融合字根信息的卷积神经网络中文分词方法
2022-02-18于丽美
王 星,于丽美,陈 吉
(辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105)
1 引 言
与以英文为代表的拉丁语系语言不同,中文词与词之间没有天然的空格符进行间隔.相比于单字,词是表征中文语义最精确的计量单位,所以在进行后续自然语言处理任务之前,需要进行中文分词,将中文序列按照一定的规则切分成一个个的词.作为自然语言处理的基础任务,中文分词准确率直接影响机器翻译、信息检索、信息抽取、自动问答等信息处理技术的结果[1].
传统的中文分词方法主要包括机械分词和统计分词.机械分词又称为基于词典的中文分词方法,主要思想为构建匹配词典,将待分词与词典内容相匹配.统计分词通过计算统计语料中相邻出现的各个字的组合频度来反映成词的可靠度,当组合频度高于某一个临界值时,便认为其构成一个词.常用的统计分词模型包括条件随机场(Conditional Random Field,CRF)、隐马尔可夫(Hidden Markov Model,HMM)等.
近年来,由于能够避免繁琐的特征工程,深度学习逐渐被运用到分词领域.主要思想是将向量化的文本信息通过多层非线性变换后进行标签推理得到分词结果.2011年,Collobert等人[2]首次利用神经网络解决自然语言处理问题.2013年,Zheng等人[3]证明了深度学习在中文分词任务中的可行性,将字向量作为模型的输入,通过一种带窗口的神经网络模型提取文本深层次特征.在几乎不损失性能的情况下提升了模型速度.但由于窗口大小固定,只能利用到固定窗口大小的上下文信息,长距离文本信息被忽略.2014年,Pei等人[4]认为简单的转换分数和非线性变换很难完全捕捉到字符之间的相互关联,所以在Zheng等人的基础上提出最大张量边界模型MMTNN,利用张量和标签之间的关系表示标签与上下文之间的关系.2015年,Chen等人[5]提出一种带有重置门和更新门结构的递归神经网络模型来保留上下文信息.同年Chen等人[6]提出单向长短期记忆网络(Long Short-Term Memory,LSTM)获取上文信息进行分词,有效解决了长期依赖问题,但是单向LSTM网络未使用到下文信息导致文本信息没有被完全利用.2016年Yao等人[7]舍弃了窗口的方法,提出用双向LSTM神经网络进行中文分词,解决LSTM神经网络不能同时利用上下文信息的问题.2016年,Xu等人[8]提出一种基于门控神经网络的分词方法,将局部信息与长距离依赖信息结合进行分词.2018年Yang等人[9]利用Lattice-LSTM神经网络将子词信息融入到字符级特征中,利用子词信息消除歧义来提升分词效果.2019年Wang等人[10]提出一种基于膨胀卷积的中文分词方法,利用膨胀卷积提取文本特征,同时引入字根信息和残差结构[11],但膨胀卷积仍然会造成局部信息丢失,虽然增大感受野,却导致长距离信息之间没有相关性[12].
由于语料之间的差异性较大,通用领域训练好的分词模型往往不能直接运用到专业领域.在缺少大规模标注语料的情况下,基于深度学习的中文分词方法通常不能在领域分词中得到较高的分词准确率.而作为自然语言处理任务的基础,面向专业领域的中文分词具有更重要的意义.如法律领域,随着人工智能的发展,智能司法成为法律领域发展的必然目标,构建法律知识图谱成为法律人工智能的研究热点.知识图谱构建首先要进行知识抽取,知识抽取任务的数据预处理阶段需要分词处理,分词效果的好坏一定程度上影响知识抽取的效果,基础任务的误差积累会对知识图谱构建的整个过程造成影响.提升领域分词模型性能是领域分词的重要任务.
为了提升分词模型在领域分词的性能,通常采用迁移学习或者引入外部词典的方法.2017年Deng等人[13]针对分词模型的领域移植问题,提出一种基于半监督CRF的跨领域中文分词方法.将有监督学习运用到通用领域,结合目标领域的无监督学习,通过半监督方式解决跨领域分词问题,同时结合领域标注语料和字典来提高未登录词的召回率.2019年Jiang等人[14]提出基于联合学习的跨领域法律文书中文分词方法,将某一领域法律文书作为目标领域的辅助数据,利用LSTM对目标领域进行预测,一定程度上提升了分词性能.同年,Cheng等人[15]提出一种自适应中文分词方法,构建含词典特征的深度学习模型,在通用领域训练好模型后通过参数微调将模型迁移到法律领域,同时增加法律词典提高领域分词性能.
以上模型在中文分词任务中虽然取得了较好的分词结果,但仍存在以下问题:
1)词向量蕴含的语义信息的丰富性还有待提升,由Word2Vec、GloVe训练得到的静态词向量不能解决多义词问题;
2)循环神经网络不能并行计算的特性使以LSTM神经网络为主的分词模型在计算效率方面受限,而卷积神经网络容易出现信息丢失的问题.
3)通用分词模型在领域分词任务上效果不佳,提升领域分词效果需要大规模标注数据和引入领域词典,分词效果依赖于词典的质量和规模且无法在仅拥有少量标注数据的情况下得到较好的分词效果.
针对以上问题,本文提出一种以字根信息为辅助特征的中文分词方法ABRCWS,模型分为主任务和辅助任务.辅助任务通过查找表得到文本数据的字根向量表示,经过卷积提取特征后进行序列标注.主任务通过轻量级预训练语言模型ALBERT[16]训练动态词向量,通过去池化卷积残差神经网络进行特征提取,将提取的特征与辅助任务特征提取层的输出进行融合后通过序列标注得到最终分词结果.损失函数为主、辅任务损失的线性加权之和.实验证明,在多数通用领域数据集上分词综合评价指标达到最优,在小型法律标注数据集上最高达到97.90%.
2 ALBERT模型
ALBERT采用基于Transformer[17]的双向编码方式,编码结构如图1所示.Transformer由堆叠的编码器和解码器构成.编码器与解码器的构成如图2所示,编码器由自注意力机制层和前馈神经网络层构成.解码器在与编码器相同的注意力机制与 前馈神经网络层之间增加一层注意力机制层,帮助当前节点获取当前需要关注的重点内容.

图2 编码器、解码器结构Fig.2 Structure of encoder and decoder

attentionoutput=Attention(Q,K,V)
(1)
(2)
为了提取不同表示空间中的注意力,ALBERT模型中采用多头注意力机制.将Q、K、V向量经过h次线性变换,将h次自注意力机制的计算结果拼接,得到更丰富的语义特征.计算定义如公式(3)-公式(4).其中headi表示在某一空间提取的注意力,MultiHead表示多个表示空间提取的注意力的联合表示.
(3)
MultiHead=Concat(head1,…,headh)WO
(4)
因式分解与跨层参数共享
动态语言模型虽然在自然语言处理多项任务中取得了非常好的效果,但同时存在着计算时间较长,内存需求较大的问题.为了突出语言模型中隐藏层学习上下文相关信息的能力,并且使模型更轻便,ALBERT模型通过因式分解将one-hot向量先映射到低维空间E,再映射到隐藏空间,使词嵌入参数O(V×H)从降低到O(V×E+E×H).V表示词典大小,H表示隐藏层大小.同时为了提高模型效率,共享所有层的所有参数.
3 ABRCWS分词模型
基于深度学习的中文分词方法通常将分词转化为序列标注任务[18],其核心是将标签序列中的标签正确赋予给字符序列中的每一个字符.常用的标注方式有4词位和6词位,本文选用4词位序列标注方式.标签序列为{B,M,E,S},其中B表示词语的开始字符,M表示中间字符,E表示结尾字符,S表示单字成词.序列标注模型主要构成为3部分:特征表示层、特征提取层、标签推理层.
3.1 特征表示层
3.1.1 主任务特征表示层
主任务词向量通过ALBERT语言模型训练得到,训练过程如图3所示.输入文本数据之后,ALBERT将文本处理成位置向量、段向量和文本向量相加的形式,经过以注意力机制为核心的多层Transformer进行编码得到最终的词向量表示.
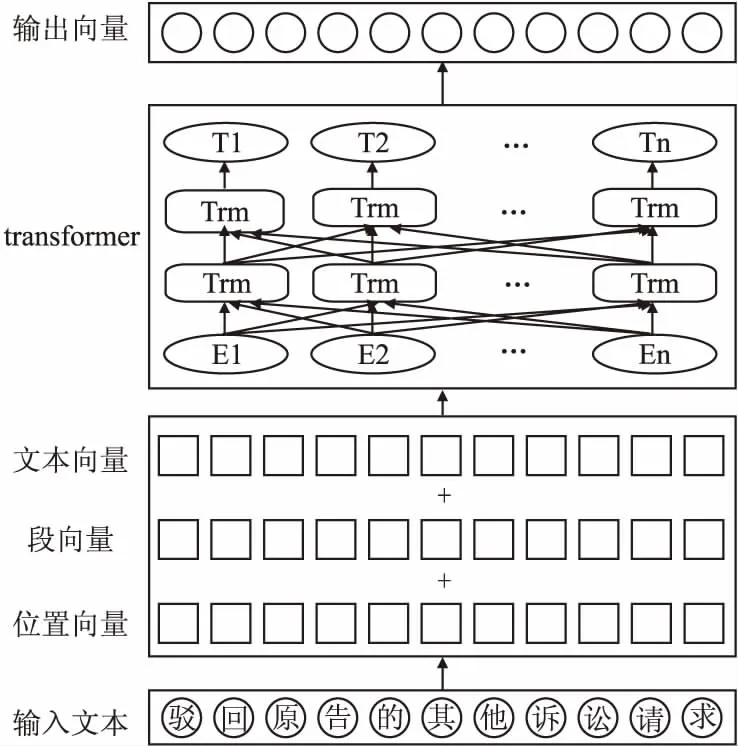
图3 词向量训练过程Fig.3 Process of training the word vector
3.1.2 辅助任务特征表示层
作为汉字的基本组成,字根具有汉字丰富的语义特征.如“诉”、“讼”的汉字字根都为“言”,由字根可知,两个字含义相近,语义层面都有“控告”“争辩”的含义.所以在词向量中融合字根信息,对词向量的精确表征具有重要帮助.

图4 获取字根向量过程Fig.4 Process of getting radical vector
获取字根向量的过程如图4所示.首先在字根词典中找到文本字符的字根表示,然后利用查找表的方式将字根转化为字根向量.由于字根携带的语义信息多存储于繁体汉字中,在简体字中的部分汉字已经丢失其繁体表示的字根信息,如“月”在“朗”字中表示“明亮”的意思,而在“腿”字中表示的原始含义为“肉”,本文引用了Dong[19]提出的方法,在处理字根表示过程中将简体字的汉字字根转化为其原始表示的含义.
3.2 文本特征提取
卷积神经网络最初应用在图像领域,近年来在文本领域取得较好的实验效果.传统卷积神经网络对数据进行卷积操作之后,会经过一个池化层对所提取的特征进行筛选,以选取最有意义的特征信息.然而池化层会导致部分信息丢失.Tu[20]等人认为由于字向量和图片的像素属于不同性质的两种特征,并且字向量在训练过程中已经进行了一定的特征筛选和简化,不再需要池化层做进一步的特征筛选.所以本文在对文本数据进行卷积操作之后去掉了传统卷积神经网络中的池化层.
3.2.1 主任务特征提取

图5 文本特征提取过程Fig.5 Process of extractingtext feature
1,2https://wenshu.court.gov.cn
zt=Wc⊗X+bt
(5)
(6)
(7)
在网络层数不断加深的过程中,由于参数初始化接近于0,会出现梯度消失的问题,导致浅层参数无法更新.小权重会对梯度传播造成一定的阻碍致使在初始训练阶段网络启动之前需要多次迭代,影响模型时间效率.在深度学习中,增加网络深度可以使模型效果更优,但是在网络已经达到最优时再加深网络会使网络难以优化从而导致网络退化.为了利用深层网络提取更丰富的文本特征,本文在卷积神经网络中使用残差连接解决梯度消失和网络退化的问题.加入残差结构之后,计算过程如公式(8)所示:
(8)
将上述操作作为一个残差块L()并重复n次,得到特征提取最终结果,定义如公式(9)所示:
(9)
3.2.2 辅助任务特征提取
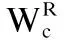
(10)
3.3 标签推理
3.3.1 主任务标签推理
对于主任务,标签推理层的输入为主任务和辅助任务特征提取层的特征融合之后的向量表示.定义见公式(11).
(11)

ht=WoEt
(12)
接下来使用SoftMax获取条件概p(y│X).计算定义见公式(13),其中hi表示公式(12)计算的标签得分.预测时,将得到的标签概率通过公式(14)求出最终结果.
(13)
y*=argmaxy∈YXp(y|X)
(14)
3.3.2 辅助任务标签推理层

(15)
(16)
(17)
3.3.3 损失函数
虽然对字根进行原始含义转换可以减少简体汉字与繁体汉字不同带来的差异,但为了避免字根表示的误差对分词任务产生较大的影响,模型损失函数为主任务和辅助任务的线性加权之和.定义见公式(18),其中T、C分别表示主任务和辅助任务中字符可能赋予的标签结果个数,h为模型推测的标签,y表示字符真实标签.角标为R的变量表示辅助任务中同等含义的变量.λ控制主、辅任务损失函数权重的变量.
(18)
4 实 验
4.1 实验环境、数据集和评价标准
本文实验配置为:Inter(R)Core i7-6800K@3.40HZ处理器,操作系统Ubuntu16.04LTS(64bit),运行内存16GB(RAM),显卡:GIGA-BYTE CeForce GTX1080Ti,使用TensorFlow1.12构建神经网络模型进行训练和测试.
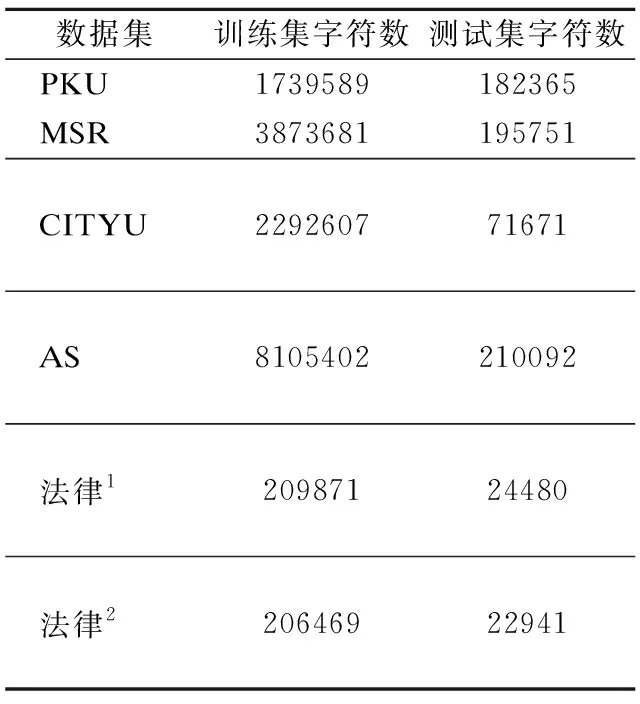
表1 数据集Table 1 Data set
对于通用领域,本文分别在SIGHAN国际汉语分词数据集BakeOff2005的PKU、MSR、CITYU、AS这4个数据集上进行实验.为验证本文提出的分词模型ABRCWS在少量领域标注数据集上的分词效果,本文使用法律领域数据集对模型进行训练以及测试.分别从中国裁判文书网 的刑法和民事合同法两个领域选取部分判决书作为法律领域小型标注数据集,其中刑事领域数据集为法律1,民事领域数据集为法律2.数据集规模如表1所示.随机选取训练数据的90%作为训练集,10%作为测试集.所有实验采用标准BakeOff评分程序常用的评价指标:P(精确率),R(召回率),F1(召回率和准确率的调和平均值),以F1值为主要评价指标,计算公式见公式(19)-公式(21).
(19)
(20)
(21)
4.2 超参数设置
4.2.1λ值设置
本文选择不同的λ值来调整辅助任务中字根信息对主任务分词的影响程度.目的是减少辅助任务中字根信息产生的误差对整体分词结果造成的负面影响,最大程度利用字根特征的有效信息.λ表示辅助任务对主任务分词结果的影响程度,越接近0表示影响程度越小,越接近1表示影响程度越大.本文设置λ在[0.5,0.9]区间内取值进行实验,以大型数据集AS和小型法律数据集法律2为例,实验结果如图6所示.观察图6中λ不同取值的实验结果可以发现,当λ=0.7时实验结果能达到最优,在λ≤0.6和λ≥0.8时实验结果都出现了不同程度的下降,所以当λ=0.7时能够使辅助任务产生的噪音对主任务的影响最小并且对分词结果的提升帮助最大.

图6 不同λ取值的实验结果Fig.6 Experimental results of different λ values
4.2.2 其他参数设置
实验的其他参数设置如表2所示.初始词向量维度为ALBERT模型的向量维度768,在分词模型中提取初级特征时将词向量维度调整为300.在主任务使用卷积提取文本初级特征时,当卷积核为7时实验效果达到最好.在卷积残差神经网络中,为了提取更详细的文本特征,卷积核设置为5,卷积神经网络层数为6.另外,初始学习率设置为2e-5,batch-size为32,迭代次数为6.

表2 超参数列表Table 2 Hyperparameters list
4.3 实验设计
为了验证去池化卷积神经网络、残差连接在特征提取中的有效性和字根信息序列标注作为辅助任务辅助分词的作用,本文将仅用ALBERT的分词模型、ALBERT结合去池化卷积神经网络的分词模型(ALBERT+CNN)、ALBERT结合去池化卷积残差神经网络分词模型(ABCWS)与本文提出字根信息辅助分词的ABRCWS模型实验结果进行对比,结果如表3所示.

表3 ALBERT、ALBERT+CNN、ABCWS、ABRCWS实验对比(%)Table 3 Comparison of ALBERT、ALBERT+CNN、ABCWS、ABRCWS(%)
为分析CRF和SoftMax解码方式对分词效果的影响,将本文提出的ABRCWS模型与ABRCWS+CRF模型的实验结果进行对比,分词结果如表4所示.运行时间对比如表5所示.在每个数据集中,速度最快的设为1,其他为与速度最快模型所用时间的比值,比值越大表示运行时间越长.

表4 CRF、SoftMax解码实验结果对比(%)Table 4 Comparison of experimental results of CRF and SoftMax decoding(%)

表5 CRF、SoftMax解码速度对比Table 5 Comparison of decoding speed between CRF and SoftMax(%)
为证明本文提出的ABRCWS模型的有效性,将ABRCWS模型与Chen等人提出的基于LSTM中文分词模型,Xu等人提出的基于GRNN改进的分词模型,Yang等人提出的引入子词的分词模型以及Wang等人提出的引入字根信息的膨胀卷积神经网络分词模型进行实验对比,实验结果如表6所示.

表6 与各模型实验对比(%)Table 6 Compared with each model experiment(%)
4.4 实验分析
4.4.1 精确度分析
由表3中的实验结果可见,本文提出的ABRCWS分词模型在多数数据集上分词精确度都达到95%以上,在具有少量标注数据的法律数据集中最高达到97.88%.通用领域中,MSR数据集为最高,达到97.77%.观察模型ALBERT和ALBERT+CNN的实验结果发现,在加深卷积网络的过程中,在除AS以外的数据集上的精确度均出现不同程度的下降,在法律1数据集上下降最高,降低了3.9%,证明在加深网络过程中出现了网络退化的现象.由ABCWS模型的实验结果发现在加入残差连接之后,精确度提高并且除MSR外的所有数据集中精确度都超过ALBERT模型的分词结果,证明去池化卷积能够提取更精确的文本特征并且残差连接有效解决网络退化问题.在加入字根信息之后,除CITYU外的所有数据集上精确度都达到了最高,说明字根信息对提高分词效果有一定的帮助.
4.4.2 标签预测方式分析
由ABRCWS模型与ABRCWS+CRF模型分词结果对比发现,采用CRF进行解码的分词时间均高于使用SoftMax解码的分词时间.而在分词效果上,在加入CRF之后,反而在数据集PKU和法律1以及法律2上出现实验效果变差的情况.其他数据集略有增加,但最高为数据集CITYU,只增加0.13%,时间却为SoftMax的1.4倍.实验证明双向预训练语言模型能够编码足够丰富的语义、句法等信息,具有足够强的拟合能力.在此情况下不需要CRF的转移矩阵便可以达到最好实验效果.
4.4.3 与其他分词模型实验结果对比
与Chen等人提出的基于LSTM的神经网络模型实验结果相比,本文提出的ABRCWS模型在PKU数据集上F1值高出1.5%,在MSR数据集上高出2.2%.与Xu等人提出的基于门控递归神经网络分词模型相比,在PKU和MSR数据集上,ABRCWS模型的F1值分别高出0.2%、1.5%.证明本文提出的分词模型能够比基于RNN循环神经网络变体的分词模型获得更好的实验效果,卷积神经网络在中文分词中可以提取丰富的文本特征.与Yang等人提出的在中文分词中引入子词特征的分词模型相比,ABRCWS模型在PKU数据集上的F1值高出0.5%,证明相比于在模型中额外引入子词信息,ALBERT预训练过程中的wordpiece子词特征能够对分词性能的提高有一定的帮助,且字根特征能够提供丰富的语义信息.与Wang等人提出的膨胀卷积神经网络的中文分词模型实验对比发现在除AS之外的3个数据集上,ABRCWS分词模型的实验结果都达到了最优,证明相比于膨胀卷积神经网络,去池化卷积神经网络能够在一定程度上避免有用信息的丢失,且动态词向量能够比静态词向量携带更丰富、更深层次的语义信息.
5 结 论
本文主要工作有以下几点:
1)使用字根信息进行序列标注作为辅助任务,辅助主任务进行分词;
2)使用去池化卷积进行文本数据特征提取,防止特征丢失;
3)在卷积神经网络中增加残差连接避免梯度消失以及网络退化问题.
实验表明本文提出的ABRCWS模型在领域分词中,只有少量标注数据集的情况下,不借助外部词典的帮助可以使分词评价指标F1值达到96%以上.在通用领域数据集上,本文提出的模型比经典分词模型的效果更优.
通用领域分词虽然使用预训练语言模型可以得到较好的分词效果,但仍然面临训练时间较长的问题.对于领域分词,虽然在少量标注数据下可以得到不错的分词效果,但是仍然需要为每一个小领域标注数据.在后续实验中,将继续寻找更高效的分词方法,提高分词模型的领域适应性.
