基于注意力机制的双编码器代码注释生成
2022-02-18董传珂赵逢禹
董传珂,赵逢禹,刘 亚
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
给软件代码添加注释可以帮助开发人员更有效地理解相关代码背后的语义,有利于提升代码的可读性和软件的可维护性,减少维护成本[1].然而由于项目进度紧迫等原因,许多项目中的代码注释通常质量很低,注释不能清楚描述代码功能[2].自动生成代码注释不仅可以节省开发人员编写注释的时间,而且还有助于理解源代码.目前,在自动生成代码注释方面已经进行了很多研究,提出了基于注释模板[3,4]的方法和信息检索IR(Information Retrieval)[5,6]的方法.文献[3]使用SoftwareWord模型创建基于规则的模板,并使用该模板生成Java方法的自然语言注释.信息检索方法通常从相似的代码片段中搜索注释实现注释迁移.文献[5]应用代码克隆检测技术找到相似的代码片段,并复制相似代码片段中的注释到目标代码中.然而由于模板方法过于死板,生成的注释包含信息有限,而信息检索通过注释迁移实现相似代码注释,生成的注释质量高低取决于代码相似度量的精确度与待检索数据集中的注释完备性,会因代码相似度量不准或检索数据注释不完备而无法生成好的注释[7].
随着软件工程和人工智能领域的结合,人们将神经机器翻译模型NMT(Neural Machine Translation)引入到代码理解任务中[8].文献[8]使用循环神经网络RNN(Recurrent Neural Network)作为编码器直接对代码序列进行编码得到其中间向量,再利用解码器将中间向量翻译为代码注释,并引入注意力机制.然而由于代码不同于一般的文本,它拥有更多的结构信息,语义理解非常复杂,机器翻译从代码序列到注释序列的过程丢失了太多的代码内在信息,导致无法准确理解语义信息而生成注释效果较差.为了提取代码语义信息,研究人员提出了基于抽象语法树的代码语义提取方法.文献[2]通过遍历抽象语法树AST(Abstract Syntax Tree),将树结构转化为节点的线性序列,以长短期记忆神经网络LSTM(Long-Short Term Memory)作编码器和解码器生成代码方法的注释.文献[9]基于代码片段的抽象语法树遍历生成token序列,使用单层门控循环单元神经网络GRU(Gated Recurrent Unit)作编码器和解码器生成代码块的注释.文献[10]基于代码方法将抽象语法树两个叶子节点之间的路径处理成序列向量,以双向长短期记忆神经网络BiLSTM(Bi-directional Long-Short Term Memory)作编码器对路径序列建模,以LSTM作解码器,解码的每条路径对应一个注释中的单词.使用抽象语法树比单纯地使用代码序列增加了结构信息,但还是丢失了数据流、代码执行路径等信息,如变量在代码中的变化过程只从树结构中不能清晰地体现出来.
针对代码序列无法包含语义信息和抽象语法树结构丢失部分语义信息问题,本文提出引入代码图结构生成代码注释的方法.以机器翻译框架NMT为基础,以方法粒度的源代码为翻译对象,方法代码对应的注释为翻译目标,在使用序列编码器的同时,以门控图神经网络GGNN(Gated Graph Neural Network)[11]作图编码器,获得代码结构信息和数据流等信息的编码.并结合序列编码器构建双编码器模型.使用带有注意力机制[12]的注意力层提高模型性能,打破相同上下文变量对模型的限制.本文以方法源代码以及对应的注释作实证数据,构建实验对自动生成代码注释结果进行验证.
2 注释生成方法
2.1 Seq2Seq模型方法
最初的机器翻译模型是由一个编码器和一个解码器组成的序列到序列Seq2Seq(Sequence to Sequence)模型[13].使用两个循环神经网络分别作编码器和解码器,编码器可以将源代码编码为向量表示,解码器将向量表示的编码解码为翻译输出.例如将英语输入“They”、“are”、“watching”、“.”翻译为法语输出“Ils”、“regardent”、“.”,编码器在每个时间步输入每个英语单词、标点和结束符
步的隐藏状态作为输入句子的编码信息.解码器在各个时间步中使用输入句子的编码信息和上个时间步的输出以及解码器隐藏状态作为输入,最终将英语翻译为法语,

图1 Seq2Seq模型示例图Fig.1 Seq2Seq model example diagram
最初的Seq2Seq模型框架应用在代码学习中无法学习更多的代码结构信息,而是与自然语言翻译相同,将代码单词作为自然语言单词处理为编码器输入序列,只是简单的在代码单词与注释单词之间建立映射关系,解码输出注释序列,因此应用在注释生成中会导致生成注释质量较差的结果.
2.2 双编码器模型方法
为了充分学习代码语义信息,生成高质量、准确度高的注释,本文使用双编码器模型利用代码序列和代码图结构结合的方式获取更多的代码内在信息.该方法首先对源码文件进行预处理,在源码文件中提取以方法为粒度的代码与该方法对应的注释;构建算法提取代码词汇、注释词汇并建立这些词汇的词典,再用词典的索引组成代码序列、代码图序列以及注释序列.然后,分别将代码序列以及代码图序列输入各自对应的编码器中进行训练;最后经过注意力机制关注解码重点,将序列向量和图向量进行拼接后,经过线性变换,再由解码器解码并训练模型.
图2展示了生成注释方法的详细信息,整个模型包括数据预处理、编码、向量拼接以及解码4步.

图2 基于注意机制的双编码器模型架构图Fig.2 Architecture diagram of dual encoder model based on attention mechanism
第1步,数据预处理
从源码文件中提取以方法为粒度的代码段以及代码对应的注释,并过滤缺失注释的无效方法.然后对代码的方法名和变量名等单词根据字节对编码BPE(Byte Pair Encoder)[14]算法拆分扩充词典库.BPE算法是一种双字母组合的数据压缩算法,本文使用BPE编码将变量名反向解码拆分为子单词,例如String getTitle(String title){ return title;}代码中,方法名getTitle经过拆分后得到get和title两个单词.运算符、括号符号等分隔符以词法分析形式写入词典.将获取到的代码和注释的单词分别进行编号并创建词典.代码图是在抽象语法树中增加数据流向的边构成,图中除了节点信息还有表示节点之间关系的边.代码图序列由节点索引的集合以及节点边的集合组成.注释序列经过词到向量word2vec(Word to Vector)处理获得注释向量矩阵作为解码器学习目标.
第2步,编码
在编码训练中,代码序列中的每一个token对应的索引经过词嵌入处理为对应的词向量,代码的词向量矩阵作为输入,由LSTM神经网络训练输出序列向量hS.通过代码图遍历到图中节点时,将此节点与前驱节点和后继节点的边关系信息生成边的邻接矩阵.节点嵌入[15]后得到图节点的嵌入向量集合.节点向量集合与边矩阵经过GGNN训练输出图向量hG.编码器输出向量由编码过程中的各个时间步的隐藏状态变换得到.
第3步,向量拼接

第4步,解码
在解码训练中,本文使用方法代码对应的注释序列词向量作为解码目标,使用综合编码信息dt、上一个时间步的解码目标和上一个时间步的解码状态更新解码器当前时间步的隐藏状态,并获得当前时间步的解码器输出目标.
3 模型算法
3.1 序列构建
3.1.1 注释序列构建
本文首先对源码文件进行处理,只提取代码和注释完备的方法代码.然后提取注释中核心词汇组成代码注释序列.因为单纯的注释序列中词与词之间不存在任何关联,本文引入word2vec技术对注释序列做向量化处理,使得每一个词向量都能保存相应的上下文信息,获得翻译目标序列y={y1,y2,y3…yn}.相比较直接使用索引序列,词向量序列表现出更好的学习效果.

表1 token定义表Table 1 Token definition table
3.1.2 代码序列构建
本文利用代码token扩充代码词典,并重新定义大粒度代码token,如表1所示.定义新的token粒度是为了提高模型对长代码的处理能力以及更方便地处理代码序列,根据词token表抽取公共代码,将一行代码定义为一个token.并将代码token表中的数据加入代码词典中,扩充词典词汇量.在提取代码序列时,方法名、参数信息和返回值也会被提取,而且相同类型的变量被定义为同一个token.
本文提出代码序列提取算法,首先利用JavaParser包将方法代码转换为AST抽象语法树,并对方法名和变量使用BPE算法拆分;然后对AST前序遍历,查找token节点类型在代码词典CodeDict中的索引,组成代码序列List.
算法1:代码序列提取算法
输入:完整的方法代码Method,代码词典CodeDict;
输出:方法代码对应的序列List={tokenIndex}.
处理:
1.初始化List={};初始化栈Stack;
2.Root=AST(Method);//将Method转换为抽象语法树.
3.Stack.push(Root);//根节点入栈.
4.while Stack不为空 do
nodeToken=Stack.pop();
//如果nodeToken属于for、if或“=”等新定义的代码行粒度token,就将属于同一行代码的其他节点归并到当前节点中作为一个节点.
newNodeToken=MergeNode(Root,nodeToken);
// newNodeToken类型在CodeDict代码词典中.
if newNodeToken∈CodeDict then
List= List∪{newNodeToken.index};
遍历newNodeToken的孩子节点,并入栈.
end if
end while
5.输出代码序列List的字符串,结束算法.
表2是经过算法1处理方法代码所得到的代码序列示例.其中bubble的索引为10,sort的索引为11.

表2 代码序列广义表Table 2 Generalized code sequence table
3.1.3 代码图序列构建
为了获得代码图序列,本文利用JavaParser包将方法代码转换为AST,先将AST中的节点与边更新到图中;然后根据节点之间的关系添加数据流向边,在AST的基础上构成有向图结构;再经过处理后作为代码图序列.本文给出代码图序列提取算法,如算法2所示.
算法2:代码图序列提取算法
输入:完整的方法代码Method;
输出:方法代码对应的代码图序列Graph={V,E}.
处理:
初始化Graph,V=Φ,E=Φ;
1.Root=AST(Method);//将Method转换为抽象语法树.
2.将Root树中的原始边与所有的节点更新到Graph中.
3.List=PreOrderAST(Root);//先序遍历AST,获得节点集合List.
4.for i=0→ List.size-1 do
for j=0→ List.size-1 do
if List[i]和List[j]存在变量定义与使用关系 then
E=E∪{(List[i].id,List[j].id)};
end if
end for
end for
5.输出处理后Graph={V,E}的json字符串,结束算法.
通过代码图序列,构建边的邻接矩阵A=[A(out),A(in)],A是由节点的输出矩阵和输入矩阵组成,用于描述节点之间的边关系.最后将节点向量集合、边矩阵作为GGNN神经网络的输入.
3.2 模型训练
3.2.1 模型参数
模型有两个编码器,分别是序列编码器和图编码器.序列编码器采用LSTM作为神经网络,以代码序列作为输入,具有2个隐藏层和256个隐藏单元.图编码器采用GGNN神经网络,以代码图序列作为输入,具有256个隐藏单元.学习率设置为0.001.解码器采用单向LSTM,具有1层和256个隐藏单元.经实验验证,模型采用以上参数效果较好.
3.2.2 模型训练算法
算法3:模型训练算法
输入:输入预处理后的训练集数据,代码序列xS、代码图序列xG和注释序列y.
输出:得到两个编码器、注意力层、解码器的权重参数W和偏置值b.
处理:
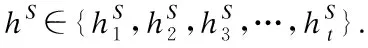
3.在解码训练中,以注释序列向量和综合向量作为输入,使得综合向量学习到注释序列向量的映射,并计算损失函数值loss.通过反向传播重新评估编码器输出向量,调整hS与hG,从(1)开始重复执行直至训练集数据训练完成.
4 实验研究
4.1 数据集
为了评估模型,本文使用Java-med数据集.该数据集是来自GitHub的1000个Java顶级项目的新数据集.该数据集包含约400万个方法,数据集中包含模型需要的源码信息以及注释信息[10].为了进行更有效的验证,本文对数据进行随机选择,其中80%的项目经过预处理后作为训练集训练模型,20%的项目经过预处理后作为测试集评估模型得分.
4.2 实验步骤
Step 1:数据预处理
对数据集进行数据预处理,过滤无注释数据.分别创建代码词典和注释词典,使用序列构建算法获取代码序列、代码图序列以及注释序列.分别制作训练集和测试集.
Step 2:模型训练
将训练集作为模型训练算法的输入训练模型,调整模型权重参数W和偏置值b.训练集数据训练完成后获得双编码器模型.
Step 3:模型验证
使用测试集检验双编码器模型效果,计算模型评估得分,进行手动调参并从STEP2重新开始执行,最终确定模型训练参数.
4.3 实验结果评估指标
本文将自动生成代码注释看作自然语言领域问题,模型框架也是基于传统翻译模型NMT实现.因此使用机器翻译评价指标BLEU-1[16]和ROUGE-L[17]对模型进行评估,同时还加入F1测评指标从多方面验证模型的有效性.
BLEU是一种基于精确度的相似性度量方法,用于评估模型结果与真实结果之间的相似性,相似性越高,得分越高,本文选用其中的BLEU-1作为测评指标[16].
ROUGE-L以翻译结果和实际结果之间的最长公共子序列为评估标准,得分越高越相似[17].
F1是精确度和召回率的加权调和平均,为了避免精确度和召回率不能全面评估模型,从而引入F1测评指标.
4.4 实验结果
本文考虑源代码的结构信息和序列信息,以更好地生成代码注释.表3和表4是部分案例,分别选定有代表性的代码方法,其中包括循环、判断等常见操作.

表3 实验结果1Table 3 Experimental results 1

表4 实验结果2Table 4 Experimental results 2
4.5 模型验证
实验1.模型得分对比
本文将提出的模型记为SG2Seq+Attn,SG2Seq为不使用注意力机制模型.模型使用双编码器,利用代码图结构学习代码的更多信息,并且引入注意力机制自动生成代码注释.本文将模型与以下模型在BLEU-1得分、F1和ROUGE-L分数方面进行比较.
Seq2Seq+Attn[8]是神经机器翻译中的经典编码器-解码器框架,作者对源代码序列使用RNN编码得到源代码的向量形式.然后利用解码器将其解码为目标注释,并引入注意力机制.
code2seq[10]使用AST抽象语法树中的路径集合作序列,使用BiLSTM神经网络作编码器,并在解码时引入注意力机制,然后通过LSTM解码获得注释序列.
表5展示了本文提出的模型与其他模型实验的对比结果.可以发现,在所有评估指标中,本文提出的模型得分均优于对比模型.code2seq利用AST两个叶子节点之间的路径提取代码特征,即代码到代码之间的关系,其中包含控制流、数据流等代码结构信息,并且在路径选择时有较大优化,因此效果较好.

表5 模型结果得分对比表Table 5 Score comparison table of model results
实验2.模型参数对比
隐藏单元决定编码器输出向量维度,表6展示了模型SG2Seq+Attn中编码器隐藏单元个数对模型的影响.根据得分结果可知,在编码器隐藏单元为512维时,模型效果得分最高.然而隐藏单元为512维时,训练时间过长,计算速度缓慢,提升效果不高.因此本文认为隐藏单元最合适的个数应为256.
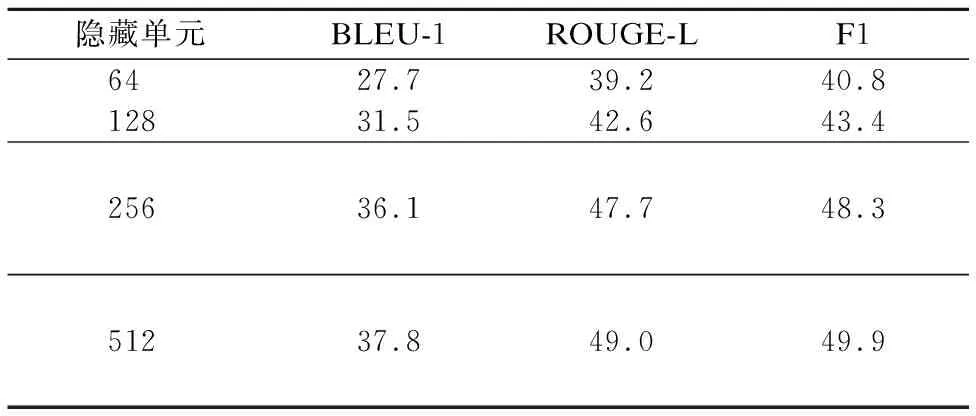
表6 不同参数模型得分对比表Table 6 Comparison of model scores with different parameters
4.6 代码长度影响分析
代码长度是模型性能的重要参考因素.随着检测代码长度的增加,模型的稳定性和准确性会受到一定影响.为了获得更好的对比,本文选择代码长度在1-30行之间的代码方法检验模型的F1得分,以此来获取代码长度对模型性能影响的直观表现.图3显示了本文提出的模型与其他模型在代码长度相同时的对比.从图中可以看出,随着代码长度的增加,模型性能逐渐下降.然而经对比可得,本文提出的模型与其他模型在代码长度相同时,F1得分仍优于其他模型.
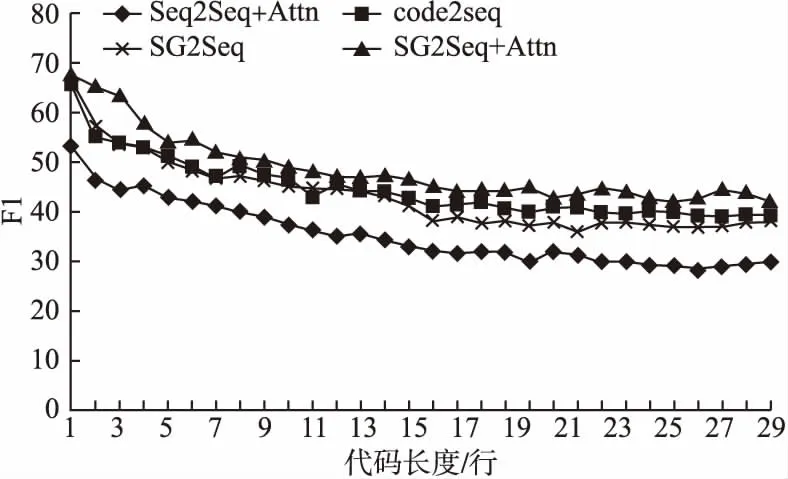
图3 模型对比图Fig.3 Model comparison chart
5 结 论
本文基于自动生成代码注释提出带有注意力机制的双编码器模型.首先通过数据预处理获取模型训练需要的数据.然后使用图编码器编码代码图结构信息,序列编码器编码序列信息,经过注意力机制对编码信息重新计算权重向量并对新向量进行拼接,再经过一层线性变换获得新的编码器综合向量.最后通过解码器解码,反向传播调整参数,训练获得模型.
实验结果表明,本文提出的模型在性能和效果上优于对比模型.并通过消融实验,证明引入注意力机制可以提高模型的稳定性和准确性.在未来的工作中还计划将此方法应用于其他软件工程任务,如代码搜索、代码补齐等.
