 调用定时批量离线预测算法组件,对存储在Hive 中的运能、运量数据进行处理,生成的预测结果存储在HDFS 中;(4)预测算法平台从Kafka 消息队列读取余票数据及相关日志,将其交由Storm 进行实时处理,依据客票销售情况对预测结果进行修正。
3 功能设计
客流预测系统主要包括交互预测、批量预测、数据维护、预测方法评价、特征监控、系统管理6个功能模块。系统用户划分为超级用户和普通用户2 类;其中,超级用户可使用系统的所有功能,包括预测方法评价、批量预测、交互预测,以及数据维护、特征监控、系统管理等管理功能;普通用户只能使用交互预测、批量预测,以及数据维护功能,如图2 所示。
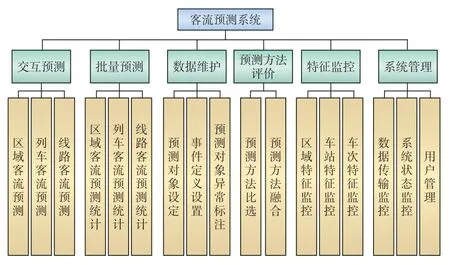
图2 客流预测系统功能结构
3.1 交互预测
按照不同的客流预测对象类型,交互预测分为3 类:区域客流预测、列车客流预测和线路客流预测;用户通过操作界面选择客流预测对象类型,系统处理后返回预测结果。
(1)区域客流预测
区域客流预测是对指定区域范围内的整体,或区域范围内指定起点与终点(OD,Origin to Destination)间的客流情况进行动态分析预测的过程和结果。
(2)列车客流预测
列车是指载客列车的整体,或者OD 间运载旅客的列车车次;对列车整车客流或指定列车某个OD的客流进行动态预测和展示。
(3)线路客流预测
对指定线路上的站到站进行动态客流预测和展示。
3.2 批量预测
批量预测的预测对象分为铁路局、站段和车站3 类,用户可在数据维护模块的操作界面中选择预测对象类型,并设置更新频率,系统按照用户设置定时进行离线批量预测。
(1)区域客流预测统计
对指定区域的客流预测结果进行统计分析和展示。
(2)列车客流预测统计
对指定列车的客流预测结果进行统计分析和展示。
(3)线路客流预测统计
对指定线路的客流预测结果进行统计分析和展示。
3.3 数据维护
用户可在数据维护模块中选定预测对象、完成事件定义和标注数据异常。
(1)预测对象设定:设置系统进行批量预测的预测对象;
(2)事件定义设置:设置事件的类型、发生时间,便于预测和分析事件对客流的影响;
(3)预测对象异常标注:对预测结果误差较大的预测对象进行标注,便于后续持续优化客流预测。
3.4 预测方法评价
(1)预测方法比选:对于相同的预测对象,采用不同的预测方法可能得到不同的预测效果。针对某一种预测对象,选用多种预测算法模型,通过历史数据进行预测处理,比较这些预测算法模型的应用效果,选择出最适用于这种预测对象的预测方法。
(2)预测方法融合:针对某一类预测对象,尝试组合运用多种预测方法,探索适用于这类预测对象的融合方法。
3.5 特征监控
分别对预测对象在区域、车站、车次的特征进行抽取和分析,对这些特征进行监控;若模型所涉及的特征有明显变化,需及时对模型进行调整。
3.6 系统管理
提供监控系统运行状态、管理用户及权限的工具,确保系统能够稳定、可靠、安全地运行。
(1)数据传输监控:监测系统数据传输是否正常、客运基础数据是否在客运大数据平台中成功生成,发现异常时告警提示。
(2)系统状态监控:监测系统主要组件、功能模块、任务等运行状态是否正常,发现异常时告警提示。
(3)用户管理:创建用户,指定用户可查看的客流预测结果的范围。
4 客流预测处理流程
4.1 客流预测处理流程分类
按照数据处理流程的共性和差异,客流预测处理流程可划分为2 大类:站站/车车预测和同一类站、车预测,如图3 所示。
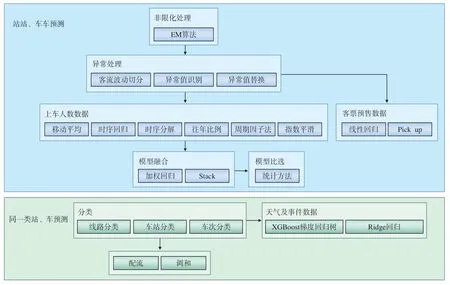
图3 客流预测处理流程分类
4.1.1 站站/车车预测
站站/车车预测,就是各个维度的客流预测对象的训练数据以该预测对象的历史数据为选取对象,所对应的预测对象满足历史数据的累积要求,通常历史数据至少累积1 年以上。具体过程为:
(1)对原始客流数据进行非限化处理,然后分析客流波动,将各维度预测对象的客流波动进行切分,对一年中平稳时段和非平稳时段进行时间点分割;
(2)分别对各时段的数据进行异常值识别,并将识别出来的异常值以某一统计量进行替换;
(3)将处理后的数据作为图1 中各种算法组件的输入;其中,以上车人数为训练数据的算法模型主要有移动平均、时序回归、时序分解、往年比例、周期因子法、指数平滑、加/乘法模型[5];以预售数据为训练数据的算法模型主要有线性回归、Pick up(增量预测);
(4)运用加权回归、Stack 方法[6],对由上述2种算法模型处理得到的预测值进行融合,最终得到更为稳定、精确的预测结果,或在线下采用模型比选的方式,选出最为精确的预测结果。
4.1.2 同一类站、车预测
同一类站、车预测:各个维度的客流预测对象的训练数据以该对象的同一类的历史客流数据为对象,对其进行预测。这类预测适用于预测对象的历史数据累积少于半年或缺少历史数据的情况,如新设立站点或新开列车。
这类预测根据客流特征及线路、车站、车次在业务上的特征进行分类,将天气数据及事件数据引入到模型中,运用XGBoost、Rigde 回归[7]等算法解决受极端天气或特定事件因素影响的客流预测问题。当受调图影响时,新的列车或新开的站运用配流、调和的方法对其进行预测,调整。
4.2 客流预测数据处理的基本流程
客流预测数据处理的基本流程,如图4 所示。
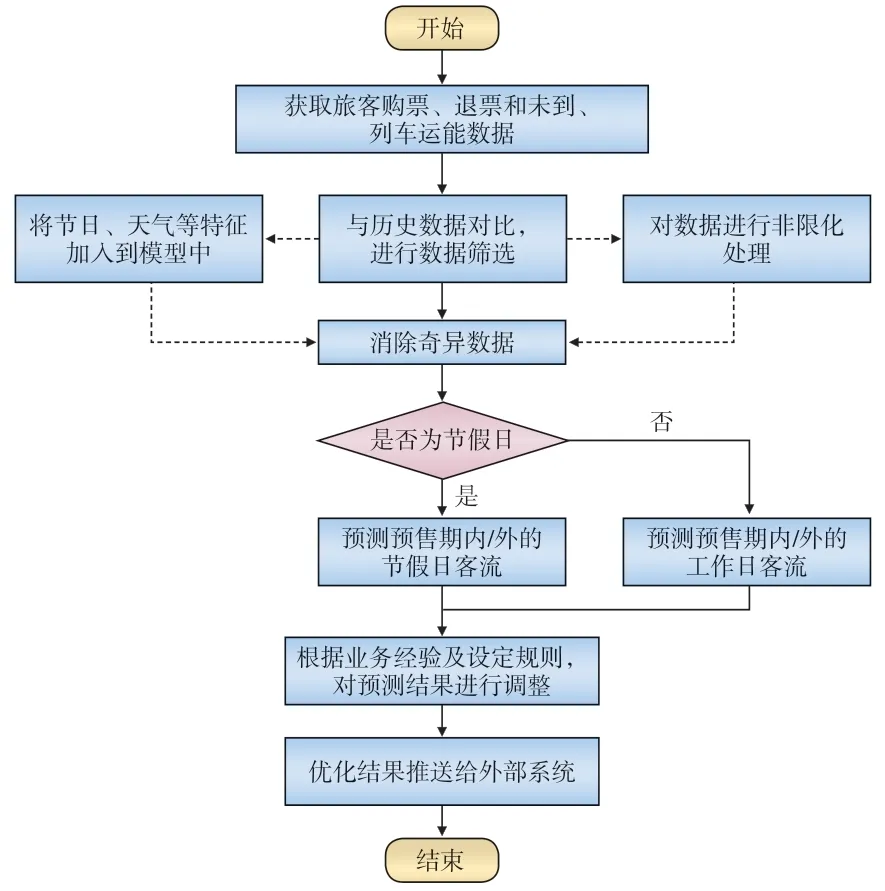
图4 客流预测数据处理基本流程示意
针对不同维度的客流预测,如发送量[8]、线路OD、车次、车次-OD,基本的数据处理流程为:
(1)从数据仓库中抽取运能、运量数据,将节日、天气、事件等特征加入到客流预测模型中,利用客流历史数据对客流预测模型进行对比筛选,然后再加入数据非限化处理,将需求受限的数据还原为需求数据的估计。
(2)对节假日、普通工作日的客流数据进行建模,分别对这2 类不同时间段的建模数据进行异常值识别、替换。
(3)判断预测时段是否为节假日;若为节假日,对进入预售期的客流和预售期之外的客流,分别使用节假日的历史客流数据、客票预售数据进行预测;若为工作日,对进入预售期的客流和预售期之外的客流,分别使用工作日的近期及同期历史客流数据、客票预售数据进行预测。
(4)运用业务经验以及相应规则,对预测结果进行修正,以适应业务应用需求。
5 结束语
针对多层面、不同时期、不同类型的铁路客流预测业务需求,依托铁路客运大数据平台,构建铁路客流预测系统,能够在同一系统平台上完成客流预测方案的测试、评价和规范化应用。基于分布式算法库,充分利用历史售票数据,并考虑年度、季节、星期、时间、节假日、重大事件、天气等各类影响因素,提供不同角度、不同粒度、不同时期的客流预测功能,根据线路性质(客运专线、既有线)、列车性质(动车、普通旅客列车)进行客流预测,支持人机交互预测和定时批量离线预测2 种应用模式,可为各类客运业务分析人员提供定制化客流预测数据,为票额智能预分、列车开行方案设计等客运业务提供准确、可靠的决策依据。
2019 年以来,铁路客流预测系统已在多个铁路局集团公司技术科及客运部开展实际运用,系统运行稳定,对未来客流变化情况预测准确度较高,且可根据实时客运数据,对客流预测结果进行即时更新和校正,为列车开行及调整、票额预分发挥了重要的指导作用。
