基于交互式叠加注意力网络的实体属性情感分类
2022-02-19周纯洁杨晓宇
周纯洁 黎 巎 杨晓宇
1(北京联合大学北京市信息服务工程重点实验室 北京 100101) 2(北京工商大学国际经管学院 北京 100048) 3(中国科学院地理科学与资源研究所资源与环境信息系统国家重点实验室 北京 100101)
0 引 言
近年来,随着互联网和社交网络的快速发展,越来越多的用户开始在网页上自由表达自己的观点。用户评论的大数据是在互联网上产生的,这些评论传达了互联网用户对产品、热点事件等的看法。随着评论的爆炸性增长,很难手动分析它们。在大数据时代,通过人工智能技术挖掘评论文本的情感倾向有助于及时了解网络舆情。情感分类的研究对于获取评论的情感趋势非常有意义。
Liu[1]将情感分类大致分为三类:篇章级、评论级和属性级情感分类。篇章级和评论级情感分类旨在将整个篇章或者评论作为一个整体,识别出整个篇章或评论的情感倾向。属性级情感分类旨在分析出篇章或评论中具体实体及其属性的情感倾向。例如,“I bought a mobile phone, its camera is wonderful but the battery life is short”中有三个属性“camera”“battery life”和“mobile phone”。其中:评论者对属性“camera”表达了积极的情感;对属性“battery life”表达了消极的情感;对实体“mobile phone”表达了混合的情感[2]。
属性级情感分类任务一般被分为两个步骤进行处理,其一为提取评论中的属性,其二为对提取到的属性进行情感分类。由于这两个步骤均存在诸多难点,因此研究者们将这两个步骤分开进行研究,本文主要研究的是步骤二。
属性级情感分类区别于篇章级和评论级情感分类的一个难点在于需要将评论中的属性与修饰属性的情感正确对应起来,因此该任务的重点在于挖掘属性与上下文的关系,实现精准定位与属性情感相关的文本片段,根据情感文本片段判断属性的情感[3]。
本文研究使用神经网络处理属性级情感分类任务下的属性与上下文特征提取及关联问题,并构建了BERT-LSTM-IAOA模型,以期提高属性级情感分类的准确率和F1值。
1 相关工作
属性级情感分类的处理方法包括基于规则的方法[4]、基于统计的方法[5]、基于传统机器学习的方法[6-7]和基于神经网络的方法等。基于神经网络的方法具有领域适应性较强,无需密集特征工程的优点,近年来得到了快速发展并成为了主流方法。
RNN系列神经网络能保存文本中单词的序列关系,因此成为了文本处理领域的热门神经网络模型。使用LSTM网络提取整条评论的特征表示作为评论中属性的情感特征表示不足以区分多属性评论中不同属性的情感。Tang等[8]最先将LSTM网络应用于属性级情感分类任务,提出以属性为中心将整个评论分为“上文+属性”和“属性+下文”两部分,在这两部分的每个单词向量后拼接属性平均词向量作为输入,用LSTM网络分别提取这两部分的特征,最后拼接两个LSTM网络的输出作为这个属性的情感特征表示。随后,Zhang等[9]基于GRU网络设计了一种门控机制刻画属性与上下文的关系,该机制根据属性所在位置的隐藏状态信息控制左右上下文信息的输入。上述模型利用多属性评论中每个属性有不同上下文的特点控制模型的输入,在一定程度上提升了分类准确率。
将注意力机制添加到基于神经网络的模型能提高大多数模型的性能,该方法已成功应用于许多自然语言处理任务[10]。Wang等[11]将注意力机制添加到基础LSTM模型中,该方法通过将平均属性词向量拼接到评论中每个单词的词向量上,使属性能够参与计算注意力权重。Wang等[12]在Tang等[8]以及Wang等[11]的基础上,引入评论中各个单词对属性的依赖关系信息,进一步提高了分类效果。以上模型的提出,表明了注意力机制与神经网络模型结合应用于属性级情感分类任务的有效性。
Ma等[13]运用注意力机制交互学习上下文和属性的特征,对属性和上下文进行了独立的特征表示。Huang等[14]提出的LSTM-AOA模型对属性和上下文进行联合注意力建模,通过注意力叠加的方式获得上下文的特征表示,该方法在未利用独立属性特征表示的情况下就取得了优于以上模型的效果。
Wang等[15]发现当上下文中单词的情感对给定属性敏感时,仅通过注意力建模无法解决情感分类性能下降的问题。如“屏幕分辨率很高”和“价格很高”,其中“高”在修饰屏幕分辨率时表达了积极的情感,在修饰价格时表达了消极的情感,因为不像“优秀”“劣质”这类词语本身就带有明确的情感,“高”本身不带有明确情感,需要与具体属性结合才能分析出其情感。因此,对属性进行单独建模,并运用属性特征辅助分类值得关注。
在基于神经网络的属性级情感分类任务中,词向量的表示是该任务的基础,以上基于神经网络的属性级情感分类模型使用的词向量均为静态词向量。静态词向量表示将单词映射为一个固定维度的向量,无法解决文本中一词多义的问题。如“saw”能表示“看见”和“锯子”这两个完全不同的意思,用同一个向量表示这两个意思显然是不合理的。Devlin等[16]提出的BERT预训练语言模型,能根据单词的上下文对同一单词生成不同的词向量表示。
本文针对属性级情感分类任务的以上问题,提出一种基于交互式叠加注意力网络进行实体属性情感分类。主要贡献如下:首先,用动态词向量表示模型BERT代替静态词向量表示模型Glove,弥补静态词向量表示存在的一词多义缺陷;其次,对属性与上下文都进行特别对待,通过交互学习生成其各自独立的特征表示,并在交互学习的过程中使用叠加注意力(AOA)代替普通注意力以挖掘属性与上下文之间深层次的语义关系。在三个基准数据集上的实验结果表明,本文提出的模型在属性级情感分类任务上的效果更好。
2 BERT-LSTM-IAOA模型
图1为本文提出的BERT-LSTM-IAOA模型的整体结构,整个模型分为四层。第一层为BERT词向量层,属性和上下文通过词向量层得到属性词向量序列和上下文词向量序列。第二层为LSTM层,属性和上下文词向量序列通过前向LSTM进行进一步语义编码。第三层为AOA层,在该层计算得到属性和上下文各自的“最终”注意力权重。第四层为输出层,将上下文“最终”注意力权重与上下文的隐藏语义状态做加权和得到上下文的最终特征表示,将属性“最终”注意力权重与属性的隐藏语义状态做加权和得到属性的最终特征表示,拼接上下文和属性的最终特征表示并将其输入到一个线性层中,最后使用Softmax计算属性所属的情感类别。
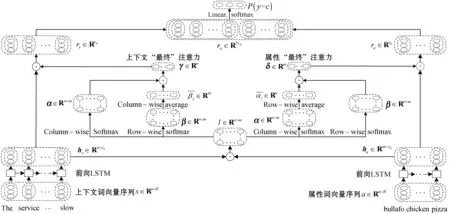
图1 BERT-LSTM-IAOA模型
2.1 任务定义
对于一条评论{w1,w2,…,wi,…,wr,…,wp},评论中有一个或者多个属性。评论中的一个属性{wi,wi+1,…,wi+q-1}是评论的一个子序列,属性级情感分类任务即分析论者对评论中某一特定属性表达了怎样的(积极的、中性的或消极的)情感。
2.2 评论预处理
将评论中待判断情感的一个属性用特殊符号“$T$”代替,经过该处理后得到这个属性的上下文s={w1,w2,…,wa,…,wp}。
2.3 BERT词向量层
通过BERT词向量层将属性和上下文词序列中每个单词映射为词向量。在词嵌入映射操作后,得到两组单词向量[vi,vi+1,…,vi+m-1]∈Rm×W和[v1,v2,…,vn]∈Rn×W,分别用于表示属性和上下文,其中W是词嵌入维度。
2.4 LSTM层
通过BERT词向量层获得单词的向量表示后,使用前向LSTM网络学习属性和上下文中单词的隐藏语义。使用LSTM的优势在于它可以避免梯度消失或爆炸的问题,并且善于学习长期依赖[17]。
将上下文词向量序列[v1,v2,…,vn]输入到前向LSTM中会生成一系列隐藏状态向量hs∈Rn×vh,其中vh是隐藏状态的维数。
(1)
将属性词向量序列[vi,vi+1,…,vi+m-1]输入到前向LSTM中会生成一系列隐藏状态向量ha∈Rm×vh,其中vh是隐藏状态的维数。
(2)
2.5 AOA层
通过AOA层获得属性和上下文中每个单词的“最终”注意力权重。AOA网络的叠加注意力机制能挖掘属性和上下文之间深层次的语义关系。
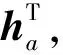
(3)
普通的获取上下文“最终”注意力权重的方式是假定属性中的每个单词对上下文注意力权重的影响是相同的,即通过式(4)得到上下文的“最终”注意力权重γ∈Rn,其中γi为上下文中第i个单词的“最终”注意力权重。
(4)
然而,我们很容易知道单词“picture”在属性“picture quality”中扮演着比“quality”更重要的角色,因此,在计算上下文“最终”注意力权重时,需要获得属性中每个单词对上下文不同的影响力权值,此即AOA网络的叠加注意力思想。
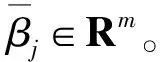
(5)
(6)
AOA网络中上下文的“最终”注意力权重γ∈Rn由式(7)计算出来。
(7)
属性级情感分类研究已经认识到了属性信息的重要性,并提出了各种方法用于通过生成属性特定的表示来精确地建模上下文,但是这些方法往往缺乏对属性的单独建模,尤其是通过上下文建模属性的特征表示。
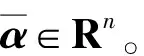
(8)
AOA网络中属性的“最终”注意力权重δ∈Rm由式(9)计算出来。
(9)
2.6 输出层
将AOA模块的属性“最终”注意力权重与属性隐藏语义状态做点积,上下文“最终”注意力权重与上下文隐藏语义状态做点积,拼接两个点积的结果得到r,将r作为最终的分类特征。
(10)
把r输入到一个线性层中,实现将r投射到目标类别的空间C={positive,negative,neutral}中。
x=Wl·r+bl
(11)
式中:Wl和bl分别是权重矩阵和偏差。在线性层之后,使用Softmax层来计算属性的情感极性为c∈C的概率如下:
(12)
属性的情感极性最终取决于预测出的概率最高的标签。用L2正则化训练本文的模型来最小化交叉熵损失。
(13)
式中:I(·)为指示函数;λ是L2正则化参数;θ是LSTM网络和线性层中的一组权重矩阵。模型中使用dropout随机丢弃LSTM单元的部分输入。
本文使用带有Adam[18]更新规则的小批量随机梯度下降来最小化模型中关于权重矩阵和偏差项的损失函数。
3 实验及结果分析
3.1 实验数据
本文采用的数据有Twitter数据集[19]和SemEval2014 Task4的竞赛数据集[20](包含Restaurant和Laptop两个数据集)。数据集中评论对属性表达的情感包含积极、中性和消极三类。表1给出了本文实验所用数据的具体情况。
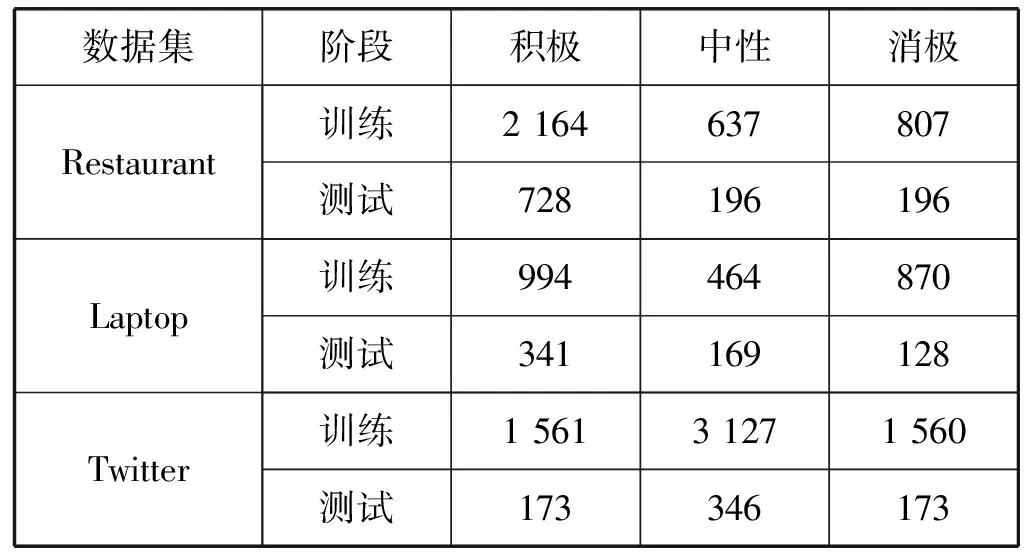
表1 实验数据统计
3.2 实验环境
实验环境如表2所示。
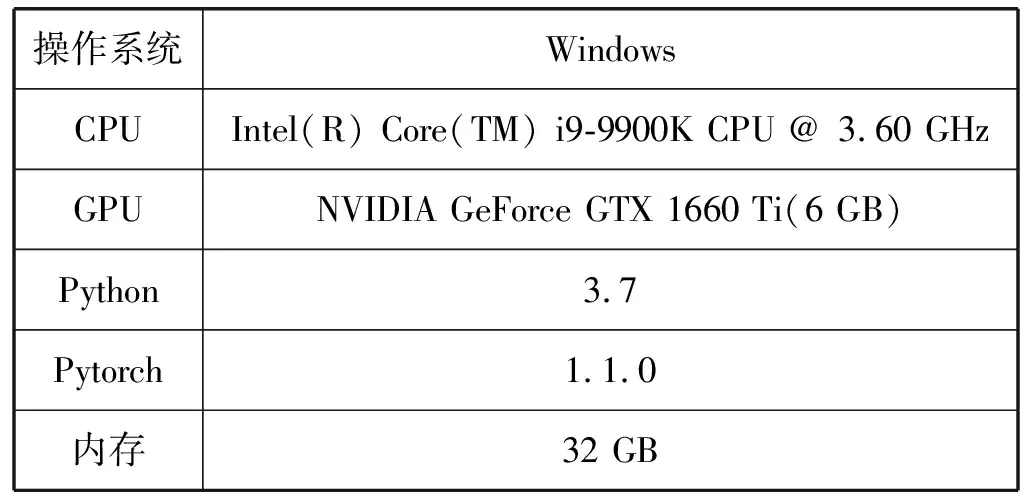
表2 实验环境
3.3 实验参数设置
本文使用谷歌官方提供的“BERT-Base,Uncased”预训练模型。句子中使用的BERT词向量维度为768,前向LSTM的层数为1层,epoch为10,batchsize为10,L2正则化项的权重为0.01,dropout为0.1,Adam优化算法的学习率为2×10-5。
3.4 实验对比
将本文提出的BERT-LSTM-IAOA模型和基线模型在3个不同领域的数据集上进行实验结果比较,结果如表3所示。
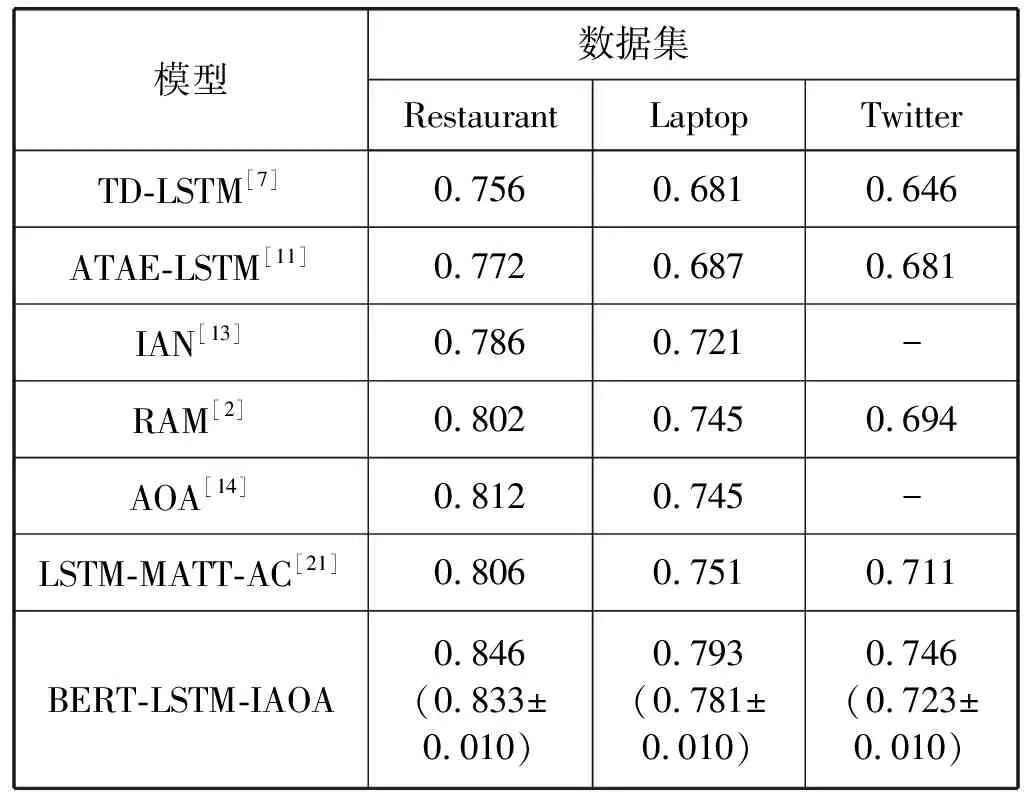
表3 与基线模型在情感三分类任务中的分类准确率对比
(1) TD-LSTM(Target-Dependent LSTM)。通过前向和反向LSTM网络分别编码属性的上文和下文,融合两个LSTM隐藏层的输出用于预测属性的情感极性。
(2) ATAE-LSTM(Attention-based LSTM with Aspect Embedding)。在标准LSTM中引入基于属性向量的注意力机制,并将属性向量连接到上下文单词向量上,让模型在LSTM编码过程中学习更多与属性相关的语义特征信息。
(3) IAN(Interactive Attention Networks)。在标准LSTM基础上运用注意力机制交互学习上下文和属性的特征,再融合上下文和属性的特征用于分类。
(4) RAM(Recurrent Attention Memory)。首先用一个堆叠的双向LSTM生成外部记忆矩阵,然后根据句子中单词和属性之间的距离信息为每个单词产生的记忆片段分配一个不同的位置权重,最后用GRU网络实现多层注意力机制并将不同注意力层级之间的结果进行非线性组合,以此形成属性的情感特征表示。
(5) AOA-LSTM(Attention-Over-Attention LSTM)。在标准LSTM基础上,通过计算基于上下文的属性注意力(text-to-target)和基于属性的上下文注意力(target-to-text)得到上下文的深层次特征表示,用于进行属性情感分类。
(6) LSTM-MATT-AC。将LSTM与内容注意力、位置注意力和类别注意力结合起来,有利于从多个方面学习句子中特定属性的情感特征。
(7) BERT-LSTM-IAOA。即本文模型。
神经网络模型的实验结果会因为不同的随机初始化值而波动是训练神经网络时众所周知的问题[22],因此本文运行10次模型算法,报告最优准确率(平均准确率±标准差),本文模型在三个数据集上的最优准确率分别达到84.6%、79.3%和74.6%,较基线模型中分类效果最好的模型在准确率上分别提升了0.040、0.042和0.035,验证了本文模型在不同领域数据集上进行属性级情感分类的有效性。
(1) BERT对三分类结果的影响。词向量的表示是属性级情感分类任务的基础,BERT预训练语言模型能解决静态词向量表示中存在的一词多义问题。通过在词向量层分别使用Glove映射的静态词向量表示和BERT映射的动态词向量表示,对比分析BERT词向量表示方法对属性分类效果的影响,实验结果如图2和图3所示。
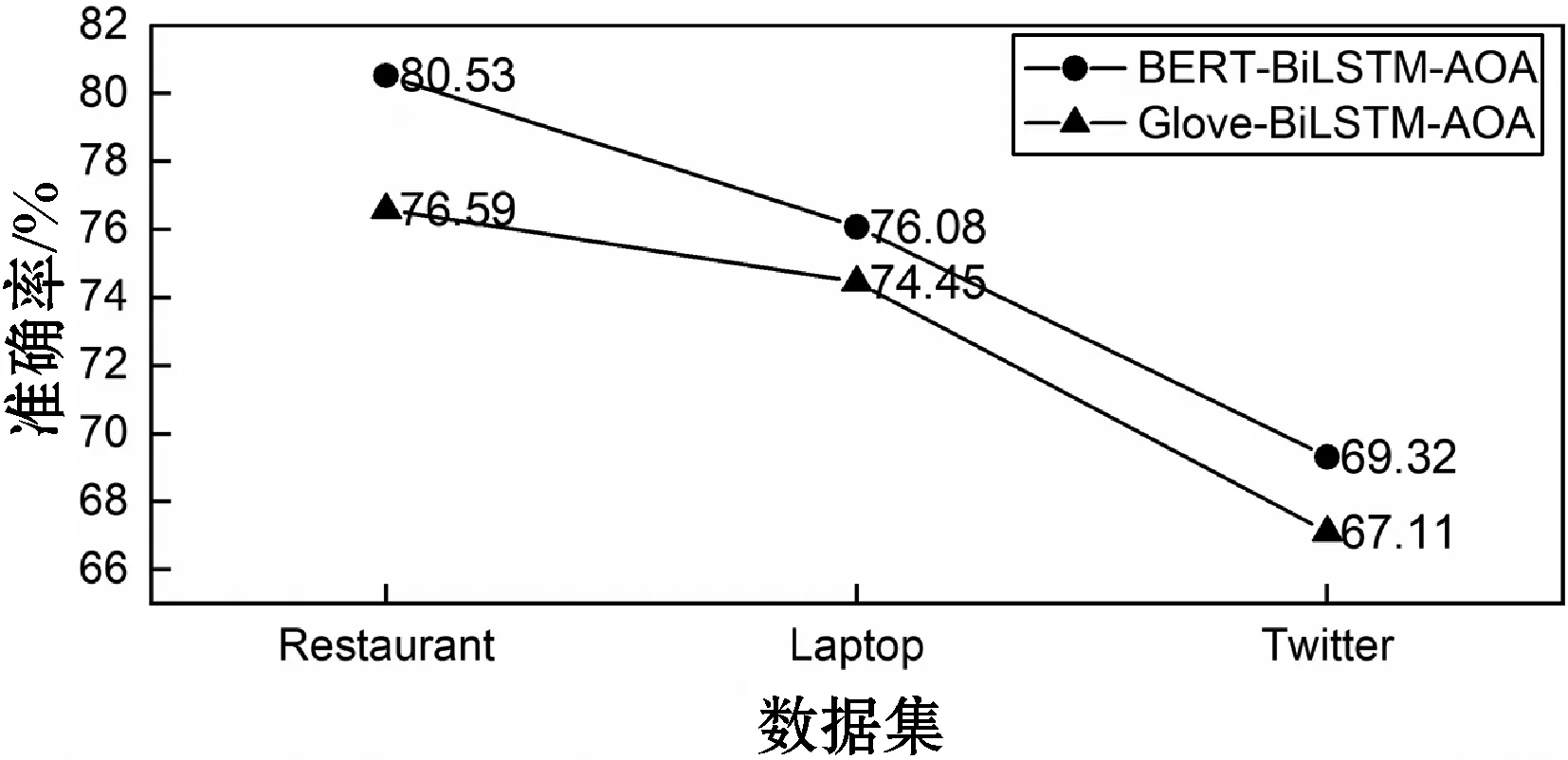
图2 不同词向量表示方法对模型准确率的影响
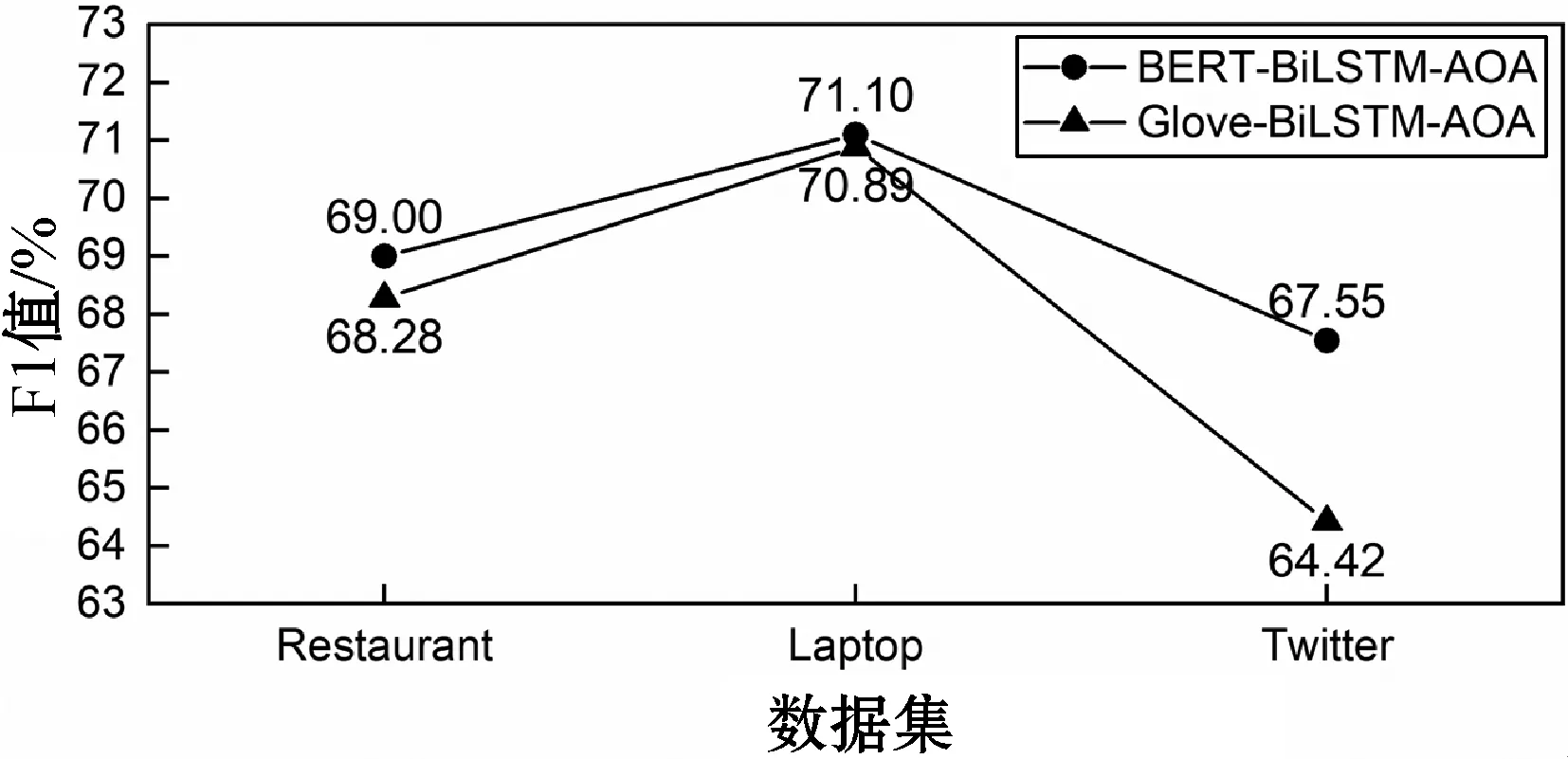
图3 不同词向量表示方法对模型F1值的影响
图2和图3分别对比了使用BERT词向量表示的BERT-BiLSTM-AOA模型和使用Glove词向量表示的Glove-BiLSTM-AOA模型的两个评价指标(准确率和F1值)。两个模型在Restaurant、Laptop和Twitter三个数据集上分别进行10次实验,对10次实验的结果取平均值。可以看到在模型中使用BERT预训练语言模型较使用Glove在三个数据集上的分类准确率分别提高了0.039、0.016、0.022,F1值分别提高了0.007、0.002、0.031。实验结果表明在本文属性级情感分类模型的词向量层使用BERT预训练语言模型比静态词向量表示模型能得到更好的分类效果。
(2) 属性单独建模对三分类结果的影响。属性信息是属性级情感分类任务中与属性上下文同样重要的信息,先前的研究大多忽略了对属性的单独建模。通过在模型中加入与不加入属性的单独建模表示,分析属性的单独建模对分类效果的影响,实验结果如图4和图5所示。
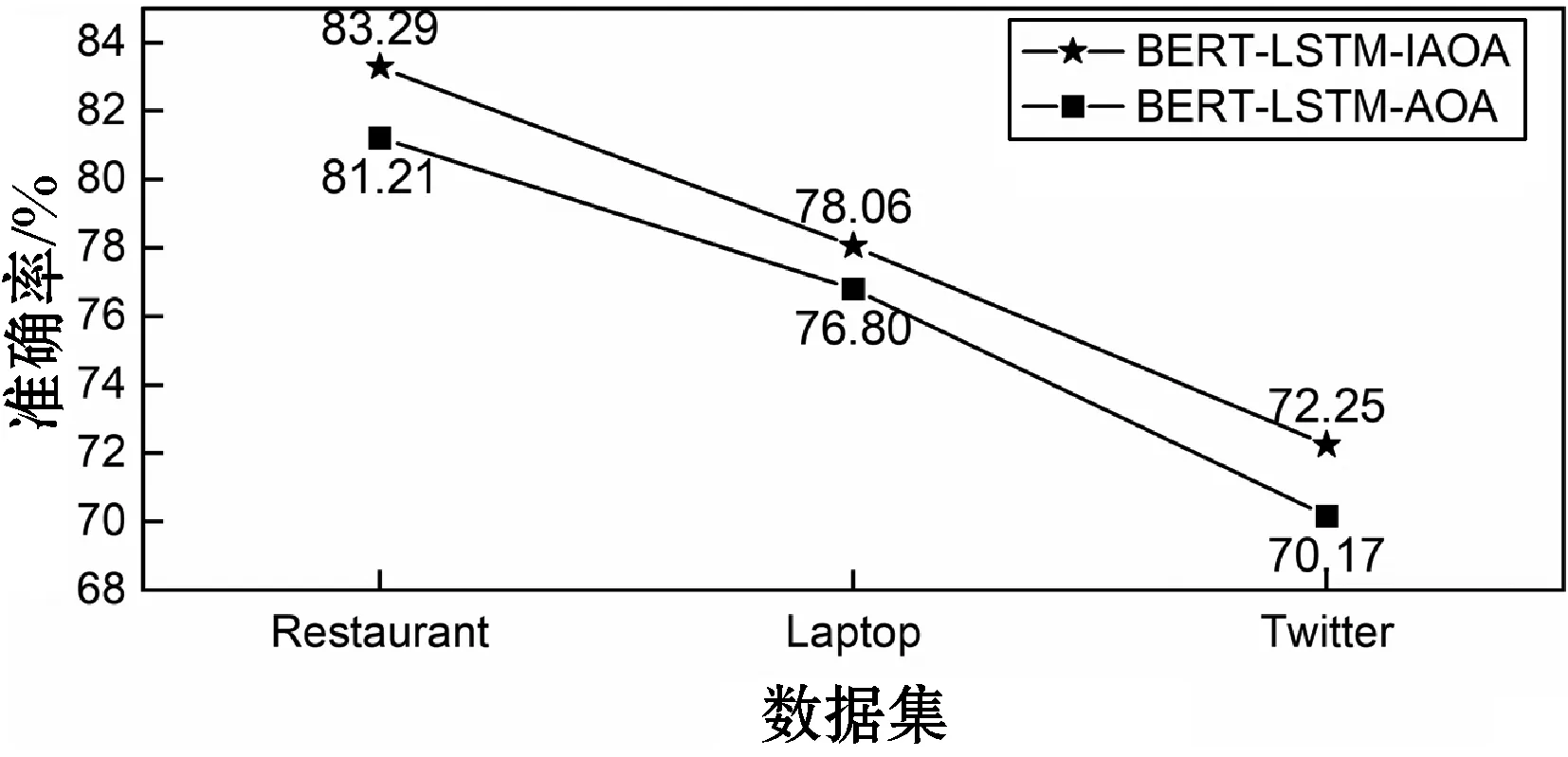
图4 属性单独建模对模型准确率的影响
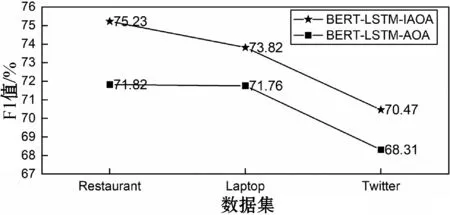
图5 属性单独建模对模型F1值的影响
图4和图5分别对比了对属性进行单独建模的BERT-LSTM-IAOA模型和未对属性进行单独建模的BERT-LSTM-AOA模型的两个评价指标(准确率和F1值)。两个模型在Restaurant、Laptop和Twitter三个数据集上分别进行10次实验,对10次实验的结果取平均值。可以看到BERT-LSTM-IAOA模型在三个数据集上分类准确率较BERT-LSTM-AOA模型分别提高了0.021、0.013、0.021,平均F1值分别提高了0.034、0.021和0.022。实验结果表明,对属性进行单独建模提高了属性级情感分类效果。
4 结 语
本文首先使用BERT预训练语言模型生成单词的词向量表示,弥补静态词向量表示存在的一词多义缺陷。其次,对属性和上下文都进行特别对待,通过交互学习生成其各自独立的特征表示,在交互学习的过程中使用叠加注意力AOA代替普通注意力以挖掘属性与上下文之间深层次的语义关系。最后,拼接属性和上下文的特征表示进行分类。本文的一系列实验结果表明这种改进方法能有效提高属性级情感分类的效果。
